






尽管对于计算机而言无所谓数据类型,因为所有的数据都在计算机中以二进制数进行存储,运输和计算,但是对数据进行人为的划定有益于人们对于数据的操作。
在C语言中对于数据类型的划分(因人而异)大致为:
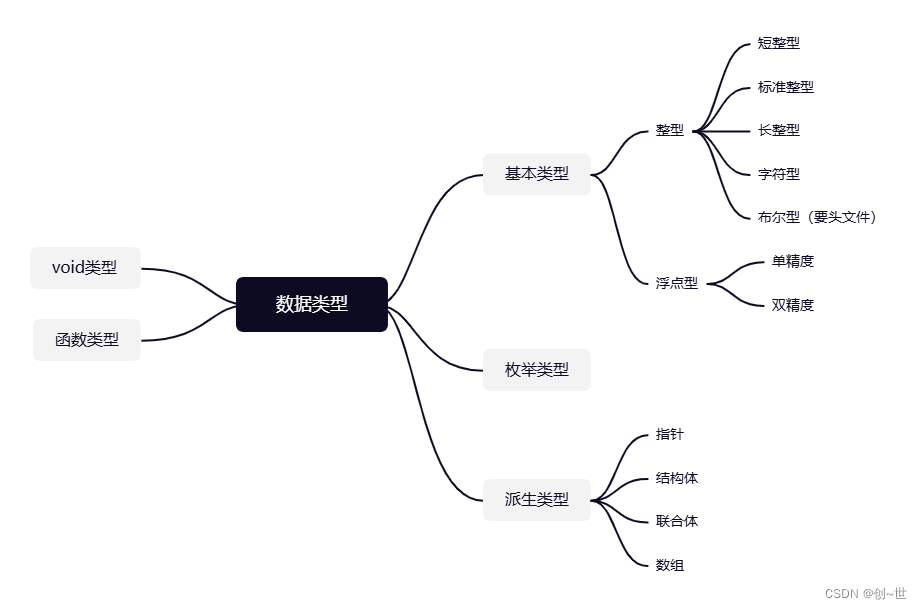
一、基本数据类型
什么是数据类型?
每一种编程语言都有它自己的数据类型体系,在多数教程中,什么是数据类型似乎是比较少讨论(或许是我忘了,不管了),但是只要讨论,就会发现(我就会发现)可以通用。下面引用自一个C++教程网站(https://www.learncpp.com/)的话:
A data type tells the compiler how to interpret a piece of data into a meaningful value.
数据类型告诉编译器如何将一段数据解释为有意义的值。
A data type (more commonly just called a type) determines what kind of value (e.g. a number, a letter, text, etc…) the object will store.
数据类型(通常称为类型)决定了对象将存储什么样的值(例如数字、字母、文本等)。
用我的话说,所谓的数据类型就是一种定义,它规定了在一块连续的内存空间上可以进行的操作(取存改值等)以及一些属性(空间大小等)。
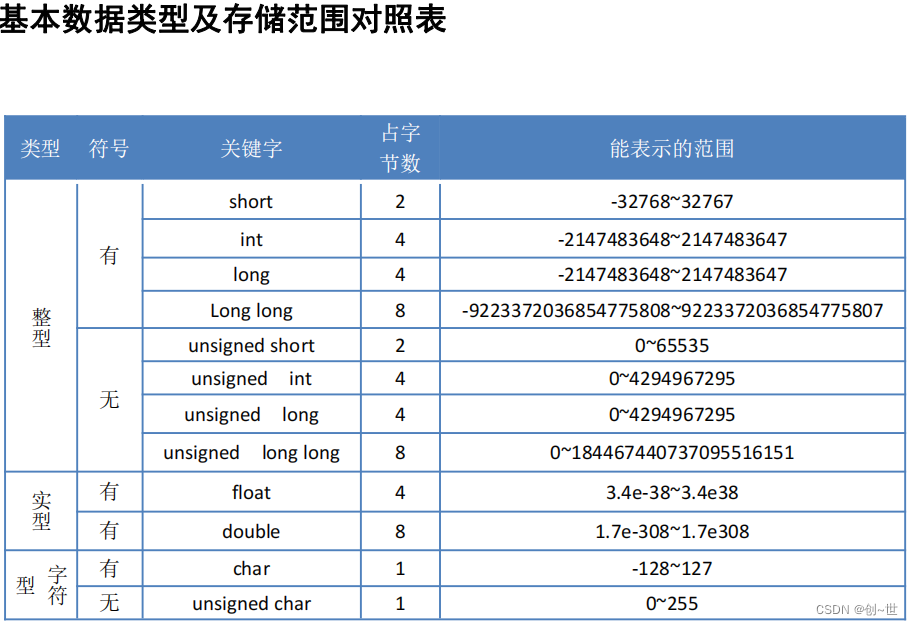
上表大致显示了C基本数据类型的大概,值得说明的是在C语言中一种数据类型的所占字节,或者说大小是有关于具体平台的,这或多或少被程序员所诟病,这好比我在拿盒子堆积木,我总是希望我所放置的那个盒子就是我看到的那样的大小,而不是说等到一定的时候上面的盒子压下来,才知道是个空包,这多少让人有点焦虑。
至于为什么数据类型会随平台的不同有所差异呢,这个读者可以自行了解,总的来说算是C平台可移植性的一种代价。同时C中也有一种库可以保证数据类型的大小的固定性,也算是一种弥补吧,这里不多说了。
二、变量、常量与字面量
在不少编程语言中,几乎都能找到这三样东西的影子,定义或许有些差异,不过也基本相同(就我了解到的而言)。
(一)变量
从数学到C
变量这个词在数学中也普遍存在,通常我们称之为。在实际问题中,诸如小明每天挣3元,问
天后小明可以挣多少钱?
我们可以很容易列出
这样的数学表达式,但是这是对的吗?请注意这里的可是天数,嗯,所以我们应该这样
可是这就对了吗?注意,小明可不是长生不老,也有可能小明看累死累活就这么点工资不干了,总之,不应该是一个无上限的自然数,所以我们又有了以下的数学表达式
嗯,看起来对于这个问题,我们已经解决了,但是这跟编程语言,或者跟C中的变量有什么关系吗?有,当然有。让我们试着用C语言描述我们的表达式:
首先,我们需要一个在C中可以表示的东西,显然,想想也没有,毕竟
可是有下限,无上限,计算机可存储不了无限的数字。不过,回到我们的问题,我们真的需要无上限吗?显然,并不必要,我们只需要一个能包含0~30范围的数集即可。
嗯,所以我们可以选择上面数据类型中的,它的取值范围可以。
接下来,就是我们的变量,幸运的是,在C中我们也可以直接用
