






今天逛壁纸网站,看见一张好看的小姐姐壁纸,准备保存下来,好家伙竟然要钱,既然这样那就不好意思啦,我已经不满足一张了,全部都是我的。

既然如此,我们就来利用爬虫把图片批量下载下来。
第一步:分析数据来源
网站链接:https://www.tooopen.com/img/88_879_1_1.aspx
进入首页点开开发者工具(f12)
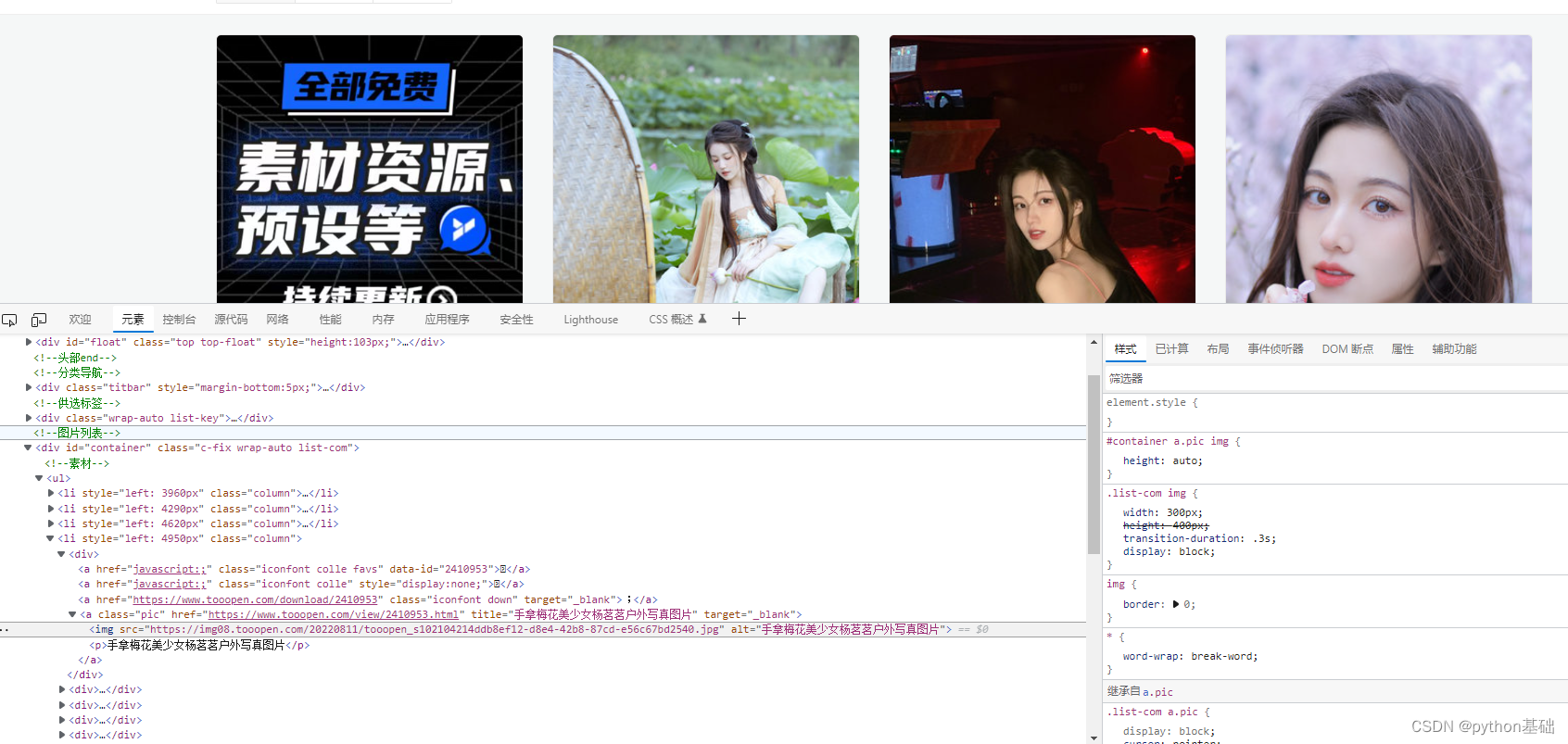
数据找到后,我们开始写代码。
第二步:获取数据
1.导入requests模块和数据解析模块:
import requests
import parsel
2.获取数据并解析数据
url = f"https://www.tooopen.com/img/88_879_1_1.aspx"
response = requests.get(url=url)
selector = parsel.Selector(response.text)
3.通过css选择器定位数据
首先在开发者工具中定位图片数据和标题,在a标签下的href和title属性里面,得到各个壁纸链接
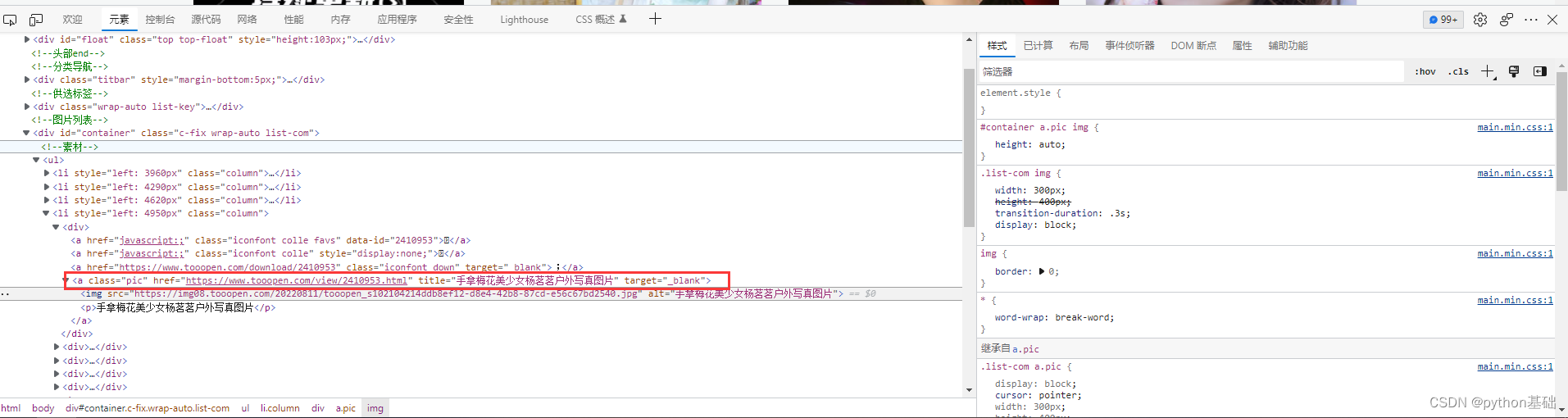
img_url = selector.css('a.pic::attr(href)').getall()
title = selector.css('a.pic::attr(title)').getall()得到壁纸链接组成的列表后遍历列表,再进行解析,得到每张图片的链接
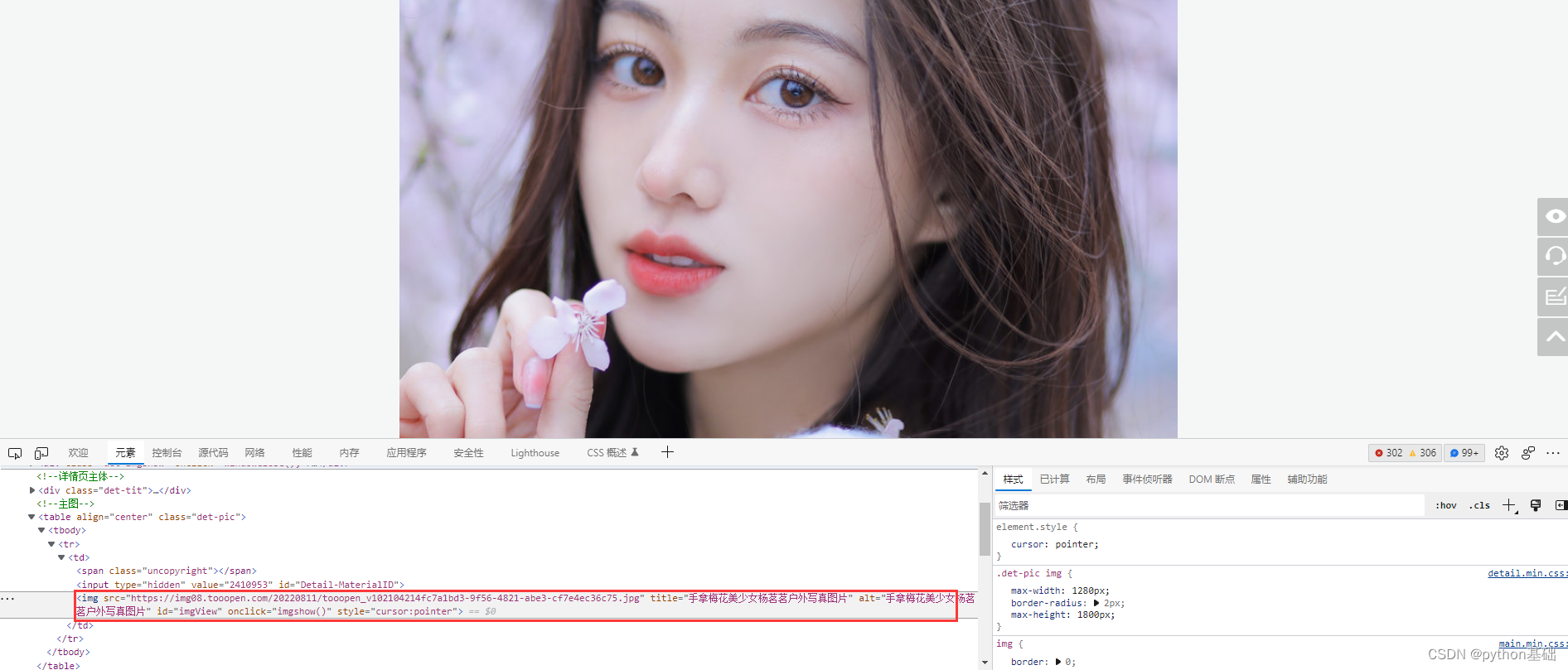
for link, title in zip(img_url, title):
# print(link, title)
image = requests.get(url=link).text
selector = parsel.Selector(image)
