






★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、面向低资源和增量类型的命名实体识别挑战赛简介
使用无所不能的PaddleNLP写个比赛基线,第一次提交,分数虽然比较低,但是还凑合,主要是给的初赛数据集覆盖范围小,太小了。
竞赛地址:
1.数据简介
本赛题采用的数据聚焦装备领域,主要从以下三个方面的来源收集整理得到,具有一定的权威性和领域价值:
- 开源资讯:对国内外主流新闻网站、百度百科、维基百科、武器大全等开源资讯网站进行数据收集,优先收集中文,并将外文数据进行翻译后获得情报数据;
- 智库报告:从智库网站中获取含有装备情报信息的论文以及报告;
- 内部成果:通过国内军工企业、研究院所、国内综合图书馆、数字图书馆、军工院所图书馆等内部网站获取成果相关的文件进行分析和整理。
本赛题从上述来源收集到充足原始无标注数据后,先结合人工排查和关键字匹配等自动化方法过滤偏离主题、不真实和有偏见的数据;随后清洗无效和非法字符并过滤篇幅较长以及不含领域实体的文本;其次采用参考权威装备标准与论著制定的标签体系对文本进行标注,并采用相关领域以往研究成果中的模型对数据进行预打标;最终统计筛选出类型分布符合任务需求的样本作为原始数据集。
2.数据说明
• 初赛数据说明
该赛题数据集共计约6000条样本,包含以下9种实体类型:飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备。参考低资源学习领域的任务设置,为每种类型从原始数据集中采样50个左右样本案例,形成共97条标注样本的训练集(每一条样本可能包含多个实体和实体类型),其余样本均用于测试集。所有数据文件编码均为UTF-8。
| 文件类型 | 文件名 | 文件说明 |
|---|---|---|
| 训练集 | ner_train.json | 97条已标注样本,每个样本对应内容为:样本id(sample_id),原始文本(text)和标注实体列表(annotations),列表中每个元素对应一个实体,包括类型(type)、文本(text)、跨度起始位置(start)和结束位置(end) |
| 测试集 | ner_test.json | 5920条未标注样本,每个样本对应内容为:样本id(sample_id)和原始文本(text) |
二、数据处理
1.数据查看
!ls data/data218296/
ner_test.json ner_train.json
import json
import csv
from pprint import pprint
# 读取 JSON 文件
with open('data/data218296/ner_train.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(f"数据集长度:{len(data)}")
print("查看数据样例:")
pprint(data[0])
数据集长度:97
查看数据样例:
{'annotations': [{'end': 117,
'sample_id': 0,
'start': 110,
'text': '宇宙神-5火箭',
'type': '太空装备'},
{'end': 148,
'sample_id': 0,
'start': 140,
'text': '宇宙神-5型火箭',
'type': '太空装备'},
{'end': 258,
'sample_id': 0,
'start': 254,
'text': '火神火箭',
'type': '太空装备'},
{'end': 284,
'sample_id': 0,
'start': 277,
'text': '德尔它-4火箭',
'type': '太空装备'}],
'sample_id': 0,
'text': '近日,据美国联合发射联盟公司宣布,该公司推出了一个网址为www.RocketBuilder.com的新网站。据称,11月30日上线的火箭制造者网站,将根据用户提供的目标轨道、载荷质量、整流罩尺寸、发射日期等参数,估算使用宇宙神-5火箭执行发射任务的价格。为保持商业发射市场竞争力,宇宙神-5型火箭的发射价格从2015年的1.84亿美元降至1.09亿美元,这一价格仅针对商业用户。而针对政府用户,因需提供额外的任务保障服务,报价需增加3000万~8000万美元。该网站仅接受商业任务预定,预计2017年底将增加火神火箭的发射报价,而不提供仅为政府用户服务的德尔它-4火箭的报价。据报道,联合发射联盟公司还打算为政府和军队用户提供一个类似的报价网站。截止目前,该公司已经成功完成113次火箭发射任务,且成功率为100%。'}
- 查看可知,需要提取9种实体类型:飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备
- 目前训练集97条标注样本
2.数据集格式转换&& 数据集划分
主要是:
- 转换格式
一般使用docano进行数据标注,完毕进行格式转换。这里我直接处理文件格式为我所需要的二个是。 - 分割训练集和测试机
按照 8:2比例进行数据切分
%cd ~
import json
# 读取 JSON 文件
with open('data/data218296/ner_train.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# schema
key_words = "飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备".split(", ")
# 数据集格式转换
# 并根据8:2比例分割为train和dev
def convert(source_data, key_word):
convert_target = []
for item in source_data:
# 单条记录
result_list = []
# 标注格式化
for item2 in item["annotations"]:
result_temp = dict()
if item2['type'] == key_word:
# 构造结果列表
result_temp['text'] = item2['text']
result_temp['start'] = item2['start']
result_temp['end'] = item2['end']
result_list.append(result_temp)
# 构造单条数据
temp = dict()
temp['content'] = item['text']
temp['result_list'] = result_list
temp['prompt'] = key_word