表示
,嗯,听起来怪怪的。
然后就是,
是因变量,所以也是变量,可以预见
的值域为[0, 90)。
最后,让我们具体实现,这里我们使用gcc,源码如下(嗯,现在只干3天了),编译一下
// hello.c
#include <stdio.h>
int main()
{
y = 3x, where x ∈ unsigned char and x < 3
return 0;
}然后就会出现一堆问题
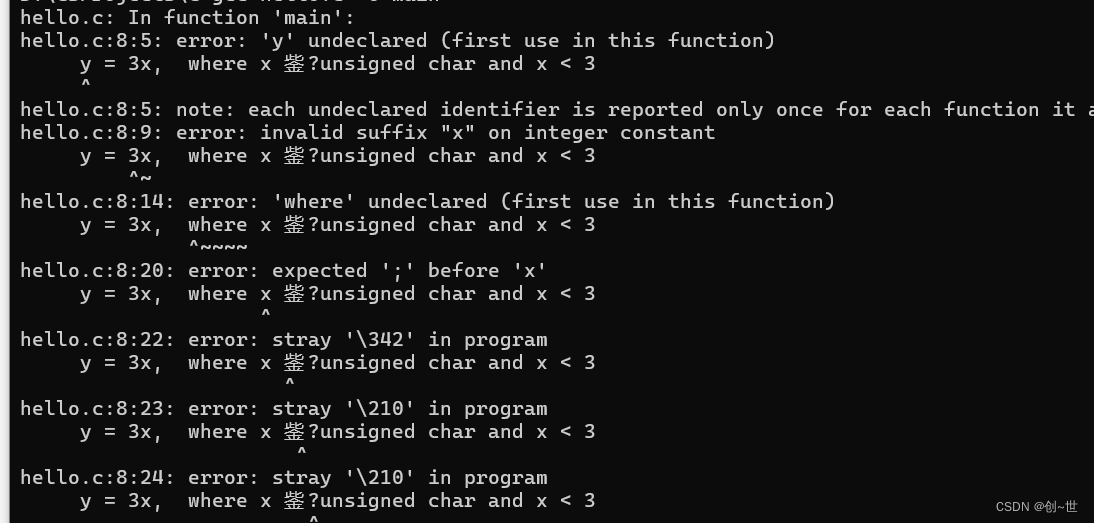
不过,不要慌,要学会看报错提示,首先第一个说'y' undeclared (first use in this function),y没有定义。什么叫没有定义,这就好比,我说,你可能会想这是报警电话,不过这也可能是一个数字而已,也就是这个数字存在二义性,而在计算机程序中不应该这样,你应该在让计算机去执行代码前就确切地说明,而不是等计算机遇到这个符号,还要从计算机中跳出一个人说,你这家伙写得这是啥?
那么怎么定义,如果以数学语言,我们可能会说
是一个值域为[0, 90)的自然数,在C语言中我们应该这么说
什么意思呢?这段代码表明,我们定义了一个变量,它的取值范围为unsigned char的取值范围,更一般地,我们会说,定义了一个unsigned char类型的变量
。
这里有两点值得注意的是,我们没有限定取值范围为[0,90),在C中也不提供这样的机制,(不过请看后面的特例),在原数学问题中,我们也只需要说
是一个自然数即可。我们也不需要这样,因为
不过是一个数值容器,无论
是<3也好<30也好,我们只需要
能够正确存储结果,从这个角度而言,
也可以。第二点是这里加了分号,这后面会讨论。
源码再次修改
// hello.c
#include <stdio.h>
int main()
{
unsigned char y;
y = 3x, where x ∈ unsigned char and x < 3
return 0;
}编译后那个错误就会消失,不过还是有其它错误:
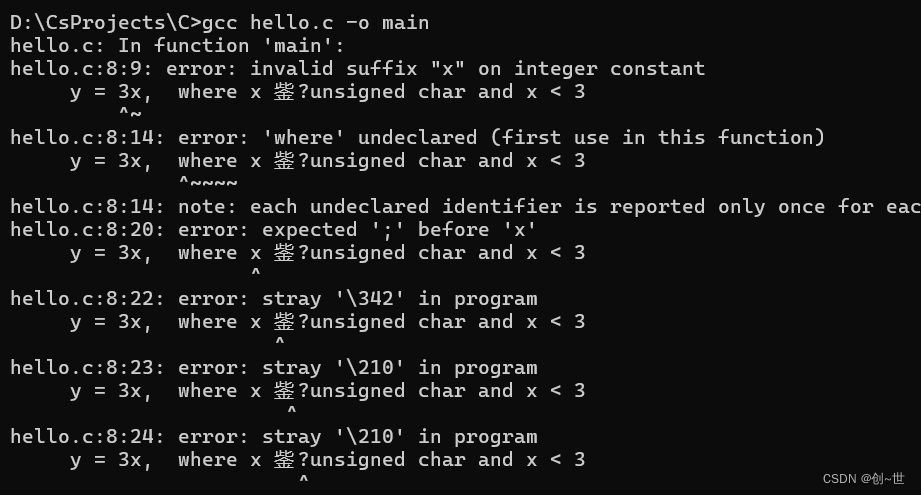
错误提示在一个整数3后面的非法x后缀,什么意思呢?invalid就是不允许这样操作,我们想要表示的并不能有效翻译成代码语言,在数学中,表示
,可在C中没有这样的转换,这是数学表达式转换成C语言非常需要注意的地方,我们要这样写
// hello.c
#include <stdio.h>
int main()
{
unsigned char y;
y = 3*x, where x ∈ unsigned char and x < 3
return 0;
}编译后,发现未定义,不过
不是在后面说明了吗,移到前面?不对,第二个错误显示C编译器不认识where,所以数学表达式转成C语言并不能拿来主义,对于一个变量的声明定义,有且有一条正途,即类似
一样
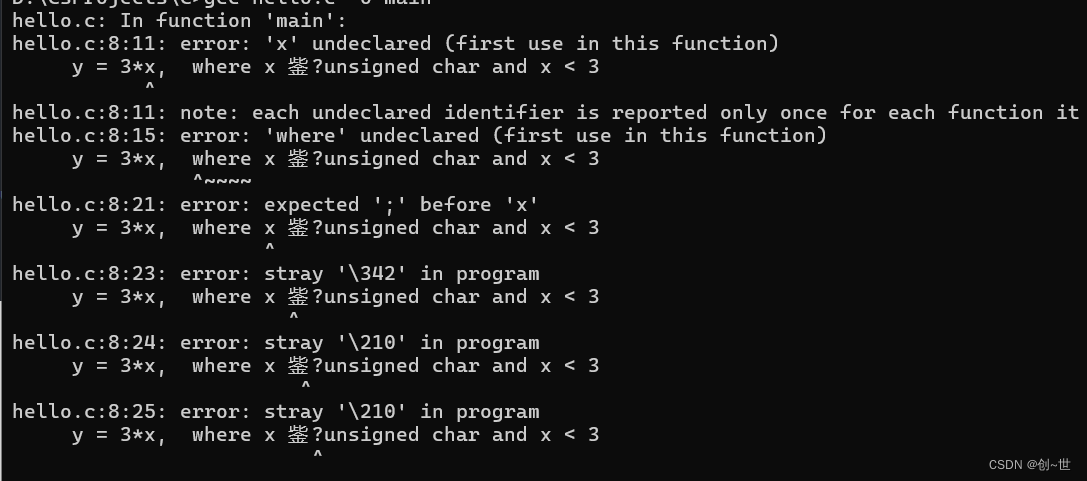
让我们再次修改,可以看到一下子干净了,不过提示我们少了东西,这个后面说,现在就加上就好。
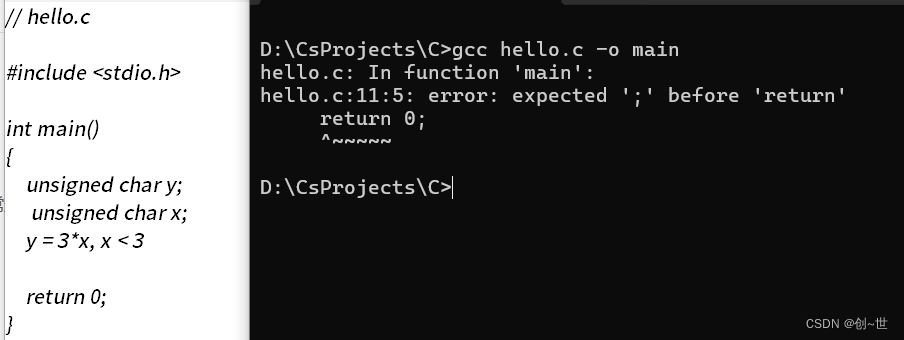
bingo!我们成功将一个数学表达式用C语言表述,不过,嗯,少了输出。

