







文章目录
机器学习常见名词含义:
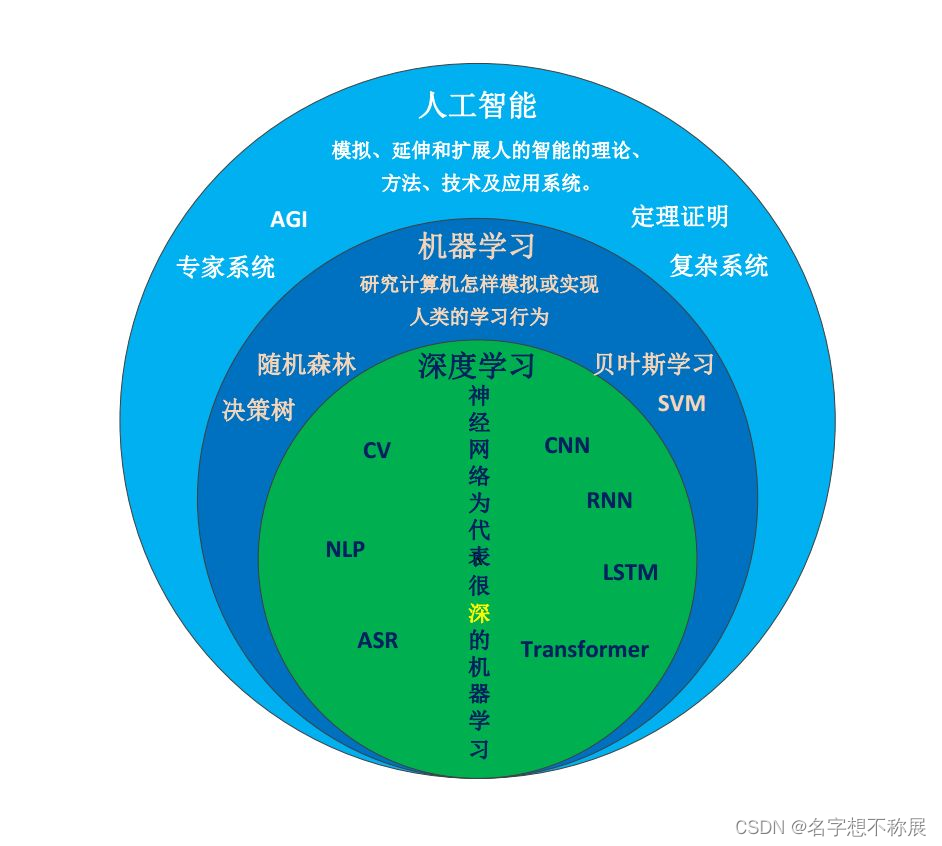
人工智能、机器学习、深度学习的关系
人工智能> 机器学习> 深度学习
监督学习(Supervised Learning)
监督学习是一种机器学习范式,其中模型在训练过程中利用带有标签的数据进行学习。也就是说,训练数据集包含输入数据(特征)和对应的输出标签(目标值)。模型通过学习这些数据之间的映射关系,以便在遇到新的未见数据时能够预测其标签。
无监督学习(Unsupervised Learning)
无监督学习是一种机器学习范式,其中模型在训练过程中使用未标记的数据进行学习。也就是说,训练数据集只有输入数据,没有对应的输出标签。模型的目标是发现数据中的模式、结构或分布。
主要特征:
- 输入输出配对:训练数据集中,每个输入样本都有一个对应的输出标签。
- 目标明确:模型的目标是找到一个映射函数,使得输入数据能够尽可能准确地映射到正确的输出标签。
主要特征:
- 无标签数据:训练数据集中只有输入数据,没有输出标签。
- 目标不明确:模型的目标是找到数据中的隐藏模式或结构。
监督学习和无监督学习的 比较:
| 特征 | 监督学习 | 无监督学习 |
|---|---|---|
| 数据集 | 有标签数据 | 无标签数据 |
| 目标 | 预测输出标签 | 发现数据模式 |
| 常见算法 | 线性回归、SVM、神经网络等 | 聚类、降维、关联规则等 |
| 应用 | 分类和回归问题 | 聚类、降维、关联规则学习 |
应用场景
监督学习
- 分类问题:如垃圾邮件检测(预测邮件是否为垃圾邮件)、图像分类(识别图像中的物体)。
- 回归问题:如房价预测(预测房子的价格)、股票价格预测。
无监督学习
- 聚类:如客户细分(根据客户行为进行市场细分)、图像分割(将图像划分为不同区域)。
- 降维:如数据可视化(将高维数据投影到低维空间)、特征提取(从高维数据中提取重要特征)。
- 关联规则学习:如购物篮分析(发现商品间的购买关联)、推荐系统(基于用户行为推荐商品)。
模型的评估指标有哪些
分类问题
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1分数(F1 Score)
- ROC曲线和AUC(Receiver Operating Characteristic and Area Under the Curve)
回归问题
- 均方误差(Mean Squared Error, MSE)
- 均方根误差(Root Mean Squared Error, RMSE)
- 平均绝对误差(Mean Absolute Error, MAE)
- 决定系数(R-squared, Coefficient of Determination)
超参数
batch_size
- 定义:batch_size 是指在每次训练迭代中,使用的训练样本的数量。
- 影响:
-
- 内存占用:较大的 batch_size 需要更多的内存来存储数据和梯度。
-
- 训练速度:较大的 batch_size 可以提高训练速度,因为并行计算效率更高。
