







 本文介绍了如何利用Python爬取携程景区信息,通过Ctrip API获取100页数据,解析并保存至Excel,方便旅游选择。
本文介绍了如何利用Python爬取携程景区信息,通过Ctrip API获取100页数据,解析并保存至Excel,方便旅游选择。
各位小伙伴们,五一马上就要来了,你们想好去哪里玩了吗,没想好的同学看过来。今天是携程景区信息的爬取,让你轻松选择。
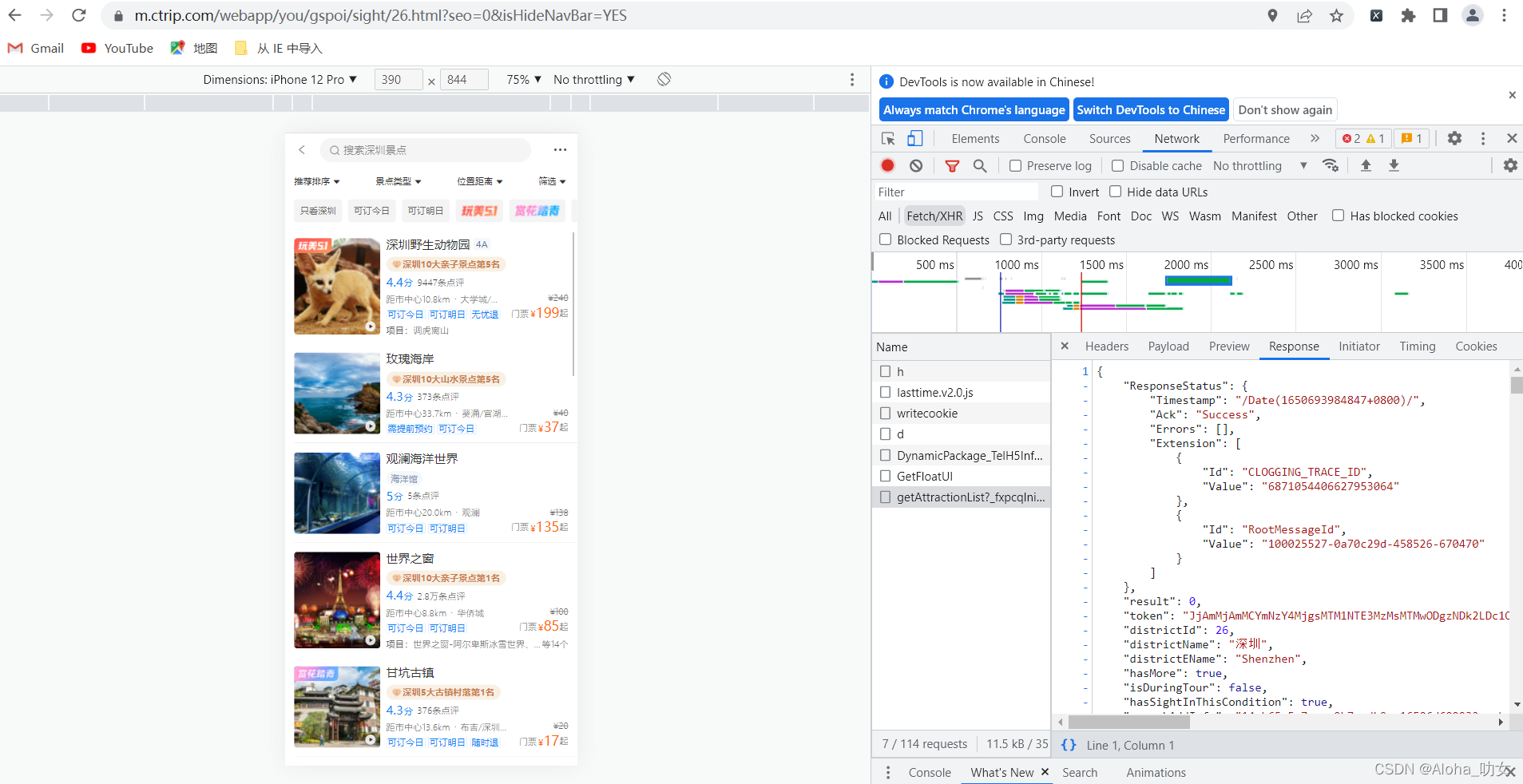
美好的一天从抓包开始,点击最后一个包,校对数据是否和页面一致,然后点击 Headers 复制 包的URL,先导入后面要用到的库
import requests
import json
from openpyxl import workbook然后就是发送请求,因为数据是json数据,所以就不是.text了,要用.json()
response = requests.post(self.url, headers=self.headers).json()
print(response)再就是解析内容,因为是json数据,解析方法基本上和前面几期差不多的,所以我就不多说了
result_list = response['attractionList']
for result in result_list:
city = result['card']['districtName'] # 城市
place = result['card']['poiName'] # 景区
status = result['card']['openStatus'] # 状态
score = result['card']['commentScore'] # 评分
tickets = result['card']['priceTypeDesc'] # 门票
distance = result['card']['distanceStr'] # 距离市中心
url = result['card']['detailUrl'] # 详情链接
print(city)
print(place)
print(status)
print(score)
print(tickets)
print(distance)
print(url)
print('===' * 30)
# print(f'景区{place}的信息收集完毕!!!')解析完成之后就是保存,这里我选择保存Excel
self.wb = workbook.Workbook() # 创建Excel表格
self.ws = self.wb.active # 激活当前表
# 向当前表添加标题
self.ws.append(['城市', '景区', '状态', '评分', '门票', '距离市中心', '详情链接'])下面还要建一个保存函数
def save(self, city, place, status, score, tickets, distance, url):
# 向表格里添加数据
mylist = [city, place, status, score, tickets, distance, url]
self.ws.append(mylist)
# 保存到表格wb
self.wb.save('携程.xlsx')这仅仅的一页的数据,下面就来设置翻页
for i in range(1, 101):
print('当前下载第{}页'.format(i))
payload = json.dumps({
"index": f'{i}',
"count": 20,
"sortType": 1,
"isShowAggregation": True,
"districtId": self.CityId, # 城市ID
"scene": "DISTRICT",
"pageId": "214062",
"traceId": "f33070fa-82a6-6d22-2d18-164f0af07734",
"extension": [
{
"name": "osVersion",
"value": "10.3.1"
},
{
"name": "deviceType",
"value": "ios"
}
],
"filter": {
"filterItems": []
},
"crnVersion": "2020-09-01 22:00:45",
"isInitialState": True,
"head": {
"cid": "09031047314318028828",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": []
}
})设置翻页需要在参数中设置,这里我也不知道具体有多少页,所以我设置了100页,然后参数里面还有一个城市的ID,这是换城市爬取的关键,比如说输入北京的城市id,就会返回北京景区的数据,其他城市也一样,目前我只知道北上广深的城市id,分别是1,2,152,26。你们如果想看其他城市的数据,在评论区说出是哪个城市,我都会帮你们找。
