







文章目录
前言
“ 大 数 据 " 定 义
(1)最 早 提 出 “ 大 数 据 " 这 一 概 念 的 全 球 知 名 咨 询 公 司 麦 肯 锡 ( 詹 姆 斯 . 麦 肯 锡 , 美 国 芝 加 哥 大 学 商 学 院 教 授 、 麦 肯 锡 公 司 创 始 人 。 ) 的 定 义 : “ 大 数 据 " 是 指 在 一 定 时 间 内 无 法 用 传 统 数 据 库 软 件 工 具 采 集 、 存 储 、 管 理 和 分 析 其 内 容 的 数 据 集 合 。
(2) 研 究 机 构 Gartner 是 这 样 定 义 “ 大 数 据 " 的 : “ 大 数 据 " 是 需 要 新 处 理 模 式 才 能 具 有 更 强 的 决 策 力 、 洞 察 发 现 力 和 流 程 优 化 能 力 的 海 量 、 高 增 长 率 和 多 样 化 的 信 息 资 产 。
一、Hadoop是什么

二、搭建Hadoop环境
1.JDK安装
代码如下(示例)
第一步需要先自己下载java的安装包,在官网上下载安装包即可,然后解压到自己想要存放的文件夹下
这里附上java官网下载地址
https://www.oracle.com/java/technologies/downloads/
配置环境变量
vim /etc/profile
在/etc/profile最后加入这一段
export JAVA_HOME=/root/software/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
使用source /etc/profile 使环境变量立即生效
在输入java查看是否安装成功
(这里可以设置ssh免密登录,但是此处不展示,可以私信我)
2.搭建HDFS伪分布群
2.1 配置环境变量hadoop
在官网上下载自己需要的hadoop安装包版本
先解压hadoop压缩包到/usr/hadoop目录下
Vim /etc/profile
export HADOOP_HOME=usr/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Source /etc/profile
切换到该目录下
cd hadoop-2.7.7/etc/hadoop
ls一下可以显示所有的配置文件
2.2 配置环境变量hadoop-env.sh
修改该文件中的JAVA_HOME的值
export JAVA_HOME=/usr/java/jdk位置
2.3配置核心组件core-site.xml
<!-- HDFS集群中NameNode的URI(包括协议、主机名称、端口号),默认为 file:/// -->
<property>
<name>fs.default.name</name>
<!-- 用于指定NameNode的地址 -->
<value>hdfs://master:9000</value>
</property>
<!-- Hadoop运行时产生文件的临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.7/hdfs/tmp</value> # 补充代码
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value> # 补充代码
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value> # 补充代码
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value> # 补充代码
</property>
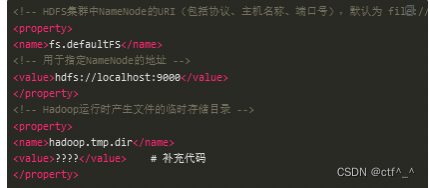
2.4 配置文件系统hdfs-site.xml
<!-- NameNode在本地文件系统中持久存储命名空间和事务日志的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<!-- DataNode在本地文件系统中存放块的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<!-- 数据块副本的数量,默认为3 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--hdfs文件操作权限,false为不验证,关闭集群权限校验,允许其他用户连接集群-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--指定datanode之间通过域名进行通信-->
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
放在文件中即可
3.搭建YARN伪分布集群
3.1配置计算框架 mapred-site.xml
- mv mapred-site.xml.template mapred-site.xml
修改hadoop2.7.7中etc/hadoop目录下mapred-site.xml文件 ,在标签中添加以下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.2配置环境变量 yarn-env.sh
加入 export JAVA_HOME=/usr/java/jdk名称
3.3配置环境变量 yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
4.同步到SLAVE1,SLAVE2
1.先该文件夹中
Vim master 里面输入 master
Vim slaves 里面输入
Slave1
Slave2
2.Scp -r /usr/hadoop root@slave1:/usr/
Scp -r /usr/hadoop root@slave2:/usr/
进行同步
5.再在SLAVE1,SLAVE2上面解压java并添加环境变量
export JAVA_HOME=/root/software/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
之后在master上格式化

hadoop namenode -format
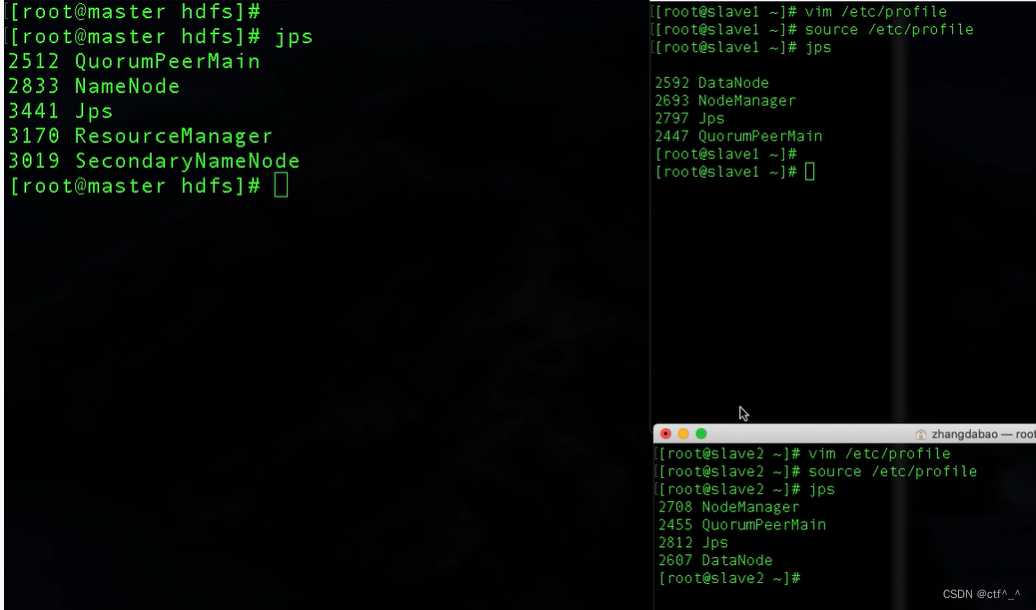
star-all.sh 启动所有集群
在输入jps即可检测是否运行成功
总结
例如:以上就是今天要讲的内容,本文简单介绍了hadoop集群的搭建。














 4724
4724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









