










😊😊 😊😊
不求点赞,只求耐心看完,指出您的疑惑和写的不好的地方,谢谢您。本人会及时更正感谢。希望看完后能帮助您理解算法的本质
😊😊 😊😊
题目描述:
小白到进阶各种解法:
一、暴搜:😊

思路:
首先想一下目标答案的所有子集,因为每次只能合并相邻两堆,那么目标区间
[
i
,
j
]
[i, j]
[i,j]必然是由相邻的两堆合并得来的,即存在一个分割点,将整体划分成两堆:

如图所示的两堆,那么由于中间的
k
k
k,在区间 [1,n]上有 n-1种取值,而不能取到n种,是因为缺少的那一种就是 n,若 k == n,请问你的区间还能分成相邻两段吗?显然不能。可知合并 [1,n]的区间的子集有:{[1,2], [3,n]}, {[1, 3], [4,n]}…多种。所以我们可以采用暴搜的方式去枚举每种划分方式带来的最小代价。
补充这里的划分方式:其实就是分割点的取值,落在不同的地方,即不同的,就会诞生两个不同的相邻的区间。依次递推下去。因为只有叶子区间才有答案,所以递归到叶子后才开始回溯答案,往上更新!
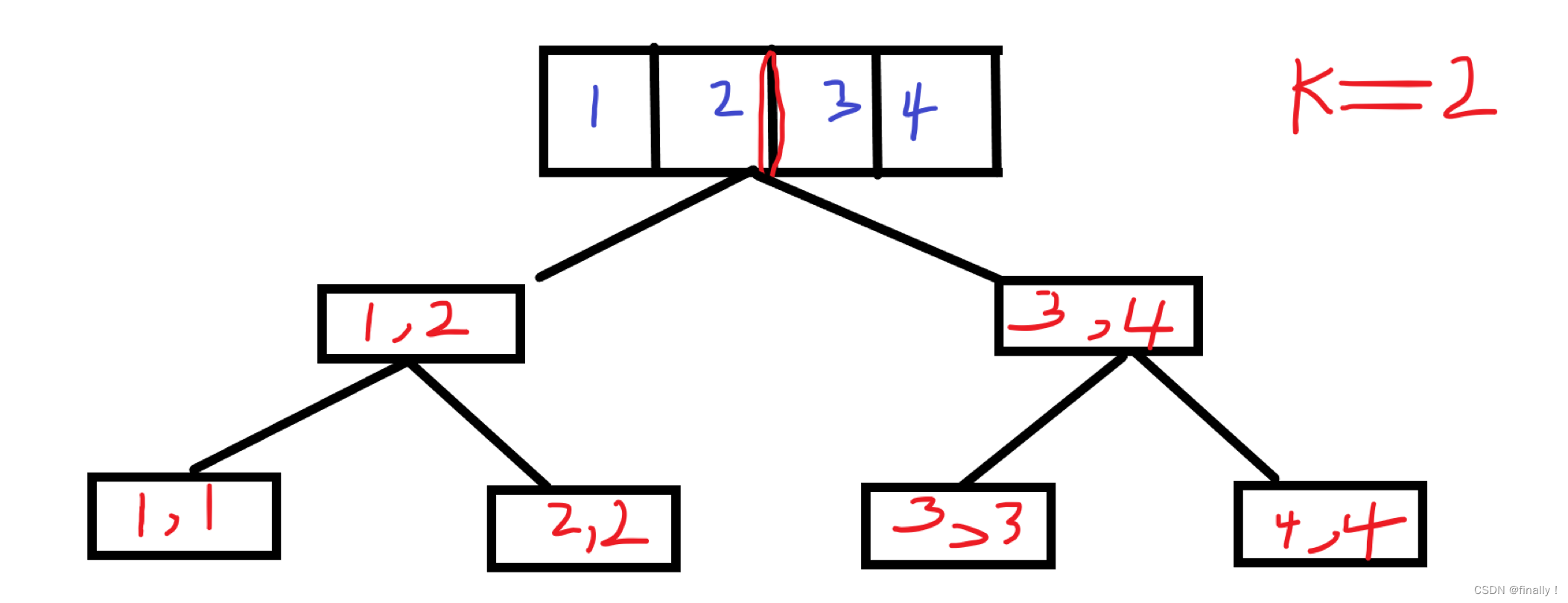
- 递归的出口:
合并两堆石子才需要付出代价,所以当递归到只有一堆石子的时候,说明只有自己一堆。合并无需代价:
if (i==j) return 0;
- 递归的参数:
由递归的出口可以知道,这里应该是区间的左右端点,当左端点 == 右端点的时候,说明区间里只有一堆石子。
dfs(int i, int j)
- 递归的计算:想想怎么计算哦?
对于一个大的区间来说,划分为两个子区间后,应该想想子区间怎么计算?由递归的出口可以知道,叶子区间才有答案,所以还要继续划分下去。接下来就是划分的方式枚举了,因为有多种划分方式,所以说,我们需要逐一去枚举所有的划分方式,而划分方式就 k k k 的落脚点,所以说,只需要让 循环 k k k 从 l − ( r − 1 ) l-(r-1) l−(r−1) 即可!
res记录的是合并当前的区间所需要的最小代价!即当前状态到目标状态的答案!
nt res=1e8;
for (int k=l; k < r; k ++) //枚举所有的划分方式!
{
res = min(res, dfs(l, k) + dfs(k+1, r) + s[r] - s[l-1]);
}
return res;
代码:
#include<iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 3e2 + 10;
int s[N];
int f[N][N];
int dfs(int l, int r)
{
if (l == r) return 0;
int res=1e8;
for (int k=l; k < r; k ++) //枚举所有的划分方式!
{
res = min(res, dfs(l, k) + dfs(k+1, r) + s[r] - s[l-1]);
}
return res;
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i ++) {
cin >> s[i];
s[i] += s[i - 1];
}
cout << dfs(1, n) << endl;
return 0;
}

