







1前言
一、笔者想说
笔者是一个不大聪明的pwn的新手,这是我根据《ctf权威竞赛指南》,b站课程,一些师傅的博客,ctfviki做的笔记,便于学习和复习
如果有错误的地方还请给位师傅指正
二、调试
下面所展示的gdb调试是根据一下调试的

注意:
1、调试记得执行到malloc后再去查看
2、记得编译
一、glibc堆概述
1)堆概述
堆是程序虚拟内存中由低地址向高地址增长的线性区域,出于效率和页对齐的考虑,通常会分配相当大的连续内存。程序再次申请时便会从这片内存中分配,直到堆空间不能满足时才会再次增长。
堆的属性是可读可写,大小通过brk()和sbrk()控制。
在堆未初始化时,program_break指向BSS段的末尾,通过调用brk()和sbrk()来移动program_break使得堆增长。
在堆未初始化时,若开启ASLR,则堆的起始地址start_brk在BSS段随机位移处,若未开启,则紧邻BSS段。
2)brk()和sbrk()、mmap()和unmmap()
见书p225
program_break指向BSS段末尾
brk()函数的参数是一个指针,用于设置program_break的指向位置
sbrk()函数的参数increment(可以是负值和0)与program_break相加来调整program_break的值
成功执行后brk()函数返回0,sbrk()函数返回上一次program_break的值(设置increment为0来获得当前
program_break的值)
3)、arena
内存分配区,可以理解为堆管理器所持有的内存池

