







本文基于ncnn-android-yolov8(GitHub开源项目)撰写
项目源:请为飞哥点个♥
主要参考:集中了主要的一些问题的讨论板块
以及nihui大佬、ncnn社区的大家上传的开源项目为我提供提高理解能力的样例(♥爱你们哦♥)
只是效果图
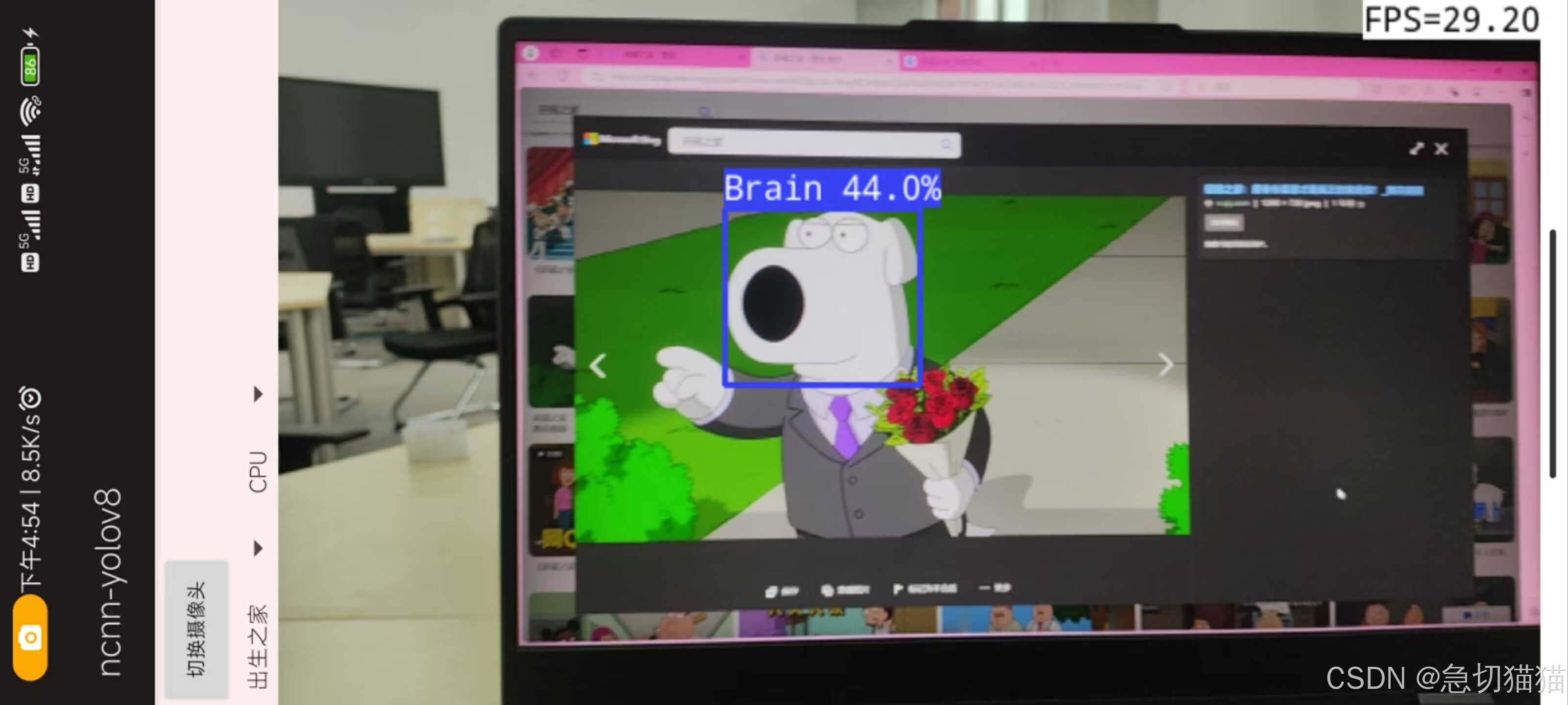
如果你已经对飞哥这个项目有一定的了解但仍有一些疑问,别担心
👇请直接从这里开始👇
在这个版块中,我将就项目实施的一些常见问题为大家提供相应的解决策略:
1.支持问题:
支持在本项目中特指:
opencv-mobile-A.B.C-android(A、B、C代指数字)
ncnn-YYYYMMDD-android-vulkan(YMD代指版本发布时间)
在飞哥的工程项目源码中,这个修改项在README中被提及,飞哥的开源项目中并未包含这两个包,而在我们部署时,这两个包是必备的。具体部署位置已经写明在README中。
一般出现这个问题,很可能是因为大家使用了ncnn-20240820-android-vulkan这个版本的ncnn支持,很多朋友在学习东西的时候都喜欢使用最新的支持(也许新的更好?)