我们改改
// hello.c
#include <stdio.h>
int main()
{
unsigned char y;
unsigned char x;
x = 10; // 工作10天
y = 3*x, x < 30;
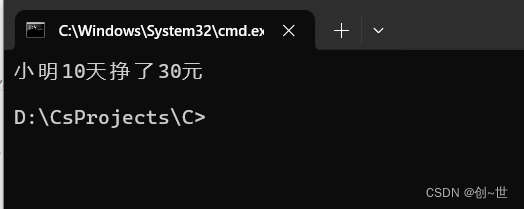
printf("小明10天挣了%d元\n",y); // 输出,后面更具体地说明这段代码
return 0;
}编译,成功,乱码
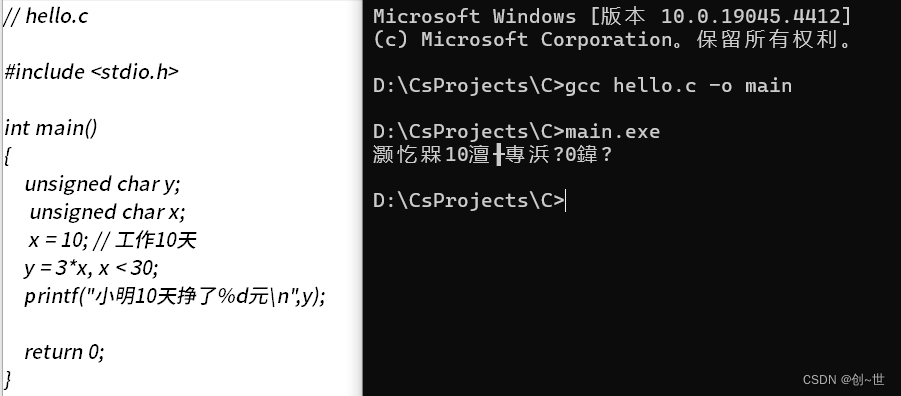
不慌,略施小计
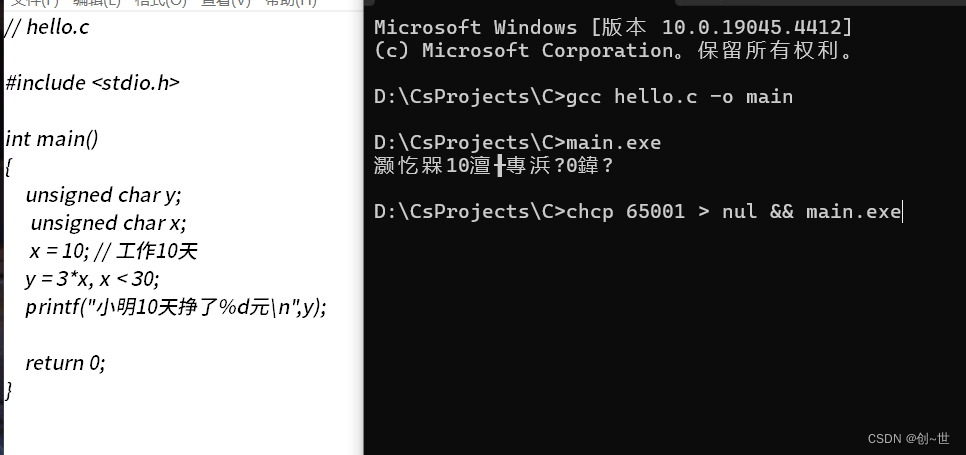
不过,我们并不能依靠这个解决我们的问题,就比如并没有被约束
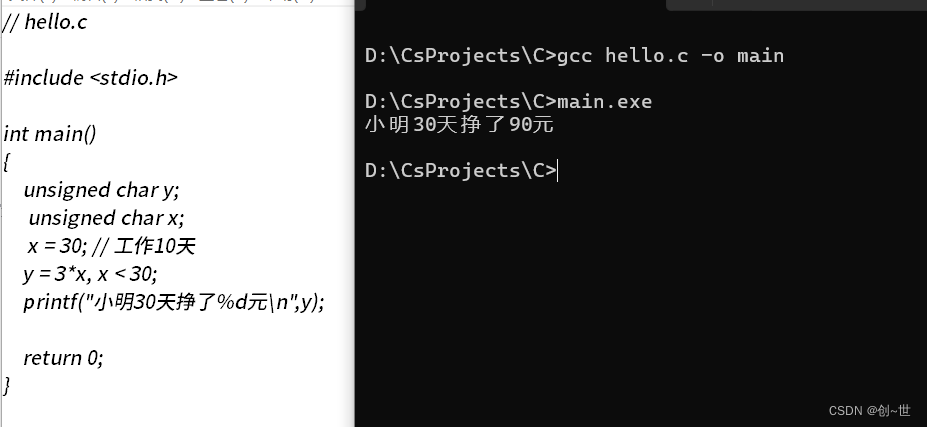
那应该怎么做呢?在C语言中,可以这样,加一个判断(以后会提到),这跟原问题有异曲同工之处。
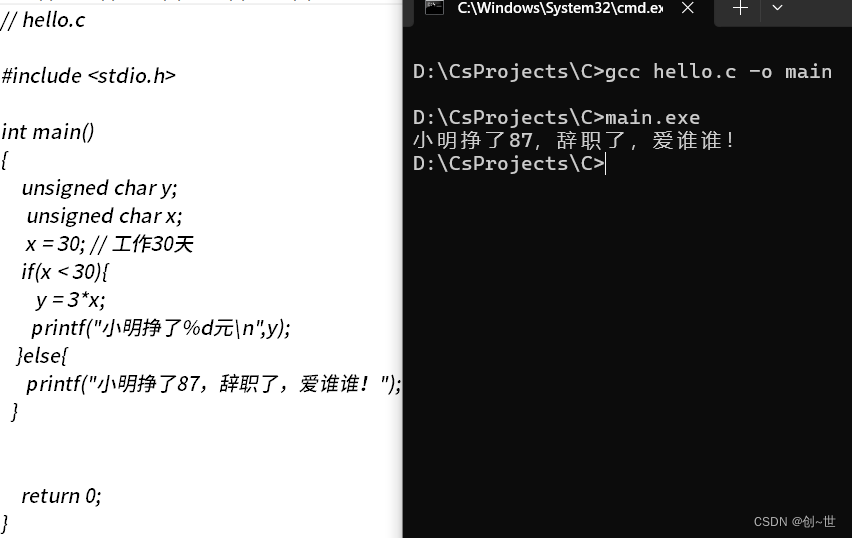
什么是变量?
我们前面说了那么多,那么回到主题上,什么是变量?C中的变量和数学中的一样吗?从前面的操作我们可以回答:相似但不相同。
具体而言,我们同样可以在C语言中对变量进行赋值,如上,以及操作如
,乃至大小
比较。如果说在数学中,我们是让变量属于某个集合,使其具有这些东西,那么在C中,我们就是让变量属于某个数据类型,这种让变量属于某个数据类型的操作,可以格式化为
这种操作,有一个专业的术语,称之为定义(definition)。
之前,我曾提过不必刻意规定的具体值域,只需保证
能够存储结果值即可,你会发现在存储问题上两者就不相同,因为在数学中,存储是虚拟的,从某种程度上存在脑子里,而在C语言中,数据是在计算机中真实存在的,也可以说也在电脑“脑子”里。所以对于C语言里面的变量,其必然要与一块内存空间相关联,也可以说这块内存空间叫做这个变量。
如果我们要计算,我们会先找到
,那么计算机也是类似的通过
找到其值(更进一步说,找到一块叫做
的内存地址的值),如此我们可以说:
A variable is a named piece of memory that we can use to store values. In order to create a variable, we use a statement called a definition statement.
变量是我们可以用来存储值的命名内存。为了创建变量,我们使用称为定义语句的语句。
注意:变量是内存,变量名是内存名
变量与赋值
变量的赋值,并不像前面的那样简简单单,就比如,换个位置,就会出错,不过这在数学上是可以的。
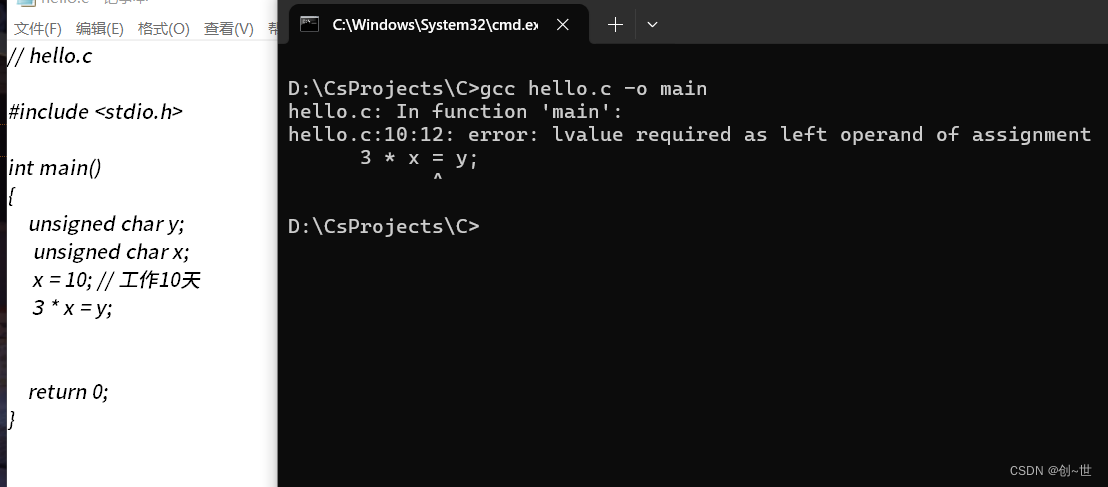
这就涉及到表达式(后面展开)中的一个左值(lvalue)概念。
左值与右值
如果简单来讲,我们或许可以说,左值(lvalue)是赋值操作左边的部分,右值(non-lvalue object (rvalue))是赋值操作右边的部分。
但,并不是想象的这样简单(或者说,左值和右值并不是仅仅发生在两侧),官方是这么说的。