二、各种chunk的样子
1)malloc chunk

2)free chunck
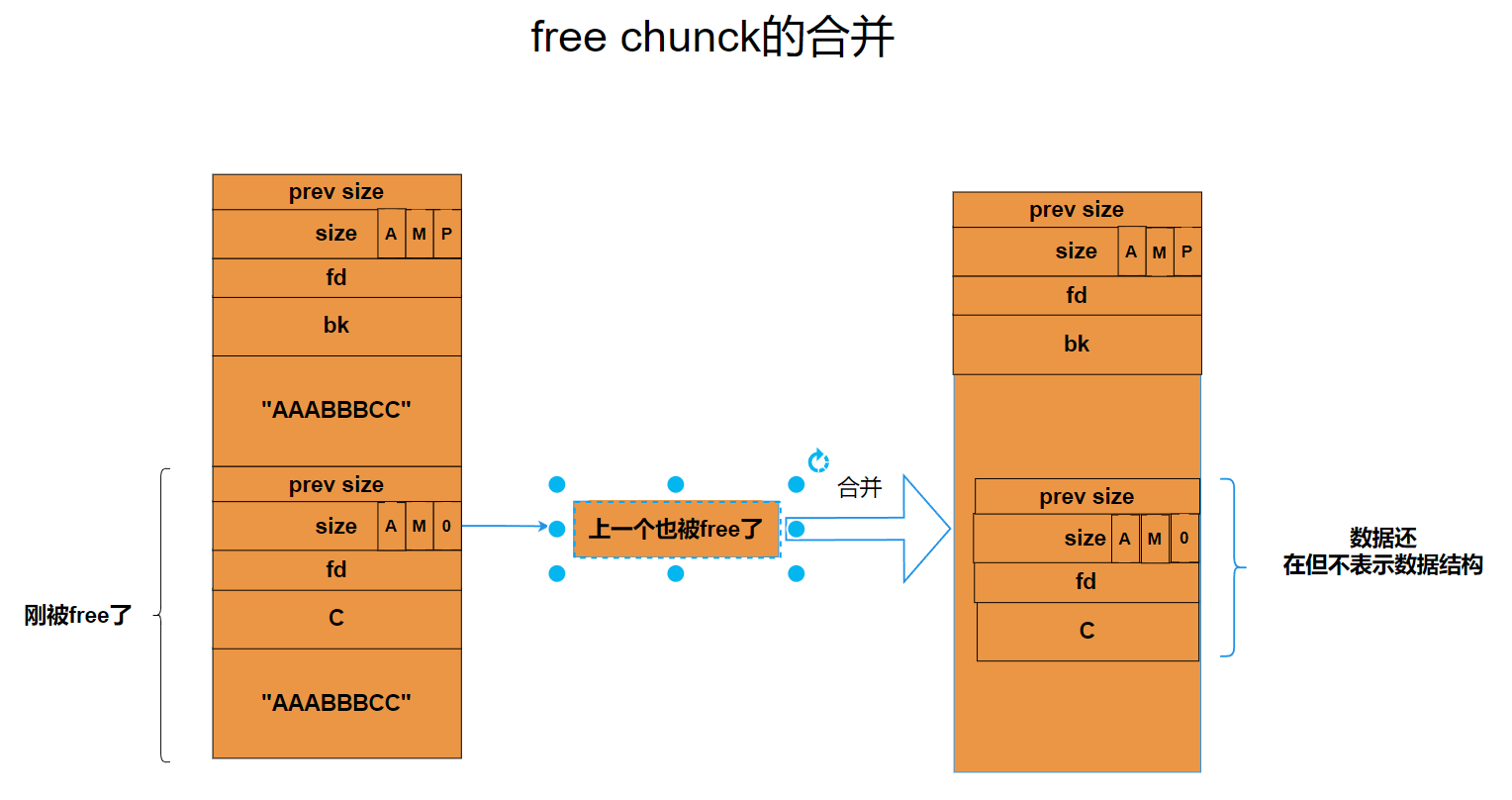
fastchunkd都是一些很小的chunk,我们程序都经常需要申请一些小空间,释放一些小空间,如果很小的空间都找堆管理器要的话,很花费堆管理器的时间,就像你存钱,总不能天天有了一块钱就存,要一块钱就取,是不是特别消耗银行的服务资源。有了fastbin,这样小内存的交易就交给fastbin来处理。
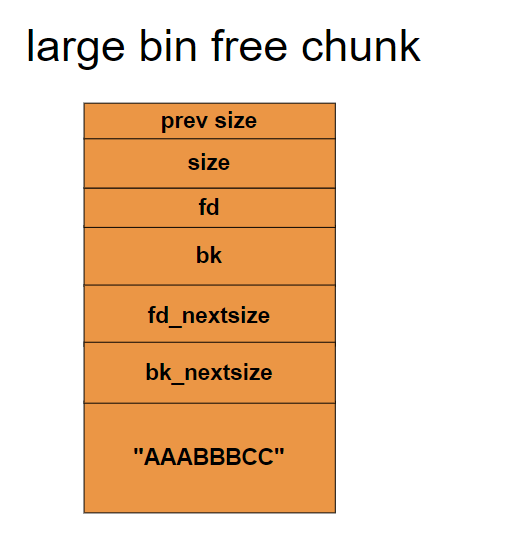
3)large bin free chunck
4)fast bin free chunck

三、堆的具体细节
1)分配chunk的时候
1、只能分配8字节的整数倍
比如32位的分配一定是8的整数倍,如果要的不是,操作系统会自动帮你补充
2、想要的的分配和实际分配
如果我们要malloc(0x100),实际上对管理器向操作系统要了0x111的内存,有两个0x8的控制字段(prev size和size),然后size的最后一位被我们写成1(看下面size的后三位),所以最后size记录的大小为(0x100+0x8+0x8+0x1)


3、空间分配的先后顺序
我们如果向操作系统申请一个一定大小的空间,堆管理器会优先去寻找free掉的有没有一样的给你优先用,如果没有,则再重新找操作系统要。
4、prev size的覆用
这里我们来举个例子
我们先malloc一个0x20大小的空间

