









★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、项目介绍
设计一个图像分类模型,该模型可以准确地分类道路是否干净或存在垃圾。由于缺乏数据,可以使用预训练模型和数据扩充。
在自行划分的验证集下进行评估:
Accuracy≥90%
Precision≥90%

二、项目路线
- 采用resnet50作为分类网络
- 采用了数据增强的方法来提高准确度
- 采用了迁移学习的方式提高模型精度
三、数据集介绍
该数据集包含干净和肮脏道路的图像。
总共有 237 张图片,所有图片都是从互联网上引导的。任务是创建一个分类模型,该模型可以准确地对道路是否干净或乱扔垃圾进行分类。由于缺乏数据,可以使用预训练模型和数据增强。
这种分类模型可用于开发应用程序,以使用摄像头检测道路的垃圾部分,并向这些区域发送必要的服务。
导航数据集:
– Images:包含所有道路图像的文件夹。
– metadata.csv:将图像名称与类标签映射的 csv 文件
下面分别给出两幅clean和dirty的图片
| clean | dirty |
|---|---|
 |  |
#导包
import paddle
import os
import cv2
import paddle.nn as nn
from paddle.io import Dataset
import pandas as pd
import paddle.vision.transforms as T
import numpy as np
from PIL import Image
from paddle.vision.transforms import ToTensor
#解压文件夹
!unzip data/data191171/archive.zip
自定义数据集,以便使用Model接口
class MyDataset(Dataset):
def __init__(self,path,root='Images/Images',rate = 0.7,mode='train'):
super(MyDataset, self).__init__()
self.root = root
if mode == 'train':
self.data = pd.read_csv(path)
self.data = self.data[:int(len(self.data)*rate)]
self.transforms = T.Compose([
T.RandomResizedCrop((224,224)), # 随机裁剪大小
T.RandomHorizontalFlip(0.5), # 随机水平翻转
# T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
])
else:
self.data = pd.read_csv(path)
self.data = self.data[int(len(self.data)*rate):]
self.transforms = T.Compose([
])
def __getitem__(self, index):
