







目录
1.工业工件字符识别
在复杂的工业制造环境中,为了更好的追踪工件的工序情况,工厂会选择在工件表面印有工件编号,工人通过肉眼识别工件编号数字,手动录入数据库信息完成对工件的管理。这种方法不仅效率低下,且混乱的工业环境极易导致错误的产生。在工件数据管理方面,迫切需要智能化工具来管理数据,将信息录入实现自动化。
1.2 难点
工业场景的图像文字识别更加复杂,出现在很多不同的场合。例如医药品包装上的文字、各种钢制部件上的文字、容器表面的喷涂文字、商店标志上的个性文字等。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此难以检测和识别图像字符。
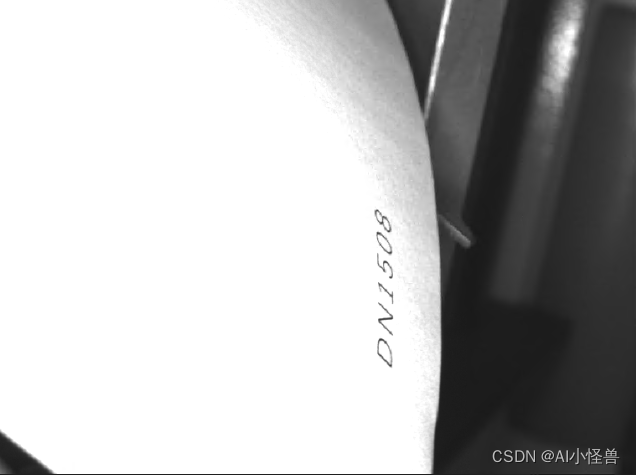
1.3 基于深度学习的OCR技术
目前,基于深度学习的场景文字识别主要包括两种方法,第一种是分为文字检测和文字识别两个阶段;第二种则是通过端对端的模型一次性完成文字的检测和识别。
2.基于Paddleocr的字符识别
🌟 特性
支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程。
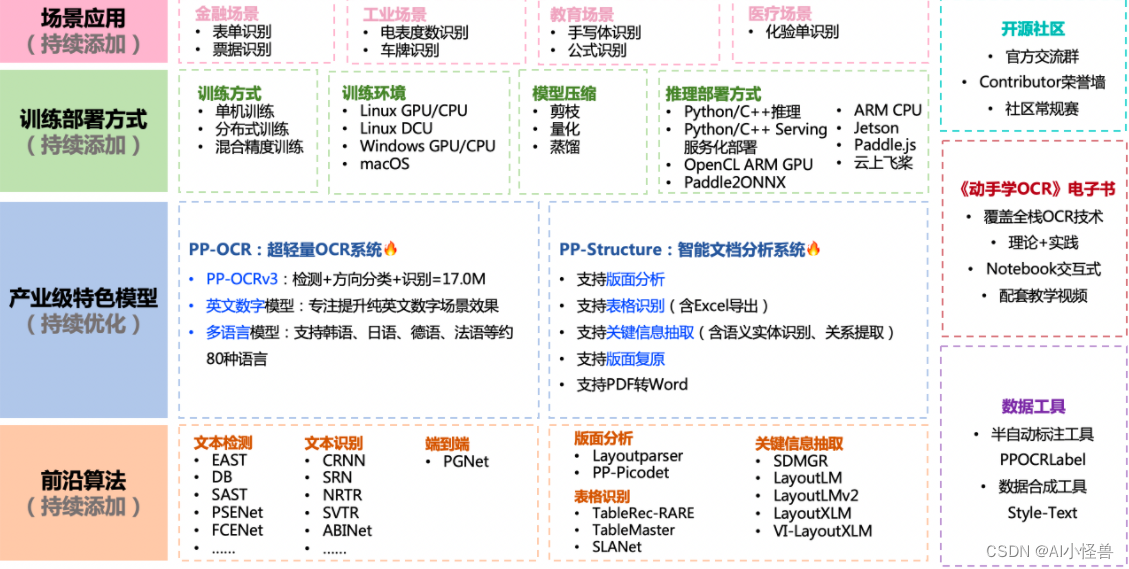
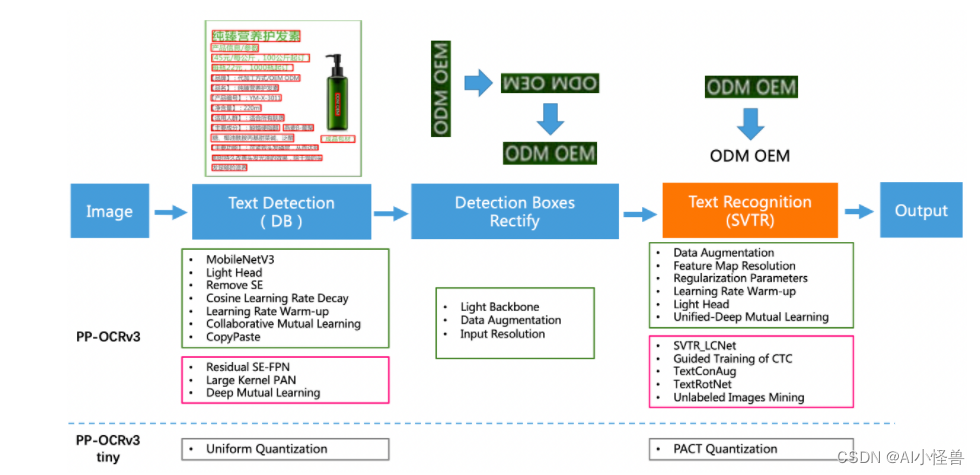
2.1 PP-OCRv3介绍
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级:
-
PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
-
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
-
PP-OCRv3系统pipeline如下:
3.本文工件字符识别数据集介绍
使用PPOCRLabel标记数据集
PPOCRLabel --lang ch 
4.PaddleOCR工件字符
4.1 字符检测
选择轻量级检测网络configs\det\det_mv3_db.yml
det_mv3_db.yml参数介绍:
Global:
use_gpu: true
use_xpu: false
use_mlu: false
epoch_num: 200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/db_mv3/
save_epoch_step: 1200
# evaluation is run every 2000 iterations
eval_batch_step: [0, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./output/det_db/predicts_db.txt
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
learning_rate: 0.001
regularizer:
name: 'L2'
factor: 0
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./dataset/
label_file_list:
- ./dataset/CapPic/Label.txt
ratio_list: [1.0]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [-10, 10] } }
- { 'type': Resize, 'args': { 'size': [0.5, 3] } }
