






一、赛题背景
客服中心每天都需要接通大量的客户来电,客户来电需要进行语音转文本,同时对文本进行概括,提取客户核心诉求,但是人工总结会增加客服工作量,降低工作效率,因此期望使用AI算法进行自动的文本摘要生成。
文本摘要的目标是自动地将输入文本转换成简短摘要,为用户提供简明扼要的内容描述,是缓解文本信息过载的一个重要手段。 文本摘要也是自然语言生成领域中的一个重要任务,有很多应用场景,如新闻摘要、论文摘要、财报摘要、传记摘要、专利摘要、对话摘要、评论摘要、观点摘要、电影摘要、文章标题生成、商品名生成、自动报告生成、搜索结果预览等。
比赛任务
赛题任务是对客户通话的语音转文字后的文本数据进行摘要提取,因而属于特定领域的通话数据,同宽泛文本提取摘要存在一定的异同,希望通过给定的文本文件,对一些通话数据进行文本摘要
主要的难点如下:
1、语音通话通过第三方服务转写为文本内容,存在一定的转写错误;
2、文本长度不固定,长短不一,可能存在文本长度过长的现象;
3、因为是具体领域的客服通话文本,专业词汇可能较多。
评选标准:
本任务采用ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评价指标。
ROUGE指标将自动生成的摘要与参考摘要进行比较,其中ROUGE-1衡量unigram匹配情况,ROUGE-2衡量bigram匹配情况,ROUGE-L记录最长公共子序列,三者都只采用f-score。
且总分的计算方式为:
0.2 * f \text {-score }(\mathrm{R} 1)+0.4 * \mathrm{f} \text {-score }(\mathrm{R} 2)+0.4 * \mathrm{f} \text {-score }(\mathrm{RL})
0.2∗f-score (R1)+0.4∗f-score (R2)+0.4∗f-score (RL)
二、项目方案
本项目是基于预训练语言模型PEGASUS的中文文本摘要产业实践,具有以下优势:
开箱即用。本项目基于FasterGeneration进行推理加速,能够提供更高性能的推理体验。训练推理全流程打通。本项目提供了全面的定制训练流程,从数据准备、模型训练预测,到模型推理部署,一应俱全。(推理部署见:PaddleNLP)
项目主要分为以下操作:
1.数据的分析与处理
2.搭建模型(基于PaddleNLP的PEGASUS模型)
3.训练配置
4.训练模型与评估
5.对测试集的文本进行摘要并保存结果
2.1准备工作
数据集的参考链接:https://datafountain.cn/competitions/536
下载好数据集后我们就能开始我们的正式的工作了,以下代码是对数据集的保存和检验
#查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
#View dataset directory.
#This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
data144577
# 查看工作区文件, 该目录下的变更将会持久保存. 请及时清理不必要的文件, 避免加载过慢.
# View personal work directory.
# All changes under this directory will be kept even after reset.
# Please clean unnecessary files in time to speed up environment loading.
!ls /home/aistudio/work
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# If a persistence installation is required,
# you need to use the persistence path as the following:
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries
mkdir: 无法创建目录"/home/aistudio/external-libraries": 文件已存在
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting beautifulsoup4
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/9c/d8/909c4089dbe4ade9f9705f143c9f13f065049a9d5e7d34c828aefdd0a97c/beautifulsoup4-4.11.1-py3-none-any.whl (128 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m128.2/128.2 kB[0m [31m5.7 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting soupsieve>1.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/16/e3/4ad79882b92617e3a4a0df1960d6bce08edfb637737ac5c3f3ba29022e25/soupsieve-2.3.2.post1-py3-none-any.whl (37 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.11.1 soupsieve-2.3.2.post1
[33mWARNING: Target directory /home/aistudio/external-libraries/beautifulsoup4-4.11.1.dist-info already exists. Specify --upgrade to force replacement.[0m[33m
[0m[33mWARNING: Target directory /home/aistudio/external-libraries/soupsieve already exists. Specify --upgrade to force replacement.[0m[33m
[0m[33mWARNING: Target directory /home/aistudio/external-libraries/soupsieve-2.3.2.post1.dist-info already exists. Specify --upgrade to force replacement.[0m[33m
[0m[33mWARNING: Target directory /home/aistudio/external-libraries/bs4 already exists. Specify --upgrade to force replacement.[0m[33m
[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
# Also add the following code,
# so that every time the environment (kernel) starts,
# just run the following code:
import sys
sys.path.append('/home/aistudio/external-libraries')
2.2数据集文本介绍和模型介绍
数据来源于客服中心通话文本数据库,首先是对通话进行录音,然后使用第三方服务进行语音转文本,文本常规情况下主要用于数据分析,用于支撑客服中心的各种客服人员指标评定和关键字分析。
