






 本项目实现了基于手势框选的文字内容点读功能。用户通过手势指定要朗读的文本区域,系统利用PaddlePaddle和OpenVINO技术进行文字识别与语音合成。
本项目实现了基于手势框选的文字内容点读功能。用户通过手势指定要朗读的文本区域,系统利用PaddlePaddle和OpenVINO技术进行文字识别与语音合成。
0 项目背景
本项目是以下四个项目的进一步升级扩展:
- 【PaddlePaddle+OpenVINO】AI“朗读机”诞生记
- 该项目是点读系列的开篇之作,对于传入的视频流,截取其中的某一帧,送入通用的PaddleOCR模型中,结合PaddleSpeech,对整页文字内容进行朗读。该项目也尝试了进行手势识别点读的操作,但是效果非常一般,串入PaddleHub的手部关键点检测模型后,预测速度调到1FPS以下,卡顿严重。
- 【PaddlePaddle+OpenVINO】打造一个指哪读哪的AI“点读机”
- 在该项目中,我们实现了一个支持点读功能的GUI程序,对于传入的实时视频流或打开的视频文件,可以结合PP-ShiTu分类模型实现逐帧预测,并将预测结果传入PaddleSpeech进行朗读
- PaddleSpeech:基于流式语音合成的电表点读系统
- 在该项目中,我们基于上面的GUI程序,将图像分类模型替换为OCR模型,但是这里的OCR模型并非通用OCR,而是基于电表检测识别模型迁移学习后的电表编号和读数OCR模型。接着,对于传入的视频流或者视频文件进行实时的电表检测,用户可以选择在合适的时候,对预测结果进行点读,报出电表读数和编号。
- PaddleDetection:手部关键点检测模型训练与Top-Down联合部署
- 对于前面提到PaddleHub的手部关键点检测模型存在的诸多问题,本项目决定重头再来——结合PaddleDetection提供的关键点检测解决方案,将手部关键点检测与手部识别主体模型进行联合部署,虽然多串入了一个模型,但预测准确性乃至效率都高了不少——手势关键点检测模型不用一直跑了,只有在主体检测符合要求的情况下,才会触发关键点检测任务。
1 项目简介
在上面介绍的前期探索基础上,本项目聚焦于实现一个真正意义上的“手势点读”场景,即:传入的视频流为一页文字内容,用户通过手势,指定要朗读的区域,“点读机”随即通过流式语音输出朗读出该段文字的内容。
1.1 操作说明
在本项目中,需要先圈定一个矩形框,然后朗读框中的内容。
圈定矩形框的方法是:
1. 将待读取的文档内容放置在摄像头下,用户右手食指的指尖指向目标矩形框的左上角,屏幕出现绿色亮点后,代表左上角的位置坐标已被系统记录。
2. 随后,再将食指指尖移到矩形框的右下角,屏幕出现绿色亮点后,会将系统读取到的矩形框绘制出来。
3. 程序会对矩形框内的文字情况进行识别,如果认定框内文字内容符合朗读要求,屏幕上会显示一排红字说明:You Can Read Now。
4. 看到可以朗读的消息后,用户点击GUI上的【点读】按钮,就可以听到自动合成的点读音频了。


1.2 实现效果
from IPython.display import Video
Video('2022-09-18 01-59-33_Trim.mp4')
video element.
