







目录
什么是哈希表
哈希表也称为散列表,单词写作Hash table.
其次,哈希表是一种数据结构,既然是数据结构,那么哈希表有什么特点呢?
特点就是:哈希表可以根据键值(key)直接访问数据,查找数据更为高效.
哈希表的本质
哈希表是一种查找数据更高效的数据类型,因为他的底层实现就是在数组上,再进行加工,就称为哈希表。
键值对和Entry
哈希表经常存放的就是键值对,可以通过key取快速的访问value的值。
键值对就是key-value的组合,key的映射到value(就是一个值对应另一个值),key就称为键值,value就称为hash值。
在哈希表中就存放的是这些键值对,Entry就是我们jdk中给键值对起的别名。
一个Entry就是一个键值对。
哈希表存放数据
经过哈希函数计算后,会得到一个值,这个值就是Entry在数组中存放的具体下标值,注意这个Entry并不是一个简单的值,因为我们上边已经说了,Entry就相当于键值对,所以我们存放的这个Entry实际上是一个键值对(key-value)。哈希函数只是通过Key值计算Entry在数组中的存放位置。
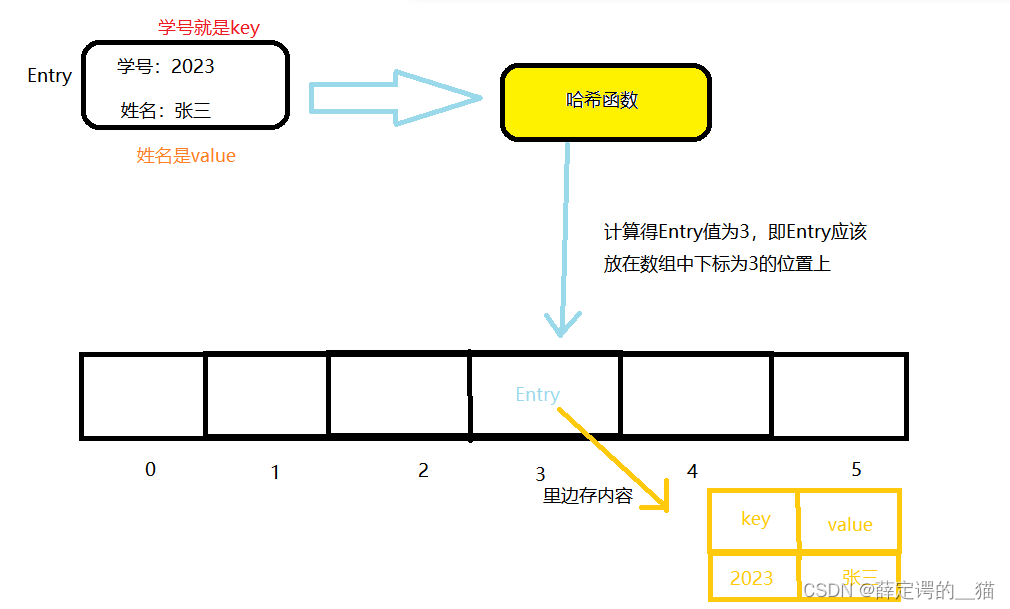
哈希函数是什么
哈希函数就是将键值映射为存储位置的函数,简单说就是根据Key的值计算出Entry位置的函数。
哈希冲突
哈希冲突是什么
当两个不一样的key值 通过 哈希函数 计算,得到的Entry位置下标一样的时候就成为哈希冲突。
即key1 != key2,Entry(key1) = Entry(key2)。
哈希冲突过高会怎么样
哈希冲突过高,就相当于一个数组元素下标处存放了多个Entry,那么就会大大降低我们查找的效率。
哈希冲突可以避免吗
理论上哈希冲突是可以避免的,前提是哈希桶的数量要大于元素的数量,即数组的长度大于要存储的Entry的个数。
但是现实中,我们认为要存储的元素(Entry)是无穷的,但是哈希桶(数组长度)的个数是有限的,所以哈希冲突是无法避免的。

降低冲突率的方法
既然无法避免,那么我们肯定要寻找方法取降低冲突率。
1.设计良好的1哈希函数
直接定制法(适用于 元素数量 <= 哈希桶数量)
除留余数法(最常用):元素编号 % 哈希桶数量
2.负载因子(load factor)
已经存在于哈希表的元素数量 / 哈希桶的数量
负载因子和冲突率之间的函数关系:

通过影响负载因子,进而影响冲突率。
设定一个冲突率的阈值,计算处它对应的负载因子阈值。一旦负载因子>=负载因子的阈值,就扩容(增加哈希桶)。
如何解决哈希冲突
开放寻址法
简单来说就是位置被占用了,那就依次向后找,例如我们计算得出的位置是0,但是0有元素了,那么我们就向后找1位置,1位置没有元素我们就放在1的位置,若是1位置也有元素了,那就继续向后找2位置,依次类推,直到找到一个空的位置。
其实就是 寻找空位置:
上述是线性探测法(+1一次向后找一个)
还有二次探测法(+1,+4,+9向后找)
链地址法

