







作者:学Java的冬瓜
博客主页:☀冬瓜的主页🌙
专栏:【JavaEE】
分享:2023.3.31号骑行的照片再发一次(狗头)。
主要内容:非原子操作引发线程安全问题,内存可见性和指令重排序导致线程安全问题。编译器优化导致内存可见性和指令重排序。synchronized和volatile。

文章目录
一、 什么是线程安全问题?
使用多线程编程,运算结果与预期不符合,有很大概率就是线程不安全导致的,比如多个线程修改同一个对象时,运算结果就很可能与预期不符。
在一些极端情况下,也有可能没影响,比如当你开了足够多的进程(或者你的运算量很小,不需要并行执行),你的两三个线程是在CPU同一个核心上并发执行而没有并行执行,那结果可能就符合预期。
-
线程安全问题,最根本的原因是多线程的抢占式执行,操作系统随机调度。当两个线程修改同一个变量时这个修改操作的非原子性也是线程安全的一大原因,此外还有可能是内存可见性,或者是编译器优化导致的指令重排序从而产生线程安全问题。这些在这篇博客中会一一谈及。
1.多线程抢占式执行,操作系统随机调度
2.多个线程修改同一个变量
3.对变量的这个操作是非原子的
4.内存可见性引发线程安全问题
5.指令重排序导致线程安全问题 -
线程安全问题的原因必有1,2两点。
第一点是硬件制作时就定下来的,无法修改。
第二点,当两个或多个线程修改同一个变量(对象)时,有线程安全问题。但是呢,一个线程修改一个变量没问题,多个线程读一个变量也没有线程安全问题,多个线程各自修改多个不同变量也没有线程安全问题。
演示线程安全问题
需求:两个线程每次加一10000次,总共同一个变量增到20000
class Counter{
public int count = 0;
public void add(){
count++;
}
}
public class ThreadTest {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(()->{
for (int i = 0; i < 10000; i++) {
counter.add();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 10000; i++) {
counter.add();
}
});
t1.start();
t2.start();
// 确保俩个线程执行完
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("每个线程自增10000次,共增到20000:"+counter.count);
}
}
结果:
每个线程自增10000次,共增到20000:18502
- 从上面的代码中,我们用两个线程各自每次add(即count+1),每个线程执行了10000次,按道理来说这个count变量最终应该是20000才对,但是结果摆在这里,它并不是20000,其原因就是
多线程的抢占式执行,操作系统的随即调度;两个线程修改同一个变量;还有这个修改操作是非原子性导致。下面我们来看看什么是非原子性:
二、非原子操作
- 在1中的代码,count++在CPU指令中其实是分三步的
load:把内存中的count变量的值拷贝到CPU里的寄存器中
add:将寄存器里的值+1
save:将寄存器里的值拷贝回count变量 - 以上这count++的CPU指令,在单线程下是不会有问题的,而在多线程情况下就不一样了,请继续往下看:
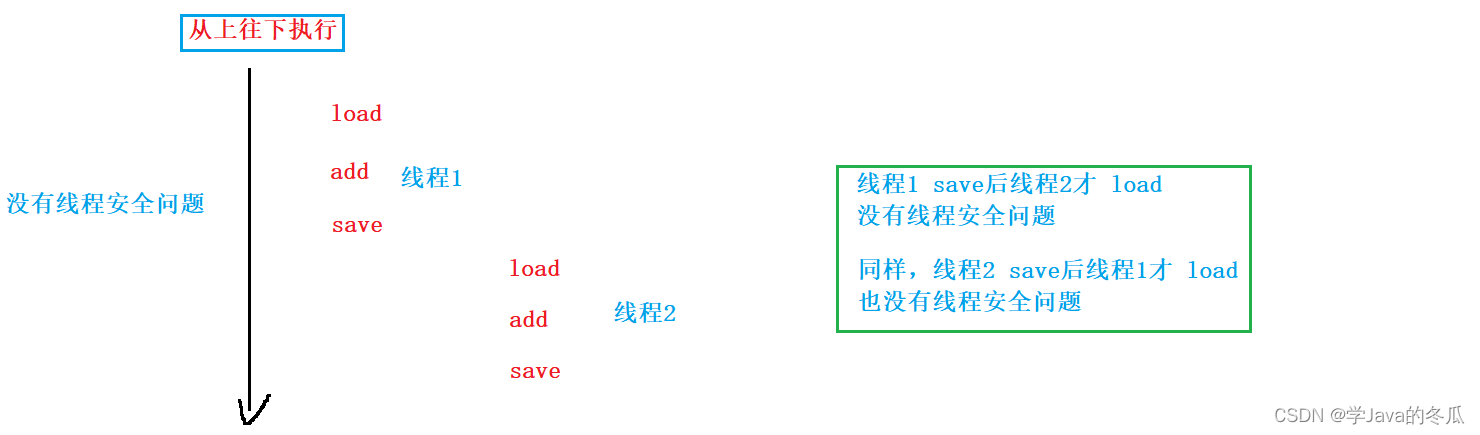

- 从上面例子中我们清晰的看到了线程安全问题导致的结果,那是为什么呢?