# 加入列表
convert_target.append(temp)
return convert_target
# 转换后总列表
train_data = []
dev_data = []
for key_word in key_words:
temp_list = convert(data, key_word)
len_split = int(len(temp_list) * 0.8)
train_data = train_data + temp_list[:len_split]
dev_data = dev_data + temp_list[len_split:]
# 将JSON数据转换为CSV格式
with open('train.txt', 'w', encoding="utf-8") as f:
for item in train_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
with open('dev.txt', 'w', encoding="utf-8") as f:
for item in dev_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
/home/aistudio
三、训练训练
1.环境设置
主要是下载并安装PaddleNLP
# git 下载PaddleNLP
!git clone https://gitee.com/paddlepaddle/PaddleNLP.git --depth=1
正克隆到 'PaddleNLP'...
remote: Enumerating objects: 5825, done.[K
remote: Counting objects: 100% (5825/5825), done.[K
remote: Compressing objects: 100% (4099/4099), done.[K
remote: Total 5825 (delta 2254), reused 3581 (delta 1437), pack-reused 0[K
接收对象中: 100% (5825/5825), 22.98 MiB | 1.19 MiB/s, 完成.
处理 delta 中: 100% (2254/2254), 完成.
检查连接... 完成。
# 安装升级PaddleNLP
%cd ~/PaddleNLP
!pip install -U -e ./
2.模型微调
推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
可配置参数说明:
model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 “uie-base”、 “uie-medium”, “uie-mini”, “uie-micro”, “uie-nano”, “uie-m-base”, “uie-m-large”。multilingual:是否是跨语言模型,用 “uie-m-base”, “uie-m-large” 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。device: 训练设备,可选择 ‘cpu’、‘gpu’ 、'npu’其中的一种;默认为 GPU 训练。per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估。
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
%cd ~/PaddleNLP/model_zoo/uie/
!python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 42 \
--model_name_or_path uie-base \
--output_dir ./checkpoint/model_best \
--train_path ~/train.txt \
--dev_path ~/dev.txt \
--max_seq_length 512 \
--per_device_eval_batch_size 16 \
--per_device_train_batch_size 32 \
--num_train_epochs 100 \
--learning_rate 1e-5 \
--label_names "start_positions" "end_positions" \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
部分训练日志
[2023-05-20 19:59:46,745] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-2100/config.json
[2023-05-20 19:59:48,050] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-2100/tokenizer_config.json
[2023-05-20 19:59:48,051] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-2100/special_tokens_map.json
[2023-05-20 19:59:50,634] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-2000] due to args.save_total_limit
[2023-05-20 20:00:00,069] [ INFO] - loss: 8.789e-05, learning_rate: 1e-05, global_step: 2110, interval_runtime: 17.824, interval_samples_per_second: 17.953, interval_steps_per_second: 0.561, epoch: 95.9091
[2023-05-20 20:00:10,666] [ INFO] - loss: 8.035e-05, learning_rate: 1e-05, global_step: 2120, interval_runtime: 10.5965, interval_samples_per_second: 30.199, interval_steps_per_second: 0.944, epoch: 96.3636
