






HDFS、Hive 和 HBase 是大数据处理领域中的几个关键组件,
HDFS,Hive,hBase都属于hadoop生态系统,此外hadoop生态系统还有其他的部分,比如说zooKeeper(分布式协作服务)、Ambari等等。

————————————————
hadoop和hdfs
Hadoop 是一个分布式计算框架,它提供了处理和分析大规模数据的能力。Hadoop 包含了多个组件,其中 HDFS(Hadoop Distributed File System)是其核心组件之一。HDFS 提供了可靠和高容错性的分布式文件系统,用于存储和管理海量数据。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop最核心的设计就是hdfs和mapreduce,hdfs提供存储,mapreduce用于计算。
————————————————
hive
Hive 是基于 Hadoop 的数据仓库工具,它提供了类似于传统数据库的查询语言(HiveQL)来执行数据查询和分析操作。Hive 可以将结构化数据映射到 HDFS 上的文件,并使用类似 SQL 的语法来查询和分析大规模数据。
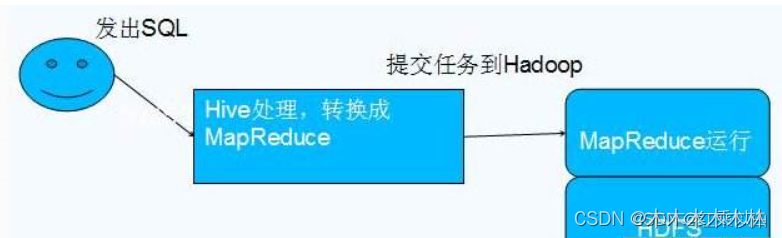
.Hive是Hadoop的延申。hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的hdfs为hive提供了数据存储,mapreduce为hive提供了分布式运算。
————————————————
HBase 是一个分布式的、面向列的 NoSQL 数据库系统,它是构建在 Hadoop 生态系统之上的。HBase 提供了实时的、高可扩展性的数据存储和访问能力,适用于对非结构化和半结构化数据进行读写操作。
拓展:
1.hive不存储数据,hive只是对数据进行分析计算,以及计算后的结果数据实际存放在分布式系统上,如HDFS;
2.hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑,通过sql编程提交后解释成mapreduce程序,然后将这个MR程序提交给yarn进行调度执行。所以实际进行分布式运算的是mapreduce程序。
3.因为hive需要操作hdfs上的数据集,那么它需要知道数据的切分格式,如行列分隔符,存储类型,是否压缩,数据的存储地址等信息。















 3665
3665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