如上面所说,线程1 load后还没有save,线程2就 load,导致两个线程都把变量加1,而结果这个变量只自增一次。很明显就是因为这个count++的操作,在CPU指令上来看,不是原子性的,即还可以拆分成load,add,save三个操作,导致两个线程同时修改一个变量时出现错误(这其实很像数据库事务中的脏读,即线程2读到了线程1修改前的数据)。 - 我们来对上面的例子进行更深层次的分析,count结果有没有可能是10000,甚至比10000还小。在运行时我们发现,没有这种情况出现,但是在理论上来说,在极端情况下,是有可能出现这种情况的。
比如:当count=100时,线程1先 load,然后线程1还没有save,线程2就 load,然后线程1自增了10次线程count=110,但此时线程2第一次自增的save才完成,那么就把线程2的自增后的101写到count中,导致线程1自增的十次无效,然后交换线程1和线程2的身份,如果线程2的10次自增也无效,很明显,结果就有可能小于10000。 - 那怎么解决这个问题呢?这时count++非原子性导致的问题,那我们就让它变成原子性的,这个让它变成原子性的操作就是
加锁。加锁就要用到关键字synchronized。
1、synchronized使用
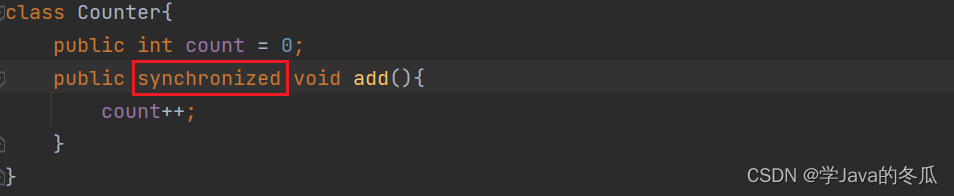
1> synchronized修饰方法
1)修饰普通方法 –针对this加锁
1)修饰静态方法 –针对类对象加锁(Counter.class)
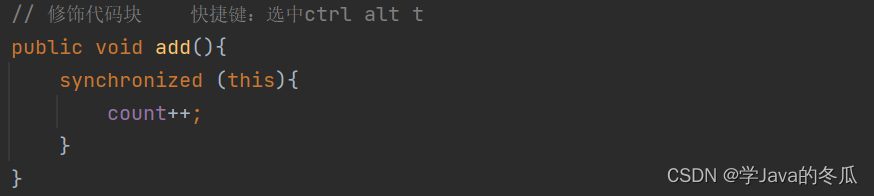
2> synchronized修饰代码块 –手动指定锁对象
原则:执行进入方法/代码块就加锁,出方法/代码块就释放锁。
synchronized也可叫moniter lock(监视器锁)。
对上面例子加锁:
synchronized修饰方法:
synchronized修饰代码块:
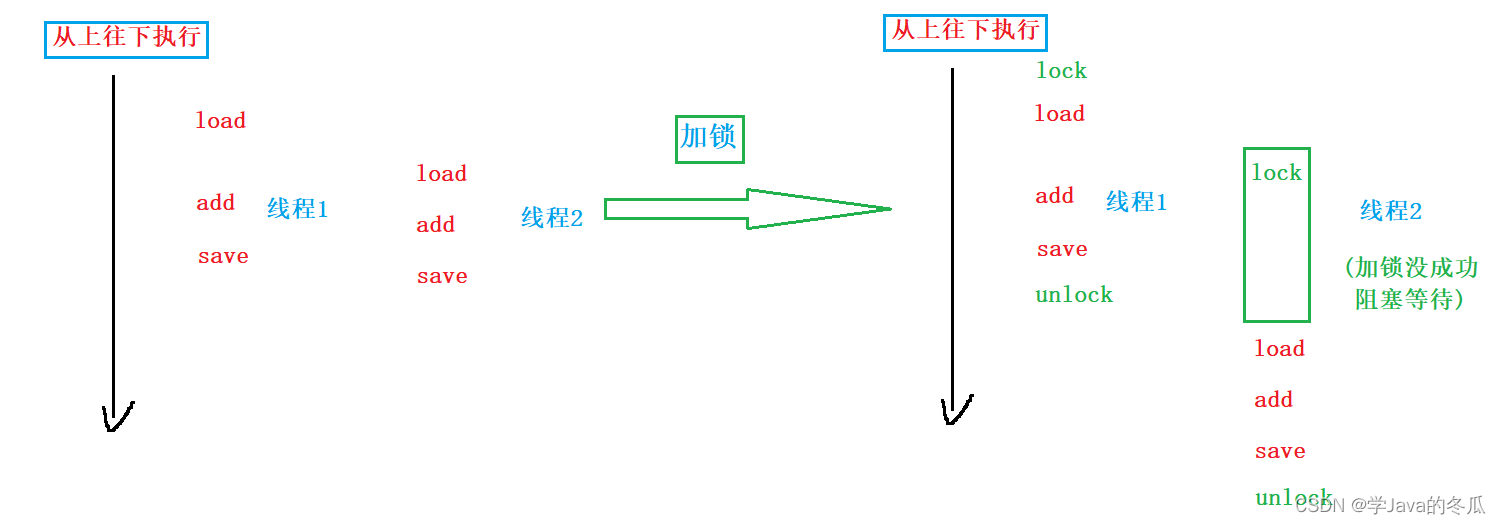
- 上图就是对加锁操作的图形描述,其实通过加锁实现原子性的操作,在底层来看的话,是当第一个线程对这个对象加锁后,在第一个线程释放锁之前,其他线程无法获取到锁,也无法修改该对象,其它线程只是
阻塞等待。 - 用
synchronized加锁时,没有获取到锁的线程会持续等下去,直到已经获取到锁的线程释放锁,它们才会去竞争尝试对对象加锁操作。也就是说,未获取到锁的线程就会死等。而使用另一个关键字加锁则不一样。 - 用
ReentrantLock加锁时,如果线程没有获取到锁,它就不再等了,即获取不到就放弃。
2、synchronized特性
互斥,即第一个线程获取到锁后,另一个线程想要获取锁,得阻塞等待,等第一个线程释放锁,才能尝试去获取锁。可重入,当一个线程获取到锁后,第二次还是这个线程给这个对象加锁时,不需要阻塞等待,可以再次加锁(相当于加了两次锁)。
可重入代码示例 :
