






五一马上就来了,上期说了去哪旅游,旅游肯定得和女神/男神去啊,那这期就来收集高质量情话,让女神/男神感受甜蜜暴击。
先抓包,因为这个网站是同步加载,所以要找的包就是All里面的第一个包
然后点击 Response,按Ctrl + F,调出搜素框,检验源码里是否有页面上的数据
然后对解析页面URL
response = session.get(self.url, headers=self.headers).content.decode()从解析回来的数据里面拿到页面所有的标签和标签url
# 拿到所有标签分类的url
xml = etree.HTML(response)
labels = xml.xpath('//div[@class="tjjjbar"]/ul/li/ul/li/a/text()') # 标签
url_ = xml.xpath('//div[@class="tjjjbar"]/ul/li/ul/li/a/@href') # 标签url用for循环遍历拿到的标签url,将url传递给解析下一页面的函数
for url_list in url_:
print(url_list)
self.parse_list_url(url_list)标签页的数据就解析完了,然后来到标签里面的列表页面
同样是解析页面,拿到列表页里的所有url,然后for循环遍历,将url传递
response_list = session.get(url_list, headers=self.headers).content.decode()
xml_list = etree.HTML(response_list)
link_list = xml_list.xpath('//div[@class="pbllists"]/div/div[2]/h4/a/@href')
for qh_url_list in link_list:
# print(qh_url_list)
self.parse_data(qh_url_list)列表页就解析完了,下个页面就是情话内容页了
同样的操作,这里不一一多说
response_data = session.get(qh_url_list, headers=self.headers).content.decode()
xml_data = etree.HTML(response_data)
qh_data = xml_data.xpath('//div[@class="askbody"]/div/a/p/text()')
# print(qh_data)
for qinghhua in qh_data:
print(qinghhua)
print('====' * 20)然后就可以将情话内容打印出来,但是这些内容是一起打印的,能不能我自己输入哪个标签就打印哪个标签的情话呢?答案是 absolutely ok的
# 构造空数据集
data_set = []
# 遍历标签和标签url
for label, url_list in zip(labels, url_):
# 构造空字典
data_dict = {}
# 设置输入等于标签
data_dict[self.user_input] = label
# 如果输入等于标签
if self.user_input == label:
# 则标签等于对应标签url
data_dict[label] = url_list
# 将字典添加到数据集中
data_set.append(data_dict)
# print(data_set)上面就是这个操作的代码,注释写的很清楚,还不懂的可以问我
然后输入什么,就输出什么情话啦
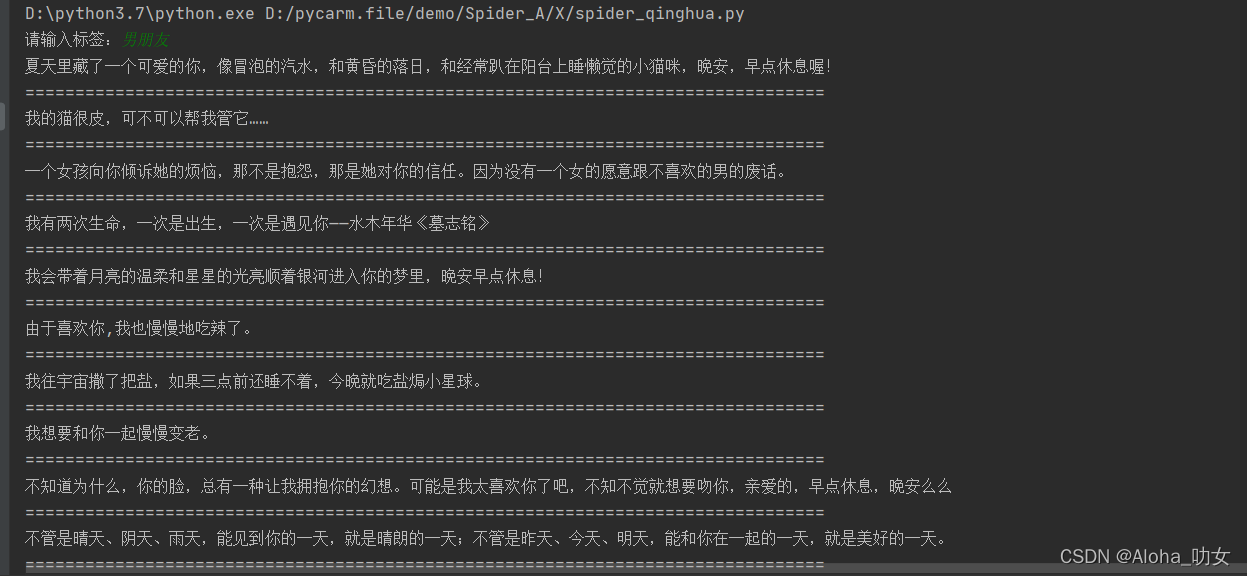
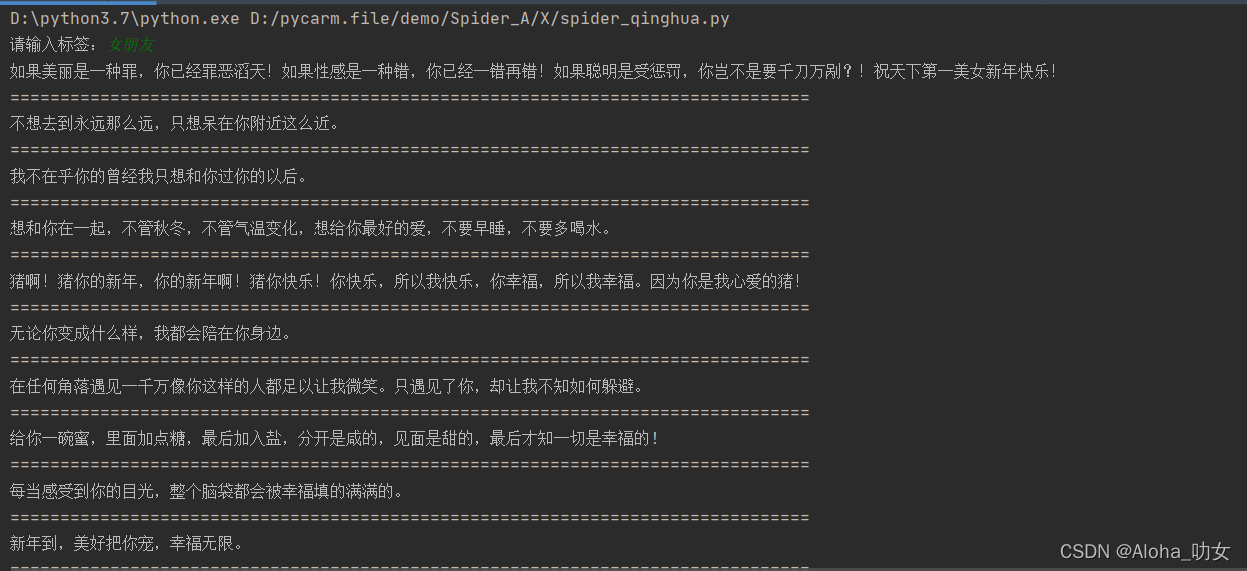
全部代码如下,赶紧用起来吧
# -*- encoding: utf-8 -*-
from fake_useragent import UserAgent
from lxml import etree
import os, xlwt, xlrd
