







Project2
主要借鉴了etcd的raft实现,和上层存储,网络等,解耦合,是一个线性的状态机,不需要考虑并发问题。
MIT6824的raft就要考虑大量的并发。并且,这个处于生产级别的考虑。kv也是做成了LSM tree。
因为在数据量大的情况下,kv存储不能fit内存,需要做成lsm-tree提高效率。同时做成了LSM-tree的话,要考虑多持久化一个applyIndex。hardState里面持久化了Log, term, vote。实际上term和vote实际上是确定时间的。log是用来记录操作用于回放的。
func (r *Raft) Step(m pb.Message) error {
// Your Code Here (2A).
if _, ok := r.Prs[r.id]; !ok && len(r.Prs) != 0 {
log.Infof("%d do not exist and have other peers return, term %d, Prs %+v\n", r.id, r.Term, r.Prs)
return nil
}
switch r.State {
case StateFollower:
if m.MsgType == pb.MessageType_MsgHup {
r.handleMsgUp()
}
if m.MsgType == pb.MessageType_MsgAppend {
r.handleAppendEntries(m)
}
if m.MsgType == pb.MessageType_MsgRequestVote {
r.handleRequestVote(m)
}
if m.MsgType == pb.MessageType_MsgHeartbeat {
r.handleHeartbeat(m)
}
if m.MsgType == pb.MessageType_MsgSnapshot {
r.handleSnapshot(m)
}
if m.MsgType == pb.MessageType_MsgTimeoutNow {
r.handleMsgTimeOut(m)
}
if m.MsgType == pb.MessageType_MsgTransferLeader {
r.handleTransferNotLeader(m)
}
case StateCandidate:
if m.MsgType == pb.MessageType_MsgHup {
r.handleMsgUp()
}
if m.MsgType == pb.MessageType_MsgAppend {
r.handleAppendEntries(m)
}
if m.MsgType == pb.MessageType_MsgRequestVote {
r.handleRequestVote(m)
}
if m.MsgType == pb.MessageType_MsgRequestVoteResponse {
r.handleRequestVoteResponce(m)
}
if m.MsgType == pb.MessageType_MsgHeartbeat {
r.handleHeartbeat(m)
}
case StateLeader:
if m.MsgType == pb.MessageType_MsgBeat {
r.broadcastHeartBeat()
}
if m.MsgType == pb.MessageType_MsgPropose {
r.handleMsgPropose(m)
}
if m.MsgType == pb.MessageType_MsgAppend {
r.handleAppendEntries(m)
}
if m.MsgType == pb.MessageType_MsgAppendResponse {
r.handleAppendResponse(m)
}
if m.MsgType == pb.MessageType_MsgRequestVote {
r.handleRequestVote(m)
}
if m.MsgType == pb.MessageType_MsgHeartbeatResponse {
r.handleHeartbeatResponse(m)
}
if m.MsgType == pb.MessageType_MsgTransferLeader {
r.handleTransfer(m)
}
}
return nil
}通过外层一些命令啊,msg信息输入,我们会得到一些新的msg,和raft的新状态。然后我们就可以在上层做处理了
如果有这些变化的话,我们就需要做处理,apply committedENtry, 发生给别的节点信息。持久化log,term, vote。应用快照等。
func (rn *RawNode) Ready() Ready {
// Your Code Here (2A).
// snapshot, err := rn.Raft.RaftLog.storage.Snapshot()
// if err != nil {
// panic(err)
// }
rd := Ready{
Messages: rn.Raft.msgs,
Entries: rn.Raft.RaftLog.unstableEntries(),
CommittedEntries: rn.Raft.RaftLog.nextEnts(),
}
if hardSt := rn.Raft.hardState(); !IsEmptyHardState(hardSt) && !isHardStateEqual(hardSt, rn.prevHardSt) {
rd.HardState = rn.Raft.hardState()
}
if !rn.Raft.softState().equal(rn.prevSoftSt) {
rd.SoftState = rn.Raft.softState()
}
if !IsEmptySnap(rn.Raft.RaftLog.pendingSnapshot) {
rd.Snapshot = *rn.Raft.RaftLog.pendingSnapshot
}
return rd
}func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) {
// Hint: you may call `Append()` and `ApplySnapshot()` in this function
// Your Code Here (2B/2C).
