







拿卷积网络识别MNIST图像举例
复习一下该程序的完整代码,并通过model.summary方法显示网络的结构,用图形的方式显示出这个有225034个参数、用序贯方式生成的卷积网络的形状。呈现出卷积神经网络的大体结构。
from keras import models # 导入Keras模型和各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = models.Sequential() # 序贯模型
model.add(Conv2D(filters=32, # 添加Conv2D层, 指定过滤器的个数, 即通道数
kernel_size=(3, 3), # 指定卷积核的大小
activation='relu', # 指定激活函数
input_shape=(28, 28, 1))) # 指定输入数据样本张量的类型
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加Max Pooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加Max Pooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 添加展平层
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活, 输出10维分类码
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定评估指标
model.summary() # 显示网络模型
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
max_pooling2d_4 (MaxPooling (None, 13, 13, 32) 0
2D)
conv2d_5 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_5 (MaxPooling (None, 5, 5, 64) 0
2D)
dropout_4 (Dropout) (None, 5, 5, 64) 0
flatten_2 (Flatten) (None, 1600) 0
dense_4 (Dense) (None, 128) 204928
dropout_5 (Dropout) (None, 128) 0
dense_5 (Dense) (None, 10) 1290
=================================================================
Total params: 225,034
Trainable params: 225,034
Non-trainable params: 0
_________________________________________________________________卷积网络也是多层的神经网络,但是层内和层间神经元的类型和连接方式与普通神经网络不同。卷积神经网络由输入层、一个或多个卷积层和输出层的全连接层组成。
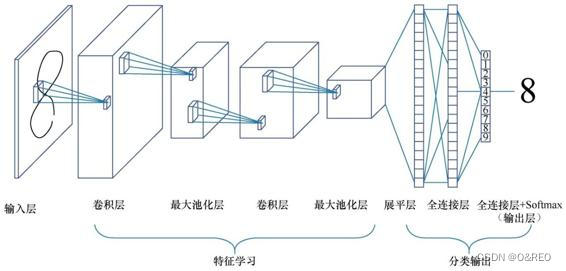
(1)网络左边仍然是数据输入部分,对数据做一些初始处理,如标准化、图片压缩、降维等工作,最后输入数据集的形状为 (样本,图像高度,图像宽度,颜色深度)。
(2)中间是卷积层,这一层中,也有激活函数的存在,示例中用的是ReLU。
(3)一般卷积层之后接一个池化层,池化层包括区域平均池化或最大池化。
(4)通常卷积+池化的架构会重复几次,形成深度卷积网络。在这个过程中,图片特征张量的尺寸通常会逐渐减小,而深度将逐渐加深。如上一张图所示,特征图从一张扁扁的纸片形状变成了胖胖的矩形。
(5)之后是一个展平层,用于将网络展平。
(6)展平之后接一个普通的全连接层。
(7)最右边的输出层也是全连接层,用Softmax进行激活分类输出层,这与普通神经网络的做法一致。
