







😊😊 😊😊
不求点赞,只求耐心看完,指出您的疑惑和写的不好的地方,谢谢您。本人会及时更正感谢。希望看完后能帮助您理解算法的本质
😊😊 😊😊
单词方阵
题目描述
给一
n
×
n
n \times n
n×n 的字母方阵,内可能蕴含多个 yizhong 单词。单词在方阵中是沿着同一方向连续摆放的。摆放可沿着
8
8
8 个方向的任一方向,同一单词摆放时不再改变方向,单词与单词之间可以交叉,因此有可能共用字母。输出时,将不是单词的字母用 * 代替,以突出显示单词。例如:
输入:
8 输出:
qyizhong *yizhong
gydthkjy gy******
nwidghji n*i*****
orbzsfgz o**z****
hhgrhwth h***h***
zzzzzozo z****o**
iwdfrgng i*****n*
yyyygggg y******g
输入格式
第一行输入一个数 n n n。( 7 ≤ n ≤ 100 7 \le n \le 100 7≤n≤100)。
第二行开始输入 n × n n \times n n×n 的字母矩阵。
输出格式
突出显示单词的 n × n n \times n n×n 矩阵。
样例 #1
样例输入 #1
7
aaaaaaa
aaaaaaa
aaaaaaa
aaaaaaa
aaaaaaa
aaaaaaa
aaaaaaa
样例输出 #1
*******
*******
*******
*******
*******
*******
*******
样例 #2
样例输入 #2
8
qyizhong
gydthkjy
nwidghji
orbzsfgz
hhgrhwth
zzzzzozo
iwdfrgng
yyyygggg
样例输出 #2
*yizhong
gy******
n*i*****
o**z****
h***h***
z****o**
i*****n*
y******g
一、暴搜:😊

