






基于StarganV2-VC的原神音色转换
原神是米哈游推出的一款开放世界冒险游戏。游戏一经推出,就收到了广大玩家的喜爱。Stargan则是一个用于多领域间的转换问题的深度学习模型,starganv2-vc就是在stargan的基础上,对stargan做出改进,并迁移到音色转换问题上的模型。本项目尝试使用starganv2-vc来实现原神不同角色之间的音色转换。

本项目由我和InseQM共同完成
一、数据集介绍
原神公测于2020年9月28日开启,至今已经有了46个角色。其中:蒙德城角色共有19名,分别为琴、安柏、 丽莎 、凯亚等;璃月港角色共有16名,分别为魈、 北斗、 凝光等;稻妻城角色共有11名,分别为神里绫华、 枫原万叶、 宵宫等。我们选择其中的九个角色,分别是:
- 甘雨:璃月七星的秘书,体内流淌着人类与仙兽的血脉。 天性优雅娴静,但仙兽“麒麟”温柔的性情与坚定毅重的工作态度毫无冲突。 毕竟,甘雨坚信自己所做的一切工作都是为了践行与帝君的契约
- 胡桃:是 璃月港“往生堂”第七十七代堂主,掌控着璃月葬仪事务的重要人物。 尽心尽力地为人们完成送别之仪,维护着世间阴阳平衡之道。 除此以外还是个神奇打油诗人,诸多“杰作”被璃月人口口相传 。
- 可莉:西风骑士团火花骑士,永远伴随闪光与爆炸出现!然后在琴团长严厉的目光注视下默默消失
。西风骑士团禁闭室的常客,蒙德的爆破大师,人称“逃跑的太阳”
- 莫娜:拥有与名号相符的不俗实力,博学而高傲。尽管过着拮据、清贫的生活,但她坚决不用占卜来牟利,正是这种坚持,导致莫娜总是在为生计发愁。
- 纳西妲:“尘世七执政”中国家须弥的草神,魔神名为“布耶尔”。被须弥人给予“小吉祥草王”的爱称
。现今七神中最年轻的一位,自诞生起已五百年
- 妮露:“祖拜尔剧场”的明星演员,舞姿娉婷,如睡莲初绽,一尘不染。但她绝非高傲清冷之人,即便只是匆匆的旅者,也会对她纯洁质朴的笑容过目不忘
- 宵宫:才华横溢的烟花工匠,“长野原烟花店”的现任店主,被誉为“夏祭的女王”。宵宫是热情似火的少女,未泯的童心与匠人的执着在她身上交织出了奇妙的焰色反应。
- 魈:守护璃月港的“三眼五显仙人”之一,妙称“护法夜叉大将”。虽然外表看起来是一个少年人,但一些有关他的传说,已在古卷中流传千年。
- 钟离:应“往生堂”邀请而来的神秘客卿。 钟离样貌俊美,举止高雅,拥有远超常人的学识。 虽说来历不明,却知礼数、晓规矩。 坐镇“往生堂”,能行天地万物之典仪。
# wav转mp3 这个可以不执行
!pip install pydub
from pydub import AudioSegment
import os
if not os.path.exists('demo'):
os.mkdir('demo')
# 因为生成版本的时候对文件体积有限制,所以这里的wav没有放进来,但是都提前转换好了,放在demo目录下,可以直接使用
if os.path.exists('Impact'):
for role in os.listdir('Impact'):
AudioSegment.from_wav(f"/home/aistudio/Impact/{role}/FormatFactoryPart8.wav").export(f"demo/{role}.mp3", format="mp3")
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: pydub in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (0.25.1)
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
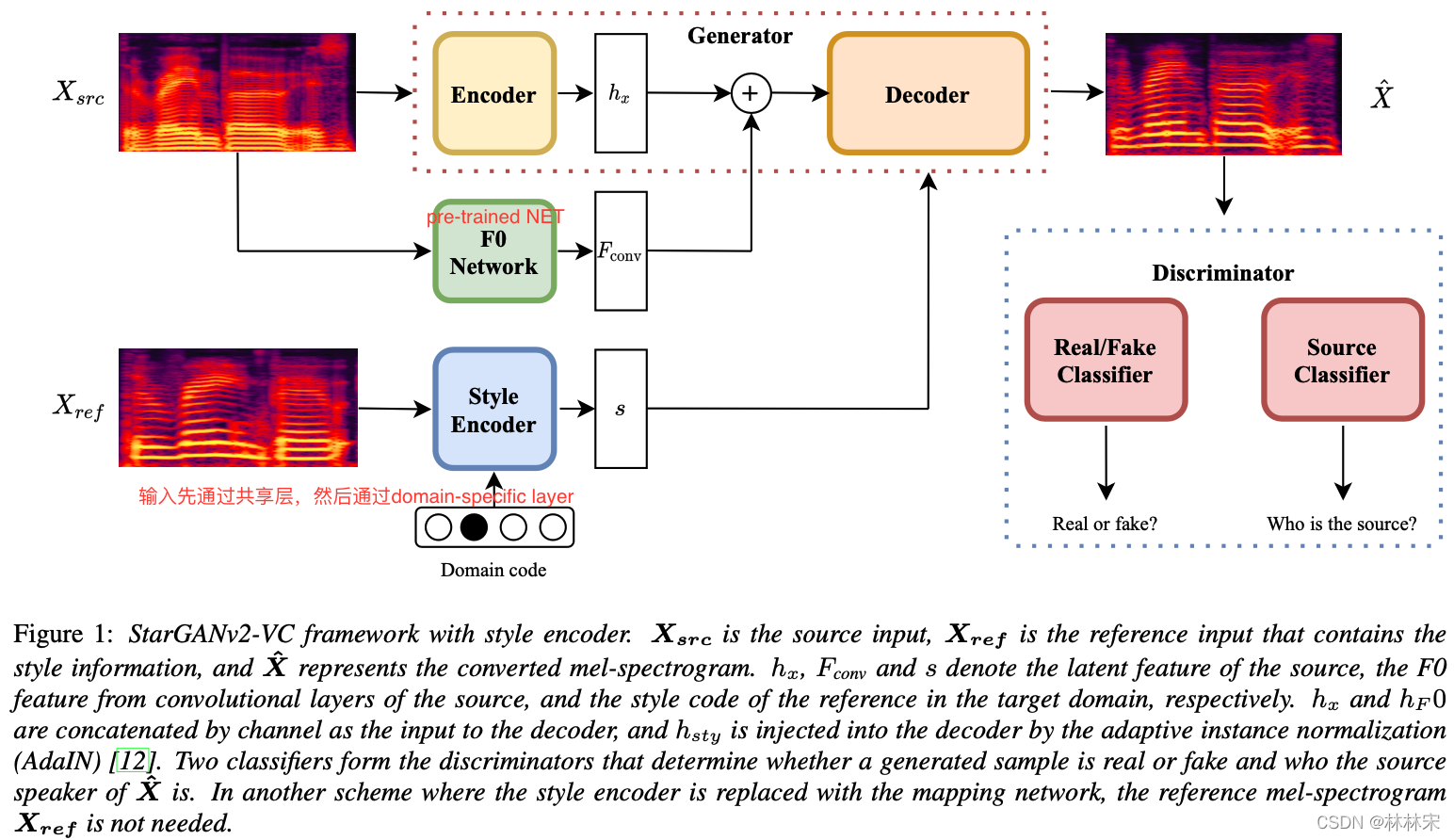
二、原理
StarganV2-VC,是基于Starganv2的一个声音转换模型,在介绍StarganV2-VC前我们先简单了解一下GAN、Stargan、以及VC
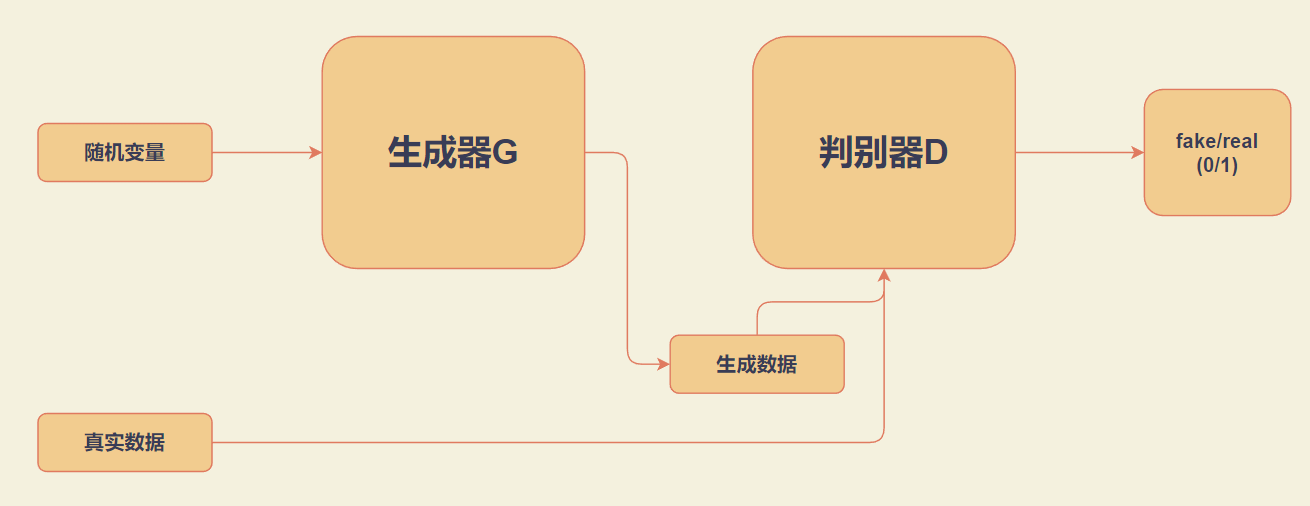
2.1 GAN
生成对抗网络(Generative adversarial networks)是深度学习领域的一个重要生成模型,即两个网络(生成器和鉴别器)在同一时间训练并且在极小化极大算法(minimax)中进行竞争。这种对抗方式避免了一些传统生成模型在实际应用中的一些困难,巧妙地通过对抗学习来近似一些不可解的损失函数,在图像、视频、自然语言和音乐等数据的生成方面有着广泛应用。
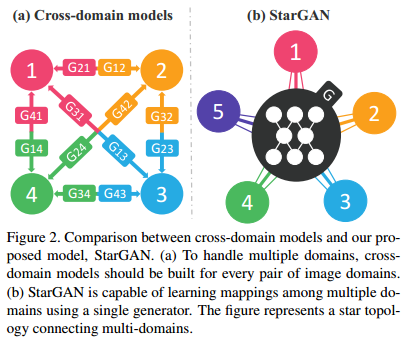
2.2 StarGAN v2
