






项目背景
狗狗品种分类是一项经典的计算机视觉任务,Kaggle上提供了该数据集的竞赛。我将使用深度学习框架PyTorch和ResNet18预训练模型来构建一个分类器,该模型将能够识别120种不同品种的狗。
数据集的处理
1.数据集的获取
本次的数据集来源于kaggle项目狗狗种类识别中的数据集 Standford Dogs Dataset,对其进行下载解压后文件的目录格式为

其中train和test根目录下为图片,labels为训练集中每个图片对应label,sample_submission为测试集和最终给出的csv格式范例
2.数据集的预处理
本次为了简单起见,我将训练集的图片数据分成了三份,先将训练集的百分之80作为新的训练集,另外百分之20作为测试集,再把新的训练集的百分之25作为验证集,剩下的则作为最后的训练集
训练集的标签信息在label.csv中,id表示训练集中的图片文件名,Breed表示类别,一共有120种狗的类别
由于train目录中保存的是图片的id,而图片的类别保存在label.csv中,所以我们必须自己定义一个Dataset数据集对象,它可以传入一个.csv文件,从中构建一个数据集,具体操作如下:
并将图片文件名和对应标签提取出来。使用train_test_split将数据按 80% 的比例划分为训练集与测试集,再将训练集的百分之25作为验证集。
# 读取CSV文件
csv_file = 'C:\\workspace\\work1\\dog_variety_recognition\\data\\labels.csv'
df = pd.read_csv(csv_file)
label_to_index = {label: idx for idx, label in enumerate(sorted(df['breed'].unique()))}
df['breed'] = df['breed'].map(label_to_index)
# 提取文件名和标签
file_names = df['id'].values # 图像文件名
labels = df['breed'].values # 对应的标签
# 首先按 80% 训练集和 20% 测试集划分(stratify 按照标签进行分层划分)
train_files, test_files, train_labels, test_labels = train_test_split(file_names, labels, test_size=0.2, stratify=labels)
# 然后在训练集上再划分出验证集
train_files, val_files, train_labels, val_labels = train_test_split(train_files, train_labels, test_size=0.25, stratify=train_labels)3.数据的增强
为了提高模型的泛化能力,使用了torchvision中的transform一系列图像增强技术,对数据集的图像进行了一系列增强,提高其泛化能力。比如使用Resize方法重新定义其大小、使用ToTensor将图片转化为Tensor数据格式,为以后的处理铺垫、使用Normalize进行归一化处理
# 数据增强与预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
4.自定义Dataset类
在开头说过要处理这种CSV类型的文件,同时为了方便对图片进行加载与处理,所以需要编写了一个自定义的Dataset类来封装图像的加载、变换和标签的获取。
# 自定义Dataset类,基于CSV文件
class MyDataset(Dataset):
def __init__(self, file_paths, labels, root_dir, transform=None):
self.file_paths = file_paths # 图像文件名列表
self.labels = labels # 对应的标签列表
self.root_dir = root_dir # 图像存储的根目录
self.transform = transform # 图像转换
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
# 获取图像的路径
img_path = os.path.join(self.root_dir, f"{self.file_paths[idx]}.jpg")
# 加载图像
image = Image.open(img_path).convert("RGB")
label = self.labels[idx]
# 如果有图像转换,进行处理
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.long)
return image, label5.使用自定义Dataset创建各种数据集以及加载
# 使用自定义 Dataset 类创建训练集、验证集、测试集
train_dataset = MyDataset(train_files, train_labels, root_dir="C:\\workspace\\work1\\dog_variety_recognition\\data\\train", transform=transform)
