







B树
B树的基本概念
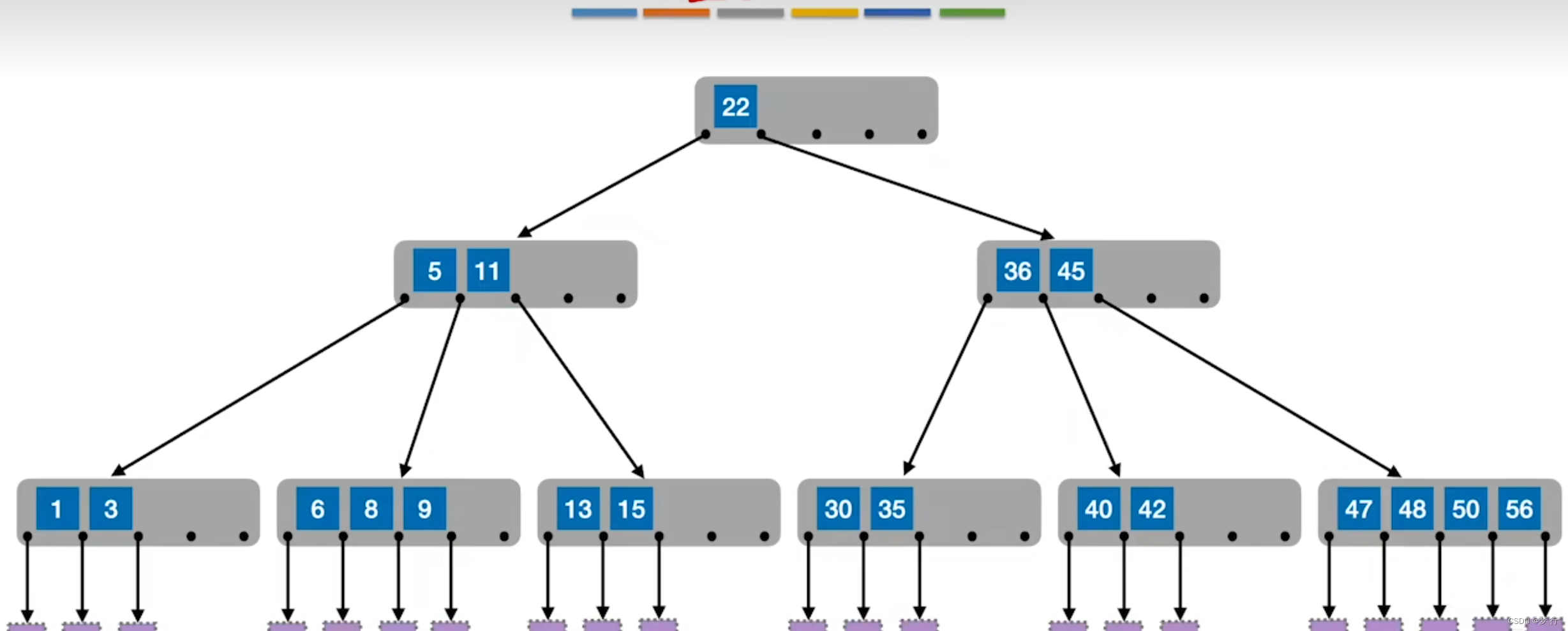
一颗m阶B树或为空树,或为满足以下条件的树:
1.每个节点至多用有m个子树,即至多有m-1个关键字。
2.若根节点不是叶子节点(树不止有一个节点),那么根节点至少有2棵子树,即至多有1一个关键字。(如果不止有根节点一个节点,那么根节点的子树起码要有一个关键字,而我们要知道单一关键字对应两颗子树。)
3.除去根节点外的所有非叶节点至少有(向上取整)个子树,那么就至少有
-1(向上取整)个关键字。
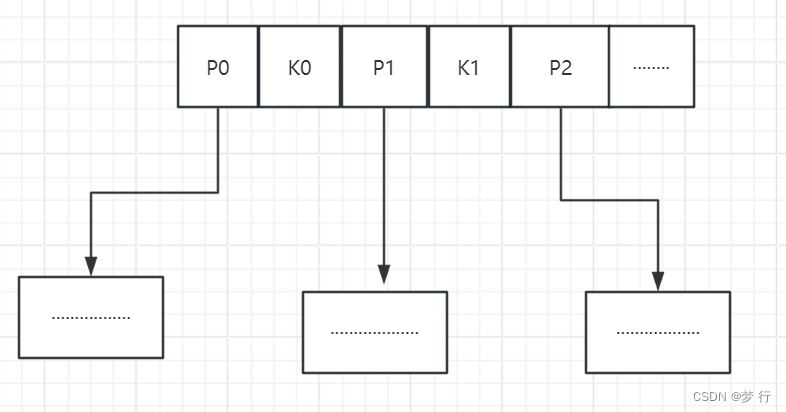
我们可以想象,每个关键字Key,被两个Point裹挟,也可以认为是关键字K将一个大范围分割成了两半。可知P一定会比K多一个。
且遵循K0<K1<K2<...Kn;以及左子树所有关键字<根节点所有关键字<右子树所有关键字的基本原则。
假设说“正无穷”到“负无穷”这个【大范围】,我挑选4作为关键字Key节点,那么衍生而出诞生了两个Point节点将Key围住,也就有了负无穷到4,以及4到正无穷这两个分割之后的【小范围】(子树)
4.所有叶节点必须出现在同一层次,这些节点不包含信息,一般被视为“失败节点”,指向他们的指针为空。(可以得知,任何节点的所有子树高度都相等)
根据以上概念可知,若B树有n个关键字,那么它所具有的叶节点(失败节点)数量为n+1
B树的查找
B树的查找包含两个操作:
1.在B树中寻找节点。
2.在节点内找关键字。
具体表现为:
从根节点开始开始,假设我们要查找的值为Search(简称S),首先将S与根节点的关键字K比对,如果与节点内的关键字匹配,则找到。
若是没有找到匹配的K,则尝试寻找:最小关键字K0(若S<K0),最大关键字Kn(若S>Kn),或者两个点Ki与Ki+1(若Ki<S<Ki+1)。
根据上面的判断,选择合适的Point指向的子树节点,进行下一轮的关键字比对。
直至找到匹配的关键字节点,或者找到叶节点/“失败节点”。
B树的高度
首先我们定义B树的高度不包含“失败节点”(有些教材中带)
若n>=1,则对任一颗包含n个关键字,高度为h,阶数为m的B树:
1.如果每个节点包含的关键字个数达到最多,则容纳相同关键字个数B树的高度就达到了最小。(没有空余位置,最拥挤的方案,h最小),因为m阶B树的节点最多拥有m个子树,那么节点的关键字个数最多为m-1。
所以一颗高度h的m阶B树中关键字个数应该满足:
n<=(m-1)*(1+m+m^2……m^h-1)=m^h-1(运用等比数列计算)
最后运用纯数学知识计算一下,就能得出h>=log m (n+1)。
(m-1):每个节点最多蕴含的关键字个数 Key Per Point简称kpp
(1+m+m^2……m^h-1):整个B树最多蕴含的节点数 Point Count简称pc
Nmax=kpp*pc(并没有叫做kpp与pc的专业术语,单纯为了好理解恶搞一下)