二、记忆化搜索:先看 [法三、区间DP] 后看它!😊
思路:回溯性记忆化搜索。
是从目标区间出发,递归到叶子区间后,回溯记录答案,更新区间。因为只有叶子区间才有答案!
目标区间递归搜索到叶子区间。从而通过递归进行区间的划分!
代码:
#include<iostream>
using namespace std;
const int N = 3e2 + 10;
int s[N];
int f[N][N];
int dfs(int l, int r)
{
if (l == r) //此时已经递归到叶子区间,那么直接返回当前值即可!
return 0;
if (f[l][r] != -1) //表示该区间的最小花费已经计算过了,无需重复,直接返回答案。
return f[l][r];
//否则的话就是没有计算 [l, r]区间的最小花费,因为有多种划分方式,每种划分方式
//都是一个分支,所以递归枚举每个分支!
//并且
f[l][r] = 1e8;
for (int k=l; k < r; k ++)
f[l][r] = min(f[l][r], dfs(l,k)+dfs(k+1,r)+s[r]-s[l-1]);枚举所有的划分方式,选取代价最小的那种。
return f[l][r];
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i ++) {
cin >> s[i];
s[i] += s[i - 1];
}
memset (f, -1, sizeof(f));
cout << dfs(1, n) << endl;
return 0;
}
三、本题考察算法:区间DP😊
思路:
区间DP的模板:
区间长度,区间起点,区间终点,长度为1的区间的初始化。枚举分割点,构造状态转移方程!
for (int len=1; len <= n; len ++)
{
for (int i=1; i + len - 1 <= n; i ++)
{
int j = i + len - 1;
if (len == 1)
{
dp[i][j] = 初始化值;
continue;
}
//枚举区间长度为len的情况下,分割点在哪里比较好!
for (int k=i; k < j; k ++)
dp[i][j] = max(dp[i][j], dp[i][k] + dp[k+1][j]);
}
}
根据模板代码来解释本题的思路:
-
枚举区间的长度,从子问题推导原问题,原问题的区间长度是 n n n,而子问题的区间长度为 1 , 2 , 3... n − 1 ) 1,2,3...n-1) 1,2,3...n−1),为什么这样一定会推导到答案了?
因为长度为 n n n 的区间也必然是由相邻两堆合并来的,那么这两堆的区间长度必然是小于等于 n n n 的:

如上图所示,在合并成区间长度为 n n n 之前,有那么多种子集去合并成长度为 n n n 的区间,但是我们并不知道合并的两个子区间的最小代价,所以说我们要从子问题 ⇒ 原问题!比如子区间 [1, 2],你知道合并这两堆的代价是多少吗?[3,4], [5, 6] 呢?都不知道,所以说只有从区间长度为2的开始去递推,逐步扩大区间的长度! -
k的作用,同样借用上面的图。
假设此时区间长度为3,区间为:[1, 2, 3],目标是求出合并三堆石子的最小代价。你知道先合并哪两堆吗?不知道。你会怎么做?
第一步先划分为两堆:
[1,1] ,[2,3]。
[1,2],[3, 3]。
第二步再将两堆合并:
合并:[1,1] + [2,3] == [1,3];
合并:[1,2] + [3, 3] == [1,3];
那么k的作用也就显现出来:k是枚举分割点的,看分为两堆的话,应该由哪两堆合并而来!
合并从 i 到 j之间的石子
取max的原因是,f[i][j]存在多种合并方式,从所有合并方式中挑选代价最小的方式!d
f[i][j] = min(f[i][j], f[i][k] + f[k+1][j] + w[i][j]);
代码:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 3e2 + 10;
int s[N]; //前缀和数组:表示合并 i~j堆的代价!
int f[N][N]; //所有将第 i 堆石子到第j堆石子合并成一堆石子的合并方式!
int main()
{
int n;
cin >> n;
for (int i=1; i <= n; i ++)
{
cin >> s[i];
s[i] += s[i-1];
}
memset (f, 0x3f, sizeof (f));
for (int len = 1; len <= n; len ++)
{
for (int i=1; i + len - 1 <= n; i ++)
{
int j = i + len - 1;
if (len == 1){
f[i][j] = 0;
continue;
}
for (int k=i; k <= j; k ++) //实际上就是在枚举长度为len的区间的合并方式了!
{
f[i][j] = min(f[i][j], f[i][k] + f[k+1][j] + s[j] - s[i-1]);
}
}
}
cout << f[1][n];
return 0;
}















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









