







一:分布式事务
1、理论基础
分布式事务主要区分本地事务
什么是本地事务(Local Transaction)?本地事务也称为数据库事务或传统事务(相对于分布式事务而言)。尤其对于数据库而言,为了数据安全,提供了以下的几个步骤来完成本地事务的提交以及回滚。其具备ACID四特性。
分布式事务是指组成事务的参与者,每个业务部分都分别部署在不同的服务器上。在微服务架构中多个节点的协调工作必须保持原子性,多个节点的逻辑必须同时成功或者同时失败。不能出现部分节点成功,部分失败的情况。一次大的操作由不同的小操作组成的,这些小的操作分布在不同的服务器上,分布式事务需要保证这些小操作要么全部成功,要么全部失败。
本质上来说,分布式事务就是为了保证不同数据库、不同服务器节点的数据一致性
主要说2个理论基础,一个是分布式的CAP定理,一个是BASE理论。
CAP定理/原则:
指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)这三个要素最多只能同时实现两点,不可能三者兼顾。在分布式场景中,由于网络硬件等客观因素,网络之间的通信可能会存在中断、丢包等情况,所以分区容错性(Partition tolerance)是我们分布式场景中必须要满足的,三要素中就只能有有这2种组合:CP和AP。
AP:AP模型强调的是系统的可用性,在做系统设计时,需要优先考虑可用性;
CP:CP模型强调的是系统的一致性,在做系统设计时,需要优先考虑一致性;
基于CAP定理的AP模型和CP模型,又演化出了BASE理论。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
一致性可以这么理解,客户端访问所有节点,返回的都是同一份最新的数据。可用性是指,每次请求都能获取非错误的响应,但不保证获取的数据是最新数据。分区容错性是指,节点之间由于网络分区而导致消息丢失的情况下,系统仍能继续正常运行。需要强调的是,这里的一致性是指线性一致性,至于什么是线性一致性,我们会在3.7节中详细解释。这里读者只需要理解为,对于单个对象,读操作会返回最近一次写操作的结果,这也叫线性一致性读。
为了便于理解,举一个具体的例子。考虑一个非常简单的分布式系统,它由两台服务器Node1和Node2组成,这两台服务器都存储了同一份数据的两个副本,我们可以简单认为这个数据是一个键值对,初始的记录为V=0。服务器Node1和Node2之间能够互相通信,并且都能与客户端通信。这个例子如图所示。
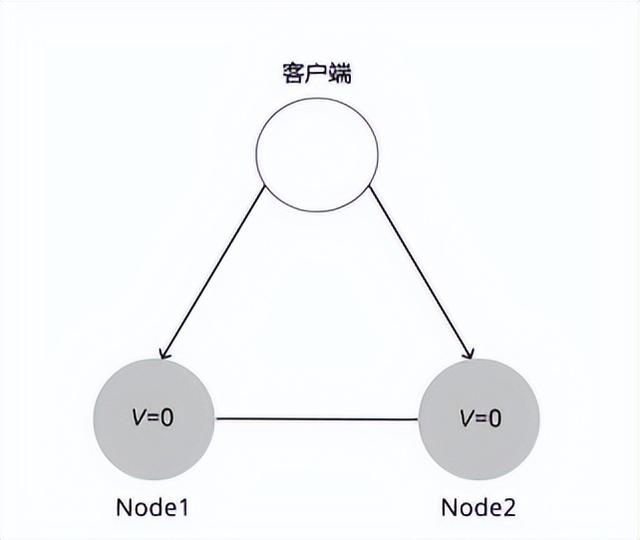
现在客户端向Node1发送写请求V=1。如果Node1收到写请求后,只将自己的V值更新为1,然后直接向客户端返回写入成功的响应,这时Node2的V值还是等于0,此时客户端如果向Node2发起了读V的请求,读到的将是旧的值0。那么,此时这两个节点是不满足一致性的。
如果Node1先把V=1复制给Node2,再返回客户端,那么此时两个节点的数据就是一致的。这样,无论客户端从哪个节点读取V值,都能读到最新的值1。此时系统满足一致性
如图数据库主从的写和读操作:
确保一致性实现流程:
写入主库后,向从库同步器件要将从库锁定,待同步完成后再释放锁,以免在新数据写入成功后,从查询的依旧是旧数据。
接下来的可用性和分区容错性就比较好理解了。
可用性(A):保证每个请求不管成功或者失败都有响应。
可用性就是说,客户端向其中一个节点发起一个请求,且该节点正常运行无故障,那么这个节点最终必须响应客户端的请求。
对于高可用性的衡量标准如下:
确保可用性的前提下上面同步加锁的情况肯定不能发生,改进异步如下:
分区容忍性(P):系统中任意信息的丢失或失败不会影响系统的继续运作。
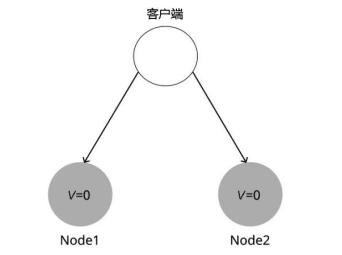
为什么CAP定理说一个系统不能同时满足一致性、可用性和分区容错性?这里给出简要的证明。
我们使用反证法证明。假设存在一个同时满足这三个属性的系统,我们第一件要做的事情就是让系统发生网络分区,就像图中的情况一样,服务器Node1和Node2之间的网络发生故障导致断开连接。
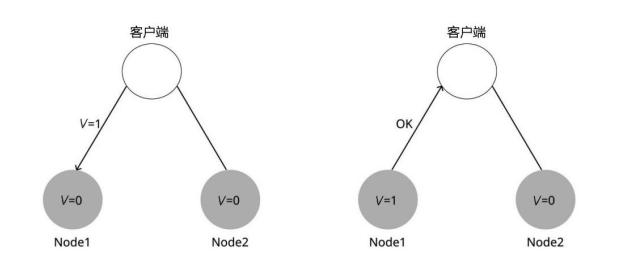
客户端向Node1发起写请求,将V的值更新为1,因为系统是可用的,所以Node1必须响应客户端的请求,但是由于网络分区,Node1无法将其数据复制到Node2,如图所示。
接着,客户端向服务器Node2发起读V的请求,再一次因为系统是可用的,所以Node2必须响应客户端的请求。还是因为网络分区,Node2无法从Node1更新V的值,所以Node2返回给客户端的是旧的值0,和客户端刚才写入的V的值不同,如图所示。
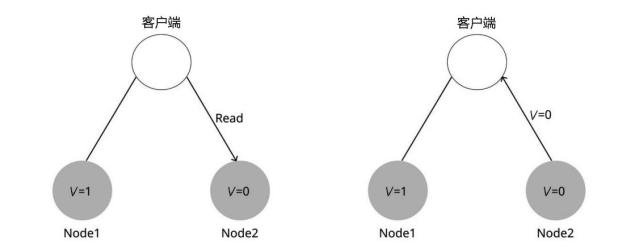
这显然违背了一致性,因此证明不存在这样的系统。
总的来说:
没有P分区容错性就不属于分布式系统,A强一致和C高可用不能并存所以只有 CP 和 AP的组合。
BASE理论
BASE理论是基于CAP原则演化而来。
是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)的简写。核心是既然没法做到强一致性,但每一个应用都可根据自身的业务特点采用适当的方式来达到最终一致性。
Basically Available(基本可用):指系统出现不可预知的故障时,允许损失部分可用性,但保证核心可用。
基本可用比较好理解,就是不追求 CAP 中的「任何时候,读写都是成功的」,而是系统能够基本运行,一直提供服务。基本可用强调了分布式系统在出现不可预知故障的时候,允许损失部分可用性,相比正常的系统,可能是响应时间延长,或者是服务被降级。
比如:系统某功能的正常响应时间是0.1秒,但由于系统出现异常(机房断电、光纤挖断等)系统功能的响应时间升到1-2秒;
再比如电商的大促或秒杀,为了保证系统的稳定性,当用户流量超过了系统阈值,可把部分用户引流到一个降级页面。
在双十一秒杀活动中,如果抢购人数太多超过了系统的 QPS 峰值,可能会排队或者提示限流,这就是通过合理的手段保护系统的稳定性,保证主要的服务正常,保证基本可用
Soft state(软状态):
与(原子性)硬状态相对。系统中的数据存在中间状态,并认为该中间状态不影响系统的整体可用性,即表示数据副本之间的同步有延迟。
软状态可以对应 ACID 事务中的原子性,在 ACID 的事务中,实现的是强制一致性,要么全做要么不做,所有用户看到的数据一致。其中的原子性(Atomicity)要求多个节点的数据副本都是一致的,强调数据的一致性。
原子性可以理解为一种“硬状态”,软状态则是允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
Eventually consistent(最终一致性):
系统中的所有数据副本,在经过一段时间后,所有数据的状态都能达到一个最终的一致的状态。
数据不可能一直是软状态,必须在一个时间期限之后达到各个节点的一致性,在期限过后,应当保证所有副本保持数据一致性,也就是达到数据的最终一致性。
比如上面的软状态,不可能让其一直存在。必须在时限内,通过人工补偿或者定时任务或者MQ消息队列的形式让所有副本数据达到一致。
总的来说:
在系统设计中,最终一致性实现的时间取决于网络延时、系统负载、不同的存储选型、不同数据复制方案设计等因素。
分布式中的一致性有三种级别:
①强一致性:系统在某个节点中写入或修改了数据,那么之后在任意节点读取到的数据都是最新的数据。
②弱一致性:不一定能读到最新的值,也不能保证在一定时间后读取到的数据是最新的,只会尽量在某个时刻达到数据一致的状态。
③最终一致性:弱一致性的升级版,可以保证在一定时间内达到数据的最终一致性。
一般常用的是最终一致性,但是也有一些对一致性要求比较高的,比如银行的交易系统,这种要保证强一致性。
2,分布式事务产生的原因
分布式事务的产生,源自互联网、电商等的发展,当同一个系统不同模块不同业务的数据在一个存储设备里,随着业务的发展,系统逐渐满足不了业务的发展时,常用的手段就是“拆”,拆的手段有垂直拆分和水平拆分,针对业务模块和数据库存储,都可以进行垂直拆分和水平拆分。拆分后就会存在不同的业务使用自己的数据库进行存储,这就会导致一个操作需要进行跨数据库操作。这就是分布式事务产生的最基本的原因所在。而我们知道,只要是事务,必须要满足事务的四性(ACID),为了使事务的四性得到满足,业内使用了多种技术手段,但各种技术手段都有其优点和缺点。
事务的四性(ACID):Automicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)。
比如:电商的下单,里面包含写订单表、扣减商品库存、写财务结算,订单信息、商品库存、财务模块按业务已经拆分到不同的模块,各自有属于自己的数据库,这个时候就是一个典型的分布式事务场景。
分布式事务的解决方案:
2PC,3PC,TCC,seeta-saga,基于消息队列的异步模型等
3、刚性分布式事务
刚性务的特点:
数据的状态强调的是强一致性,系统能支持的并发低,事务执行的时间都比较短,属于短事务,所有数据在事务内同步执行。刚性分布式事务遵循XA协议,通过实现XA的接口来实现分布式事务。XA规范由AP、RM、TM组成。
AP:(应用程序 Application Program)定义事务的开始和结束,并访问事务内的资源;
RM:(资源管理器 Resource Manager)通常指的就是数据库资源;
TM:(事务管理器 Transaction Manager) 负责管理事务,分配事务的唯一标识、监控事务的执行情况、并负责事务的提交、回滚等操作;
下面列出一些常见的实现XA协议的分布式事务方法。
两阶段提交(2PC):
