







1、trie树
字典树介绍
概念:字典树(TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。主要思想是利用字符串的公共前缀来节约存储空间。很好地利用了串的公共前缀,节约了存储空间。字典树主要包含两种操作,插入和查找。
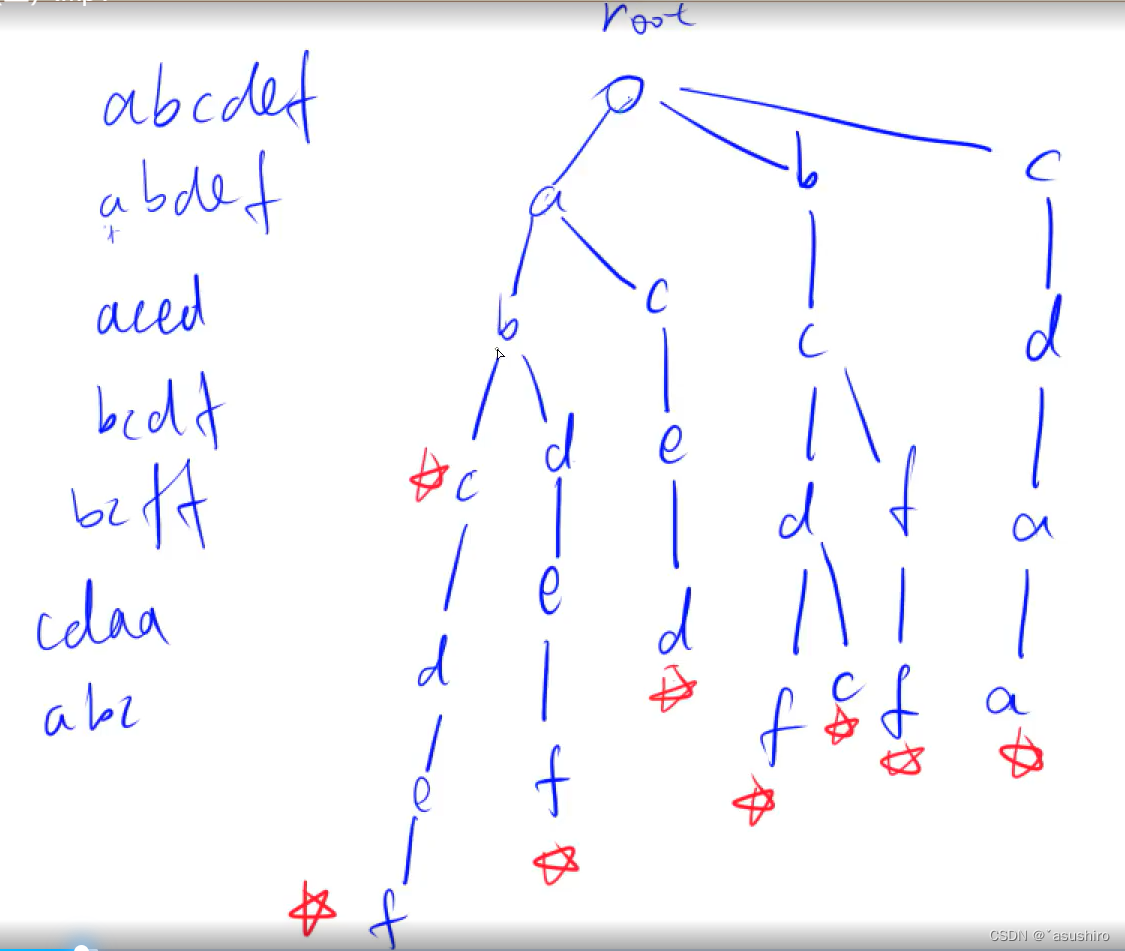
1.变量idx: idx代表字典树中每一个节点的编号,idx的大小只与插入字典树的先后顺序有关.