[2023-05-20 20:00:19,844] [ INFO] - loss: 0.00018339, learning_rate: 1e-05, global_step: 2130, interval_runtime: 9.1781, interval_samples_per_second: 34.866, interval_steps_per_second: 1.09, epoch: 96.8182
[2023-05-20 20:00:30,380] [ INFO] - loss: 0.00016458, learning_rate: 1e-05, global_step: 2140, interval_runtime: 10.5355, interval_samples_per_second: 30.374, interval_steps_per_second: 0.949, epoch: 97.2727
[2023-05-20 20:00:39,596] [ INFO] - loss: 7.949e-05, learning_rate: 1e-05, global_step: 2150, interval_runtime: 9.216, interval_samples_per_second: 34.722, interval_steps_per_second: 1.085, epoch: 97.7273
[2023-05-20 20:00:50,418] [ INFO] - loss: 3.194e-05, learning_rate: 1e-05, global_step: 2160, interval_runtime: 10.8225, interval_samples_per_second: 29.568, interval_steps_per_second: 0.924, epoch: 98.1818
[2023-05-20 20:00:59,611] [ INFO] - loss: 4.646e-05, learning_rate: 1e-05, global_step: 2170, interval_runtime: 9.193, interval_samples_per_second: 34.809, interval_steps_per_second: 1.088, epoch: 98.6364
[2023-05-20 20:01:10,505] [ INFO] - loss: 8.13e-06, learning_rate: 1e-05, global_step: 2180, interval_runtime: 10.8938, interval_samples_per_second: 29.374, interval_steps_per_second: 0.918, epoch: 99.0909
[2023-05-20 20:01:19,716] [ INFO] - loss: 2.278e-05, learning_rate: 1e-05, global_step: 2190, interval_runtime: 9.2108, interval_samples_per_second: 34.742, interval_steps_per_second: 1.086, epoch: 99.5455
[2023-05-20 20:01:28,519] [ INFO] - loss: 4.91e-06, learning_rate: 1e-05, global_step: 2200, interval_runtime: 8.8031, interval_samples_per_second: 36.351, interval_steps_per_second: 1.136, epoch: 100.0
[2023-05-20 20:01:28,519] [ INFO] - ***** Running Evaluation *****
[2023-05-20 20:01:28,519] [ INFO] - Num examples = 180
[2023-05-20 20:01:28,519] [ INFO] - Total prediction steps = 12
[2023-05-20 20:01:28,519] [ INFO] - Pre device batch size = 16
[2023-05-20 20:01:28,519] [ INFO] - Total Batch size = 16
[2023-05-20 20:01:32,844] [ INFO] - eval_loss: 0.005472011864185333, eval_precision: 0.5806451612903226, eval_recall: 0.2857142857142857, eval_f1: 0.3829787234042553, eval_runtime: 4.2858, eval_samples_per_second: 41.999, eval_steps_per_second: 2.8, epoch: 100.0
[2023-05-20 20:01:32,844] [ INFO] - Saving model checkpoint to ./checkpoint/model_best/checkpoint-2200
[2023-05-20 20:01:32,850] [ INFO] - Configuration saved in ./checkpoint/model_best/checkpoint-2200/config.json
[2023-05-20 20:01:56,132] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/checkpoint-2200/tokenizer_config.json
[2023-05-20 20:01:56,133] [ INFO] - Special tokens file saved in ./checkpoint/model_best/checkpoint-2200/special_tokens_map.json
[2023-05-20 20:02:36,638] [ INFO] - Deleting older checkpoint [checkpoint/model_best/checkpoint-2100] due to args.save_total_limit
[2023-05-20 20:02:36,830] [ INFO] -
Training completed.
[2023-05-20 20:02:36,830] [ INFO] - Loading best model from ./checkpoint/model_best/checkpoint-700 (score: 0.4242424242424242).