starGAN 是 Yunjey Choi 等人于 17年11月 提出的一个模型。该模型可以实现 图像的多域间的迁移(作者在论文中具体应用于人脸属性的转换)。在 starGAN 之前,也有很多 GAN模型 可以用于 image-to-image,比如 pix2pix(训练需要成对的图像输入),UNIT(本质上是coGAN),cycleGAN(单域迁移)和 DiscoGAN。而 starGAN 使用 一个模型 实现 多个域 的迁移,这在其他模型中是没有的,这提高了图像域迁移的可拓展性和鲁棒性。
2.3 VC
VC(voice conversion)是保持语言内容但音色转换成另外一个人的声音(比如柯南的变声器),AC(accent conversion)是保持语言内容和说话人的音色,但口音发生变化(如把标准普通话转成天津话,四川话等发音方式)。目前通用的流程,是先通过ASR模型把语音转成与说话者无关的中间表现形式,比如PPG(phonetic posteriorgram)或者BN(bottleneck feature)等。然后,使用encoder-decoder的模型把中间变现形式转换成目标发音人的声学特征。最后,使用声码器合成音频。
有需求的同学可以关注merlin和sprocket。
2.4 音频的预处理
音频存储下来是每个时间点声波不同的振幅,因为现实中的声音是很多声波叠在一起的,所以存储下来的数据单看是不规律的,需要使用短时傅里叶变换将一小段时间内的时域转换为频域,而频域是可以无限大的,我们只取人耳可以辨别的80块,这80块组成的频谱被称为梅尔谱,通过Log处理,再将梅尔谱转换为梅尔倒谱,这个转换使得人声能更多地分布在频谱上,而不是挤在高频率区域。
梅尔倒谱便是声音处理的一般输入输出。
2.5 声码器 (Vocoder)
但是声音处理到梅尔倒谱时已经丢失了很多信息,所以需要声码器将梅尔倒谱转换为波形,使重建的波形更自然。常见的声码器有WaveGAN,MelGAN, HifiGAN,Parallel WaveGAN,这些在PaddleSpeech中都有集成。本项目提供的是转换过来的vctk上训练的Parallel WaveGAN预训练声码器,对英文语音优化较好。
2.6 Starganv2-VC
StarGAN v2提出两个模块,一个映射网络mapping network和一个样式编码器style encoder。 映射网络学习将随机高斯噪声转换为style code,编码器则学习从给定的参考图像中提取style code。 考虑到多个域,两个模块都具有多个输出分支,每个分支都提供特定域的style code。 利用这些style code,生成器能够在多个域上成功合成各种图像。
通过这两个模块,v2解决了v1多样性和可拓展性的问题。也正是如此,语音转换版本的StarGAN v2才能实现类别不多,却可以轻易拓展到域外的说话人的语音转换的能力,即开头将从未参与训练的我的声音转换为域内标记过的声音的能力,通过一些手段,还可以将声音转换为域外未标记的声音上,这个我们下期再讲。
三、模型训练
模型训练非常耗时,这里仅做简单介绍,感兴趣的同学可以添加自己的数据集来进行训练,这里我们以元神数据集为例
- 首先,执行下面的cell,按装相关的依赖和解压预训练模型
- 修改config文件,需要注意的是num_domain应该根据自己训练集中的角色数来进行调整
- 进入
starganv2vc-paddle目录下,执行python train.py
# 解压一些模型,按装相关包
%cd /home/aistudio
import os
!pip install munch paddleaudio paddlespeech
if not os.path.exists('./nltk_data'):
# 下载解压nltk包,这是paddlespeech的依赖
!wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf data/nltk_data.tar.gz
if not os.path.exists('starganv2vc-paddle/Models'):
!unzip data/data145012/Models.zip -d starganv2vc-paddle
if not os.path.exists('starganv2vc-paddle/Vocoder'):
!unzip data/data145012/Vocoder.zip -d starganv2vc-paddle
!cd starganv2vc-paddle && pip install -r requirements.txt