2.若是让每层的关键字个数最少,则B树的高度也会达到最大。
根据B树基本概念,第一层至少有一个结点(内含一个K,两个P),第二层至少有两个结点。除了第一层以外,每层结点需要遵循至少有(向上取整数)个子树的原则。
于是第一层有1个节点,第二层有2个节点,第三层有2*,第四层有2*
^2……以此类推,第h+1层有2*
^(h-1)个节点,并且都是叶节点/“失败节点”
我们之前得出过n个关键字的B树,有n+1个叶节点/“失败节点”的结论,现在我们可以用它来定界。
n+1>=2()^(h-1)
即h<=log ((n+1)/2)+1
B树的插入,删除
B树的插入
B树插入的位置,是终端节点(最底层的非叶子节点,也就是叶子节点上一层的节点),但是直接插入过后或许会使整棵树不再满足B树的基本定义要求,所以一般插入过后还要进行调整。
B树插入的步骤:
1.定位插入:利用B树查找算法,找出插入关键字的位置(将K插入指向失败节点的Point位置)
2.判定调整:在插入关键字后,结点关键字的数量会发生变化,如果插入后的数量小于m,那么插入成功;如果插入之后关键字的数量大于m-1,发生溢出,则需要进行分裂调整
分裂:对于需要需要分裂的结点,首先要创造一个新的结点,以原结点第个关键字为界限,左半部分的关键字留在原结点,右半部分的关键字划入刚刚创建的新结点。最后再将作为界限的第
个关键字,移动到原结点的父节点。
注意:分裂操作或许会使原结点的父节点发生溢出,届时对父结点继续进行分裂操作,直至整棵树再次满足B树的基本定义。
B树的删除
B树的删除操作同样可能导致B树不满足基本定义。
我们首先判断需要删除的关键字,是否为终端结点。
1.非终端节点
需要删除的关键字K,需要其直接前驱(或直接后继)K'顶替。
直接前驱关键字,一般为最靠近K的左子树中,最右下角的关键字(一定位于终端节点);同理,直接后继关键字为最靠近K的右子树中,最左下角的关键字(也必然位于终端节点)。
完成该删除操作之后,一开始被删除的K关键字,被K’顶替,而K‘也从原本所在的终端节点中被删除。
(非终端节点的关键字K没了,但有前驱/后继关键字K’填上窟窿,删了一个,又来一个,所以该节点的关键字数量并未发生改变。可是终端节点的K‘没了就是真的没了,K’本来所在的结点,关键字数量实打实的少了一个,如果不再满足B树基本定义的话,需要调整。)
ps:可以得出一个结论,就算我们想要删除的关键字位于非终端结点,最终也可以归结于针对终端节点上关键字的删除。
2.终端节点
如果需要删除的关键字位于终端节点,那么需要分以下三种情况讨论:
1.如果原结点中关键字的数量大于等于,那么就算删掉一个关键字,节点内关键字数量依然满足B树定义的n>=
-1的要求,所以直接删掉就是了。
2.如果原结点内的关键字数量=-1,那么在删除一个关键字,就不满足B树的定义了,需要进一步调整。具体方法为跟富裕的兄弟借,如果原结点的左/右兄弟节点中,有结点的关键字数量>=
