






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
0 项目背景
信息抽取任务旨在从非结构化的自然语言文本中提取结构化信息。在本系列项目中,将讨论如何又好又快地实现一个简历信息提取任务。
作为该系列文章的第三篇,我们将尝试把原始数据集转换为PaddleNLP支持的文本/文档抽取标注格式,为后续的模型微调做好准备。
在前置项目中,我们已经介绍了不同格式简历信息提取的方法,并用PaddleNLP提供的Taskflow API完成了简历基本信息的批量抽取。当然,我们也发现使用的预训练模型在信息抽取时,有不少缺失。
针对上述问题,PaddleNLP为我们提供了基于UIE优秀的小样本微调能力,可以实现低成本模型定制适配。
对应地,我们需要为此准备好符合要求的标注格式并进行训练,这也是本项目试图解决的问题。我们将首先从文本信息抽取任务着手,而文档信息抽取,涉及到ocr识别等内容,情况更为复杂,就等文本信息抽取模型训练和部署完成后,再进行介绍。
0.1 参考资料
1 安装Label Studio
PaddleNLP为我们提供了不同抽取场景的Label Studio标注解决方案,可基于该方案实现从数据标注到训练数据构造的无缝衔接,大大降低了数据标注、模型定制的时间成本。
尽管简历数据集其实已经自带了标注文件,但是我们还是要先看看Label Studio在实体抽取任务中输出的数据格式到底是怎样的,然后才好针对性地进行匹配和调整。
Label Studio的安装需要在本地执行,标注示例用到的环境配置如下:
- Python 3.8+
- label-studio == 1.6.0
- paddleocr >= 2.6.0.1
建议本地使用时,直接conda create一个新环境。安装好之后,在命令行运行label-studio start,在弹出的页面中操作。
首次登陆时要注册下账号和密码,用于区分不同账号管理的标注任务。
我们可以看到,Label Studio目前只支持文本文档或者图片格式,因此无论是word格式的简历还是pdf格式的,都需要进行转换。
在Label Studio中找到实体信息标注的任务,点击进入。
顺便我们也能看到,其实Label Studio功能相当强大,支持的标注任务类型基本涵盖了AI最常用的各个领域。
对于更加具体的操作方法,读者可以参考PaddleNLP的文档说明:文本抽取任务Label Studio使用指南。
这里另外提供一份更加简化的用户经验总结命名实体识别(NER)标注神器——Label Studio 简单使用,帮助大家快速上手标注任务。
注意:PaddleNLP任务中,命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务的标注都要选择
Relation Extraction。
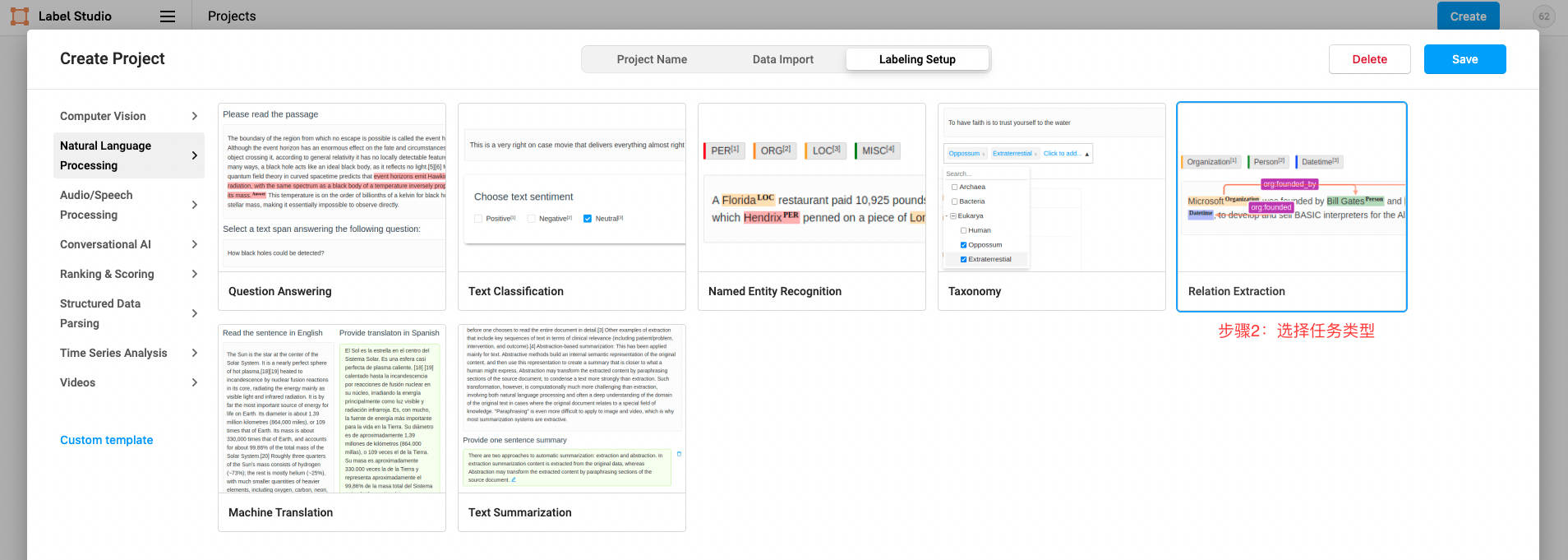
2 环境准备
# 解压缩数据集
!unzip data/data40148/train_20200121.zip
# 拉取PaddleNLP项目程序包
!git clone https://gitee.com/paddlepaddle/PaddleNLP.git
# 安装依赖库
!pip install python-docx
!pip install --upgrade paddlenlp
# 首次更新完以后,重启后方能生效
from docx import Document
from docx.shared import Inches
import datetime
import os
import cv2
import shutil
import numpy as np
import pandas as pd
import re
import json
from tqdm import tqdm
3 准备数据集
由于Label Studio在NER任务中只支持txt文档导入,我们就先将word文档先解析了,需要注意的是,如何准备txt文件,还是要回到Label Studio的工作页面上看。
3.1 Label Studio标注文件分析
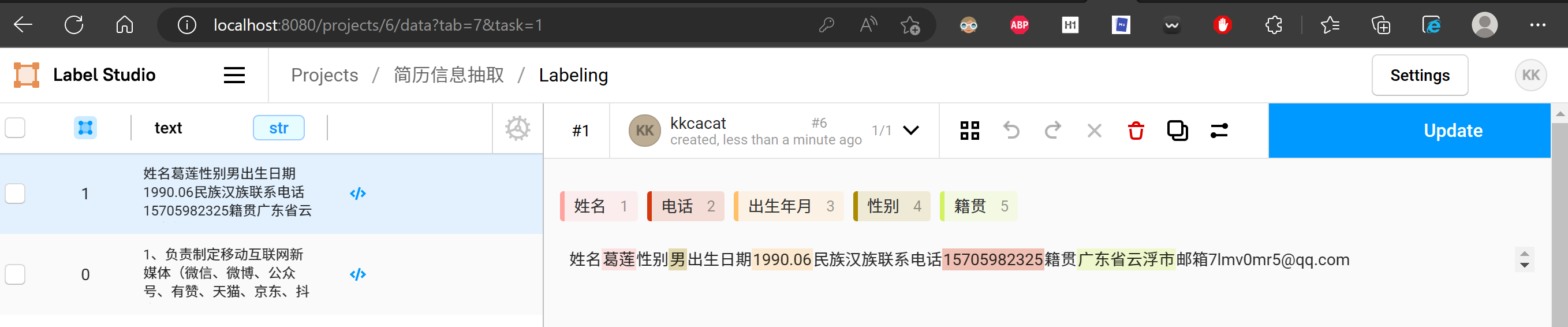
从上面这个应用的使用界面,我们可以发现,Label Studio在处理NER标注时,是逐行读取导入的txt文件,然后逐行标注的。
这个道理看似简单,这意味着,我们可以逐个读取word格式的简历文件,但是一个文件对应到txt中只有一行。解析时,需要严格控制换行符的使用。
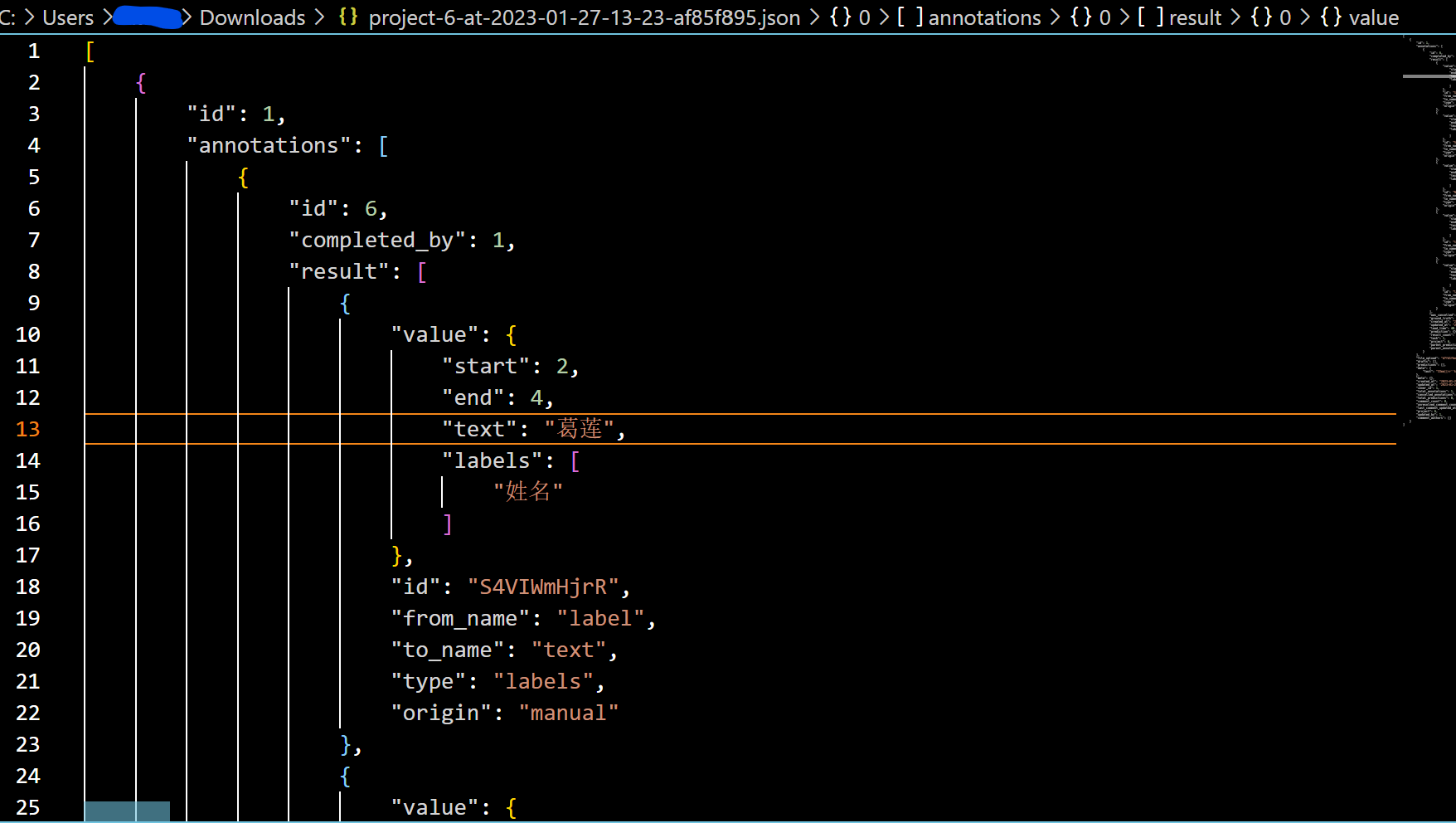
接下来再看下Label Studio标注完成后导出的json文件:
