






从数据页的角度看B+树
mysql8的存储引擎采用的 InnoDB
那InnoDB是如何存储数据的?
记录存储是采用 行 来存储,读取按照 数据页 的方式来读。也就是说每次读一条记录的时候,并不是将记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。数据库的I/O操作最小单位是页,InnoDB数据页的默认大小是16kb。
一个数据页的组成:
| 名称 | 说明 |
|---|---|
| 文件头 | 表示页的信息 |
| 页头 | 表示页的状态信息 |
| 最小和最大记录 | 两个虚拟的伪记录,分别表示页中的最小记录和最大记录 |
| 用户记录 | 存储行记录内容 |
| 空闲空间 | 页中还没被使用的空间 |
| 页目录 | 存储用户记录的相对位置,对记录起到索引作用 |
| 文件尾 | 校验页是否完整 |
在文件头中有两个指针,分别指向了上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表
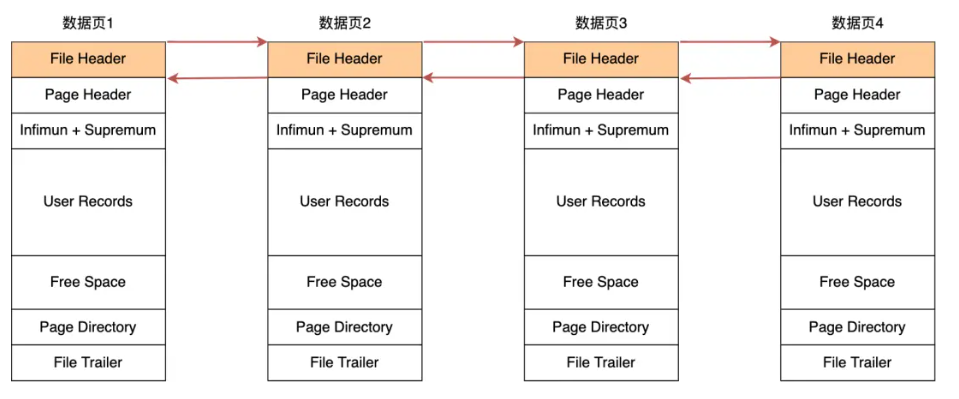
这样的链式结构让数据页之间在逻辑上产生连续的关系。
数据页的主要作用还是用来存储数据库数据的,那用户记录中是如果存储数据的?
每个数据页内的数据按照 主键 顺序组成了 单向链表。单向链表插入、删除比较方便,但是搜索太慢,应该怎么办?
因此,数据页中要有一个页目录,起到索引的作用。
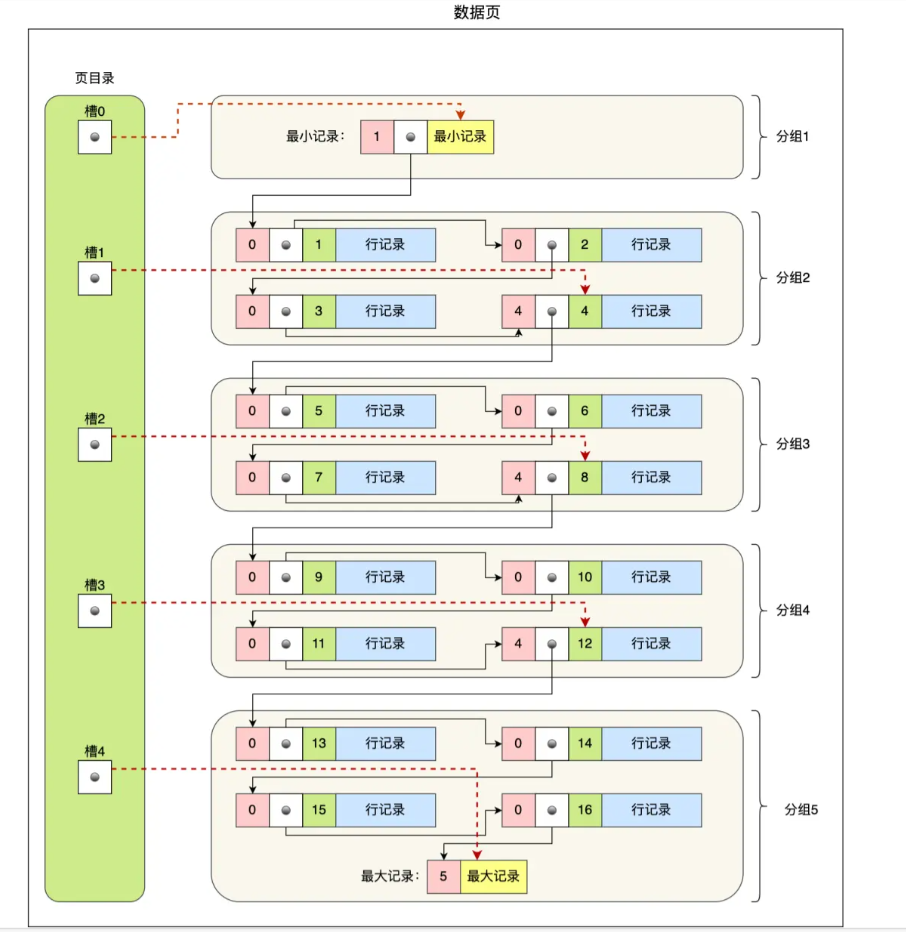
页目录的创建过程
- 先将所有的记录划分成几个组。记录中不包含 标记“已删除”的记录;
- 每个记录组中最后一条记录就是 组内最大的数据,并且最后一条记录的头部信息会存储该组的数据总数;