这个方案的思路来源其实就是【积分商城能换】超好用的小度智能词典笔:

只不过相较于用词典笔对获取的图像进行识别,本项目采用了一种更“土”但更加便捷的方式——直接手势框选。
2 解决方案要点
项目源代码详见挂载数据集的SpotReads-OCR-v2.zip文件,读者可以下载到本地运行代码。
项目环境依赖在requirement.txt文件中。
!unzip data/data162171/SpotReads-OCR-v2.zip
# 准备环境依赖
!pip install -r requirement.txt
# 在本地环境下,进入python目录,运行main.py
!cd python/
!python main.py
2.1 指尖关键点获取
关键点检测部署代码直接使用PaddleDetection关键点检测Python部署方案进行改造。但是这里面临的重点是,我们训练的时候,标注的数据集是这样的:
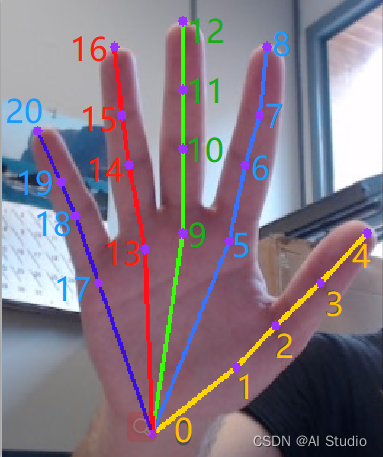
然而,具体需要点读的时候,我们往往只需要特定关键点的点位——比如本项目只需要左(右)手的食指指尖,来框选需要朗读的内容。因此,我们要对部署模型中的联合部署方案进行改造,只输出需要的内容。
# 以下代码需要在读者本地环境运行
def topdown_unite_predict_camera(detector,
topdown_keypoint_detector,
frame,
keypoint_batch_size):
# 获取视频帧
frame2 = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = detector.predict_image([frame2], visual=False)
# 关键点检测阈值设置为0.4
results = detector.filter_box(results, 0.4)
keypoint_res = predict_with_given_det(
frame2, results, topdown_keypoint_detector, keypoint_batch_size, run_benchmark=False)
if len(keypoint_res['keypoint'][0]) > 0:
if len(keypoint_res['keypoint'][0][0]) > 0:
# 8号点为训练数据集中,食指指尖所在点位(其实26号也是,训练的时候区分了左右手)
if keypoint_res['keypoint'][0][0][8][2] > 0.4:
# 返回食指指尖所在的坐标
return keypoint_res['keypoint'][0][0][8][0:2]
2.2 IoU算法的改造
2.2.1 思路分析