That‘s fine,因为我也一样,但是在这个项目中,我尝试了很多版本的opencv-mobile-A.B.C-android和ncnn-YYYYMMDD-android-vulkan。
也许目前支持该项目的最新包组合是:
opencv-mobile-4.10.0-android
ncnn-20240410-android-vulkan
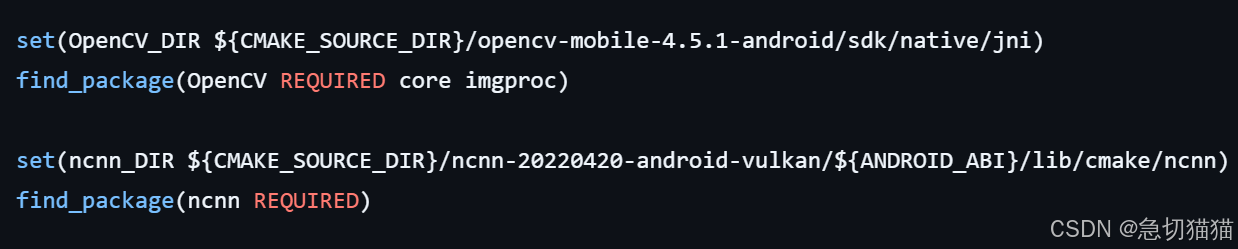
这就是项目外需要额外导入的两个支持,放置完别忘记替换cmakelist中的path哦!
当然也可以参考我的CMakelist:
project(yolov8ncnn)
cmake_minimum_required(VERSION 3.10)
set(OpenCV_DIR ${CMAKE_SOURCE_DIR}/opencv-4.10.0-android-sdk/sdk/native/jni)
find_package(OpenCV REQUIRED core imgproc)
set(ncnn_DIR ${CMAKE_SOURCE_DIR}/ncnn-20240410-android-vulkan/${ANDROID_ABI}/lib/cmake/ncnn)
find_package(ncnn REQUIRED)
add_library(yolov8ncnn SHARED yolov8ncnn.cpp yolo.cpp ndkcamera.cpp)
target_link_libraries(yolov8ncnn ncnn ${OpenCV_LIBS} camera2ndk mediandk)
2.gradle、AGP以及cmake的适配问题:
cmake:3.10.2.4988404+
以现在为基准,clone完飞哥的项目后在本地加载的第一步会给你来个大惊喜,一个加粗了SDK字眼的红色大三角(悲),这一般是因为我们没给项目配置cmake的path。
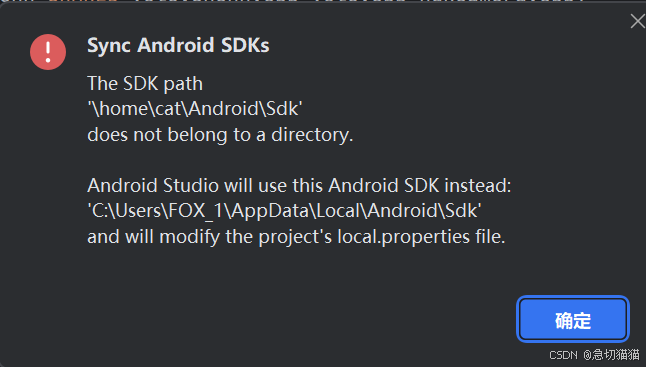
操作位置:local-properties
操作描述:其中的sdk.dir会在加载该项目时auto配置
此外,我们需要配置cmake.dir,cmake的位置就在sdk文件夹之下,sdk位置auto
配置后,在文件资源管理器中找到sdk,打开它,并在其下一级单位中找到名为
cmake的file,打开它,现在就会显示你安装的各版本cmake,复制他们的绝对路径,
写在cmake.dir=“path”。
样例:他看起来会像是↓(Ubantu记得使用单斜杠替换路径)