var err error
// raft store
applysnapresult := new(ApplySnapResult)
raftWB := new(engine_util.WriteBatch)
kvWB := new(engine_util.WriteBatch)
if !raft.IsEmptySnap(&ready.Snapshot) {
applysnapresult, _ = ps.ApplySnapshot(&ready.Snapshot, kvWB, raftWB)
if len(ready.Entries) > 0 {
if ready.Entries[0].Index <= ps.AppliedIndex() {
log.Errorf("idx{%v} applyidx{%v}", ready.Entries[0].Index, ps.AppliedIndex())
}
}
}
if err = ps.Append(ready.Entries, raftWB); err != nil {
log.Panic(err)
}
if !raft.IsEmptyHardState(ready.HardState) {
// may be stableID has change
*ps.raftState.HardState = ready.HardState
// if ready.HardState.Commit > ps.raftState.LastIndex {
// ps.raftState.LastIndex = ready.HardState.Commit
// }
}
if err = raftWB.SetMeta(meta.RaftStateKey(ps.region.Id), ps.raftState); err != nil {
log.Panic(err)
}
raftWB.MustWriteToDB(ps.Engines.Raft)
kvWB.MustWriteToDB(ps.Engines.Kv)
return applysnapresult, nil
}然后如果日志无限的增加就要做一个snapshot,snapshot首先是要做一个压缩的,后台tick会检查压缩条件,如果满足的话,给raft发生一个log,发起通识,commit后,可以应用。
func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) {
// Hint: you may call `Append()` and `ApplySnapshot()` in this function
// Your Code Here (2B/2C).
var err error
// raft store
applysnapresult := new(ApplySnapResult)
raftWB := new(engine_util.WriteBatch)
kvWB := new(engine_util.WriteBatch)
if !raft.IsEmptySnap(&ready.Snapshot) {
applysnapresult, _ = ps.ApplySnapshot(&ready.Snapshot, kvWB, raftWB)
if len(ready.Entries) > 0 {
if ready.Entries[0].Index <= ps.AppliedIndex() {
log.Errorf("idx{%v} applyidx{%v}", ready.Entries[0].Index, ps.AppliedIndex())
}
}
}
if err = ps.Append(ready.Entries, raftWB); err != nil {
log.Panic(err)