,那么需要将指向原结点,与兄弟节点的父亲节点当中的Point,其中间夹住的关键字Key转移到原结点中,然后从兄弟节点中拿走一个关键字,填补父亲节点的Key(父子换位法)
(原结点删除的关键字窟窿,从父亲节点中抽出来一个补上,然后父亲节点的窟窿,再用富裕的兄弟节点多出来的关键字补上,只有富哥们受伤的世界完成了。父亲变儿子,兄弟变父亲,最熟悉的一集。)
3.如果连需要删除关键字的原结点,和其兄弟节点的关键字数量都是(-1),兄弟几个家里全都揭不开锅,没有多余的关键字填补窟窿,那么就要采取合并的策略。
将关键字删除后,与左(右)兄弟节点及其双亲结点中的关键字进行合并(双亲中的关键字,就是指向两兄弟的Point,中间夹着的那个关键字Key,两兄弟连带着老父亲一起合并。),合并得出的新结点,顶替原结点。
最后得到的新结点一定满足B树定义,但父亲结点却少了一个关键字,这可能会引发新的问题,到时候就按照2.与3.法针对父节点进行调整,直到得到一个满足定义的B树。
ps:如果原结点的父亲结点是根节点,而根节点的数量从1变为0,那么合并得到的新结点就是新的根节点了。
B +树
m阶B+树的基本定义为:
1.每个分支节点最多有m个子树(孩子节点)
2.非叶根节点至少有两颗子树,其他每个分支结点至少有颗子树
3.节点的子树个数,与关键字个数相等(关键字和子树个数一一对应,这是B +树与B树相比,主要不同的点。虽然两类树中,除了非叶根节点以外的其他结点,子树的上限m和下限一样,但关键字上限和下限却不同)
4.所有叶节点包含全部关键及其指向相应记录的指针(叶节点一层中,包含整棵树的所有关键字,以及存储关键字信息的地址),叶节点中将关键字按大小顺序排序,并且相邻叶节点按照大小顺序相互链接起来(支持顺序查找)
5.所有分支节点中,只包含其子结点当中最大的关键字,以及指向其子节点的指针。
可以看出B +树相比B树更倾向于“索引”。
B +与B树的主要差异:

1.B +树中,具有n个关键字的结点只有n颗子树;B树中n个关键字的结点,对应n+1颗子树。
2.B +树中,每个结点的关键字个数n的范围是<=n<=m(非叶根节点:2<=n<=m);而在B树中,每个节点的关键字范围是
-1<=n<=m-1(根节点:1<=n<=m-1)
3.B +树中,叶节点包含了整棵树所有的关键字,非叶节点的关键字也会出现在叶节点,而在B树中,终端节点当中出现的关键字和其他结点中的关键字不会出现重合。
4.B +树中的叶节点包含信息,非叶节点仅仅起到索引作用,当我们在查询的时候,不管是成功还是失败,最终都会找到叶节点所在的层次,查找的时间复杂度相对稳定。而B树中的所有结点都记录有信息(存储地址,指针等),查找到目标关键字后,不会继续向下查询,所以时间复杂度相对不稳定。
5.B +树中,用一个指针指向关键字最小的叶节点,将所有叶节点串成一个相信链表。

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