# !python train.py
四、模型推理
模型推理之前,我们要先计算一下人物音色的embedding,以便后续音色转换。
# 计算Demo文件夹下的说话人的风格
speaker_dicts = {}
selected_speakers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for idx, s in enumerate(os.listdir('/home/aistudio/Impact')):
path = os.path.join('/home/aistudio/Impact', s, 'FormatFactoryPart8.wav')
speaker_dicts[s] = (path, idx)
reference_embeddings = compute_style(speaker_dicts)
这一段就是计算style-embedding
之后,我们在wav_path = '' # 这里改成你上传的干净低噪声的wav格式语音文件处上传自己的声音文件就可以进行音色转换了。(建议在gpu设备上体验,cpu上也可以但是比较慢)
%cd starganv2vc-paddle/
import random
import yaml
from munch import Munch
import numpy as np
import paddle
from paddle import nn
import paddle.nn.functional as F
import paddleaudio
import librosa
from starganv2vc_paddle.Utils.ASR.models import ASRCNN
from starganv2vc_paddle.Utils.JDC.model import JDCNet
from starganv2vc_paddle.models import Generator, MappingNetwork, StyleEncoder
speakers = [0, 1, 2, 3, 4, 5, 6, 7, 8]
to_mel = paddleaudio.features.MelSpectrogram(
n_mels=80, n_fft=2048, win_length=1200, hop_length=300)
to_mel.fbank_matrix[:] = paddle.load('starganv2vc_paddle/fbank_matrix.pd')['fbank_matrix']
mean, std = -4, 4
def preprocess(wave):
wave_tensor = paddle.to_tensor(wave).astype(paddle.float32)
mel_tensor = to_mel(wave_tensor)
mel_tensor = (paddle.log(1e-5 + mel_tensor.unsqueeze(0)) - mean) / std
return mel_tensor
def build_model(model_params={}):
args = Munch(model_params)
generator = Generator(args.dim_in, args.style_dim, args.max_conv_dim, w_hpf=args.w_hpf, F0_channel=args.F0_channel)
mapping_network = MappingNetwork(args.latent_dim, args.style_dim, args.num_domains, hidden_dim=args.max_conv_dim)
style_encoder = StyleEncoder(args.dim_in, args.style_dim, args.num_domains, args.max_conv_dim)
nets_ema = Munch(generator=generator,
mapping_network=mapping_network,
style_encoder=style_encoder)
return nets_ema
def compute_style(speaker_dicts):
reference_embeddings = {}
for key, (path, speaker) in speaker_dicts.items():
if path == "":
label = paddle.to_tensor([speaker], dtype=paddle.int64)