-
- 梯度估计稳定性:较大的 batch_size 使梯度估计更加稳定,收敛性更好,但可能导致跳过局部最优解。
- 典型值:常见的 batch_size 值有32、64、128、256(2的多少次方)等。具体值需要根据硬件条件和数据集大小进行调整。
epochs
- 定义:epochs 是指完整遍历训练数据集的次数。
- 影响:
-
- 训练时间:较多的 epochs 会增加训练时间。
-
- 模型收敛:较多的 epochs 可以让模型更好地学习数据,但过多的 epochs 可能导致过拟合(模型在训练数据上表现很好,但在新数据上表现不佳)。
- 典型值:根据数据集大小和复杂度,一般在10到数百之间。通常在训练过程中使用验证集来监控模型性能,以确定最佳的 epochs 数量。
learning_rate
- 定义:learning_rate 是指每次更新模型参数时步长的大小。
- 影响:
-
- 收敛速度:较大的 learning_rate 可以加快收敛速度,但可能会跳过全局最优解,导致发散。
-
- 训练稳定性:较小的 learning_rate 会使训练更加稳定,但收敛速度较慢,可能陷入局部最优解。
- 调整方法:常见的调整方法包括学习率衰减(随着训练进行逐步减小学习率)和自适应学习率方法(如Adam、RMSprop)。
- 典型值:常见的 learning_rate 值在0.001到0.1之间。具体值需要通过实验调整。
总结
- batch_size:每次迭代中使用的训练样本数量。
- epochs:完整遍历训练数据集的次数。
- learning_rate:每次参数更新的步长大小。
过拟合
过拟合和欠拟合是机器学习中模型性能评估的重要概念,反映了模型在训练数据集和测试数据集上的表现情况。
过拟合:过拟合指的是模型在训练数据上表现得很好,但在新数据(测试数据)上表现不佳的现象。
直观解释:好比一位学生只记住了练习题的答案,但不能解决新题目。虽然在练习题上得分很高,但在考试中表现不佳。
这通常发生在模型过于复杂,能够很好地拟合训练数据中的噪声和细节,导致它不能很好地泛化到未见过的数据上。
解决方法
- 减少模型复杂度(例如,通过降维、减少特征数或简化模型结构)。
- 使用正则化技术(如L1或L2正则化)。
- 增加训练数据。
- 使用交叉验证来选择模型。
欠拟合
欠拟合:欠拟合指的是模型在训练数据和新数据上都表现不佳的现象。
直观解释:好比一位学生没有充分学习,只掌握了基础知识,既不能很好地解决练习题,也不能解决考试题目。
这通常发生在模型过于简单,无法捕捉数据中的复杂结构和模式。
解决方法
- 增加模型复杂度 (通过添加更多的特征、使用更复杂的模型如神经网络或决策树等)
- 减少特征选择中的约束条件。
- 增加训练时间或迭代次数。
- 使用更多的特征工程。
交叉验证
一种评估机器学习模型性能的技术,主要用于避免模型的过拟合和欠拟合问题。它通过将数据集分成多个子集,多次训练和验证模型,来评估模型在未见过的数据上的表现。
交叉验证的基本概念
- 数据集分割:将可用的数据集分成多个子集,通常称为折(folds)。最常见的是将数据集分成k个等大的子集,这种方法称为k折交叉验证(k-Fold Cross-Validation)。