对于小白读者,这可能很难理解,所以我们再看看右值(从反面入手):
Known as rvalues, non-lvalue object expressions are the expressions of object types that do not designate objects, but rather values that have no object identity or storage location. The address of a non-lvalue object expression cannot be taken.
非左值(rvalues)对象表达式,专业上称为rvalues,这类表达式涉及的是对象类型,但它们并不指向具体的对象实体,而是代表那些没有独立对象标识或固定存储位置的值。由于非左值对象表达式不具备可寻址特性,因此无法对其取地址操作。
综上,一个简单的比方,可以是这样的,我有两个盒子A与B,它们可能规格类型相同也可不同。我想把B盒子中的一样东西C放到盒子A中(假设能够装得下)。那么C可简单认定为右值,A盒可认为是左值,至于B盒只是个右值的载体。
显然,在这个操作中,有几个关键点:
- A盒必须能够被放入东西(Modifiable),能放得下(overflow),特殊的,可以放在指定位置位置(member,index);
- B盒只是C的载体,C可在其它地方;
在上面的问题中,就是一个右值,虽然
是变量,但是
使成为了一个确定的值,换句话说,我们要的是
里面的值,而不是
本身,如此
当然就不指向具体的对象实体,因为这个值可以被任何能放置的内存“盒子”存储。
为了简化,我们可以说左值是待赋值的变量(一个内存空间,用于接收值),而不能是非变量,也即不能改变的量,右值是值的来源,可以是以载体的形式,也可以是原始值。
实例化与初始化
回到我之前的一个源码,我并没有在这里对进行赋值,又把它赋值给了
,程序并没有报错,这是为什么呢?(当然,在数学中,这完全可以,因为这不过是一个数学表达式。但是经过前面的描述,你会发现,这不是一个数学表达式,或者说在C中称之为赋值更为贴切)。
首先,我们要认识到一个点:
When the program is run, each defined variable is instantiated, which means it is assigned a memory address.
当程序运行时,每个定义的变量都被实例化,这意味着它被分配了一个内存地址。
也就是说当我如此操作时,是直接取这个被分配的内存地址里面的数据(当然我给它赋值后也是如此),换句话说,我们将得到一个意想不到的值(这并不意味着错误,通常只是警告),这时称之为未初始化变量(uninitialized variable),值得注意的是,初始化(initialization)并不是等同说赋值(Assignment):
- Initialized = The object is given a known value at the point of definition.
初始化=在定义时被赋予一个值。
- Assignment = The object is given a known value beyond the point of definition.
Assignment=定义后被赋予一个值。
- Uninitialized = The object has not been given a known value yet.
未初始化=对象尚未被赋予值。
另一个值得说明的是,有时,我们会说"Reassignment"(重赋值),指将一个新值赋予已经声明过的变量的过程,这意味着变量的当前值被新值替换。这在后面会进一步说明。
下面是一个简单的代码说明:
// 声明一个变量
int a; // dataType varibale;
// 赋值
a = 10; // variable = value;
// 声明并初始化一个变量
int b = 10; dataType variable = value;在这里,几个我比较认同的Best Practice 是:尽量初始化变量,避免使用未经初始化的变量;对于变量,尽量单独定义,不要连续定义,以防出现忘了初始化某个变量。
声明与定义
可以看到,在上面我使用了不同两种说法描述,这一过程:
声明(Declaration)与定义(Definition)
更严格地说,这就是定义,但是有时,也会看到说这是声明。声明就好比老板跟小明说你每天的工资是3元,但是,是不是就是另一回事了,而定义就好比跟小明签了个契约,工资啥的纸上都有。这说明定义相比于声明更加的具体和可靠,在C语言中定义也意味着分配内存。
专业点可能如下:
A declaration tells the compiler about the existence of an identifier and its associated type information.
声明告诉编译器标识符的存在及其关联的类型信息。
A definition is a declaration that actually implements (for functions and types) or instantiates (for variables) the identifier.
定义是实际实现(对于函数和类型)或实例化(对于变量)标识符的声明。
关于声明与定义,后面会结合其它语法更加深入讨论。
关于变量的其他说明
关于变量,还有一些很多教程都会首先提到的一些东西,比如命名(基本上很多编程语言都一样),这些东西基本上就属于编程规范了。在C语言的变量基本要素中(数据类型、值、名、作用域),我将在后面讨论作用域的问题。
关于基本数据类型的再探讨
为什么要再探讨呢?因为在基本数据类型的那张表中,有一个地方,我并没有讨论过,那就是类型,类型何以重要,就凭数据类型可以简称类型!在那张表中,有三种数据类型(整型、实型和字符),不过读者可能发现,即使有这三种不同的类型,但是在上面的语境中,它们仍然不过是透明的,就比如在选择的类型时,我们关注的是取值范围,
和
都可以,这难免会让人有点困惑。
让我们打个比方。将内存想象成一块土地,把数据类型当作一种建筑类型,而变量就是一个具体的建筑,显然建筑有很多种(数据类型多样),但构成建筑的原材料几乎类似(让我们抽象为0与1),向具体的建筑中放置原材料(赋数值,复杂一点的数据类型可能并不直接)当然可以,但是可能有点怪,就比如往一个办公楼里面放一吨的水泥,我们倾向于说给办公楼增加一层(让数据以合适的形式赋予特定的数据类型),所以我们可能会这样
即赋予一个类型的变量
字符
值,但请注意,这并不意味着在
的内存中就是一个字符
,而是二进制(01组合)的数值65,因为
的
码值就是65。换句话说,上面的定义效果等同于
嗯?这是为什么呢?这就要归功于(赋值运算符)的作用了,它会将右值转换为左值的数据类型(赋值转换),这就相当于装修工人,把原材料转换成建筑里面的东西。
值得注意的是,尽管这么说,但是在计算机内存中都只是0和1而已,在计算机内存中并不存在数据类型。数据类型是编程语言在内存上抽象的“建筑”,拥有对里面的数据的解释权(这一块是办公区,这一块是……)。
(二)常量
在数学中,我们也经常用到这个词,就比如大名鼎鼎的。不过并不等同于数学中的常量,在编程中,常量应该更确切的说是在预期的时间段内不会改变的值,换句话说,在程序运行时不变的量。
好比说,小明在一开始的工资是个常量3,不过可能过了一星期就变成了7。这时候我的程序就要改动了。
在C语言中有三种定义形式的常量
宏常量
一般定义在C文件的上部,单独占一行
示例:
#define 符号标识符(宏名) 常量(数值或表达式)
#define PI 3.14定义时一行写完,一般不出现分号
由宏定义方式定义的符号标识符与其对应常量具有等价关系,在程序编译预处理时进行替换,不会做多余地改变,应当注意的是,在输出语句中的符号标识符不会进行替换,此时的符号标识符不是宏常量,而是字符串
下面举个例子 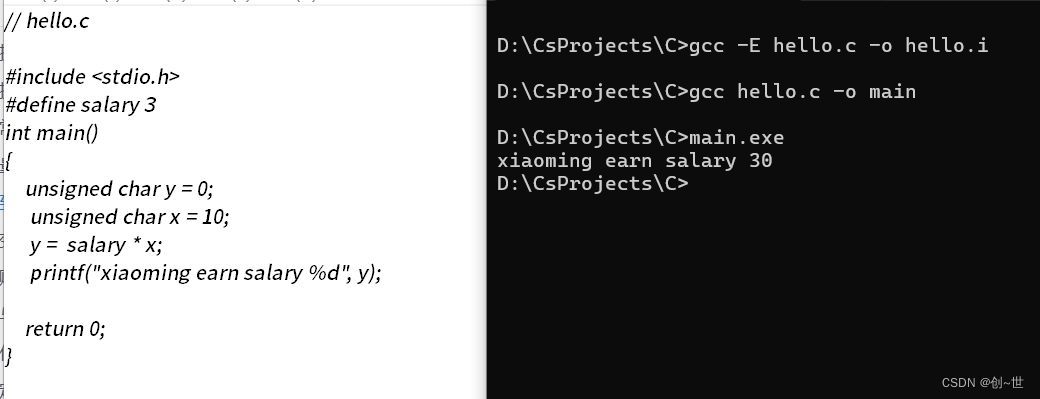
找到i文件,可以发现变量被替换了,但是字符串里面的没有

