







经典查找排序算法
体验算法之美
算法其实离我们不远,它就是一个程序段或者一个函数,我们在日常编码中也会不自觉地使用算法的思想,只要有意识的运用这些思想,就能解决原本不在我们智商范围内的问题。比如使用“递归”的思想就能轻松和那个解决用于智商测试的汉诺塔问题。可以用算法可视化工具或者网站帮助理解。算法可视化网站
- 如果要用递归思想解决问题,就可以将问题简化,抽象出最简单的一次运算,然后迭代这种运算即可。

n个盘子时,需要三部:
1.把n-1个盘子从A经过C移动到B
2. 把第n个圆盘从A移动到C
3. 把第n个圆盘从A移动到C
def hanoi(n,a,b,c): # n表示盘子的个数,a,b,c表示柱子的名字
if n > 0:
hanoi(n - 1, a, c, b)
print("moving from %s to %s"%(a,c))
hanoi(n - 1, b, a, c)
复杂的问题,巧妙的逻辑,简介的代码,多少是有点赏心悦目了。
常见查找算法
- 暴力查找(太过暴力,不解释)
def liner_search(li, val):
for index, v in enumerate(li): # 历数 li中元素的索引和值
if v == val:
return index
else:
return None
- 二分查找:也很朴素的思想,类似于猜价格,给定一个区间,比如100-500,我们肯定会去先猜(100+500)/2=300,如果人家说我们猜的这个数大了,我们就找(100+300)/2=200,如果人家说我们猜的这个数小了,我们就去找(200+300)/2=250,如果答案是250,我们用了三次机会就猜对了,如果不是就还按这样的逻辑一直折半继续猜,代码如下:
# 二分查找的条件是列表有序
def binary_search(li, val):
left = 0
right = len(li) - 1
while(left <= right): #候选区有值
mid = (left + right) // 2
if li[mid] == val:
return mid
elif li[mid] > val:
right = mid - 1
else:
left = mid + 1
return None
十大排序算法
3种朴素的排序算法
- 冒泡排序重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。其实每次都选出一个最大/最小值,冒泡到最后面的位置(最后面的位置可以看成是需要维护的有序部分),代码如下:
# 从小到大排序
def bubble_sort(li):
for i in range(len(li) - 1): #第i趟
exchange = False
for j in range(len(li) - i - 1):
if li[j] > li[j + 1]:
exchange = True
li[j], li[j+1] = li[j+1], li[j]
print(li)
if not exchange: # 如果第一次没有发生交换,说明值本身就是有序的,直接退出
return li
return li
- 插入排序:它的基本思想是将一个记录插入到已经排好序的有序表中,从而产生一个新的、记录数增1的有序表。在实现的过程中为了降低空间复杂度,复用原本的存储空间,将数组最前面的部分视为需要维护的有序部分,在对后面部分遍历的每一趟,前面有序的部分长度就增长1;插入排序可以理解为在斗地主,我们手里的牌是按8、9、10、J、Q排好的,在摸牌的过程中,比如下一张摸到8,我们逐个扫描手里的牌,寻找刚好不大于摸到牌点数的那张手牌,把摸到的牌插到这张牌后面。然后这张牌后面的牌都忘后挪一挪。代码如下:
def insert_sort(li):
# 可以用摸一手牌,继续摸牌时对牌排序
for i in range(1,len(li)): #i表示摸到的牌的下标
tmp = li[i]
j = i - 1 #j指的是手里最后一张牌的下标 && 每一趟
while j >= 0 and li[j] > tmp:
li[j + 1] = li[j] # 将比摸到的牌数大的手牌往右移,即下标+1
j -= 1 # 看下一张
li[j + 1] = tmp # 此时j就是第一张比摸到的牌小的牌或者j已经是-1,那么手牌存到j+1中
- 选择排序:它的工作原理是:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法(所谓不稳定,是指值相等的元素,在排序的过程中不能保持他们原有的位序,一般来说,挨个做交换的排序算法是稳定的,跳着交换的排序算法是不稳定的)。代码如下:
def select_sort(li):
for i in range(len(li) - 1):#i是第几趟 在倒数第二趟时,已经选走了较小值,留下了较大值,所以不需要进行最后一趟
min_loc = 0
for j in range(i + 1, len(li)): # 0-i表示我们需要维护的局部的有序列表 ,用j遍历寻找无序列表中的最小值,同时有序列表向右扩张1位,无序列表向右收缩一位
if li[min_loc] < li[j]:
min_loc = j
li[i], li[min_loc] = li[min_loc], li[i]
3种高级的排序算法
- 归并排序:归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。这里也用到了递归的思想,我一直分段,直到每一段都只有一个元素,一个元素当然有序了,然后我就从函数栈中往回调用,做分段的反操作(归并),最后整体有序了。
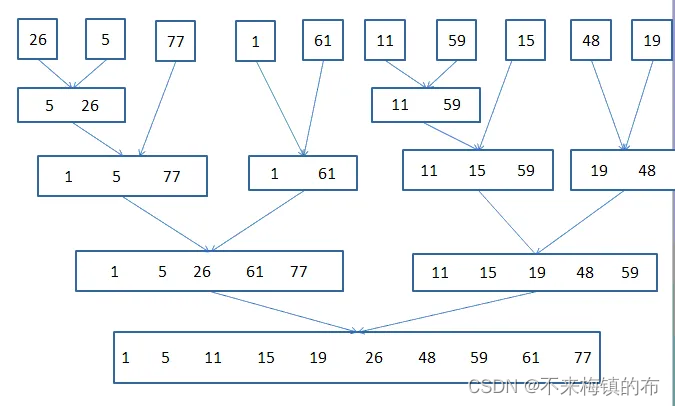 代码如下:
代码如下:
def merge(li,low,mid,high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high: #只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i = i + 1
else:
ltmp.append(li[j])
j = j + 1
# while执行完,左右两部分肯定有一部分没数了
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp
# 使用递归来简化问题,在分左右子集的过程中最后左右两边都是只有一个数,所以是有序的,然后再回溯,组合起来的子集也是有序的
def merge_sort(li,low,high):
if low < high: #至少有两个元素,递归
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid + 1, high)
merge(li, low, mid,high)
- 快速排序:该算法通过多次比较和交换来实现排序,其排序流程如下:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
排序算法千千万,而它敢叫快速排序,完全不把其他排序算法放在眼里的那种,肯定是有点东西的!代码如下:
def partition(li, left ,right):
tmp = li[left] # 将最左边的值存起来,然后这个位置用于存搜寻到的比tmp小的值
while left < right:
while left < right and li[right] >= tmp: #从右边找比tmp小的数
right -= 1
li[left] = li[right] #把右边的值写到左边的空位上 此时右边为空位
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left] #·把左边的值写到右边的空位上
li[left] = tmp #把tmp归位
return left
def quick_sort(li, left, right):
if left < right:
mid = partition(li, left, right)
quick_sort(li, left, mid - 1)
quick_sort(li, mid + 1, right)
- 堆排序:在堆的数据结构中,堆中的最大值总是位于根节点(在优先队列中使用堆的话堆中的最小值位于根节点)。堆中定义以下几种操作:
最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
创建最大堆(Build Max Heap):将堆中的所有数据重新排序
堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算 。
排序的过程是这样的,通过迭代sift函数(最大堆调整)创建一个堆,然后从尾开始遍历,一直调用HeapSort,将最后的数与堆顶的最大值做交换,然后重新选出最大值,然后再交换,总把最大值放在堆末尾并维护成一个有序区。(堆排序相对来说最难理解,而且运算速度在三巨头中也属于较慢的,而且是不稳定的排序,不过它引入了堆的思想,可以有很多变式)

