







深度学习训练中遇到一些bug -- torch版
- RuntimeError:
- 类型一:RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
- 类型二:RuntimeError: CUDA error: device-side assert triggered
- 类型三:RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument weight in method wrapper_CUDA__native_layer_norm)
- 类别四:RuntimeError: The size of tensor a (5) must match the size of tensor b (512) at non-singleton dimension 2
- 类别五:Python: too many values to unpack (expected 2,3......n)
- IndexError
- ValueError: only one element tensors can be converted to Python scalars
- forward() takes 2 positional arguments but 3 were given
- local variable: local variable referenced before assignment
- 参考文献:
读这篇文章之前建议先看一下这篇文章:.numpy()、.item()、.cpu()、.clone()、.detach()及.data的使用 && tensor类型的转换 补充一下数据转换的基础,可以torch的一些操作
RuntimeError:
类型一:RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
解决办法: 加载模型的时候,数据和model放入cuda-gpu 上进行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
input_ids, attention_masks, token_type_ids, target = input_ids.to(device), attention_masks.to(
device), token_type_ids.to(device), target.to(device)
类型二:RuntimeError: CUDA error: device-side assert triggered
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile withTORCH_USE_CUDA_DSAto enable device-side assertions.
(如果,先暂时不用GPU训练,全在cpu上训练,你会发现它的报错会更加细致)
有两种可能:
第一种可能:
- 分类的类别,不连续且不是从零开始,如下图,全连接层如果设置为种类数的话,这些标签不能覆盖,解决办法,把实际的标签映射到从0开始的标签中,解决问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-649D3OEv-1689909122848)(D:\S\typora文件夹\img\image-20230717212430808.png)]
设置一个映射表,把这些标签映射到从零开始的一些新的”标签“中去。
a = list(range(100,117))
a.remove(105)
a.remove(111)
label2label = a
label2label
# [100, 101, 102, 103, 104, 106, 107, 108, 109, 110, 112, 113, 114, 115, 116]
# 可以通过label2label.index(原来的label) 映射到新的label: 0-14
# 也可以直接label2label[新的label] 映射回原来的label
# 在自定义数据集的时候就是这样
target = torch.tensor(label2label.index(int(self.y[index])))
第二种可能:
- 前面训练的显存用的太多,导致没有显存利用,解决办法,关闭pycharm和notebook进行重启。然后就可以继续愉快地训练啦!
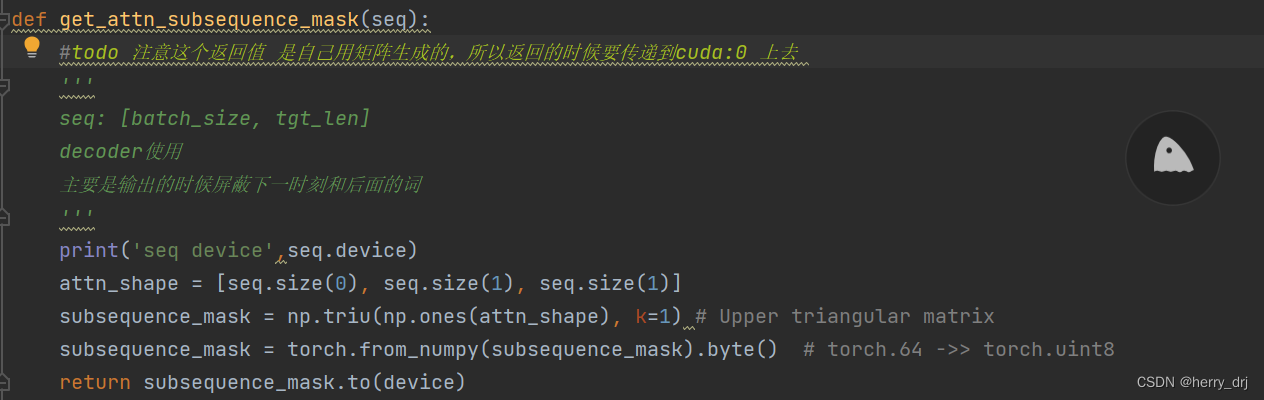
类型三:RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument weight in method wrapper_CUDA__native_layer_norm)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument weight in method wrapper_CUDA__native_layer_norm)

