







3.9 表分区
3.9.1 表分区概述
Hive 分区partition (订单介绍)
必须在表定义时指定对应的partition字段,分区的本质相当于在表的目录下在分目录进行数据的存储。
分区好处:
查询时可以通过过滤不需要的分区下的数据,减少查询时的磁盘IO操作。
单分区建表语句:
create table day_table (id int, content string) partitioned by (dt string);
单分区表,按天分区,在表结构中存在id,content,dt三列。以dt为文件夹区分
双分区建表语句:
create table day_hour_table (id int, content string) partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
先以dt为文件夹,再以hour子文件夹区分
理论上分区的个数可以任意多,但是常用的为单分区和双分区。
**注意:**定义分区和格式化语句的位置(在row format 上边)分区的元数据保存到mysql的hive_remote数据库实例的表中: PARTITION_KEYS、PARTITION_KEY_VALS、PARTITIONS。
3.9.1 单分区
建表
create table person5(
id int comment "唯一标识id",
name string comment "名称",
likes array<string> comment "爱好",
address map<string,string> comment "地址"
)
partitioned by(age int)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n";
查看表的信息
hive> desc formatted person5;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array<string> 爱好
address map<string,string> 地址
# Partition Information
# col_name data_type comment
age int
。。。。。。。。。。。。
注意分区字段不能出现在脚本的table后面的小括号中。
添加数据
hive> load data local inpath
'/root/data/person.txt' into table person5;
Query ID = root_20211111203223_7dd1d883-7d5d4d71-bd0e-dfb74c08da40
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since
there's no reduce operator
......
Loading data to table default.person5 partition
(age=null)
#hdfs路径:
person5/age=__HIVE_DEFAULT_PARTITION__
一定要指定对应的分区数据
hive> load data local inpath '/root/data/person.txt' into table person5 partition(age=10);
Loading data to table default.person5 partition (age=10)
OK
Time taken: 2.304 seconds
3.9.2 双分区
建表
create table person6(
id int comment "唯一标识id",
name string comment "名称",
likes array<string> comment "爱好",
address map<string,string> comment "地址"
)
partitioned by(age int,sex string)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n";
查看表信息:
hive> desc formatted person6;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array<string> 爱好
address map<string,string> 地址
# Partition Information
# col_name data_type comment
age int
sex string
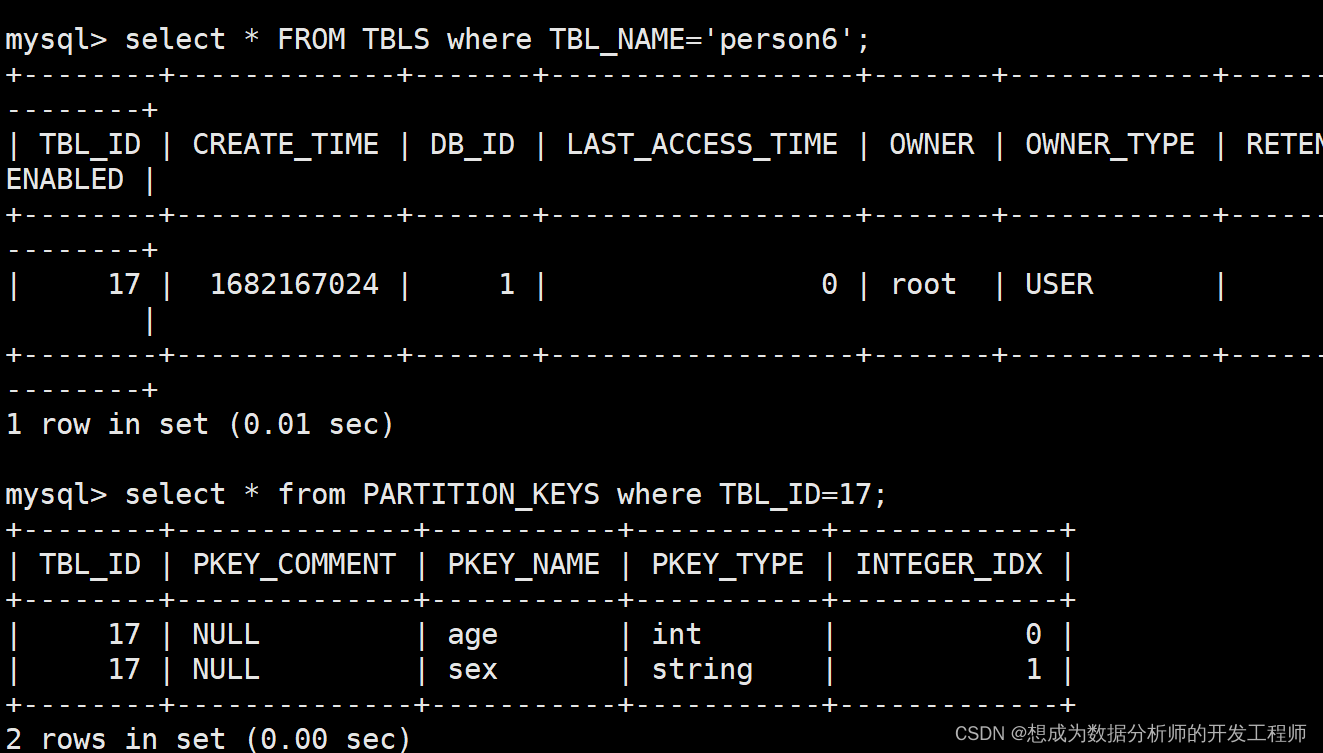
添加数据
加载数据时,分区先写谁都可以,但是属性名称不能写错了。
