






极大似然估计(数学基础)
极大似然估计是我们机器学习中很重要的数学基础之一,为了更好地理解极大似然估计,我们先从贝叶斯决策入手。
- 贝叶斯决策
-
我们都知道经典的贝叶斯公式

其中:
p(w)为先验概率,表示每种类别分布的概率;p(x|w)为类条件概率,表示在某种类别前提下,某事发生的概率;
P(w|x)为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。 例子:在夏季,某公园男性穿凉鞋的概率为1/2,女性穿凉鞋的概率为2/3,并且该公园中男女比例通常为2:1。问题:若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?从问题看,就是上面讲的,某事发生了,它属于某一类别的概率是多少?即后验概率。
解:
设w1=男性,w2=女性,x=穿凉鞋。
则: 男性和女性穿凉鞋相互独立,所以
男性和女性穿凉鞋相互独立,所以
 由贝叶斯概率计算出后验概率为:
由贝叶斯概率计算出后验概率为:

问题引出
但是在实际问题中并不都是这样幸运的,我们能获得的数据可能只有有限数目的样本数据,而先验概率和类条件概率(各类的总体分布)都是未知的。根据仅有的样本数据进行分类时,一种可行的办法是我们需要先对先验概率和类条件概率进行估计,然后再套用贝叶斯分类器。
先验概率的估计较简单,1、每个样本所属的自然状态都是已知的(有监督学习:有非常明确的答案);2、依靠经验;3、用训练样本中各类出现的频率估计。
类条件概率的估计(非常难),原因包括:概率密度函数包含了一个随机变量的全部信息;样本数据可能不多;特征向量x的维度可能很大等等。总之要直接估计类条件概率的密度函数很难。解决的办法就是,把估计完全未知的概率密度转化为估计参数。这里就将概率密度估计问题转化为参数估计问题,极大似然估计就是一种参数估计方法。当然了,概率密度函数的选取很重要,模型正确,在样本区域无穷时,我们会得到较准确的估计值,如果模型都错了,那估计半天的参数,肯定也没啥意义了。
重要前提
上面说到,参数估计问题只是实际问题求解过程中的一种简化方法(由于直接估计类条件概率密度函数很困难)。所以能够使用极大似然估计方法的样本必须需要满足一些前提假设。
重要前提:训练样本的分布能代表样本的真实分布。每个样本集中的样本都是所谓独立同分布的随机变量 (iid条件),且有充分的训练样本。
极大似然估计:

总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
关于参数的例子:
我们实验的结果是,10次抛硬币,有6次是“花”。
所谓最大似然估计,就是假设硬币的参数,然后计算实验结果的概率是多少,概率越大的,那么这个假设的参数就越可能是真的。
我们先看看硬币是否是公平的,就用0.5作为硬币的参数,实验结果的概率为:

单独的一次计算没有什么意义,让我们继续往后面看。
再试试用0.6作为硬币的参数,实验结果的概率为:

之前说了,单次计算没有什么意义,但是两次计算就有意义了,因为可以进行比较了。可以看到:

这个函数用图形表示是这样:

我们可以从图中看出两点:
• 参数为0.6时,概率最大
• 参数为0.5 或其他值也是有可能的,但可能性都小一点
所以更准确的说,似然(现在可以说似然函数了)是参数θ的概率分布。
而求最大似然估计的问题,就变成了求似然函数的极值。在这里,极值出现在θ为 0.6 时。
最大似然估计真正的用途是针对多次实验。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:

似然函数(linkehood function):联合概率密度函数称为相对于的θ的似然函数。


求解极大似然函数
ML估计:求使得出现该组样本的概率最大的θ值。

实际中为了便于分析,定义了对数似然函数:

1. 未知参数只有一个(θ为标量)
在似然函数满足连续、可微的正则条件下,极大似然估计量是下面微分方程的解:

2.未知参数有多个(θ为向量)
则θ可表示为具有S个分量的未知向量:

记梯度算子:
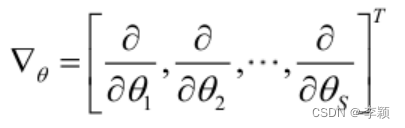
若似然函数满足连续可导的条件,则最大似然估计量就是如下方程的解。

方程的解只是一个估计值,只有在样本数趋于无限多的时候,它才会接近于真实值。














 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