关于宏常量还有很多有趣的地方后面讨论。
const 常量
const 常量与变量相比显著多了一个const,与宏常量相比,const常量具有数据类型,const常量更像是常量,宏常量只不过是替换。
const 数据类型 常量名=值; // 也可以 数据类型 const 常量名 = 值;
const int PI = 3.14; 另一个重要的点是const常量必须初始化,不然后面再赋值就是错误,因为const定义后就是只读的。 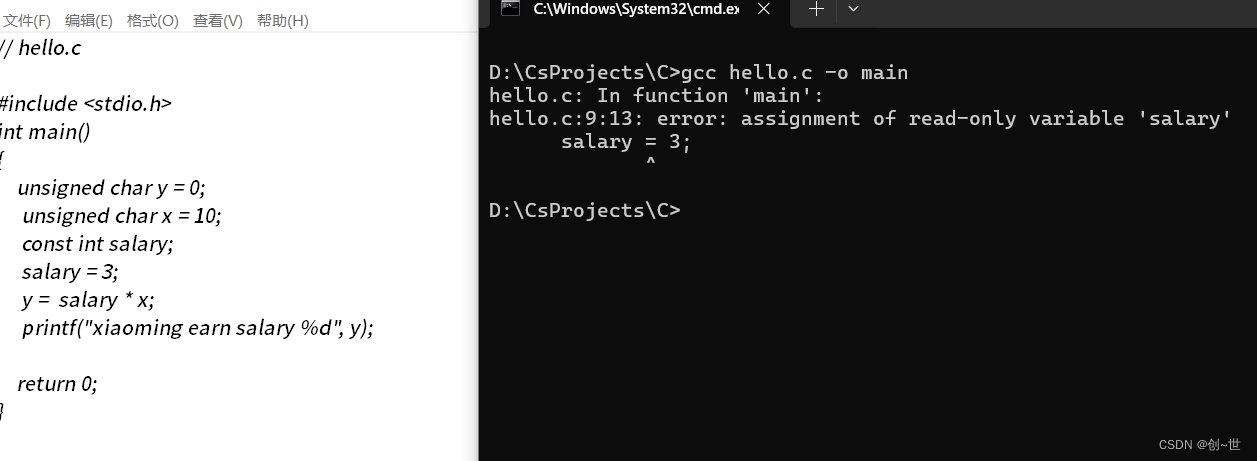
枚举常量与枚举类型
如果还记得我之前所说的对变量的取值范围做限制的特例,这就是。
所谓枚举,就是可以一个一个数,它并不像short等有6千多取值可能(当然也可以数),不过枚举类型的变量的取值只有你定义时写出的枚举值个数个。
举个例子,如下,这个枚举类型只有7种取值
// enum [枚举类型名]{枚举值列表} 定义一个枚举类型
enum Weekdays {Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday};也就是说enum Weekdays这个枚举类型定义的变量只能赋予这7种值。诶,这就有点怪了,和之前的数据类型相比,感觉好复杂,下面才是定义变量。
// enum 枚举类型名 变量 定义一个枚举变量
enum Weekdays today;给枚举变量赋值:可以使用枚举值来给枚举变量赋值。
today = Monday;使用枚举变量:可以在表达式中使用枚举变量。编译器会根据枚举值自动替换枚举变量。
printf("Today is %d\n", today); // 输出 "Today is 1" 注意:枚举类型的第一个枚举值默认为0,后续的枚举值依次加1。例如,在上面的例子中,Sunday是第一个枚举值,其值为0;Monday是第二个枚举值,其值为1,以此类推。
当然也可以自定义整数顺序,如下:
enum Weekdays {Sunday = 7, Monday, Tuesday = 9, Wednesday, Thursday, Friday, Saturday};没有显式说明的枚举值默认就是前面的枚举值加1。
(三)字面量(变量的值)
字面量是变量的值表现形式,比如12、34、‘a’等这些确定的值,所以字面量也可称为字面常量(literal constant)。
A literal (also known as a literal constant) is a fixed value that has been inserted directly into the source code.
文字(也称为文字常量)是直接插入源代码的固定值。
在程序中,我们将在不同情况下使用到字面量,其中一种最常见的情况下就是变量的赋值:
int a = 1; 这里要讨论的,不是将1变成其它值如2,而是其它形式的1,比如0X01(十六进制的1),即值的表现形式。
字面整型(数)常量
1、值的进制
整数常量(integer constant)可表示为常见的十进制数字、八进制数字、十六进制记数法乃至二进制的数字。
以下为128的不同进制表示
int d = 128; // 十进制
int h = 0x80; // 十六进制,以0x或0X开头
int o = 0200; // 八进制,以0开头
int b = 0B10000000; // 以0b或0B开头2、值的类型
由于所定义的整数常量最终将用于表达式与声明中,因此它们的类型非常重要,当常量的值被确定时,常量的类型也会被同时定义。
对于一个整数,不加修饰的,都默认为int类型,如下在vscode中,当鼠标悬浮在整数上时
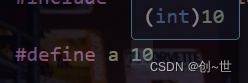
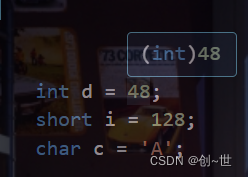
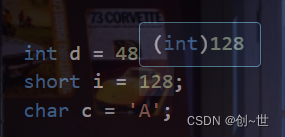
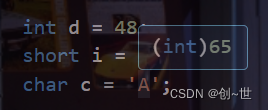
以上只是部分说明,可以看到字符常量默认也是int类型。
也可以利用后缀显式定义常量的类型。
| 整数常量后缀(大小写皆可) | 类型 |
|
| unsigned int |
|
| long |
|
| unsigned long |
|
| long long |
|
| unsigned long long |
实型(浮点)常量
实型常量是指带有小数点的数,如0.2,所以下面形式的实型常量也是合法的
float a = .125; // ==0.125 不写整数部分
float b = 10.; // == 10.0 不写小数部分浮点常量可采用十进制或者十六进制记数法(C99标准引入)
// 十进制
float a = 64.25;
// 十进制指数形式 (整数或小数)e(E)(整数)
float b = 642.5e-1 // 642.5 x 10^(-1) = 64.25
// 十六进制记数法,只能是科学记数法的形式,和整型一样加上0x或0X前缀,用p或P代替e,用 2 的幂代替 10 的幂
float b = 0x10.1p2; // (1 x 16^1 + 0 x 16^0 + 1 x 16^(-1) ) x 2^2 = 64.25实型常量隐含按双精度类型(double)处理,如果要显式声明其为单精度常量后可跟F或f
float a = 3.14F;与整数常量类似的长双精度常量后缀可加用L或l。
long double a = 3.14L;浮点常量示例:
| 浮点常量 | 值 |
|
| 10 |
|
| 2.34x105 |
|
| 67.0x10-12 |
字符常量
用 ''括起来的一个ASCII字符,如'a',双单引号里面至少包含一个字符,而不能为空。
特别的,对于有些ASCII字符,需要使用以\为开头标志的转义字符。以下是C语言中常见的转义字符及其含义的表格形式:
| 转义字符 | 含义 | ASCII码(十进制) |
|
| 空字符(NULL) | 0 |
|
| 制表符(HT) | 9 |
|
| 退格符(BS) | 8 |
| \n | 换行符(LF) | 10 |
|
| 回车符(CR) | 13 |
|
| 换页符(FF) | 12 |
|
| 响铃符(BEL) | 7 |
|
| 垂直制表符(VT) | 11 |
|
| 反斜线符 | 92 |
|
| 单引号 | 39 |
|
| 双引号 | 34 |
|
| 问号 | 63 |
|
| 任意字符 | 三位八进制 |
|
| 任意字符 | 二位十六进制 |
字符串常量
C语言中的字符串字面量是用于表示字符序列的一种特殊形式的字面量,主要用于创建字符串。字符串字面量是由一对双引号包围的一系列字符组成,其中可以包含普通字符、转义序列以及空白字符。如“Hello World”,这应该是C入门者看到的第一个字符串常量,这一切看起来如此简单,不过,如果在一些IDE上,你可能会发现这种提示