然后全部代码如下
# -*- encoding: utf-8 -*-
import requests
import json
from openpyxl import workbook
"""
城市ID{上海: 2, 北京: 1, 广州: 152, 深圳: 26}
"""
class XcSpider(object):
def __init__(self):
self.CityId = input('请输入城市ID:')
self.url = "https://m.ctrip.com/restapi/soa2/18254/json/getAttractionList?_fxpcqlniredt=09031047314318028828&x-traceID=09031047314318028828-1646054807738-9064633"
self.headers = {
'content-type': 'application/json',
'origin': 'https://m.ctrip.com',
'referer': 'https://m.ctrip.com/webapp/you/gspoi/sight/2.html?seo=0&allianceid=4897&sid=155952&isHideNavBar=YES&from=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fyou%2Fgsdestination%2Fplace%2F2.html%3Fseo%3D0%26ishideheader%3Dtrue%26secondwakeup%3Dtrue%26dpclickjump%3Dtrue%26allianceid%3D4897%26sid%3D155952%26ouid%3Dindex%26from%3Dhttps%253A%252F%252Fm.ctrip.com%252Fhtml5%252F',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'ibulanguage=CN; ibulocale=zh_cn; cookiePricesDisplayed=CNY; _gcl_au=1.1.2001712708.1646054591; _RF1=223.104.63.214; _RGUID=0731b0f7-45b5-4666-9828-888744fb269f; _RSG=cPKj5TFinS0VQo.4T8YeW9; _RDG=2868710522b1702c43085468305d1ce8b8; _bfaStatusPVSend=1; MKT_CKID=1646054594542.yi12k.1t3u; MKT_CKID_LMT=1646054594543; _ga=GA1.2.333705235.1646054595; _gid=GA1.2.1046662294.1646054595; appFloatCnt=2; nfes_isSupportWebP=1; GUID=09031047314318028828; nfes_isSupportWebP=1; MKT_Pagesource=H5; _bfs=1.4; _jzqco=%7C%7C%7C%7C1646054602232%7C1.1650478479.1646054594536.1646054655182.1646054672431.1646054655182.1646054672431.0.0.0.4.4; __zpspc=9.2.1646054672.1646054672.1%232%7Cwww.baidu.com%7C%7C%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23; _bfi=p1%3D100101991%26p2%3D100101991%26v1%3D5%26v2%3D4; _bfaStatus=success; mktDpLinkSource=ullink; librauuid=MTPpuP1M6AmQCSUc; ibu_h5_lang=en; ibu_h5_local=en-us; _pd=%7B%22r%22%3A12%2C%22d%22%3A259%2C%22_d%22%3A247%2C%22p%22%3A260%2C%22_p%22%3A1%2C%22o%22%3A263%2C%22_o%22%3A3%2C%22s%22%3A263%2C%22_s%22%3A0%7D; Union=OUID=&AllianceID=4897&SID=155952&SourceID=&AppID=&OpenID=&exmktID=&createtime=1646054807&Expires=1646659606764; MKT_OrderClick=ASID=4897155952&AID=4897&CSID=155952&OUID=&CT=1646054806768&CURL=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fyou%2Fgspoi%2Fsight%2F2.html%3Fseo%3D0%26allianceid%3D4897%26sid%3D155952%26isHideNavBar%3DYES%26from%3Dhttps%253A%252F%252Fm.ctrip.com%252Fwebapp%252Fyou%252Fgsdestination%252Fplace%252F2.html%253Fseo%253D0%2526ishideheader%253Dtrue%2526secondwakeup%253Dtrue%2526dpclickjump%253Dtrue%2526allianceid%253D4897%2526sid%253D155952%2526ouid%253Dindex%2526from%253Dhttps%25253A%25252F%25252Fm.ctrip.com%25252Fhtml5%25252F&VAL={"h5_vid":"1646054589723.2rr0y3"}; _bfa=1.1646054589723.2rr0y3.1.1646054589723.1646054806818.1.10.214062'
}
self.wb = workbook.Workbook() # 创建Excel表格
self.ws = self.wb.active # 激活当前表
# 向当前表添加标题
self.ws.append(['城市', '景区', '状态', '评分', '门票', '距离市中心', '详情链接'])
def get_data(self):
for i in range(1, 101):
print('当前下载第{}页'.format(i))
payload = json.dumps({
"index": f'{i}',
"count": 20,
"sortType": 1,
"isShowAggregation": True,
"districtId": self.CityId, # 城市ID
"scene": "DISTRICT",
"pageId": "214062",
"traceId": "f33070fa-82a6-6d22-2d18-164f0af07734",
"extension": [
{
"name": "osVersion",
"value": "10.3.1"
},
{
"name": "deviceType",
"value": "ios"
}
],
"filter": {
"filterItems": []
},
"crnVersion": "2020-09-01 22:00:45",
"isInitialState": True,
"head": {
"cid": "09031047314318028828",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": []
}
})
response = requests.post(self.url, headers=self.headers, data=payload).json()
# print(response)
self.parse(response)
def parse(self, response):
result_list = response['attractionList']
for result in result_list:
city = result['card']['districtName'] # 城市
place = result['card']['poiName'] # 景区
status = result['card']['openStatus'] # 状态
score = result['card']['commentScore'] # 评分
tickets = result['card']['priceTypeDesc'] # 门票
distance = result['card']['distanceStr'] # 距离市中心
url = result['card']['detailUrl'] # 详情链接
print(city)
print(place)
print(status)
print(score)
print(tickets)
print(distance)
print(url)
print('===' * 30)