image_path, label = self.data.iloc[index]
img = cv2.imread(os.path.join(self.root,image_path), cv2.IMREAD_COLOR)
img = cv2.resize(img,(224, 224))
img = self.transforms(img)
image = np.array(img,dtype = 'float32')
image = paddle.vision.transforms.to_tensor(image, data_format='CHW').astype('float32')
return image, label
def __len__(self):
return len(self.data)
# 测试定义的数据集
train_dataset = MyDataset(path='metadata.csv',mode='train')
val_dataset = MyDataset(path='metadata.csv',mode='test')
train_dataset.__len__(),val_dataset.__len__()
(165, 72)
四、模型介绍
ResNet
ResNet(Residual Network)是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对随着网络训练加深导致准确度下降的问题,ResNet提出了残差学习方法来减轻训练深层网络的困难。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
残差模块如图1所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
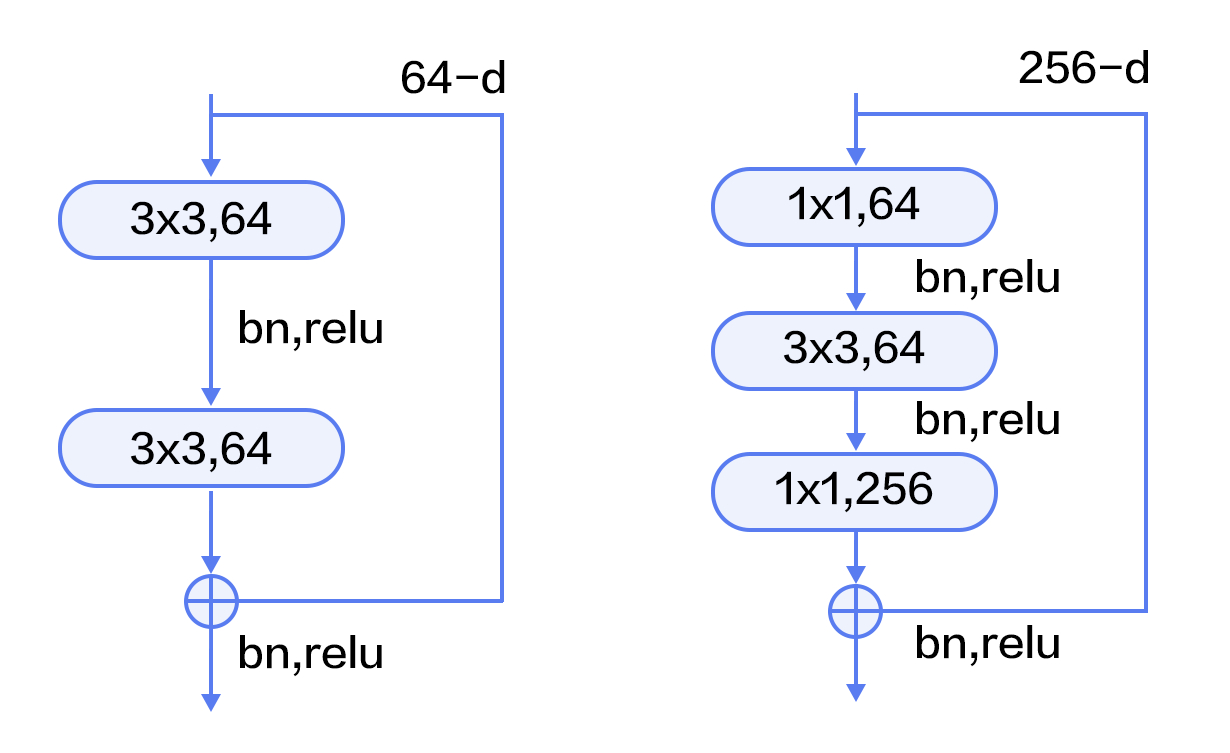
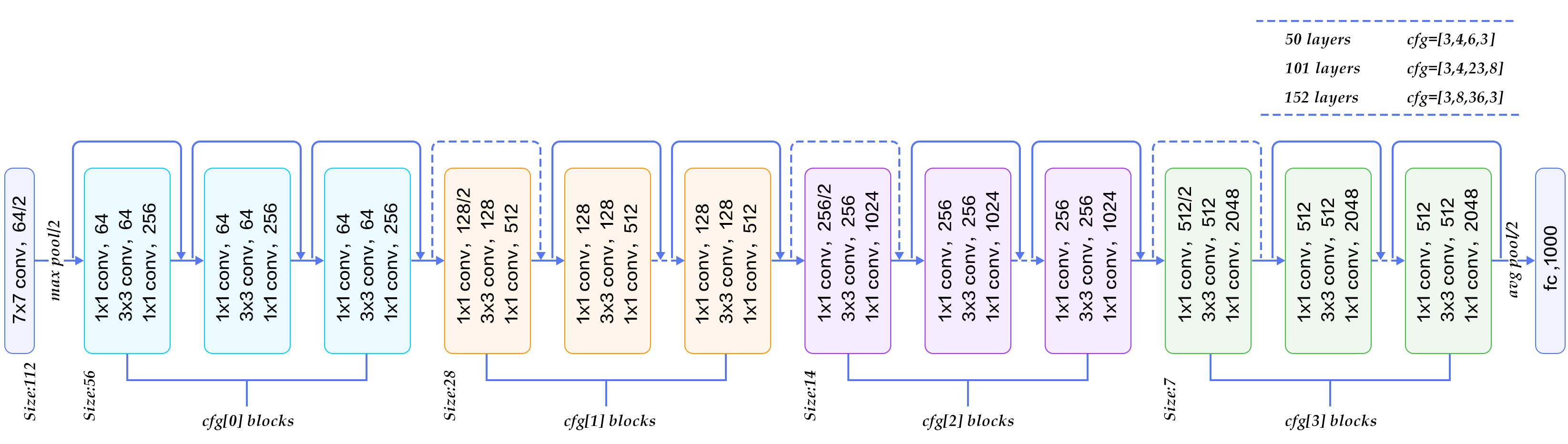
图2展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
#定义BottleneckBlock
class BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BottleneckBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2D
width = int(planes * (base_width / 64.)) * groups
self.conv1 = nn.Conv2D(inplanes, width, 1, bias_attr=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2D(width,
width,
3,
padding=dilation,
stride=stride,
groups=groups,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2D(width,