val_dataset = MyDataset(val_files, val_labels, root_dir='C:\\workspace\\work1\\dog_variety_recognition\\data\\train', transform=transform)
test_dataset =MyDataset(test_files, test_labels, root_dir='C:\\workspace\\work1\\dog_variety_recognition\\data\\train', transform=transform)
# 创建 DataLoader
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
模型构建
1.ResNet预训练模型
我使用了预训练的ResNet18模型,并将其最后一层替换为适合120类输出的全连接层,以此来处理狗狗分类问题。
# 构建模型这里使用与训练好的模型ResNet
class DogTrainModel(torch.nn.Module):
def __init__(self, n_classes=120):
super(DogTrainModel, self).__init__()
self.model=models.resnet18(pretrained=True)
self.model.fc = torch.nn.Linear(512, n_classes)
def forward(self, x):
return self.model(x)2.自己创建模型
我创建了一个新的CNN模型,从头开始进行训练。这个模型会包含多个卷积层、池化层以及全连接层。
class MyCNNModule(nn.Module):
def __init__(self, n_classes=120):
super(MyCNNModule, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# 第二个卷积层
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
# 第三个卷积层
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1)
# 全连接层
self.fc1 = nn.Linear(128 * 28 * 28, 512)
self.fc2 = nn.Linear(512, n_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 卷积 + 激活 + 池化
x = self.pool(F.relu(self.conv2(x))) # 卷积 + 激活 + 池化
x = self.pool(F.relu(self.conv3(x))) # 卷积 + 激活 + 池化
x = x.view(-1, 128 * 28 * 28) # 展平
x = F.relu(self.fc1(x)) # 全连接 + 激活
x = self.fc2(x) # 输出层
return x
该模型包含3个卷积层(每个卷积层后面跟一个ReLU激活函数和最大池化层),每次池化操作将图像尺寸减半。我输入图像的尺寸为224×224,经过3次2×2的池化后变为28×28,最后我们将卷积输出展平为一维向量,并通过两层全连接层进行分类。
模型的训练以及评估
1.模型训练
我定义了模型训练的函数 train_model,通过Adam优化器和交叉熵损失函数来优化模型。训练过程输出每个 epoch 的损失值,并且在每个 epoch 结束后在验证集上计算准确率。
def train_model(model,train_loader,val_loader,criterion,optimizer,epochs=1):
for epoch in range(epochs):
model.train()
total_train_step = 0
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
total_train_step = total_train_step + 1
print("Epoch [{}/{}], Step [{}], Loss: {:.4f}".format(epoch + 1, epochs, total_train_step + 1, running_loss / (total_train_step + 1)))
model.eval()
val_labels = []
val_preds = []
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
val_labels.extend(labels.cpu().numpy())
val_preds.extend(preds.cpu().numpy())