在下面的代码中, increase 和 increase2 两个方法都加了 synchronized, 此处的synchronized 都是针对 this 当前 对象加锁的.
在调用 increase2 的时候, 先加了一次锁,
执行到 increase 的时候, 又加了一次锁. (上个锁还没释 放, 相当于连续加两次锁)
这个代码是完全没问题的. 因为synchronized 是可重入锁.
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
synchronized void increase2() {
increase();
}
}
3、Java标志库中的线程安全类
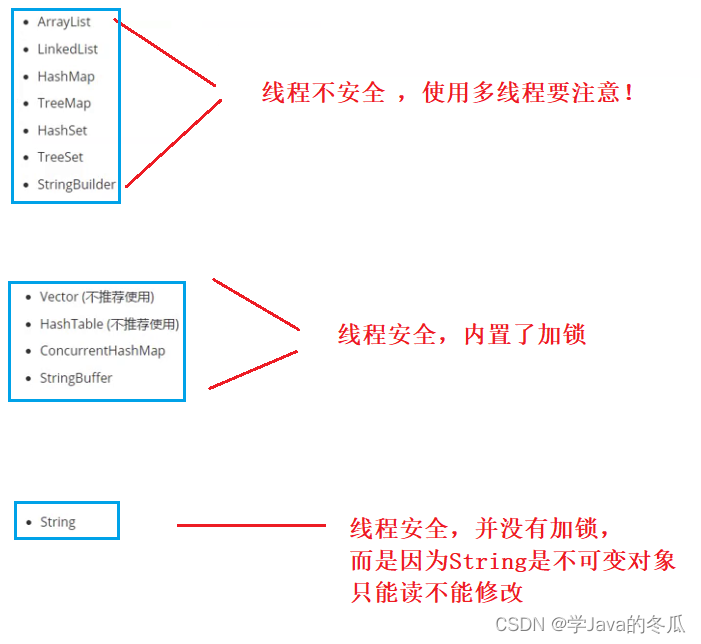
三、内存可见性
1、内存可见性的问题
需求:用线程t1读MyCounter类型的成员变量,如果成员变量flag=0,就一直循环,用t2线程修改MyCounter类型的成员变量flag,让t1线程停止循环并结束线程然后结束整个进程。
存在内存可见性的代码:
import java.util.Scanner;
class MyCounter {
public int flag = 0;
}
public class Main {
public static void main(String[] args) {
MyCounter myCounter = new MyCounter();
Thread t1 = new Thread(()->{
while (myCounter.flag == 0){
//
}
});
Thread t2 = new Thread(()->{
Scanner in = new Scanner(System.in);
System.out.println("请输入一个整数,输入0表示继续,输入其它表示停止");
myCounter.flag = in.nextInt();
});
t1.start();
t2.start();
}
}
结果:
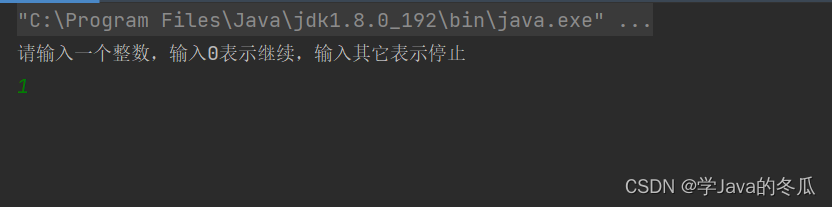
在上面的代码运行结果中,我们发现,并没有按照预期那样把flag改为非0的数后,程序就结束,而是程序一直挂着,就是不结束。为什么呢?我们来从底层理解理解。

循环的执行操作是很快的,每秒钟执行上百万次。那么在我们输入非0的数之前(t2线程修改变量flag之前),load的值都是一样的为0。又因为load比cmp操作,速度慢很多很多(因为load是从内存读到寄存器上,而cmp是直接在寄存器上操作CPU对寄存器的操作比对内存操作块3-4个数量级。),那编译器(在java中就是JVM)发现,你在反复load一个固定的值flag=0,那它索性就不load了,直接给你比较,所以结果就是t2修改了flag的值,但是t1load的是t2修改前的值,且t1后续不再重新load。这就导致内存可见性问题。
但是呢,内存可见性,不一定只是内存和寄存器之间的,也有可能是内存和cache,或者cache和寄存器之间。cache是介于内存和寄存器之间的高速缓存器,比内存运行块,比寄存器造价低。