(8)在编译网络时,使用了Adam优化器,以分类交叉熵作为损失函数,采用了准确率作为评估指标。
1载入StanfordDogsDataset
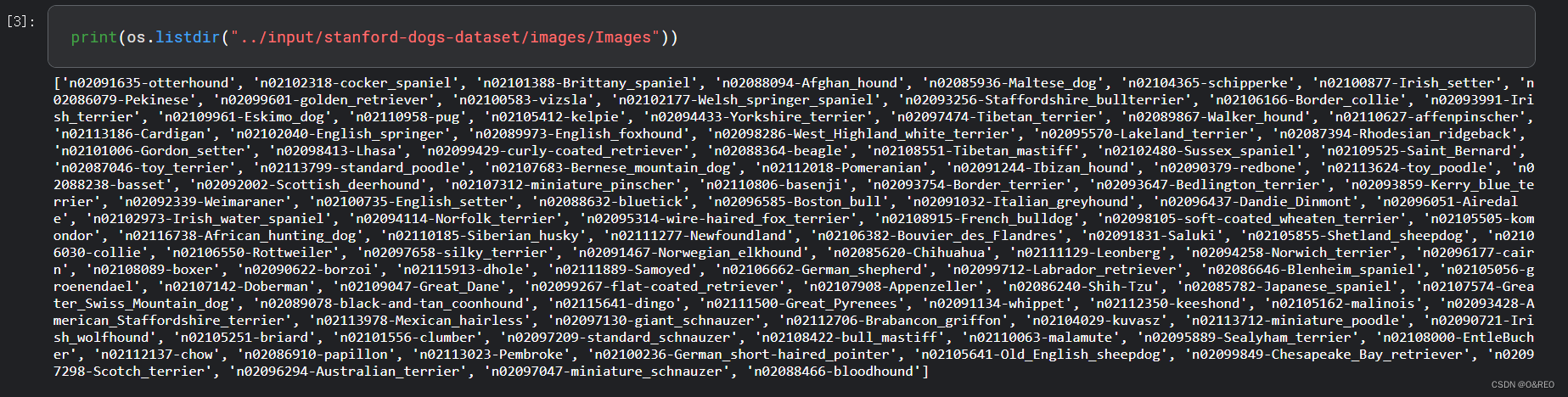
# 本示例只处理10种狗
dir = '../input/stanford-dogs-dataset/images/Images/'
chihuahua_dir = dir+'n02085620-Chihuahua' #吉娃娃
japanese_spaniel_dir = dir+'n02085782-Japanese_spaniel' #日本狆
maltese_dir = dir+'n02085936-Maltese_dog' #马尔济斯犬
pekinese_dir = dir+'n02086079-Pekinese' #狮子狗
shitzu_dir = dir+'n02086240-Shih-Tzu' #西施犬
blenheim_spaniel_dir = dir+'n02086646-Blenheim_spaniel' #英国可卡犬
papillon_dir = dir+'n02086910-papillon' #蝴蝶犬
toy_terrier_dir = dir+'n02087046-toy_terrier' #玩具猎狐梗
afghan_hound_dir = dir+'n02088094-Afghan_hound' #阿富汗猎犬
basset_dir = dir+'n02088238-basset' #巴吉度猎犬
import cv2 # 导入Open CV工具库
X = []
y_label = []
imgsize = 150
# 定义一个函数读入狗狗图像
def training_data(label, data_dir):
print ("正在读入🐕"+ data_dir)
for img in os.listdir(data_dir):
path = os.path.join(data_dir, img)# 图像文件的完整路径
img = cv2.imread(path, cv2.IMREAD_COLOR)# 以彩色图像方式加载图像数据
img = cv2.resize(img, (imgsize, imgsize))# 调整图像大小
X.append(np.array(img))# 将图像数据添加到列表X中
y_label.append(str(label))
# 读入10个目录中的狗狗图像
training_data('chihuahua', chihuahua_dir)
training_data('japanese_spaniel', japanese_spaniel_dir)
training_data('maltese', maltese_dir)
training_data('pekinese', pekinese_dir)
training_data('shitzu', shitzu_dir)
training_data('blenheim_spaniel', blenheim_spaniel_dir)
training_data('papillon', papillon_dir)
training_data('toy_terrier', toy_terrier_dir)
training_data('afghan_hound', afghan_hound_dir)
training_data('basset', basset_dir)
print("🐕🐕🐕")
 🐕🐕🐕
🐕🐕🐕
此时X和y仍是Python列表,而不是NumPy数组。
2构建X、y张量
下面的代码用于构建X、y张量,并将标签从文本转换为One-hot格式的分类编码:
from sklearn.preprocessing import LabelEncoder # 导入标签编码工具
from keras.utils.np_utils import to_categorical # 导入One-hot编码工具
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_label) # 标签编码