XA协议:XA是一个分布式事务协议。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。
思路
2PC机制顾名思义分为两个阶段,是基于DB来完成,其实施思路可概括为:
(1)投票阶段(voting phase):参与者将操作结果通知协调者;
(2)提交阶段(commit phase):收到参与者的通知后,协调者再向参与者发出通知,根据反馈情况决定各参与者是否要提交还是回滚;
举例
ABCDE五个室友,A组织一场王者荣耀开黑游戏,A需要拉其他四个室友五排,为了大家都有时间,你需要发送信息去问室友。这时候A就属于协调者,BCDE属于参与者、
投票阶段:
(1)A在寝室群发送一条消息,说今晚下课后寝室五黑,询问室友是否有时间;
(2)B回复有时间;
(3)C回复有时间;
(4)D回复有时间
(5)E迟迟不回复,此时对于这个活动,ABCD均处于阻塞状态,算法无法继续进行;
提交阶段:
(1)协调者A将收集到的结果反馈给BCDE(什么时候反馈,以及反馈结果如何,在此例中取决与E的时间与决定);
(2)B收到;
(3)C收到;
(4)D收到;
(5)E收到;
2PC 的流程如下图所示:

从上图可以看出,要实现 2PC,所有的参与者都要实现三个接口:
-
Prepare():TM 调用该接口询问各个本地事务是否就绪
-
Commit():TM 调用该接口要求各个本地事务提交
-
Rollback():TM 调用该接口要求各个本地事务回滚
2PC的缺点:
1、同步阻塞:所有参与事务的资源都处于阻塞状态;
2、TM瓶颈:当TM故障时,所有的参与者都将被锁定,资源得不到释放;
3、RM资源锁定时间过长;
4、全局锁定(隔离级别串行化),不适合长事务,并发低;
基于2PC的缺点,又提出三阶段(3PC)提交。
三阶段(3PC)提交:
三阶段(3PC)提交分为CanCommit询问阶段、PreCommit准备阶段和DoCommit提交三个阶段。
CanCommit:TM向所有RM发出CanCommit指令,RM收到指令后,判断可否提交事务,如果可以返回ok,否则返回no;
PreCommit:当TM收到所有RM都返回CanCommit的结果为ok时,TM向所有RM发出PreCommit;当有一个RM返回no或超时,导致TM没收到反馈则事务中断,TM向所有RM发出abort终止事务,TM收到abort后终止事务,释放资源。如果RM没收到TM发出的abort或是超时,则RM也会中断自身的事务,释放资源;
DoCommit:TM收到所有RM都返回PreCommit的结果为ok时,TM向所有RM发出DoCommit,执行事务真正的提交,TM收到所有RM的DoCommit的执行结果为ok时,释放所占用的所有资源;当有一个RM返回no或超时,导致TM没收到反馈则事务中断,TM向所有RM发出abort终止事务,各个RM收到abort后利用CanCommit阶段的Undo信息执行回滚操作,释放占用的资源;但是,如果RM没收到TM发出的abort或是超时后,则RM会继续提交事务,这将导致数据的不一致。
三阶段相比两阶段,优点有:降低阻塞范围;TM瓶颈问题得到部分解决,即在第一二阶段时,当超时的时候RM会自动释放资源,不依赖TM。但进入第三阶段后,如果超时则不会释放资源,而会继续提交事务,这种情况下,将导致数据的不一致。
4、柔性分布式事务
柔性分布式事务是相对刚性分布式事务、是对强一致性的妥协(也称补偿性事务),从而降低对数据库资源的锁定时间,提升系统的性能。柔性分布式事务适合于长事务、高并发,强调最终一致性的场合。常用的实现柔性分布式事务的方式有:TCC模型、Saga模型、基于消息队列的异步模型。
1、TCC(Try-Confirm-Cancel)模型
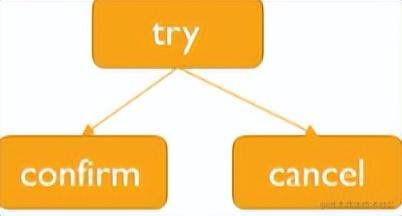
TCC是一个两阶段提交(2PC)的实现,每一个业务都需要实现Try-Confirm-Cancel三个接口
Try:准备阶段,是尝试执行业务,完成所有业务执行前的检查;
协调者调用所有的每个微服务提供的 try 接口,将整个全局事务涉及到的资源锁定住,若锁定成功 try 接口向协调者返回 yes。
Confirm:提交阶段,是真正执行业务,提交事务,释放资源;
若所有的服务的 try 接口在阶段一都返回 yes,则进入提交阶段,协调者调用所有服务的 confirm 接口,各个服务进行事务提交。
Cancel:取消阶段,业务失败的时候回滚业务操作,释放资源。
如果有任何一个服务的 try 接口在阶段一返回 no 或者超时,则协调者调用所有服务的 cancel 接口。
使用的电商微服务模型如下图所示,在这个模型中,shopping-service 是事务协调者,repo-service 和 order-service 是事务参与者。

TCC模型的实现是分为2步操作完成一次事务操作,达到最终事务的一致性。
TCC 的流程如下图所示:

这里有个关键问题,既然 TCC 是一种服务层面上的 2PC,它是如何解决 2PC 无法应对宕机问题的缺陷的呢?
答案是不断重试。由于 try 操作锁住了全局事务涉及的所有资源,保证了业务操作的所有前置条件得到满足,因此无论是 confirm 阶段失败还是 cancel 阶段失败都能通过不断重试直至 confirm 或 cancel 成功(所谓成功就是所有的服务都对 confirm 或者 cancel 返回了 ACK)。
这里还有个关键问题,在不断重试 confirm 和 cancel 的过程中(考虑到网络二将军问题的存在)有可能重复进行了 confirm 或 cancel,因此还要再保证 confirm 和 cancel 操作具有幂等性,也就是整个全局事务中,每个参与者只进行一次 confirm 或者 cancel。
实现 confirm 和 cancel 操作的幂等性,有很多解决方案,例如每个参与者可以维护一个去重表(可以利用数据库表实现也可以使用内存型 KV 组件实现),记录每个全局事务(以全局事务标记 XID 区分)是否进行过 confirm 或 cancel 操作,若已经进行过,则不再重复执行。
TCC 由支付宝团队提出,被广泛应用于金融系统中。我们用银行账户余额购买基金时,会注意到银行账户中用于购买基金的那部分余额首先会被冻结,由此我们可以猜想,也就是进入了 TCC 的第一阶段。
优点:
性能提升,具体业务来实现控制资源锁的粒度大小
数据最终一致性,基于confirm和cancel的幂等性,确保事务最终完成是提交还是取消的最终一致性
可靠性,解决了XA协议的协调者单点故障问题,有主业务发起并控制整个业务活动,业务活动管理器也变为多点,引入集群
缺点:
TCC的try,confirm和cancel操作功能要按具体业务来实现,业务耦合度较高,提高了开发成本
2、Saga模式
起源于1987年Hector Garcia-Molina和Kenneth Salem发表的论文《Sagas》,主要思想是把一个分布式事务拆分为多个本地事务,每一个本地事务都有相应的正常执行方法和异常补偿方法,当任意一个本地事务出错时,都可以通过调用相应的异常补偿方法恢复之前的事务或是继续执行未完成的事务,保证事务的最终一致性。
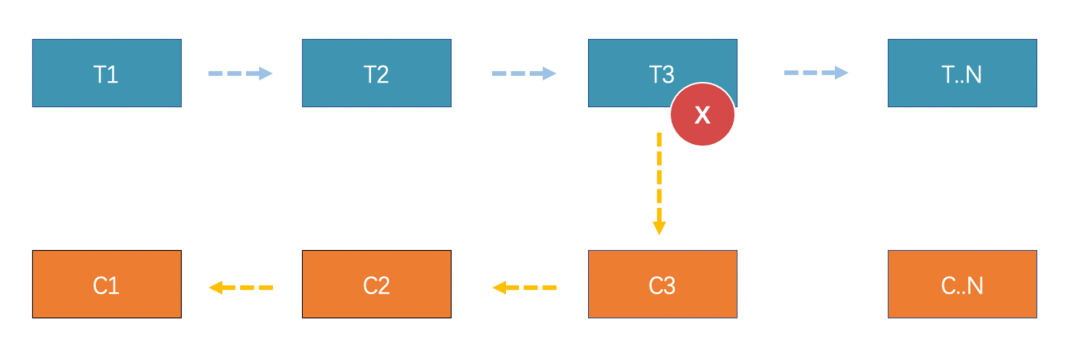
它是一种基于失败的设计,如上图可以看到,每个活动或者子事务流程,一般都会有对应的补偿服务。如果分布式事务发生异常的话,在 Saga 模式中,就要进行所谓的“恢复”,恢复有两种方式,逆向补偿和正向重试。
比如上面的分布式事务执行到 T3 失败,逆向补偿将会依次执行对应的 C3、C2、C1 操作,取消事务活动的“影响”。
那正向补偿,它是一往无前的,T3 失败了,会进行不断的重试,然后继续按照流程执行 T4、T5 等。
Saga的实现方式
有多种,流行的有基于事件的方式和基于命令的方式。
基于事件:(Event Choreography)
没有协调中心,整个模式的工作方式就像舞蹈一样,每个舞蹈者按照预先编排的动作和走位各自表演,最终形成舞蹈。处于当前Saga下的各个服务,会产生某类事件,或者监听其他服务产生的时间并决定是否针对要监听的时间做响应。
优点:
-
各参与方相互无直接沟通,完全解耦
-
适合整个分布式事务只有2-4个步骤。
缺点:
-
如果业务方较多,容易失控。
-
各个业务参与方可随意监控对方消息,最后可能没人知道到底那个系统在监听哪些消息,甚至坏环监听(两个业务相互监听对方产生的事件)
基于命令:(Order Orchestrator)
这种形式就像乐队,由一个指挥家(协调中心)来协调大家的工作。协调中心来告诉Saga的参与者应该执行哪一部分本地事务。
优点:
-
服务之间关系简单,避免服务间循环依赖
-
事务交由协调中心管理,协调中心对整个业务非常清晰
-
程序开发简单,只需要执行命令/回复(其实回复消息也是一种事件消息),降低参与者的复杂性
-
易维护扩展,在添加新步骤时,事务复杂性保持线性,回滚更容易管理,更容易实施和测试
缺点:
-
中央协调器处理逻辑容易变得庞大复杂,导致难以维护。
-
存在协调器单点故障风险。
2.2 seeta-saga状态机模式
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
Seata将为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
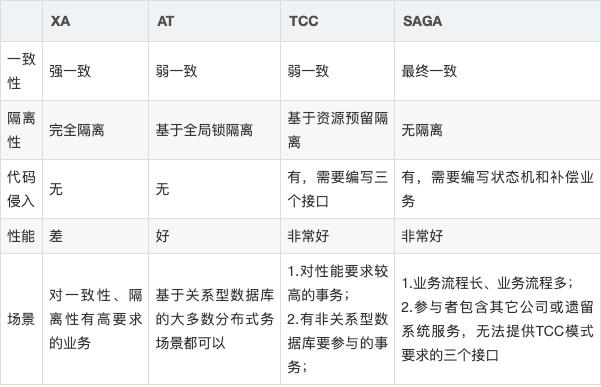
1.1 Seata的三大角色
在 Seata 的架构中,一共有三个角色:
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
Seata Saga的实现方式:
Seata Saga 的实现方式是编排式,是基于状态机引擎实现的。状态机执行的最小单位是节点:节点可以表示一个服务调用,对应 Saga 事务就是子事务活动或流程,也可以配置其补偿节点,通过链路的串联,编排出一个状态机调用流程。在 Seata 里,调用流程目前使用 JSON 描述,由状态机引擎驱动执行,当异常的时候,我们也可以选择补偿策略,由 Seata 协调者端触发事务补偿。
有没有感觉像是服务编排,区别于服务编排,Seata Saga 状态机是 Saga+服务编排,支持补偿服务,保证最终一致性。
我们来看看一个简单的状态机流程定义:
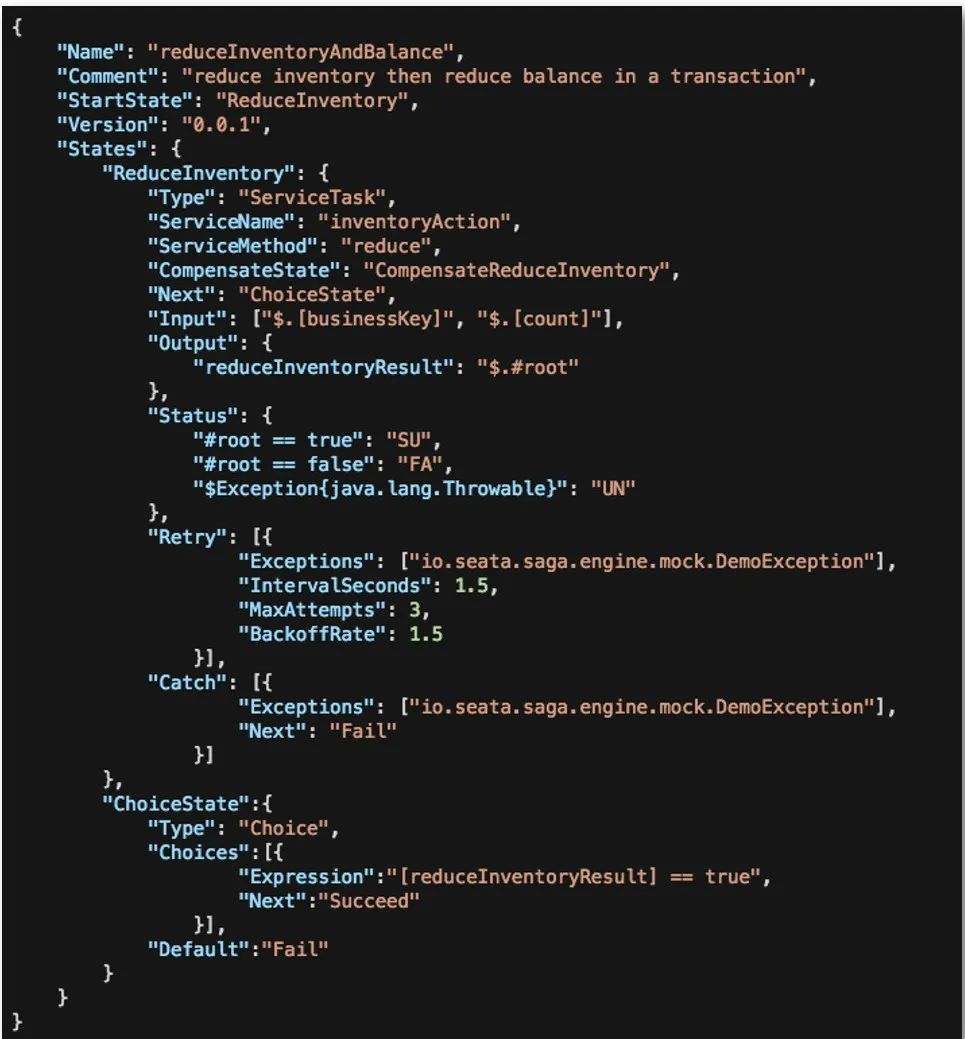
上方是一个 Name 为 reduceIncentoryAndBalance 的状态机描述,里面定了 ServiceTask 类型的服务调用节点以及对应的补偿节点 CompensateReduceInventory。
看看几个基本的属性:
Type:节点类型,Seata Saga 支持多种类型的节点。例如 ServiceTask 是服务调用节点
ServiceName/ServiceMethod:标识 ServiceTask 服务及对应方法
Input/Output:定义输入输出参数,输入输出参数取值目前使用的是 SPEL 表达式
Retry:控制重试流程
Catch/Next:用于流程控制、衔接,串联整个状态机流程
Seata -saga工作流程图:
更多类型和语法可以参考 Seata 官方文档[1],可以看到状态机 JSON 声明还是有些难度的,为了简化状态机 JSON 的编写,我们也提供了可视化的编排界面[2],如下所示,编排了一个较为复杂的流程。
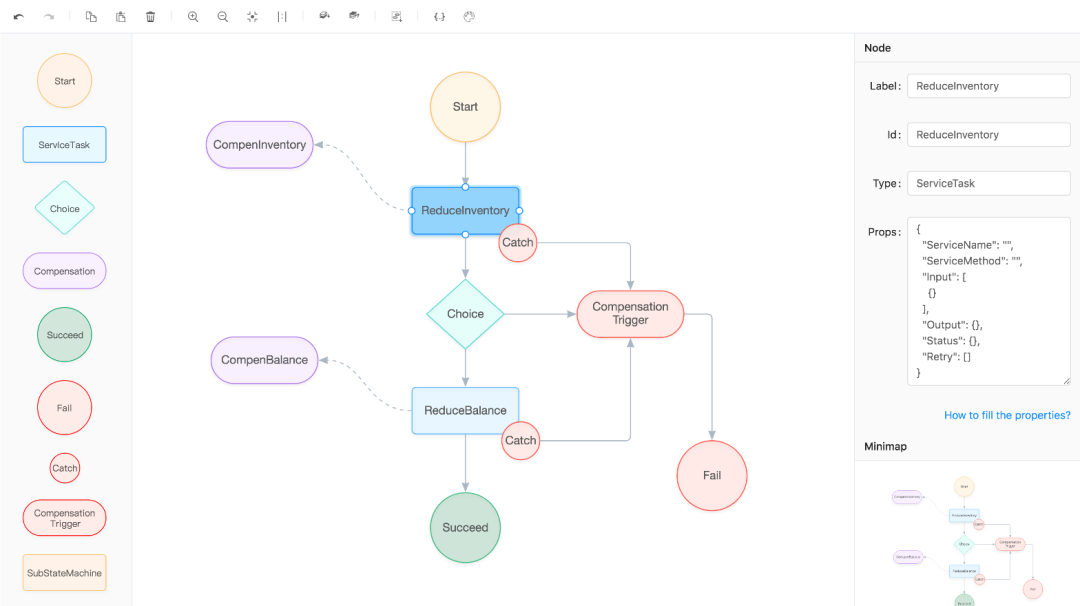
Reduce Inventory 进行扣减库存
Reduce Balance 进行扣减余额
Compensation Trigger 触发补偿机制
Compen Inventory 进行补偿库存
Compen Balance 进行补偿余额
优点:
-
Saga模式非常适合用来处理时间跨度比较长的分布式事务问题。
-
对于分布式事务参与方的完成时效性没有要求。
-
Saga模式可以在不同的阶段进行补偿操作,从而保证了数据的最终一致性。
-
Saga模式可以通过异步消息来实现,从而提高了系统的可扩展性。
缺点:
-
Saga模式需要开发人员自己实现补偿操作,这增加了开发难度。
-
Saga模式需要开发人员自己实现事务状态机,这增加了开发难度。
-
Saga模式可能会导致事务执行时间过长,从而影响系统的性能。
2.2. Seata-AT模式
Seata 的 AT 模式建立在关系型数据库的本地事务特性的基础之上,通过数据源代理类拦截并解析数据库执行的 SQL,记录自定义的回滚日志,如需回滚,则重放这些自定义的回滚日志即可。
AT 模式虽然是根据 XA 事务模型(2PC)演进而来的,但是 AT 打破了 XA 协议的阻塞性制约,在一致性和性能上取得了平衡。
AT 模式是基于 XA 事务模型演进而来的,它的整体机制也是一个改进版本的两阶段提交协议。AT 模式的两个基本阶段是:
1)第一阶段:首先获取本地锁,执行本地事务,业务数据操作和记录回滚日志在同一个本地事务中提交,最后释放本地锁;
2)第二阶段:如需全局提交,异步删除回滚日志即可,这个过程很快就能完成。如需要回滚,则通过第一阶段的回滚日志进行反向补偿。
Seata in AT mode 的工作原理使用的电商微服务模型如下图所示:

在上图中,协调者 shopping-service 先调用参与者 repo-service 扣减库存,后调用参与者 order-service 生成订单。这个业务流使用 Seata in XA mode 后的全局事务流程如下图所示:

上图描述的全局事务执行流程为:
1)shopping-service 向 Seata 注册全局事务,并产生一个全局事务标识 XID
2)将 repo-service.repo_db、order-service.order_db 的本地事务执行到待提交阶段,事务内容包含对 repo-service.repo_db、order-service.order_db 进行的查询操作以及写每个库的 undo_log 记录
3)repo-service.repo_db、order-service.order_db 向 Seata 注册分支事务,并将其纳入该 XID 对应的全局事务范围
4)提交 repo-service.repo_db、order-service.order_db 的本地事务
5)repo-service.repo_db、order-service.order_db 向 Seata 汇报分支事务的提交状态
6)Seata 汇总所有的 DB 的分支事务的提交状态,决定全局事务是该提交还是回滚
7)Seata 通知 repo-service.repo_db、order-service.order_db 提交/回滚本地事务,若需要回滚,采取的是补偿式方法
其中 1)2)3)4)5)属于第一阶段,6)7)属于第二阶段。
2.2. Seata in AT mode 工作流程详述
在上面的电商业务场景中,购物服务调用库存服务扣减库存,调用订单服务创建订单,显然这两个调用过程要放在一个事务里面。即:
start global_trx call 库存服务的扣减库存接口 call 订单服务的创建订单接口 commit global_trx
在库存服务的数据库中,存在如下的库存表 t_repo:
| id | production_code | name | count | price |
|---|---|---|---|---|
| 10001 | 20001 | xx 键盘 | 98 | 200.0 |
| 10002 | 20002 | yy 鼠标 | 199 | 100.0 |
在订单服务的数据库中,存在如下的订单表 t_order:
| id | order_code | user_id | production_code | count | price |
|---|---|---|---|---|---|
| 30001 | 2020102500001 | 40001 | 20002 | 1 | 100.0 |
| 30002 | 2020102500001 | 40001 | 20001 | 2 | 400.0 |
现在,id 为 40002 的用户要购买一只商品代码为 20002 的鼠标,整个分布式事务的内容为:
1)在库存服务的库存表中将记录
| id | production_code | name | count | price |
|---|---|---|---|---|
| 10002 | 20002 | yy 鼠标 | 199 | 100.0 |
修改为
| id | production_code | name | count | price |
|---|---|---|---|---|
| 10002 | 20002 | yy 鼠标 | 198 | 100.0 |
2)在订单服务的订单表中添加一条记录
| id | order_code | user_id | production_code | count | price |
|---|---|---|---|---|---|
| 30003 | 2020102500002 | 40002 | 20002 | 1 | 100.0 |
以上操作,在 AT 模式的第一阶段的流程图如下:

从 AT 模式第一阶段的流程来看,分支的本地事务在第一阶段提交完成之后,就会释放掉本地事务锁定的本地记录。这是 AT 模式和 XA 最大的不同点,在 XA 事务的两阶段提交中,被锁定的记录直到第二阶段结束才会被释放。所以 AT 模式减少了锁记录的时间,从而提高了分布式事务的处理效率。AT 模式之所以能够实现第一阶段完成就释放被锁定的记录,是因为 Seata 在每个服务的数据库中维护了一张 undo_log 表,其中记录了对 t_order / t_repo 进行操作前后记录的镜像数据,即便第二阶段发生异常,只需回放每个服务的 undo_log 中的相应记录即可实现全局回滚。
undo_log 的表结构:
| id | branch_id | xid | context | rollback_info | log_status | log_created | log_modified |
|---|---|---|---|---|---|---|---|
| …… | 分支事务 ID | 全局事务 ID | …… | 分支事务操作的记录在事务前后的记录镜像,即 beforeImage 和 afterImage | …… | …… | …… |
第一阶段结束之后,Seata 会接收到所有分支事务的提交状态,然后决定是提交全局事务还是回滚全局事务。
1)若所有分支事务本地提交均成功,则 Seata 决定全局提交。Seata 将分支提交的消息发送给各个分支事务,各个分支事务收到分支提交消息后,会将消息放入一个缓冲队列,然后直接向 Seata 返回提交成功。之后,每个本地事务会慢慢处理分支提交消息,处理的方式为:删除相应分支事务的 undo_log 记录。之所以只需删除分支事务的 undo_log 记录,而不需要再做其他提交操作,是因为提交操作已经在第一阶段完成了(这也是 AT 和 XA 不同的地方)。这个过程如下图所示:

分支事务之所以能够直接返回成功给 Seata,是因为真正关键的提交操作在第一阶段已经完成了,清除 undo_log 日志只是收尾工作,即便清除失败了,也对整个分布式事务不产生实质影响。
2)若任一分支事务本地提交失败,则 Seata 决定全局回滚,将分支事务回滚消息发送给各个分支事务,由于在第一阶段各个服务的数据库上记录了 undo_log 记录,分支事务回滚操作只需根据 undo_log 记录进行补偿即可。全局事务的回滚流程如下图所示:

这里对图中的 2、3 步做进一步的说明:
1)由于上文给出了 undo_log 的表结构,所以可以通过 xid 和 branch_id 来找到当前分支事务的所有 undo_log 记录;
2)拿到当前分支事务的 undo_log 记录之后,首先要做数据校验,如果 afterImage 中的记录与当前的表记录不一致,说明从第一阶段完成到此刻期间,有别的事务修改了这些记录,这会导致分支事务无法回滚,向 Seata 反馈回滚失败;如果 afterImage 中的记录与当前的表记录一致,说明从第一阶段完成到此刻期间,没有别的事务修改这些记录,分支事务可回滚,进而根据 beforeImage 和 afterImage 计算出补偿 SQL,执行补偿 SQL 进行回滚,然后删除相应 undo_log,向 Seata 反馈回滚成功。
事务具有 ACID 特性,全局事务解决方案也在尽量实现这四个特性。以上关于 Seata in AT mode 的描述很显然体现出了 AT 的原子性、一致性和持久性。下面着重描述一下 AT 如何保证多个全局事务的隔离性的。
在 AT 中,当多个全局事务操作同一张表时,通过全局锁来保证事务的隔离性。下面描述一下全局锁在读隔离和写隔离两个场景中的作用原理:
1)写隔离(若有全局事务在改/写/删记录,另一个全局事务对同一记录进行的改/写/删要被隔离起来,即写写互斥):写隔离是为了在多个全局事务对同一张表的同一个字段进行更新操作时,避免一个全局事务在没有被提交成功之前所涉及的数据被其他全局事务修改。写隔离的基本原理是:在第一阶段本地事务(开启本地事务的时候,本地事务会对涉及到的记录加本地锁)提交之前,确保拿到全局锁。如果拿不到全局锁,就不能提交本地事务,并且不断尝试获取全局锁,直至超出重试次数,放弃获取全局锁,回滚本地事务,释放本地事务对记录加的本地锁。
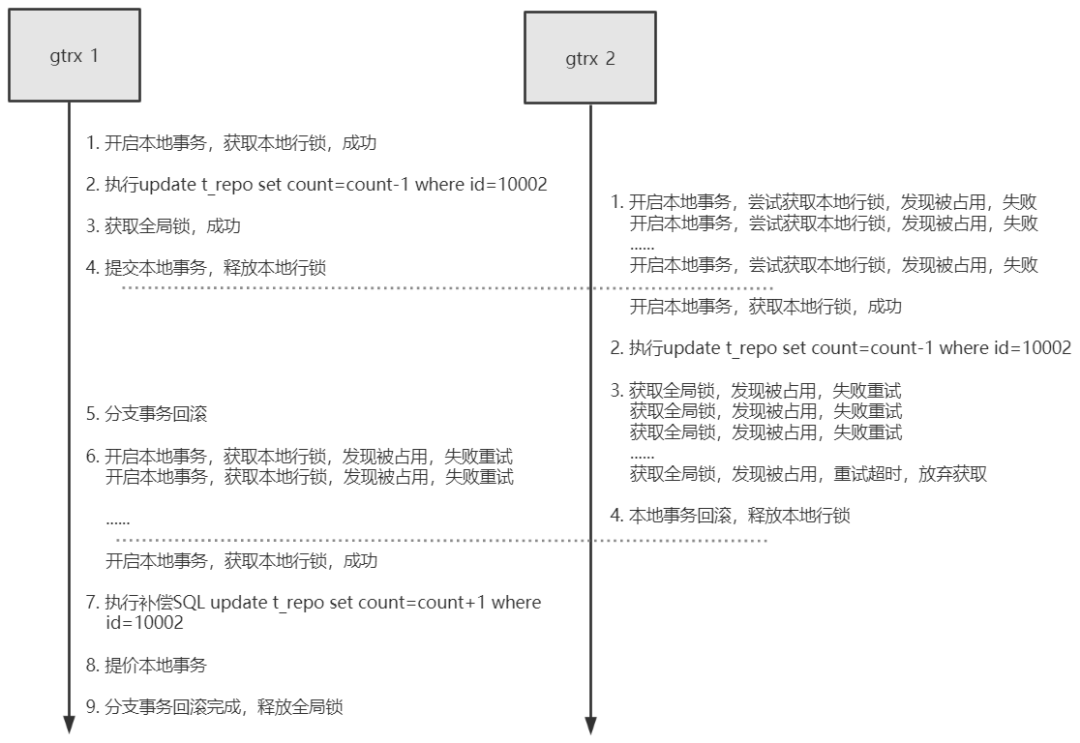
假设有两个全局事务 gtrx_1 和 gtrx_2 在并发操作库存服务,意图扣减如下记录的库存数量:
AT 实现写隔离过程的时序图如下:

图中,1、2、3、4 属于第一阶段,5 属于第二阶段。
在上图中 gtrx_1 和 gtrx_2 均成功提交,如果 gtrx_1 在第二阶段执行回滚操作,那么 gtrx_1 需要重新发起本地事务获取本地锁,然后根据 undo_log 对这个 id=10002 的记录进行补偿式回滚。此时 gtrx_2 仍在等待全局锁,且持有这个 id=10002 的记录的本地锁,因此 gtrx_1 会回滚失败(gtrx_1 回滚需要同时持有全局锁和对 id=10002 的记录加的本地锁),回滚失败的 gtrx_1 会一直重试回滚。直到旁边的 gtrx_2 获取全局锁的尝试次数超过阈值,gtrx_2 会放弃获取全局锁,发起本地回滚,本地回滚结束后,自然会释放掉对这个 id=10002 的记录加的本地锁。此时,gtrx_1 终于可以成功对这个 id=10002 的记录加上了本地锁,同时拿到了本地锁和全局锁的 gtrx_1 就可以成功回滚了。整个过程,全局锁始终在 gtrx_1 手中,并不会发生脏写的问题。整个过程的流程图如下所示:
2)读隔离(若有全局事务在改/写/删记录,另一个全局事务对同一记录的读取要被隔离起来,即读写互斥):在数据库本地事务的隔离级别为读已提交、可重复读、串行化时(读未提交不起什么隔离作用,一般不使用),Seata AT 全局事务模型产生的隔离级别是读未提交,也就是说一个全局事务会看到另一个全局事务未全局提交的数据,产生脏读,从前文的第一阶段和第二阶段的流程图中也可以看出这一点。这在最终一致性的分布式事务模型中是可以接受的。
如果要求 AT 模型一定要实现读已提交的事务隔离级别,可以利用 Seata 的 SelectForUpdateExecutor 执行器对 SELECT FOR UPDATE 语句进行代理。SELECT FOR UPDATE 语句在执行时会申请全局锁,如果全局锁已经被其他全局事务占有,则回滚 SELECT FOR UPDATE 语句的执行,释放本地锁,并且重试 SELECT FOR UPDATE 语句。在这个过程中,查询请求会被阻塞,直到拿到全局锁(也就是要读取的记录被其他全局事务提交),读到已被全局事务提交的数据才返回。这个过程如下图所示:

3、基于消息队列的异步模型
无论是 2PC & 3PC 还是 TCC、事务状态表,基本都遵守 XA 协议的思想,即这些方案本质上都是事务协调者协调各个事务参与者的本地事务的进度,使所有本地事务共同提交或回滚,最终达成一种全局的 ACID 特性。在协调的过程中,协调者需要收集各个本地事务的当前状态,并根据这些状态发出下一阶段的操作指令。
但是这些全局事务方案由于操作繁琐、时间跨度大,或者在全局事务期间会排他地锁住相关资源,使得整个分布式系统的全局事务的并发度不会太高。这很难满足电商等高并发场景对事务吞吐量的要求,因此互联网服务提供商探索出了很多与 XA 协议背道而驰的分布式事务解决方案。
其中利用消息中间件实现的最终一致性全局事务就是一个经典方案。
为了表现出这种方案的精髓,我将使用如下的电商系统微服务结构来进行描述:

在这个模型中,用户不再是请求整合后的 shopping-service 进行下单,而是直接请求 order-service 下单,order-service 一方面添加订单记录,另一方面会调用 repo-service 扣减库存。
这种基于消息中间件的最终一致性事务方案实现方式:
如下所示:

完整业务流程图:
当用户下单操作业务开始,订单服务先插入订单表,并记录事件表,定时任务会读取未发送的事件(0未发送,1已发送)发到消息队列并将事件状态改为1.
库存服务监听程序会消费消息队列中的消息,并根据事件记录事件表,并返回消息队列ACK确认。库存服务中同样有一个定时任务读取事件,并将未处理(0未处理,1已处理)的做响应的扣减库存操作。
上图所示的方案,利用消息中间件如 rabbitMQ 来实现分布式下单及库存扣减过程的最终一致性。对这幅图做以下说明:
1)order-service 中,
在 t_order 表添加订单记录 && 在 t_local_msg 添加对应的扣减库存消息
这两个过程要在一个事务中完成,保证过程的原子性。同样,repo-service 中,
检查本次扣库存操作是否已经执行过 && 执行扣减库存如果本次扣减操作没有执行过 && 写判重表 && 向 MQ sever 反馈消息消费完成 ACK
这四个过程也要在一个事务中完成,保证过程的原子性。
2)order-service 中有一个后台程序,源源不断地把消息表中的消息传送给消息中间件,成功后则删除消息表中对应的消息。如果失败了,也会不断尝试重传。由于存在网络 2 将军问题,即当 order-service 发送给消息中间件的消息网络超时时,这时候消息中间件可能收到了消息但响应 ACK 失败,也可能没收到,order-service 会再次发送该消息,直至消息中间件响应 ACK 成功,这样可能发生消息的重复发送,不过没关系,只要保证消息不丢失,不乱序就行,后面 repo-service 会做去重处理。
3)消息中间件向 repo-service 推送 repo_deduction_msg,repo-service 成功处理完成后会向中间件响应 ACK,消息中间件收到这个 ACK 才认为 repo-service 成功处理了这条消息,否则会重复推送该消息。但是有这样的情形:repo-service 成功处理了消息,向中间件发送的 ACK 在网络传输中由于网络故障丢失了,导致中间件没有收到 ACK 重新推送了该消息。这也要靠 repo-service 的消息去重特性来避免消息重复消费。
4)在 2)和 3)中提到了两种导致 repo-service 重复收到消息的原因,一是生产者重复生产,二是中间件重传。为了实现业务的幂等性,repo-service 中维护了一张判重表,这张表中记录了被成功处理的消息的 id。repo-service 每次接收到新的消息都先判断消息是否被成功处理过,若是的话不再重复处理。
通过这种设计,实现了消息在发送方不丢失,消息在接收方不被重复消费,联合起来就是消息不漏不重,严格实现了 order-service 和 repo-service 的两个数据库中数据的最终一致性。
优点:
基于消息中间件的最终一致性全局事务方案是互联网公司在高并发场景中探索出的一种创新型应用模式,利用 MQ 实现微服务之间的异步调用、解耦合和流量削峰,支持全局事务的高并发,并保证分布式数据记录的最终一致性。降低用户的响应时间,提高系统的吞吐量。
缺点:
系统不能做到强一致,会有短暂不一致。
归纳总结:
XA 协议是 X/Open 提出的分布式事务处理标准。文中提到的 2PC、3PC、TCC、本地事务表、Seata in AT mode,无论哪一种,本质都是事务协调者协调各个事务参与者的本地事务的进度,使使所有本地事务共同提交或回滚,最终达成一种全局的 ACID 特性。在协调的过程中,协调者需要收集各个本地事务的当前状态,并根据这些状态发出下一阶段的操作指令。这个思想就是 XA 协议的要义,我们可以说这些事务模型遵守或大致遵守了 XA 协议。
基于消息中间件的最终一致性事务方案是互联网公司在高并发场景中探索出的一种创新型应用模式,利用 MQ 实现微服务之间的异步调用、解耦合和流量削峰,保证分布式数据记录的最终一致性。它显然不遵守 XA 协议。
对于某项技术,可能存在业界标准或协议,但实践者针对具体应用场景的需求或者出于简便的考虑,给出与标准不完全相符的实现,甚至完全不相符的实现,这在工程领域是一种常见的现象。TCC 方案如此、基于消息中间件的最终一致性事务方案如此、Seata in AT mode 模式也如此。而新的标准往往就在这些创新中产生。
二:分布式幂等性如何设计
1. 什么是幂等性?