[2023-05-20 20:02:37,655] [ INFO] - train_runtime: 2395.941, train_samples_per_second: 28.924, train_steps_per_second: 0.918, train_loss: 0.000252399416314223, epoch: 100.0
[2023-05-20 20:02:37,687] [ INFO] - Saving model checkpoint to ./checkpoint/model_best
[2023-05-20 20:02:37,877] [ INFO] - Configuration saved in ./checkpoint/model_best/config.json
[2023-05-20 20:02:47,142] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/tokenizer_config.json
[2023-05-20 20:02:47,143] [ INFO] - Special tokens file saved in ./checkpoint/model_best/special_tokens_map.json
[2023-05-20 20:02:47,144] [ INFO] - ***** train metrics *****
[2023-05-20 20:02:47,144] [ INFO] - epoch = 100.0
[2023-05-20 20:02:47,144] [ INFO] - train_loss = 0.0003
[2023-05-20 20:02:47,144] [ INFO] - train_runtime = 0:39:55.94
[2023-05-20 20:02:47,144] [ INFO] - train_samples_per_second = 28.924
[2023-05-20 20:02:47,144] [ INFO] - train_steps_per_second = 0.918
[2023-05-20 20:02:47,155] [ INFO] - ***** Running Evaluation *****
[2023-05-20 20:02:47,155] [ INFO] - Num examples = 180
[2023-05-20 20:02:47,155] [ INFO] - Total prediction steps = 12
[2023-05-20 20:02:47,155] [ INFO] - Pre device batch size = 16
[2023-05-20 20:02:47,155] [ INFO] - Total Batch size = 16
[2023-05-20 20:02:51,340] [ INFO] - eval_loss: 0.004970937501639128, eval_precision: 0.5833333333333334, eval_recall: 0.3333333333333333, eval_f1: 0.4242424242424242, eval_runtime: 4.1849, eval_samples_per_second: 43.012, eval_steps_per_second: 2.867, epoch: 100.0
[2023-05-20 20:02:51,340] [ INFO] - ***** eval metrics *****
[2023-05-20 20:02:51,341] [ INFO] - epoch = 100.0
[2023-05-20 20:02:51,341] [ INFO] - eval_f1 = 0.4242
[2023-05-20 20:02:51,341] [ INFO] - eval_loss = 0.005
[2023-05-20 20:02:51,341] [ INFO] - eval_precision = 0.5833
[2023-05-20 20:02:51,341] [ INFO] - eval_recall = 0.3333
[2023-05-20 20:02:51,341] [ INFO] - eval_runtime = 0:00:04.18
[2023-05-20 20:02:51,341] [ INFO] - eval_samples_per_second = 43.012
[2023-05-20 20:02:51,341] [ INFO] - eval_steps_per_second = 2.867
[2023-05-20 20:02:51,343] [ INFO] - Exporting inference model to ./checkpoint/model_best/model
[2023-05-20 20:03:08,719] [ INFO] - Inference model exported.
[2023-05-20 20:03:08,720] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/tokenizer_config.json
[2023-05-20 20:03:08,720] [ INFO] - Special tokens file saved in ./checkpoint/model_best/special_tokens_map.json
四、模型评估
1.评估模型
可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。multilingual: 是否是跨语言模型,默认关闭。schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。
通过运行以下命令进行模型评估:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ~/dev.txt \
--batch_size 16 \
--max_seq_len 512
[32m[2023-05-20 20:32:36,774] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.[0m
[32m[2023-05-20 20:32:36,804] [ INFO][0m - loading configuration file ./checkpoint/model_best/config.json[0m
[32m[2023-05-20 20:32:36,806] [ INFO][0m - Model config ErnieConfig {
"architectures": [
"UIE"
],
"attention_probs_dropout_prob": 0.1,
"dtype": "float32",
"enable_recompute": false,
"fuse": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 2048,
"model_type": "ernie",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"paddlenlp_version": null,
"pool_act": "tanh",
"task_id": 0,
"task_type_vocab_size": 3,
"type_vocab_size": 4,
"use_task_id": true,
"vocab_size": 40000
}
[0m
W0520 20:32:39.414932 26536 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0520 20:32:39.419473 26536 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2023-05-20 20:32:40,342] [ INFO][0m - All model checkpoint weights were used when initializing UIE.