y = to_categorical(y, 10) # 将标签转换为One-hot编码
X = np.array(X) # 将X从列表转换为张量数组
X = X/255 # 将X张量归一化
print ('X张量的形状:', X.shape)
print ('X张量中的数据:', X[0])
print ('y中的数据:', y) 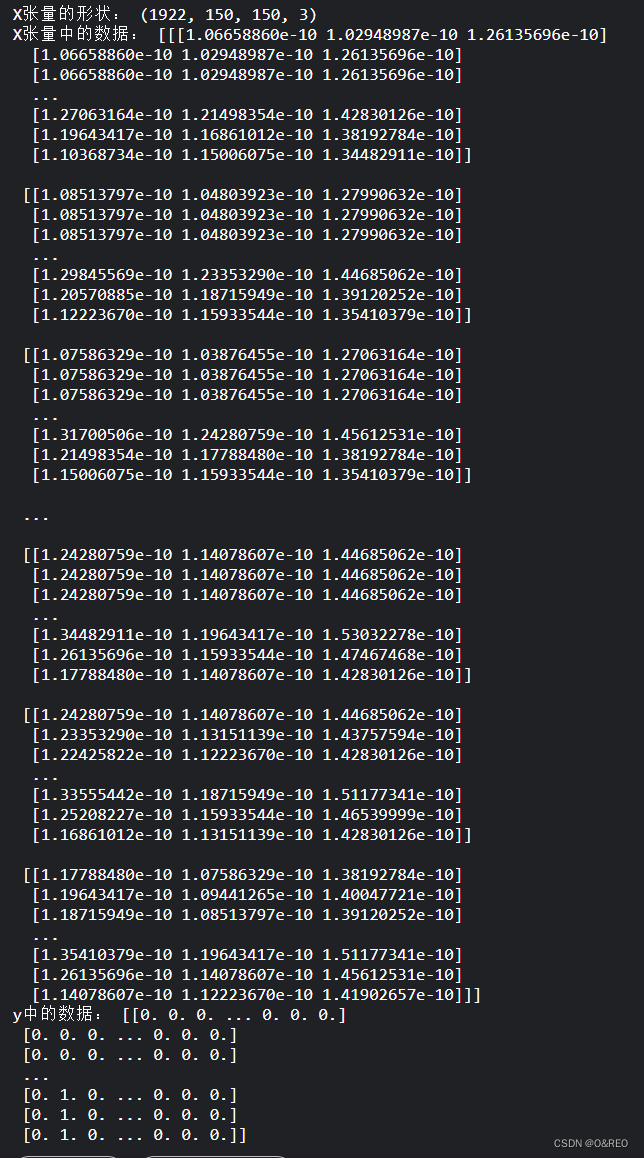
也可以将已经缩放至[0,1]区间之后的张量重新以图像的形式显示出来:
import matplotlib.pyplot as plt # 导入Matplotlib库
import random as rdm # 导入随机数工具
# 随机显示几张可爱的狗狗图像
fig, ax = plt.subplots(5, 2) # 创建一个包含5行2列子图的图形对象
fig.set_size_inches(20, 20) # 设置图形对象的尺寸为20x20英寸
for i in range(5): # 循环5次,控制行数
for j in range(2): # 循环2次,控制列数
r = rdm.randint(0, len(X)) # 随机生成一个范围在0到X的长度之间的整数
ax[i, j].imshow(X[r]) # 在当前子图中显示第r个图像
ax[i, j].set_title('Dog: ' + y_label[r]) # 设置当前子图的标题为'Dog: '加上对应的标签
plt.tight_layout() # 调整子图的布局,使其更紧凑


3拆分数据集
随机地乱序并拆分训练集和测试集
from sklearn.model_selection import train_test_split # 导入拆分工具
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=0)下面就开始构建简单的卷积网络
from keras import layers # 导入所有层
from keras import models # 导入所有模型
cnn = models.Sequential() # 序贯模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积层
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Flatten()) # 展平层
cnn.add(layers.Dense(512, activation='relu')) # 全连接层
cnn.add(layers.Dense(10, activation='softmax')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer='rmsprop', # 优化器
metrics=['acc']) # 评估指标
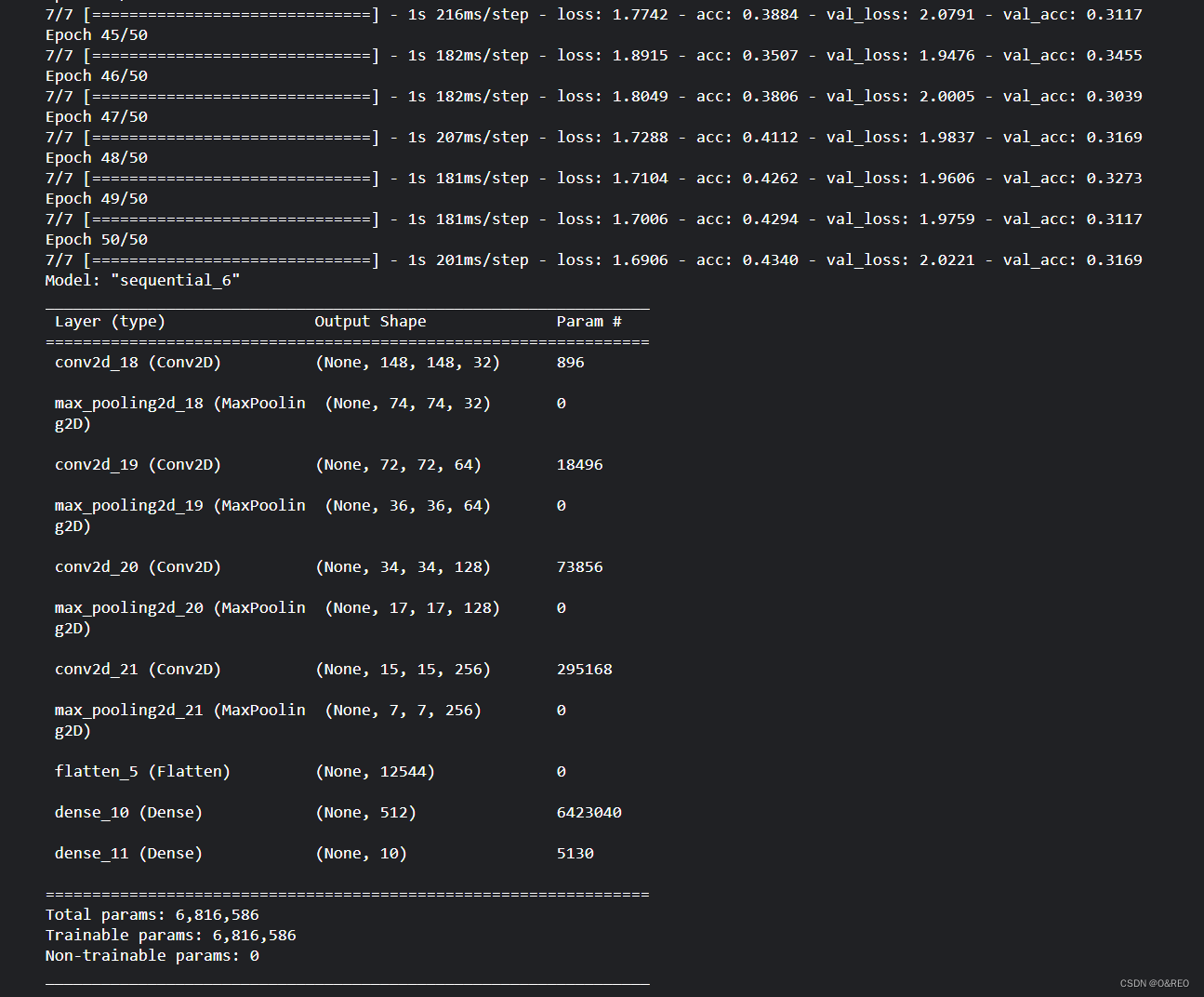
cnn.summary()Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_22 (Conv2D) (None, 148, 148, 32) 896
max_pooling2d_22 (MaxPoolin (None, 74, 74, 32) 0
g2D)
conv2d_23 (Conv2D) (None, 72, 72, 64) 18496
max_pooling2d_23 (MaxPoolin (None, 36, 36, 64) 0
g2D)
conv2d_24 (Conv2D) (None, 34, 34, 128) 73856
max_pooling2d_24 (MaxPoolin (None, 17, 17, 128) 0
g2D)
conv2d_25 (Conv2D) (None, 15, 15, 128) 147584
max_pooling2d_25 (MaxPoolin (None, 7, 7, 128) 0