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization 是Google在2020年ICML会议上提出的工作。它针对文本摘要任务设计了无监督预训练任务(Gap Sentence Generation,简称GSG),即随机遮盖文档中的几个完整句子,让模型生成被遮盖的句子。该预训练任务能够很好地与实际地文本摘要任务匹配,从而使得预训练后的模型经过简单的微调后达到较好的摘要生成效果。
2.3数据处理
数据集中的是csv文件,我先将其转为json文件,其中顺便做了清除掉一些停用词,停用词是指在交谈过程中没有信息,或者信息量对我们的提取没有目的的词语,通过建立停用词文档来处理数据。文档中的停用词除了参考网上文件以外,还考虑到了行业的特殊性,自己还添加了一些停用词
2.3.1根据文件创建停用词列表
import jieba
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 引入停用词表
stopwords = stopwordslist('停用表.txt') # 这里加载停用词的路径
2.3.2构造分句函数
将不再停用表中的词语保留下来
def splitWord(txt):
tmpRow = []
words = list(jieba.lcut(txt))
for word in words:
if word not in stopwords:
tmpRow.append(word)
#处理
#词频消除
tmpRow=''.join(tmpRow)
#连接词
return tmpRow
2.3.3构造切分句子的函数
文本长短不一,许多文本太长需要裁减,这里我们裁取了文本的前250字和后250字,因为感觉这样包含了通话内容的问题与结果
def split(txt):
tmpRow=[]
if len(txt)<500:
tmpRow=txt
else :
tmpRow=txt[:250]+txt[-250:-1]
return tmpRow
2.3.4划分训练集(trainOKDataset.csv)和验证集(yanzheng_dataset.csv)
对数据集进行随机切割,按9:1划分出训练集和验证集
import random
# 按比例随机切割数据集
train_ratio = 0.9 # 训练集占0.9,验证集占0.1
train_length=25001
with open("yanzheng_dataset.csv","w",encoding="utf-8") as yanzheng:
with open("trainOKDataset.csv","w",encoding="utf-8") as train:
with open('train_dataset.csv', 'r',encoding="utf-8") as f:
line=f.readline()
for i in range(train_length):
line=f.readline()
if line=='':
continue
if random.uniform(0, 1) < train_ratio:
train.write(line.strip())
train.write("\n")
else:
yanzheng.write(line.strip())
yanzheng.write("\n")
2.3.5将对应的csv文件转换为json文件
转换前格式: id|content|abstract
转换后格式: {content:“”,title:“”}
import json
def yanzhengFile(inpu:str,out):
#处理csv为固定格式json文件
with open(inpu,"r",encoding="utf-8") as f:
json_list=[]
for i in range(25000):
line=f.readline()
line=line.strip()
k=[]
k=line.split("|")
if len(k)!=3:
print(k[0])
continue
if i%100==0:
print(i)
json_list.append({'title':k[2],'content':k[1]})
#写入json文件
with open(out,"w",encoding="utf-8") as f:
for line in json_list:
json.dump(line,f,ensure_ascii=False)
yanzhengFile("yanzheng_dataset.csv","yanzheng_dataset.json")
#训练数据集转换
import json
def trainFile(inpu:str,out):
#处理csv为固定格式json文件
with open(inpu,"r",encoding="utf-8") as f:
json_list=[]
for i in range(25001):
line=f.readline()
line.strip()
k=line.split("|")
if len(k)!=3:
continue
#k[-2]=splitWord(k[-2])
#k[-2]=summarizer(k[-2])
#k[-2]=split(k[-2])
if i%100==0:
print(k[0])
if len(k[-2])>500:
k[-2]=splitWord(k[-2])
k[-2]=split(k[-2])
#print(k[0],len(k[-2]))
#st=summarizer(k[-2])
#print(k[0],print(st[0]))
#json_list.append({'title':k[-1],'content':st[0]})
json_list.append({'title':k[-1],'content':k[-2]})
else:
json_list.append({"title":k[-1],"content":k[-2]})
#写入json文件
with open(out,"w",encoding="utf-8") as f:
for line in json_list:
json.dump(line,f,ensure_ascii=False)
f.write('\n')
trainFile("trainOKDataset.csv","trainDataset.json")
#预测集
def testFile(inpu:str,out):
#处理csv为固定格式json文件,为目标预测集
with open(inpu,"r",encoding="utf-8") as f:
title=f.readline()
lines=f.readlines()
json_list=[]
for line in lines:
line.strip()
k=line.split("|")
if len(k)!=2:
print(k[0],k)
json_list.append({"id":k[0],"content":k[1]})
if len(k)==0:
break
#写入json文件
with open(out,"w",encoding="utf-8") as f:
for line in json_list:
json.dump(line,f,ensure_ascii=False)
f.write('\n')
testFile("test_dataset.csv","test_dataset.json")
2.3.6安装PaddleNLP环境,导入相关库
!pip install rouge==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlenlp==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
from IPython.display import clear_output
clear_output()
print("环境安装成功!请重启内核!!")