url = selector.css('.det-pic img::attr(src)').getall()遍历每张图片链接,进行数据解析,并转换成二进制数据进行保存
url = requests.get(url=img, headers=headers).content
# print(url)
with open(f'img1/{title}.jpg', mode='ab') as f:
f.write(url)然后来看效果:

第一页的数据就爬下来了,然后爬取多页面数据,对每页链接进行分析
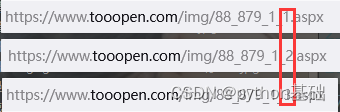
每页数据都是通过后面数字进行跳转,然后在代码前面加上for循环,对url进行修改
url = f"https://www.tooopen.com/img/88_879_1_{page}.aspx"
完整代码如下:
import requests
import parsel
for page in range(1, 3):
url = f"https://www.tooopen.com/img/88_879_1_{page}.aspx"
response = requests.get(url=url)
# print(response.text)
想需要更多有趣的python代码请V:oudashuai1
selector = parsel.Selector(response.text)
img_url = selector.css('a.pic::attr(href)').getall()
# print(img_url)
title = selector.css('a.pic::attr(title)').getall()
# print(title)
for link, title in zip(img_url, title):
# print(link, title)
image = requests.get(url=link).text
selector = parsel.Selector(image)
url = selector.css('.det-pic img::attr(src)').getall()
# print(url)
for img in url:
想需要更多有趣的python代码请V:oudashuai1
# print(img)
headers = {
'referer': f'https://www.tooopen.com/img/88_879_1_{page}.aspx',
'cookie': 'ASP.NET_SessionId=a5d09d0c-58a4-4642-a120-734ca473c542; Hm_lvt_d3ac2f8840ead98242d6205eeff29cb4=1658921995; history=2403843,2406976,2407361,2407473; RefreshFilter=http://www.tooopen.com/ajax/gethistory?callback=jQuery18305605885723622803_1658930997557&_=1658930997665; Hm_lpvt_d3ac2f8840ead98242d6205eeff29cb4=1658930998',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'
}
url = requests.get(url=img, headers=headers).content
# print(url)
with open(f'img1/{title}.jpg', mode='ab') as f:
f.write(url)欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【关注】行不行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