- 多次训练和验证:在每次迭代中,使用k-1个子集训练模型,剩下的1个子集用于验证模型。这个过程会重复k次,每次选择不同的子集作为验证集,其余作为训练集。
- 性能评估:通过k次验证的结果,计算模型性能的平均值和方差,以此来评估模型的稳定性和泛化能力。
交叉验证的优点
- 减少过拟合风险:通过多次训练和验证,交叉验证可以更好地估计模型的泛化能力。
- 充分利用数据:特别适用于数据量较小的情况,交叉验证能更有效地利用数据。
- 模型选择和调优:有助于选择最佳的模型参数和算法,提升模型性能。
交叉验证的缺点
- 计算成本高:特别是对于大数据集或复杂模型,k次训练和验证的计算成本较高。
- 不适用于时间序列数据:由于时间序列数据有顺序性,交叉验证的随机分割会破坏这种顺序,需要使用其他方法如滚动预测(rolling forecast)进行验证。
K折交叉验证
步骤:
- 将数据集随机分成k个等大小的子集。
- 进行k次迭代:
- 每次迭代中,选择一个不同的子集作为验证集,其余k-1个子集作为训练集。
- 在训练集上训练模型。
- 在验证集上评估模型性能(例如,计算准确率、误差等)。
- 计算k次验证的平均性能指标,例如平均准确率或平均误差。
示例:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
# 加载示例数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建模型
model = LogisticRegression(max_iter=200)
# 执行k折交叉验证
scores = cross_val_score(model, X, y, cv=5) # 5折交叉验证
# 输出每次验证的得分和平均得分
print("Cross-Validation Scores:", scores)
print("Mean Score:", scores.mean())
交叉验证的目的
-
评估模型的泛化能力:
交叉验证通过多次将数据集分为训练集和验证集,可以更准确地评估模型在未见数据上的性能。相比单一的训练/测试分割,交叉验证提供了对模型泛化能力的更全面的评价。 -
防止过拟合和欠拟合:
通过使用多个训练/验证分割,交叉验证可以帮助识别模型是否过拟合或欠拟合。过拟合的模型在训练数据上表现良好但在验证数据上表现不佳,而欠拟合的模型在训练和验证数据上都表现不佳。 -
模型选择和参数调优:
交叉验证常用于选择最佳的模型参数和算法。通过比较不同参数设置或不同模型在交叉验证中的表现,可以选择出最优的参数或模型配置。 -
利用数据:
在数据量有限的情况下,交叉验证通过多次分割和训练,可以更有效地利用数据集的每一部分,确保所有数据都用于训练和验证。 -
减少评估结果的偏差:
单次的训练/测试分割可能由于随机性导致评估结果存在偏差。交叉验证通过多次分割和重复评估,能够减少这种偏差,提高评估结果的可靠性。
正则化
定义
是机器学习中一种防止模型过拟合的方法。过拟合是指模型在训练数据上表现得很好,但在测试数据上表现不佳的现象。其核心思想是在模型的损失函数中加入一个惩罚项,以限制模型参数的复杂度,从而提高模型在未见数据上的泛化能力。