g2D)
flatten_8 (Flatten) (None, 6272) 0
dense_16 (Dense) (None, 512) 3211776
dense_17 (Dense) (None, 10) 5130
=================================================================
Total params: 3,457,738
Trainable params: 3,457,738
Non-trainable params: 0
_________________________________________________________________
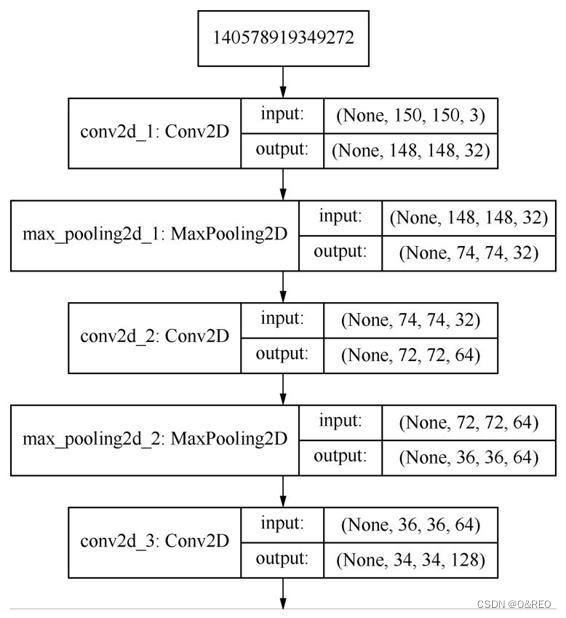
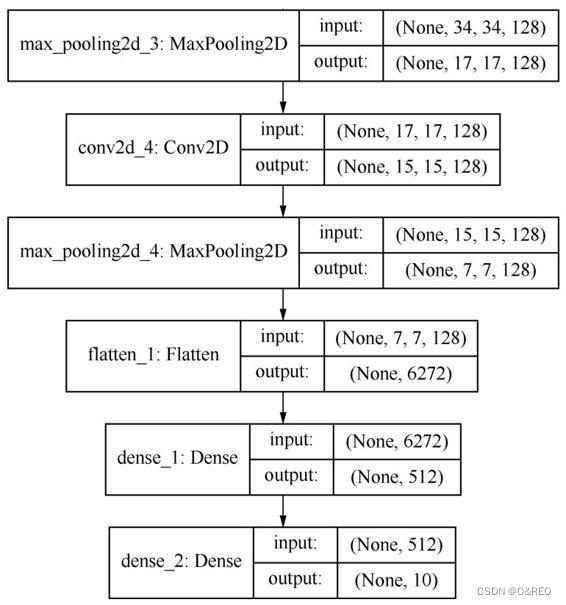
可以看出,卷积网络中,特征图的深度在逐渐增加(从32增大到128),而特征图的大小却逐渐减小(从150px×150px减小到7px×7px)。这是构建卷积神经网络的常见模式。
因为需要的层类型比较多,所以没有逐一导入,而是直接导入了Keras中所有的层。简单地介绍一下这个卷积网络中用到的各个层和超参数。
■Conv2D,是2D卷积层,对平面图像进行卷积。卷积层的参数32,(3,3)中,32是深度,即该层的卷积核个数,也就是通道数;后面的(3,3)代表卷积窗口大小。第一个卷积层中还通过input_shape=(150,150,3)指定了输入特征图的形状。
全部的卷积层都通过ReLU函数激活。
其实还有其他类型的卷积层,比如用于处理时序卷积的一维卷积层Conv1D等。
■Max Pooling2D,是最大池化层,一般紧随卷积层出现,通常采用2×2的窗口,默认步幅为2。这是将特征图进行2倍下采样,也就是高宽特征减半。
上面这种卷积+池化的架构一般要重复几次,同时逐渐增加特征的深度。
■Flatten,是展平层,将卷积操作的特征图展平后,才能够输入全连接层进一步处理。
■最后两个Dense,是全连接层。
□第一个是普通的层,用于计算权重,确定分类,用Re LU函数激活。
□第二个则只负责输出分类结果,因为是多分类,所以用Softmax函数激活。
■在网络编译时,需要选择合适的超参数。
□损失函数的选择是categorical_crossentropy,即分类交叉熵。它适用于多元分类问题,以衡量两个概率分布之间的距离,使之最小化,让输出结果尽可能接近真实值。
□优化器的选择是RMSProp。
□评估指标为准确率acc,等价于accucary。
4对网络进行训练
(为了简化模型,这里还是直接使用训练集数据进行验证)
上GPU
history = cnn.fit(X_train, y_train, # 指定训练集
epochs=50,# 指定轮次
batch_size=256,# 指定批量大小
validation_data=(X_test, y_test)) # 指定验证集
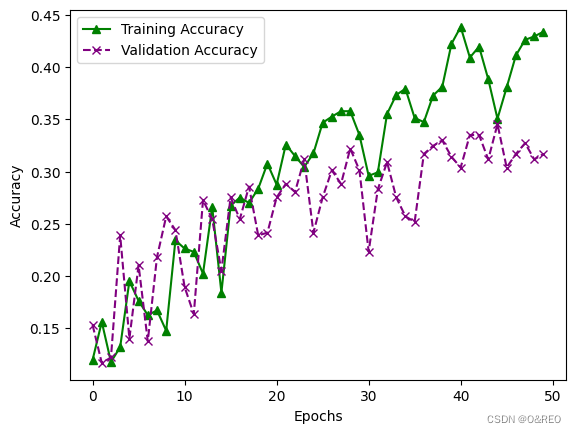
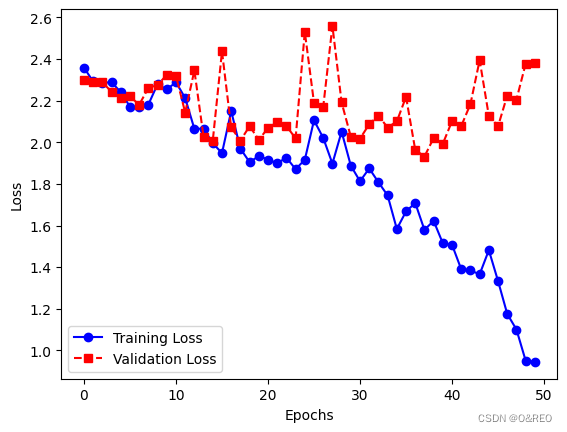
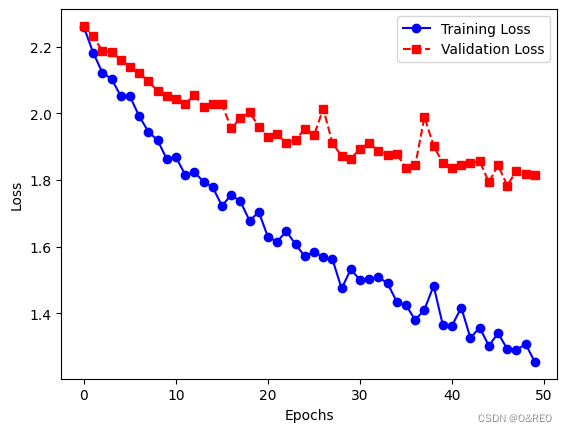
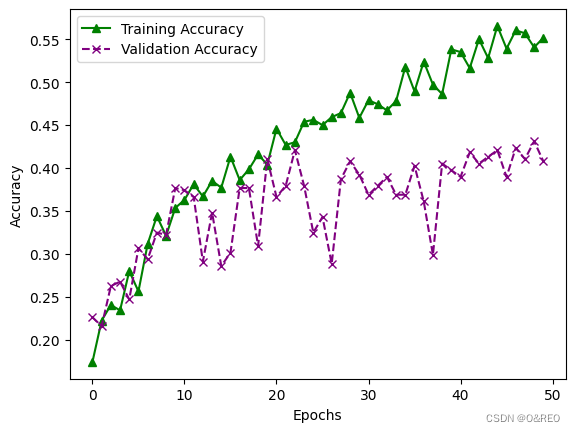
5绘制训练集和验证集上的损失曲线和准确率曲线
# 获取训练历史记录
train_loss = history.history['loss']
val_loss = history.history['val_loss']
train_acc = history.history['acc']
val_acc = history.history['val_acc']
# 绘制损失曲线
plt.plot(train_loss, label='Training Loss', color='blue', linestyle='-', marker='o')