再把它free掉
然后我们再申请一个0x28的空间
Q:可是我们只有0x20的大小,不够我们所需要的0x28,那剩下的一个字长我们去哪里要呢?
A:堆管理器会向下一个chunk下手,将他的prev size分配给我们用
Q:这里我们就会疑惑,为啥子这么重要的一个控制字段,堆管理器会这么轻而易举的给我们?
A:因为prev size记录的事上一个free掉的chunk的大小,但我们现在申请后,上一个chunk变成了malloc chunk,因此prevsize就没有什么用了
这样会使得malloc一个0xn8和一个0xn0的操作系统给的大小是一致的
2)size的低3比特会有三个控制字段(000)
Q:chunk最小是多少?
A:理论上按照64位考虑,2个字长16字节(32位,8字节)
所以我们最小的size是1000(32位),如果size后三位不是零的话(eg.100,就会出现4)不符合实际
既然后三位一定是0了,干嘛不给他添个功能以便于充分利用,于是分别添加了三个控制A、M、P
这里的
实际上如上图所示,fastbin最小,是0x20
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
3)段载入的地址的基地址末三位都是“000”
由于页映射导致的页对齐策略,页的大小的4kb,需要保持4kb对齐,4kb所需要的是2的12次方,也就是3字节,3字节对应了最后的3个0。
注意:这里的三个0不要和size字段的最后三位的三个0相混肴,这里的地址是转化为末三位的3个字节为0,而size中是最后三个比特
四、bin的相关知识
1、作用
管理arena中空闲chunk的结构,以数组的形式存在,在数组元素为相应大小的chunk链表的链表头存在于arena的malloc_state中
保管用户暂时不需要的内存空间,当用户需要重新申请内存的时候,就不需要向操作系统要新的内存空间了,如果回收站中有正好满足你需求的空间,就把那份空间分配给你就可以了。
2、bin和bins结构
1)fast bins(单向链表)

通过链表的形式,将一个一个满足要求(同类的)的chunk串联起来,这些形成一个链表(逻辑链表),组成了一个bin,这要在malloc的时候可以分门别类的找到我们所需要的chunk
后入先出(LIFO)
它的chunk in use 位永远是1
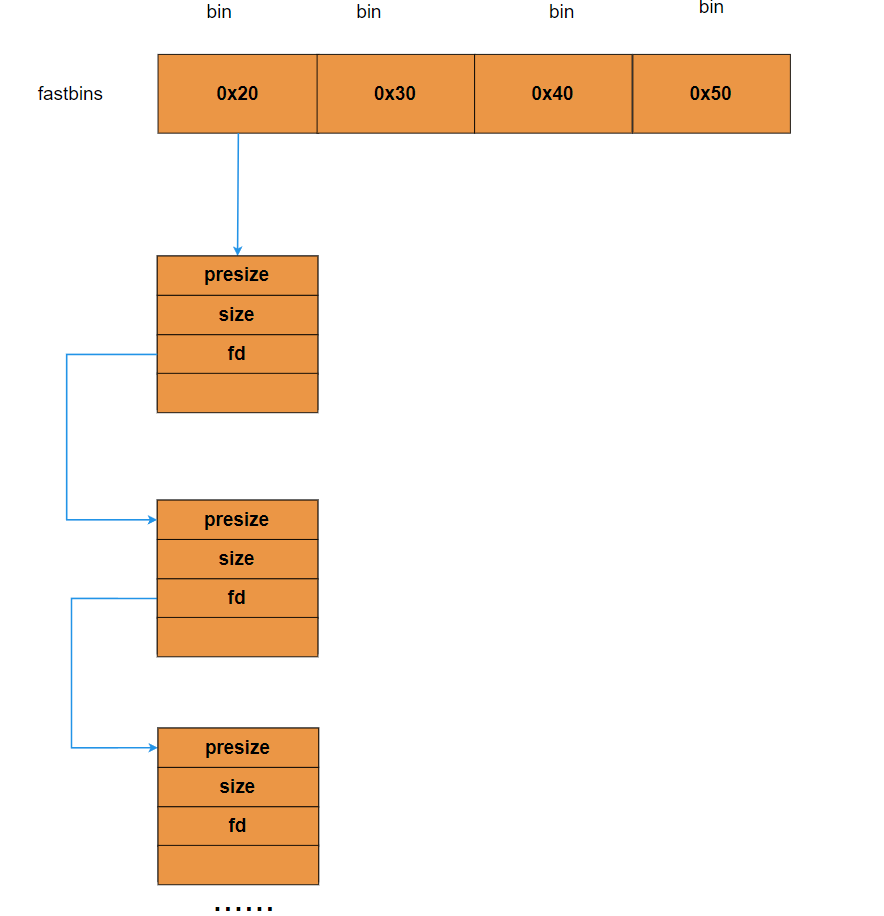
当我们malloc一个0x10的chunk时,获得的是这里的地址,因为从这里开始才是用户可写数据的地方。