环境安装成功!请重启内核!!
import os
import json
import argparse
import random
import time
import distutils.util
from pprint import pprint
from functools import partial
from tqdm import tqdm
import numpy as np
import math
from datasets import load_dataset
import contextlib
from rouge import Rouge
from visualdl import LogWriter
from paddlenlp import Taskflow
import paddle
import paddle.nn as nn
from paddle.io import BatchSampler, DistributedBatchSampler, DataLoader
from paddlenlp.transformers import PegasusForConditionalGeneration, PegasusChineseTokenizer
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.utils.log import logger
from paddlenlp.metrics import BLEU
from paddlenlp.data import DataCollatorForSeq2Seq
[2022-12-13 22:34:06,121] [ WARNING] - Detected that datasets module was imported before paddlenlp. This may cause PaddleNLP datasets to be unavalible in intranet. Please import paddlenlp before datasets module to avoid download issues
2.3.7模型搭建
# 通过load_dataset读取本地数据集:train.json和valid.json
train_dataset = load_dataset("json", data_files='trainDataset.json', split="train")
dev_dataset = load_dataset("json", data_files='yanzheng_dataset.json', split="train")
Using custom data configuration default-f7f45ae0ad50e989
Found cached dataset json (/home/aistudio/.cache/huggingface/datasets/json/default-f7f45ae0ad50e989/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab)
Using custom data configuration default-899a94576a30debf
Found cached dataset json (/home/aistudio/.cache/huggingface/datasets/json/default-899a94576a30debf/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab)
数据格式转换
创建Tokenizer,用于分词,将token映射成id。
# 初始化分词器
tokenizer = PegasusChineseTokenizer.from_pretrained('IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese')
[2022-12-13 22:37:22,188] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/vocab.txt and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-13 22:37:22,191] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/vocab.txt
0%| | 0.00/365k [00:00<?, ?B/s]
100%|██████████| 365k/365k [00:00<00:00, 2.18MB/s]
[2022-12-13 22:37:22,485] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/added_tokens.json and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-13 22:37:22,487] [ INFO] - Downloading added_tokens.json from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/added_tokens.json
100%|██████████| 2.00/2.00 [00:00<00:00, 1.32kB/s]
[2022-12-13 22:37:24,062] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/special_tokens_map.json and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-13 22:37:24,065] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/special_tokens_map.json
100%|██████████| 65.0/65.0 [00:00<00:00, 51.5kB/s]
[2022-12-13 22:37:24,231] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/tokenizer_config.json and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-13 22:37:24,233] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/tokenizer_config.json
100%|██████████| 2.00/2.00 [00:00<00:00, 2.19kB/s]
定义convert_example,将content和title文本映射成int类型的id,同时构造labels
def convert_example(example, text_column, summary_column, tokenizer,
max_source_length, max_target_length):
"""
构造模型的输入.
"""
inputs = example[text_column]
targets = example[summary_column]
# 分词
model_inputs = tokenizer(inputs,
max_length=max_source_length,
padding=False,
truncation=True,
return_attention_mask=True)
labels = tokenizer(targets,
max_length=max_target_length,
padding=False,
truncation=True)
# 得到labels,后续通过DataCollatorForSeq2Seq进行移位
model_inputs["labels"] = labels["input_ids"]
return model_inputs
使用partial函数指定默认参数,使用map函数转换数据。map函数把原来的文本根据词汇表的编号转换成了相应的id,为了便于理解,这里把训练集合的3条样本展示出来。
# 原始字段需要移除
remove_columns = ['content', 'title']
# 文本的最大长度
max_source_length = 500
# 摘要的最大长度
max_target_length =100
# 定义转换器
trans_func = partial(convert_example,
text_column='content',
summary_column='title',
tokenizer=tokenizer,
max_source_length=max_source_length,
max_target_length=max_target_length)
# train_dataset和dev_dataset分别转换
train_dataset = train_dataset.map(trans_func,
batched=True,
load_from_cache_file=True,
remove_columns=remove_columns)
dev_dataset = dev_dataset.map(trans_func,
batched=True,
load_from_cache_file=True,
remove_columns=remove_columns)
# 输出训练集的前 3 条样本
for idx, example in enumerate(dev_dataset):
if idx < 3:
print(example)
0%| | 0/23 [00:00<?, ?ba/s]
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.782 seconds.