plt.plot(val_loss, label='Validation Loss', color='red', linestyle='--', marker='s')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 绘制准确率曲线
plt.plot(train_acc, label='Training Accuracy', color='green', linestyle='-', marker='^')
plt.plot(val_acc, label='Validation Accuracy', color='purple', linestyle='--', marker='x')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
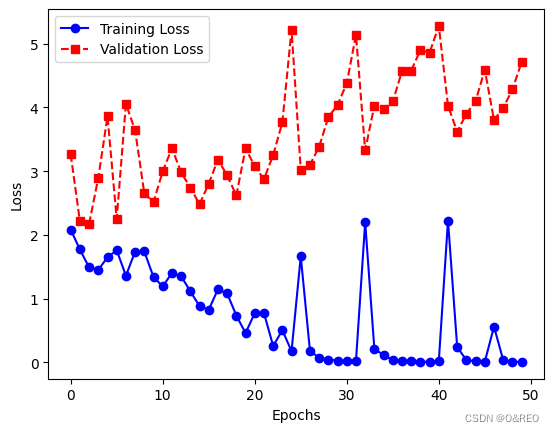
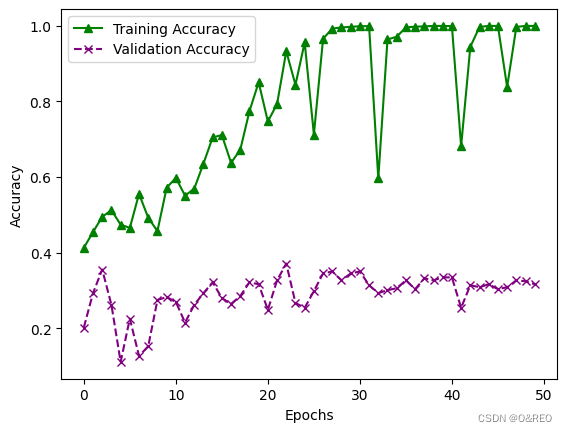
6优化器修改
optimizer='rmsprop', # 优化器改为
optimizer=optimizers.Adam(lr=1e-4), # 更新优化器并设定学习速率在深度学习中,优化器(optimizer)是用于更新模型参数以最小化损失函数的算法。Adam 是一种常用的优化器之一,它结合了 AdaGrad 和 RMSProp 的优点,并引入了偏置修正。学习速率(learning rate)是优化器的一个参数,用于控制每次参数更新的步长或大小。
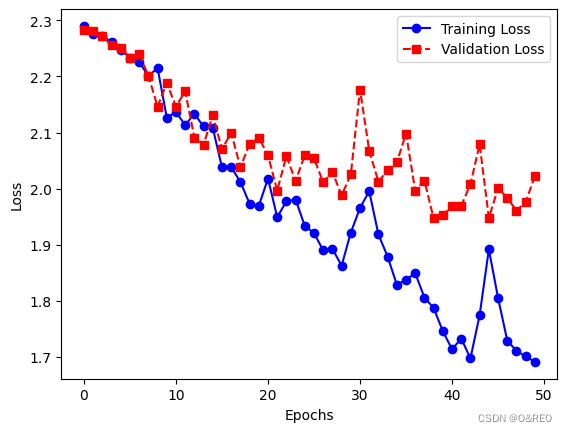
另外Adam会根据模型的历史梯度信息来动态的调整学习率
不设置初始值(optimizer='adam', # 优化器不设定学习速率)时:
Adam 优化器会自动调整学习速率。在 Adam 中,学习速率不需要手动调整,而是根据每个参数的梯度自适应地进行调整。
Adam 优化器使用了自适应学习速率算法,它会根据参数的梯度以及之前的梯度信息来自动调整学习速率。具体而言,Adam 优化器会计算每个参数的自适应学习速率,将较大梯度的参数的学习速率缩小,而将较小梯度的参数的学习速率放大,以更好地适应不同参数的更新需求。
因此,对于大多数情况下,使用 Adam 优化器并不需要手动设置学习速率,它会自动进行调整。设置默认的学习速率(如1e-4)是为了提供一个初始值,但在训练过程中,Adam 优化器会根据梯度自动调整学习速率,以便更好地优化模型。
然而,对于某些特定的问题和数据集,手动调整学习速率可能仍然是必要的。在这种情况下,你可以尝试不同的学习速率值,并观察模型的训练效果,选择最优的学习速率。但对于大多数情况下,Adam 优化器的默认学习速率通常是一个合理的选择。
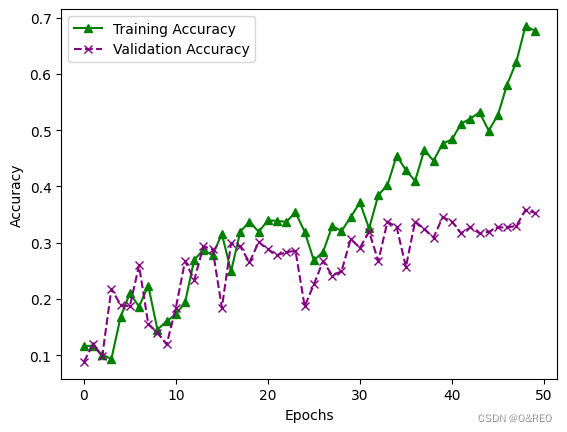
7添加Dropout层并扩大轮次
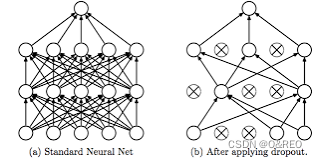
from keras import layers # 导入所有层
from keras import models # 导入所有模型
from keras import optimizers # 导入优化器
cnn = models.Sequential() # 序贯模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积层
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.Dropout(0.5)) # Dropout层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.Dropout(0.5)) # Dropout层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(256, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Flatten()) # 展平层