如何只朗读我们框选的区域?在处理这个问题时,其实我们有两种方案:
- 只把框选区域的图像传入PaddleOCR进行识别
- 对整帧图片进行OCR识别,筛选出和框选区域存在重叠的部分进行朗读
实际操作中,本项目选择了方案2。主要基于几方面的原因:
- PaddleOCR的识别效果其实和上下文有一定关联,如果只是对框选区域进行OCR识别,准确率不一定好。
- 手指相对书本某一个段落,框住的内容未必100%一致,对于处在边缘的部分,如果被截掉文字,进一步会影响OCR识别的效果。
- 从代码改造量来说,框重叠计算相对更好实现,有现成的IoU计算方案可以参考。
2.2.2 IoU算法改造
对于目标检测任务中的IoU,我们是这样算的:
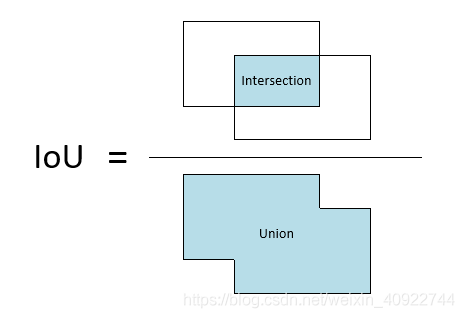
假设有两个BBOX:Box1与Box2,分子部分就是Box1与Box2交集的面积,先设为A1。分母部分是Box1与Box2并集集的面积,设为A2,其实也是Box1面积S1加上Box2面积S2再减去一个A1(为什么要减去A1呢,因为Box1与Box2重合了A1部分,需要减去一个)。
-
I o U = A 1 / A 2 IoU = A1 / A2 IoU=A1/A2
-
A 2 = S 1 + S 2 − A 1 A2 = S1 + S2 -A1 A2=S1+S2−A1
-
I o U = A 1 / ( S 1 + S 2 − A 1 ) IoU = A1 / (S1 + S2 -A1) IoU=A1/(S1+S2−A1)
参考资料:『算法动手学』Python极简实现IoU
但是,在“点读”任务中,其实我们面临的情况往往是这样的:
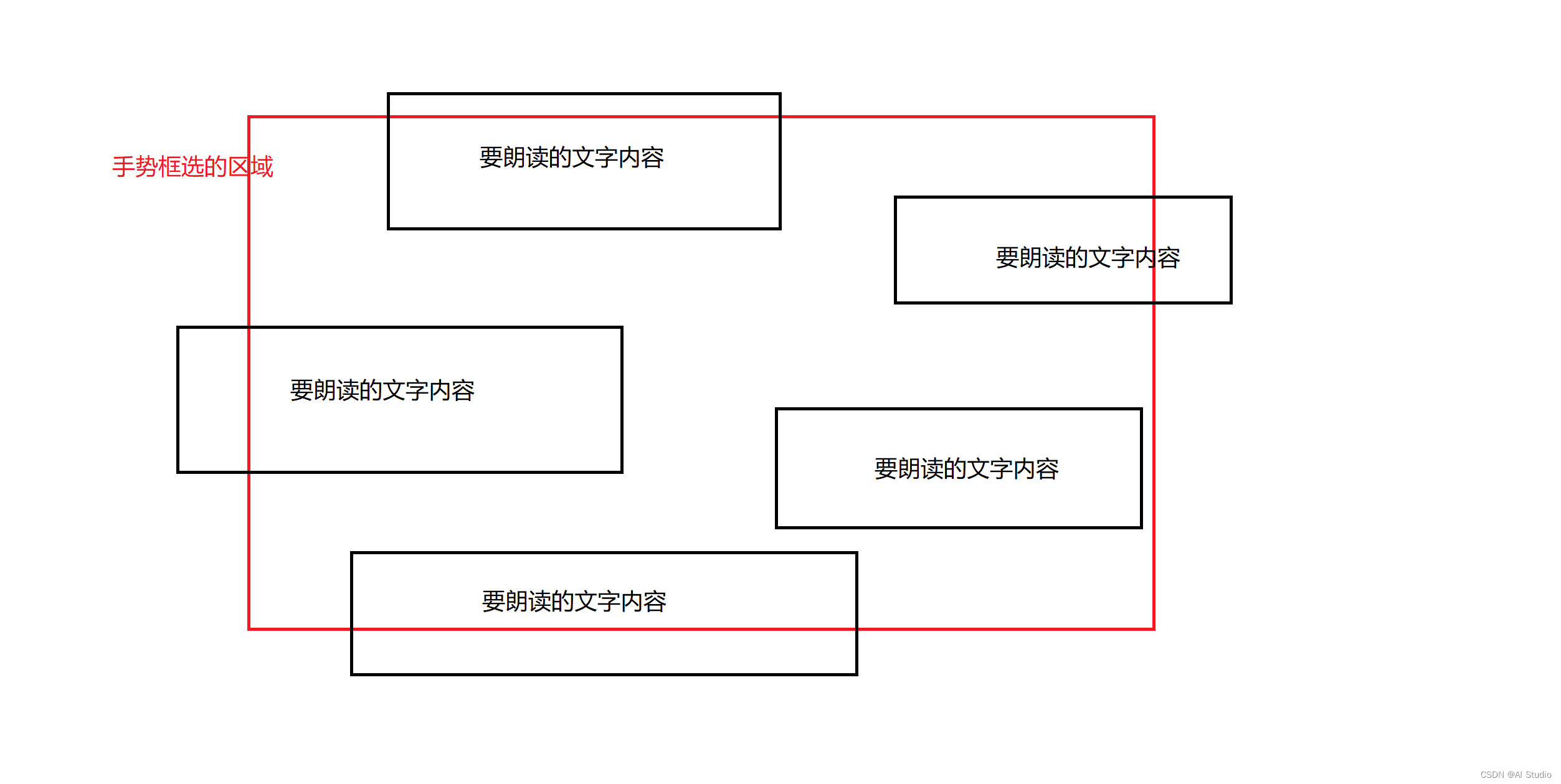
所以,在分子不变的情况下,其实我们关心的是,文字框与手势框相交部分的面积,之于文字框本身的比例!于是有:
-
I o U = A 1 / A 2 IoU = A1 / A2 IoU=A1/A2
-
A 2 = S 1 + S 2 − A 1 A2 = S1 + S2 -A1 A2=S1+S2−A1
-
I o U = A 1 / S 1 IoU = A1 / S1 IoU=A1/S1
改造后代码如下:
# 以下代码需要在读者本地环境运行
def cal_iou(box1, box2):
"""
:param box1: = [xmin1, ymin1, xmax1, ymax1]
:param box2: = [xmin2, ymin2, xmax2, ymax2]
:return:
"""
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
# 计算每个矩形的面积
s1 = (xmax1 - xmin1) * (ymax1 - ymin1) # b1的面积
