









★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
真实场景篡改图像检测挑战赛
背景
目前各类社交平台中视频、图像、文本内容的截图内容恶意篡改的情况日益加剧,截屏图像的原始性和真实性面临严峻挑战。经过篡改合成的截屏图像内容通过通讯应用会被用于散播谣言、经济诈骗、编造虚假新闻、非法获取经济利益,这些安全隐患无疑会对个人、社会造成非常严重和恶劣的负面影响。目前国内外学术届对图像篡改检测的研究都集中在自然图像篡改检测上面,但日常生活中对我们带来风险损失的假图通常是资质证书、文案、截图等。因此我们举办一个针对真实场景中大量出现的篡改图像的检测比赛,提供一个接近真实经济生活场景的篡改图像数据集,让篡改检测领域更加关注此类高风险篡改图像,通过比赛促进此方向的技术进步。
赛事介绍
数据介绍
数据包括训练集和测试集,训练集有4000张JPEG图像及对应Mask(分辨率与原图保持一致,像素值0表示该像素标识为未篡改,像素值255表示该像素标识为篡改),JPEG图像的EXIF信息均被擦除,除部分无后处理外,其它可能经过裁边、平滑、下采样、社交工具传输(没有使用组合方式);测试集有4000张JPEG图像,处理过程与训练集一致;允许使用集外数据进行训练学习。
数据示例如下图所示,右侧mask图像标注区域对应为为左侧图像篡改区域(图像中的数字部分)。

比赛玩法
比赛开始后,赛事平台会对外开放相关接口及数据集,初赛阶段本期比赛选手提交线下本地生成的测试集mask,通过计算mask和ground truth相似度作为选手在排行榜上展示的排名成绩,提交结束后主办方会对选手提交的训练测试代码进行验证,成功验证后成绩方能生效。复赛阶段比赛选手需要提交docker形式,在未公开的测试集上规定时间内线上运行结果作为选手在复赛排行榜上展示的排名成绩,同样成功验证后成绩方能生效。
赛程安排
重要时间
报名( 2022 年 1 月 30 日 —2022 年 3 月 18 日, UTC+8 )及实名认证( 2022 年 1 月 30 日 —2022 年 3 月 21 日, UTC+8 )
1、报名方式:登录比赛官网,完成个人信息注册,即可报名参赛。
2、选手可单人成队或最多不超过3人组队参赛,每位选手只能加入一支队伍。
3、选手需确保报名的个人信息完整、真实、有效,组委会有权取消不符合条件队伍的参赛资格及奖励。
4、报名、组队变更截止时间均为2022年3月18日15:00 PM (UTC+8)。 实名认证截止时间为2022年3月21日 00:00 AM (UTC+8)。 未完成认证的参赛团队将无法继续参赛。
初赛( 2022 年 2 月 16 日 —2022 年 3 月 21 日, UTC+8 )
1、报名成功后,参赛队伍通过天池平台下载数据,本地调试算法,在线提交结果。
2、2月16日10:00 (UTC+8) 起系统实时评测,每小时更新排行榜,队伍一天内有2次提交机会;按照评测指标排序;(排行榜将选择选手在本阶段的历史最优成绩进行排名展示,不做最终排名计算,排行榜成绩为未经复现校验的成绩,仅供参考)。
3、初赛2022年3月21日00:00 (UTC+8)评测结束。之后主办方会依次取排行榜上靠前的提交进行验证,验证选手提交可成功复现排行榜结果后成绩方能生效,否则取消进入复赛资格,成绩生效的Top20队伍进入复赛。
复赛( 2022 年 3 月 21 日 —2022 年 3 月 25 日, UTC+8 )
1、进入复赛队伍每次提交将要求在之前未公开的同类型2000张篡改图像上进行验证,需同时提交docker形式的模型和测试代码;
2、3月21日12:00 (UTC+8)起,队伍每天有1次提交机会,主办方会根据队伍提交的模型进行评测及验证,按照评测指标排序,将于第二天12:00(UTC+8)更新复赛排名。(排行榜将选择选手在本阶段的历史最优成绩进行排名展示,若模型在单卡2080Ti上2小时内无法运算出有效结果则当次提交无效)
数据提交
参赛选手需要上传一个含4000张mask图像的压缩包,图像的尺寸、命名、文件格式(.png)以及存放路径应和原始图像保持一致。保证所有的图片不改变命名,存放于images文件夹中,之后将整个文件夹打包成images.zip上传,系统会自动根据上传的数据计算得分。为了顺利提交,请务必保证对所有图像放于images文件夹内,再zip压缩images目录,然后进行提交。
评价指标
在测试集的4000张图像中选手需要进行篡改定位,生成对应的二值化mask图像。我们会对选手所提交的mask与我们的基准mask计算F1值与IOU值。线上得分是选手提交的4000张mask其中3000张图像的F1和IOU两个得分的总和,每张图像分数为2分,总分6000分:

解压数据集
!unzip -oq /home/aistudio/data/data129288/data.zip
数据EDA
!pip install seaborn==0.11.0
Found existing installation: seaborn 0.10.0
Uninstalling seaborn-0.10.0:
Would remove:
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/seaborn-0.10.0.dist-info/*
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/seaborn/*
Proceed (Y/n)? ^C
[31mERROR: Operation cancelled by user[0m
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting seaborn==0.11.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/bc/45/5118a05b0d61173e6eb12bc5804f0fbb6f196adb0a20e0b16efc2b8e98be/seaborn-0.11.0-py3-none-any.whl (283 kB)
|████████████████████████████████| 283 kB 6.4 MB/s
[?25hRequirement already satisfied: numpy>=1.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seaborn==0.11.0) (1.19.5)
Requirement already satisfied: matplotlib>=2.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seaborn==0.11.0) (2.2.3)
Requirement already satisfied: pandas>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seaborn==0.11.0) (1.1.5)
Requirement already satisfied: scipy>=1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seaborn==0.11.0) (1.3.0)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (2019.3)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (2.8.2)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (3.0.7)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (1.1.0)
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (0.10.0)
Requirement already satisfied: six>=1.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib>=2.2->seaborn==0.11.0) (1.16.0)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib>=2.2->seaborn==0.11.0) (41.4.0)
Installing collected packages: seaborn
Attempting uninstall: seaborn
Found existing installation: seaborn 0.10.0
Uninstalling seaborn-0.10.0:
Successfully uninstalled seaborn-0.10.0
Successfully installed seaborn-0.11.0
[33mWARNING: You are using pip version 21.3.1; however, version 22.0.4 is available.
You should consider upgrading via the '/opt/conda/envs/python35-paddle120-env/bin/python -m pip install --upgrade pip' command.[0m
import os
import cv2
import random
from tqdm import tqdm
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
TRAIN = '/home/aistudio/data/data129288/data/train/img'
MASK = '/home/aistudio/data/data129288/data/train/masked'
TEST = '/home/aistudio/data/data129288/data/test/img'
train = os.listdir(TRAIN)
test = os.listdir(TEST)
mask = os.listdir(MASK)
训练集尺寸分布
w,h = [],[]
from tqdm import tqdm
for i in tqdm(test):
if i.endswith('jpg'):
h.append(cv2.imread(os.path.join(TRAIN, i)).shape[0])
w.append(cv2.imread(os.path.join(TRAIN, i)).shape[1])
100%|██████████| 4000/4000 [00:59<00:00, 67.03it/s]
f, ax = plt.subplots(1,3, figsize=(16,4))
sns.histplot(w, ax=ax[0], palette=sns.light_palette("seagreen", as_cmap=True)).set_title('Width');
sns.histplot(h, ax=ax[1], palette=sns.color_palette("RdPu", 10)).set_title('Height');
sns.histplot(np.array(w)/np.array(h), ax=ax[2], palette=sns.color_palette("RdPu", 10)).set_title('W&H Ratio');
测试集图片尺寸分布
w,h = [],[]
from tqdm import tqdm
for i in tqdm(test):
if i.endswith('jpg'):
h.append(cv2.imread(os.path.join(TEST, i)).shape[0])
w.append(cv2.imread(os.path.join(TEST, i)).shape[1])
100%|██████████| 4000/4000 [00:59<00:00, 67.58it/s]
f, ax = plt.subplots(1,3, figsize=(16,4))
sns.histplot(w, ax=ax[0]);
sns.histplot(h, ax=ax[1]);
sns.histplot(np.array(w)/np.array(h), ax=ax[2]);
训练样本随机展示
f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):
for j in range(5):
axs[i][j].imshow(cv2.imread(os.path.join(TRAIN, train[random.randint(0,len(train)-1)].split('.')[0] + '.jpg'), cv2.IMREAD_UNCHANGED));