# print(f'景区{place}的信息收集完毕!!!')
self.save(city, place, status, score, tickets, distance, url)
def save(self, city, place, status, score, tickets, distance, url):
# 向表格里添加数据
mylist = [city, place, status, score, tickets, distance, url]
self.ws.append(mylist)
# 保存到表格wb
self.wb.save('携程.xlsx')
if __name__ == '__main__':
x = XcSpider()
x.get_data()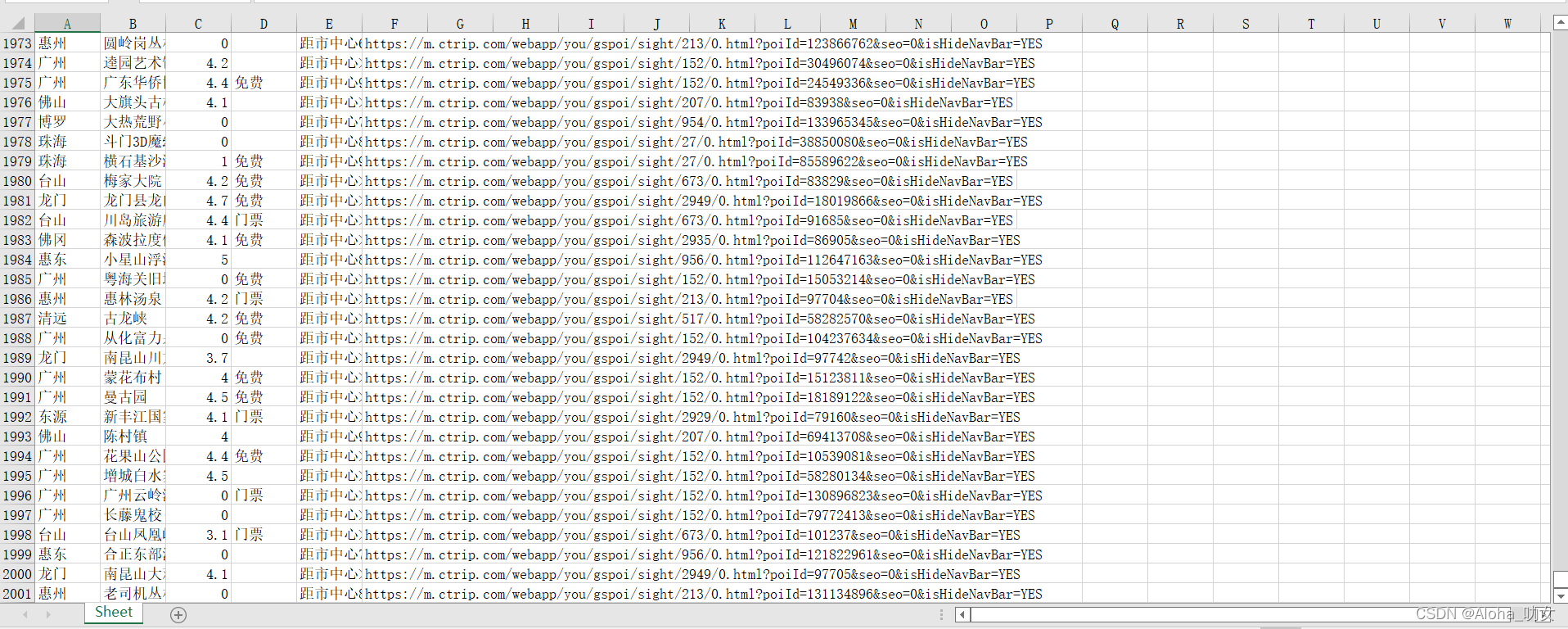
这个是我爬取到的深圳数据,它每一页是20个景区,100页刚好2000数据。ok,这期分享到此结束,后面还有更多好玩有趣的爬虫。

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