[0m
[32m[2023-05-20 20:32:40,342] [ INFO][0m - All the weights of UIE were initialized from the model checkpoint at ./checkpoint/model_best.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training.[0m
[32m[2023-05-20 20:32:44,914] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:32:44,914] [ INFO][0m - Class Name: all_classes[0m
[32m[2023-05-20 20:32:44,914] [ INFO][0m - Evaluation Precision: 0.58333 | Recall: 0.33333 | F1: 0.42424[0m
[0m
2.debug模式评估模型
可开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ~/dev.txt \
--debug
[32m[2023-05-20 20:33:10,580] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.[0m
[32m[2023-05-20 20:33:10,607] [ INFO][0m - loading configuration file ./checkpoint/model_best/config.json[0m
[32m[2023-05-20 20:33:10,608] [ INFO][0m - Model config ErnieConfig {
"architectures": [
"UIE"
],
"attention_probs_dropout_prob": 0.1,
"dtype": "float32",
"enable_recompute": false,
"fuse": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 2048,
"model_type": "ernie",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"paddlenlp_version": null,
"pool_act": "tanh",
"task_id": 0,
"task_type_vocab_size": 3,
"type_vocab_size": 4,
"use_task_id": true,
"vocab_size": 40000
}
[0m
W0520 20:33:12.984724 26703 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0520 20:33:12.989074 26703 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2023-05-20 20:33:13,874] [ INFO][0m - All model checkpoint weights were used when initializing UIE.
[0m