我们会发现,除了一些支持Label Studio功能实现的元数据字段,同时还需要对应保存信息提取内容的起始/终点位置。
总结说来,对于简历文本标注数据的准备,就是几个要点:
- 数据文件要从多文件转换成单txt文件,一行就是一份简历
- 原标注文件和简历文件要同时读取,这样才能匹配文本位置信息
- 数据转换时,一些多余的Label Studio元数据可以删除
如果我们使用PaddleNLP提供的、预先标注好的军事关系抽取数据集的文件,可以更加清晰地理解需要组织好数据集格式。
wget https://bj.bcebos.com/paddlenlp/datasets/military.tar.gz
tar -xvf military.tar.gz
mv military data
rm military.tar.gz
3.2 数据标注文件转换
在该小节中,我们将对简历数据集的原始标注文件进行分析,尝试转换为与Label Studio标注匹配的格式。
# 设置实体抽取信息
schema = ['姓名', '出生年月', '电话', '性别', '项目名称', '项目责任', '项目时间', '籍贯', '政治面貌', '落户市县', '毕业院校', '学位', '毕业时间', '工作时间', '工作内容', '职务', '工作单位']
def get_paragraphs_text(path):
document = Document(path)
# 有的简历是表格式样的,因此,不仅需要提取正文,还要提取表格
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 表格提取中,需要添加一个去重机制
fore_str = ""
cell_text = ""
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
# 避免使用换行符
cell_text += cell.text + ';'
# 提取正文文本
paragraphs_text = ""
for paragraph in document.paragraphs:
# 拼接一个list,包括段落的结构和内容,避免使用换行符
paragraphs_text += paragraph.text + ";"
# 剔除掉返回内容中多余的空格、tab、换行符
cell_text = cell_text.replace('\n', ';').replace(' ', '').replace('\t', '')
paragraphs_text = paragraphs_text.replace('\n', ';').replace(' ', '').replace('\t', '')
return cell_text, paragraphs_text
with open('resume_train_20200121/train_data.json', "r", encoding="utf-8") as f:
raw_examples = json.loads(f.read())
schema_dict = {}
for line in raw_examples:
if line=='020b0120c240':
# 解析简历文本内容
cell_text, paragraphs_text = get_paragraphs_text(os.path.join('resume_train_20200121/docx',line) + '.docx')
text_content = cell_text + paragraphs_text
for item in schema:
if item in raw_examples[line]:
# 找到要抽取的文本内容
schema_dict["text"] = raw_examples[line][item]
# 遍历字符串,找到首个符合匹配的字符位置
schema_dict["start"] = text_content.find(schema_dict["text"])
# 计算文本内容结束位置
schema_dict["end"] = len(schema_dict["text"]) + text_content.find(schema_dict["text"])
# 保存标签信息
schema_dict["labels"] = [item]
if len(raw_examples[line]['项目经历']) > 0:
for i in range(len(raw_examples[line]['项目经历'])):
if item in raw_examples[line]['项目经历'][i]:
schema_dict["text"] = raw_examples[line]['项目经历'][i][item]
schema_dict["start"] = text_content.find(schema_dict["text"])
schema_dict["end"] = len(schema_dict["text"]) + text_content.find(schema_dict["text"])
schema_dict["labels"] = [item]
if len(raw_examples[line]['工作经历']) > 0:
for i in range(len(raw_examples[line]['工作经历'])):
if item in raw_examples[line]['工作经历'][i]:
schema_dict["text"] = raw_examples[line]['工作经历'][i][item]
schema_dict["start"] = text_content.find(schema_dict["text"])
schema_dict["end"] = len(schema_dict["text"]) + text_content.find(schema_dict["text"])
schema_dict["labels"] = [item]
if len(raw_examples[line]['教育经历']) > 0:
for i in range(len(raw_examples[line]['教育经历'])):
if item in raw_examples[line]['教育经历'][i]:
schema_dict["text"] = raw_examples[line]['教育经历'][i][item]
schema_dict["start"] = text_content.find(schema_dict["text"])
schema_dict["end"] = len(schema_dict["text"]) + text_content.find(schema_dict["text"]) - 1
schema_dict["labels"] = [item]
print(schema_dict)
{'text': '凤丹', 'start': 0, 'end': 2, 'labels': ['姓名']}
{'text': '1986.04', 'start': 23, 'end': 30, 'labels': ['出生年月']}
{'text': '13208160239', 'start': 6, 'end': 17, 'labels': ['电话']}
{'text': '13208160239', 'start': 6, 'end': 17, 'labels': ['电话']}
{'text': '深圳市光明新区企业劳资关系情况调查与对策研究', 'start': -1, 'end': 21, 'labels': ['项目名称']}
{'text': '1、根据公司业务状况,提供及时实效的资金数据;2、根据公司财务数据,提供周度、月度、年度资金计划及分析报告、为领导决策提供依据;3、对闲置资金进行理财建议,提高资金高效周转,降低财务成本;4、监控企业负债情况,制定合理转贷计划,提高资金周转率,避免资金短缺,为领导决策提供依据。', 'start': 838, 'end': 977, 'labels': ['项目责任']}
{'text': '1998.11-2017.08', 'start': -1, 'end': 14, 'labels': ['项目时间']}
{'text': '1998.11-2017.08', 'start': -1, 'end': 14, 'labels': ['项目时间']}
{'text': '1998.11-2017.08', 'start': -1, 'end': 14, 'labels': ['项目时间']}
{'text': '北京市', 'start': 34, 'end': 37, 'labels': ['落户市县']}
{'text': '北京理工大学', 'start': -1, 'end': 4, 'labels': ['毕业院校']}
{'text': '硕士学位', 'start': -1, 'end': 2, 'labels': ['学位']}
{'text': '2014.08', 'start': -1, 'end': 5, 'labels': ['毕业时间']}
{'text': '2008/06-2018/11', 'start': -1, 'end': 14, 'labels': ['工作时间']}