- 页目录用来存储每组最后一条数据的地址偏移量。这些地址偏移量会按先后顺序存储起来,每组的地址偏移量也被称为槽(slot),每个槽相当于指向了对应组中的最后一条记录。
最终,页目录将由多个槽组成,槽也就相当于分组记录的索引了。每次当通过槽查找记录的时候,可以使用二分快速定位到要查询的记录在哪个槽,定位槽后,在遍历槽内所有记录,便可以找到对应的记录了。
B+树是如何进行查询的?
上面分析的是在一个数据页中进行数据检索,因为一个数据页中的所有记录是有限的,且主键值是有序的,所以通过对所有记录进行分组,然后将组号存储到页目录,使其起到索引作用。
但是当数据页多的时候,我们就需要考虑如何建立合适的索引了。
InnoDB在这里采用了"矮胖"的B+树数据结构,这样对磁盘的I/O次数更少,而且B+树更适合进行关键字的范围查询。
InnoDB里的 B+树中的每个节点都是一个数据页:
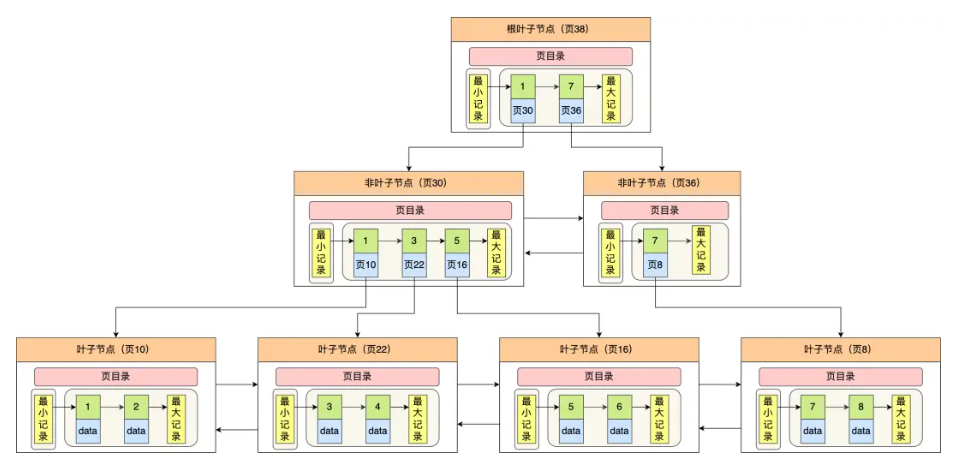
从图得出,B+树的特点:
- 只有叶子节点(没有子节点的节点)才存放数据,非叶子节点仅存放目录项作为索引
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询。
聚簇索引和二级索引
索引可以分为 聚簇索引和非聚簇索引(二级索引),它们区别就在于叶子节点存放的是什么数据:
- 聚簇索引的叶子结点存放的是实际数据,所有完整的用户记录都存放在聚簇索引的叶子节点;
- 二级索引的叶子节点存放的是主键值,而不是实际数据;
因为表的数据都是存放在聚簇索引的叶子节点里面,所以InnoDB存储引擎一定会为表创建一个聚簇索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个。
InnoDB创建聚簇索引的时候,会根据不同场景选择不同的列作为索引:
- 如果有主键,默认使用主键作为聚簇索引的索引键;