2.trie[N][26]: 每个trie代表一条边,字典树其中1~N为边上方节点的编号,0代表root节点,1~26为连在i节点下方的26个字母。如果trie[i][x]=0,则代表字典树中目前没有这个点,而trie[i][x]的值代表这个点下方连有的点的编号,例如:trie[i][2]=9代表第i号点和的下方连有一个点‘c’,并且那个点的编号是9,为什么是c呢?因为 ‘c’-‘a’=2
3.cnt[N]: cnt[i]==0代表编号为i的点不是一个单词的结束点,在上面的图中代表这个点不是空点,但是没有标红,cnt[i]!=0代表编号为i的点是一个单词的结束点,即红点。cnt[i]不一定只为0或1,因为有可能多次输入了同一个单词。
理解:
在代码中理解,可以将tire[i][26]看作一个类(连着26个边的结点(可能是空结点)),在插入查询操作时都是对tire[i][26]进行操作的,idx就是对指向哪个的
int son[N][26], cnt[N], idx;
// 0号点既是根节点,又是空节点
// son[][]存储树中每个节点的子节点
// cnt[]存储以每个节点结尾的单词数量
// idx表示指向当前这一行的指针对应的是N的指针
// 插入一个字符串
void insert(char *str)
{
int p = 0;//开始时表示根节点
for (int i = 0; str[i]; i ++ )//在c++中字符串结尾时是0
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;//如果不存在子节点就创建一个
p = son[p][u];//指向下一个节点
}
cnt[p] ++ ;//到了结尾对应整条路线结尾标红
}
// 查询字符串出现的次数
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';//子节点对应26中的一个
if (!son[p][u]) return 0;//未找到
p = son[p][u];
}
return cnt[p];
}
2、并查集
操作:
- 将两个集合合并
- 查询两个元素是否在同一个集合当中
基本原理:每个集合用一颗数来表示。树根的编号就是整个集合的编号。每个结点存储他的父节点,p[x]表示x的父节点
问题:
1、如何判断树根:if(p[x] == x)
2、如何求x的集合编号:while(p[x] != x) x = p[x];
3、如何将两个集合合并:px是x的集合编号,py是y的集合编号。那么p[x] = y就是将y的集合查到x的树根下面
(1)朴素并查集:
int p[N]; //存储每个点的祖宗节点
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ ) p[i] = i;
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
(2)维护size的并查集:
int p[N], size[N];
//p[]存储每个点的祖宗节点, size[]只有祖宗节点的有意义,表示祖宗节点所在集合中的点的数量
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
size[i] = 1;
}
// 合并a和b所在的两个集合:
size[find(b)] += size[find(a)];
p[find(a)] = find(b);
(3)维护到祖宗节点距离的并查集:
int p[N], d[N];
//p[]存储每个点的祖宗节点, d[x]存储x到p[x]的距离
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x)
{
int u = find(p[x]);