这个是什么呢?原来,在C语言中,字符串字面量实际上是一个字符数组(后面讲解,简单来说,就是一个放置连续字符的空间),以空字符(`\0`)作为终止符,这个终止符你可能没有看到,不过如果你数数的字符个数,你就会发现它只有12个,这就是为什么char后面的数字是13。
更深入的内容,留到后面讨论。接下来,我们来说说字符串的编码问题,但并不会太过深入,仅仅作为一个小扩展。
正如数值类型,我们可以给数值添加一些后缀或者前缀以启某种作用,在C中也支持在字符串前加上一些修饰,来声明字符编码。有以下几种
- 基本字符串字面量:这是最常见的字符串字面量形式,没有修饰,如, "Hello, World!"
- UTF-8 编码的字符串字面量(自C11起):u8"你好,世界!"
- UTF-16 编码的字符串字面量(自C11起): u"你好,世界!"
- UTF-32 编码的字符串字面量(自C11起): U"你好,世界!"
- 宽字符串字面量,通常用于处理多字节字符集或Unicode,L"你好,世界!";
每种字符串字面量都有其特定的用途,选择哪种类型取决于你的具体需求,比如目标平台的字符编码、性能考虑或国际化的需要。在C11标准之前,仅支持基本的字符串字面量和宽字符串字面量;而自C11标准引入了对Unicode编码字符串的支持后,开发人员有了更多的选择来处理国际化文本。【以上除了前两个,后面的似乎不支持,在我所测试中。】
一个简单的说明

控制台默认为GBK,所以使用UTF-8编码的字符串常量显然乱码了。值得注意的是,并不是说字符串常量本身默认为GBK编码,这取决于源文件的编码与运行文件时的输出编码设置以及显示编码,例如,在我的vscode,我执行C程序的命令中,有这么一条命令