- EastRandomCropData:
size: [640, 640]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
loader:
shuffle: True
drop_last: False
batch_size_per_card: 16
num_workers: 0
use_shared_memory: True
Eval:
dataset:
name: SimpleDataSet
data_dir: ./dataset/
label_file_list:
- ./dataset/CapPic/Label_val.txt
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
image_shape: [736, 1280]
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1
num_workers: 0
use_shared_memory: True
python tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
指标评估
python3 tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="output/db_mv3/best_accuracy"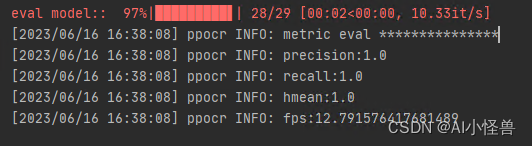
4.2 字符识别
python tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy \
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=Trueen_PP-OCRv3_rec.yml超参数
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/v3_en_mobile
save_epoch_step: 3
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: dataset/ic15_dict.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_en.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- SARLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: ./dataset/CapPic/
ext_op_transform_idx: 1
label_file_list:
- ./dataset/CapPic/rec_gt.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 64
drop_last: true
num_workers: 0
Eval:
dataset:
name: SimpleDataSet
data_dir: ./dataset/CapPic/
label_file_list:
- ./dataset/CapPic/rec_gt_val.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 32
num_workers: 0



















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