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.Dense(512, activation='relu')) # 全连接层
cnn.add(layers.Dense(10, activation='sigmoid')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer='adam', # 更新优化器并设定学习速率
metrics=['acc']) # 评估指标
history = cnn.fit(X_train, y_train, # 指定训练集
epochs=100,# 指定轮次
batch_size=256,# 指定批量大小
validation_data=(X_test, y_test)) # 指定验证集
cnn.summary()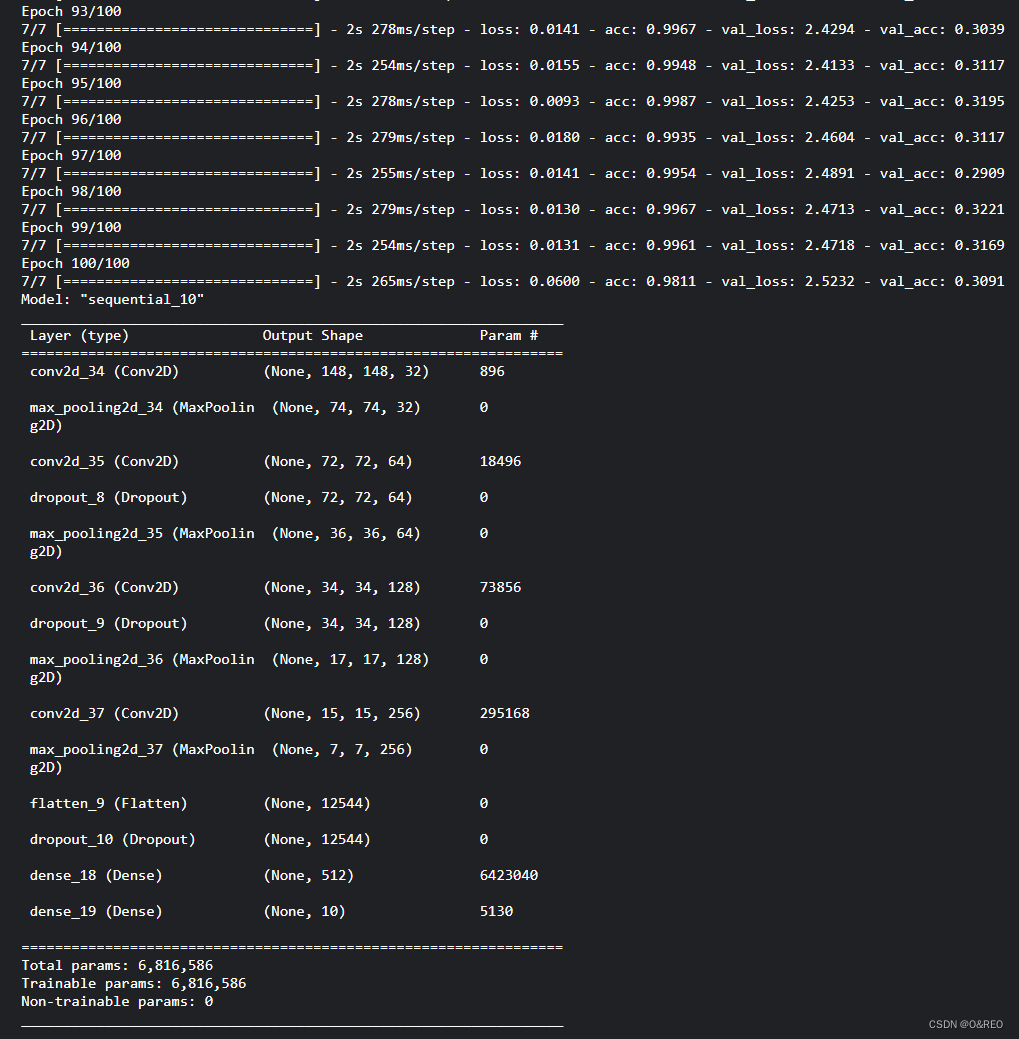
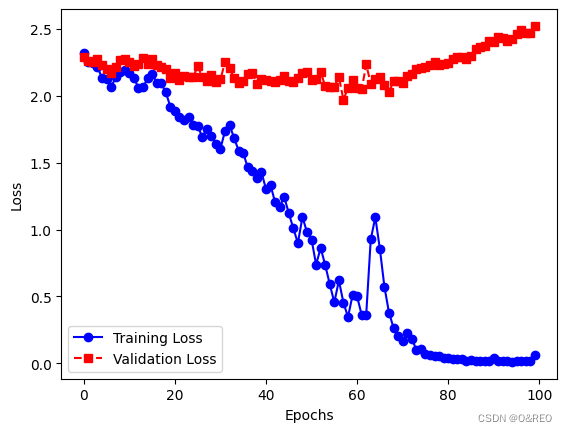
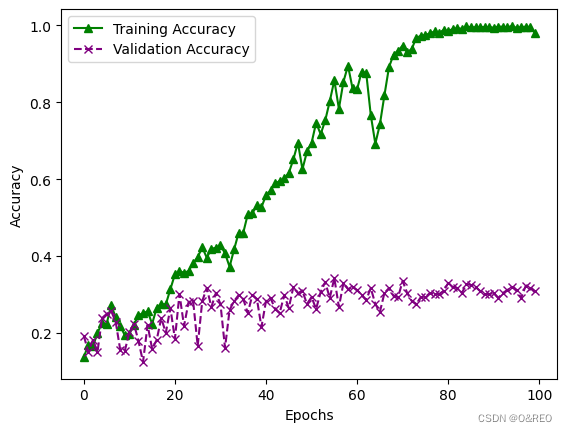
准确率的提升不大,还是35%左右。而且训练集和验证集之间的准确率,仍然是天壤之别。
8 数据增强(Data augmentation)
在Keras中,可以用Image Data- Generator工具来定义一个数据增强器:
# 定义一个数据增强器, 并设定各种增强选项
from keras.preprocessing.image import ImageDataGenerator
augs_gen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=10,
zoom_range = 0.1,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=False)
augs_gen.fit(X_train) # 针对训练集拟合数据增强器网络还是用回相同的网络,唯一的区别是在训练时,需要通过model.fit方法动态生成被增强后的训练集:
history = cnn.fit(
augs_gen.flow(X_train, y_train, batch_size=16), # 增强后的训练集
validation_data=(X_test, y_test),# 指定验证集
validation_steps=20,# 指定验证步长
steps_per_epoch=80,# 指定每轮步长
verbose = 1,
epochs=50,# 指定轮次
) # 指定是否显示训练过程中的信息每个批次的大小设置为16。由于设置了 steps_per_epoch 为80,表示每个训练轮次中会从数据增强生成器中获取80个批次进行训练。
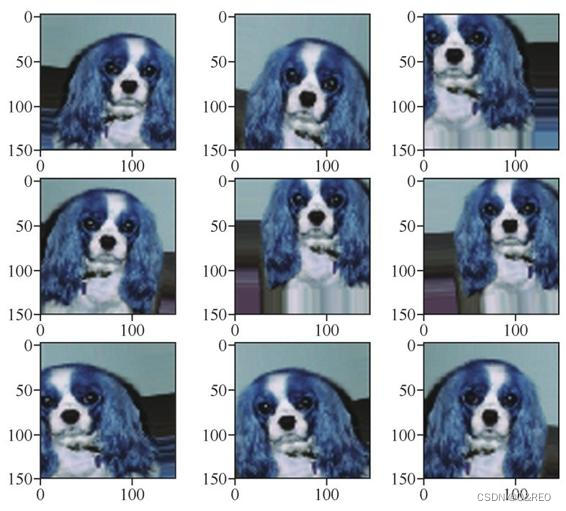
因此,训练集总共增强到了 80*16=1280 个图像。
9保存
from keras.models import load_model # 导入模型保存工具
cnn.save('../my_dog_cnn.h5')# 创建一个HDF5格式的文件'my_dog_cnn.h5'
del cnn# 删除当前模型
cnn = load_model('../my_dog_cnn.h5') # 重新载入已经保存的模型10卷积神经网络中的各层通道可视化
在卷积神经网络中,层的通道数和层的数量是两个不同的概念。
层的通道数是指每一层神经网络所包含的输入或输出数据的数量,这些数据流经网络的不同层次,用于提取不同的特征映射。通常,每个通道对应一个特定的特征映射或数据流。例如,对于一个RGB图像,如果输入层有3个通道,则每个通道对应于图像的一个颜色通道(红色、绿色或蓝色)。
层的数量通常是指卷积神经网络中不同层次的数量,这些层次由多个卷积层、池化层和全连接层等组成。在卷积神经网络中,每一层都可以执行特定的操作,例如卷积层进行特征提取和过滤,池化层进行下采样,全连接层进行分类等。