幂等性是指在分布式系统中,一个操作多次执行的结果与其执行一次的结果相同。设计具有幂等性的分布式系统可以有效避免数据不一致和重复处理的问题。
幂等系统的应用场景
在微服务架构下,由于分布式天然特性的时序问题, 以及网络的不可靠性(机器、机架、机房故障, 电缆被挖断等等), 重复请求很常见, 接口幂等性设计就显得尤为重要。 比如浏览器/客户端多次提交、微服务间超时重试、消息重复消费等。 以订单流程为例的幂等性场景:
1.一个订单创建接口,第一次调用超时了,然后调用方重试了一次 2.在订单创建时,我们需要去扣减库存,这时接口发生了超时,调用方重试了一次 3.当这笔订单开始支付,在支付请求发出之后,在服务端发生了扣钱操作,接口响应超时了,调用方重试了一次 4.一个订单状态更新接口,调用方连续发送了两个消息,一个是已创建,一个是已付款。但是你先接收到已付款,然后又接收到了已创建 5.在支付完成订单之后,需要发送一条短信,当一台机器接收到短信发送的消息之后,处理较慢。消息中间件又把消息投递给另外一台机器处理
为了解决以上问题,就需要保证接口的幂等性,接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的。有些接口可以天然的实现幂等性,比如查询接口,对于查询来说,你查询一次和两次,对于系统来说,没有任何影响,查出的结果也是一样。除了查询功能具有天然的幂等性之外,增加、更新、删除都要保证幂等性。
2. 分布式幂等性设计方法
2.1 利用数据库实现幂等性
数据库的唯一约束和事务特性可以用来实现幂等性。例如,在处理支付请求时,我们可以在支付记录表中插入一条带有唯一支付 ID 的记录。如果数据库已存在相同支付 ID 的记录,则认为该支付请求已处理过,从而实现幂等性。
1、去重表(唯一索引)
往数据库去重表里插入数据的时候,利用数据库的唯一索引特性,保证唯一的逻辑。唯一序列号可以是一个字段,例如订单的订单号,也可以是多字段的唯一性组合。
使用数据库防重表的方式它有个严重的缺点,那就是系统容错性不高,如果幂等表所在的数据库连接异常或所在的服务器异常,则会导致整个系统幂等性校验出问题。
2、多版本号控制之乐观锁
多版本并发控制,该策略主要使用update with condition(更新带条件来防止)来保证多次外部请求调用对系统的影响是一致的。在系统设计的过程中,合理的使用乐观锁,通过version或者updateTime(timestamp)等其他条件,来做乐观锁的判断条件,这样保证更新操作即使在并发的情况下,也不会有太大的问题。借鉴数据库的乐观锁机制。
示例:
update t_goods set count = count -1 , version = version + 1 where good_id=2 and version = 1
根据version版本,也就是在操作库存前先获取当前商品的version版本号,然后操作的时候带上此version号。我们梳理下,我们第一次操作库存时,得到version为1,调用库存服务version变成了2;但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传如的version还是1,再执行上面的sql语句时,就不会执行;因为version已经变为2了,where条件就不成立。这样就保证了不管调用几次,只会真正的处理一次。
3、悲观锁
使用悲观锁实现幂等性,一般是配合事务一起来实现。
使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住。for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
select for update,整个执行过程中锁定该订单对应的记录。注意:这种在DB读大于写的情况下尽量少用。
举个更新订单的业务场景:
假设先查出订单,如果查到的是处理中状态,就处理完业务,再然后更新订单状态为完成。如果查到订单,并且是不是处理中的状态,则直接返回
4、全局唯一ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、Redis等。如果存在则表示该方法已经执行。使用全局唯一ID是一个通用方案,可以支持插入、更新、删除业务操作。
结合redis的incr自增实现全局唯一ID,是一个常用的方案。
示例代码:
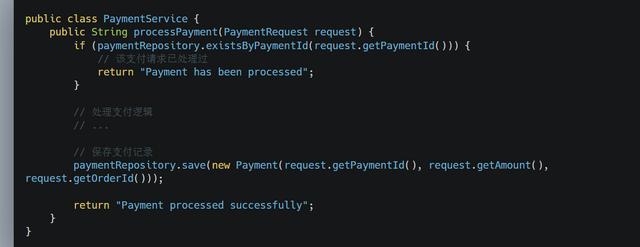
#####
2.2 使用分布式事务实现幂等性
在涉及多个服务和数据源的场景下,可以使用分布式事务来实现幂等性。例如,使用两阶段提交(2PC)或者三阶段提交(3PC)协议来保证多个服务间的数据一致性。
示例代码:
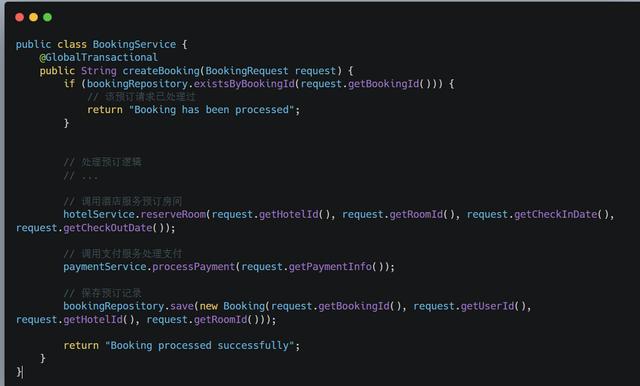
在这个示例中,我们使用 @GlobalTransactional 注解来标记需要分布式事务支持的方法。在处理预订请求时,系统首先检查预订记录是否已存在,然后依次调用酒店服务和支付服务。如果其中任何一个服务出现异常,分布式事务将回滚,确保数据的一致性和幂等性。
2.3、token机制
token机制的幂等保障的主要流程就是:
1.服务端提供了发送token的接口。我们在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存2.到redis中。(微服务肯定是分布式了,如果单机就适用jvm缓存)。 3.然后调用业务接口请求时,把token携带过去,一般放在请求头部。 4.服务器判断token是否存在redis中,存在表示第一次请求,这时把redis中的token删除,继续执行业务。 5.如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行。
缺点:
业务请求每次请求,都会有额外的请求(一次获取token请求、判断token是否存在的业务)。其实真实的生产环境中,1万请求也许只会存在10个左右的请求会发生重试,为了这10个请求,我们让9990个请求都发生了额外的请求。(当然redis性能很好,耗时不会太明显)
2.4,分布式锁
分布式锁可以确保同一时间只有一个线程处理特定的操作。我们可以在处理关键业务逻辑之前获取分布式锁,从而保证幂等性。
示例代码:
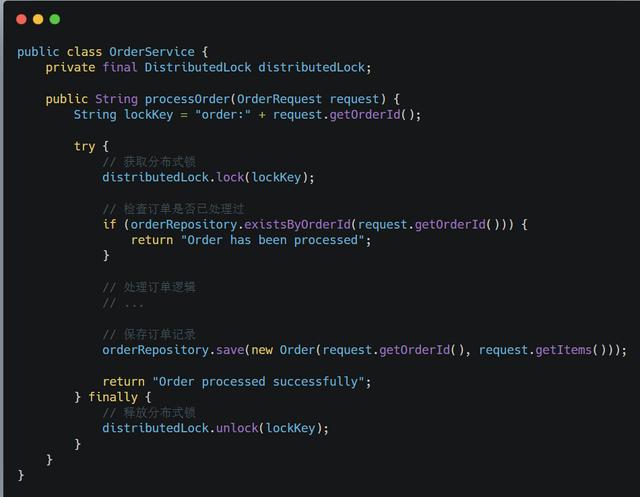
#####
分布式锁实现幂等性的逻辑是,在每次执行方法之前判断,是否可以获取到分布式锁,如果可以,则表示为第一次执行方法,否则直接舍弃请求即可。需要注意的是分布式锁的key必须为业务的唯一标识,通常适用redis或者zookeeper来实现分布式锁
如果是分布是系统,构建唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统,在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路;
目前主要有几种方式实现分布式锁:
1、redis setNx命令
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
优点:
(1)Redis有很高的性能; (2)Redis命令对此支持较好,实现起来比较方便
2,基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock; (2)线程A想获取锁就在mylock目录下创建临时顺序节点; (3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁; (4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点; (5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
3, 状态机
在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机,就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,这时候,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。
很多业务表,都是有状态的,比如转账流水表,就会有0-待处理,1-处理中、2-成功、3-失败状态。转账流水更新的时候,都会涉及流水状态更新,即涉及状态机 (即状态变更图)。
状态机是怎么实现幂等的呢?