{'text': '1、根据年度指标制定部门开发规划,业绩预估及执行、月度/季度完成度追踪;2、负责维系现有批发客户关系,定期与合作客户进行沟通,完成补货及收款,建立良好的长期合作关系,完成批发销售业绩;3、开拓新的潜在客户,拓展品牌分销渠道,建立新客户档案;4、组织统筹买手订货会,完成展销业绩。展会前规划拟定策略、展会后整理采购订单、后期追踪跟单及每季销售整理总结;5、公司品牌活动的策划参与执行。', 'start': 47, 'end': 238, 'labels': ['工作内容']}
{'text': '环卫副主任', 'start': -1, 'end': 4, 'labels': ['职务']}
{'text': '中航锂电科技有限公司', 'start': -1, 'end': 9, 'labels': ['工作单位']}
通过上面的代码,其实我们就成功遍历得到了label_studio.json文件中最关键的value字段信息,当然需要更严谨地涉及逻辑,比如:
- 匹配不到起始位置的标注需要剔除
- 一些标注信息存在重复
if len(raw_examples[line]['教育经历']) > 0这种写法容易报错
接下来要做的工作,就是要把没有完善好的逻辑整理清楚,再把所有数据集准备工作串起来。
3.3 生成数据集
逐一读取word文档,得到的无标注的文本数据文件和转换后的label_studio.json文件。
with open('resume_train_20200121/train_data.json', "r", encoding="utf-8") as f1, open('resume_train_20200121/unlabeled_data.txt', "a", encoding='utf-8') as f2:
raw_examples = json.loads(f1.read())
label_list = []
line_num = 1
for line in tqdm(raw_examples):
result_list = []
# 解析简历文本内容
cell_text, paragraphs_text = get_paragraphs_text(os.path.join('resume_train_20200121/docx',line) + '.docx')
text_content = cell_text + paragraphs_text
# 保存提取的简历内容到无标签数据文件
f2.write(text_content + '\n')
for item in schema:
schema_dict = {}
if item in raw_examples[line] and text_content.find(raw_examples[line][item]) > 0:
# 找到要抽取的文本内容
schema_dict["text"] = raw_examples[line][item]
# 遍历字符串,找到首个符合匹配的字符位置
schema_dict["start"] = text_content.find(raw_examples[line][item])
# 计算文本内容结束位置
schema_dict["end"] = len(raw_examples[line][item]) + text_content.find(raw_examples[line][item])
# 保存标签信息
schema_dict["labels"] = [item]
if '项目经历' in raw_examples[line]:
for i in range(len(raw_examples[line]['项目经历'])):
if item in raw_examples[line]['项目经历'][i] and text_content.find(raw_examples[line]['项目经历'][i][item]) > 0:
schema_dict["text"] = raw_examples[line]['项目经历'][i][item]
schema_dict["start"] = text_content.find(raw_examples[line]['项目经历'][i][item])
schema_dict["end"] = len(raw_examples[line]['项目经历'][i][item]) + text_content.find(raw_examples[line]['项目经历'][i][item])
schema_dict["labels"] = [item]
if '工作经历' in raw_examples[line]:
for i in range(len(raw_examples[line]['工作经历'])):
if item in raw_examples[line]['工作经历'][i] and text_content.find(raw_examples[line]['工作经历'][i][item]) > 0:
schema_dict["text"] = raw_examples[line]['工作经历'][i][item]
schema_dict["start"] = text_content.find(raw_examples[line]['工作经历'][i][item])
schema_dict["end"] = len(raw_examples[line]['工作经历'][i][item]) + text_content.find(raw_examples[line]['工作经历'][i][item]) - 1
schema_dict["labels"] = [item]
if '教育经历' in raw_examples[line]:
for i in range(len(raw_examples[line]['教育经历'])):
if item in raw_examples[line]['教育经历'][i] and text_content.find(raw_examples[line]['教育经历'][i][item]) > 0:
schema_dict["text"] = raw_examples[line]['教育经历'][i][item]
schema_dict["start"] = text_content.find(raw_examples[line]['教育经历'][i][item])
schema_dict["end"] = len(raw_examples[line]['教育经历'][i][item]) + text_content.find(raw_examples[line]['教育经历'][i][item])
schema_dict["labels"] = [item]
if len(schema_dict) > 0:
result_dict = {"value":schema_dict,
"id": "",
"from_name": "label",
"to_name": "text",
"type": "labels",
"origin": "manual"}
result_list.append(result_dict)
line_dict = {"id": line_num,
"annotations":[{"id":line_num,"result":result_list}],
"data": {"text":text_content}
}
label_list.append(line_dict)
line_num += 1
100%|██████████| 2000/2000 [00:44<00:00, 45.39it/s]
抽取一份简历看一下标注文件整理后的内容。
label_list[7]
{'id': 8,
'annotations': [{'id': 8,
'result': [{'value': {'text': '马风',
'start': 13,
'end': 15,
'labels': ['姓名']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '1925.09', 'start': 21, 'end': 28, 'labels': ['出生年月']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '15504235877',
'start': 69,
'end': 80,
'labels': ['电话']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '1、执行公司薪酬绩效政策,核算月度薪资及奖金;2、各类薪酬数据的统计及分析;3、参与各部门绩效指标的制定与优化;4、对接集团供应链中心薪酬绩效组,完成领导交办的其他工作。',
'start': 941,
'end': 1026,
'labels': ['项目责任']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '黑龙江省佳木斯市', 'start': 32, 'end': 40, 'labels': ['籍贯']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '中国共产党预备党员',
'start': 46,
'end': 55,