因此,要查看一个层的通道数和层的数量,需要查看网络模型的架构。通常,在卷积神经网络的架构中,每一层的通道数和层的数量都会被明确地定义和列出。这些信息可以在网络模型的文档或代码中找到。
根据建立的CNN序贯模型
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_22 (Conv2D) (None, 148, 148, 32) 896
max_pooling2d_22 (MaxPoolin (None, 74, 74, 32) 0
g2D)
conv2d_23 (Conv2D) (None, 72, 72, 64) 18496
max_pooling2d_23 (MaxPoolin (None, 36, 36, 64) 0
g2D)
conv2d_24 (Conv2D) (None, 34, 34, 128) 73856
max_pooling2d_24 (MaxPoolin (None, 17, 17, 128) 0
g2D)
conv2d_25 (Conv2D) (None, 15, 15, 128) 147584
max_pooling2d_25 (MaxPoolin (None, 7, 7, 128) 0
g2D)
flatten_8 (Flatten) (None, 6272) 0
dense_16 (Dense) (None, 512) 3211776
dense_17 (Dense) (None, 10) 5130
=================================================================
Total params: 3,457,738
Trainable params: 3,457,738
Non-trainable params: 0
_________________________________________________________________- conv2d_22 (Conv2D):32个通道
- max_pooling2d_22 (MaxPooling2D):32个通道
- conv2d_23 (Conv2D):64个通道
- max_pooling2d_23 (MaxPooling2D):64个通道
- conv2d_24 (Conv2D):128个通道
- max_pooling2d_24 (MaxPooling2D):128个通道
- conv2d_25 (Conv2D):128个通道
- max_pooling2d_25 (MaxPooling2D):128个通道
- flatten_8 (Flatten):将上一层的多维输入一维化,通道数无意义
- dense_16 (Dense):全连接层,512个神经元
- dense_17 (Dense):全连接层,10个神经元,用于最后的分类输出
from keras.models import load_model # 导入模型保存工具
import matplotlib.pyplot as plt # 导入Matplotlib库
model = load_model('../my_dog_cnn.h5')# 载入刚才保存的模型
# 绘制特征通道
# 获取模型的前50层的输出作为新模型的输出,新模型的输入与原模型相同。
layer_outputs = [layer.output for layer in model.layers[:32]]
# 获取训练集的第一张图片作为输入。
image = X_train[0]
# 将图片的形状调整为适合模型输入的形状。这里假设模型的输入是一个150x150的RGB图片。
image = image.reshape(1, 150, 150, 3)
# 创建新的模型,该模型的输入与原模型相同,但输出是原模型的前32层的激活。
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
# 使用新模型对图片进行预测,以得到各层的激活。
activations = activation_model.predict(image)