第1次请求来时,如流水号是 666,该流水的状态是处理中,值是 1,要更新为2-成功的状态,所以该update语句可以正常更新数据,sql执行结果的影响行数是1,流水状态最后变成了2。 第2请求也过来了,如果它的流水号还是 666,因为该流水状态已经2-成功的状态了,所以不会再处理业务逻辑,接口直接返回。 示例: 对于不少业务是有一个业务流转状态的,每一个状态都有前置状态和后置状态,以及最后的结束状态。例如流程的待审批,审批中,驳回,从新发起,审批经过,审批拒绝。订单的待提交,待支付,已支付,取消。
3.幂等性设计的注意事项
在实现分布式幂等性时,需要考虑以下几点:
-
幂等性操作的粒度:根据业务场景和性能要求,可以选择适当的幂等性设计粒度,如方法级、服务级或全局级。
-
幂等性与性能的权衡:实现幂等性可能会增加系统的复杂性和性能开销。在设计时,需要考虑这些因素并选择合适的实现策略。
-
幂等性与可用性的关系:某些幂等性实现方法可能会影响系统的可用性,如分布式锁。在设计时,需要充分了解各种方法的优缺点,选择合适的方案。
三:分布式ID
必要性
业务量小于500W或数据容量小于2G的时候单独一个mysql即可提供服务,再大点的时候就进行读写分离也可以应付过来。但当主从同步也扛不住的是就需要分表分库了,但[分库分表]后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;
特别一点的如订单、[优惠券]也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
分布式ID需满足那些条件
-
全局唯一:基本要求就是必须保证ID是全局性唯一的。
-
高性能:高可用低延时,ID生成响应要快。
-
高可用:无限接近于100%的可用性
-
好接入:遵循拿来主义原则,在系统设计和实现上要尽可能的简单
-
趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
1. UUID
UUID 是指Universally Unique Identifier,翻译为中文是通用唯一识别码,UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息。形式为 8-4-4-4-12,总共有 36个字符。用起来非常简单
import java.util.UUID; public static void main(String[] args) { String uuid = UUID.randomUUID().toString().replaceAll("-",""); System.out.println(uuid); }
输出结果 99a7d0925b294a53b2f4db9d5a3fb798,但UUID却并不适用于实际的业务需求。订单号用UUID这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;而对于数据库来说用作业务主键ID,它不仅是太长还是字符串,存储性能差查询也很耗时,所以不推荐用作分布式ID。
优点:生成足够简单,本地生成无网络消耗,具有唯一性
缺点:无序的字符串,不具备趋势自增特性,没有具体的业务含义。如此长的字符串当MySQL主键并非明智选择。
2. 基于数据库自增ID
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
CREATE DATABASE `SoWhat_ID`;CREATE TABLE SoWhat_ID.SEQUENCE_ID (
`id` bigint(20) unsigned NOT NULL auto_increment,
`value` char(10) NOT NULL default '',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (id),) ENGINE=MyISAM;insert into SEQUENCE_ID(value) VALUES ('values');
当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点:实现简单,ID单调自增,数值类型查询速度快
缺点:DB单点存在宕机风险,无法扛住高并发场景
3. 基于数据库集群模式
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?解决方案:设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、3、5、7、9 2、4、6、8、10
但是如果两个还是无法满足咋办呢?增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:解决DB单点问题
缺点:不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
4. 基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator ( `id` int(10) NOT NULL, `max_id` bigint(20) NOT NULL COMMENT '当前最大id', `step` int(20) NOT NULL COMMENT '号段的步长', `biz_type` int(20) NOT NULL COMMENT '业务类型', `version` int(20) NOT NULL COMMENT '版本号', PRIMARY KEY (`id`))
-
max_id :当前最大的可用id
-
step :代表号段的长度
-
biz_type :代表不同业务类型
-
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
| id | biz_type | max_id | step | version |
|---|---|---|---|---|
| 1 | 101 | 1000 | 2000 | 0 |
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = {max_id+step}, version = version + 1 where version = {version} and biz_type = XX
由于多业务端可能同时操作,所以采用版本号 version 乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。但是如果遇到了双十一或者秒杀类似的活动还是会对数据库有比较高的访问。
5. 基于Redis模式
Redis 也同样可以实现,原理就是Redis 是单线程的,因此我们可以利用redis的incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1OK127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值(integer) 2
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF。
6. 基于雪花算法(Snowflake)模式
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,为什么叫雪花算法呢?私以为众所周知世界上没有一对相同的雪花。雪花算法基本上保持自增的,后面的代码中有详细的注解。
| 1bit | 41bit | 5bit | 5bit 12 bit | |
|---|---|---|---|---|
| 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 11001 0000 00000000 |
这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。举例如上图:
-
第一个部分是 1 个 bit:0, 这个是无意义的。因为二进制里第一个 bit 位如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
-
第二个部分是 41 个 bit:表示的是时间戳。单位是毫秒。41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
-
第三个部分是 5 个 bit:表示的是机房 id 5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房)
-
第四个部分是 5 个 bit:表示的是机器 id。每个机房里可以代表 2 ^ 5 个机器(32 台机器),也可以根据自己公司的实际情况确定。
-
第五个部分是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号。12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
总结:简单来说,你的某个服务假设要生成一个全局唯一 id,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 id。
这个 SnowFlake 算法系统首先肯定是知道自己所在的机房和机器的,比如机房 id = 17,机器 id = 12。
接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 id,64 个 bit 中的第一个 bit 是无意义的。
接着 41 个 bit,就可以用当前时间戳(单位到毫秒),然后接着 5 个 bit 设置上这个机房 id,还有 5 个 bit 设置上机器 id。
最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 id 的请求累加一个序号,作为最后的 12 个 bit。最终一个 64 个 bit 的 id 就出来了,类似于:
| 1bit | 41bit | 5bit | 5bit 12 bit | |
|---|---|---|---|---|
| 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 11001 0000 00000000 |
这个算法可以保证一个机房的一台机器在同一毫秒内,生成了一个唯一的 id。可能一个毫秒内会生成多个 id,但是有最后 12 个 bit 的序号来区分开来。
总结:就是用一个 64 bit 的数字中各个 bit 位来设置不同的标志位,区分每一个 id。
SnowFlake 算法的实现代码如下:
/** * 雪花算法相对来说如果思绪捋顺了实现起来比较简单,前提熟悉位运算。 */
public class SnowFlake{
/** * 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** * 机器id所占的位数 */
private final long workerIdBits = 5L;
/** * 数据标识id所占的位数 */
private final long dataCenterIdBits = 5L;
/** * 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = ~(-1L << workerIdBits); /** * 支持的最大机房标识id,结果是31 */
private final long maxDataCenterId = ~(-1L << dataCenterIdBits); /** * 序列在id中占的位数 */
private final long sequenceBits = 12L; /** * 机器ID向左移12位 */
private final long workerIdShift = sequenceBits; /** * 机房标识id向左移17位(12+5) */
private final long dataCenterIdShift = sequenceBits + workerIdBits; /** * 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
/** * 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = ~(-1L << sequenceBits); /** * 工作机器ID(0~31) */
private volatile long workerId; /** * 机房中心ID(0~31) */
private volatile long dataCenterId; /** * 毫秒内序列(0~4095) */
private volatile long sequence = 0L; /** * 上次生成ID的时间截 */
private volatile long lastTimestamp = -1L; //==============================Constructors=====================================
/** * 构造函数 * * @param workerId 工作ID (0~31) * @param dataCenterId 机房中心ID (0~31) */
public SnowFlake(long workerId, long dataCenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException(String.format("dataCenter Id can't be greater than %d or less than 0", maxDataCenterId)); }
this.workerId = workerId; this.dataCenterId = dataCenterId;
} // ==============================Methods==========================================
/** * 获得下一个ID (该方法是线程安全的) * 如果一个线程反复获取Synchronized锁,那么synchronized锁将变成偏向锁。 * * @return SnowflakeId */
public synchronized long nextId() throws RuntimeException { long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException((String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp))); }
//如果是毫秒级别内是同一时间生成的,则进行毫秒内序列生成
if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出,一毫秒内超过了4095个
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp); } } else {
//时间戳改变,毫秒内序列重置
sequence = 0L; }
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) | (dataCenterId << dataCenterIdShift) | (workerId << workerIdShift) | sequence; }
/** * 阻塞到下一个毫秒,直到获得新的时间戳 * @param lastTimestamp 上次生成ID的时间截 * @return 当前时间戳 */
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen(); while (timestamp <= lastTimestamp) {
timestamp = timeGen(); } return timestamp; }
/** * 返回以毫秒为单位的当前时间 * @return 当前时间(毫秒) */
private long timeGen() { return System.currentTimeMillis(); }
}
SnowFlake算法的优点:
-
高性能高可用:生成时不依赖于数据库,完全在内存中生成。
-
容量大:每秒中能生成数百万的自增ID。
-
ID自增:存入数据库中,索引效率高。
SnowFlake算法的缺点:
-
依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。
-
在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况 (此缺点可以认为无所谓,一般分布式ID只要求趋势递增,不会严格要求递增,90%的需求都只要求趋势递增)
实际中我们的机房并没有那么多,我们可以改进改算法,将10bit的机器id优化成业务表或者和我们系统相关的业务。
7. 百度uid-generator
项目GitHub地址:https://github.com/baidu/uid-generator,uid-generator是由百度技术部开发,基于Snowflake算法实现的,与原始的snowflake算法不同在于,uid-generator支持自定义时间戳、工作机器ID和 序列号等各部分的位数,而且uid-generator中采用用户自定义workId的生成策略。
uid-generator需要与数据库配合使用,需要新增一个WORKER_NODE表。当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的workId数据由host,port组成。
由上图可知,UidGenerator的时间部分只有28位,这就意味着UidGenerator默认只能承受8.5年(2^28-1/86400/365)。当然,根据你业务的需求,UidGenerator可以适当调整delta seconds、worker node id和sequence占用位数。
接下来分析百度UidGenerator的实现。需要说明的是UidGenerator有两种方式提供:和DefaultUidGenerator和CachedUidGenerator。我们先分析比较容易理解的DefaultUidGenerator。
DefaultUidGenerator
delta seconds这个值是指当前时间与epoch时间的时间差,且单位为秒。epoch时间就是指集成UidGenerator生成分布式ID服务第一次上线的时间,可配置,也一定要根据你的上线时间进行配置,因为默认的epoch时间可是2016-09-20,不配置的话,会浪费好几年的可用时间。
worker id接下来说一下UidGenerator是如何给worker id赋值的,搭建UidGenerator的话,需要创建一个表:
UidGenerator会在集成用它生成分布式ID的实例启动的时候,往这个表中插入一行数据,得到的id值就是准备赋给workerId的值。由于workerId默认22位,那么,集成UidGenerator生成分布式ID的所有实例重启次数是不允许超过4194303次(即2^22-1),否则会抛出异常。
这段逻辑的核心代码来自DisposableWorkerIdAssigner.java中,当然,你也可以实现WorkerIdAssigner.java接口,自定义生成workerId。sequence核心代码如下,几个实现的关键点:
-
synchronized保证线程安全。
-
如果时间有任何的回拨,那么直接抛出异常。
-
如果当前时间和上一次是同一秒时间,那么sequence自增。如果同一秒内自增值超过2^13-1,那么就-- 会自旋等待下一秒(getNextSecond)。
-
如果是新的一秒,那么sequence重新从0开始。
/** * Get UID * * @return UID * @throws UidGenerateException in the case: Clock moved backwards; Exceeds the max timestamp */ protected synchronized long nextId() { long currentSecond = getCurrentSecond(); // Clock moved backwards, refuse to generate uid if (currentSecond < lastSecond) { long refusedSeconds = lastSecond - currentSecond; throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds); } // At the same second, increase sequence if (currentSecond == lastSecond) { sequence = (sequence + 1) & bitsAllocator.getMaxSequence(); // Exceed the max sequence, we wait the next second to generate uid if (sequence == 0) { currentSecond = getNextSecond(lastSecond); } // At the different second, sequence restart from zero } else { sequence = 0L; } lastSecond = currentSecond; // Allocate bits for UID return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence); }
总结通过DefaultUidGenerator的实现可知,它对时钟回拨的处理比较简单粗暴。另外如果使用UidGenerator的DefaultUidGenerator方式生成分布式ID,一定要根据你的业务的情况和特点,调整各个字段占用的位数:
<property name="timeBits" value="28"/><property name="workerBits" value="22"/><property name="seqBits" value="13"/><property name="epochStr" value="2016-09-20"/>
CachedUidGenerator
CachedUidGenerator是UidGenerator的重要改进实现。它的核心利用了RingBuffer,如下图所示,它本质上是一个数组,数组中每个项被称为slot。UidGenerator设计了两个RingBuffer,一个保存唯一ID,一个保存flag。RingBuffer的尺寸是2^n,n必须是正整数:
具体细节阅读Git源码即可,可以直接通过 SpringBoot 集成开发使用。
8. 美团(Leaf)
Leaf由美团开发,github地址:GitHub - Meituan-Dianping/Leaf: Distributed ID Generate Service,Leaf同时支持号段模式和snowflake算法模式,可以 切换使用。
号段模式
先导入源码 https://github.com/Meituan-Dianping/Leaf ,在建一张表leaf_alloc
DROP TABLE IF EXISTS `leaf_alloc`;CREATE TABLE `leaf_alloc` ( `biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务key', `max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id', `step` int(11) NOT NULL COMMENT '初始步长,也是动态调整的最小步长', `description` varchar(256) DEFAULT NULL COMMENT '业务key的描述', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据库维护的更新时间', PRIMARY KEY (`biz_tag`)) ENGINE=InnoDB;
然后在项目中开启号段模式,配置对应的数据库信息,并关闭snowflake模式
leaf.name=com.sankuai.leaf.opensource.testleaf.segment.enable=trueleaf.jdbc.url=jdbc:mysql://localhost:3306/leaf_test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8leaf.jdbc.username=rootleaf.jdbc.password=rootleaf.snowflake.enable=false#leaf.snowflake.zk.address=#leaf.snowflake.port=
启动leaf-server 模块的 LeafServerApplication项目就跑起来了 号段模式获取分布式自增ID的测试url :http://localhost:8080/api/segment/get/leaf-segment-test 监控号段模式:http://localhost:8080/cache
snowflake模式
Leaf的snowflake模式依赖于ZooKeeper,不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
leaf.snowflake.enable=trueleaf.snowflake.zk.address=127.0.0.1leaf.snowflake.port=2181
snowflake模式获取分布式自增ID的测试url:http://localhost:8080/api/snowflake/get/test
9. 滴滴(Tinyid)
Tinyid 由滴滴开发,Github地址:https://github.com/didi/tinyid
Tinyid是一个ID生成器服务,它提供了REST API和Java客户端两种获取方式,如果使用Java客户端获取方式的话,官方宣称能单实例能达到1kw QPS(Over10 million QPSper single instance when using the java client.)