}
if !raft.IsEmptyHardState(ready.HardState) {
// may be stableID has change
*ps.raftState.HardState = ready.HardState
// if ready.HardState.Commit > ps.raftState.LastIndex {
// ps.raftState.LastIndex = ready.HardState.Commit
// }
}
if err = raftWB.SetMeta(meta.RaftStateKey(ps.region.Id), ps.raftState); err != nil {
log.Panic(err)
}
raftWB.MustWriteToDB(ps.Engines.Raft)
kvWB.MustWriteToDB(ps.Engines.Kv)
return applysnapresult, nil
}应用完成后,要把raft推进到下一个状态。这就是一个比较完整的raft周期了。
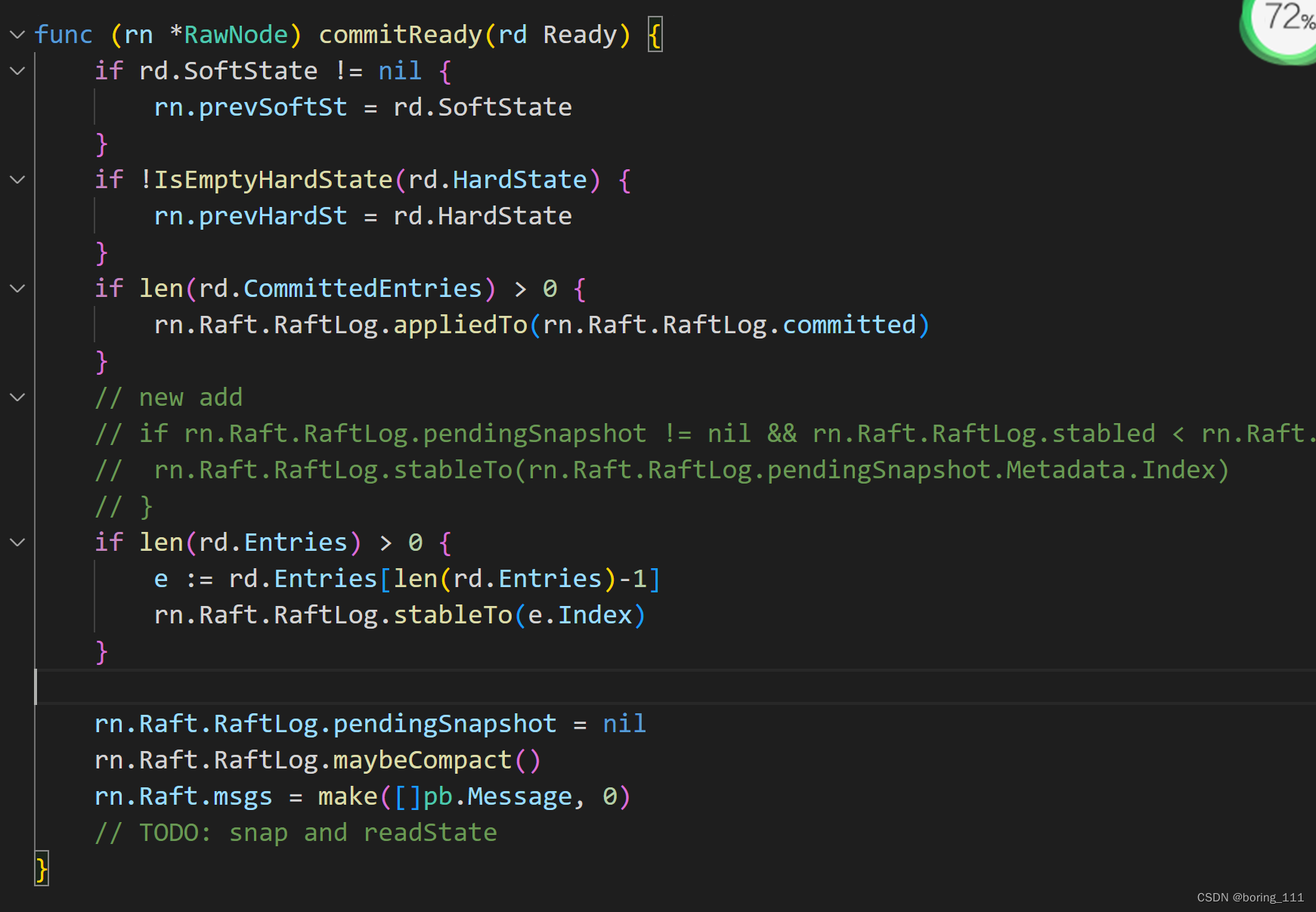
大体流程就介绍完了。
project3
这个地方实现了transfer leader和confChange
还是可以说说的。
transfer leader
leadership transfer可以把raft group中的leader身份转给其中一个follower。这个功能可以用来做负载均衡,比如可以把leader放在性能更好的机器或者离客户端更近的机器上。
大概原理就是保证transferee(transfer的目标follower)拥有和原leader有一样新的日志,期间需要停写,然后给transferee发送一个特殊的消息,让这个follower可以马上进行选主,而不用等到election timeout,正常情况下,这个follower的term最大,当选,原来的leader变为备。
由于transferee明确知道是transfer,就没有必要采用这种两阶段的选主,所以传入的参数是campaignTransfer(etcd实现)etcd raft如何实现leadership transfer - 知乎
confChange
raft论文里面的单步变更,就是一次apply只变更一个,提交后才能变更下一个。
// removeNode remove a node from raft group
func (r *Raft) removeNode(id uint64) {
// Your Code Here (3A).
r.PendingConfIndex = 0
log.Infof("node{%v} remove node{%v}", r.id, id)
newPeers := make([]uint64, 0)
// if r.id == id {
// r.becomeFollower(r.Term, None)
// }
for _, peer := range r.peers {
if peer != id {
newPeers = append(newPeers, peer)
}
}
r.peers = newPeers
delete(r.Prs, id)
if len(r.peers) != 0 {
if r.maybeCommit() {
r.broadcastAppendEntry()
}
}
if r.State == StateLeader && r.leadTransferee == id {
r.abortLeaderTransfer()
}
}
1.我看etcd是单步变更是直接把变更作为一条commit后才生效的日志来做的,没有两次日志提交吧。大佬这里说的是日志到了,就马上生效的情况,才是两次提交吗?