hive> load data local inpath '/root/data/person.txt' into table person6 partition(age=20,sex='man');
Loading data to table default.person6 partition (age=20, sex=man)
OK
Time taken: 0.813 seconds
hive> load data local inpath '/root/data/person.txt' into table person6 partition(age=30,sex='man');
Loading data to table default.person6 partition (age=30, sex=man)
OK
Time taken: 0.784 seconds
hive>
> select * from person6
> ;
OK
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 20 man
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 20 man
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 20 man
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"} 20 man
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "} 20 man
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 20 man
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "} 20 man
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "} 20 man
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"} 20 man
1 小明1 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 30 man
2 小明2 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 30 man
3 小明3 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 30 man
4 小明4 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong"} 30 man
5 小明5 ["lol","movie"] {"beijing":"xisanqishanghai:pudong "} 30 man
6 小明6 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudong "} 30 man
7 小明7 ["lol","book"] {"beijing":"xisanqishanghai:pudong "} 30 man
8 小明8 ["lol","book"] {"beijing":"xisanqishanghai:pudong "} 30 man
9 小明9 ["lol","book","movie"] {"beijing":"xisanqishanghai:pudon"} 30 man
Time taken: 2.409 seconds, Fetched: 18 row(s)
load数据时,分区先写谁都可以,但是分区字段名称不可以写错
该命令共做了三件事情:
在hdfs上创建目录,和创建表的顺序有关,和load数据时写的分区字段的顺序无关
讲数据文件上传到对应的目录上
在元数据的数据库实例hivve_remote表PARTITIONS中添加分区信息
3.9.3 添加分区
hive文档链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
(表已创建,在此基础上添加分区,注意只能添加在表创建时定义好的分区的值)
语法格式
alter table table_name add [if not exists]partition partition_spec [location 'location'][, partition partition_spec [location'location'], ...];
partition_spec:
: (partition_column = partition_col_value,partition_column = partition_col_value, ...)