Prefix dict has been built successfully.
0%| | 0/3 [00:00<?, ?ba/s]
{'input_ids': [188, 1117, 1607, 189, 18283, 5661, 34663, 230, 1826, 2337, 648, 5661, 188, 15823, 189, 5661, 936, 5661, 8967, 32576, 5661, 1909, 15928, 32018, 115, 115, 115, 36320, 5661, 188, 1117, 1607, 189, 9165, 6963, 2274, 815, 5665, 15944, 873, 1653, 2355, 2274, 3846, 1101, 6445, 3399, 815, 5665, 1397, 2274, 1826, 2274, 1101, 4920, 6228, 13909, 9165, 6963, 5661, 32011, 18697, 13909, 5034, 6963, 5661, 2274, 15944, 6963, 5661, 32011, 39207, 2274, 9165, 6963, 188, 15823, 189, 1934, 2355, 430, 791, 5661, 10934, 3711, 25537, 4908, 31921, 1477, 7005, 1909, 6228, 297, 18739, 5661, 15928, 18739, 257, 6963, 5661, 1021, 5661, 13585, 1909, 752, 266, 10946, 13909, 5661, 1909, 18739, 32576, 4908, 25537, 1477, 1266, 266, 5661, 9165, 445, 7005, 4656, 5333, 5661, 8756, 197, 2449, 3399, 197, 2449, 16705, 5661, 24630, 4908, 25537, 5661, 27850, 32593, 45759, 827, 200, 4571, 5661, 7005, 1909, 6228, 18739, 5661, 188, 1117, 1607, 189, 4920, 6228, 13909, 9165, 6963, 815, 5665, 32011, 18697, 13909, 5034,
{'input_ids': [188, 1117, 1607, 189, 18283, 5661, 34663, 230, 1826, 2337, 648, 5665, 188, 15823, 189, 5661, 8967, 5661, 32576, 5661, 1909, 10838, 36100, 19992, 266, 15212, 9172, 5661, 1397, 2274, 19773, 1909, 4656, 1909, 4920, 23548, 4792, 266, 5661, 8756, 1909, 3399, 23548, 32012, 36107, 148, 23167, 1403, 5661, 18086, 4919, 346, 4792, 854, 5661, 188, 1117, 1607, 189, 5000, 1826, 12695, 4659, 1826, 3630, 3705, 5661, 1826, 25160, 11138, 3399, 23548, 636, 3399, 2274, 14541, 23548, 5661, 14541, 23548, 5661, 21038, 5679, 3023, 615, 41240, 20805, 128, 3023, 7709, 18776, 3290, 5661, 1826, 32402, 3399, 16764, 3290, 1403, 266, 5661, 188, 15823, 189, 32012, 6228, 33335, 5661, 17025, 1909, 3290, 32576, 23548, 3399, 20842, 5661, 1397, 346, 200, 15705, 3399, 3851, 1909, 763, 9172, 19773, 1909, 5661, 8756, 25160, 4792, 266, 32577, 1227, 5661, 257, 23165, 19773, 5661, 192, 199, 1370, 763, 266, 11576, 5661, 39771, 3851, 1909, 13119, 1909, 23548, 4792, 266, 5661, 188, 1117, 1607, 189, 1909, 3441, 6224
{'input_ids': [188, 1117, 1607, 189, 18283, 5661, 1722, 34663, 230, 1826, 2337, 648, 5665, 188, 15823, 189, 5661, 979, 5661, 8967, 5661, 1909, 1477, 1857, 13207, 6224, 32018, 5661, 1909, 2274, 5686, 1625, 262, 3399, 32018, 27676, 40168, 30702, 35135, 501, 3399, 31385, 618, 3110, 32122, 3299, 4637, 718, 5661, 1397, 4920, 39852, 12551, 6322, 5661, 1909, 32018, 3299, 4637, 718, 25160, 16764, 31920, 266, 5661, 25160, 4919, 4054, 4919, 5661, 4054, 4054, 4054, 4054, 2335, 11191, 30346, 815, 5665, 188, 1117, 1607, 189, 8377, 3299, 4637, 718, 926, 6228, 791, 2349, 2355, 791, 3505, 3399, 815, 188, 15823, 189, 7005, 956, 5661, 1909, 32018, 16359, 10838, 4656, 32018, 262, 3399, 32018, 25537, 503, 460, 718, 5661, 1477, 40920, 2274, 4792, 618, 3110, 5661, 32122, 25537, 5661, 3299, 4637, 718, 5665, 188, 1117, 1607, 189, 1055, 5661, 503, 460, 718, 31920, 266, 2274, 815, 31920, 2335, 44982, 266, 5665, 9518, 2335, 6322, 266, 815, 5661, 188, 15823, 189, 1454, 5665, 16359, 1397, 32018, 20869, 16359, 1397
- 组装Batch,同时初始化模型
# 初始化模型,也可以选择IDEA-CCNL/Randeng-Pegasus-523M-Summary-Chinese
model = PegasusForConditionalGeneration.from_pretrained('IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese')
# 组装 Batch 数据 & Padding
batchify_fn = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
