







Kafka 概述
1、定义
大数据场景下,Kafka 经常用于把前端采集到的日志数据安全可靠地传递到后端,至于为什么要经过它而不是直接传递给我们的 Hadoop、Spark 或是 Flink,这是因为前后端生产数据和处理数据的能力往往不一样,就像我们在《计算机网络》中学的 TCP 流量控制。当我们的后端处理不了前端大量的数据的时候,总不能让前端停止工作一会吧,或者让前端的数据不断写入到日志服务器。这时候我们的 Kafka 就担任了一个缓冲的作用,我们的日志数据会被存储到 Kafka 当中,我们的后端从 Kafka 按照自己的速度来读取数据。

Kafka 传统定义:Kafka 是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会讲消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
Kafka 最新定义:Kafka 是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道,流分析,数据集成和关键任务处理。
2、消息队列
目前企业中比较常见的消息队列产品主要有Kafka、ActiveMQ、RabbitMQ、RocketMQ等。
在大数据场景主 要采用Kafka作为消息队列。在JavaEE开发中主要采用ActiveMQ、RabbitMQ、RocketMQ。
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
2.1、缓存/削峰
也就是当生产者数据产生的数据大于消费者的处理能力的时候,Kafka 可以帮我们把数据缓冲起来,这样我们的生产者和消费者都可以继续按照自己的速度生产和消费数据。
2.2、解耦
没有消息队列之前,我们的生产者和消费者是直接连接的,加入我们有 n 个生产者和 n 个消费者则需要建立 n*n 个连接,但现在有了消息队列作为中间件,就大大简化了数据传递网络的复杂性。