acc = accuracy_score(val_labels, val_preds)
print("Epoch [{}/{}], Validation Accuracy: {:.4f}".format(epoch + 1, epochs, acc))这里传入的criterion和optimizer分别使用交叉熵损失函数以及Adma优化器进行损失计算以优化,学习率设置为0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)2.模型评估
训练完成后,我使用 evaluate_model 函数来对模型的表现进行评估,包括输出分类报告以及绘制混淆矩阵。
def evaluate_model(model, val_loader):
model.eval()
val_labels = []
val_preds = []
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
val_labels.extend(labels.cpu().numpy())
val_preds.extend(preds.cpu().numpy())
# 打印分类报告
print(classification_report(val_labels, val_preds))
# 绘制混淆矩阵
cm = confusion_matrix(val_labels, val_preds)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.show()调参
1.动态学习率
学习率衰减:在每个epoch后降低学习率。使用torch.optim.lr_scheduler来实现。
# 定义学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 每5个epoch降低学习率一半
在每5个epoch结束后调整学习率为原来的一半
模型测试
在模型测试中,我使用预先训练好的模型Resnet18进行训练,设定epoc为10轮,并且每经过无论将学习率减半,我创建了一个test_model函数来完成测试
# 定义测试模型的函数
def test_model(model, test_loader):
model.eval()
test_labels = []
test_preds = []
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
test_labels.extend(labels.cpu().numpy())
test_preds.extend(preds.cpu().numpy())
# 打印分类报告
print("Test Set Classification Report:")
print(classification_report(test_labels, test_preds))
# 绘制混淆矩阵
cm = confusion_matrix(test_labels, test_preds)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix (Test Set)')
plt.show()
在模型训练完成后,调用该函数,传入模型以及测试加载集
train_model(model, train_loader, val_loader, criterion, optimizer)
test_model(model, test_loader)经过等待时间后,会打印出相关的测试分类报告
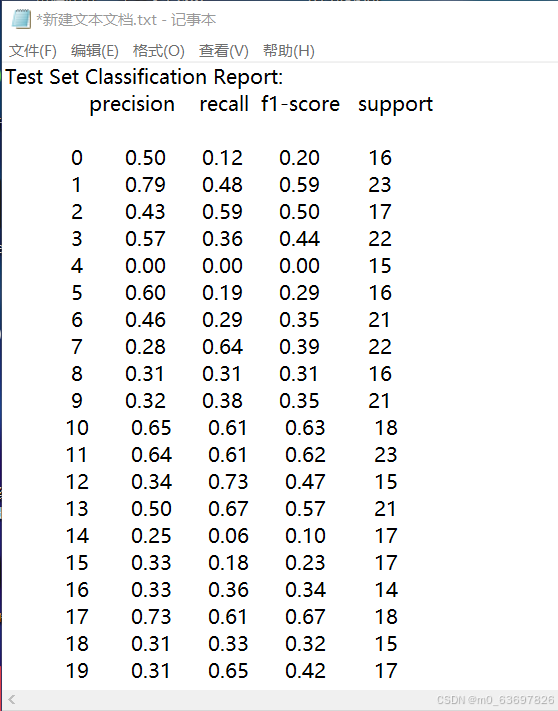
对于测试集中的2045张图片,第一列为狗狗的种类,最后一列support为狗狗对应的种类总数,这里用数字代替每一个种类,其他三个为相关的参数。
同时以tensorboard来展示相关测试集的准确率和损失
补充
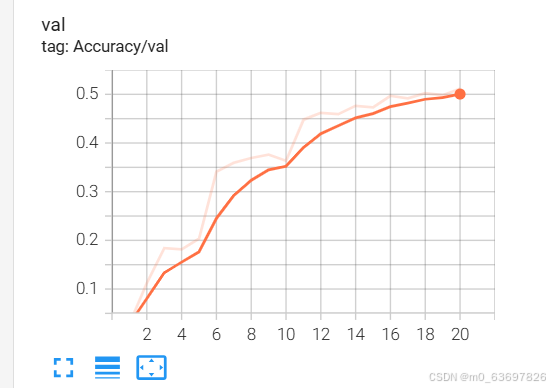
由于该模型我只训练了20轮,从上面的图可以看出该模型的准确率只能达到百分之50左右,可能是因为该数据集的狗狗种类太多(120种)且我训练的次数太少,这里我自己利用pytorch提供的一个小数据集来进行另一个实验,即CIFAR10数据集,该数据集只有十种类别,也是进行图片的分类功能。这里直接给上代码,其框架和上述模型是一致的,且较为简单,这里就直接贴上整体代码,主要是看我创建的神经网络模型的效果如何。
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model(x) # 前向传播时调用模型
return x # 返回输出
transform = transforms.Compose([
transforms.ToTensor()
])
train_data=torchvision.datasets.CIFAR10(root='C:\\workspace\\work1\\data', train=True, download=False,transform=transform)
