







 该博客介绍了一个利用Python库实现的视频字幕生成和演讲稿提取流程。首先,通过moviepy将视频转为音频,然后使用auditok进行音频切割。接着,借助PaddleSpeech的ASR模型将每段音频转换为文本。最后,将所有文本存入CSV文件。项目适用于本地运行,作者在AIStudio上遇到问题但未解决。
该博客介绍了一个利用Python库实现的视频字幕生成和演讲稿提取流程。首先,通过moviepy将视频转为音频,然后使用auditok进行音频切割。接着,借助PaddleSpeech的ASR模型将每段音频转换为文本。最后,将所有文本存入CSV文件。项目适用于本地运行,作者在AIStudio上遇到问题但未解决。
转自AI Studio,原文链接:[PaddleSpeech]助力视频字幕生成演讲稿提取 - 飞桨AI Studio
在导师的项目的启发下,想着做出来这个视频分割以及文本提取的案例
输入:
一个mp4或者MP4文件的视频
输出:
一个csv的对话文本
项目需要在本地跑,平台上不知为何会报错找不到zip
1 视频转音频
In [1]
!pip install moviepy
In [2]
import moviepy.editor as mp
# 采样率16k 保证和paddlespeech一致
def extract_audio(videos_file_path):
my_clip = mp.VideoFileClip(videos_file_path,audio_fps=16000)
if (videos_file_path.split(".")[-1] == 'MP4' or videos_file_path.split(".")[-1] == 'mp4'):
p = videos_file_path.split('.MP4')[0]
my_clip.audio.write_audiofile(p + '_video.wav')
new_path = p + '_video.wav'
return new_path
2 音频切割
In [4]
!pip install auditok<span style="color:rgba(0, 0, 0, 0.85)"><span style="background-color:#ffffff">Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting auditok
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/49/3a/8b5579063cfb7ae3e89d40d495f4eff6e9cdefa14096ec0654d6aac52617/auditok-0.2.0-py3-none-any.whl (1.5 MB)
<span style="color:#555555">━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span> <span style="color:#00bb00">1.5/1.5 MB</span> <span style="color:#bb0000">3.8 MB/s</span> eta <span style="color:#00bbbb">0:00:00</span>a <span style="color:#00bbbb">0:00:01</span>
Installing collected packages: auditok
Successfully installed auditok-0.2.0
</span></span>
In [5]
import auditok
import os
def qiefen(path, ty='video', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55):
file = path
audio_regions = auditok.split(
file,
min_dur=mmin_dur, # minimum duration of a valid audio event in seconds
max_dur=mmax_dur, # maximum duration of an event
# maximum duration of tolerated continuous silence within an event
max_silence=mmax_silence,
energy_threshold=menergy_threshold # threshold of detection
)