思路:
- 明确目标是所有的
yizhong,以字母: y y y 开头。启发我们以字符 y y y为突破口。 - 若以 y y y 为入口,则应该检测其某个方向上往后的8个字符是否符合目标字符。
- 题目要求把非目标字符串改成 “ ∗ ” “*” “∗”,目标字符串保持不变。那么我们不仅要搜出目标字符串,还得进行标记,在最后输出的时候,利用标记进行特判!
- 那么为了检测到所有的字符 y y y,我们应该预处理出来 y y y的坐标。然后每个 y y y 都要依次搜索它的八个方向,且每个方向搜完后,回溯到起点 y y y 后才往下一个方向搜,回溯的时候也不能变换分支。否则会保留非目标字符串里的部分字符。
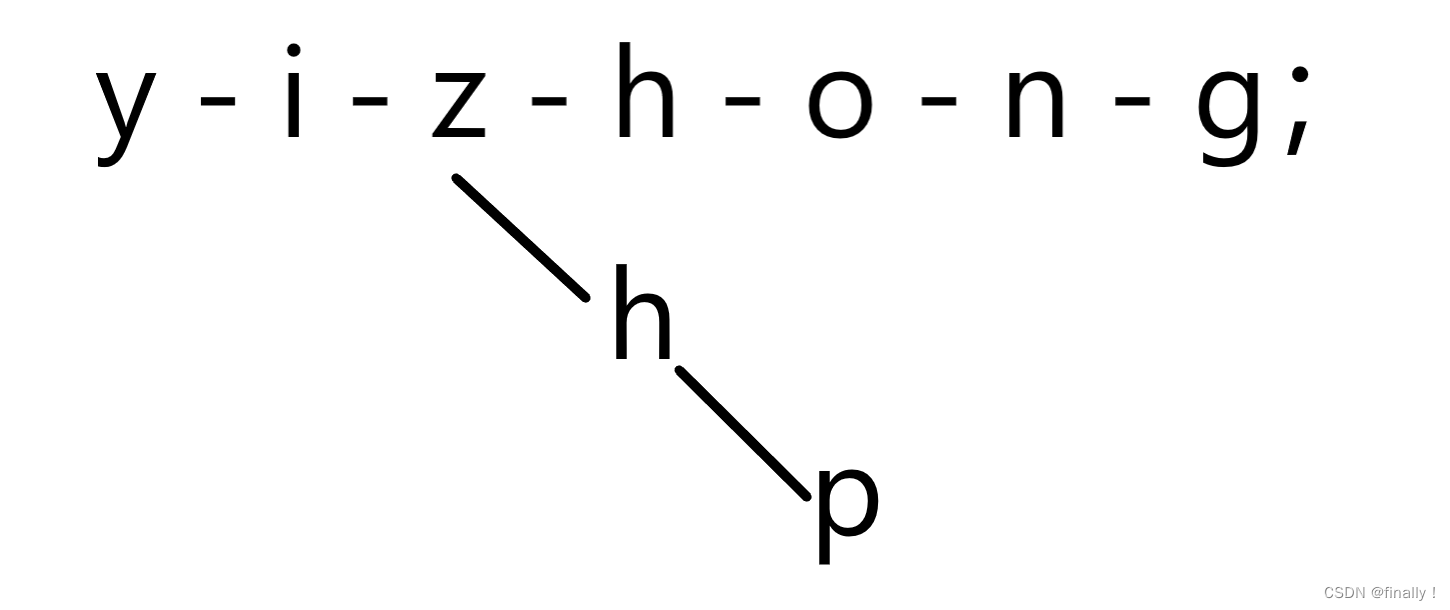
- 本题关键就在于:一次搜索,只能搜索一个方向,其每个方向上不能有分支,一旦出现分支,会导致信息错误!如下所示,若中途走向其他分支,则会错误地保留多的
h
h
h;
代码:
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 110;
int st[N][N]; //进行标记目标字符串上的每个字符为1,其余的没有标记的为0,即输出为 *;
char str[N][N];
int n;
string target = "yizhong";
//depth:深度,用于表示当前应该是目标字符串的第几个字符了 也是递归的出口.
int dfs (int x, int y, int t1, int t2, int depth)
{
if (depth == 6 && str[x][y] == target[depth]) //此时是递归的出口,说明在该方向上
{
st[x][y] = 1; //标记为1!
return 1;
}
//没有越界就去搜!
if (str[x][y] == target[depth])
{
if (x+t1>=1 && x+t1<=n && y+t2>=1 && y+t2<=n)
{
if (dfs (x+t1, y+t2, t1, t2, depth+1))
{
st[x][y] = 1;
return 1;
}
}
}
return 0; //表示中断了没有搜到!
}
int main()
{
cin >> n;
for (int i=1; i <= n; i ++)
for (int j=1; j <= n; j ++)
cin >> str[i][j];
for (int i=1; i <= n; i ++)
{
for (int j=1; j <= n; j ++)
{
if (str[i][j] == 'y') //入口 ==> 搜索!
{
for (int t1=-1; t1 <= 1; t1 ++)
{
for (int t2=-1; t2 <= 1; t2 ++)
{
if (t1 == 0 && t2 == 0) continue;
if (dfs (i+t1, j+t2, t1, t2, 1))
st[i][j] = 1;
}
}
}
}
}
//打印方案:
for (int i=1; i <= n; i ++)
{
for (int j=1; j <= n; j ++)
{
if (st[i][j]) cout << str[i][j];
else cout << "*";
}
puts("");
}
return 0;
}
总结:初次总结,日后会逐步取其精华!
- 本题为在二维平面上搜索某个字符串,相比于之前的在二维平面上搜索时某个目标答案,通常是搜索出一套完整的方案后,再让你在终点判断该状态是否合法。
- 而本题在于一边搜索一边匹配答案是否合法。当然每个字符都有8个方向,若每个字符的8个方向都要去搜的话,则时间复杂度高,存在许多无效的搜索,不如固定起点,固定一个方向,每次只枚举起点的8个方向即可了!时间复杂度得到优化。
- 总结下本题的递归方式:
(1)、递归的出口:分情况讨论,第一种情况:即当搜到目标字符串的最后一个字符时,即可进行答案的处理判断。第二种情况:即为不合法的情况下,则直接退出返回。
(2)、递归的参数:(x,y)为当前位置的坐标。可以用来判断是否越界,(其实本题不用判断越界的,因为越界意味着并没有搜索到目标字符串,则等同处理)。(t1,t2)固定搜索方向用的。depth:递归的出口和判断当前搜索到的字符是否和目标字符的第 d e p t h depth depth 位相等!
(3)、递归的计算:只要合法就往固定方向前进呗!
















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