'labels': ['政治面貌']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '山西省朔州市', 'start': 59, 'end': 65, 'labels': ['落户市县']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'},
{'value': {'text': '1、根据公司价格制度对所负责区域内直销客户进行业务洽谈;2、对负责区域内客户进行定期回访、管理客户关系,完成销售任务;3、核实合同并催收货款及确认款项到账情况;4、了解和发掘客户需求及购买愿望,介绍自己产品的优点和特色,积极适时、合理有效地开发新客户,努力拓展业务渠道,不断扩大公司产品的市场占有率;5、部门及公司领导临时交办的其他工作;6、在贵州和兴义市有一定的人脉资源。',
'start': 333,
'end': 519,
'labels': ['工作内容']},
'id': '',
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'origin': 'manual'}]}],
'data': {'text': '简历;;;个人信息;姓名;马风;出生年月;1925.09;籍贯;黑龙江省佳木斯市;政治面貌;中国共产党预备党员;户籍;山西省朔州市;电话;15504235877;Email;b3m7gqqo@163.com;;个人技能;吃饭喝茶;教育背景;;工作经历;工作内容:;1、负责在公司战略、政策框架下,积极建立高净值客户、机构客户与各类渠道的合作关系,提供专业的金融投资服务与建议,为客户提供适合的私募基金产品组合;2、编制个人的业务发展计划,按照公司要求完成个人的业绩目标;3、根据对客户需求分析和市场变化的判断,及时传达市场较新资讯,对公司的产品和服务及销售政策提出改进建议;4、组织开展各类客户活动;5、积极协助其他同事完成必要的工作及领导交办的工作。;工作内容:;1、根据公司价格制度对所负责区域内直销客户进行业务洽谈;2、对负责区域内客户进行定期回访、管理客户关系,完成销售任务;3、核实合同并催收货款及确认款项到账情况;4、了解和发掘客户需求及购买愿望,介绍自己产品的优点和特色,积极适时、合理有效地开发新客户,努力拓展业务渠道,不断扩大公司产品的市场占有率;5、部门及公司领导临时交办的其他工作;6、在贵州和兴义市有一定的人脉资源。;;项目经验;项目职责:;1、遵守各项管理规定,服从单位管理及领导安排;2、熟练掌握云中医系统、挂号、收银、对账等操作;3、保证每笔账款结算快递、准确、有条不紊;4、下班必须按规定每日交接清单清楚,交接要及时准确,编制《收银员收入明细表》等内部账表;5、为顾客提供良好的服务,回答顾客咨询;6、各种票据和文件的收集、保管和传递。;项目职责:;1、负责编制月度合并管理报表,分析实际数据与预算的差异,协助财务经理完成月度经营分析报告,为管理层提供财务建议和决策支持;2、负责核对编制月度利润简报,分析实际收入与预测偏差原因,跟踪收入执行情况,识别潜在风险,分析原因并及时预警;3、协助编制公司预算,并组织实施;监督预算的执行结果,及时统计决算数据,根据财务分析数据提出合理化建议,完成预算的执行情况分析;4、负责公司日常财务数据分析工作,定期提供各种财务分析报告、经营绩效分析报告,不定期提供财务专项分析报告,提出有效的财务建议。;项目职责:;1、执行公司薪酬绩效政策,核算月度薪资及奖金;2、各类薪酬数据的统计及分析;3、参与各部门绩效指标的制定与优化;4、对接集团供应链中心薪酬绩效组,完成领导交办的其他工作。;;;;'}}
看起来效果相当不错,接下来,我们把这个标注文件保存起来就行了。
json.dump(label_list, open('resume_train_20200121/label_studio.json', mode='w'), ensure_ascii=False, indent=4)
3.4 切分数据集
关于如何进行模型微调,PaddleNLP的文档中提供了详细的说明。读者可以点击进行查阅。
%cd PaddleNLP/applications/information_extraction/text/
/home/aistudio/PaddleNLP/applications/information_extraction/text
在开始训练之前,我们当然要先划分好训练集和验证集。通过label_studio.py脚本可将我们标注的数据集转为UIE的数据格式,需要注意的是,抽取任务要设置--task_type ext参数。
!python ../label_studio.py \
