







首先祝贺自己成功通关!!

任务描述
本关任务:实现4位先行进位加法器的设计。
实验目的
1、掌握先行进位部件CLU的设计方法
2、掌握先行进位加法器的设计方法
3、掌握进位生成函数和进位传递函数的设计方法
4、传播延迟时间对比检测
实验原理
几乎所有算术运算都要用到ALU或加法器,而ALU的核心还是加法器,因此要提高计算机的运算速度,关键在于提升加法器的执行速度。为了提高加法器的速度,必须尽量避免进位之间的依赖关系和传递关系,先行进位(也称超前进位)部件(Carry Lookahead Unit,CLU)就能实现这一功能。
把进位传递函数 Pi = Xi + Yi和进位生成函数Gi = XiYi 列入到4位二进制数加法器进位C1-C4的逻辑表达式中,可以得到以下4个先行进位Ci的逻辑表达式,从公式(4-1)中的表达式可以看出,Ci仅与Xi、Yi和C0有关,相互间的进位没有依赖关系。只要X1-X4、Y1-Y4和C0同时到达,就可几乎同时形成C1-C4,并同时生成各个数位的和。
C1 = G0+ P0C0
C2 = G1 + P1G0 + P1P0C0
C3 = G2 + P2G1 + P2P1G0 + P2P1P0C0
C4 = G3 + P3G2 + P3P2G1 + P3P2P1G0 + P3P2P1P0C0
4位先行进位部件CLU设计原理图如下图所示。
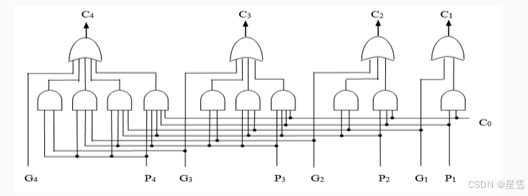
更多位数的加法器可通过分组的方式来实现,采用组内和组间都并行的进位方式。为了实现组间并行,需要在先行进位部件中输出组间进位生成函数Gg和组间进位传递函数Pg。
Pg= P3P2P1P0
Gg= G3+P3G2+P3P2G1+P3P2P1G0
将式(4-1)中进位C4的逻辑表达式改写成为C4=Gg+PgC0,CLU部件中增加两个输出端口Pg和Gg。
编程要求
在Logisim中打开/data/workspace/myshixun/lab4.1.circ文件,设计并实现4位先行进位加法器。请不要更改电路封装、修改引脚、移动引脚、添加引脚,否则评测将出错。
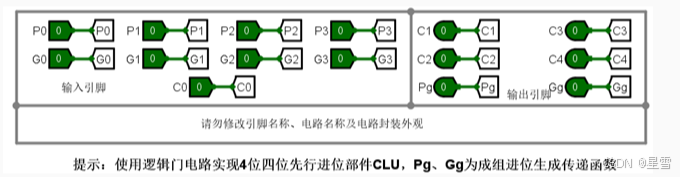