2)unsorted bin(双向链表)
可以视为空闲chunk回归其所属的bin之前的缓冲区
1、长的样子
这个有一点乱所以我就简要的描述一下
fd指向的上一个freechunk的首地址
bk指向的下一个freechunk的首地址
只有一个bin元素

2、chunk的取用原则
双向链表串联起来的chunk,它在里面的取用的顺序是先进先出,最先链接到bin的最先离开
3、双向链表的特殊操作
freechunk的合并是在刚释放的时候,和一些特殊情境下
特殊情景的e.g我们要malloc一个很大的chunk,以至于达到一个large chunk,堆管理器会查找unsorted bin,然后等他遍历完发现欸,么得我们要的,然后它才会去largebins里面找。在离开unsortedbin之前,它会先把unsortedbin里面所有的chunk检查(遍历)一遍,然后两个物理相邻的chunk合并,然后会触发这个分类机制sort一下,然后把分类好的内容放到smallbins和largebins中.
fastbin和smallbin会有重合的地方,这就要在sorted后会把fastbin也给分个类
4、读写
一段放入数据,一段取用数据,这样可以加快数据的处理速度
一个刚free的数据,只要不能放入fastbin,就可以先放入unsortedbin
3)smallbin和largebin
1、长的样子
上面是不同的bin
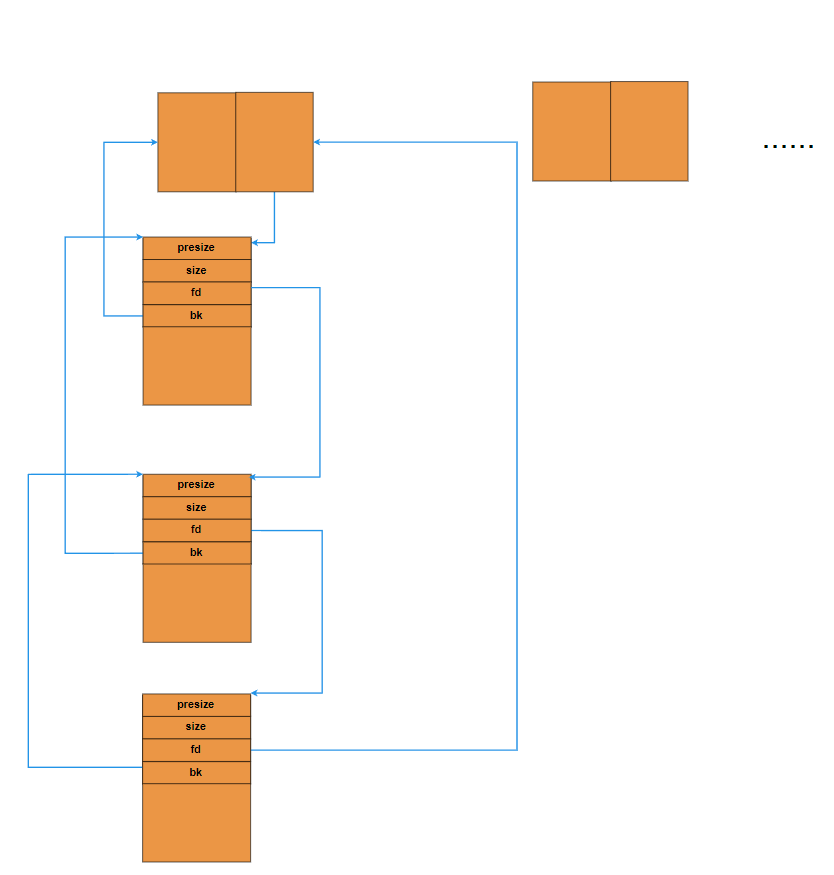
2、区别
smallbin的每个bin记录的字节大小是固定的 (FIFO)
largebin的每个bin记录的字节大小是不固定的,是一个范围,最后一个就是一个数到无限大
区分在504bytes(32位上)
















 1574
1574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