from xlutils.copy import copy
from requests_html import HTMLSession
# 构造请求对象
session = HTMLSession()
class Spider(object):
def __init__(self):
self.user_input = input('请输入标签:')
self.url = 'http://www.ainicr.cn/tab/'
self.ua = UserAgent()
self.headers = {
'User-Agent': self.ua.random,
'cookie': 'UM_distinctid=17f2963c6b9d85-0406648327385d-f791b31-144000-17f2963c6baf6a; CNZZDATA1272896529=851467696-1645664284-https%253A%252F%252Fwww.baidu.com%252F%7C1650776082',
'Host': 'www.ainicr.cn'
}
# 解析标签分类页
def parse_response(self):
response = session.get(self.url, headers=self.headers).content.decode()
# 拿到所有标签分类的url
xml = etree.HTML(response)
labels = xml.xpath('//div[@class="tjjjbar"]/ul/li/ul/li/a/text()') # 标签
url_ = xml.xpath('//div[@class="tjjjbar"]/ul/li/ul/li/a/@href') # 标签url
# 构造空数据集
data_set = []
# 遍历标签和标签url
for label, url_list in zip(labels, url_):
# 构造空字典
data_dict = {}
# 设置输入等于标签
data_dict[self.user_input] = label
# 如果输入等于标签
if self.user_input == label:
# 则标签等于对应标签url
data_dict[label] = url_list
# 将字典添加到数据集中
data_set.append(data_dict)
# print(data_set)
self.parse_list_url(url_list)
# 解析标签列表页
def parse_list_url(self, url_list):
response_list = session.get(url_list, headers=self.headers).content.decode()
xml_list = etree.HTML(response_list)
link_list = xml_list.xpath('//div[@class="pbllists"]/div/div[2]/h4/a/@href')
for qh_url_list in link_list:
# print(qh_url_list)
self.parse_data(qh_url_list)
# 解析最终情话页面
def parse_data(self, qh_url_list):
response_data = session.get(qh_url_list, headers=self.headers).content.decode()
xml_data = etree.HTML(response_data)
qh_data = xml_data.xpath('//div[@class="askbody"]/div/a/p/text()')
# print(qh_data)
for qinghhua in qh_data:
print(qinghhua)
print('====' * 20)
data = {
f'{self.user_input}': [qinghhua]