s2 = (xmax2 - xmin2) * (ymax2 - ymin2) # b2的面积
# 计算相交矩形
xmin = max(xmin1, xmin2)
ymin = max(ymin1, ymin2)
xmax = min(xmax1, xmax2)
ymax = min(ymax1, ymax2)
w = max(0, xmax - xmin)
h = max(0, ymax - ymin)
a1 = w * h # C∩G的面积
iou = a1 / s2 #iou = a1/ s1
return iou
2.3 可视化效果优化
既然是一个面向用户的应用场景,优化用户体验也是一个重要内容。应该是,相较于强大的商用模型,现在的点读机算法还是有点“简陋”。主要原因就是对于指尖关键点的检测效果虽然相较于PaddleHub好了不少,但是实际用起来,还有点不准——到底指没指到,用户要怎么知道?
另一方面,“指哪读哪”的选框到底要怎么生成?我们需要规定好逻辑。
基于确定一个矩形框,只需要两个顶点,因此,本项目确定了下面一个逻辑:
- 初始的两个点都是(0,0)
- 每找到一次指尖,绘制一个圆点
- 每5个点,记录一次选框的顶点,被记录的顶点绘制原点的时候为绿色,其余都是红色
- 每记录两个顶点,在实时视频流画面中绘制一次矩形框
- 每10个点,清空一次顶点计数
这部分的关键代码如下:
# 以下代码需要在读者本地环境运行
while self.cap.isOpened():
# 视频启动时,点读按钮切换到可触发状态
self.ui.Read.setEnabled(True)
ret, frame = self.cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 加入手势关键点检测,找到食指指向
pos = topdown_unite_predict_camera(detector, topdown_keypoint_detector,
frame, 1)
if pos is not None:
num += 1
# 每5个点确定一次坐标,记录食指所在点位
cv2.circle(frame, (int(pos[0]),int(pos[1])), 20, (255,0,0), -1)
if num == 4:
pos_1 = (int(pos[0]),int(pos[1]))
cv2.circle(frame, pos_1, 20, (0,255,0), -1)
elif num == 9:
pos_2 = (int(pos[0]),int(pos[1]))
# 将两次记录的食指点位用矩形框选出来
cv2.circle(frame, pos_2, 20, (0,255,0), -1)
cv2.rectangle(frame, pos_1, pos_2, (255, 0, 0), 2)