## This file must *NOT* be checked into Version Control Systems,
# as it contains information specific to your local configuration.
#
# Location of the SDK. This is only used by Gradle.
# For customization when using a Version Control System, please read the
# header note.
#Tue Oct 22 17:10:46 CST 2024
sdk.dir=C\:\\Users\\FOX_1\\AppData\\Local\\Android\\Sdk
cmake.dir=C\:\\Users\\FOX_1\\AppData\\Local\\Android\\Sdk\\cmake\\3.30.5注意事项:如果不用飞哥自配的3.10.2.4988404版本,想要用新版本的cmake是可行的,需要
再配置build.gradle(:app)
样例:他看起来会像是↓
apply plugin: 'com.android.application'
android {
compileSdkVersion 24
buildToolsVersion "29.0.2"
defaultConfig {
applicationId "com.tencent.yolov8ncnn"
archivesBaseName = "$applicationId"
minSdkVersion 24
}
// 添加命名空间属性
namespace 'com.tencent.yolov8ncnn' // 这里使用你的 applicationId 作为命名空间
externalNativeBuild {
cmake {
version "3.30.5"
path file('src/main/jni/CMakeLists.txt')
}
}
dependencies {
implementation 'com.android.support:support-v4:24.0.0'
}
}
AGP:8.5.0+
操作位置:build.gradle(ncnn-android-yolov8)
样例:他看起来会像是↓
// Top-level build file where you can add configuration options common to all sub-projects/modules.
buildscript {
repositories {
jcenter()
google()
}
dependencies {
classpath 'com.android.tools.build:gradle:8.5.0'
}
}
allprojects {
repositories {
jcenter()
google()
}
}
就算安装了8.5.0也会出现如下提示框:
这很正常,不必在意(反正不是红的)
gradle:8.7+
操作位置:gradle-wrapper.properties
样例:他看起来会像是↓
#Tue Oct 22 18:07:55 CST 2024
distributionBase=GRADLE_USER_HOME
distributionPath=wrapper/dists
distributionUrl=https\://services.gradle.org/distributions/gradle-8.9-bin.zip
zipStoreBase=GRADLE_USER_HOME
zipStorePath=wrapper/dists
3.程序闪退/乱框:
造成闪退/乱框的可能原因:
1.ncnn模型与项目不适配或pt模型导出错误
就目前这个时间段,基本可以确定是朋友你的导出方式出错了,下面我将介绍几个
出错点以及我认为的原因:
Ⅰ:pt2onnx部分
//个人认为整个项目中最容易出问题的部分
主要问题&原因:
项目开源距今时间一年了,ultralytics一直在更新,内置大大小小的函数和包也在不
断的更替变化。飞哥对ultralytics包内py文件及其函数的更改已经不再适配现在的版
本,一句句去找注释掉的代码再按照飞哥的逻辑去重组函数有一定的挑战性(很显
然我不是喜欢挑战的人)所以,对此
我的解决方案是回退到去年这个时候的ultralytics的版本
我采用的ultralytics版本version==8.0.50
pip install ultralytics==8.0.50返回到这个版本更改飞哥提示的配置,如果你采取了和我一样的策略,可以clone我
的代码或直接获取我的样板文件:
修改提示:
修改导出形式的ultralytics将不能再进行训练,且同一版本的ultralytcis只能导出大版本相同的yolov8模型及其迁移训练模型
鉴于操作的繁复,我的策略是单独为pt2onnx配置conda环境,再单独为训练pt模型配置conda环境(这两个环境下的ultralytics版号相同)
如果需要使用最新版的ultralytics(其实感觉yolo11感觉提升也不是很大)做其他项目,则需要新建环境,否则项目之间协调不便(函数老改来改去好麻烦啊)
样例:
conda environment:
(pt2onnx):负责pt模型导出onnx(ultralytics版本号一致)
(ncnn-main):负责模型训练,调参,测试等一系列主事件(ultralytics版本号一致)
(Edge_cat):负责其他项目的环境(任选版本)
C2F层改动
修改路径样例:
D:\For_anaconda\envs\ncnn\Lib\site-packages\ultralytics\nn\modules.C2F
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
# y = list(self.cv1(x).chunk(2, 1))
# y.extend(m(y[-1]) for m in self.m)
# return self.cv2(torch.cat(y, 1))
print('forward C2f')
x = self.cv1(x)
x = [x, x[:, self.c:, ...]]