总的来说,内存可见性问题的产生就是因为,t1线程进行读取的时候,只读取了工作内存的值(cache或寄存器),t2线程进行修改的时候,先修改工作内存中的值,再把工作内存中的值同步到主存(内存)上。但是由于编译器优化,导致t1线程没有从主存读取数据到它的工作内存,t1就从工作内存读到的结果就是修改之前的结果。
2、volatile解决内存可见性
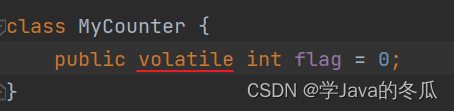
在上面的代码中,当我们给flag这个成员变量加上volatile后,代表这个变量是易变的,那么编译器就不会忽略线程1的load,而是踏踏实实,按照规矩,每次都从"主存"load到"工作内存"上,不产生编译器优化,这样就解决了内存可见性问题。
3、volatile不保证原子性
volatile和synchronized都可以保证线程安全。但是volatile不能用于处理多线程++同一个变量的操作,这是要保证原子性,而原子性是由 synchronized来保证的;而两个线程一个读,一个改这样的操作容易存在内存可见性问题,由volatile来保证线程安全。
四、指令重排序
1、指令重排序的问题
在Java中,指令重排序是指编译器或者CPU可以对指令的执行顺序进行优化,来提高程序的性能。但是,在多线程环境下,指令重排序很可能会引发线程安全问题。
代码:
public class Singleton{
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance(){
if(instance == null){
synchronized(Singleton.class){
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
关于指令重排序我们接着往下看:

比如:t1 和 t2线程,t1是按照1 3 2的顺序执行的
但是呢,t1执行完 1、3后就被切出CPU了,t2来执行。
此时 t2看 t1已经执行完 3操作,就认为instance非空了,那么,t2就相当于直接返回了instance引用,并且可能会尝试使用引用中的属性。但是由于 t1还没执行2操作,实际上没有真正的new出对象,还没构造完成的对象。因此指令重排序就产生了线程安全问题。
2、volatile解决指令重排序
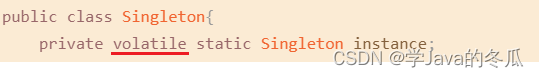
volatile可以防止指令重排序。volatile防止止指令重排序实际上是用时间来交换线程安全。
五、synchronized和volatile功能
synchronized保证多线程情况下的操作原子性,volatile保证多线程情况下消除一些编译器优化,解决内存可见性和指令重排序的问题。
















 2960
2960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