Tinyid教程 的原理非常简单,通过数据库表中的数据基本是就能猜出个八九不离十,就是经典的segment模式,和美团的leaf原理几乎一致。原理图如下所示,以同一个bizType为例,每个tinyid-server会分配到不同的segment,例如第一个tinyid-server分配到(1000, 2000],第二个tinyid-server分配到(2000, 3000],第3个tinyid-server分配到(3000, 4000]:
再以第一个tinyid-server为例,当它的segment用了20%(核心源码:segmentId.setLoadingId(segmentId.getCurrentId().get() + idInfo.getStep() * Constants.LOADING_PERCENT / 100);,LOADING_PERCENT的值就是20),即设定loadingId为20%的阈值,例如当前id是10000,步长为10000,那么loadingId=12000。那么当请求分布式ID分配到12001时(或者重启后),即超过loadingId,就会返回一个特殊code:new Result(ResultCode.LOADING, id);tinyid-server根据ResultCode.LOADING这个响应码就会异步分配下一个segment(4000, 5000],以此类推。
四:常见的负载均衡算法
介绍
负载均衡算法是在分布式系统中常用的一种技术,它通过合理地分配请求负载到多个服务器上,提高系统的性能和可靠性。
常见的负载均衡算法,包括轮询、随机、加权、EDF、堆维护、最小连接数、加权最少连接数和哈希算法等,接下来看看其原理和适用场景。
一、轮询算法(Round Robin)
轮询算法是最简单直观的负载均衡算法之一。在轮询算法中,每个请求依次按照顺序被分配到不同的服务器上。当一个新的请求到达时,它会被分配到列表中的下一个服务器。轮询算法可以保证请求均匀地分配到各个服务器上,但无法考虑各个服务器的实际负载情况。
后面讲的的加权也可结合轮询使用
代码实现示范:
public class RoundRobinLoadBalancer {
// 记录上一次选择的服务器下标
private int lastIndex = -1;
// 传入服务器列表,返回轮询选择的服务器
public Server selectServer(List<Server> serverList) {
// 获取服务器列表大小
int size = serverList.size();
// 如果服务器列表为空,返回null
if (size == 0) {
return null;
}
// 如果只有一个服务器,直接返回该服务器
if (size == 1) {
return serverList.get(0);
}
// 上锁,保证线程安全
synchronized (this) {
// 如果上一次选择的服务器下标超出了服务器列表大小,重置为-1
if (lastIndex >= size) {
lastIndex = -1;
}
// 选择下一个服务器
int index = lastIndex + 1;
lastIndex = index;
// 返回选择的服务器
return serverList.get(index);
}
}
// 服务器类
public static class Server {
private String ip;
private int port;
public Server(String ip, int port) {
this.ip = ip;
this.port = port;
}
// getter和setter方法省略
}
}
这里有两个需要注意的点
-
当我们初始化位置时,需要将其设置为一个随机值,避免多个负载均衡器同时请求同一个服务器,造成服务器的瞬时压力
-
在位置自增时,需要忽略符号位,因为Java没有无符号整数,所以当位置的值超出整型最大值时会变成负值导致抛出异常。至于为什么不能使用绝对值,是因为整型的最小值没有对应的绝对值,得到的依旧是负值
二、随机算法(Random)
随机算法是一种将请求随机分配到集群中的某个节点上的负载均衡算法。它通过随机选择一个节点来处理该请求。由于随机算法的特性,随着请求量的增加,各个节点处理请求的数量会趋于平衡,即演变为轮询算法。随机算法简单高效,适用于对负载均衡的绝对要求不高的场景。
基于Java的随机负载均衡算法实例:
// 基于Java的随机负载均衡算法
public class RandomLoadBalancer {
// 传入服务器列表,返回随机选择的服务器
public Server selectServer(List<Server> serverList) {
// 获取服务器列表大小
int size = serverList.size();
// 生成随机数
int randomIndex = new Random().nextInt(size);
// 返回随机选择的服务器
return serverList.get(randomIndex);
}
// 服务器类
public static class Server {
private String ip;
private int port;
public Server(String ip, int port) {
this.ip = ip;
this.port = port;
}
// getter和setter方法省略
}
}
三、加权算法(Weighted)
加权算法是一种根据服务器节点性能和负载情况分配权重的负载均衡算法。每个节点的权重值根据其性能差异进行设置,性能好的节点设置较大的权重,而性能差的节点则设置较小的权重。当收到一个新的请求时,算法会根据节点权重的比例来分配请求。这样可以更好地平衡各个节点的负载压力。
假设有3台服务、权重为3/5/2: server1 3 server2 5 server3 2
可以细分为随机加权负载、轮询加权负载
区别如下
随机加权负载: 就是按照几率选择服务,这里提供一个方案:
初始化一个容量为10的数组,随机装载上以上服务id,比如server2就会占有5个下标,获取服务的时候获取一个随机数0-9,取对应下标的服务,如果服务已经被取过了则下标+1,往上推,到了边界则置0再往上推,如果全被取过一次了,则重新装载
轮询加权负载: 就是挨个遍历结果,这里提供一个比较好的示例:
public class WeightedRoundRobinLoadBalancer {
// 记录上一次选择的服务器下标
private int lastIndex = -1;
// 记录当前权重
private int currentWeight = 0;
// 最大权重
private int maxWeight;
// 权重的最大公约数
private int gcdWeight;
// 服务器列表
private List<Server> serverList;
public WeightedRoundRobinLoadBalancer(List<Server> serverList) {
this.serverList = serverList;
init();
}
// 初始化
private void init() {
// 获取最大权重
maxWeight = getMaxWeight();
// 获取权重的最大公约数
gcdWeight = getGcdWeight();
}
// 传入服务器列表,返回加权轮询选择的服务器
public Server selectServer() {
while (true) {
// 上一次选择的服务器下标加1
lastIndex = (lastIndex + 1) % serverList.size();
// 如果上一次选择的服务器下标为0,重新计算当前权重
if (lastIndex == 0) {
currentWeight = currentWeight - gcdWeight;
if (currentWeight <= 0) {
currentWeight = maxWeight;
if (currentWeight == 0) {
return null;
}
}
}
// 获取当前下标的服务器
Server server = serverList.get(lastIndex);
// 如果当前服务器的权重大于等于当前权重,返回该服务器
if (server.getWeight() >= currentWeight) {
return server;
}
}
}
// 获取最大权重
private int getMaxWeight() {
int maxWeight = 0;
for (Server server : serverList) {
int weight = server.getWeight();
if (weight > maxWeight) {
maxWeight = weight;
}
}
return maxWeight;
}
// 获取权重的最大公约数
private int getGcdWeight() {
int gcdWeight = 0;
for (Server server : serverList) {
int weight = server.getWeight();
if (gcdWeight == 0) {
gcdWeight = weight;
} else {
gcdWeight = gcd(gcdWeight, weight);
}
}
return gcdWeight;
}
// 求最大公约数
private int gcd(int a, int b) {
if (b == 0) {
return a;
} else {
return gcd(b, a % b);
}
}
// 服务器类
public static class Server {
private String ip;
private int port;
private int weight; // 权重
public Server(String ip, int port, int weight) {
this.ip = ip;
this.port = port;
this.weight = weight;
}
// getter和setter方法省略
}
public static void main(String[] args) {
List<Server> servers=new ArrayList<>();
servers.add(new Server("1", 1, 3));
servers.add(new Server("2", 2, 5));
servers.add(new Server("3", 3, 2));
WeightedRoundRobinLoadBalancer weightedRoundRobinLoadBalancer = new WeightedRoundRobinLoadBalancer(servers);
System.out.println(JSON.toJSON(weightedRoundRobinLoadBalancer.selectServer()));
}
}
这里有三个需要注意的点:
-
当实例按权重展开成数组的时候,可能会出现实例权重都很大,但是它们的最大公约数不为1,这个时候可以使用最大公约数来减少展开后的数组大小。因为最大公约数的诸多限制,例如任意自然数N与N+1互质,任意自然数N与1互质,所以很容易出现优化失败的情况,因此本示例并未给出,感兴趣的可以去看Spring Cloud相关PR(Spring Cloud #1140)
-
在实例按权重展开成数组后,需要对得到的数组进行洗牌,以保证流量尽可能均匀,避免连续请求相同实例(Java中实现的洗牌算法是Fisher-Yates算法,其他语言可以自行实现)
-
因为是在构建负载均衡器的时候按权重展开成数组的,所以在负载均衡器构建完成后无法再改变实例的权值,对于频繁动态变更权重的场景不适用
四、EDF(Earliest Deadline First)实现
EDF算法最早被用在CPU调度上,EDF是抢占式单处理器调度的最佳调度算法。EDF实现与权重轮转实现相似,引入了名为deadline的额外变量,可以认为权重越高的服务器实例完成任务的时间越快,那么在假设所有请求的成本相同时,所需要花费的时间是权重的倒数,所以可以很自然地选择可以最早空闲出来提供服务的服务器实例,并将任务分配给它。
实现EDF算法只需要将每个下游服务器实例与deadline绑定,然后以deadline为优先级维护到优先队列中,并不断取出队首元素,调整它的deadline,并将它重新提交到优先队列中。知名Service Mesh代理envoy使用了此方法实现加权负载均衡(envoy),以及蚂蚁开源网络代理mosn中也实现了此方法
java实例代码如下:
public class WeightedLoadBalancer {
private final PriorityQueue entries;
public WeightedLoadBalancer(List instances) {
this.entries = instances.stream().map(EdfEntry::new).collect(Collectors.toCollection(PriorityQueue::new));
}
public ServiceInstance peek(HttpServletRequest request) {
EdfEntry entry = entries.poll();
if (entry == null) {
return null;
}
ServiceInstance instance = entry.instance;
entry.deadline = entry.deadline + 1.0 / instance.getWeight();
entries.add(entry);
return instance;
}
private static class EdfEntry implements Comparable {
final ServiceInstance instance;
double deadline;
EdfEntry(ServiceInstance instance) {
this.instance = instance;
this.deadline = 1.0 / instance.getWeight();
}
@Override
public int compareTo(EdfEntry o) {
return Double.compare(deadline, o.deadline);
}
}
}
EDF每次选择的算法复杂度为O(log(n)),相较于数组展开要慢,但相较于上界收敛选择在最坏情况下以及权重轮转都需要O(n)的时间复杂度来说,其性能表现的非常好,并且对于超大集群,其性能下降不明显。其空间复杂度为O(n),不会造成很大的内存开销
五、堆维护方式
所有动态有序集合都可以通过优先队列来实现,与EDF算法相同,取出队首的元素,修改它的优先级,并放回队列中
代码如下:
public class LeastConnectionLoadBalancer {
private final PriorityQueue instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances.stream().collect(toCollection(
() -> new PriorityQueue<>(comparingInt(ServiceInstance::getConnections))));