偶遇报错:
FAILED: SemanticException Unable to fetch table person5. Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: java.net.ConnectException: 拒绝连接 (Connection refused)
at org.apache.thrift.transport.TSocket.open(TSocket.java:226)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:516)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.reconnect(HiveMetaStoreClient.java:379)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient$1.run(RetryingMetaStoreClient.java:187)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
处理方法
重新连接hive
[root@node3 ~]# hive --service metastore &
[1] 13910
添加操作
#单分区可以直接指定
hive> alter table person5 add partition(age=30);
OK
Time taken: 3.063 seconds
# 双分区必须指定两个分区名称,不可以单独指定
hive> alter table person6 add partition(age=40);
FAILED: ValidationFailureSemanticException default.person6: partition spec {age=40} doesn't contain all (2) partition columns
# 正常操作
hive> alter table person6 add partition(age=40,sex='man');
OK
Time taken: 0.304 seconds
# 不允许重复添加分区
hive> alter table person6 add partition(age=40,sex='man');
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. AlreadyExistsException(message:Partition already exists: Partition(values:[40, man], dbName:default, tableName:person6, createTime:0, lastAccessTime:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:唯一标识id), FieldSchema(name:name, type:string, comment:名称), FieldSchema(name:likes, type:array<string>, comment:爱好), FieldSchema(name:address, type:map<string,string>, comment:地址)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{mapkey.delim=:, collection.delim=-, serialization.format=,, line.delim=
, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), parameters:{totalSize=0, numRows=0, rawDataSize=0, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true","COLUMN_STATS":{"address":"true","id":"true","likes":"true","name":"true"}}, numFiles=0}, catName:hive))