就是每次存放好一个元素后,这时候这个位置存放的不单单是之前的那个Entry了,此时的Entry还额外的保存了一个next指针,如果这个位置再来元素的时候,就让这个next指针指向新来的元素的位置,他同样有一个新增的next指针。同理,再来新的就让空的next指针指向它,这样就形成了一个链表。

哈希表的实现代码 及 实现用例
public class MyHashMap {
//哈希表由一个数组组成,保存的就是链表的头节点
private Node[] array;//定义一个数组,存放哈希表的Entry
private int size;//数组长度
public MyHashMap(){
this.array=new Node[8];
this.size=0;
}
public static class Node{
String key;
Long value;
Node next;//链地址法
Node(String key,Long value){
this.key=key;
this.value=value;
}
}
public int maxSize(){
int max=Integer.MIN_VALUE;//取value最小值为max
for(int i=0;i<array.length;i++){
int count=0;
Node cur = array[i];
while(cur != null){
count++;
cur=cur.next;
}
if(count>max){
max=count;
}
}
return max;
}
public Long put(String key,Long value){
//查找先看key是否存在
int h=key.hashCode();
//h只是一个>=0的整数(自然数)
//把h变成[0,array.length)的取值,才能对应一个合法的下标
//int index=j%array.length;//方法1:除留余数法
//方法二JDK内部的HashMap使用的方法(前提:array.length总是2的幂次方
//array.length in(2,4,8,16,32,64....)
int h16=h>>16;
//取h的高16位
int l16=0xFF & h;
//取h的低16位
h=h16^l16;
int index=h&(array.length-1);
//根据下标找到对应的链表头节点
Node head=array[index];
Node cur=head;
while(cur!=null){
//比较key和cur.key是否相等
//相等性用equals
if(key.equals(cur.key)){
//存在key
//更新value
Long oldValue=cur.value;
cur.value=value;
return oldValue;
}
cur=cur.next;
}
//没有找到key,进行插入
Node node=new Node(key,value);
//往head对应的链表插入,头插尾插都可以
//JDK7用的是头插
node.next=head;
//head=node; /head只是临时变量,不能折磨改
array[index]=node;
size++;
if(1.0*size/array.length>=0.75){
grow();
}
return null;
}
//扩容
private void grow(){
//扩容时候仍然要保证array.length是2的幂次方
int newLength=array.length*2;
Node[] newArray=new Node[newLength];
//和是顺序表不同,不能简单的把数组的元素搬过来,
// 元素e的下标是和array.length有关的
//array.length 变了,下标可能会发生变化,所以需要每个key都需要重新计算
// for(int i=0;i<array.length;i++){
// newArray[i]=array[i];
// }
//如何把哈希表中的所有元素都遍历到
for(int i=0;i<array.length;i++){
Node head = array[i];
Node cur = head;
while(cur != null){
Node next = cur.next;
int h=cur.key.hashCode();
int h16=h>>16;
int l16=0xFF & h;
h=h16^l16;
int index=h&(newLength-1);
//头插法
cur.next=newArray[index];
newArray[index]=cur;
cur=next;
}
}
this.array=newArray;
}
public Long get(String key){
int h=key.hashCode();
int h16=h>>16;
int l16=0xFF & h;
h=h16^l16;
int index = h & (array.length-1);
for(Node cur=array[index];cur!=null;cur=cur.next){
if(key.equals(cur.key)){
return cur.value;
}
}
return null;
}
//删除操作
public Long remove(String key){
int h=key.hashCode();
int h16=h>>16;
int l16=0xFF & h;
h=h16^l16;
int index=h & (array.length - 1);
Node prev=null;
for(Node cur = array[index];cur!=null;prev=cur,cur=cur.next){
if (key.equals(cur.key)) {
Long value=cur.value;
if(prev==null){
array[index]=cur.next;
}else{
prev.next=cur.next;
}
size--;
return value;
}
}
return null;
}
}
import java.util.Random;
public class UseMyHashMap {
private static final String chars="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
private static final Random rand=new Random();
private static String randomString(){
StringBuilder sb=new StringBuilder();
//要写能修改的字符串就需要用到StingBuilder
for(int i=0;i<100;i++){
int idx=rand.nextInt(chars.length());
char randChar=chars.charAt(idx);
sb.append(randChar);
}
return sb.toString();
}
public static void main(String[] args){
MyHashMap map=new MyHashMap();
for(int i=0;i<1000;i++){
String key=randomString();
Long value=rand.nextLong();
map.put(key,value);
}
System.out.println(map.maxSize());
}
}













 7534
7534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