num = 0
对 于“点读机”,能框出内容其实只解决了一半的问题——框出的内容未必能正确识别并点读。因此还要加一个阈值判断的操作,在本项目中,只有当手势框与文本框相交部分面积大于文本框面积的50%时,才判定框选内容符合点读条件。这时,为了方便用户操作,会在可视化界面上打出一段文字:“现在可以点读了”(You Can Read It Now!)向用户进行告知。
这部分内容关键代码如下:
# 以下代码需要在读者本地环境运行
# OCR检测模型对全图进行文字识别,返回的是四点标注框和框内文字
for (box, txt) in enumerate(zip(boxes, txts)):
# 将手势识别食指框选的矩形框坐标转换成bbox形式,为计算IoU做准备
pos_box = list(map(lambda x: int(x), pos_box))
# 找到OCR检测输出的四点标注框外接矩形
rect = cv2.minAreaRect(box)
box = cv2.boxPoints(rect)
box = np.int0(box)
# 获取四个顶点坐标
left_point_x = np.min(box[:, 0])
right_point_x = np.max(box[:, 0])
top_point_y = np.min(box[:, 1])
bottom_point_y = np.max(box[:, 1])
# 计算OCR检测框的外接矩形和手势框矩形相交面积之于文字外接框的占比
# print(pos_box, [left_point_x, top_point_y, right_point_x, bottom_point_y], str(txt))
# print(cal_iou(pos_box, [left_point_x, top_point_y, right_point_x, bottom_point_y]), str(txt))
# 相交部分占比超过50%的,记录下文字内容,输出为点读文本
if cal_iou(pos_box, [left_point_x, top_point_y, right_point_x, bottom_point_y]) > 0.5:
load_list.append(txt)
# 同时屏幕提示用户,此时可以按下点读按钮
cv2.putText(img=draw_img, text=f"You Can Read It Now!",
org=(0, 200),fontFace=cv2.FONT_HERSHEY_COMPLEX, fontScale=1.0,
color=(255, 0, 0), thickness=1, lineType=cv2.LINE_AA)
# 要返回的点读内容
if len(load_list) > 0:
text_list = load_list
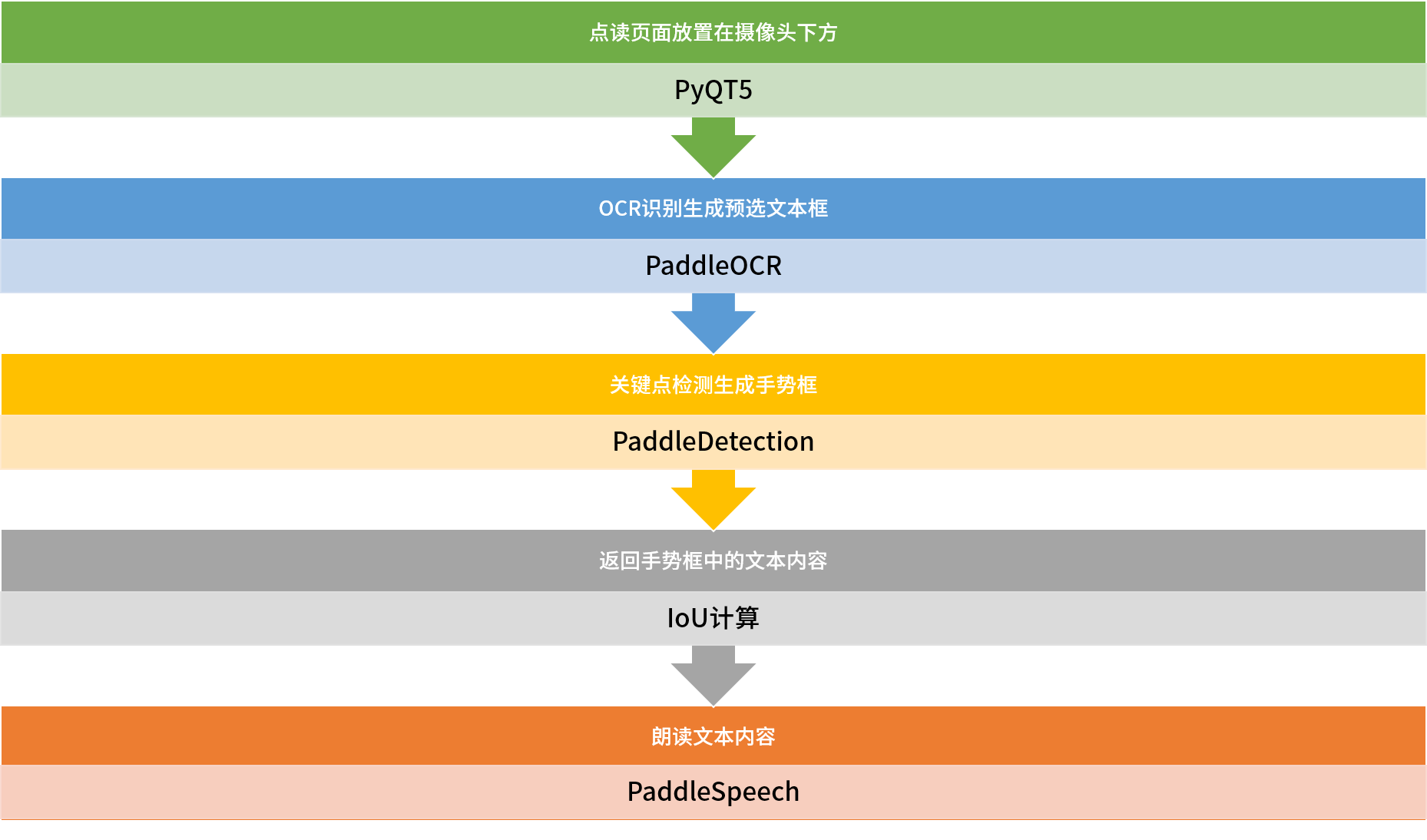
3 整体实现逻辑
搞定了关键要点,现在只需要把整个逻辑梳理清楚,基于之前的模型,把它们串起来,这里面重点参考的是PaddleSpeech:基于流式语音合成的电表点读系统项目,不同之处在于:
- 把PaddleOCR从电表迁移模型换回通用模型(注意还是只能用OCRv2,因为OpenVINO还没有适配OCRv3)
- OCR识别前加入关键点检测联合部署模型
- 找到食指指尖坐标,并执行相关逻辑
- 通过面积算法调整OCR识别函数后返回给PaddleSpeech的文本内容
点读的全流程如下:
4 小结
在本项目中,我们对之前的“点读机”项目进行了大幅升级,现在其基本能够支持近实时的点读效果,读者可以自行运行代码体验。当然,也还留下了一些提升空间:
4.1 模型优化空间
4.1.1 关键点检测还是有些“卡”,只识别食指指尖还是很容易落空。
问题基本还是出在主体模型上。PaddleDetection:手部关键点检测模型训练与Top-Down联合部署项目后面训练的主体模型,基于比较标准的手部检测数据集,但是在点读场景下,我们送入的其实并不是“完整”的手掌,只是其中一部分,这导致主体检测模型不一定能把指尖部分送给关键点检测任务,造成了检测落空。
另一方面,关键点检测模型也需要更准确、更轻量——手势关键点检测数据集其实也比较标准,跟真实的点读场景不太一样。
4.1.2 轻量级OCR检测模型效果不佳
不少时候存在这样的问题,框到了但是读出来的文字不太对。PaddleOCR-v3暂时还不能适配OpenVINO,后续考虑直接基于PaddleOCR部署,看看具体效果。
也可以考虑用OCR的服务端模型,这里就涉及到速度和准确性的平衡。当然,有条件的读者可以试试看全部模型都基于GPU推理,理论上可以大幅提升点读表现。
4.2 数据集优化空间
其实手势关键点、手部主体检测数据集体量都比较一半,如果要在商用场合下,这些数据量还是远远不够,可以考虑基于一系列开源的手势识别数据集进行补充——但是和实际场景差比较多,不确定有多大提升空间。
对于数据集和实际“点读场景”的差异问题,现在有个想法——也许我们可以用切图的思路,让主体检测模型基于子图训练,这样就“人为”地制作了部分手掌的数据集训练。具体效果将在后续项目中进一步研究。
4.3 逻辑优化空间
现在的操作是,“框好”要点读区域后,还需要用户单击“点读”按钮进行点读,实际上是一个二次确认的过程,看起来有点繁琐、不太好操作。后续如果关键点检测模型性能进一步提高,框选区域效果稳定,其实可以考虑改为代码逻辑自动触发点读,让整个系统更加智能。
此文章为搬运
原项目链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