单分区的表添加分区时指定一个分区,可以直接添加。
表在创建时定义的时双分区,条件分区值时,不能只指定一个,需要同时指定两个分区的值。
3.9.4 删除分区
语法格式
alter table table_name drop [if exists]
partition partition_spec[, partitionpartition_spec, ...] [ignore protection] [purge];
双分区表,可以通过指定两个分区值进行删除:
删除前
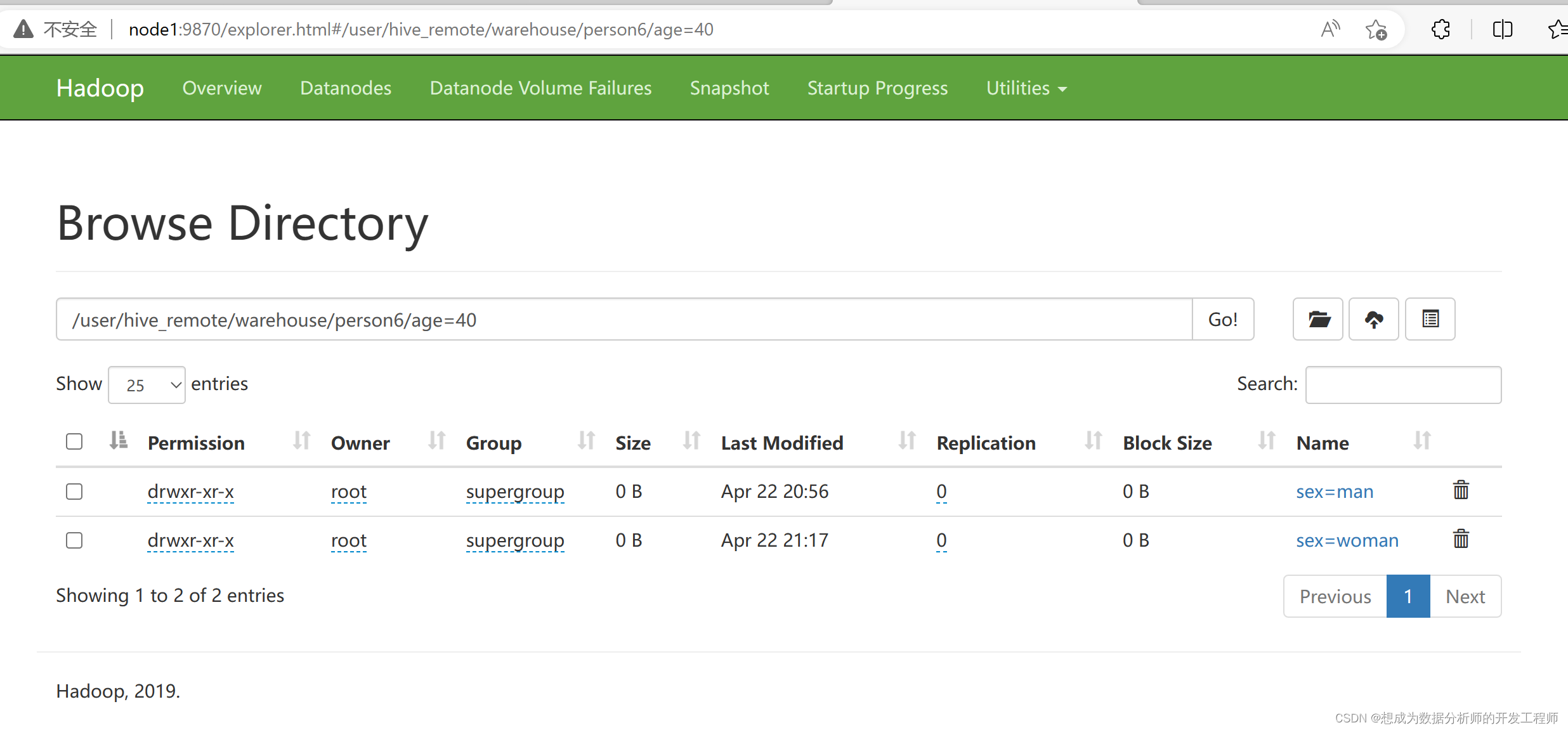
hive> alter table person6 drop partition(age=40,sex='woman');
将age=40 sex=woman删除,age=40,sex=man不删除
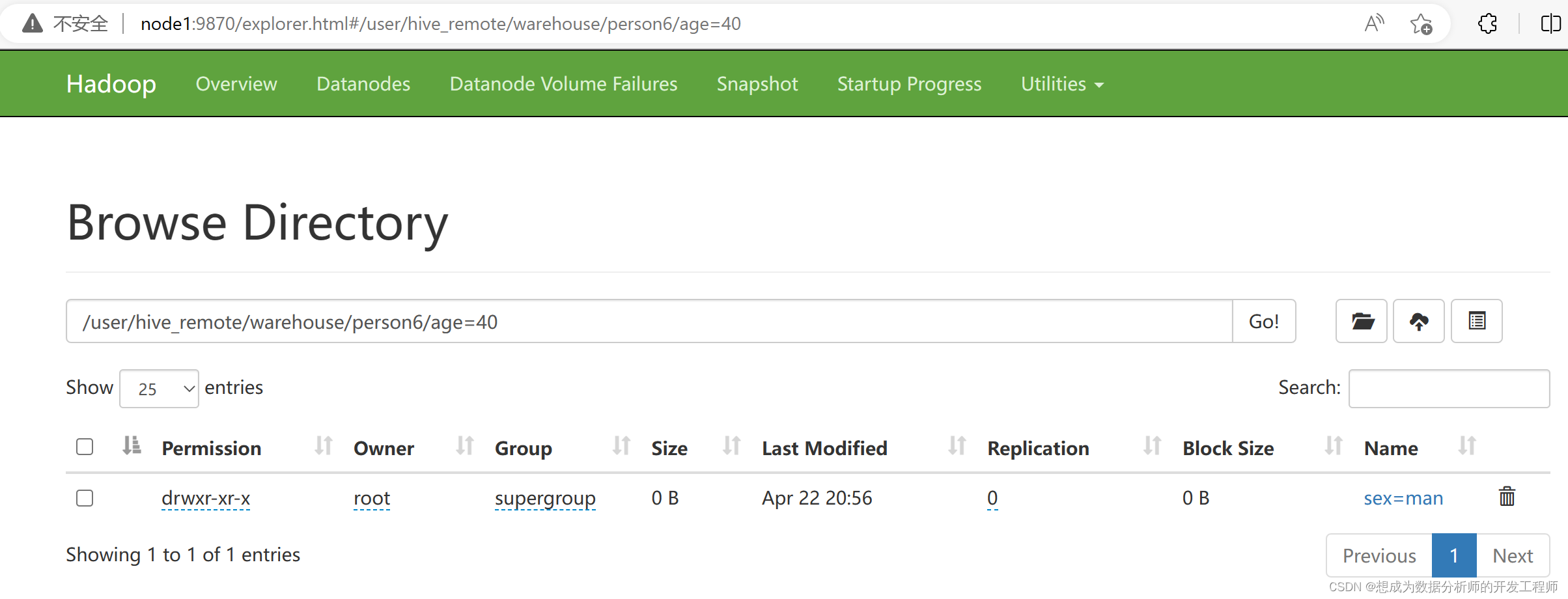
双分区表,可以通过指定一个分区(父级)值进行删除:
hive> alter table person6 drop partition(age=30);
Dropped the partition age=30/sex=man
OK
Time taken: 0.375 seconds
将age=30的分区的所有值都删除
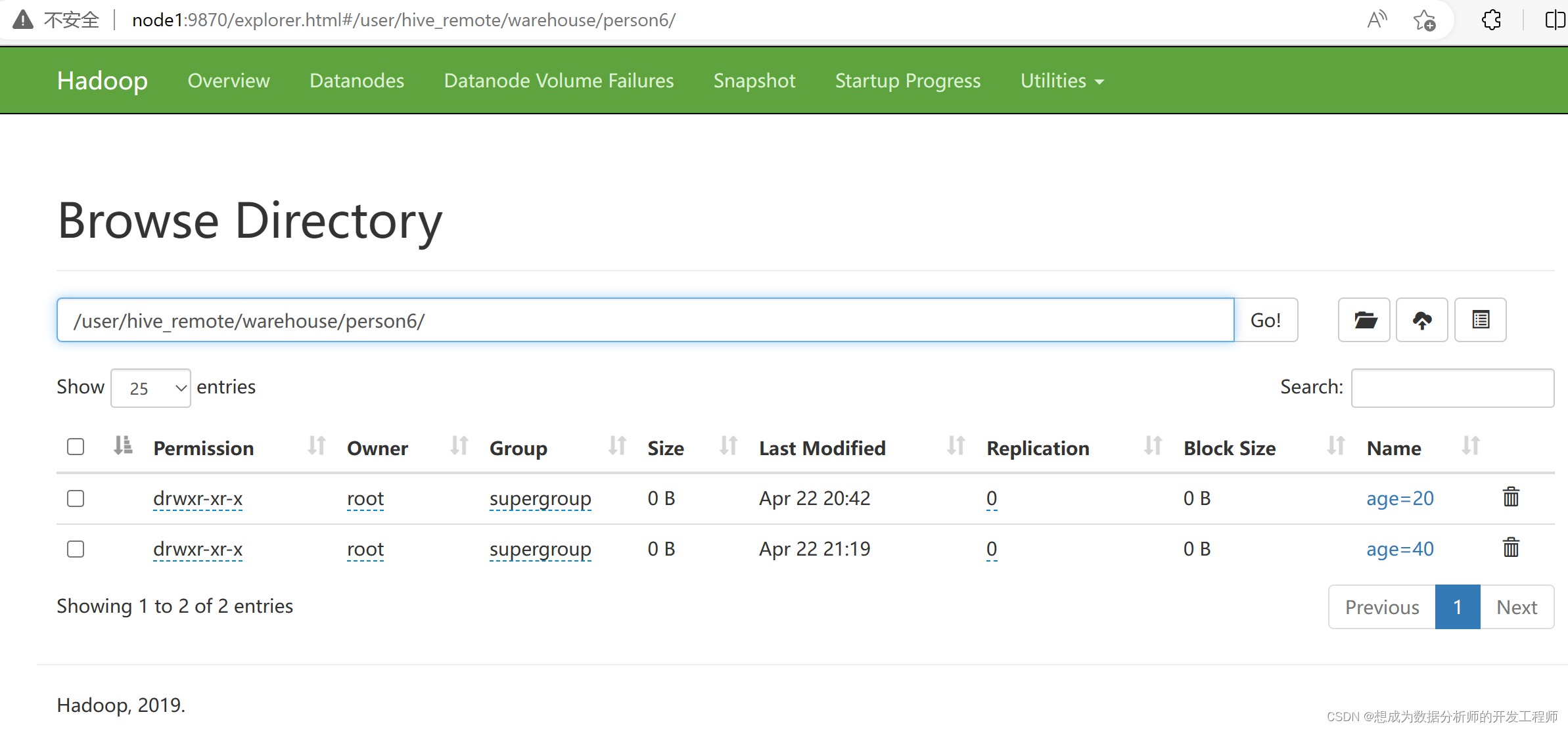
双分区表,可以通过指定一个分区(子级)值进行删除:
hive> alter table person6 drop partition(sex='man');
Dropped the partition age=20/sex=man
Dropped the partition age=40/sex=man
OK
Time taken: 0.379 seconds
如果age=20下只有sex=‘man’,那么在删除sex='man’时,age=20也会被删除掉。
3.9.6 修复分区
语法格式
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
msck [repair] table table_name [add/drop/sync partitions];
先在hdfs上创建目录
[root@node4 ~]# hdfs dfs -mkdir /usr/person7
[root@node4 ~]# hdfs dfs -ls /usr/
Found 3 items
drwxr-xr-x - root supergroup 0 2023-04-22 19:18 /usr/external
-rw-r--r-- 3 root supergroup 493 2023-04-22 19:04 /usr/person.txt
drwxr-xr-x - root supergroup 0 2023-04-22 21:25 /usr/person7
root@node4 ~]# hdfs dfs -mkdir /usr/person7/age=10
[root@node4 ~]# hdfs dfs -put /root/data/person.txt /usr/person7/age=10
2023-04-22 21:26:47,702 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[root@node4 ~]# hdfs dfs -ls /usr/person7/age=10
Found 1 items
-rw-r--r-- 3 root supergroup 493 2023-04-22 21:26 /usr/person7/age=10/person.txt
创建外部表person7
