










博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
目录
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
源码获取文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专栏
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
(1) 绪论:其中主要包括国内外关于糖尿病病预测模型的研究现状,发展趋势。 开发背景,研究目的与意义。 (2) 需求分析:主要分析社会对糖尿病管理的需求,旨在为患者提供更好的疾病管理方案,提高其生活质量,减轻社会医疗负担。主要阐述模型的功能,包括数据收集、数据清洗与预处理、数据挖掘与分析、机器学习算法实训以及用户UI界面设计等。 (3) 数据说明:主要介绍了样本数据集的来源,数据集共分为两个部分,分别用于后续构建糖尿病的回归分析模型和疾病分类预测模型。说明数据预处理的过程,包括对缺失值和异常值进行相应处理,填充缺失值,剔除异常值点,以保证数据的真实性,提高后续筛选变量的准确度和模型预测精度。 (4) 关键技术与方法:准备介绍模型采用的关键技术,包括Python编程语言中的机器学习算法(、随机森林、决策树、线性回归算法。阐述集成学习方法在疾病预测中的应用,通过模型融合来提高预测的准确性和效率。 |
(5) 模型设计与实现:主要描述模型的总体设计流程,包括数据获取、数据清洗与降维处理、机器学习算法模型预测、多维分析验证以及用户UI界面设计。展示KNN、随机森林、决策树、逻辑回归和神经网络算法在疾病预测中的具体应用和结果分析,包括算法准确率、混淆矩阵等。
(1) 绪论:其中主要包括国内外关于糖尿病病预测模型的研究现状,发展趋势。 开发背景,研究目的与意义。 (2) 需求分析:主要分析社会对糖尿病管理的需求,旨在为患者提供更好的疾病管理方案,提高其生活质量,减轻社会医疗负担。主要阐述模型的功能,包括数据收集、数据清洗与预处理、数据挖掘与分析、机器学习算法实训以及用户UI界面设计等。 (3) 数据说明:主要介绍了样本数据集的来源,数据集共分为两个部分,分别用于后续构建糖尿病的回归分析模型和疾病分类预测模型。说明数据预处理的过程,包括对缺失值和异常值进行相应处理,填充缺失值,剔除异常值点,以保证数据的真实性,提高后续筛选变量的准确度和模型预测精度。 (4) 关键技术与方法:准备介绍模型采用的关键技术,包括Python编程语言中的机器学习算法(、随机森林、决策树、线性回归算法。阐述集成学习方法在疾病预测中的应用,通过模型融合来提高预测的准确性和效率。 |