- 如果没有主键,会选择第一个不包含null值的唯一列作为聚簇索引的索引键;
- 上面两个都没有的情况下,InnoDB将自动生成一个隐式自增id列作为聚簇索引的索引键;
一张表只能有一个聚簇索引,那为了实现非主键字段的快速索引,就引出了二级索引(非主键索引),它也是利用了B+树的数据结果,但是二级索引的叶子节点不在存放实际数据,而是存放主键值。
二级索引的B+树如下图:
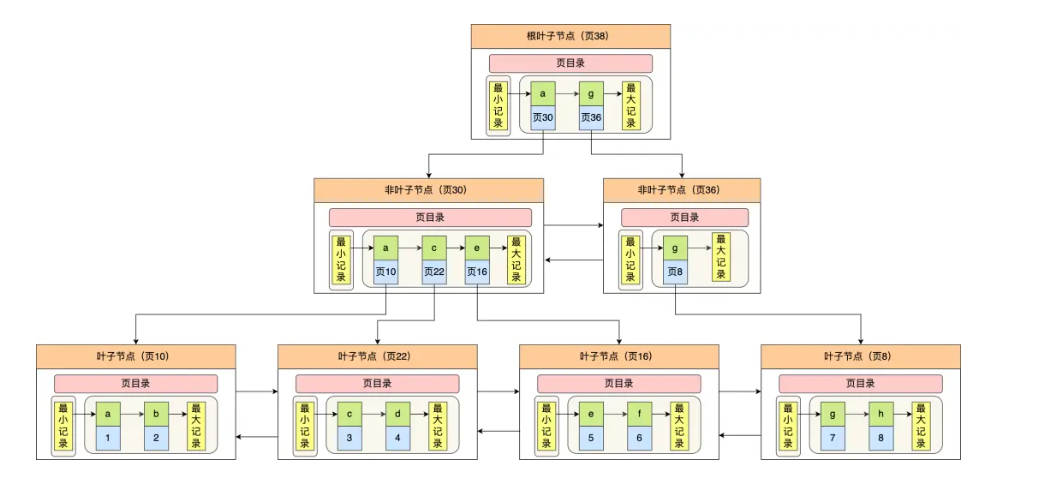
因此:如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获取数据行。这时也就要求查两个B+树才能查询到最终数据,这个过程叫做 回表。
当查询的数据是主键值时,那仅通过二级索引便可查到,不用再通过聚簇索引查询。这时只需要查询一个B+树就能查询到了最终数据,这个过程就叫做 索引覆盖
总结
-
InnoDB的数据按 数据页 为单位来读写的,默认数据页大小为16KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但逻辑上连续。
-
每个数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在页内查询速度,设置了页目录,页目录存储的是各个槽(分组),且主键值有序,此时便可通过二分快速查找。
-
数据页多的情况下,InnoDB采用B+树作为索引,每个节点都是一个数据页。
-
叶子节点存储的数据就是实际数据那就是聚簇索引,一个表只能有一个聚簇索引;如果叶子结点存储的不是实际数据,而是主键则是二级索引,一个表中可以有多个二级索引。
-
使用二级索引的情况下,又分为 回表 和 索引覆盖 两种情况















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