2.还有一个疑惑就etcd应该是一次只能apply一个config,但是etcd分了两部分来检查这个,一个是发起选举时候检查apply -> commit部分不能存在config日志,一个是变成leader时检查是commit->最后,是否存在单条config日志。为啥不直接检查是否存在apply ->最后,而要分成两次来做检查?我的理解是为了防止follower在应用log在 apply->commit之间的这个过程没完成,crash了,然后变成leader的话,要做个处理,也就是等待上层做完下次handleRaftReady。不知道还有没有别的什么更深的原因。希望大佬能解答一下
我是没有按照这个来实现tinykv的,只用了一个apply之后的log,可能会导致后面panic了。但是可以做一下修改。有空可以做一下修改。
然后就是3b做的一些命令的应用了。
比如confChange
比如我们增加节点的命令要递增confversion,然后根据元数据,缓存等。
func (d *peerMsgHandler) processConfChange(entry *eraftpb.Entry, cc *eraftpb.ConfChange, KVwb *engine_util.WriteBatch) *engine_util.WriteBatch {
cmd := new(raft_cmdpb.RaftCmdRequest)
if err := cmd.Unmarshal(cc.Context); err != nil {
panic(err)
}
request := cmd.AdminRequest
changeNodeId := request.GetChangePeer().Peer.Id
if d.IsLeader() {
log.Infof("leaderNode{%v} changeConf{%v {%v}}", d.Tag, cc.ChangeType, cc.NodeId)
if d.RaftGroup.Raft.PendingConfIndex != entry.Index {
log.Panicf("pendConfIndex{%v} entryIdx{%v}", d.RaftGroup.Raft.PendingConfIndex, entry.Index)
}
}
if request.GetChangePeer().ChangeType == eraftpb.ConfChangeType_AddNode {
log.Infof("{%v} add node{%v}", d.Tag, changeNodeId)
for _, peer := range d.peerStorage.region.Peers {
if peer.Id == changeNodeId {
log.Infof("node{%v} has existed, no need to add", changeNodeId)
return KVwb
}
}
d.peerStorage.region.RegionEpoch.ConfVer++
d.peerStorage.region.Peers = append(d.peerStorage.region.Peers, request.ChangePeer.Peer)
log.Infof("{%v} increase {%v} Peers{%v}", d.Tag, d.peerStorage.region.RegionEpoch.ConfVer, d.peerStorage.region.Peers)
d.RaftGroup.ApplyConfChange(eraftpb.ConfChange{ChangeType: eraftpb.ConfChangeType_AddNode, NodeId: changeNodeId})
meta.WriteRegionState(KVwb, d.peerStorage.region, rspb.PeerState_Normal)
metaStore := d.ctx.storeMeta
metaStore.Lock()
metaStore.regions[d.regionId] = d.peerStorage.region
metaStore.regionRanges.ReplaceOrInsert(®ionItem{d.peerStorage.region})
metaStore.Unlock()
d.insertPeerCache(request.ChangePeer.Peer)
// d.PeersStartPendingTime[changeNodeId] = time.Now()
}
if request.GetChangePeer().ChangeType == eraftpb.ConfChangeType_RemoveNode {
log.Infof("{%v} remove node{%v}", d.Tag, changeNodeId)
exit_flag := true
if len(d.peerStorage.region.Peers) == 2 {
log.Errorf("err only have 2 nodes")
}
for _, peer := range d.peerStorage.region.Peers {
if peer.Id == changeNodeId {
exit_flag = false
break
}
}
if exit_flag {
log.Infof("node{%v} has no existed, need to break", changeNodeId)
return KVwb
}
if d.storeID() == request.ChangePeer.Peer.StoreId {
d.destroyPeer()
return KVwb
}
d.RaftGroup.ApplyConfChange(eraftpb.ConfChange{ChangeType: eraftpb.ConfChangeType_RemoveNode, NodeId: changeNodeId})
newPeers := make([]*metapb.Peer, 0)
for _, Peer := range d.peerStorage.region.Peers {
if Peer.Id != changeNodeId {
newPeers = append(newPeers, Peer)
}
}
d.peerStorage.region.RegionEpoch.ConfVer++
log.Infof("{%v} increase {%v} Peers{%v}", d.Tag, d.peerStorage.region.RegionEpoch.ConfVer, d.peerStorage.region.Peers)
d.peerStorage.region.Peers = newPeers
meta.WriteRegionState(KVwb, d.peerStorage.region, rspb.PeerState_Normal)
metaStore := d.ctx.storeMeta
metaStore.Lock()
metaStore.regions[d.regionId] = d.peerStorage.region
metaStore.Unlock()
d.removePeerCache(changeNodeId)
// delete(d.PeersStartPendingTime, changeNodeId)
}
// localState.Region = d.peerStorage.region
// KVwb.SetMeta(meta.RegionStateKey(d.regionId), localState)
d.peerStorage.applyState.AppliedIndex = entry.Index
KVwb.SetMeta(meta.ApplyStateKey(d.regionId), d.peerStorage.applyState)
KVwb.WriteToDB(d.ctx.engine.Kv)
KVwb = new(engine_util.WriteBatch)
resp := newResp()
d.processCallback(entry, resp, false)
if d.IsLeader() {
