







1. 1欢迎
1.2 机器学习是什么
参考视频: 1 - 2 - What is Machine Learning_ (7 min).mkv
1.2.1 机器学习定义
• Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed. 机器学习:在进行特定编程的情况下,给予计算机学习能力的领域。
• Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. 卡内基梅隆大学Tom 定义:一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P, 当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
例题,以垃圾邮件监测为例,解释Tom 定义中字母的对应:
1.2.2 机器学习算法
1、常用:
Supervised Learning 监督学习:学习数据带有标签
Unsupervised Learning 无监督学习:没有任何的标签,或者有相同的标签。已知数据集,不知如何处理,也未告知每个数据点是什么。
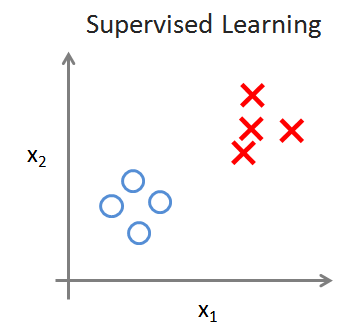
(右侧的例子,无监督学习将数据划分为两个集合,也就是聚类clustering algorithm)
2、其他:
Reinforcement learning 强化学习, recommender systems 推荐系统
1.2.3 课程目的
If you actually tried to develop a machine learning system, how to make those best practices type decisions about the way in which you build your system. 如何在构建机器学习系统的时候选择最好的实践类型决策,节省时间。
1.3 监督学习
参考视频: 1- 3- Supervised Learning (12 min).mkv
1.3.1 Regression回归问题:预测结果是连续的输出值
在历史房价数据的基础上,预测房屋价格。可以使用直线拟合(粉色),也可以使用二次曲线拟合(蓝色)。
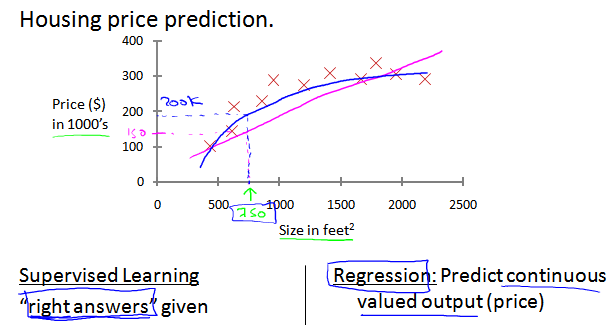
监督学习:基于已有的正确结果。 回归问题:预测连续的输出值
1.3.2 Classification分类问题:预测结果是离散的多个值
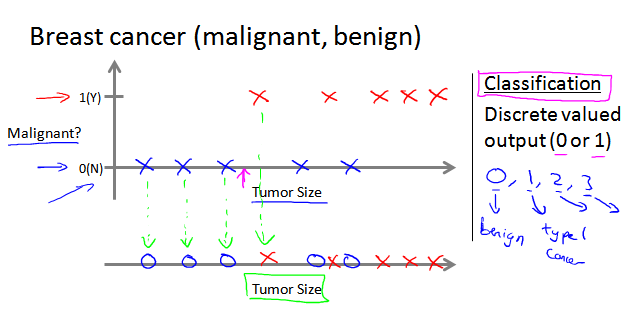
下图是基于两个特征(两个维度)进行预测的例子, 右边是其他可能维度(维度可能有无穷多个)
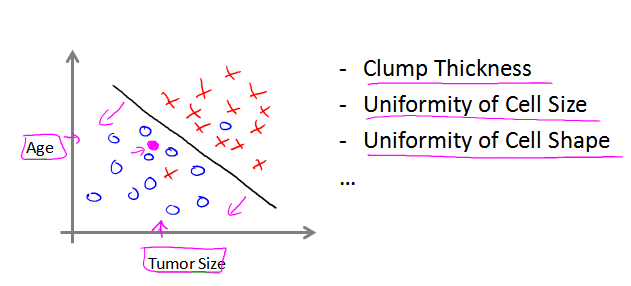
1.3.3 区分 “分类问题”和“回归问题”
例题:
1.4 无监督学习
参考视频: 1 - 4 - Unsupervised Learning (14 min).mkv
1.4.1 聚类算法clustering algorithm 在现实生活中的应用
1、Google News 每天将爬来的网址分为一个个的新闻专题。
2、基因信息分组。
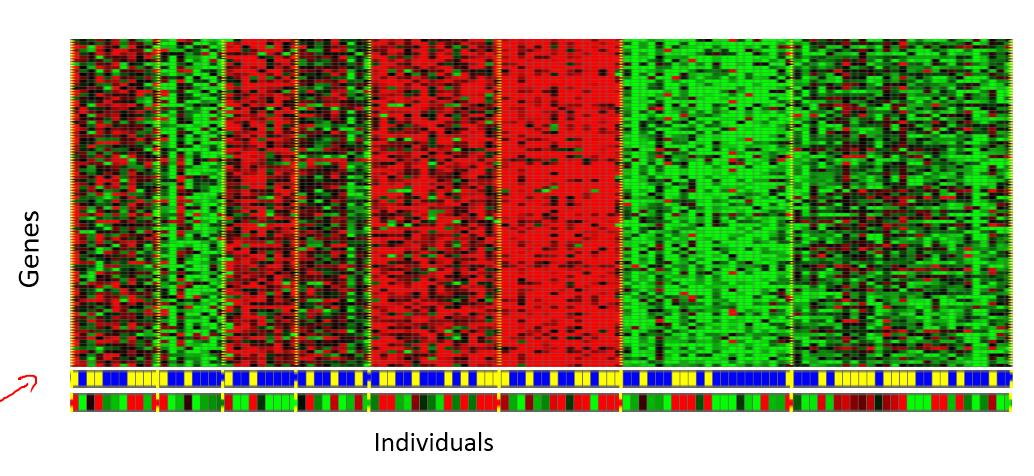
3、组织大型计算机集群。 社交网络的分析。市场分割。天文数据分析