代码如下:
def sift(li, low, high):
"""
li: 列表
low: 堆的根节点位置
high: 堆的最后一个元素的位置
"""
i = low
j = 2 * i + 1 #j开始是左孩子
tmp = li[low] #把堆顶存起来
while j <= high: #只要j位置有数
if j+1 <= high and li[j + 1] > li[j]: #如果有右孩子,并且右孩子比较大
j = j + 1 #j指向右孩子
if li[j] > tmp:
li[i] = li[j] #把孩子上的数放上去
i = j #往下看一层
j = 2 * i + 1
else: #tmp更大,把tmp放到i的位置上
li[i] = tmp #把tmp放到某一级领导位置上
break
else:
li[i] = tmp #把tmp放在叶子节点上
#1.先建堆
#2.挨个出数
def heap_sort(li):
n = len(li)
for i in range((n-2)//2, -1, -1):
#i表示建堆的时候调整的部分的根的下标
sift(li, i, n-1)
#建堆任务完成了
for i in range(n-1, -1, -1):
# i指向当前堆的最后一个位置
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1) # i-1 是新的high
四种扩展的排序算法
- 桶排序:原理是将数组分到有限数量的桶里。每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。代码如下:
def bucket_sort(li,n = 5, max_number = 10): # n表示分的桶的个数,max_number表示数的范围
buckets = [[] for _ in range(n)] #用列表创建式创建一个二维列表,用来表示所有的桶
for val in li:
i = min(val // (max_number // n), n - 1) # i表示var放到几号桶里
buckets[i].append(val) # 把val加到桶内
# 以下代码维持该桶内有序
for j in range(len(buckets[i]) - 1, 0, -1):
if buckets[i][j] < buckets[i][j - 1]:
buckets[i][j],buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]
else:
break
sorted_li = []
for buc in buckets:
sorted_li.extend(buc) # [].extend函数:把一个列表添加到本列表后边
return sorted_li
- 基数排序: 将所有待比较数值(自然数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列(对高位进行排序的过程中必须使用稳定的排序算法)。

