







前提:模式匹配的在干嘛?
答:模式匹配的目的就是找到字串在在主串中的位置,根据结束条件的不同可以区分成两种情景,第一:找到字串第一次出现的的位置,第二:字串出现的次数,这里我们只讨论第一种。
关于两个指针i和j的解释:在全文都是这个逻辑
i 和 j 分别作为主串S 和 模式串T中当前正待比较的字符的位置。
1.BF暴力匹配
前提:暴力匹配很好理解,里面的数学逻辑也比较简单这个我简单赘述一下。

这个是王道书上的代码。
1.关于两个指针i和j的解释:
i 和 j 分别作为主串S 和 模式串T中当前正待比较的字符的位置。
2.关于else中 i = i - j + 2的数学模型:

2.KMP匹配
前提1:为什么提出KMP算法?
因为BF算法太过于耗费时间,然而从BF算法的过程中我们能够提取到更快捷的方法。
注意:KMP算法是在BF算法和部分匹配值两者结合获得的灵感,看我下文解释。
前提2: 字符串的前缀、后缀和部分匹配值三者的概念和关系。
概念:
字符串前缀:除最后一个字符以外,所有”头部字串“。
字符串后缀:除第一个字符以外,所有”尾部字串“。
部分匹配值:字符串前后缀最长相等的前后缀。
注:头部字串表示一定是从头开始必须包含头元素的不间断字串
尾部字串表示一定是从结尾开始必须包含尾元素的不间断字串
例子:” ababa “

对应PM表(Partical Match):
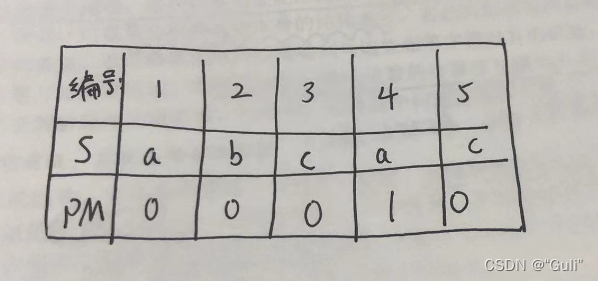
重点
需要强调,这里的PM表是数组的形式,下标是以0开始的,从而也就引发下文对PM的第一次优化。
假设当我们匹配到 ab 时子串的 b字符与主串中对应位置字符匹配失败,我们发现已匹配字符串最后一个元素 a 所对应的部分匹配值是在PM表中下标是 字符a 的对应编号 - 1的位置。,所有我们对PM表进行第一次优化,进而有了next表。
注: 要理解对应匹配值讲的是一个字串前后缀的匹配关系。
部分匹配值的使用
结论:在KMP算法中 i 指针是不回退的(既主串始终没有回退),只有 j 指针去寻找匹配失败后的位置
j = 移动位数 + 1
移动位数 = 已匹配字符数 - 对应的部分匹配值(已匹配字符的部分匹配值)
原理:

通过上述我们发现可以不用移动 i 指针,直接移动 j 指针,就可以完成匹配,那移动的规律我们也能从上述中找到:
语言描述:
既当某个字符匹配失败,我们只需要让 j 移动到已经匹配子串中对应匹配值所对应的匹配位置,既当上述图片①在最后一个c字符匹配失败后,已经匹配子串abca中前后缀相同的最长的位置既 ④的位置,此时 j的指针应该指在④的第一个字符a的后边。
数学计算:
上述我们分两步计算:
第一:子串的移动。既跳过② ③直接到④的数学公式
第二:指针 j 的位置。既当前要重新比较新位置是否匹配。
右移(移动)位数 = 已经匹配字符数 - 对应的部分匹配值
所以:Move = (j - 1) - PM[j-1]
解释:
j表示当前不匹配指针的位置,所以 j-1 表示当前匹配的长度。
PM为什么用j-1作为下标,上文我已经在PM第一次出现的地方讲过。 我再讲一遍:PM表是数组的形式,下标是以0开始的,而j指针是从1开始的,所以已经匹配到的子串的最后一个元素对应的,所以对应的部分匹配值是在PM数组中下标是最后一个元素位置-1
那我们开始计算 j 指针:
j = j - Move = j - {( j -1 ) - PM[j-1] } = PM[j-1] + 1
解释:这里为什么子串会右移?
这里是因为 i指针是没有回退的,当j指针指向新的位置后,就要去和i所指向的主串进行比较从而构造了一种子串移动的效果,如图:
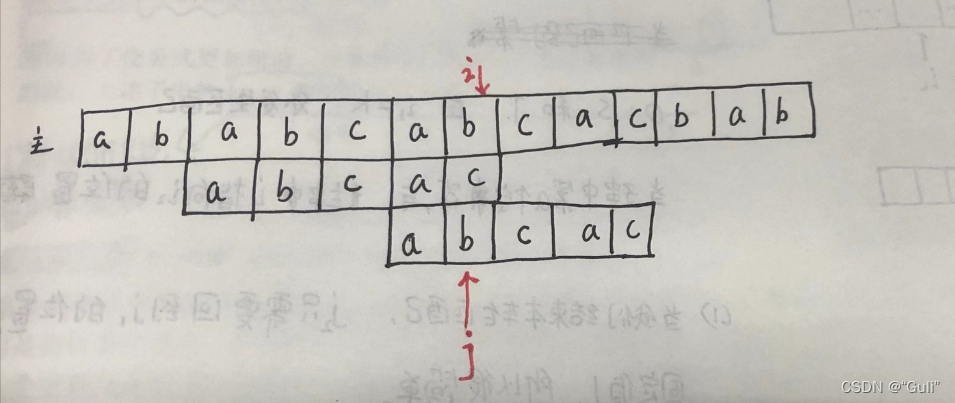
两次优化:
第一次优化
是对PM[]数组进行优化:使其不用 j-1 而是直接用 j 就能找到对应部分匹配值,减少一次j-1的计算。
让PM的元素都往后移动一位,第一位补-1,最后一位舍去,解释如图

结论:
优化后: j = next[j] + 1
第二次优化:
让next数组中对应的元素都+1,第二次优化比较简单,目的就是在改变j指针时只需要一个next数组就好。
结论:
优化后 j = next[j]















 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









