






仅供学习,请遵守法律法规和robots协议。
请在爬取时设置爬取延时,防止给网站造成不必要的麻烦和损失,也避免给自己送进去。

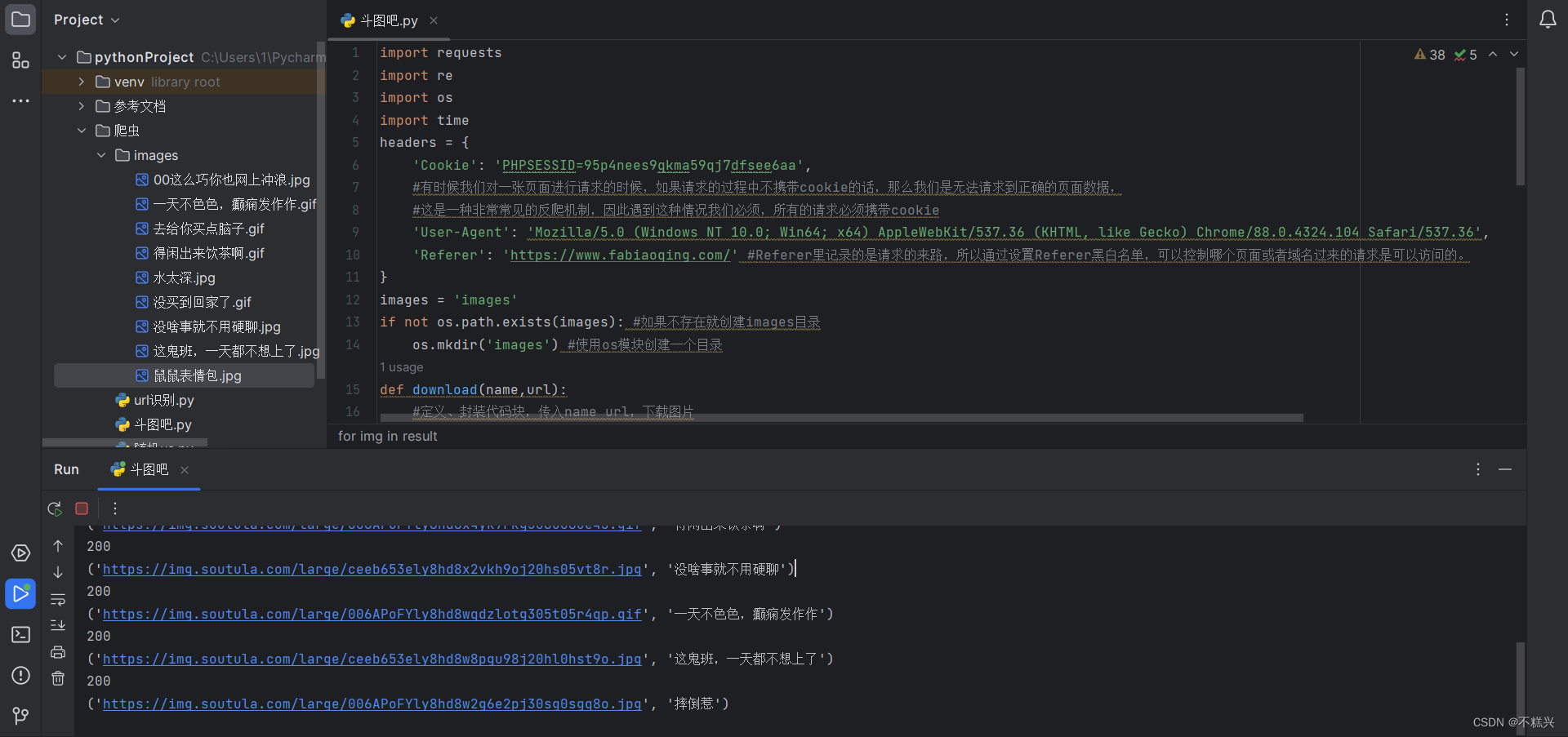
爬取图片一般需要导入的库有:
import requests
import re #正则表达式(.*?)