log.Infof("leaderNode{%v} send heartbeat", d.Tag)
d.HeartbeatScheduler(d.ctx.schedulerTaskSender)
}
return KVwb
}split也是差不多的原理,要注意的是key range实际上是一个环。更新version,注册peer,本地的就行了(region的follower和leader都要处理这个分裂),要把新的peer注册到路由上。
if request.CmdType == raft_cmdpb.AdminCmdType_Split {
if requests.Header.RegionId != d.regionId {
regionNotFound := &util.ErrRegionNotFound{RegionId: requests.Header.RegionId}
d.processCallback(entry, ErrResp(regionNotFound), false)
log.Warning(regionNotFound)
return KVwb
}
if errEpochNotMatch, ok := util.CheckRegionEpoch(requests, d.Region(), true).(*util.ErrEpochNotMatch); ok {
d.processCallback(entry, ErrResp(errEpochNotMatch), false)
log.Warning("stale{%v}", errEpochNotMatch)
return KVwb
}
if err := util.CheckKeyInRegion(request.Split.SplitKey, d.Region()); err != nil {
d.processCallback(entry, ErrResp(err), false)
log.Warning(err)
return KVwb
}
if len(d.Region().Peers) != len(request.Split.NewPeerIds) {
d.processCallback(entry, ErrRespStaleCommand(d.Term()), false)
log.Warning("peers num diff")
return KVwb
}
Peers := make([]*metapb.Peer, 0)
for _, peer := range d.peerStorage.region.Peers {
newPeer := new(metapb.Peer)
*newPeer = *peer
Peers = append(Peers, newPeer)
}
for i, peerId := range request.Split.NewPeerIds {
Peers[i].Id = peerId
}
newRegion := new(metapb.Region)
newRegion.Id = request.Split.NewRegionId
newRegion.StartKey = request.Split.SplitKey
newRegion.EndKey = d.peerStorage.region.EndKey
newRegion.RegionEpoch = &metapb.RegionEpoch{ConfVer: InitEpochConfVer, Version: InitEpochVer}
newRegion.Peers = Peers
metaStore := d.ctx.storeMeta
metaStore.Lock()
metaStore.regionRanges.Delete(®ionItem{region: d.peerStorage.region})
d.Region().EndKey = request.Split.SplitKey
d.peerStorage.region.RegionEpoch.Version++
metaStore.regions[d.peerStorage.region.Id] = d.peerStorage.region
metaStore.regions[request.Split.NewRegionId] = newRegion
metaStore.regionRanges.ReplaceOrInsert(®ionItem{newRegion})
metaStore.regionRanges.ReplaceOrInsert(®ionItem{d.peerStorage.region})
metaStore.Unlock()
newRegionState := new(rspb.RegionLocalState)
oldRegionState := new(rspb.RegionLocalState)
newRegionState.State = rspb.PeerState_Normal
newRegionState.Region = newRegion
oldRegionState.State = rspb.PeerState_Normal
oldRegionState.Region = d.peerStorage.region
KVwb.SetMeta(meta.RegionStateKey(request.Split.NewRegionId), newRegionState)
KVwb.SetMeta(meta.RegionStateKey(d.peerStorage.region.Id), oldRegionState)
d.peerStorage.applyState.AppliedIndex = entry.Index
KVwb.SetMeta(meta.ApplyStateKey(d.peerStorage.region.Id), d.peerStorage.applyState)
KVwb.WriteToDB(d.ctx.engine.Kv)
KVwb = &engine_util.WriteBatch{}
newPeer, err := createPeer(d.storeID(), d.ctx.cfg, d.ctx.regionTaskSender, d.ctx.engine, newRegion)
if err != nil {
panic(err)
}
d.ctx.router.register(newPeer)
d.ctx.router.send(newRegion.Id, message.NewMsg(message.MsgTypeStart, nil))
log.Warningf("Node{%v} split key{%v} oldRegion{%v} newRegion{%v}", d.Tag, request.Split.SplitKey, d.peerStorage.region.Id, request.Split.NewRegionId)
if d.IsLeader() {
log.Infof("leaderNode{%v} send heartbeat split", d.Tag)
d.notifyHeartbeatScheduler(oldRegionState.Region, d.peer)
d.notifyHeartbeatScheduler(newRegionState.Region, newPeer)
}
resp := newResp()
resp.Header = &raft_cmdpb.RaftResponseHeader{}
resp.AdminResponse = &raft_cmdpb.AdminResponse{
CmdType: raft_cmdpb.AdminCmdType_Split,
Split: &raft_cmdpb.SplitResponse{Regions: []*metapb.Region{newRegion, d.peerStorage.region}},
}
resp.AdminResponse.CmdType = raft_cmdpb.AdminCmdType_Split
d.processCallback(entry, resp, false)
}3c就是一个region负载均衡,就是每个store节点负载region的peer迁移















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