x.extend(m(x[-1]) for m in self.m)
x.pop(1)
return self.cv2(torch.cat(x, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))Detect层改动
修改路径样例:
D:\For_anaconda\envs\ncnn\Lib\site-packages\ultralytics\nn\modules.Detect
class Detect(nn.Module):
# YOLOv8 Detect head for detection models
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()): # detection layer
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
# if self.export and self.format == 'edgetpu': # FlexSplitV ops issue
# x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
# box = x_cat[:, :self.reg_max * 4]
# cls = x_cat[:, self.reg_max * 4:]
# else:
# box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1)
# dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
# y = torch.cat((dbox, cls.sigmoid()), 1)
# return y if self.export else (y, x)
print('forward Detect')
pred = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).permute(0, 2, 1)
return pred
def bias_init(self):
# Initialize Detect() biases, WARNING: requires stride availability
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)完成上述修改后,在环境中建立pt2onnx.py
采用以下代码导出onnx模型,onnx将位于选定pt模型同级文件夹下,可以用netron查看网络
from ultralytics import YOLO
model = YOLO("训练好的模型.pt")
success = model.export(format="onnx", opset=12, simplify=True)至此,pt2onnx这个模块我们就完美通过了
当然,也可以按照飞哥改动的代码一段段找寻新版本ultralytics的对应语句一句句注释后,重构函数去适配这个项目的网络,因为工程量有点大,笔者只是个大二学生,平时还有很多课和比赛项目等待完善,暂时完成不了,我相信会有比我有时间有能力的大佬出现解决这个问题的。
Ⅱ:onnx2ncnn部分
//pt2onnx模块一样容易出问题的部分
主要问题:
根据社区大家的反馈,社区当时使用的在线转换工具已经失效。
根据ncnn-20240820日志,onnx2ncnn在这个版本后也停止了维护,推荐大家使用
PNNX转换。
我在使用onnx2ncnn工具后,得到命令行的反馈,遂按照提示使用PNNX对导出的
onnx做最终转换。很遗憾。我最终导出的模型部署依旧闪退了。
//对不起nihui大佬,我还是太弱小了/(ㄒoㄒ)/~~
在我几天熬夜查找bug后(哎,断电了,只能打灯看屏,心酸啊),最终发现,对
比飞哥项目中给出的两个样例的网络层次(yolov8n/yolov8s),我发现同样是
yolov8n,我使用PNNX导出的param&bin的ncnn模型的网络各层次与飞哥给出的样
例大相径庭,那么到这里,就解决问题了,程序闪退和工程项目中其他任何文件都
无关,问题就是出在了导出模型上。
原因解析:
PNNX导出模型时会删除尾部permute,导致和适配模型的框架不符合
而此时onnx2ncnn工具又停止维护了,笔者到这里陷入了沉默。有幸在闲暇时多看
了一些ncnn社区大佬们的开源项目,我得到了解决方案。
同样也希望和我一样的学生朋友们在学习时也能多多的从大佬的项目中吸取经验,
求同存异。
解决方案:
核心理念:停止维护≠无法使用
因为飞哥给的样例模板很干净整洁:such👇
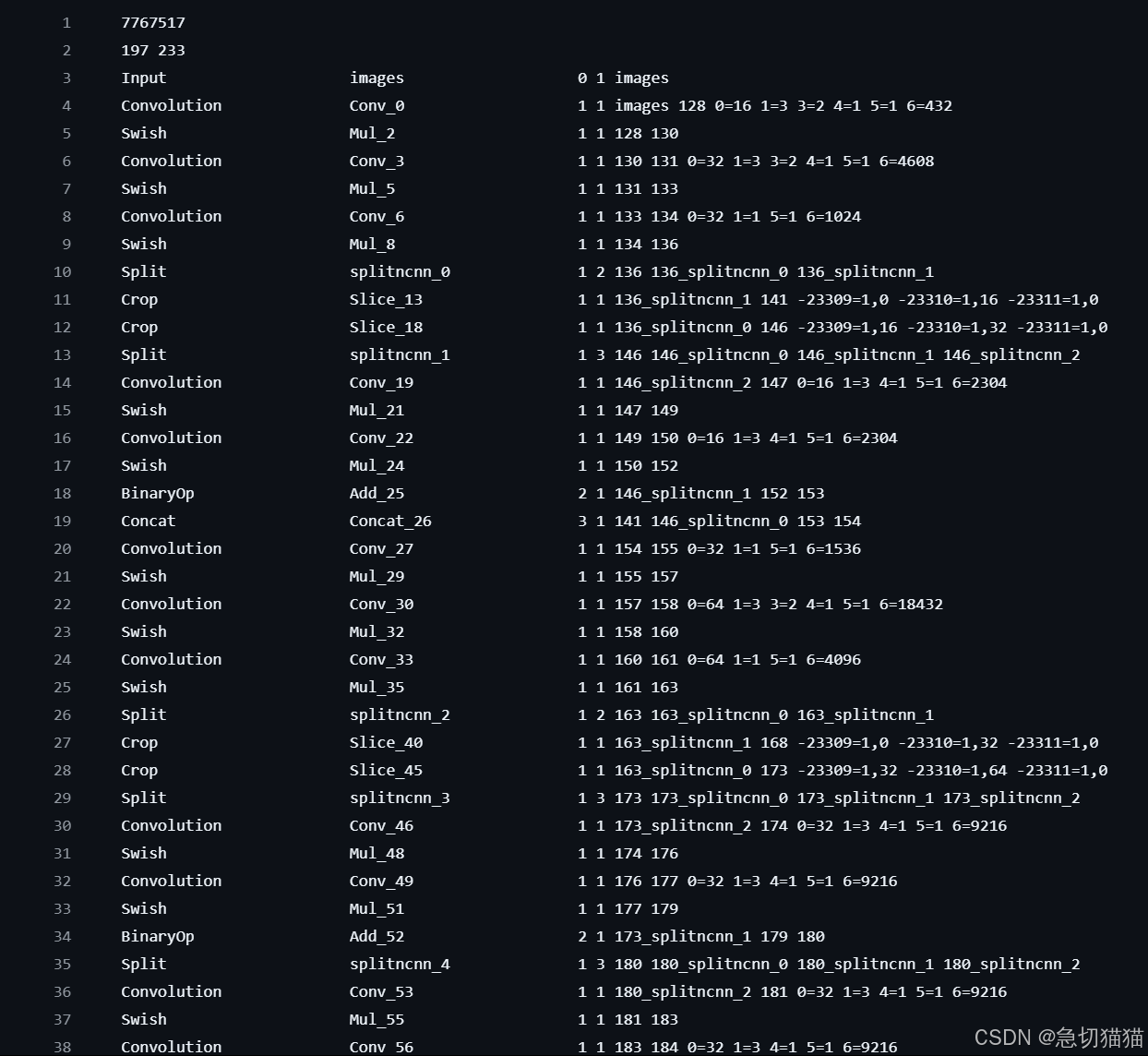
而这是我最后输出可用的parma:such👇
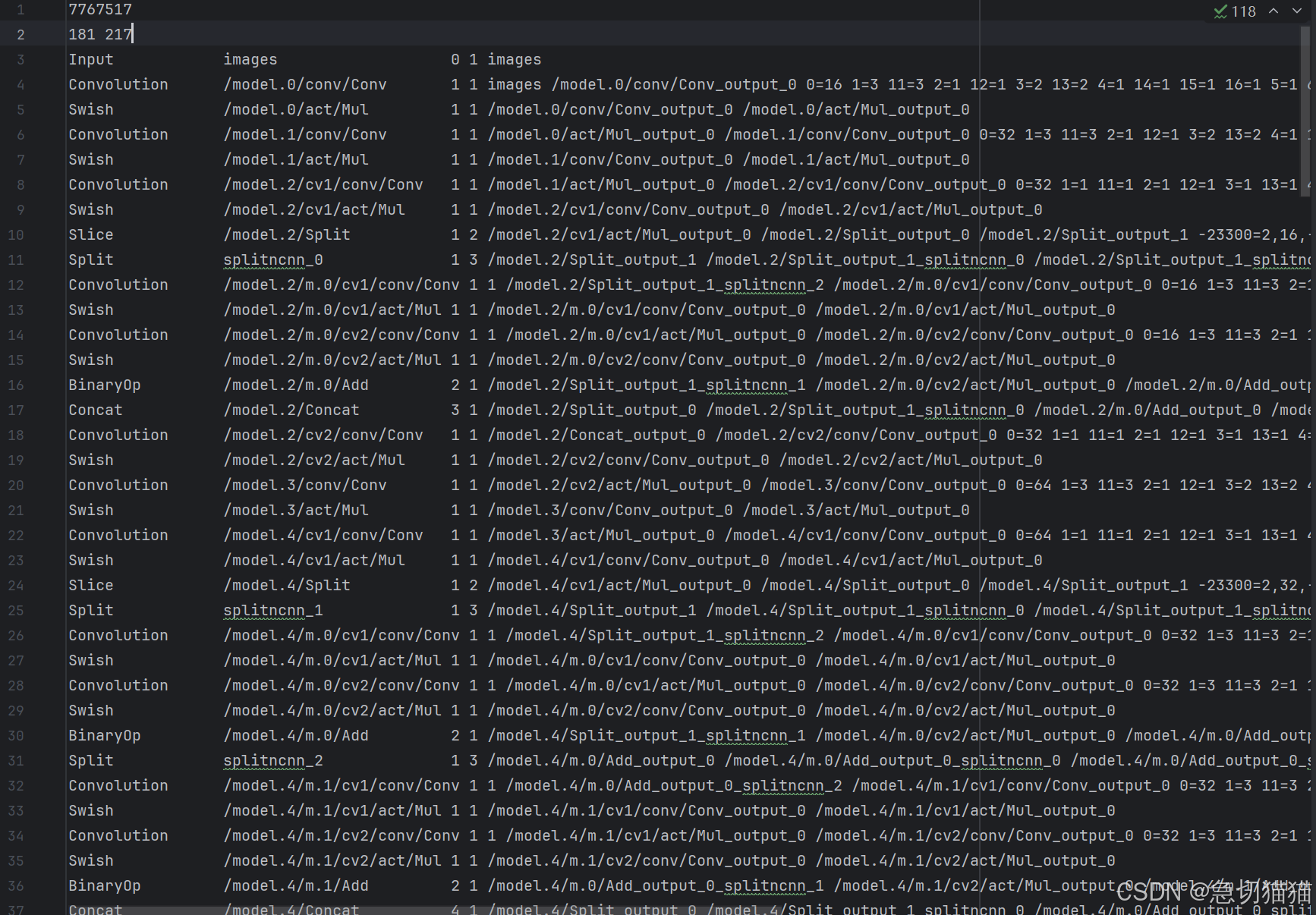
所以最初免不得产生很强的疑惑,我导出来这是什么玩意?
于是愚蠢的开始想要按照飞哥的样例想要手动裁剪自己的导出模型使得架构能够适
配这个项目(被自己蠢晕了)。最后真的没办法了就先去做Android项目的UI和界面
设计逻辑了,但是最后在一个月黑风高的凌晨,我在合电脑之前不甘心自己的失败