for i, r in enumerate(audio_regions):
# Regions returned by `split` have 'start' and 'end' metadata fields
print(
"Region {i}: {r.meta.start:.3f}s -- {r.meta.end:.3f}s".format(i=i, r=r))
epath = ''
file_pre = str(epath.join(file.split('.')[0].split('/')[-1]))
mk = '/change'
if (os.path.exists(mk) == False):
os.mkdir(mk)
if(os.path.exists(mk+'/'+ty) == False):
os.mkdir(mk+'/'+ty)
if(os.path.exists(mk+'/'+ty+'/'+file_pre) == False):
os.mkdir(mk+'/'+ty+'/'+file_pre)
num = i
# 为了取前三位数字排序
s = '000000'+str(num)
file_save = mk+'/'+ty+'/'+file_pre + '/' + \
s[-3:]+'-'+'{meta.start:.3f}-{meta.end:.3f}'+'.wav'
filename = r.save(file_save)
print("region saved as: {}".format(filename))
return mk+'/'+ty+'/'+file_pre
3 逐段音频转文本
In [6]
!pip install --upgrade pip && pip install paddlespeech==0.1.0
In [10]
import paddle
from paddlespeech.cli import ASRExecutor, TextExecutor
import warnings
warnings.filterwarnings('ignore')
asr_executor = ASRExecutor()
text_executor = TextExecutor()
def audio2txt(path):
# 返回path下所有文件构成的一个list列表
filelist = os.listdir(path)
# 保证读取按照文件的顺序
filelist.sort(key=lambda x: int(x[:3]))
# 遍历输出每一个文件的名字和类型
words = []
for file in filelist:
print(path+'/'+file)
text = asr_executor(
audio_file=path+'/'+file,
device=paddle.get_device())
if text:
result = text_executor(
text=text,
task='punc',
model='ernie_linear_p3_wudao',
device=paddle.get_device())
else:
result = text
words.append(result)
return words4 存入csv
In [11]
import csv
def txt2csv(txt):
with open(path+'.csv', 'w', encoding='utf-8') as f:
f_csv = csv.writer(f)
for row in txt_all:
f_csv.writerow([row])5 执行代码
In [ ]
# 拿到新生成的音频的路径
path = extract_audio('1.mp4')
# 划分音频
path = qiefen(path=path, ty='video',
mmin_dur=0.5, mmax_dur=100000, mmax_silence=0.5, menergy_threshold=55)
# 音频转文本 需要GPU
txt_all = audio2txt(path)
# 存入csv
txt2csv(txt_all)6 结果展示
在aistudio上跑不通,需要在本地跑
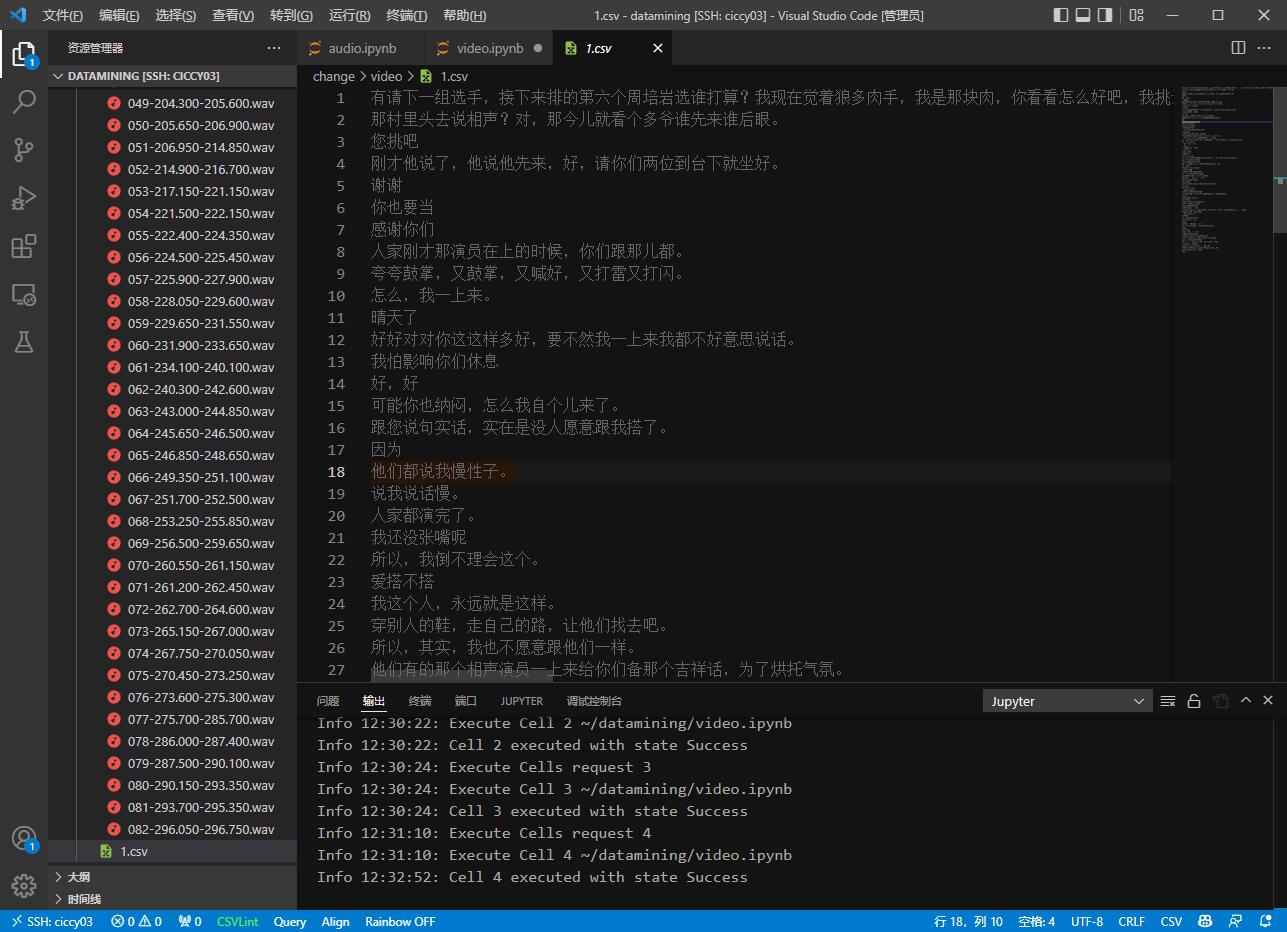
项目总结
思路是很简单的,主要是找这个存结果的函数找了好久,记录下来方便大家本地使用。
至于在aistudio上为什么跑不通,报错bindzip的问题,我也很迷茫,有大佬知道的话可以指点一下。
个人总结
全网同名:
iterhui
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