import os #os用来创建文件夹保存图片
import time #设置延时站主加了cdn防盗链、cookie反爬等机制,我们在 header{} 中除了 user-agent 外还需要加入:
Referer 和 Cookie ,如下:
headers = {
'Cookie': 'PHPSESSID=95p4nees9qkma59qj7dfsee6aa',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'Referer': 'https://www.fabiaoqing.com/'
}cookie:有时候我们对一张页面进行请求的时候,如果请求的过程中不携带cookie的话,那么我们是无法请求到正确的页面数据,这是一种非常常见的反爬机制,因此遇到这种情况我们必须,所有的请求必须携带cookie
referer:Referer里记录的是请求的来路,所以通过设置Referer黑白名单,可以控制哪个页面或者域名过来的请求是可以访问的。(设置成他网站的主页即可)
然后,创建一个目录保存下载的图片:
images = 'images'
if not os.path.exists(images): #如果images目录不存在就创建一个
os.mkdir('images') #使用os模块创建一个目录定义一个代码块,只需要在里面传入 name、url ,就可以下载图片:
def download(name,url):
#定义、封装代码块,传入name url,下载图片
response = requests.get(url,headers=headers)
print(response.status_code)#200表示请求成功
suffix = url.split('.')[-1]
try:
with open(images + '/' + name + '.' + suffix,mode='wb') as file:
#wb: write binary 以二进制写入
file.write(response.content)
except:
#如果失败了,输出“保存失败”字段
print('保存失败:',name + '.' + suffix)怎么找到我需要的图片并下载呢?
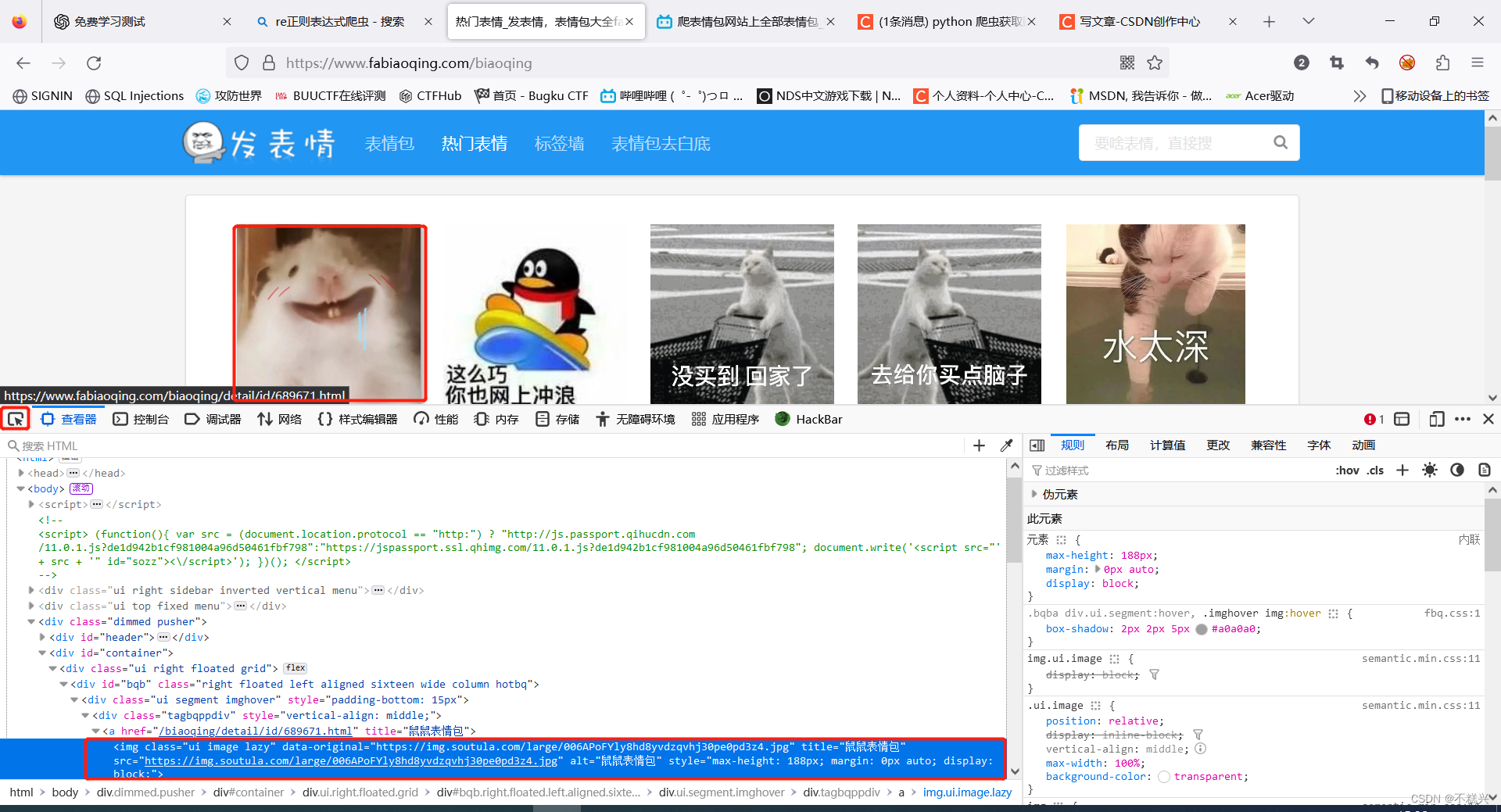