想要看看这个项目有没有人做迁移部署,于是登上了GitHub寻找自己答案,最终,
我发现在一些大佬的开源项目中,他们配置的param也如上图一般丑陋,哈哈!丑
陋是无罪的!
我是今年十月中旬才接触到这个项目的,没机会用大家提及的在线转换工具和断维
护前的onnx2ncnn,所以才会有这些问题,相信从这个时间段往后的新朋友们会需
要这份解答。我的样例同样上传到了GitHub中,供大家参考(自定义训练了恶搞之
家的dataset)
Point1:
上图不是我最初的param,这是从一个可执行param中截取的片段,因为我知道到
这步依旧会有一些朋友会出一些问题,比如在param中出现了这样的东西:
Convolution onnx::/model.0/conv/Conv 1 1 images onnx::/model.0/conv/Conv_output_0 0=16 1=3 11=3 2=1 12=1 3=2 13=2 4=1 14=1 15=1 16=1 5=1 6=432
Swish onnx::/model.0/act/Mul 1 1 onnx::/model.0/conv/Conv_output_0 /model.0/act/Mul_output_0
Convolution onnx::/model.1/conv/Conv 1 1 onnx::/model.0/act/Mul_output_0 /model.1/conv/Conv_output_0 0=32 1=3 11=3 2=1 12=1 3=2 13=2 4=1 14=1 15=1 16=1 5=1 6=4608
Swish onnx::/model.1/act/Mul 1 1 onnx::/model.1/conv/Conv_output_0 /model.1/act/Mul_output_0
Convolution onnx::/model.2/cv1/conv/Conv 1 1 onnx::/model.1/act/Mul_output_0 /model.2/cv1/conv/Conv_output_0 0=32 1=1 11=1 2=1 12=1 3=1 13=1 4=0 14=0 15=0 16=0 5=1 6=1024
Swish onnx::/model.2/cv1/act/Mul 1 1 onnx::/model.2/cv1/conv/Conv_output_0 /model.2/cv1/act/Mul_output_0层名和参数是我瞎写的,不用一个个去对照,重点是这个onnx::
出现这个东西,大概率这个ncnn模型从训练到导出的全流程就都G囖!
