






一、loss
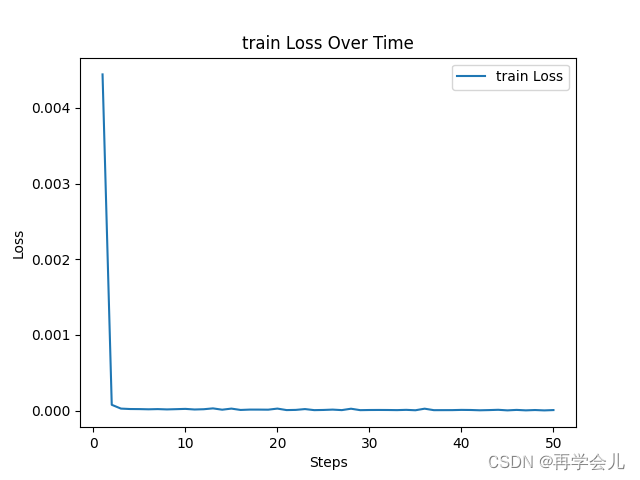
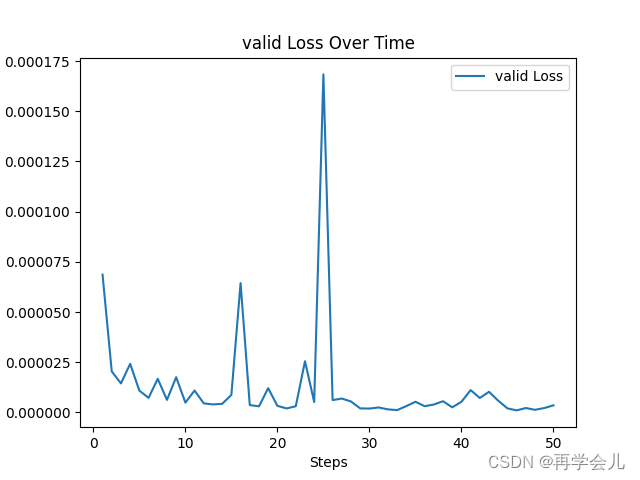
二、数据集
将自己的数据集转化成了类似与Moving-mnist结构,参考的是这篇文章:【时空序列预测实战】基于Moving-mnist结构制作自己的时空序列数据集——时空序列预测任务-前期数据集准备_movingmnist-CSDN博客
三、代码
分为了四个部分
dataset.py
仅使用了.npz文件
批处理大小设置为8
# dataset.py
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class NPZDataset(Dataset):
def __init__(self, npz_file):
data = np.load(npz_file)
self.inputs = data['input_raw_data']
self.targets = data['input_raw_data'] # 假设是自编码任务,将输入作为目标
def __len__(self):
return len(self.inputs)
def __getitem__(self, idx):
x = torch.tensor(self.inputs[idx], dtype=torch.float32)
y = torch.tensor(self.targets[idx], dtype=torch.float32)
return x, y
# 加载数据集
train_dataset = NPZDataset('autodl-tmp/mydata_train.npz')
valid_dataset = NPZDataset('autodl-tmp/mydata_valid.npz')
# 定义数据加载器
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=8, shuffle=False)
model.py
具体的unet结构和上一篇一样,没有修改,只是最基础的unet
# model.py
import torch
import torch.nn as nn
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class UNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(UNet, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.encoder = nn.ModuleList([
DoubleConv(in_channels, 64),
DoubleConv(64, 128),
DoubleConv(128, 256),
DoubleConv(256, 512)
])
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.decoder = nn.ModuleList([
nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2),
DoubleConv(512, 256), # Concatenated with skip connection (256 + 256)
nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2),
DoubleConv(256, 128), # Concatenated with skip connection (128 + 128)
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2),
DoubleConv(128, 64), # Concatenated with skip connection (64 + 64)
])
self.final_conv = nn.Conv2d(64, out_channels, kernel_size=1)
def forward(self, x):
skips = []
for encoder in self.encoder:
x = encoder(x)
skips.append(x)
x = self.pool(x)
x = skips.pop()
for i in range(0, len(self.decoder), 2):
x = self.decoder[i](x)
skip = skips.pop()
x = torch.cat([x, skip], dim=1)
x = self.decoder[i + 1](x)
x = self.final_conv(x)
return x
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
import shutil
from dataset import train_loader, valid_loader # 从dataset.py中导入
from model import UNet # 从model.py中导入
# 初始化模型
model = UNet(in_channels=3, out_channels=3).cuda() # 将模型移动到GPU
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 设置TensorBoard
# shutil.rmtree('/root/tf-logs')
writer = SummaryWriter(log_dir='tf-logs') # 可以根据需要修改log_dir路径
# 训练循环
num_epochs = 50
for epoch in range(num_epochs):
print(f"Starting Epoch {epoch+1}/{num_epochs}")
model.train()
running_loss = 0.0
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.cuda(), targets.cuda() # 将数据移动到GPU
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {train_loss}")
# 将训练损失写入TensorBoard
writer.add_scalar('Loss/train', train_loss, epoch+1)
# 验证
model.eval()
val_loss = 0.0
with torch.no_grad():
for inputs, targets in valid_loader:
inputs, targets = inputs.cuda(), targets.cuda() # 将验证数据移动到GPU
outputs = model(inputs)
loss = criterion(outputs, targets)
val_loss += loss.item()
val_loss = val_loss / len(valid_loader)
print(f"Validation Loss: {val_loss}")
# 将验证损失写入TensorBoard
writer.add_scalar('Loss/valid', val_loss, epoch+1)
# 关闭TensorBoard写入器
writer.close()
读取tensorboard日志的draw.py
import matplotlib.pyplot as plt
from tensorboard.backend.event_processing import event_accumulator
# 加载日志数据
logdir = 'tf-logs/events.out.tfevents.1717555663.autodl-container-470e41955c-e3876269.852.0' # 替换为你的日志目录
ea = event_accumulator.EventAccumulator(logdir)
ea.Reload()
# 获取标量数据
scalar_data = ea.Scalars('Loss/train')
# 提取步骤和对应的值
steps = [x.step for x in scalar_data]
values = [x.value for x in scalar_data]
# 使用Matplotlib绘制图像
plt.figure()
plt.plot(steps, values, label='train Loss')
plt.title('train Loss Over Time')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.legend()
plt.savefig('train_loss.png')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