[2022-12-11 14:11:49,220] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/model_state.pdparams and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-11 14:11:49,224] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/model_state.pdparams
100%|██████████| 675M/675M [00:10<00:00, 66.5MB/s]
[2022-12-11 14:11:59,981] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/model_config.json and saved to /home/aistudio/.paddlenlp/models/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
[2022-12-11 14:11:59,986] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/models/community/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese/model_config.json
100%|██████████| 731/731 [00:00<00:00, 485kB/s]
构造Dataloader¶
# 分布式批采样器,用于多卡分布式训练
train_batch_sampler = DistributedBatchSampler(
train_dataset, batch_size=10, shuffle=True)
# 构造训练Dataloader
train_data_loader = DataLoader(dataset=train_dataset,
batch_sampler=train_batch_sampler,
num_workers=0,
collate_fn=batchify_fn,
return_list=True)
dev_batch_sampler = BatchSampler(dev_dataset,
batch_size=12,
shuffle=False)
# 构造验证Dataloader
dev_data_loader = DataLoader(dataset=dev_dataset,
batch_sampler=dev_batch_sampler,
num_workers=0,
collate_fn=batchify_fn,
return_list=True)
2.3.8训练配置
# 学习率预热比例
warmup = 0.02
# 学习率
learning_rate = 0.001
# 训练轮次
num_epochs = 5
# 训练总步数
num_training_steps = len(train_data_loader) * num_epochs
# AdamW优化器参数epsilon
adam_epsilon = 1e-6
# AdamW优化器参数weight_decay
weight_decay=0.01
# 训练中,每个log_steps打印一次日志
log_steps = 500
# 训练中,每隔eval_steps进行一次模型评估
eval_steps = 10000
# 摘要的最小长度
min_target_length = 0
# 训练模型保存路径
output_dir = 'checkpoints1'
# 解码beam size
num_beams = 4
log_writer = LogWriter('visualdl_log_dir')
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup)
# LayerNorm参数不参与weight_decay
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 优化器AdamW
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
beta1=0.9,
beta2=0.999,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
# 计算训练评估参数Rouge-1,Rouge-2,Rouge-L,BLEU-4
def compute_metrics(preds, targets):
assert len(preds) == len(targets), (
'The length of pred_responses should be equal to the length of '
'target_responses. But received {} and {}.'.format(
len(preds), len(targets)))
rouge = Rouge()
bleu4 = BLEU(n_size=4)
scores = []
for pred, target in zip(preds, targets):
try:
score = rouge.get_scores(' '.join(pred), ' '.join(target))
scores.append([
score[0]['rouge-1']['f'], score[0]['rouge-2']['f'],
score[0]['rouge-l']['f']
])
except ValueError:
scores.append([0, 0, 0])
bleu4.add_inst(pred, [target])
rouge1 = np.mean([i[0] for i in scores])
rouge2 = np.mean([i[1] for i in scores])
rougel = np.mean([i[2] for i in scores])
bleu4 = bleu4.score()
print('\n' + '*' * 15)
print('The auto evaluation result is:')
print('rouge-1:', round(rouge1*100, 2))
print('rouge-2:', round(rouge2*100, 2))
print('rouge-L:', round(rougel*100, 2))
print('BLEU-4:', round(bleu4*100, 2))
return rouge1, rouge2, rougel, bleu4
# 模型评估函数
@paddle.no_grad()
def evaluate(model, data_loader, tokenizer, min_target_length,
max_target_length):
model.eval()
all_preds = []
all_labels = []
model = model._layers if isinstance(model, paddle.DataParallel) else model
for batch in tqdm(data_loader, total=len(data_loader), desc="Eval step"):
labels = batch.pop('labels').numpy()
# 模型生成
preds = model.generate(input_ids=batch['input_ids'],
attention_mask=batch['attention_mask'],
min_length=min_target_length,
max_length=max_target_length,
diversity_rate='beam_search',
num_beams=num_beams,
use_cache=True)[0]
# tokenizer将id转为string
all_preds.extend(