F12使用查看器,选中图片,自动跳转到图片对应的标签 ,如图所示,把关键字复制下来,打开网站源码搜索:
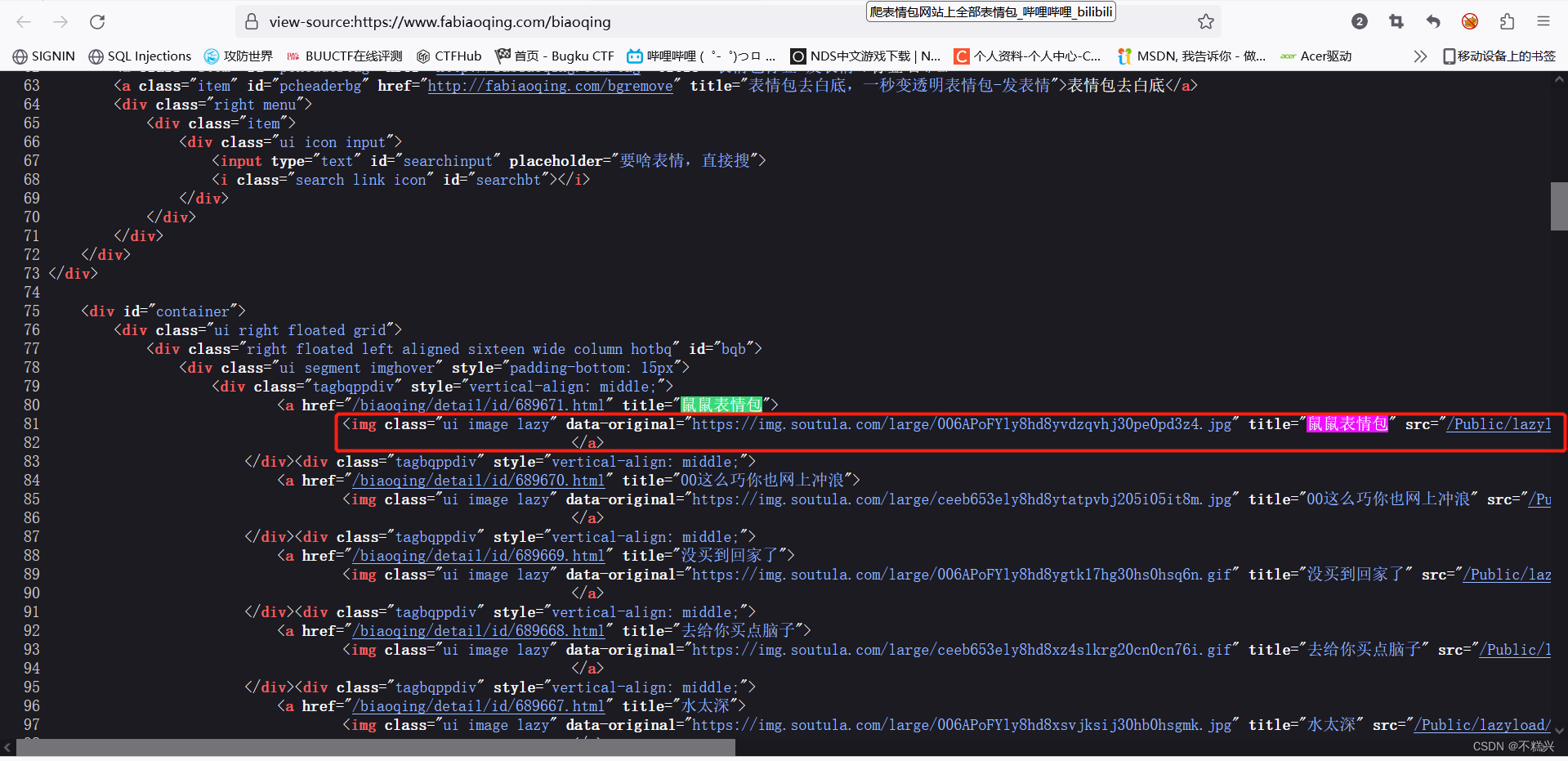
将<img>标签复制下来,如下:
<img class="ui image lazy" data-original="https://img.soutula.com/large/006APoFYly8hd8yvdzqvhj30pe0pd3z4.jpg" title="鼠鼠表情包" src="/Public/lazyload/img/transparent.gif" alt="鼠鼠表情包" style="max-height:188;margin: 0 auto"/>
再取一个来比较:
<img class="ui image lazy" data-original="https://img.soutula.com/large/ceeb653ely8hd8ytatpvbj205i05it8m.jpg" title="00这么巧你也网上冲浪" src="/Public/lazyload/img/transparent.gif" alt="00这么巧你也网上冲浪" style="max-height:188;margin: 0 auto"/>
对比来看,发现仅有 data-original= 、 alt= 和 title= 的内容是不同的,下面用到re.findall中正则表达式(.*?):
re_temp = '<img class="ui image lazy" data-original="(.*?)" title="(.*?)" src="/Public/lazyload/img/transparent.gif" alt=".*" style="max-height:188;margin: 0 auto"/>'完整代码如下:
import requests
import re
import os
import time
headers = {
'Cookie': 'PHPSESSID=95p4nees9qkma59qj7dfsee6aa',
#有时候我们对一张页面进行请求的时候,如果请求的过程中不携带cookie的话,那么我们是无法请求到正确的页面数据,
#这是一种非常常见的反爬机制,因此遇到这种情况我们必须,所有的请求必须携带cookie