# 获取第八层的激活。
layer_activation = activations[7]
plt.matshow(layer_activation[0, :, :, 10], cmap='cool')# 绘制第10个通道的激活 [批次,空即完整高度,空即完整宽度,通道数]
plt.matshow(layer_activation[0, :, :, 50], cmap='cool')
plt.matshow(layer_activation[0, :, :, 80], cmap='cool')
plt.matshow(layer_activation[0, :, :, 100], cmap='cool')# 绘制第100个通道的激活
plt.matshow(layer_activation[0, :, :, 120], cmap='cool')
# 获取第六层的激活。
layer_activation = activations[5]
plt.matshow(layer_activation[0, :, :, 10], cmap='spring')
plt.matshow(layer_activation[0, :, :, 127], cmap='spring')# 绘制第127个通道的激活
plt.matshow(layer_activation[0, :, :, 40], cmap='spring')
plt.matshow(layer_activation[0, :, :, 20], cmap='spring')
plt.matshow(layer_activation[0, :, :, 30], cmap='spring')
# 获取第二层的激活。
layer_activation = activations[1]
plt.matshow(layer_activation[0, :, :, 2], cmap='jet')
plt.matshow(layer_activation[0, :, :, 3], cmap='jet')
plt.matshow(layer_activation[0, :, :, 10], cmap='jet')# 绘制第10个通道的激活
plt.matshow(layer_activation[0, :, :, 20], cmap='jet')
plt.matshow(layer_activation[0, :, :, 30], cmap='jet')
# 获取第一层的激活。
first_layer_activation = activations[0]
plt.matshow(first_layer_activation[0, :, :, 2], cmap='viridis')
plt.matshow(first_layer_activation[0, :, :, 3], cmap='viridis')
plt.matshow(first_layer_activation[0, :, :, 10], cmap='viridis')# 绘制第10个通道的激活
plt.matshow(first_layer_activation[0, :, :, 20], cmap='viridis')
plt.matshow(first_layer_activation[0, :, :, 30], cmap='viridis')# 绘制第30个通道的激活
 通过观察这些特征通道的中间激活图就能发现,卷积网络中的各个通道并不是漫无目地进行特征提取,而是各负其责,忽略不相关的噪声信息,专门聚焦于自己所负责的那部分特征,激活各个特征点。这些特征点(也就是小模式)进行组合,就实现了高效率的图像识别。
通过观察这些特征通道的中间激活图就能发现,卷积网络中的各个通道并不是漫无目地进行特征提取,而是各负其责,忽略不相关的噪声信息,专门聚焦于自己所负责的那部分特征,激活各个特征点。这些特征点(也就是小模式)进行组合,就实现了高效率的图像识别。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