d[x] += d[p[x]];
p[x] = u;
}
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
d[i] = 0;
}
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
d[find(a)] = distance; // 根据具体问题,初始化find(a)的偏移量
3、堆
概念:
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<=K2i+2 ,则称为小堆(或大堆)。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
结构:
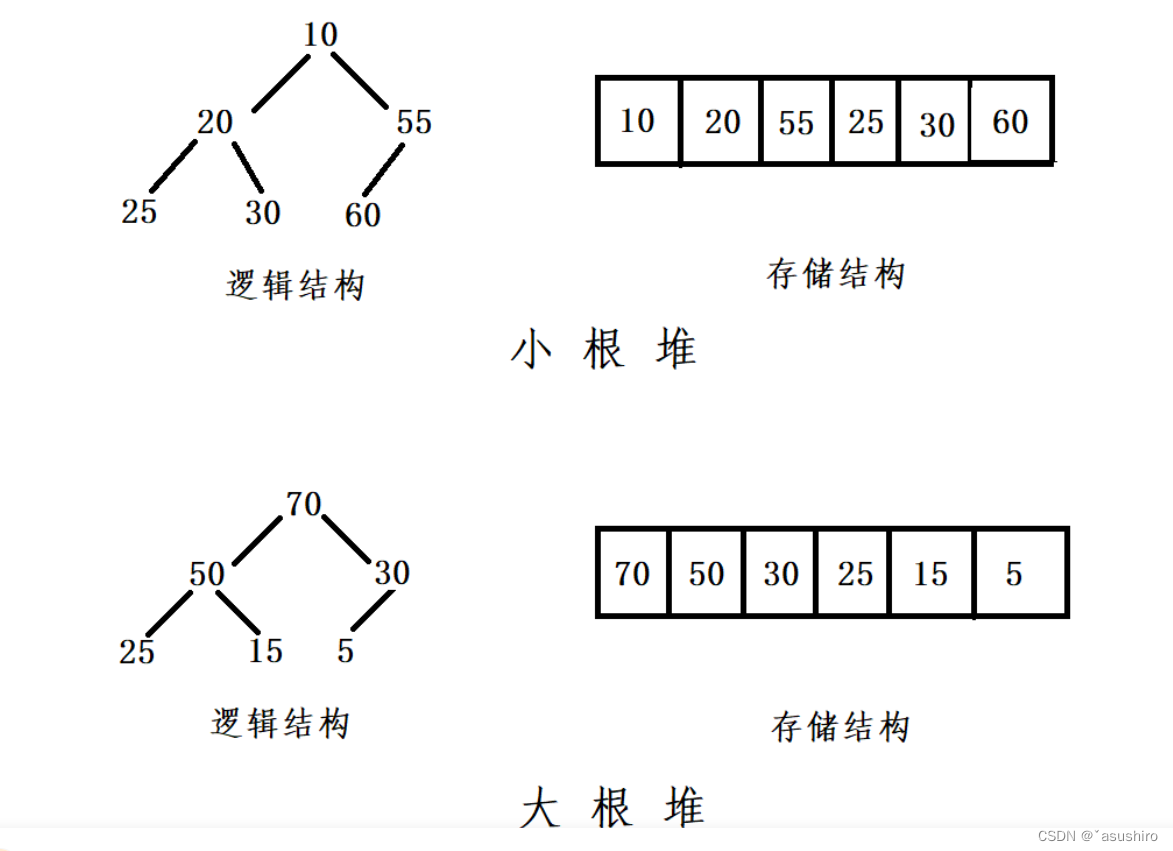
性质:小根堆:每个结点都是小于等于左右儿子的值
如何手写一个堆?
堆的操作都可以用up和down两个操作进行:
- 插入一个数 heap[++ size]; up(size)
- 求集合中的最小值 heap[1];
- 删除最小值 heap[1] = heap[size]; size --; down[1];
- 删除任意一个元素 heap[k] = heap[size]; size -- ; up[k]; down[k];
- 修改任意一个元素 heap[k] = x; up[k]; down[k];
当进行第K个元素交换时heap[] = heap[]的交换时就需要用heap_swap函数
存储:
根节点的下标是1, 结点的左儿子是2x, 右儿子是 2x + 1;
// h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1
// ph[k]存储第k个插入的点在堆中的位置
// hp[k]存储堆中下标是k的点是第几个插入的
int h[N], ph[N], hp[N], size;
//当维护对中第k个插入的数时就需要用到ph和hp数组,这两个数组互为反数组,一个是从第k个元素到堆中下标的映射, 一个是从堆下标到第k个元素的映射,为此也需要建立一个特殊的交换函数进行维护这两个数组
// 交换两个点,及其映射关系
void heap_swap(int a, int b)
{
swap(ph[hp[a]],ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
void down(int u)
{
int t = u;// t是用来表示根节点和两个儿子结点中的最小的结点下标
if (u * 2 <= size && h[u * 2] < h[t]) t = u * 2;
if (u * 2 + 1 <= size && h[u * 2 + 1] < h[t]) t = u * 2 + 1;
if (u != t)// 当最小的结点下标不是根节点时就要进行交换
{
heap_swap(u, t);//当要处理第K个插入的元素时用到特殊的交换函数
down(t); // 进行递归处理
}
}
void up(int u)
{
while (u / 2 && h[u] < h[u / 2])// 当子节点比根节点小时就进行交换
{
heap_swap(u, u / 2);
u /= 2;
}
}
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);// 从中间开始建立堆,保证在插入新的结点时下面的子节点连成的树已经是堆只需要进行down操作
以上学习自ACwing
















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