}
self.save(data)
def save(self, data):
# 获取表的名称
sheet_name = [i for i in data.keys()][0]
# 创建保存excel表格的文件夹
# os.getcwd() 获取当前文件路径
os_mkdir_path = os.getcwd() + '/情话数据/'
# 判断这个路径是否存在,不存在就创建
if not os.path.exists(os_mkdir_path):
os.mkdir(os_mkdir_path)
# 判断excel表格是否存在 工作簿文件名称
os_excel_path = os_mkdir_path + '数据.xls'
if not os.path.exists(os_excel_path):
# 不存在,创建工作簿(也就是创建excel表格)
workbook = xlwt.Workbook(encoding='utf-8')
"""工作簿中创建新的sheet表""" # 设置表名
worksheet1 = workbook.add_sheet(sheet_name, cell_overwrite_ok=True)
"""设置sheet表的表头"""
sheet1_headers = ('情话')
# 将表头写入工作簿
for header_num in range(0, len(sheet1_headers)):
# 设置表格长度
worksheet1.col(header_num).width = 2560 * 3
# 写入表头 行, 列, 内容
worksheet1.write(0, header_num, sheet1_headers[header_num])
# 循环结束,代表表头写入完成,保存工作簿
workbook.save(os_excel_path)
"""=============================已有工作簿添加新表==============================================="""
# 打开工作薄
workbook = xlrd.open_workbook(os_excel_path)
# 获取工作薄中所有表的名称
sheets_list = workbook.sheet_names()
# 如果表名称:字典的key值不在工作簿的表名列表中
if sheet_name not in sheets_list:
# 复制先有工作簿对象
work = copy(workbook)
# 通过复制过来的工作簿对象,创建新表 -- 保留原有表结构
sh = work.add_sheet(sheet_name)
# 给新表设置表头
excel_headers_tuple = ('情话')
for head_num in range(0, len(excel_headers_tuple)):
sh.col(head_num).width = 2560 * 3
# 行,列, 内容, 样式
sh.write(0, head_num, excel_headers_tuple[head_num])
work.save(os_excel_path)
"""========================================================================================="""
# 判断工作簿是否存在
if os.path.exists(os_excel_path):
# 打开工作簿
workbook = xlrd.open_workbook(os_excel_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_excel_path)
if __name__ == '__main__':
s = Spider()
s.parse_response()
下期再见!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