Point1-reason:
出现这种情况大概率整个网路都是错的,究其原因还是因为版本的问题,建议老兄
还是老老实实去换成8.0.xx的大版本,同时,需求的onnx最稳定版本是1.16.1,
onnxruntime和onnx-simplyfiy就随意啦!
Point1-reply:
建议从解决闪退的部分开始按照我的流程走一遍
2.yolo.cpp/yolov8ncnn.cpp修改错误
修改位置Ⅰ:
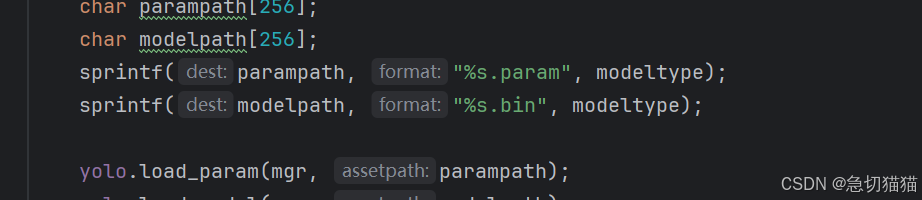
此处与yolov8ncnn.cpp联动组合路径,%s拿取的modeltype来自yolov8ncnn.cpp的字串组
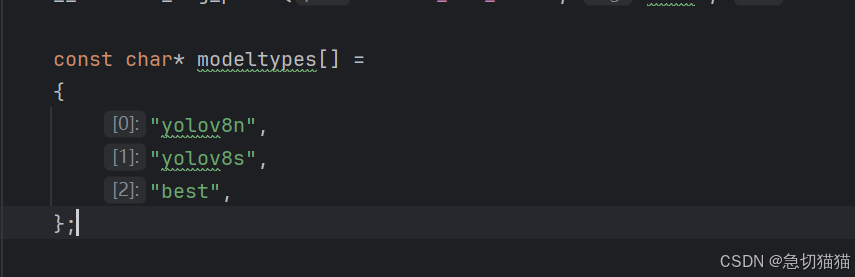
飞哥的原文是:

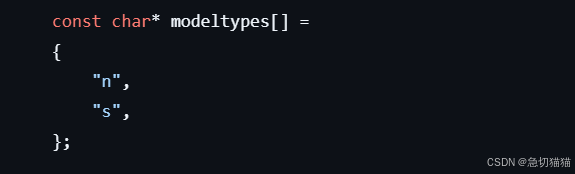
对于自定义部署模型来说,我觉得这两个分开写有点小麻烦,就做了些更改,只要把modeltype组中字串改名即可链接我们的模型路径。
修改位置Ⅱ:
注意模型的IO,images/output是飞哥的样例模型的IO,当我们使用onnx2ncnn工具
时,导出的模型IO为images/output0
Func1:靠拢模板,修改param最后层output0为output。