--label_studio_file /home/aistudio/resume_train_20200121/label_studio.json \
--save_dir ./data \
--splits 0.76 0.24 0 \
--negative_ratio 3 \
--task_type ext
[32m[2023-01-27 20:23:39,089] [ INFO][0m - Converting annotation data...[0m
100%|█████████████████████████████████████| 1520/1520 [00:00<00:00, 2918.62it/s]
[32m[2023-01-27 20:23:39,612] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|███████████████████████████████████| 1520/1520 [00:00<00:00, 101573.18it/s]
[32m[2023-01-27 20:23:39,630] [ INFO][0m - Converting annotation data...[0m
100%|███████████████████████████████████████| 480/480 [00:00<00:00, 6851.41it/s]
[32m[2023-01-27 20:23:39,701] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|██████████████████████████████████████| 480/480 [00:00<00:00, 99445.09it/s]
[32m[2023-01-27 20:23:39,707] [ INFO][0m - Converting annotation data...[0m
0it [00:00, ?it/s]
[32m[2023-01-27 20:23:39,707] [ INFO][0m - Adding negative samples for first stage prompt...[0m
0it [00:00, ?it/s]
[32m[2023-01-27 20:23:40,147] [ INFO][0m - Save 25840 examples to ./data/train.txt.[0m
[32m[2023-01-27 20:23:40,284] [ INFO][0m - Save 8160 examples to ./data/dev.txt.[0m
[32m[2023-01-27 20:23:40,284] [ INFO][0m - Save 0 examples to ./data/test.txt.[0m
[32m[2023-01-27 20:23:40,284] [ INFO][0m - Finished! It takes 1.50 seconds[0m
inished! It takes 1.50 seconds[0m
[0m
4 模型训练
本项目中,我们使用Trainer API对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
我们可以看到数据集能够正常训练,这也就意味着,本文千辛万苦转换的标注文件是符合要求的。
!python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 1000 \
--model_name_or_path uie-base \
--output_dir ./checkpoint/model_best \
--train_path data/train.txt \
--dev_path data/dev.txt \
--max_seq_len 512 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
部分训练过程日志如下:
[2023-01-28 08:15:24,828] [ INFO] ***** Running Evaluation *****
[2023-01-28 08:15:24,828] [ INFO] Num examples = 16874
[2023-01-28 08:15:24,828] [ INFO] Total prediction steps = 528
[2023-01-28 08:15:24,828] [ INFO] Pre device batch size = 32
[2023-01-28 08:15:24,828] [ INFO] Total Batch size = 32