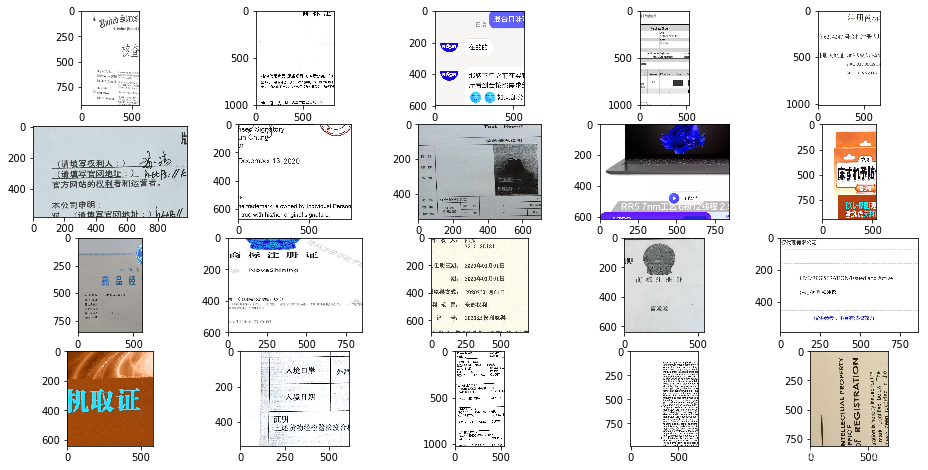
测试集随机样本展示
f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):
for j in range(5):
axs[i][j].imshow(cv2.imread(os.path.join(TEST, test[random.randint(0,len(test)-1)].split('.')[0] + '.jpg'), cv2.IMREAD_UNCHANGED));
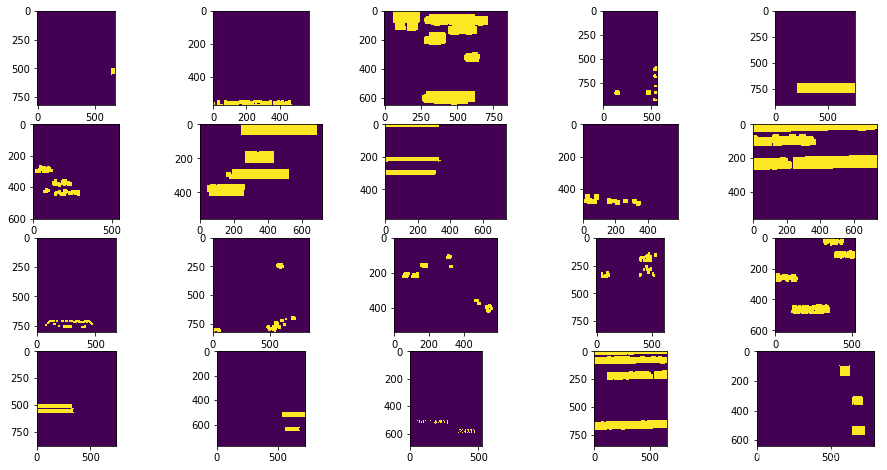
Mask区域展示
f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):
for j in range(5):
axs[i][j].imshow(cv2.imread(os.path.join(MASK, mask[random.randint(0,len(mask)-1)]), cv2.IMREAD_GRAYSCALE));
查看Mask区域占据整体图片的比例
ratios = []
for i in tqdm(range(len(mask))):
mask_area = cv2.imread(os.path.join(MASK, mask[i]), cv2.IMREAD_GRAYSCALE)
ratio = np.sum(mask_area/255.) / (mask_area.shape[0] * mask_area.shape[1])
ratios.append(ratio)
100%|██████████| 4000/4000 [00:17<00:00, 228.33it/s]
f, ax = plt.subplots(figsize=(16,16))
sns.histplot(ratios, ax=ax);
数据集划分
对训练集进行划分,按照9:1的比例进行划分,通过验证集对模型进行调参。本次项目主要是跑通整个参赛流程,确保大家不在结果提交上浪费过多时间。
!cd PaddleSeg/ && bash split.sh
SH命令如下所示
python tools/split_dataset_list.py /home/aistudio/data/train img masked --split 0.9 0.1 0.0 --format jpg png
数据训练
本次比赛的baseline选择SegForme。
知识点
SegFormer:使用Transformer进行语义分割的简单高效设计
SegFormer是一种简单、有效且鲁棒性强的语义分割的方法。SegFormer 由两部分组成:(1) 层次化Transformer Encoder (2) 仅由几个FC构成的decoder。SegFormer不仅在经典语义分割数据集(如:ADE20K, Cityscapes, Coco Stuff)上取得了SOTA的精度同时速度也不错(见图1),而且在Cityscapes-C(对测试图像加各种噪声)上大幅度超过之前的方法(如:DeeplabV3+),反映出其良好的鲁棒性。其模型结构如下图所示:

该算法目前在PaddleSeg中已有复现版本,模型的性能如下图所示:

这里我们选择B3版本作为基线模型,这里为大家展示一下这里我使用的config文件,大家需要注意将num_classes更改为数据集的类别数。
_base_: '../_base_/cityscapes_1024x1024.yml'
batch_size: 2
iters: 16000
model:
type: SegFormer_B3
num_classes: 2
pretrained: https://bj.bcebos.com/paddleseg/dygraph/mix_vision_transformer_b3.tar.gz
optimizer:
_inherited_: False
type: AdamW
beta1: 0.9
beta2: 0.999
weight_decay: 0.01
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.00003
power: 1
loss:
types:
- type: CrossEntropyLoss
coef: [1]
test_config:
is_slide: True
crop_size: [1024, 1024]
stride: [768, 768]
接下来我们可以进行模型训练了,为了方便更改模型配置,已经将python命令写入对应的SH脚本中,大家直接运行即可。
python train.py --config configs/segformer/segformer_b3_cityscapes_1024x1024_160k.yml
!cd PaddleSeg/ && bash train.sh
模型预测
在提交结果中,需要将背景区域的像素设为0,篡改区域的像素应为255。
python predict.py \
--config configs/segformer/segformer_b3_cityscapes_1024x1024_160k.yml \
--model_path /home/aistudio/data/data131417/output/ppoc_3569886_125648/output/iter_160000/model.pdparams \
--image_path /home/aistudio/data/data129288/data/test/img \
--save_dir output/result \
--custom_color 0 0 0 255 255 255
!cd PaddleSeg/ && bash infer.sh
打包提交文件
运行上面的预测命令之后,会生成一个output文件夹,将mask文件夹更改为images,并压缩成zip包,直接提交即可。
BaseLine提交结果:

总结与展望
代码使用PaddleSeg完成基础的训练和提交,包括数据集格式转换、模型训练和预测步骤,并完成提交。
对于模型的调优,大家可以有如下几个方面:
1、模型的产参数,学习率等参数。
2、模型训练方式,包括优化器的选择、WarmUp方式选择。
3、预测时是否采用图像增强,或者调整为更小的阈值。















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