latent_dim = starganv2.mapping_network.shared[0].weight.shape[0]
ref = starganv2.mapping_network(paddle.randn([1, latent_dim]), label)
else:
wave, sr = librosa.load(path, sr=24000)
audio, index = librosa.effects.trim(wave, top_db=30)
if sr != 24000:
wave = librosa.resample(wave, sr, 24000)
mel_tensor = preprocess(wave)
with paddle.no_grad():
label = paddle.to_tensor([speaker], dtype=paddle.int64)
ref = starganv2.style_encoder(mel_tensor.unsqueeze(1), label)
reference_embeddings[key] = (ref, label)
return reference_embeddings
F0_model = JDCNet(num_class=1, seq_len=192)
params = paddle.load("Models/bst.pd")['net']
F0_model.set_state_dict(params)
_ = F0_model.eval()
import yaml
import paddle
from yacs.config import CfgNode
from paddlespeech.s2t.utils.dynamic_import import dynamic_import
from paddlespeech.t2s.models.parallel_wavegan import PWGGenerator
with open('Vocoder/config.yml') as f:
voc_config = CfgNode(yaml.safe_load(f))
voc_config["generator_params"].pop("upsample_net")
voc_config["generator_params"]["upsample_scales"] = voc_config["generator_params"].pop("upsample_params")["upsample_scales"]
vocoder = PWGGenerator(**voc_config["generator_params"])
vocoder.remove_weight_norm()
vocoder.eval()
vocoder.set_state_dict(paddle.load('Vocoder/checkpoint-400000steps.pd'))
model_path = '/home/aistudio/data/data183067/epoch_00009.pd'
with open('../config.yml') as f:
starganv2_config = yaml.safe_load(f)
starganv2 = build_model(model_params=starganv2_config["model_params"])
params = paddle.load(model_path)
params = params['model_ema']
_ = [starganv2[key].set_state_dict(params[key]) for key in starganv2]
_ = [starganv2[key].eval() for key in starganv2]
starganv2.style_encoder = starganv2.style_encoder
starganv2.mapping_network = starganv2.mapping_network
starganv2.generator = starganv2.generator
# 计算Demo文件夹下的说话人的风格
speaker_dicts = {}
selected_speakers = ['甘雨', '胡桃', '可莉', '莫娜', '纳西妲', '妮露', '宵宫', '魈', '钟离']
for idx, s in enumerate(selected_speakers):