create external table person7(
id int comment "唯一标识id",
name string comment "名称",
likes array<string> comment "爱好",
address map<string,string> comment "地址"
)
partitioned by(age int)
row format delimited
fields terminated by ","
collection items terminated by "-"
map keys terminated by ":"
lines terminated by "\n"
location '/usr/person7';
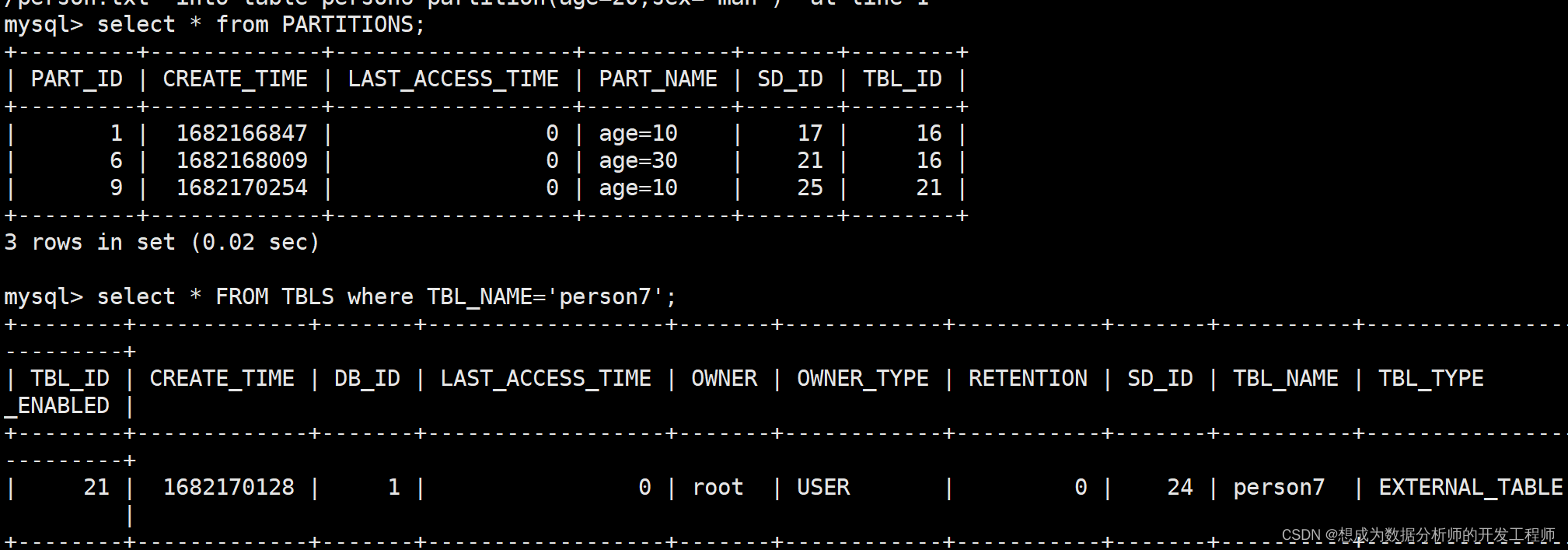
创建完表后,并不会将对应的分区信息同步到MySQL数据库的元数据中在TBLS表中存在person7,它的id为31;然后去PARTITIONS表中存在,找到对应的信息。
可以通过修复分区来实现:
hive> msck repair table person7;
OK
Partitions not in metastore: person7:age=10
Repair: Added partition to metastore person7:age=10
Time taken: 0.4 seconds, Fetched: 2 row(s)
3.10 使用已有表建表(扩展)
3.10.1 Create Table Like
Create Table Like:
只创建相同结构的空表,没有具体的表中的数据。
语法格式:
create [temporary] [external] table [if not exists] [db_name.]table_name
like existing_table_or_view_name
[location hdfs_path];
实操演示:
hive> select * from person3;
OK
1 小明3 ["lol","book","movie"] {"beijing":null,"xisanqi":"shanghai\u0003pudong"}
Time taken: 3.729 seconds, Fetched: 1 row(s)
hive> create table person8 like person3;
OK
Time taken: 2.617 seconds
hive> select * from person8;
OK
Time taken: 0.305 seconds
hive> desc formatted person8;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array<string> 爱好
address map<string,string> 地址
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Sun Apr 23 07:15:15 CST 2023
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/user/hive_remote/warehouse/person8
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"address\":\"true\",\"id\":\"true\",\"likes\":\"true\",\"name\":\"true\"}}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1682205315
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.204 seconds, Fetched: 33 row(s)
hive> desc formatted person3;