4、鸡尾酒party问题,将混在一起的多个音频源拆开。
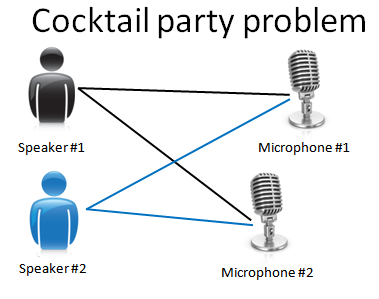
通过这个例子,特别强调了Octave和MATLAB这些软件的简洁之处,这个算法的实现在Octave里只需要一行代码
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');小总结
对⽐⼀:有标签 vs ⽆标签
有监督机器学习⼜被称为“有⽼师的学习”,所谓的⽼师就是标签。有监督的过程为先通过已知的训练样本(如已知输⼊和对应的输出)来
训练,从⽽得到⼀个最优模型,再将这个模型应⽤在新的数据上,映射为输出结果。再经过这样的过程后,模型就有了预知能⼒。
⽽⽆监督机器学习被称为“没有⽼师的学习”,⽆监督相⽐于有监督,没有训练的过程,⽽是直接拿数据进⾏建模分析,意味着这些都是要
通过机器学习⾃⾏学习探索。这听起来似乎有点不可思议,但是在我们⾃⾝认识世界的过程中也会⽤到⽆监督学习。⽐如我们去参观⼀个画
展,我们对艺术⼀⽆所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别。⽐如哪些更朦胧⼀点,哪些更写实⼀些。即使我们
不知道什么叫做朦胧派和写实派,但是⾄少我们能把他们分为两个类。
对⽐⼆ : 分类 vs 聚类
有监督机器学习的核⼼是分类,⽆监督机器学习的核⼼是聚类(将数据集合分成由类似的对象组成的多个类)。有监督的⼯作是选择分类器
和确定权值,⽆监督的⼯作是密度估计(寻找描述数据统计值),这意味着⽆监督算法只要知道如何计算相似度就可以开始⼯作。
对⽐三 : 同维 vs 降维
有监督的输⼊如果是n维,特征即被认定为n维,也即y=f(xi)或p(y|xi), i =n,通常不具有降维的能⼒。⽽⽆监督经常要参与深度学习,做特
征提取,或者⼲脆采⽤层聚类或者项聚类,以减少数据特征的维度。
回归和分类的区别
初学机器学习,一直没有准确理解回归和分类的概念的区别,经过听课和在网上查阅相关资料,终于有了一个区分的方式。
首先假设线性回归是个黑盒子,那按照程序员的思维来说,这个黑盒子就是个函数。我们只要往这个函数传一些参数作为输入,就能得到一个结果作为输出。那回归是什么意思呢?其实就是这个黑盒子输出的结果是个连续的、不固定的值。如果输出不是个连续值而是个离散、固定的那就叫分类。那什么叫做连续值呢?非常简单,举个栗子:比如我告诉你我这里有间房子,这间房子有40平,然后你来猜一猜我的房子总共值多少钱?这就是连续值,因为房子可能值80万,也可能值80.2万,也可能值80.21万。再比如,我告诉你我有间房子,120平,总共值180万,然后你来猜猜我这间房子会有几个卧室?那这就是离散值了。因为卧室的个数只可能是1, 2, 3,4,充其量到5个封顶了,这样预测的值就是固定的那几个,而且卧室个数也不可能是什么1.1, 2.9个。所以只要知道我要完成的任务是预测一个连续值的话,那这个任务就是回归问题,离散值的话就是分类问题。















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