正则化的主要方法
- L1正则化(Lasso回归)
- L2正则化(Ridge回归)
- Elastic Net正则化
线性支持向量机
线性支持向量机的分类模型
待更新
线性支持向量机生成的模型正如同一块平板,把原本无法用线性模型进行分类的数据成功地分隔了。
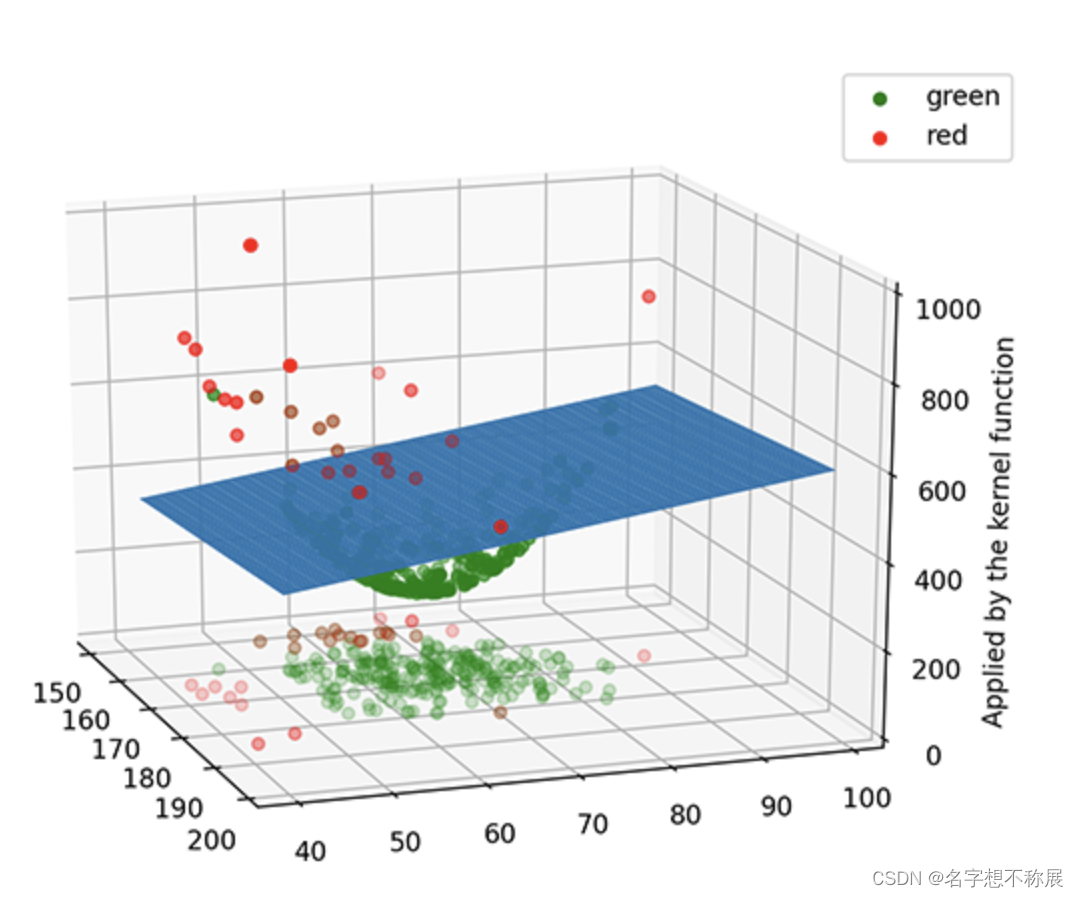
线性支持向量机的主要目的是:找到一个平面,将不同类别的数据点完全分隔。
决策树算法
待更新
泛化能力
模型在训练集和测试集以及新的数据集上,表现都很好。
特征工程
特征工程(Feature Engineering)是机器学习中的一个关键步骤,指的是从原始数据中提取、有意义的特征以提升模型性能的过程。特征工程的质量直接影响模型的表现,因此它是机器学习工作流程中至关重要的一部分。
特征工程的主要步骤和方法
- 特征提取(Feature Extraction):
- 从原始数据中提取特征,这是特征工程的核心。可以从数值型数据、分类数据、文本数据、图像数据等不同类型的数据中提取特征。
- 特征选择(Feature Selection):
- 从提取的特征集中选择对模型有用的特征,以减少维度、降低模型复杂度、提高模型的泛化能力。常用的方法包括相关性分析、PCA、Lasso等。
- 特征转换(Feature Transformation):
- 对特征进行变换以更好地表示数据的结构和分布。常见的方法包括标准化、归一化、对数变换、平方根变换等。
- 特征编码(Feature Encoding):
- 对分类特征进行编码,使其可以被机器学习算法使用。常见的方法包括独热编码(One-Hot Encoding)、标签编码(Label Encoding)、目标编码(Target Encoding)等。
- 特征组合(Feature Combination):
- 将现有的特征组合生成新的特征,以提高模型的表达能力。例如,可以通过特征之间的加减乘除生成新的特征。
- 处理缺失值(Handling Missing Values):
- 对数据中的缺失值进行处理,常见的方法包括填补缺失值(如均值填补、中位数填补、使用模型预测填补)、删除含缺失值的样本或特征。
常见的特征工程技术
- 归一化和标准化:
- 归一化(Normalization):将特征值缩放到 [0, 1] 范围内。
- 标准化(Standardization):将特征值转换为均值为0,方差为1的分布。
- 类别特征编码:
- 独热编码(One-Hot Encoding):将分类变量转换为二进制向量。
- 标签编码(Label Encoding):将分类变量转换为整数标签。
- 数值特征离散化:
- 将连续数值特征转换为离散区间,以处理非线性关系或减少模型复杂度。
- 特征交互:
- 创建特征之间的交互项,以捕捉变量之间的相互作用。
- 时间特征提取:
- 从时间数据中提取特征,如年、月、日、小时、星期几、季度等。
处理不平衡的数据集
方法一:过采样
过采样是一种处理数据不平衡的方法,通过增加少数类样本的数量,使得少数类样本与多数类样本数量平衡。这可以通过复制现有的少数类样本或生成新的少数类样本来实现。