- 原因: 在传播过程中,tensor没有放入cuda中,在层里面导致有些tensor在不同的device里面
- 解决办法: 在层里面用cuda放入gpu训练 注意函数的返回值的类型
类别四:RuntimeError: The size of tensor a (5) must match the size of tensor b (512) at non-singleton dimension 2
RuntimeError: The size of tensor a (5) must match the size of tensor b (512) at non-singleton dimension 2
- 原因,在定义层内传播的时候维度shape出现了错误:
- 解决办法,一般在全连接层查找出错的层的维度,调整维度。
eg. 如果下面的self.fc传入的最后一个维度是768维,而此处定义的fc是512x200的因此导致了这个错误出现,正确的应该将第一个全连接层改为768x200
class MypretrainModel(nn.Module):
def __init__(self,is_lock=False):
super(MypretrainModel,self).__init__()
self.encoder = Encoder()
self.fc = nn.Linear(512,200) # 此处应该nn.Linear(768,200)
self.dropout = nn.Dropout()
self.classifier = nn.Linear(200,label_nums)
def forward(self,x):
x,_ = self.encoder(x)
x = F.relu(self.fc(x))
x = self.dropout(x)
out = self.classifier(x)
return out
类别五:Python: too many values to unpack (expected 2,3…n)
Python: too many values to unpack (expected 2,3…n)
- 赋值的时候,等式左右两边的变量个数不对应:
x,y,z,w = (1,'torch',[3,'b'])
# 左边是四个变量,右边元组中只有三个变量,因此左右不统一会进行报错。
x,y,z = (1,'torch',[3,'b'])
# 正确做法,左右变量个数对应。
IndexError
- 列表 或者 元组 越界,即超过实际有的范围了,调整范围。
- 深度学习中,多分类标签中label的索引,超过你设置的种类数目,解决方法同上。
ValueError: only one element tensors can be converted to Python scalars
- list 里面有tensor类型的数据,不能直接转换tensor,应当便利list里面的元素,先全部转为numpy()格式。详细解释看这里
val= torch.tensor([item.cpu().detach().numpy() for item in val]).cuda()
forward() takes 2 positional arguments but 3 were given
forward() takes 2 positional arguments but 3 were given
在forward中明明正确数量的参数,却报错:forward() takes 2 positional arguments but 3 were given;
问题分析:
使用nn.Sequential()定义的网络,只接受单输入def forward(self, input): 在前向传播中只有一个参数,但是在后面使用的时候出现了多个参数,如下例子都是传入model的参数过多。
eg.1:
def __init__(self):
self.backbone=nn.Sequential(nn.lstm(input_size=20, hidden_size=40, num_layers=2),
nn.linear(in_features=40, out_features=2))
def forward(self, input):
h0 = torch.randn(hidden_layers, batch_size, hidden)
c0 = torch.randn(hidden_layers, batch_size, hidden)
output, _ = self.backbone(input) (对)
output, _ = self.backbone(input, ho) (错误,因为nn.Sequential()定义的网络,只接受单输入)
eg.2: model()只能前向传播一个变量,但是传入了两个
# model前向传播部分:
def forward(self,x):
x,_ = self.bert_pretrained(x)
x = self.dropout(x)
x = F.relu(self.fc(x))
out = self.classifier(x)
return out
model = MypretrainModel()
output = model(input_ids,target) # output = model(input_ids,target)
- 解决方案: model(input)
local variable: local variable referenced before assignment
local variable referenced before assignment
- def 函数中 改变全局变量 的问题 local variable referenced before assignment
a = 5
def add(a):
a += 5
add(a) # 会报错
# 正确做法:
def add(a):
global a
a += 5
add(a)
参考文献:
.numpy()、.item()、.cpu()、.clone()、.detach()及.data的使用 && tensor类型的转换
















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