Fucn2:靠拢模型,修改yolo.cpp下IO为images/output0。
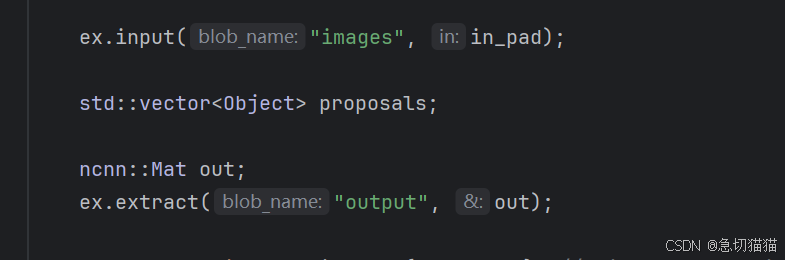
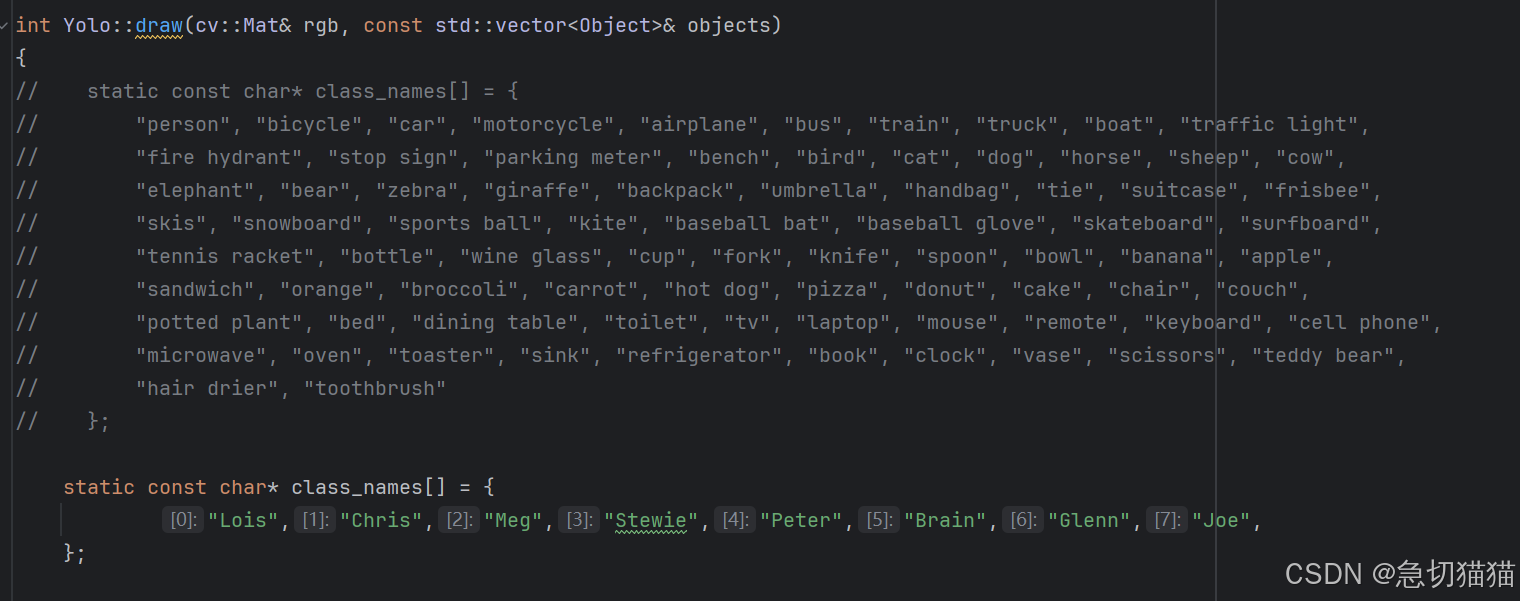
修改位置Ⅲ:
注意修改模型的类,需要同时修改类的数量(num_class)和标签(class_names),数量
应<=标签数。

放个乱框在这里,希望大家不要出这个问题<( ̄︶ ̄)↗[GO!]

这差不多是这个项目在目前时间戳的一些主流问题,一些涉及项目DIY和自主创新的操作教程我应该会在本周末有空的时候撰写,同时我也会出一个全流程的教程给需要的小白们,之后有机会应该会录个视频发B站,这是我的B站UID:455584611
请期待我的更新吧!
至此FIX板块就彻底完结啦,今晚真的是花了好久写这个文档呢,给个免费的赞应该可以吧♥
同时欢迎关注专栏Android端部署YOLOV8
我将在专栏中持续更新相关内容
再次感谢腾讯优图实验室的开源ncnn项目和ncnn社区一众大佬的开源项目帮助!
爱你们!

















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