[2023-01-28 08:21:57,438] [ INFO] eval_loss: 0.00010252965148538351, eval_precision: 0.9738339021615472, eval_recall: 0.9492653174383144, eval_f1: 0.9613926716271235, eval_runtime: 392.6089, eval_samples_per_second: 42.979, eval_steps_per_second: 1.345, epoch: 12.2526
[2023-01-28 08:21:57,439] [ INFO] Saving model checkpoint to ./checkpoint/model_best/checkpoint-26000
[2023-01-28 08:21:57,441] [ INFO] Configuration saved in ./checkpoint/model_best/checkpoint-26000/config.json
[2023-01-28 08:21:58,741] [ INFO] tokenizer config file saved in ./checkpoint/model_best/checkpoint-26000/tokenizer_config.json
[2023-01-28 08:21:58,741] [ INFO] Special tokens file saved in ./checkpoint/model_best/checkpoint-26000/special_tokens_map.json
[2023-01-28 08:22:01,656] [ INFO] Deleting older checkpoint [checkpoint/model_best/checkpoint-24000] due to args.save_total_limit
在验证集上f1 score很快可以到0.9+,模型收敛效果良好。
由于模型训练时间较长,读者请耐心等待。可以发现,由于一些标注的文本,如:项目责任、工作责任等,长度超过了max_seq_len,训练时触发warning。除了使用默认参数,读者还可用根据实际情况进行调整。
可配置参数说明如下:
device: 训练设备,可选择 ‘cpu’、‘gpu’ 其中的一种;默认为 GPU 训练。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。model_name_or_path:进行 few shot 训练使用的预训练模型。默认为 “uie-x-base”。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。train_path:训练集路径;默认为None。dev_path:开发集路径;默认为None。max_seq_len:文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。learning_rate:训练最大学习率,UIE-X 推荐设置为 1e-5;默认值为3e-5。label_names:训练数据标签label的名称,UIE-X 设置为’start_positions’ ‘end_positions’;默认值为None。do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。export_model_dir:静态图导出地址,默认为None。overwrite_output_dir: 如果True,覆盖输出目录的内容。如果output_dir指向检查点目录,则使用它继续训练。disable_tqdm: 是否使用tqdm进度条。metric_for_best_model:最优模型指标,UIE-X 推荐设置为eval_f1,默认为None。load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints输出目录,默认为None。
5 小结
在本项目中,我们成功将原始简历数据集的标注文件转换为Label Studio的关系抽取格式标注,并通过PaddleNLP提供的转换脚本,将数据集转为UIE的数据格式,从而能够进行文本抽取任务的模型微调训练。
在后续项目中,我们将围绕微调后得到的模型如何评估、部署、应用开展探索,进一步提升简历文本批量抽取导出结果的完整性、准确性。















 7288
7288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