方法二:欠采样
欠采样是一种处理数据不平衡的方法,通过减少多数类样本的数量,使得多数类样本与少数类样本数量平衡。这可以通过随机删除多数类样本来实现。
搭建神经网络的步骤
一、拿数据
数据集有多种来源,比如:公开数据集、企业内部数据集、API接口提供的数据集等等。此时应该使用适当的工具和库(如Pandas、Numpy)导入对应的数据集
二、数据预处理(数据清洗)
- 处理缺失值:
- 对数据集中缺失的值,可以选择删除或特值填补。
- 数据标准化和归一化:
- 对数据进行标准化或归一化处理,以确保特征值在相同的尺度上。
- 编码分类变量:
- 使用独热编码
One-Hot将分类变量转换为数值形式
- 分割数据集:
- 将数据集分为训练集和测试集。
三、搭建神经网络
- 选择模型架构:选择适合任务的神经网络架构,如前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等。
- 定义模型:使用深度学习框架(如TensorFlow、Keras、PyTorch等)定义模型结构。
四、优化和训练
- 编译模型:选择损失函数、优化器和评价指标。
- 训练模型:使用训练数据集进行模型训练,通过多次迭代(epochs)来优化模型参数。
五、预测
- 模型评估:在测试集上评估模型性能,检查模型是否过拟合或欠拟合。
- 模型预测:使用训练好的模型进行预测。
六、部署
- 使用
Django或者Flask框架创建模型的API,并且在框架中的views.py编写相关的调用模型的逻辑代码即可 - 使用云服务(如AWS、GCP、Azure)进行部署.
-
- 将模型通过
Git推送到云服务平台
- 将模型通过
-
- 使用平台提供的服务创建和部署API。
- 通过云服务平台持续监控模型性能,并根据需要进行维护和更新。
随机森林中降低模型方差
- 增加树的数量(n_estimators):
增加随机森林中树的数量,可以通过多次独立的采样和训练,减少模型的方差。更多的树可以平均化误差,减少模型对单个训练样本的依赖。
- 减少每棵树的最大深度(max_depth):
限制每棵树的最大深度可以防止树过于复杂,从而减少过拟合。较浅的树可以降低方差,但要注意深度不能过浅,以避免欠拟合。
- 增加每个节点的最小样本数(min_samples_split):
增加叶节点的最小样本数可以防止叶节点包含过少的样本,从而减少方差。
- 增加叶节点的最小样本数(min_samples_leaf):
增加叶节点的最小样本数可以防止叶节点包含过少的样本,从而减少方差。
- 使用更多的特征进行分割(max_features):
在每次分裂时使用更多的特征可以降低方差,因为更多的特征可以提供更多的信息用于分裂节点。max_features 参数可以设置为较大的值。
- 集成方法
结合多种随机森林模型,使用不同的超参数配置或子样本进行训练,进一步降低模型方差。















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