planes * self.expansion,
1,
bias_attr=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
#搭建resnet50网络
class ResNet(nn.Layer):
def __init__(self,
block=BottleneckBlock,
width=64,
num_classes=1000,
with_pool=True,
groups=1):
super(ResNet, self).__init__()
layers = [3, 4, 6, 3]
self.groups = groups
self.base_width = width
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D
self.inplanes = 64
self.dilation = 1
self.conv1 = nn.Conv2D(3,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias_attr=False)
self.bn1 = self._norm_layer(self.inplanes)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
if with_pool:
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(self.inplanes,
planes * block.expansion,
1,
stride=stride,
bias_attr=False),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.with_pool:
x = self.avgpool(x)
if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
# 下载预训练权重
# !wget https://paddle-hapi.bj.bcebos.com/models/resnet50.pdparams
#加载预训练权重
network = ResNet(num_classes=2)
weight_path = 'resnet50.pdparams'
param = paddle.load(weight_path)
network.set_dict(param)
model = paddle.Model(network)
model.summary((-1, ) + tuple((3,224,224)))
五、模型训练
EPOCHS = 20
BATCH_SIZE = 165
optimizer = paddle.optimizer.Adamax(learning_rate=0.0001, parameters=model.parameters())
# 模型训练配置
model.prepare(optimizer, # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