[32m[2023-05-20 20:33:13,875] [ INFO][0m - All the weights of UIE were initialized from the model checkpoint at ./checkpoint/model_best.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training.[0m
[32m[2023-05-20 20:33:14,746] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:14,746] [ INFO][0m - Class Name: 单兵武器[0m
[32m[2023-05-20 20:33:14,746] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000[0m
[32m[2023-05-20 20:33:14,948] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:14,948] [ INFO][0m - Class Name: 炸弹[0m
[32m[2023-05-20 20:33:14,949] [ INFO][0m - Evaluation Precision: 0.76190 | Recall: 0.66667 | F1: 0.71111[0m
[32m[2023-05-20 20:33:15,002] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:15,002] [ INFO][0m - Class Name: 装甲车辆[0m
[32m[2023-05-20 20:33:15,002] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667[0m
[32m[2023-05-20 20:33:15,074] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:15,074] [ INFO][0m - Class Name: 火炮[0m
[32m[2023-05-20 20:33:15,074] [ INFO][0m - Evaluation Precision: 0.50000 | Recall: 0.16667 | F1: 0.25000[0m
[32m[2023-05-20 20:33:15,103] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:15,103] [ INFO][0m - Class Name: 太空装备[0m
[32m[2023-05-20 20:33:15,103] [ INFO][0m - Evaluation Precision: 0.00000 | Recall: 0.00000 | F1: 0.00000[0m
[32m[2023-05-20 20:33:15,292] [ INFO][0m - -----------------------------[0m
[32m[2023-05-20 20:33:15,292] [ INFO][0m - Class Name: 其他武器装备[0m
[32m[2023-05-20 20:33:15,292] [ INFO][0m - Evaluation Precision: 0.33333 | Recall: 0.03571 | F1: 0.06452[0m
[0m
五、预测
1.读取test数据集
%cd ~/PaddleNLP/model_zoo/uie/
import json
import csv