test_data=torchvision.datasets.CIFAR10(root='C:\\workspace\\work1\\data', train=False, download=False,transform=transform)
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
# 创建网络模型
model = MyCNN()
# 创建损失函数
loss_fn=nn.CrossEntropyLoss()
# 定义学习率和优化器
learn_rate=0.01
optimizer=torch.optim.SGD(model.parameters(),lr=learn_rate)
# 开始训练
total_train_step=0
total_test_step=0
epoch=20
writer=SummaryWriter(log_dir='./logs')
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
model.train() # 切换到训练模式
for data in train_dataloader:
image, label = data
outputs=model(image)
loss=loss_fn(outputs,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100 == 0: # 每 100 步打印一次损失
print("训练次数: {} Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
model.eval()
total_accuracy=0
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
image, label = data
outputs=model(image)
loss=loss_fn(outputs,label)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1) == label).sum()
total_accuracy=total_accuracy+accuracy
print("整个测试集上的损失为:{}".format(total_test_loss))
print("整个测试集上的准确率为:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_accuracy", total_accuracy/test_data_size,total_test_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step=total_test_step+1
writer.close()这里展示一些输出效果
这是测试集准确率的曲线图
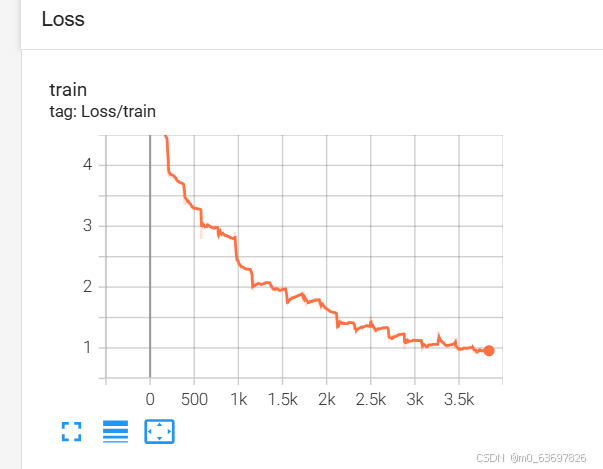
这是总体损失的曲线图,这里达到100多的损失率是因为没有取平均值
总结收获和反思
1.总结
在本次项目中,我构建并训练了一个用于狗狗种类识别的深度学习模型。主要的流程包括数据的加载与预处理、模型的构建与训练、模型调参以及模型评估。我利用了已经训练好的模型ResNet的迁移学习方法,并且也自己构建了一个卷积神经网络模型,并通过模型的训练。通过分类报告和混淆矩阵的分析,进行可视化分析。
2.收获
在本次项目的构建中,我学会了以下几点:
1.当数据的标签被存放到一个CSV文件中时,如何使用pandas方法去读取标签并且进行路径拼接将数据集获取
2.学会了使用torchvision中transform对图像进行一些处理,增强图像的泛化能力
3.学会了自己自定义一个Dataset类来继承torch中自带的Dataset类,并且加入相关所需要的功能
4.学会了自己构建一神经网络模型,学习了卷积层的内部原理、最大池化的使用、非线性激活等等
5.学会了去pytorch官网去找torch类中预先训练好的各种模型,各种模型对应于不同的任务项目,我本次完成的狗狗种类识别就是一个图像的分类任务,所以可以使用预先训练好的模型Resnet18
6.学会了损失函数的使用以及优化器的使用,学会了去官网找各种损失函数的解释,什么样类型的任务利用什么样的损失函数,以及优化器中各种优化方式的解释
7.理解了利用反向传播来进行调优,利用计算出的梯度值,采用优化算法(如梯度下降、Adam等)来更新神经网络的权重和偏置。
8.学会了模型训练的整体框架以及模型评估的整体框架的搭建
3.反思
对于反思我有以下几点:
1.对于神经网络模型的构建我还需要继续深入去研究如何才能够搭建一个好的神经网络模型
2.对于不同数据集的获取我需要学习不同的数据集的获取方式
3.虽然在本次项目中我进行了多个参数的调节,但这是远远不够的,后续我会学习其他参数的调节方式
4.本项目没有使用五折交叉验证的方式来评估模型,我后续也会学习如何使用五折交叉验证来进行模型的评估

















 5829
5829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