[paddle.metric.Accuracy()] # 评估指标
)
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
val_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
callbacks=[visualdl] ) # 回调函数使用
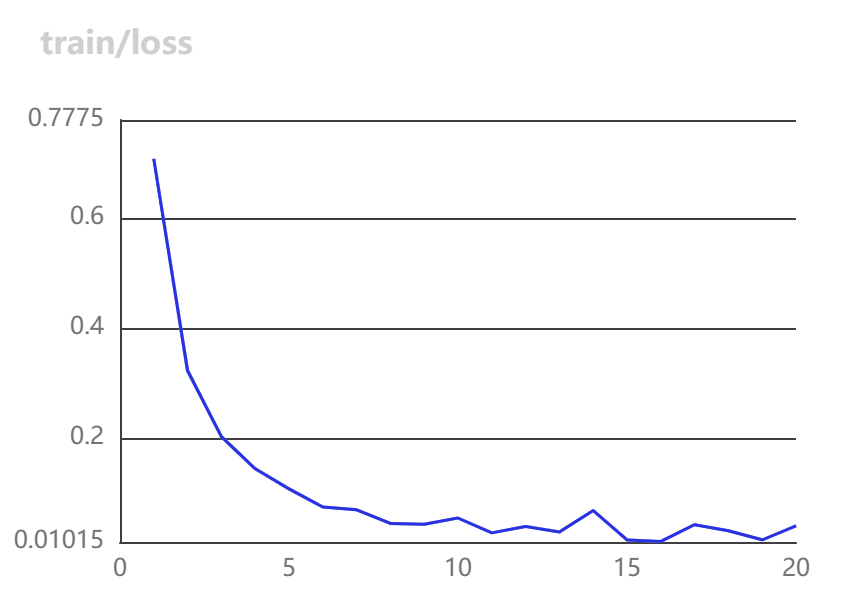
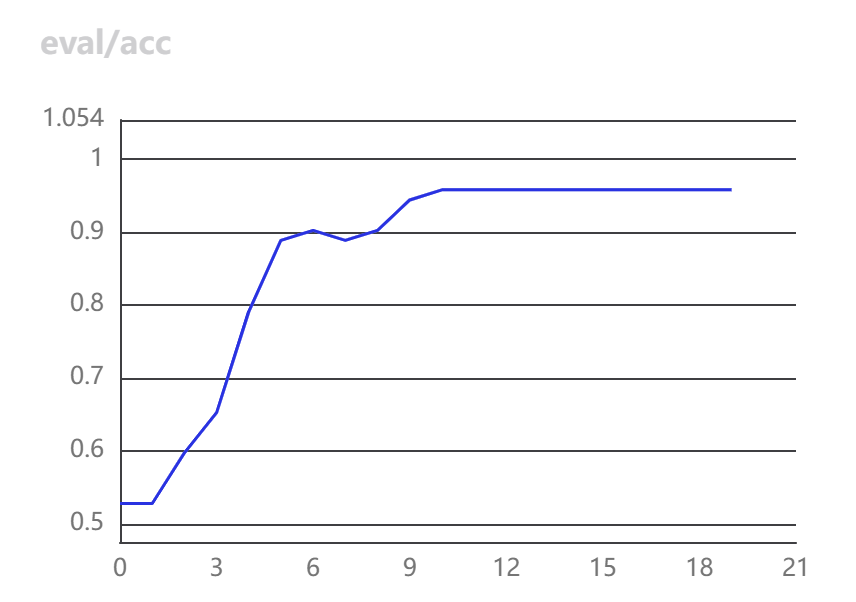
- 训练时损失函数和准确率变换如下:
 |  |
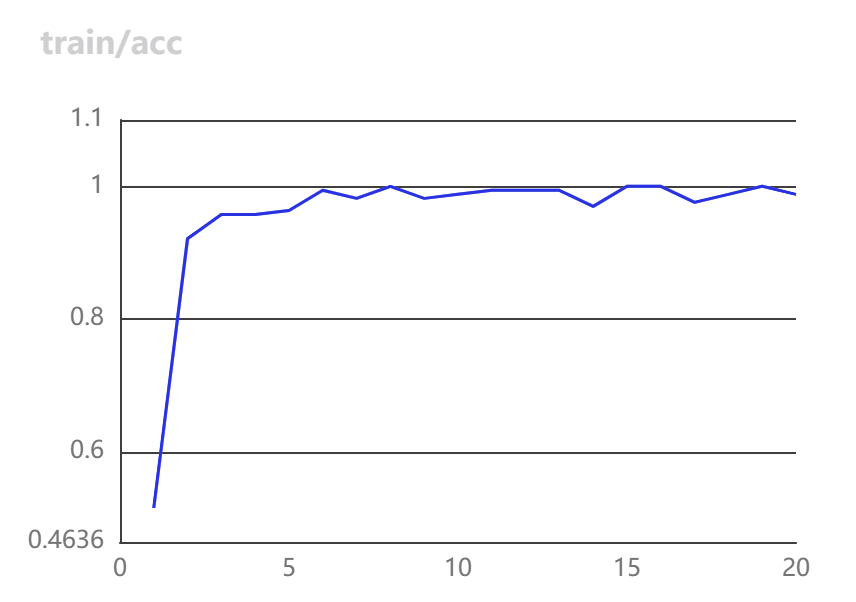 | 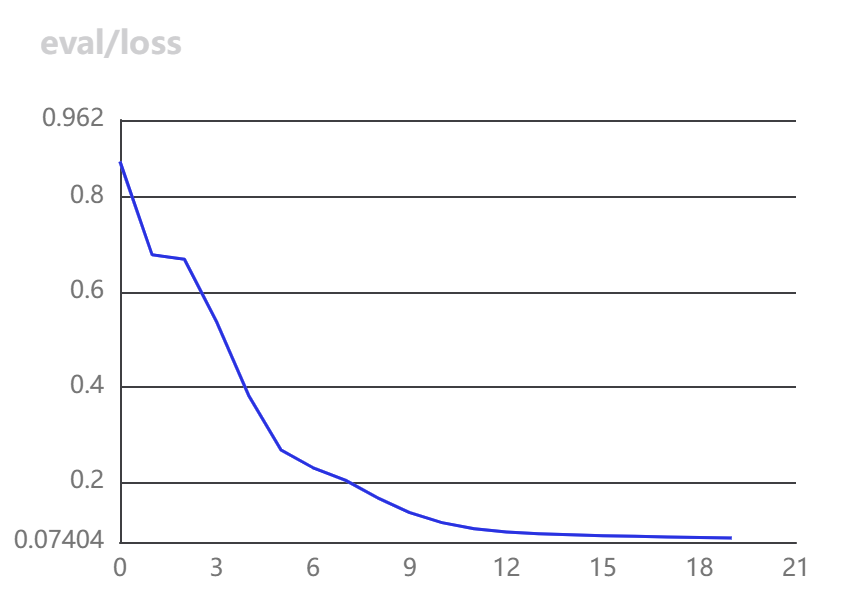 |
#保存模型权重
model.save('model')
六、模型评价
#加载训练好的权重
model.load('model')
#模型评价
model.evaluate(val_dataset, batch_size=72, verbose=1)
Eval begin...
step 1/1 [==============================] - loss: 0.0823 - acc: 0.9583 - 1s/step
Eval samples: 72
{'loss': [0.08226429], 'acc': 0.9583333333333334}
result = model.predict(val_dataset, batch_size=75)
from sklearn.metrics import precision_score,accuracy_score
final = result[0][0][:,1]
final[final>0] = 1
final[final<0] = 0
label = pd.read_csv('metadata.csv')
label = np.array(label[-72:]['label'])
print('测试集上准确率和查准率分别为:',end='')
precision_score(final,label),accuracy_score(final,label)
Predict begin...
step 1/1 [==============================] - 1s/step
Predict samples: 72
es: 72
测试集上准确率和查准率分别为:
(0.972972972972973, 0.9583333333333334)
七、总结
- 1.本项目数据集较小,可以使用迁移学习的方式来提高精度
- 2.可以通过数据增强的方式来扩充数据集来提高精度
- 3.可以使用更加前沿的模型来提高精度
八、作者介绍
作者:姓名:李灿 个人主页
指导老师:姓名:郑博培 个人主页















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