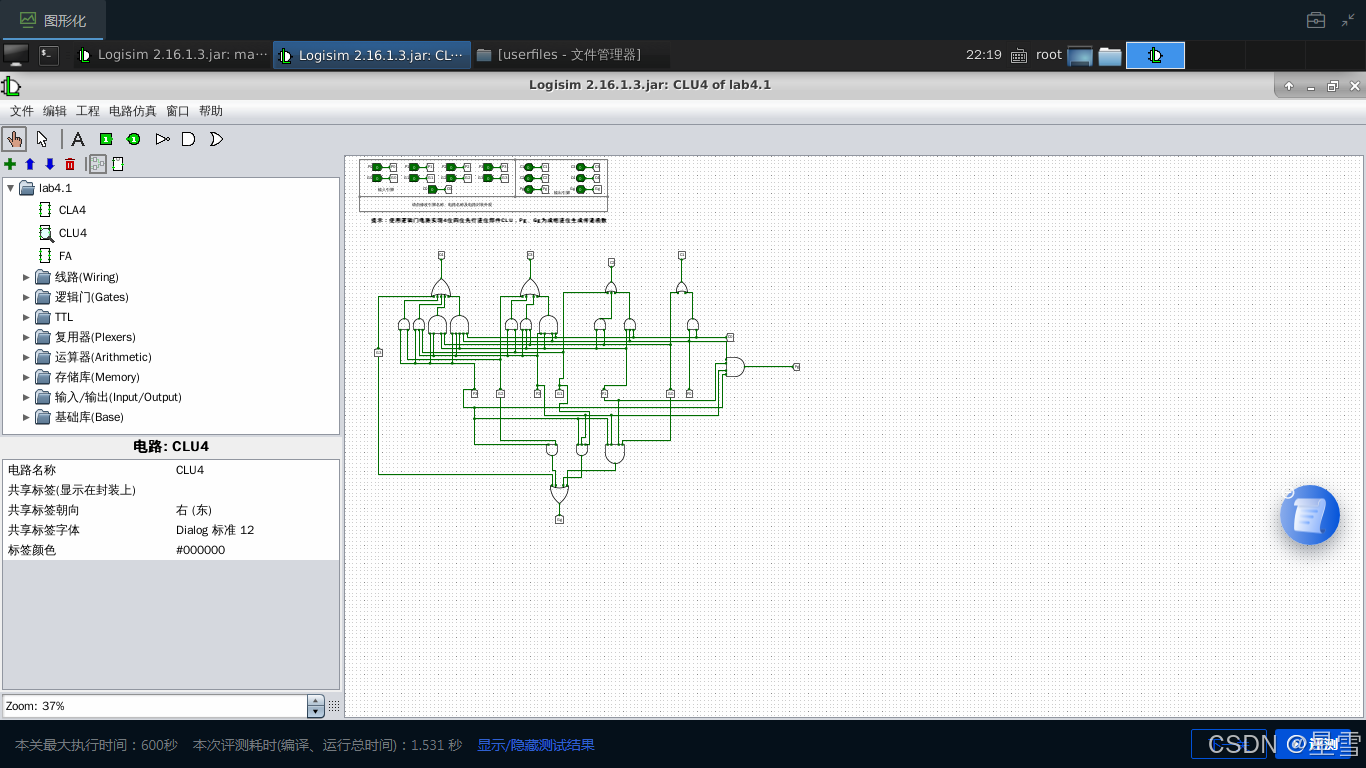
1)设计4位先行进位部件CLU。根据先行进位部件的原理图,在Logisim中设计4位先行进位部件子电路CLU。布局图如下所示。
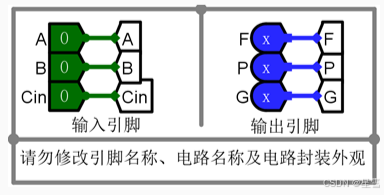
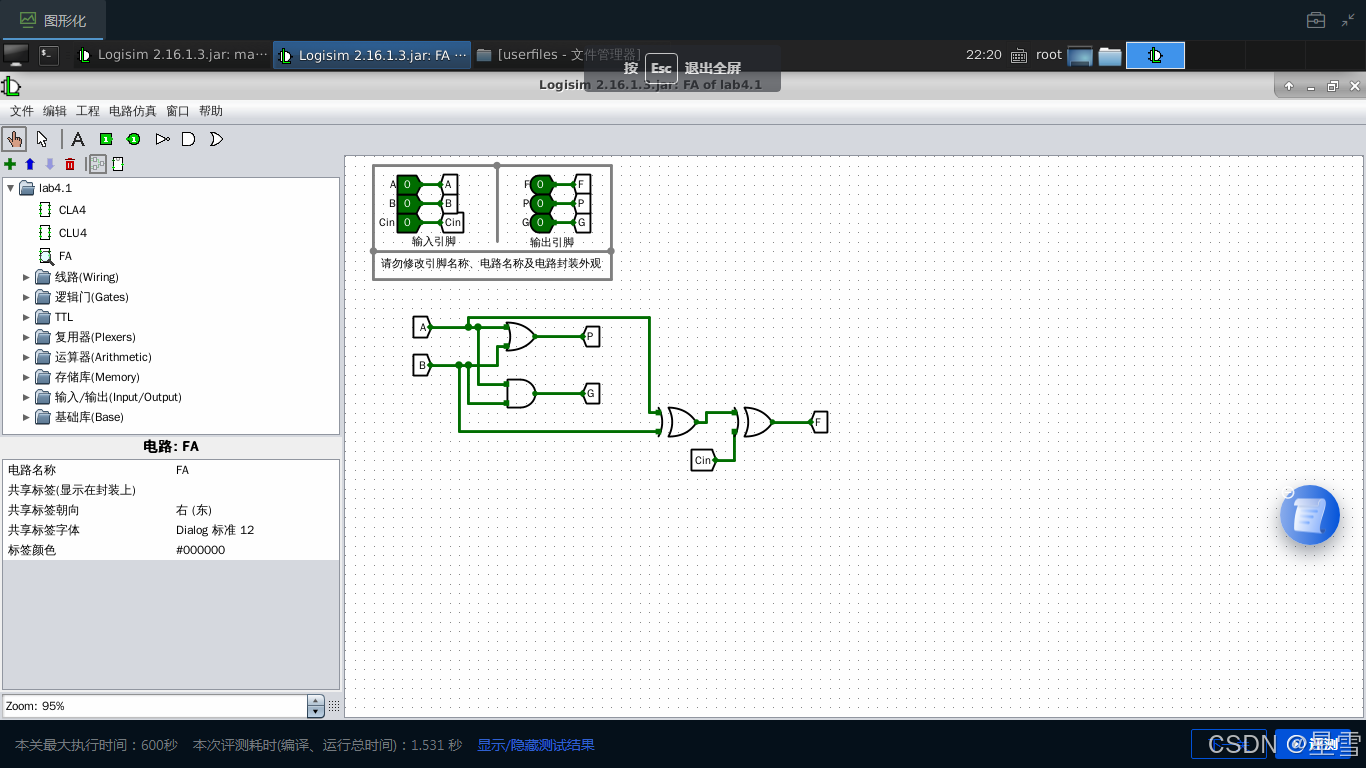
2)设计支持进位生成函数和进位传递函数的全加器。在Logisim中添加全加器子电路FA,电路引脚图如下所示。
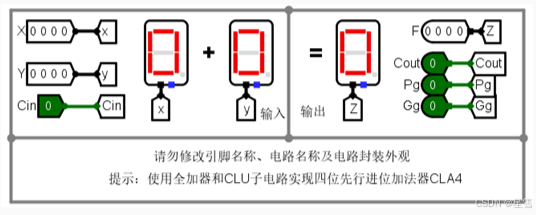
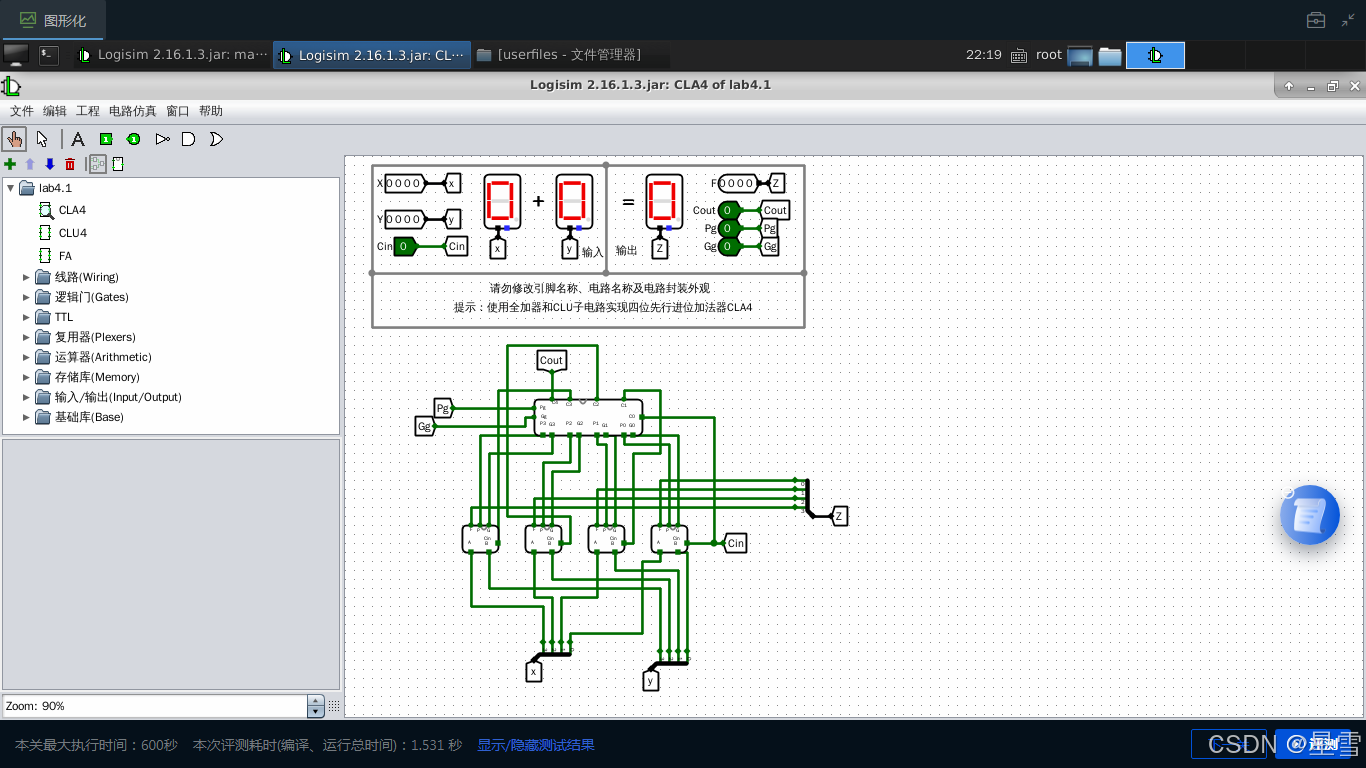
3)4位快速加法器CLA实验。在Logisim主电路的工作区中按下图所示的布局,定义输入输出引脚和组件布局,其中包含输入输出引脚、隧道、1个4位先行进位部件子电路、4个全加器子电路、LED数码管、逻辑门电路等组件。为了能够实现组间并行运算,增加了组间进位产生函数Gg和组间进位传递函数Pg的输出。修改属性,参照课件和教材上的电路原理图,连接组件,实现电路。通过设置不同的X、Y和Cin的输入值,观察结果F、进位Cout、Pg、Gg等输出值,以验证电路的正确性,记录测试数据。
测试说明
平台会对你编写的代码进行测试:
X、Y、Cin表示输入的数据,分别表示被加数、加数和低位进位;Z、Cout、Gg、Pg表示输出数据,分别表示和、进位、组间进位生成信号和组间进位传递信号。
测试数据:
Cnt X Y Cin Z Cout Gg Pg
00 f 2 0 1 1 1 1
01 e 3 0 1 1 1 1
02 d 4 0 1 1 1 0
03 c 5 0 1 1 1 0
04 b 6 0 1 1 1 1
05 a 7 0 1 1 1 1
06 9 8 0 1 1 1 0
07 8 9 0 1 1 1 0
开始你的任务吧,祝你成功!
不说废话,直接开干!!
CLA4:
CLU4:
FA:


















 9489
9489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