tokenizer.batch_decode(preds.numpy(),
skip_special_tokens=True,
clean_up_tokenization_spaces=False))
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
all_labels.extend(
tokenizer.batch_decode(labels,
skip_special_tokens=True,
clean_up_tokenization_spaces=False))
rouge1, rouge2, rougel, bleu4 = compute_metrics(all_preds, all_labels)
model.train()
return rouge1, rouge2, rougel, bleu4
2.3.9模型训练和评估
def train(model, train_data_loader):
global_step = 0
best_rougel = 0
tic_train = time.time()
for epoch in range(num_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
# 模型前向训练,计算loss
_, _, loss = model(**batch)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % log_steps == 0:
logger.info(
"global step %d/%d, epoch: %d, batch: %d, rank_id: %s, loss: %f, lr: %.10f, speed: %.4f step/s"
% (global_step, num_training_steps, epoch, step,
paddle.distributed.get_rank(), loss, optimizer.get_lr(),
log_steps / (time.time() - tic_train)))
log_writer.add_scalar("train_loss", loss.numpy(), global_step)
tic_train = time.time()
if global_step % eval_steps== 0 or global_step == num_training_steps:
tic_eval = time.time()
rouge1, rouge2, rougel, bleu4 = evaluate(model, dev_data_loader, tokenizer,
min_target_length, max_target_length)
logger.info("eval done total : %s s" % (time.time() - tic_eval))
log_writer.add_scalar("eval_rouge1", rouge1, global_step)
log_writer.add_scalar("eval_rouge2", rouge2, global_step)
log_writer.add_scalar("eval_rougel", rougel, global_step)
log_writer.add_scalar("eval_bleu4", bleu4, global_step)
if best_rougel < rougel:
best_rougel = rougel
if paddle.distributed.get_rank() == 0:
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Need better way to get inner model of DataParallel
model_to_save = model._layers if isinstance(
model, paddle.DataParallel) else model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# 调用模型训练
train(model, train_data_loader)
2.3.10对测试集的文本进行摘要并保存结果
文本提交格式要求
id|摘要结果
max_target_length=100
min_target_length=0
max_source_length=500
def infer(text, model, tokenizer):
tokenized = tokenizer(text,
truncation=True,
max_length=max_source_length,
return_tensors='pd')
preds, _ = model.generate(input_ids=tokenized['input_ids'],
max_length=max_target_length,
min_length=min_target_length,
decode_strategy='beam_search',
num_beams=4)
return tokenizer.decode(preds[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
# 加载训练好的模型
model = PegasusForConditionalGeneration.from_pretrained('checkpoints2')
model.eval()
tokenizer = PegasusChineseTokenizer.from_pretrained('checkpoints2')
#评估2
ls=evaluate(model, dev_data_loader, tokenizer, min_target_length, max_target_length)
print(ls)
# 推理
text = "【坐席】很高兴为您服务,您好,【客户】,我想问一下,我买了30块钱十个G的流量,嗯,为什么这么卡,【坐席】我看一下稍等,【客户】我就怕3G卡,昨天我又买了十个G7天的,嗯,还这么卡有,那我用3G呗,我也不用花钱呢,【坐席】您现在是您现在的话是限速状态,限速状态的话,您是开这种多天包是它是解不开限速的?【客户】那我能不能退啊,【坐席】您现在这个的话,它是已经使用了现在,而且已经生效了,您用了1631兆,【客户】那我我要不买的话也是限速3G啊,【坐席】对,因为您是限速之后,您开这种多日包,他只解不了限速,只能开咱们普通的5G升级包或者大流量权益包,这种可以解开限速,多日包的话解不了限速的?【客户】噢,30块钱不白花了吗,【坐席】嗯,那这边可以给您做一下登记,反馈到后台,到时候会有工作人员联系您,帮您处理的,您接听一下,工作人员回复电话好吧,【客户】那我已经买了买了,就那个十个G的是我,那我这样的话我不用买不也行吗?那你把那个更改跟着给我反应给我退了,【坐席】我这边给您做登记,到时候工作人员给您打电话,您注意接听,【客户】我要的是四个G不是3G3G我不用花钱?【坐席】嗯,明白,那我这边给您做登记了,您看还有其他问题吗,【客户】没有了【坐席】嗯,感谢来电,祝您愉快,再见,嗯"
print(len(text))
infer(text, model, tokenizer)
541
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.773 seconds.
Prefix dict has been built successfully.
'用户来电反映对202101 月份的流量使用情况有疑义,我某某人常按照上网日志解释并建议其查询上网详单,用户强烈不认可,要求我方为其核实具体使用情况,请尽快处理,谢谢!'