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'Referer': 'https://www.fabiaoqing.com/' #Referer里记录的是请求的来路,所以通过设置Referer黑白名单,可以控制哪个页面或者域名过来的请求是可以访问的。
}
images = 'images'
if not os.path.exists(images): #如果不存在就创建images目录
os.mkdir('images') #使用os模块创建一个目录
def download(name,url):
#定义、封装代码块,传入name url,下载图片
response = requests.get(url,headers=headers)
print(response.status_code)#200表示请求成功
suffix = url.split('.')[-1]
try:
with open(images + '/' + name + '.' + suffix,mode='wb') as file:#wb:write binary以二进制写入
file.write(response.content)
except:#如果失败了
print('保存失败:',name + '.' + suffix)
response = requests.get('https://www.fabiaoqing.com/biaoqing/lists/page/1.html',headers=headers)
re_temp = '<img class="ui image lazy" data-original="(.*?)" title="(.*?)" src="/Public/lazyload/img/transparent.gif" alt=".*" style="max-height:188;margin: 0 auto"/>'
#re正则表达式(.*?)
result = re.findall(re_temp,response.text)
for img in result:
time.sleep(2) #延时访问,避免访问过快而被封ip,避免影响服务器正常访问
print(img)
download(img[1],img[0]) 













 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