from pprint import pprint
# 读取 JSON 文件
with open('/home/aistudio/data/data218296/ner_test.json', 'r', encoding='utf-8') as f:
test_data = json.load(f)
print(f"数据集长度:{len(test_data)}")
print("查看数据样例:")
pprint(test_data[0])
/home/aistudio/PaddleNLP/model_zoo/uie
数据集长度:5920
查看数据样例:
{'sample_id': 0,
'text': '第五艘西班牙海军F-100级护卫舰即将装备集成通信控制系统。该系统由葡萄牙EID公司生产。该系统已经用于巴西海军的圣保罗航母,荷兰海军的四艘荷兰级海上巡逻舰和四艘西班牙海军BAM近海巡逻舰。F-105护卫舰于2009年初铺设龙骨。该舰预计2010年建造完成,2012年夏交付。'}
2.设定抽取目标 && 定制化模型权重路径
from pprint import pprint
from paddlenlp import Taskflow
schema = "飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备".split(", ")
# 设定抽取目标和定制化模型权重路径
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
[2023-05-21 00:11:31,237] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
3.预测
results=[]
for i in range(len(test_data)):
uie_result=my_ie(test_data[i]['text'])
# pprint(uie_result)
for key, item in uie_result[0].items():
for ii in range(len(item)):
temp_result=dict()
temp_result['sample_id']=test_data[i]['sample_id']
temp_result['text']=item[ii]['text']
temp_result['type']=key
temp_result['start']=item[ii]['start']
temp_result['end']=item[ii]['end']
results.append(temp_result)
print(len(results))
31775
temp_result['end']=item[ii]['end']
results.append(temp_result)
```python
print(len(results))
31775
4.保存结果
with open('result.json','w', encoding="utf-8") as f:
json.dump(results, f,indent=4, ensure_ascii=False)
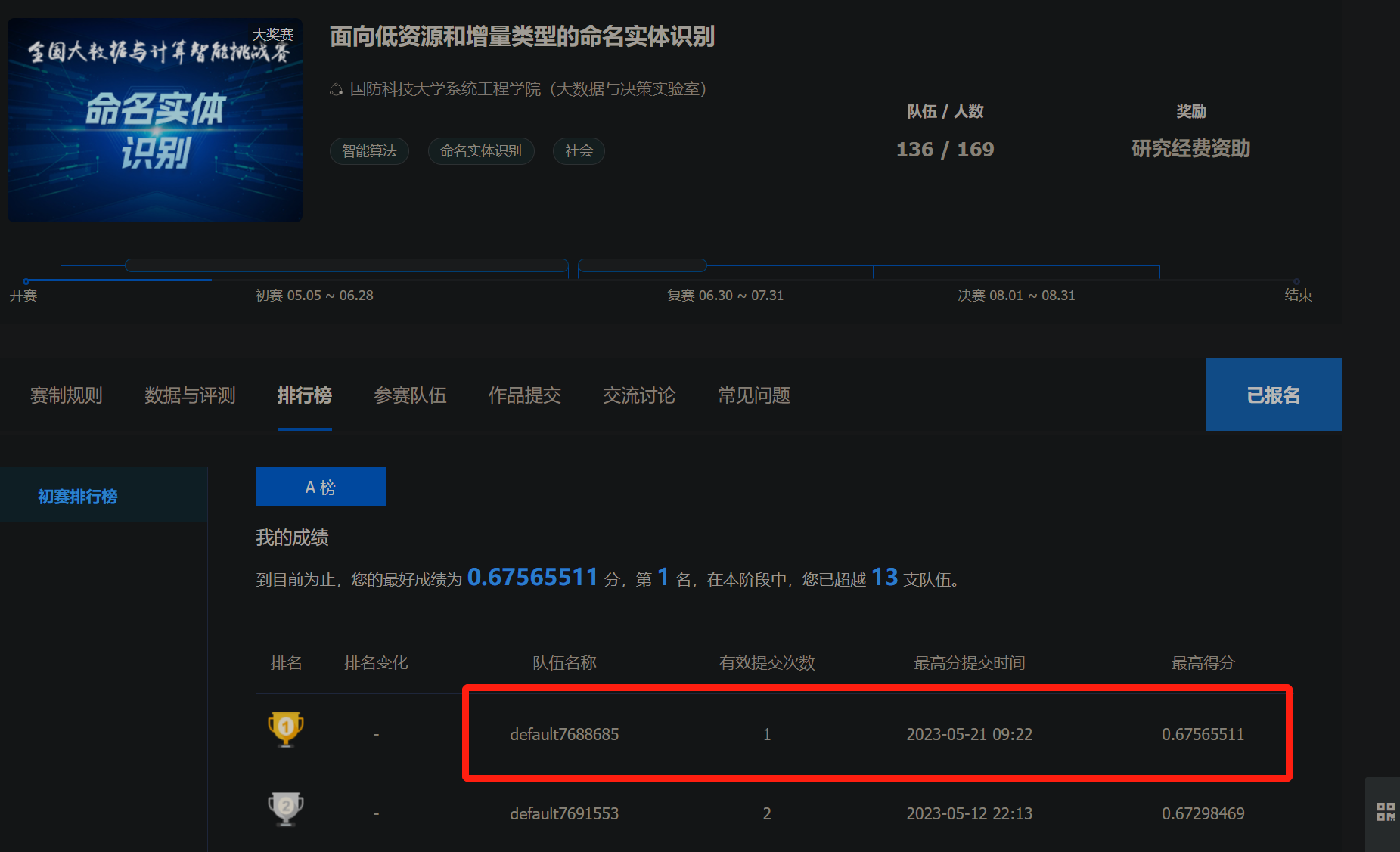
六、提交
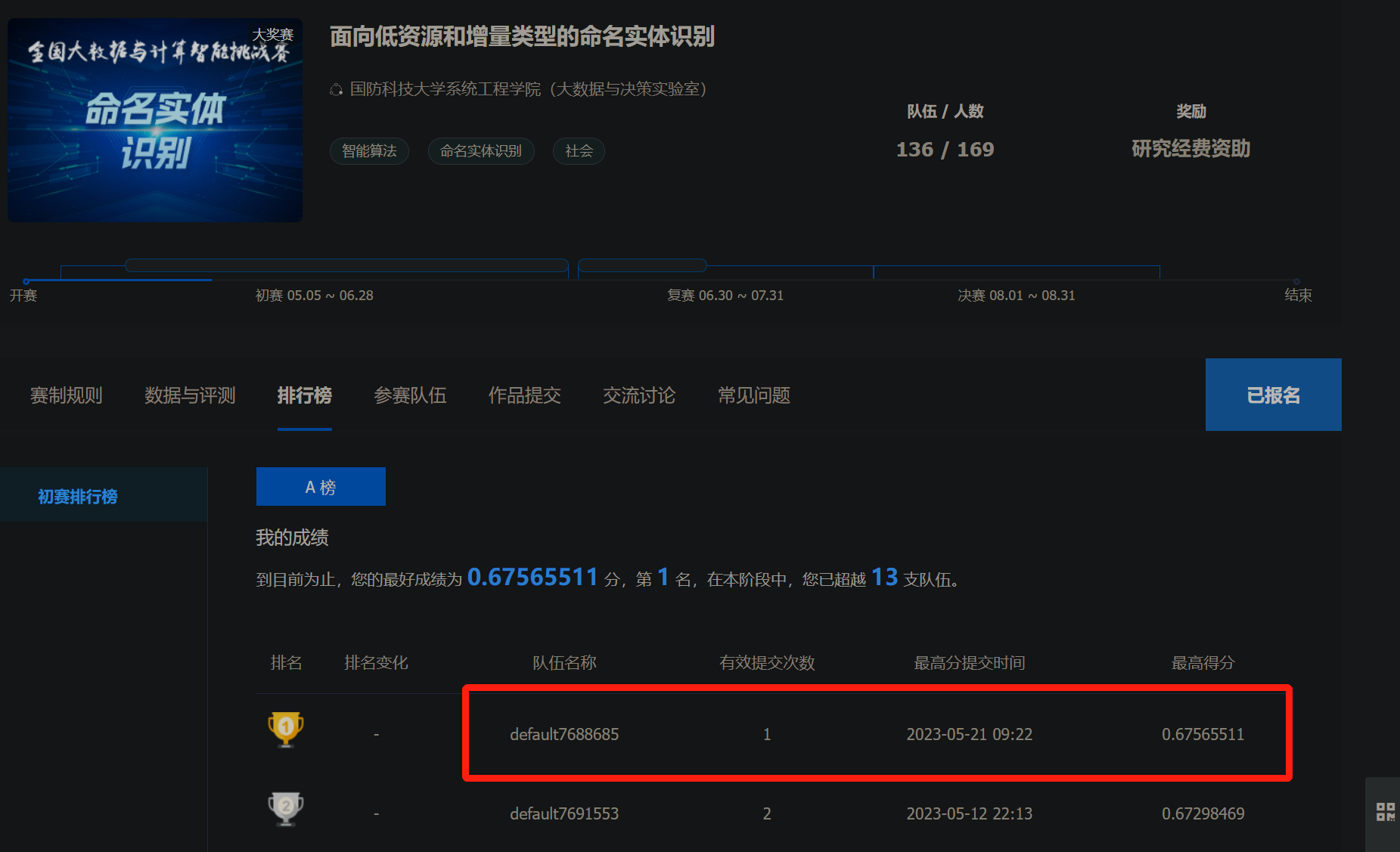
此文章为搬运
原项目链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