#预测集
def testFile2():
#处理csv为固定格式json文件,为目标预测集
with open("test_dataset.csv","r",encoding="utf-8") as f:
with open("submit.csv","w",encoding="utf-8") as file:
title=f.readline()
i=0
lines=f.readlines()
for line in lines:
line.strip()
k=line.split("|")
if i%100==0:
print(i)
if len(k)!=2:
print(k[0],k)
if len(k[1])>500:
k[1]=split(k[1])
result=infer(k[1], model, tokenizer)
file.write(f"{k[0]}|{result}\n")
if len(k)==1:
break
#if __name__=="__main__":
ls1=Process(target=c,args=(1,"test1.csv"))
ls2=Process(target=c,args=(2,"test2.csv"))
ls3=Process(target=c,args=(3,"test3.csv"))
ls4=Process(target=c,args=(4,"test4.csv"))
ls1.start()
ls2.start()
ls3.start()
ls4.start()
Process Process-9:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 725, in convert_to_tensors
tensor = as_tensor(value)
Process Process-10:
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 546, in to_tensor
return _to_tensor_non_static(data, dtype, place, stop_gradient)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 411, in _to_tensor_non_static
stop_gradient=stop_gradient,
Traceback (most recent call last):
OSError: (External) CUDA error(3), initialization error.
[Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:172)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 725, in convert_to_tensors
tensor = as_tensor(value)
During handling of the above exception, another exception occurred:
Process Process-11:
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 546, in to_tensor
return _to_tensor_non_static(data, dtype, place, stop_gradient)
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 411, in _to_tensor_non_static
stop_gradient=stop_gradient,
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
OSError: (External) CUDA error(3), initialization error.
[Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:172)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 725, in convert_to_tensors
tensor = as_tensor(value)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
During handling of the above exception, another exception occurred:
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 546, in to_tensor
return _to_tensor_non_static(data, dtype, place, stop_gradient)
File "/tmp/ipykernel_770/2652853561.py", line 19, in c
result = infer(k[1], model, tokenizer)
Traceback (most recent call last):
File "/tmp/ipykernel_770/3648606620.py", line 8, in infer
return_tensors='pd')
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 411, in _to_tensor_non_static
stop_gradient=stop_gradient,
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2275, in __call__
**kwargs)
OSError: (External) CUDA error(3), initialization error.
[Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:172)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2349, in encode
**kwargs,
During handling of the above exception, another exception occurred:
File "/tmp/ipykernel_770/2652853561.py", line 19, in c
result = infer(k[1], model, tokenizer)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils.py", line 1038, in _encode_plus
**kwargs)
Traceback (most recent call last):
File "/tmp/ipykernel_770/3648606620.py", line 8, in infer
return_tensors='pd')
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2853, in prepare_for_model
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2275, in __call__
**kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 219, in __init__
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2349, in encode
**kwargs,
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 735, in convert_to_tensors
"Unable to create tensor, you should probably activate truncation and/or padding "
File "/tmp/ipykernel_770/2652853561.py", line 19, in c
result = infer(k[1], model, tokenizer)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils.py", line 1038, in _encode_plus
**kwargs)
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
File "/tmp/ipykernel_770/3648606620.py", line 8, in infer
return_tensors='pd')
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2853, in prepare_for_model
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2275, in __call__
**kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 219, in __init__
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2349, in encode
**kwargs,
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 735, in convert_to_tensors
"Unable to create tensor, you should probably activate truncation and/or padding "
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils.py", line 1038, in _encode_plus
**kwargs)
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2853, in prepare_for_model
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 219, in __init__
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 735, in convert_to_tensors
"Unable to create tensor, you should probably activate truncation and/or padding "
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
Process Process-12:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 725, in convert_to_tensors
tensor = as_tensor(value)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 546, in to_tensor
return _to_tensor_non_static(data, dtype, place, stop_gradient)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py", line 411, in _to_tensor_non_static
stop_gradient=stop_gradient,
OSError: (External) CUDA error(3), initialization error.