OK
# col_name data_type comment
id int 唯一标识id
name string 名称
likes array<string> 爱好
address map<string,string> 地址
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Sat Apr 22 18:24:17 CST 2023
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/user/hive_remote/warehouse/person3
Table Type: MANAGED_TABLE
Table Parameters:
bucketing_version 2
numFiles 1
numRows 0
rawDataSize 0
totalSize 57
transient_lastDdlTime 1682159627
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.167 seconds, Fetched: 33 row(s)
3.10.2 Create Table As Select (CTAS)
语法格式
create table new_key_value_store
row format serde "org.apache.hadoop.hive.serde2.columnar.columnarserde"
stored as rcfile
as
select (key % 1024) new_key, concat(key, value) key_value_pair
from key_value_store
sort by new_key, key_value_pair;
实操演示
hive> create table person9 as select id,name from person3;
Query ID = root_20211113114654_f824ccc6-9067-43ab-a0a5-5907a0506d2e
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
......
Time taken: 35.093 seconds
hive> select * from person9;
OK
1 小明1
Time taken: 0.419 seconds, Fetched: 1 row(s)
hive> desc formatted person9;
OK
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Sat Nov 13 11:47:29 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://mycluster/user/hive_remote/warehouse/person9
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
bucketing_version 2
numFiles 1
numRows 1
rawDataSize 9
totalSize 10
transient_lastDdlTime 1636775249
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.182 seconds, Fetched: 32 row(s)
在select子句中可以选择需要的字段,既可以将表创建好,也会数据带过来。
3.11 Hive SerDe
Hive SerDe - Serializer and Deserializer
SerDe 用于做序列化和反序列化。
构建在数据存储和执行引擎之间,对两者实现解耦。
Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写。