(5) 模型设计与实现:主要描述模型的总体设计流程,包括数据获取、数据清洗与降维处理、机器学习算法模型预测、多维分析验证以及用户UI界面设计。展示KNN、随机森林、决策树、逻辑回归和神经网络算法在疾病预测中的具体应用和结果分析,包括算法准确率、混淆矩阵等。

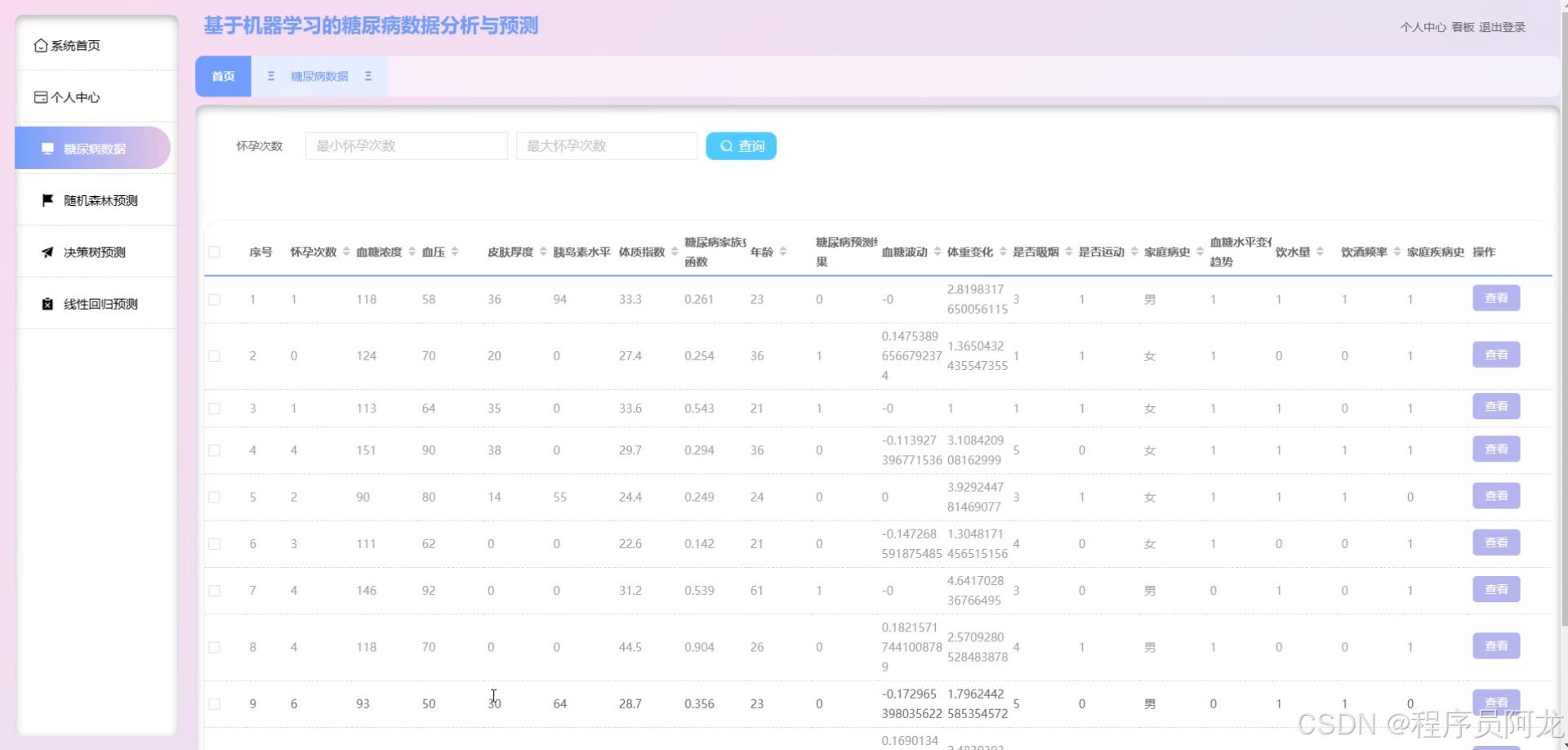
系统实现界面:
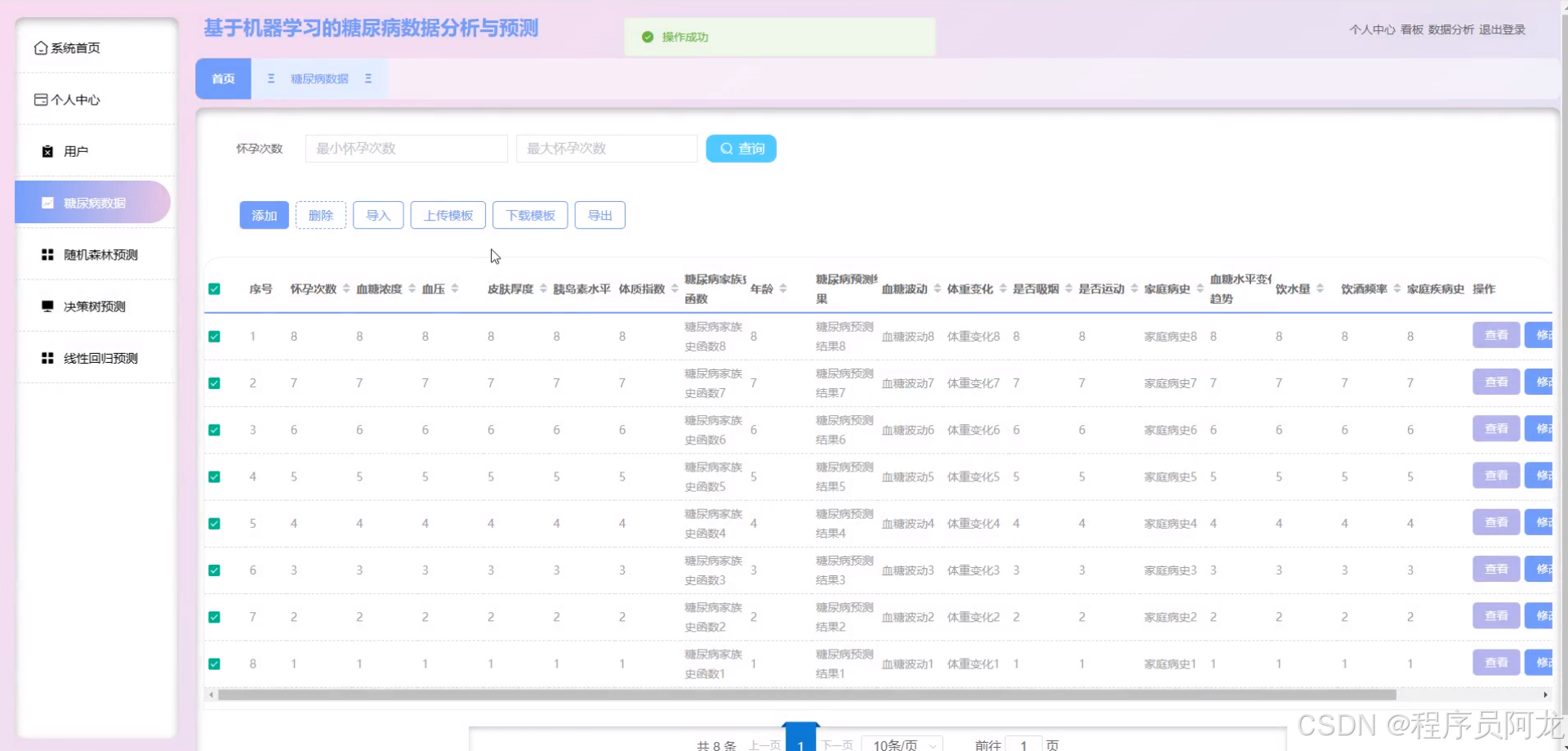
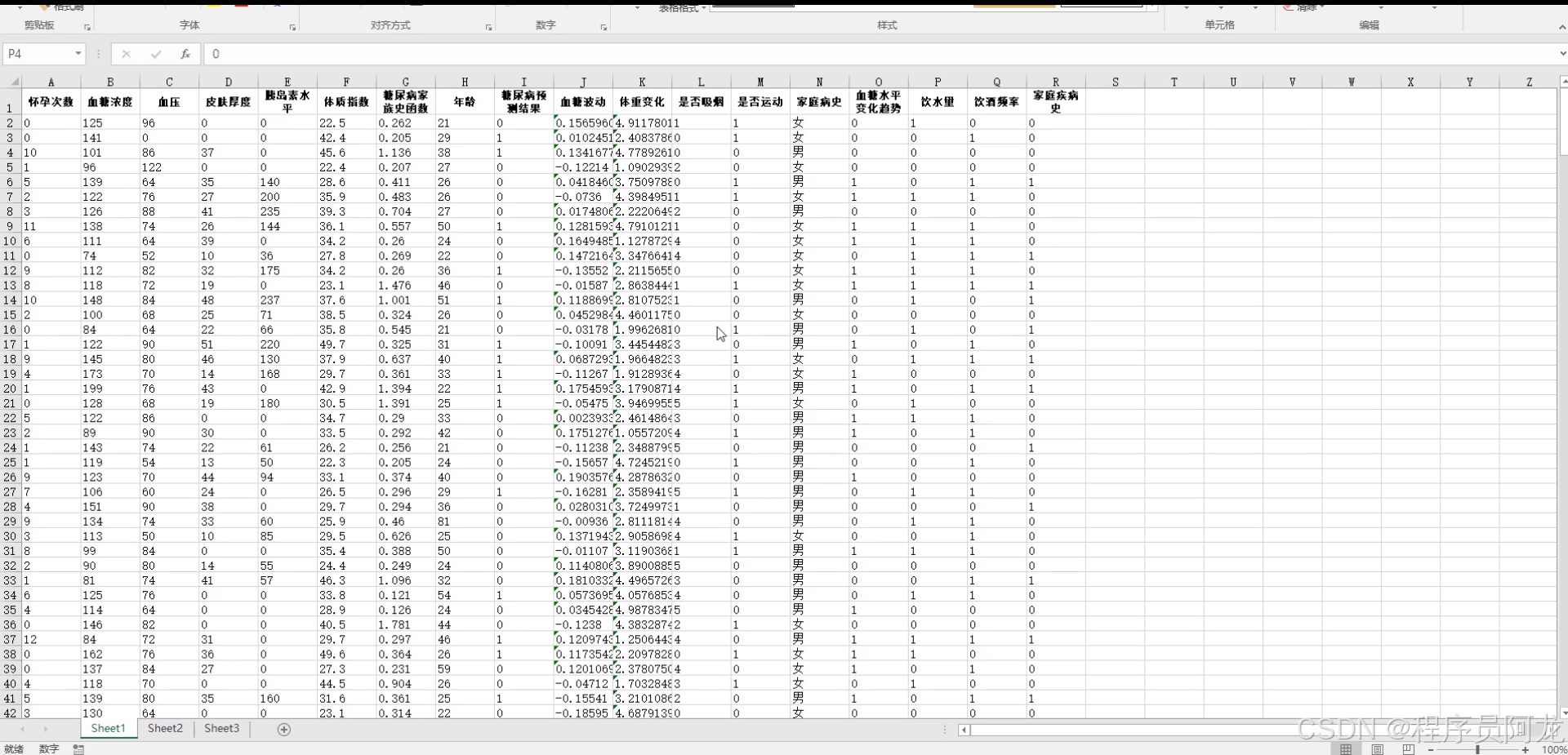
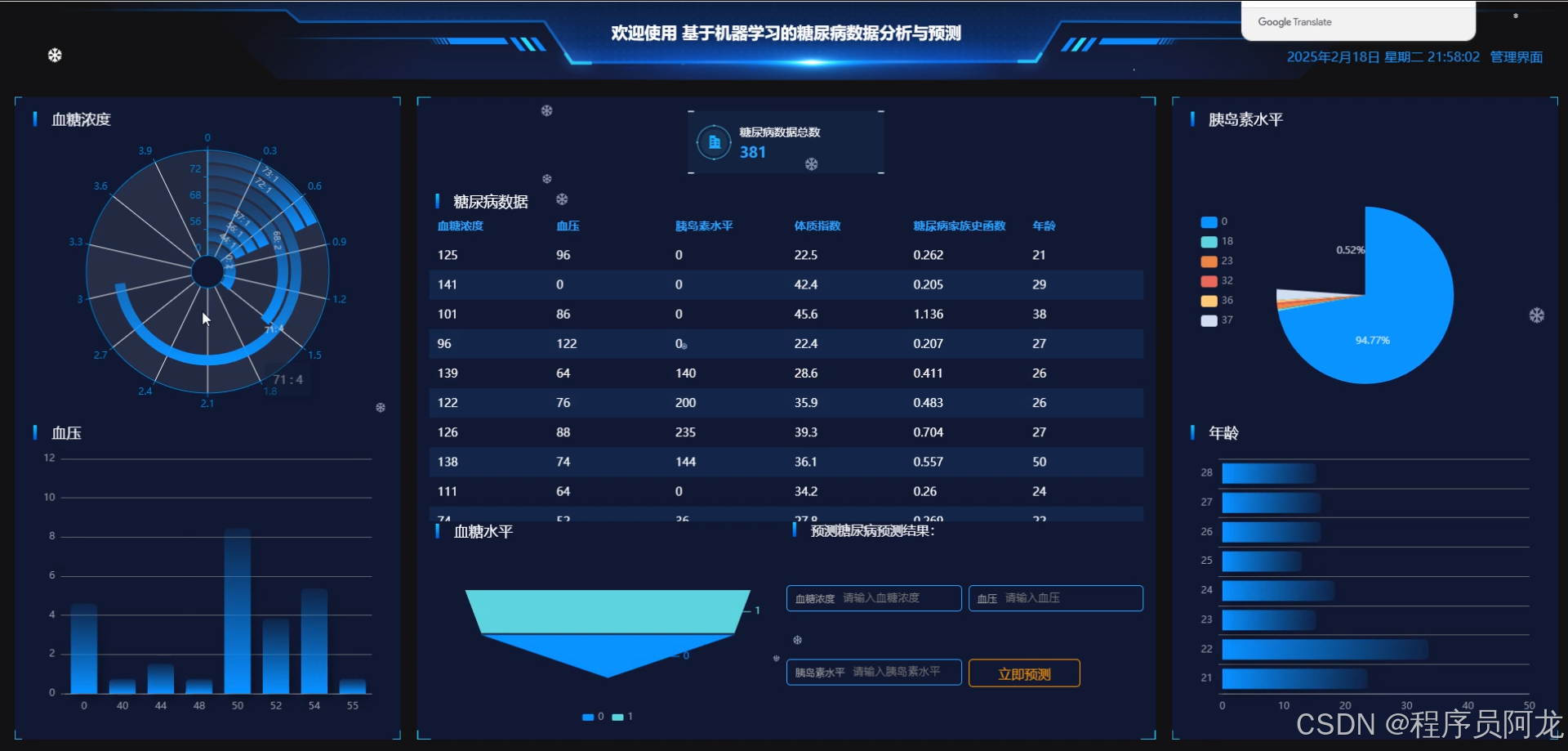

核心代码介绍:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score, roc_curve, accuracy_score
# 1. 加载数据 (以 UCI 心脏病数据集为例)
url = 'https://raw.githubusercontent.com/ageron/handson-ml/master/datasets/heart/heart.csv'
data = pd.read_csv(url)
# 2. 数据预处理
# 查看缺失值
print("缺失值情况:\n", data.isnull().sum())
# 分离特征与目标变量
y = data['target']
X = data.drop(columns=['target'])
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42, stratify=y
)
# 4. 训练模型
# 4.1 逻辑回归
lr_model = LogisticRegression(random_state=42)
lr_model.fit(X_train, y_train)
# 4.2 随机森林
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 5. 模型评估函数
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
print(f"模型: {model.__class__.__name__}")
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))
print("ROC AUC:", roc_auc_score(y_test, y_prob))
# 可视化 ROC 曲线
fpr, tpr, _ = roc_curve(y_test, y_prob)
import matplotlib.pyplot as plt
plt.figure()
plt.plot(fpr, tpr, label=f'{model.__class__.__name__} (AUC = {roc_auc_score(y_test, y_prob):.2f})')
plt.plot([0, 1], [0, 1], linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
print('-' * 40)
# 6. 对比评估
evaluate_model(lr_model, X_test, y_test)
evaluate_model(rf_model, X_test, y_test)
# 7. 特征重要性 (仅对随机森林)
import numpy as np
feature_importances = rf_model.feature_importances_
features = X.columns
indices = np.argsort(feature_importances)[::-1]
print("\n随机森林特征重要性:")
for idx in indices:
print(f"\t{features[idx]}: {feature_importances[idx]:.4f}")

1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