[Hint: Please search for the error code(3) on website (https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g3f51e3575c2178246db0a94a430e0038) to get Nvidia's official solution and advice about CUDA Error.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:172)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "/tmp/ipykernel_770/2652853561.py", line 19, in c
result = infer(k[1], model, tokenizer)
File "/tmp/ipykernel_770/3648606620.py", line 8, in infer
return_tensors='pd')
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2275, in __call__
**kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2349, in encode
**kwargs,
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils.py", line 1038, in _encode_plus
**kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 2853, in prepare_for_model
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 219, in __init__
prepend_batch_axis=prepend_batch_axis)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/tokenizer_utils_base.py", line 735, in convert_to_tensors
"Unable to create tensor, you should probably activate truncation and/or padding "
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
c(1,'test1.csv')
100
Unable to create tensor, you should probably activate truncation and/or padding with ‘padding=True’ ‘truncation=True’ to have batched tensors with the same length.
c(1,'test1.csv')
100
c(2,'test2.csv')
c(3,'test3.csv')
c(4,'test4.csv')
import time
from multiprocessing import Process
def c(d,file):
with open(file,"r",encoding="utf-8") as f:
k=f'Test{str(d)}.csv'
with open(k,"w",encoding="utf-8") as file:
lines=f.readlines()
i=0
for line in lines:
i+=1
line.strip()
k = line.split("|")
if i % 100 == 0:
print(i)
if len(k) != 2:
print(k[0], k)
if len(k[1]) > 500:
k[1] = split(k[1])
result = infer(k[1], model, tokenizer)
file.write(f"{k[0]}|{result}\n")
if len(k) == 1:
break
#time.sleep(d)
#切割数据集
with open("test_dataset.csv","r",encoding="utf-8") as f:
line=f.readline()
lines=f.readlines()
ls1=[]
ls2=[]
ls3=[]
ls4=[]
i=0
for line in lines:
i=i%4
if i==0:
ls1.append(line)
elif i==1:
ls2.append(line)
elif i==2:
ls3.append(line)
elif i==3:
ls4.append(line)
i+=1
def save(file,ls):
with open(file,"w",encoding="utf-8") as f:
for x in ls:
f.write(x)
save("test1.csv",ls1)
save("test2.csv",ls2)
save("test3.csv",ls3)
save("test4.csv",ls4)
testFile2()
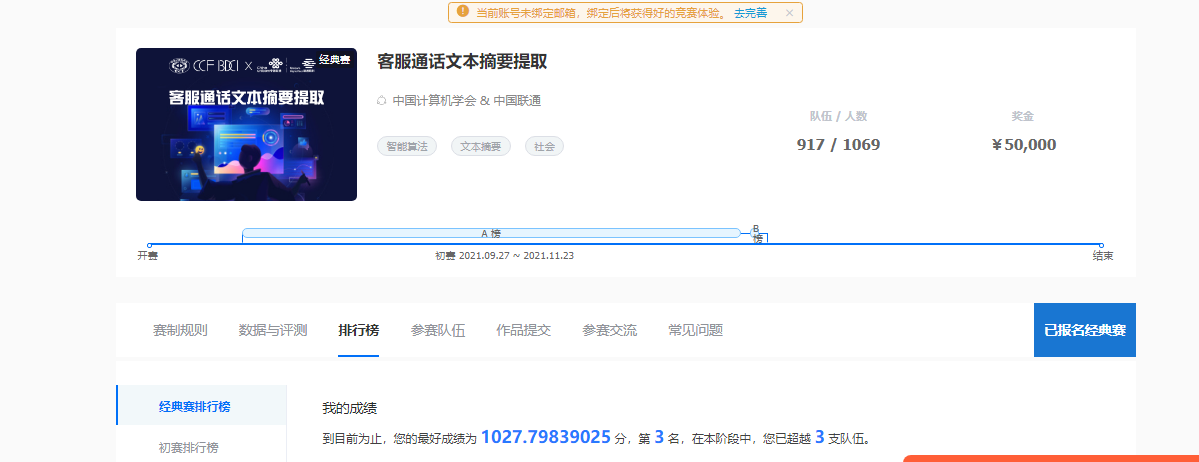
三、结果图提交和赛题得分展示

四、项目总结
本次项目是本人的第一次项目写作,在写作过程中借鉴了中文文本摘要 的代码和模型构建思路,在本次项目中我做了对数据集文件进行初步的数据处理,数据清洗,利用停用词表对数据进行了数据的出不清洗,在模型构建方面,我选择了PaddleNLP中的PEGASUAS模型,利用数据集提供的文件,经过一些调参之后,我获取了预想的数据结果。在此过程中我体会到了模型的数据从处理到,模型的搭建,再到模型的训练,再到最后的预测,文本摘要的过程的简单快捷方便让我深刻的感受到了Paddle NLP的方便快捷。
本次项目可能优化的地方还有可能有,部分参数设置的并不合理,可能需要重新调参,其次是训练的时间过慢,内存耗用的地方大,之后的模型预测并没有采用线程并发的思想,或者说采用迭代器的方法进行预测以至于数据的时间消耗长。
五、个人介绍
本人是AI达人特训营第二期项目中的一名学员,非常有幸能与大家分享自己的所思所想。
作者:刘文平 指导导师:黄灿桦
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