row_format
: delimited [fields terminated by char [escaped by char]] [collection items terminated by char]
[map keys terminated by char] [lines terminated by char]
[null defined as char]
| serde serde_name [with serdeproperties (property_name=property_value, property_name=property_value, ...)]
Hive正则匹配
CREATE TABLE logtbl (
`host` string,
`identity` string,
`t_user` string,
`time` string,
`request` string,
`referer` string,
`agent` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
将该文件上传到node4的/root/data目录
[root@node4 ~]# cd data/
[root@node4 data]# ls
person3.txt person.txt
[root@node4 data]# rz -E [root@node4 data]#
[root@node4 data]# ls
localhost_access_log.txt person3.txt person.txt
[root@node4 data]# mv localhost_access_log.txt logtb1.txt
在hive中新建表,并load数据到表中,然后在查询数据:
hive> CREATE TABLE logtbl (
> `host` string,
> `identity` string,
> `t_user` string,
> `time` string,
> `request` string,
> `referer` string,
> `agent` string)
> ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
> WITH SERDEPROPERTIES (
> "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
> )
> STORED AS TEXTFILE;
OK
Time taken: 0.366 seconds
hive> load data local inpath '/root/data/logtbl.txt' into table logtbl;
Loading data to table default.logtbl
OK
Time taken: 0.735 seconds
hive> select * from logtbl;
OK
192.168.57.4 - - 29/Feb/2016:18:14:35 +0800 GET /bg-upper.png HTTP/1.1 304 -
192.168.57.4 - - 29/Feb/2016:18:14:35 +0800 GET /bg-nav.png HTTP/1.1 304 -
192.168.57.4 - - 29/Feb/2016:18:14:35 +0800 GET /asf-logo.png HTTP/1.1 304 -
192.168.57.4 - - 29/Feb/2016:18:14:35 +0800 GET /bg-button.png HTTP/1.1 304 -
192.168.57.4 - - 29/Feb/2016:18:14:35 +0800 GET /bg-middle.png HTTP/1.1 304 -
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