当把其改为UTF-8时,就都乱码了,因为我的输出为UTF-8,而控制台为GBK

三、表达式与运算
C语言的表达式和数学在一般形式上是相同的。
An expression is a sequence of operators and their operands, that specifies a computation.
表达式是指定计算的运算符及其操作数序列。
进一步说,表达式(expression)是由一系列的常量、标识符和运算符表示的值操作。如:
a = 1 + 3;
b = -5;操作数(operant)是运算符作用于的实体,是表达式中的一个组成部分,它规定了指令中进行数字运算的量 ;操作数是相对于表达式而言的。
a = 1 + 3; // 操作数:1、3
b = -5; // 操作数: 5
c = a + b; // 操作数:a、b表达式是操作数和操作符的组合。以下为C语言的常见运算符表:
 接下来,我将对需要注意的运算符做说明,其它运算符和数学相比也差不了多少。
接下来,我将对需要注意的运算符做说明,其它运算符和数学相比也差不了多少。
(一)算术运算符
主要用于进行数学运算,如加、减、乘、除等。
| 运算符 | 说明 |
|---|---|
|
| 乘法 |
|
| 加法 |
|
| 减法 |
|
| 正号 |
|
| 负号 |
除法
不同于数学的除法,C语言的除法具有“两面性”,如果操作数中有一个是浮点类型,则相除结果会保留小数部分的数据,否则则保留整数。下面的示例建议结合后面的知识来看

模运算
模运算要求操作数不能是浮点数,只能是整型,不然会报错

同时由于模运算的实质是除运算,所以不能取模0

位运算
位运算(Bitwise operations)是在计算机科学和编程中直接对二进制数字(比特位)进行操作的一类运算。在C语言中,位运算符允许你直接对整数的二进制表示进行操作,这对于优化代码、硬件编程、加密算法、数据压缩等领域非常有用。
| 位运算 | 运算法则 | 示例 |
|---|---|---|
| 按位与(&) | 按位与运算符比较两个整数的每一位,如果两位都是1,则该位的结果为1;否则为0。 | 0b1010 & 0b1100 => 0b1000 |
| 按位或(|) | 按位或运算符比较两个整数的每一位,如果两位中至少有一个是1,则该位的结果为1;否则为0。 | 0b1010 | 0b1100 => 0b1110 |
| 按位异或(^) | 异或运算符比较两个整数的每一位,如果两位不同,则该位的结果为1;否则为0。 | 0b1010 ^ 0b1100 => 0b0110 |
| 按位取反(~) | 按位取反运算符反转一个整数的每一位,1变成0,0变成1。 | 假设一个系统中`int`类型占用32位,`~0b1010` 的结果将是 `0b11111111111111111111111111110101 |
| 右移(>>) | 右移运算符将一个整数的所有位向右移动指定的位数,低位溢出的部分被丢弃,高位根据原数值的正负补充(对于无符号整数,高位补充0) | 0b1010 >> 2 => 0b10 |
| 左移(<<) | 左移运算符将一个整数的所有位向左移动指定的位数,高位溢出的部分被丢弃。 | 0b1010 << 2 => 0b101000 |
对于左移
对于无符号数,如果移动导致了溢出(即超过了该类型所能表示的最大值),超出部分会被丢弃,而不会引发错误或警告,对于有符号数可能触发未定义行为(Undefined Behavior,UB)。

对于右移

- 对于无符号整数(
unsigned)的右移操作,LHS >> RHS的值是LHS / 2^RHS的整数部分。这意味着右移操作会将LHS的二进制表示向右移动RHS位,高位丢失,低位补零。
有符号右移
- 对于非负的有符号整数(
signed)的右移操作,LHS >> RHS的值同样是LHS / 2^RHS的整数部分,与无符号右移类似。 - 对于负数的有符号整数(
signed),LHS >> RHS的行为由具体实现定义。大多数实现采用算术右移,这意味着右移操作会保留原来的符号位(最左边的位),高位丢失,新生成的高位填充原来符号位的值(如果是负数,则填充1,如果是非负数,则填充0)。这种行为确保了负数右移后依然保持负数。
使用小技巧:
位运算在编程中可以用来实现一些巧妙的操作,尤其是在需要高效处理二进制数据或资源受限的环境中。
奇偶校验:可以使用按位与运算符 `&` 来快速判断一个整数是否为偶数。如果一个整数与1进行按位与操作的结果为0,那么这个数就是偶数;否则,它是奇数。
快速交换:使用异或运算符 `^` 可以在不使用额外变量的情况下交换两个变量的值。
快速设置或清除位:可以使用按位或 `|` 和按位与 `&` 来设置或清除一个整数中的特定位。
快速翻转位:使用按位异或 `^` 来翻转一个整数中的特定位。
(二)逻辑运算符
用于进行逻辑运算,并且产生一个int类型的值。如果表达式为真,这个值为1,不然为0。运算符&&和||的操作数计算次序是从左到右,如果左操作数的值已经能决定整个计算的结果,那么右操作数就根本不会计算,这称为逻辑短路
| 运算符 | 说明 |
|---|---|
| && | 逻辑与 |
| || | 逻辑或 |
| ! | 逻辑非 |
// 对于任何数值,如果不是0,则相当于true,否则为false
1 && 0 => false
1 || 0 ==> true
// 短路现象
a = 1;
b = 3;
a > 3 && b = 4; // b的值不会改变,因为a > 3就已经决定了这个表达式为false(三)比较运算符
用于比较两个值之间的关系,并且产生一个int类型的值。如果指定的关系成立,这个值为1,不然为0
| 运算符 | 说明 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
(四)赋值运算符
用于将一个值赋给一个变量。例如,a = b 表示将变量 b 的值赋给变量 a。
| 运算符 | 示例 | 相当于 |
|---|---|---|
| = | a = b | a = b |
| += | a += b | a = a+b |
| -= | a -= b | a = a-b |
| /= | a /= b | a = a / b |
| %= | a %= b | a = a % b |
| &= | a &= b | a = a & b |
| |= | a |= b | a = a | b |
| ^= | a ^= b | a = a ^b |
| >>= | a >>= b | a = a >> b |
| <<= | a <<= b | a = a << b |
除了第一个运算符,其它的称之为复合运算符,与其等价运算相比,执行速度更快
(五)自增和自减运算符
自增和自减运算符就其运算结果而言,无异于
但是,却不止于此,
int a = 1;
int b = 1;
int c = a++;
int d = ++b;
printf("%d, %d, %d, %d", a,b,c,d);

最终a和b都变成了2,因为它们都++,但是它们++的行为不同,a在++前将值给了c,b在++后才把值给了d。
所以,表达式中使用前缀自增时,变量的值先被增加1,然后再用于后续计算,使用后缀自增时,变量的值首先用于当前表达式的计算,之后才增加1。--类似。
(六)其它运算符
在其他运算符中,这里只介绍三个,其它的后面讨论
| 运算符 | 说明 | 示例/说明 |
|---|---|---|
|
| 以字节为单位,计算操作数的空间大小 |
、 |
|
| 表达式1 ? 表达式2 : 表达式 3 | 当表达式1为真,执行表达式2,否则表达式3 |
|
| 表达式1,表达式2,.....,表达式n | 顺序处理n个表达式,最后一个表达式的类型和值作为整个表达式的结果 |
sizeof运算符用于计算某个类型的内存占用大小,操作数可以是一个值、一个类型或者是一个表达式,但无论是什么都会将其的数据类型作为计算对象,后面的括号不是必须的,只要能够让sizeof正确识别到即可。