同时,Kafka 允许我们扩展和修改消费者和消费者的处理过程,只要它们保证相同的接口约束。
2.3、异步通信
允许用户把一个数据放入队列,但并不立即处理它,然后在需要的时候再去处理它。比如我们的注册验证,邮件发送,当用户提交表单后会立即收到注册成功的消息,而不会等待后端处理完毕才响应,这样就即保证了用户的体验也不用担心数据太多可能丢失的问题了。
3、Kafka 基础架构
这里需要了解一个特别容易混淆的概念,就是关于 Kafka 的生产者和消费者,前端源源不断产生数据,所以可以叫做 生产者,但是 Kafka 也有自己的生产者,它是用来对接外部的数据源(比如日志服务器、Mysql...);我们的消息订阅者 Hadoop、Spark 不断从 Kafka 获取数据,它们也可以叫消费者,但是 Kafka 也有自己的消费者,是用来专门对接这些订阅者的。这里要区分一下,Kafka 有自己的生产者和消费者,不要和外部的生产者和消费者混淆。
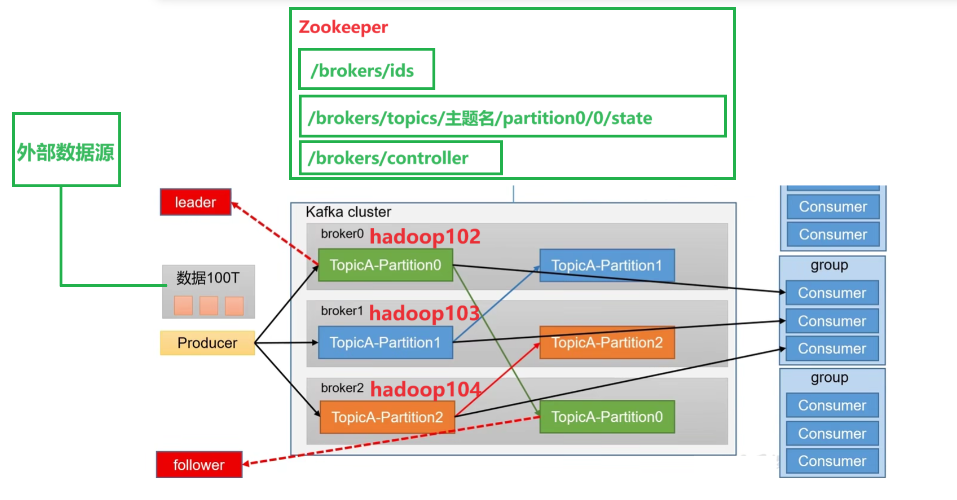
(1)Producer:消息生产者,就是向Kafka broker发消息的客户端。
(2)Consumer:消息消费者,从Kafka broker取消息的客户端。
(3)Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
(4)Broker:一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
(5)Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
(6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
(7)Replica:副本。一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
(8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
(9)Follower:每个分区多个副本中的“从”,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。
Kafka 命令行操作
Kafka 主要包括三大部分:生产者、主题分区节点、消费者。
1、Topic 命令行操作
也就是我们 kafka 下的脚本 kafka-topics.sh 的相关操作。
常用命令行操作
| 参数 | 描述 |
| --bootstrap-server <String: server toconnect to> | 连接的Kafka Broker主机名称和端口号。 |
| --topic <String: topic> | 操作的topic名称。 |
| --create | 创建主题。 |
| --delete | 删除主题。 |
| --alter | 修改主题。 |
| --list | 查看所有主题。 |
| --describe | 查看主题详细描述。 |
| --partitions <Integer: # of partitions> | 设置分区数。 |
| --replication-factor<Integer: replication factor> | 设置分区副本。 |
| --config <String: name=value> | 更新系统默认的配置。 |
查看当前一共有多少个 topic:
我们测试环境下一般只通过一台节点连接,但是生产环境下可以在 hadoop102:9092 后面加个逗号,再跟一个 hadoop103:9092 。
kafka-topics.sh --bootstrap-server hadoop102:9092 --list创建 topic :
创建一个 点赞 的主题,必须指定分区和副本才能创建成功,这里我们指定分区数和副本数分别为 1 和 3 。
kafka-topics.sh --bootstrap-server hadoop102:9092 --topic like --create --partitions 1 --replication-factor 3查看主题详细信息:
kafka-topics.sh --bootstrap-server hadoop102:9092 --topic like --describe运行结果:
Topic: like TopicId: 2RDnQulpR_K1FSmLVIKMlw PartitionCount: 1 ReplicationFactor: 3 Configs:
Topic: like Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0可以看到副本分别位于 2,1,0, 也就是我们之前安装时指定的 broker.id 这个参数。leader:2 表示 leader 节点的 broker.id = 2 ,也就是我们的 hadoop104 节点。
修改 like 主题的分区数:
修改分区数为 3(原本是 1)。
kafka-topics.sh --bootstrap-server hadoop102:9092 --topic like --alter --partitions 3修改结果:
Topic: like TopicId: 2RDnQulpR_K1FSmLVIKMlw PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: like Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: like Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: like Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
注意:
分区数只能增加不能减少!副本也不能通过命令行减少。
删除 topic like
kafka-topics.sh --bootstrap-server hadoop102:9092 --topic like --delete2、生产者命令行操作
也就是我们 kafka 下的脚本 kafka-console-producer.sh 的相关操作。
常用命令式行
| 参数 | 描述 |
| --bootstrap-server <String: server toconnect to> | 连接的Kafka Broker主机名称和端口号。 |
| --topic <String: topic> | 操作的topic名称。 |
生产消息
kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic like
> 消息1
> 消息2
> ...3、消费者命令行操作
常用命令行
| 参数 | 描述 |
| --bootstrap-server <String: server toconnect to> | 连接的Kafka Broker主机名称和端口号。 |
| --topic <String: topic> | 操作的topic名称。 |
| --from-beginning | 从头开始消费。 |
| --group <String: consumer group id> | 指定消费者组名称。 |
消费消息
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic like把主题中所有数据读取出来(所有历史数据)
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first注意:慎用,可能会把已经处理过的消息又处理一遍。















 8757
8757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