speaker_dicts[str(s)] = (f'/home/aistudio/demo/wavs/{s}/FormatFactoryPart8.wav', speakers.index(idx))
reference_embeddings = compute_style(speaker_dicts)
%cd ..
/home/aistudio/starganv2vc-paddle
/home/aistudio
import IPython.display as ipd
wav_path = '/home/aistudio/demo/wavs/甘雨/FormatFactoryPart8.wav' # 这里改成你上传的干净低噪声的wav格式语音文件
audio, source_sr = librosa.load(wav_path, sr=24000)
audio = audio / np.max(np.abs(audio))
audio.dtype = np.float32
import time
start = time.time()
source = preprocess(audio)
keys = []
converted_samples = {}
reconstructed_samples = {}
converted_mels = {}
for key, (ref, _) in reference_embeddings.items():
with paddle.no_grad():
f0_feat = F0_model.get_feature_GAN(source.unsqueeze(1))
out = starganv2.generator(source.unsqueeze(1), ref, F0=f0_feat)
c = out.transpose([0,1,3,2]).squeeze()
y_out = vocoder.inference(c)
y_out = y_out.reshape([-1])
if key not in speaker_dicts or speaker_dicts[key][0] == "":
recon = None
else:
wave, sr = librosa.load(speaker_dicts[key][0], sr=24000)
mel = preprocess(wave)
c = mel.transpose([0,2,1]).squeeze()
recon = vocoder.inference(c)
recon = recon.reshape([-1]).numpy()
converted_samples[key] = y_out.numpy()
reconstructed_samples[key] = recon
converted_mels[key] = out
keys.append(key)
end = time.time()
print('总共花费时间: %.3f sec' % (end - start) )
# print('原始语音 (使用声码器解码):')
wave, sr = librosa.load(wav_path, sr=24000)
mel = preprocess(wave)
c = mel.transpose([0,2,1]).squeeze()
with paddle.no_grad():
recon = vocoder.inference(c)
recon = recon.reshape([-1]).numpy()
# display(ipd.Audio(recon, rate=24000))
print('原始语音:')
display(ipd.Audio(wav_path, rate=24000))
import IPython.display as ipd
for key, wave in converted_samples.items():
print('语音转换结果: %s' % key)
display(ipd.Audio(wave, rate=24000))
# print('参考的说话人 (使用声码器解码): %s' % key)
# if reconstructed_samples[key] is not None:
# display(ipd.Audio(reconstructed_samples[key], rate=24000))
总共花费时间: 8.655 sec
原始语音:
原始语音:



此文章为搬运
原项目链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