逗号运算符一般而言,仅仅是作为一个分隔符,具体的操作读者可以去尝试。
三目运算符,在很多时候具有不错的灵活性,比如求三个数之中的最大值
四、数据类型转换
考虑以下一个程序运算场景:
int a = 12 + 3.14;
// 12 默认为int类型
// 3.14默认为double类型- 不同类型的变量怎么相运算?(数据类型自动转换)
- 赋给一个变量与其数据类型不相同的值时怎么处理?(赋值数据类型转换)
这就涉及到数据类型的转换问题,只有统一数据类型才能相操作。
(一)类型自动转换
类型自动转换是在运算时系统自动完成的,转换规则为级别低的类型向级别高的转换,即存储位数少的向存储位数多的转换。
当一个运算符的几个操作数类型不同时,就需要通过一些规则把它们转换为某种共同的类型。一般来说,自动转换是指把“比较窄的”操作数转换为“比较宽的”操作数,并且不丢失信息的转换,例如,在计算表达式 f+i 时,将整型变量 i 的值自动转换为浮点型(这里的变量 f 为浮点型)。
这种由于在运算中,操作数的类型的不同而导致的类型自动转换,我们称之为隐式转换(Implicit conversions)。
隐式转换一般发生在以下情况
- (赋值转换)Conversion as if by assignment
- (类型提升)Default argument promotions(函数调用时)
- (算术转换)Usual arithmetic conversions
When an expression is used in the context where a value of a different type is expected, conversion may occur。
当表达式在需要不同类型值的上下文中使用时,可能会发生转换。
(二)赋值转换
在赋值运算时,当赋值运算符两边的操作数类型不一致时,将右侧操作数的运算结果类型转换为左侧的数据类型:
- 整型给实型,整数部分不变,以浮点数形式储存到变量中
- 实型给整型,舍弃小数部分,不四舍五入
- 字符型给整型,数值不变,将字符变量的8个二进制位存入整型变量的低8位中
- 整型给字符型,将整型低8位存入字符型变量中
- float给double,数值不变,位数增加
- double给float,截取double型的前7位有效数字
- 当单双引号
''中的字符不止一个且不是转义字符,赋值给一个字符变量时,取后八位,一般即最后一个字符
下面通过一个小程序来说明这种转换:
char c = 250;
unsigned char d = c + 249;
char f = c + 249;问c、d、f为何值?
对于,
是默认的
类型,所以只取低八位数值给c,
的二进制为
,所以
的内存数据就是这八位,不过注意
是有符号的,最高位为符号位,这就意味着
本身的
类型把这个数据解释为一个负数的补码(数值一般都是以补码形式存储),它对应的真值的计算方式为
符号位不变,其余位为取反后的二进制数值加一,得到的就是在数据类型
解释下的它的这块内存所表示的真值。
所以,
依然是一个
类型的数据,低八位为
。这八位数据将复制到
和
表示的内存中。注意
是无符号的数据类型变量,所以
能够正常表示这个数据(真值为正数的补码和原码相同),但是
依然是一个有符号的数据类型变量,所以一样的算法

(三)强制类型转换
也可以叫做显式类型转换(explicit type conversion),相比较于隐式,需要使用一种叫做cast的操作符。
强制类型转换允许开发者在不同类型间显式地转换数据。
在C语言中,强制类型转换的语法通常采用以下形式:
(类型说明符) 表达式
或者,对于复杂表达式或类型名较长的情况,可以使用括号包围类型说明符和表达式:
(类型说明符)(表达式)
#include <stdio.h>
int main() {
float f = 10.5;
int i;
// 强制类型转换
i = (int)f; // 将浮点数转换为整数,注意这会导致小数部分被截断
printf("Float: %.1f, Integer: %d\n", f, i);
// 复杂表达式的强制类型转换
float result = (float)(i + 1) / 2;
printf("Result: %.1f\n", result);
return 0;
}强制类型转换的注意事项
1. 数据丢失:从精度高的类型转换到精度低的类型(如从`float`到`int`)时,可能会丢失数据。例如,转换一个带有小数部分的浮点数到整数时,小数部分会被舍弃。
2. 范围检查:从大范围类型转换到小范围类型时(如从`long`到`short`),如果原值超出了目标类型的表示范围,可能会导致溢出或未定义行为。
3. 显式转换与隐式转换:强制类型转换是显式转换,与之相对的是隐式类型转换,即编译器自动进行的类型转换。在某些情况下,显式转换可以防止编译器进行不希望的隐式转换。
4.类型兼容性:并非所有类型都能相互转换。例如,指针类型之间的转换通常需要特别注意,以确保转换后的指针仍然指向合法的内存区域。
5.浮点数到整数转换:从浮点数转换到整数时,C语言规定转换将舍去小数部分,而不是四舍五入。
(四)数据溢出
每一种基本数据类型,尽管大小不一,但是所占空间是确定的,如果赋予其超过其范围的数据,就会有问题,就像往一个无盖的1m正方体盒子里面注超过1立方米的水,就会溢出。
整数溢出
整数溢出可以分为有符号整数溢出和无符号整数溢出。
-
有符号整数溢出:
- 当一个有符号整数增加到最大值(通常是
INT_MAX)后再增加,或者减少到最小值(通常是INT_MIN)后再减少时,会发生溢出。 - 在这种情况下,数值将“环绕”(wrap around),从最大值变到最小值,或从小到最大。
- 这种行为在C标准中是未定义的(undefined behavior),意味着编译器可以自由选择如何处理这种情况,这可能导致难以预料的程序行为。
- 当一个有符号整数增加到最大值(通常是
-
无符号整数溢出:
- 无符号整数没有负数的概念,它们只表示非负数。
- 当无符号整数达到其最大值后再次增加时,它会从0开始计数,这也是“环绕”。
- 不同于有符号整数,无符号整数的这种行为在C语言中是定义明确的,它将执行模运算。
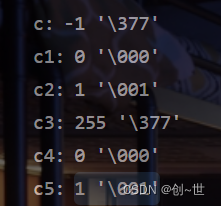
以下为一个简单的变量溢出测试,其中char是 有符号且最大可表示127,unsigned char最大可表示255。可以发现unsigned char类型的变量的确有环绕现象。
至于为什么c是-1,这就涉及到数值的存储。255二进制表示为1111 1111,赋值时直接存在c中,而内存中的数据一般是默认为真值的补码形式,恰好char类型是有符号的,1111 1111被解释为-1的补码。

浮点数溢出
浮点数也可能发生溢出,但通常称为上溢(overflow)或下溢(underflow)。当浮点数的值太大或太小而不能表示时,可能发生以下情况:
- 上溢:数值太大,被表示为无穷大(
+INF或-INF)。 - 下溢:数值太小,接近于零,可能被表示为零。
浮点数的溢出,可参考以下示意图,这里不多展开了。


敬读者:
由于文章篇幅过长,可能导致叙述逻辑的不严密、不连贯,还请读者体谅。另外,本文仅作为个人的理解,不代表任何专业性的见解。不得不承认,文章在某些地方可能有划水现象,希望读者自我甄别。
- 2024/7/5:补充了一些知识,并修改了一些不妥之处
- 2024/7/6:增加了示例















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