代码如下:
def radix_sort(li):
max_num = max(li) #最大值
# 需要确定最大值的位数来确定进行桶排序的次数 最大值 p->1,99->2,888>3,10000->5
# 确定位数可以用log10,也可以:
it = 0
while 10 ** it <= max_num:
buckets = [[] for _ in range(10)] #分十个桶
for var in li:
digit = (var // 10 ** it) % 10 #取该位上的数
buckets[digit].append(var)
#分桶完成
#把数重新写回li
li.clear()
for buck in buckets:
print(buck,end=',')
li.extend(buck)
it += 1
print('')
return li
- 计数排序:确定数组的值域,创建一个集合,键为值域内的整数(或者步长),集合的值为数组中等于该键的数字的个数,然后将这个键值对集合输出成一个数组。(计数排序假设数据中所有值都是整数)代码如下:
def count_sort(li,max_count = 100):
count = [0 for _ in range(max_count + 1)]
for val in li:
count[val] += 1
li.clear()
for ind, val in enumerate(count):
for i in range(val):
li.append(ind)
- 希尔排序:希尔排序是把数组按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的要素越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止,希尔排序是对插入排序算法的一种改进,该算法是冲破O(n2)的第一批算法之一。

希尔排序代码如下:
def insert_sort_gap(li, gap):
for i in range(gap,len(li)): # i表示摸到的牌的下标
tmp = li[i] # tmp表示摸到的牌
j = i - gap # j指的是手里的牌的下标
while j >= 0 and li[j] > tmp:
li[j + gap] = li[j]
j -= gap
li[j + gap] =tmp
print(i)
def shell_sort(li):
d = len(li) // 2
while d >= 1:
insert_sort_gap(li, d)
d //= 2
return li
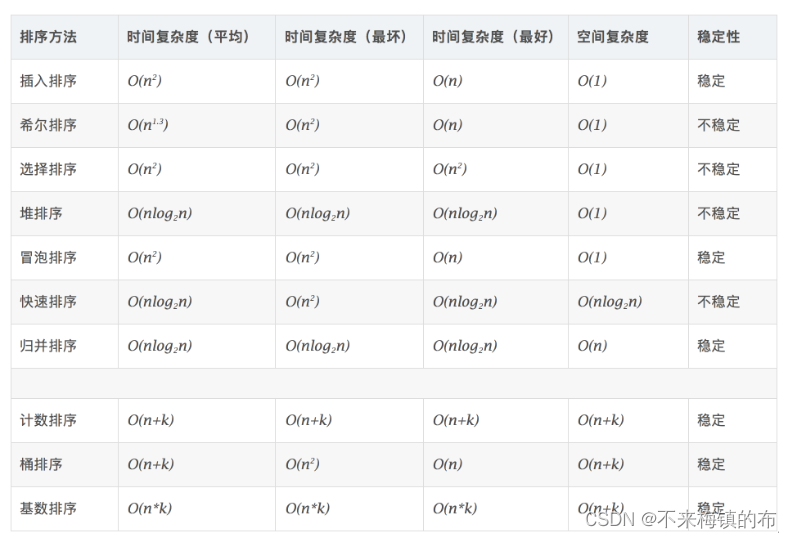
十大排序算法比较















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