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = instances.poll();
if (best == null) {
return null;
}
best.setConnections(best.getConnections() + 1);
return best;
}
}
六、最小连接数算法(Least Connections)
最小连接数算法是一种根据集群中每个节点的当前连接数来决定请求分发的负载均衡算法。每次请求都会被分配给当前连接数最少的节点。
该算法可以避免某些节点负载过重,但在突发请求的情况下,仍然可能导致负载不平衡。
代码如下:
public class LeastConnectionLoadBalancer {
private final List instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = null;
for (ServiceInstance instance : instances) {
if (best == null || instance.getConnections() < best.getConnections()) {
best = instance;
}
}
if (best != null) {
best.setConnections(best.getConnections() + 1);
}
return best;
}
}
如果希望最大限度地减少响应时间,则最短响应时间算法是一个很好的选择。对于能够更好地处理复杂请求的服务实例,可以选择最少连接数算法
七、加权最少连接负载均衡算法(Weighted Least Connections)
加权最少连接负载均衡算法的实现方式与最少连接负载均衡算法相同,只是在计算时增加了权重相关的参数
代码如下:
public class LeastConnectionLoadBalancer {
private final List instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = null;
for (ServiceInstance instance : instances) {
if (best == null || instance.getConnections() * best.getWeight() < best.getConnections() * instance.getWeight()) {
best = instance;
}
}
if (best != null) {
best.setConnections(best.getConnections() + 1);
}
return best;
}
}
注意:在不等式中 a/b < c/d 与 ad < bc等价,并且可以避免除法带来的性能与精度问题
八、哈希算法(Hashing)
哈希算法是一种根据请求的特征(如IP地址或URL)进行哈希计算,并将计算结果与集群节点数量取模来确定请求应该被分发到哪个节点的负载均衡算法。哈希算法能够保证相同特征的请求总是被分配到同一个节点上,适用于需要保持特定状态的场景,但它也存在单点服务的问题。
public class HashLoadBalancer {
// 服务器列表
private List<Server> serverList;
public HashLoadBalancer(List<Server> serverList) {
this.serverList = serverList;
}
// 传入客户端IP,返回选择的服务器
public Server selectServer(String clientIp) {
// 将客户端IP进行Hash
int hashCode = clientIp.hashCode();
// 取模得到服务器下标
int index = hashCode % serverList.size();
// 返回对应下标的服务器
return serverList.get(index);
}
// 服务器类
public static class Server {
private String ip;
private int port;
public Server(String ip, int port) {
this.ip = ip;
this.port = port;
}
// getter和setter方法省略
}
}
需要注意的点:
面向公网提供服务的负载均衡器前面可能会经过任意多层反向代理服务器,为了获取到真实的源地址,需要先获取X-Forwarded-For头部,如果该头部不存在再去获取TCP连接的源地址
九、自适应负载均衡算法(Adaptive LoadBalance)
自适应负载均衡算法在P2C(Power of two Choice随机选择两个节点后继续选择连接数较少的节点)算法的基础上,选择二者中load最小的那个节点。详细使用可参看dubbo官网:知乎 - 安全中心
负载均衡有两个主要目标:
保持较短的请求响应时间和较小的请求阻塞概率; 负载均衡算法的 overhead 在可控级别,不占用过多的 CPU 、网络等资源。 自适应负载均衡是指无论系统处于空闲、稳定还是繁忙状态,负载均衡算法都会自动评估系统的服务能力,进行合理的流量分配,使整个系统始终保持较好的性能,不产生饥饿或者过载、宕机。
这种算法对于现在的电商系统、数据中心、云计算等领域都很有必要,使用自适应负载均衡能够更合理的利用资源,提高性能。例如,在双十一零点,用户集中下单支付,整个电商系统的请求速率到达峰值。如果将这些请求流量只分配给少部分 server,这些机器接收到的请求速率会远超过处理速率,新来的任务来不及处理,产生请求任务堆积。
示范代码:
@RestController
@RequestMapping("/balace")
public class DemoController {
@DubboReference(loadbalance=LoadbalanceRules.ADAPTIVE)
public DemoService demoService;
@GetMapping("/hello")
public String sayHello(String name) {
return demoService.sayHello(name);
}
}
综上所述:
负载均衡算法是分布式系统中重要的技术之一,是网络代理与网关组件最核心的组成部分。
能够提高系统的性能和可靠性。本文介绍了常见的负载均衡算法,包括轮询、随机、加权、最小连接数和哈希算法等,并分别说明了它们的原理和适用场景以及实现代码和注意事项。当然还有很多其他的负载均衡策略比如处理能力均衡(CPU、内存)此种均衡算法将把服务请求分配给内部中处理负荷(根据服务器 CPU 型号、CPU 数量、内存大小及当前连接数等换算而成)最轻的服务器,由于考虑到了内部服务器的处理能力及当前网络运行状况,所以此种均衡算法相对来说更加精确,尤其适合运用到第七层(应用层)负载均衡的情况下。以及DNS 响应均衡(Flash DNS)
在此均衡算法下,分处在不同地理位置的负载均衡设备收到同一个客户端的域名解析请求,并在同一时间内把此域名解析成各自相对应服务器的 IP 地址并返回给客户端,则客户端将以最先收到的域名解析 IP 地址来继续请求服务,而忽略其它的 IP 地址响应。在种均衡策略适合应用在全局负载均衡的情况下,对本地负载均衡是没有意义的。
在实际应用中,我们可以根据需求和场景选择合适的负载均衡算法,并结合其他优化策略来提升系统的性能和可扩展性。
五:常见的限流算法
介绍:
随着微服务的流行,服务和服务之间的依赖越来越强,调用关系越来越复杂,服务和服务之间的稳定性越来越重要。在遇到突发的请求量激增,恶意的用户访问,亦或请求频率过高给下游服务带来较大压力时,我们常常需要通过缓存、限流、熔断降级、负载均衡等多种方式保证服务的稳定性。其中限流是不可或缺的一环
在高并发系统中,我们通常需要通过各种手段来提供系统的可以用性,例如缓存、降级和限流等
限流简称流量限速(Rate Limit)是指只允许指定的事件进入系统,超过的部分将被拒绝服务、排队或等待、降级等处理.常见的限流方案如下
限流顾名思义,就是对请求或并发数进行限制;通过对一个时间窗口内的请求量进行限制来保障系统的正常运行。如果我们的服务资源有限、处理能力有限,就需要对调用我们服务的上游请求进行限制,以防止自身服务由于资源耗尽而停止服务。
在限流中有两个概念需要了解。
-
阈值:在一个单位时间内允许的请求量。如 QPS 限制为10,说明 1 秒内最多接受 10 次请求。
-
拒绝策略:超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待等。
4.1:固定时间窗口限流算法
1,什么是固定时间窗口限流算法?
固定时间窗口限流算法是一种简单的限流方法,也被称之为计数器算法。它将时间分成固定长度的时间窗口,然后在每个时间窗口内对请求进行计数。如果某个时间窗口内的请求数超过了预设的阈值,那么后续请求将被拒绝,直到进入下一个时间窗口。
实现原理
-
时间线划分为多个独立且固定大小窗口;
-
落在每一个时间窗口内的请求就将计数器加1;
-
如果计数器超过了限流阈值,则后续落在该窗口的请求都会被拒绝。但时间达到下一个时间窗口时,计数器会被重置为0。
优点
-
逻辑简单、维护成本比较低;
缺点
-
窗口切换时无法保证限流值。
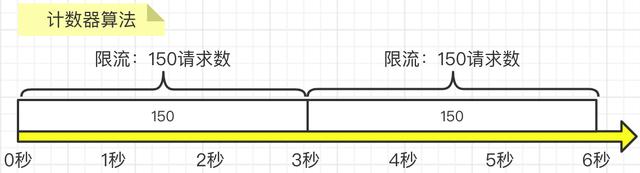
如图所示,我们要求3秒内的请求不要超过150次:
但是,貌似看似很“完美”的流量统计方式其实存在一个非常严重的临界问题,即:如果第2到3秒内产生了
150次请求,而第3到4秒内产生了150次请求,那么其实在第2秒到第4秒这两秒内,就已经发生了300次请求了,远远大于我们要求的3秒内的请求不要超过150次这个限制,如下图所示: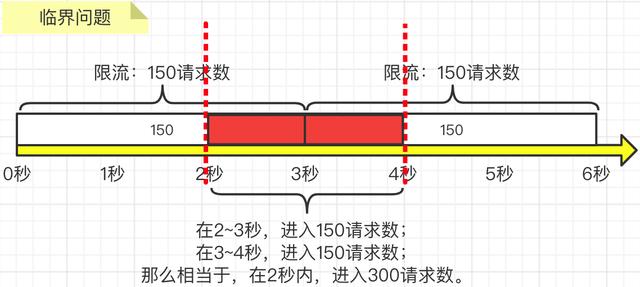
2. 应用场景
固定时间窗口限流算法适用于以下场景:
-
保护后端服务免受大流量冲击,避免服务崩溃。
-
对 API 调用进行限制,保证公平使用。
-
防止恶意用户对服务进行洪水攻击。
3. 代码示例
以下是使用 Java 编写的一个简单的固定时间窗口限流算法实现:
下面是简单的代码实现,QPS 限制为 2,这里的代码做了一些优化,并没有单独开一个线程去每隔 1 秒重置计数器,而是在每次调用时进行时间间隔计算来确定是否先重置计数器。
/**
* @author https://www.wdbyte.com
*/
public class RateLimiterSimpleWindow {
// 阈值
private static Integer QPS = 2;
// 时间窗口(毫秒)
private static long TIME_WINDOWS = 1000;
// 计数器
private static AtomicInteger REQ_COUNT = new AtomicInteger();
private static long START_TIME = System.currentTimeMillis();
public synchronized static boolean tryAcquire() {
if ((System.currentTimeMillis() - START_TIME) > TIME_WINDOWS) {
REQ_COUNT.set(0);
START_TIME = System.currentTimeMillis();
}
return REQ_COUNT.incrementAndGet() <= QPS;
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
Thread.sleep(250);
LocalTime now = LocalTime.now();
if (!tryAcquire()) {
System.out.println(now + " 被限流");
} else {
System.out.println(now + " 做点什么");
}
}
}
}
运行结果:
20:53:43.038922 做点什么 20:53:43.291435 做点什么 20:53:43.543087 被限流 20:53:43.796666 做点什么 20:53:44.050855 做点什么 20:53:44.303547 被限流 20:53:44.555008 被限流 20:53:44.809083 做点什么 20:53:45.063828 做点什么 20:53:45.314433 被限流
从输出结果中可以看到大概每秒操作 3 次,由于限制 QPS 为 2,所以平均会有一次被限流。看起来可以了,不过我们思考一下就会发现这种简单的限流方式是有问题的,虽然我们限制了 QPS 为 2,但是当遇到时间窗口的临界突变时,如 1s 中的后 500 ms 和第 2s 的前 500ms 时,虽然是加起来是 1s 时间,却可以被请求 4 次。

简单修改测试代码,可以进行验证:
// 先休眠 400ms,可以更快的到达时间窗口。
Thread.sleep(400);
for (int i = 0; i < 10; i++) {
Thread.sleep(250);
if (!tryAcquire()) {
System.out.println("被限流");
} else {
System.out.println("做点什么");
}
}
得到输出中可以看到连续 4 次请求,间隔 250 ms 没有却被限制。:
20:51:17.395087 做点什么 20:51:17.653114 做点什么 20:51:17.903543 做点什么 20:51:18.154104 被限流 20:51:18.405497 做点什么 20:51:18.655885 做点什么 20:51:18.906177 做点什么 20:51:19.158113 被限流 20:51:19.410512 做点什么 20:51:19.661629 做点什么
4. 固定时间窗口限流算法的局限性
虽然固定时间窗口限流算法简单易实现,但它存在一些局限性:
-
请求可能会在时间窗口的边界处集中,导致短时间内流量激增,从而影响服务稳定性。例如,在某个时间窗口的末尾和下一个时间窗口的开始,短时间内可能会有大量请求通过限流器。
-
由于时间窗口是固定的,限流器对突发流量的处理能力较弱。在某些情况下,可能需要使用更为灵活的限流算法,如滑动时间窗口限流算法或令牌桶算法。
尽管存在这些局限性,但固定时间窗口限流算法在许多场景下仍然具有较好的表现。
在实际应用中,可以根据对此限流算法做响应的改进。
4.2:滑动时间窗口限流算法
1,什么是滑动时间窗口限流算法?
滑动时间窗口算法是对固定时间窗口算法的一种改进,在滑动窗口的算法中,同样需要针对当前的请求来动态查询窗口。但窗口中的每一个元素,都是子窗口。子窗口的概念类似于方案一中的固定窗口,子窗口的大小是可以动态调整的。
解决了固定窗口在窗口切换时会受到两倍于阈值数量的请求,滑动窗口在固定窗口的基础上,将一个窗口分为若干个等份的小窗口,每个小窗口对应不同的时间点,拥有独立的计数器,当请求的时间点大于当前窗口的最大时间点时,则将窗口向前平移一个小窗口(将第一个小窗口的数据舍弃,第二个小窗口变成第一个小窗口,当前请求放在最后一个小窗口),整个窗口的所有请求数相加不能大于阈值。其中,Sentinel就是采用滑动窗口算法来实现限流的。如图所示:
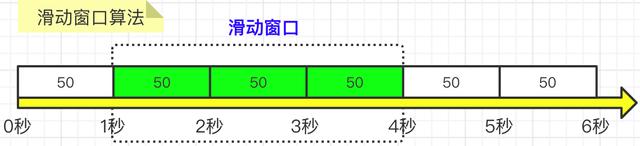
【1】 把3秒钟划分为3个小窗,每个小窗限制请求不能超过50秒。 【2】 比如我们设置,3秒内不能超过150个请求,那么这个窗口就可以容纳3个小窗,并且随着时间推移,往前滑动。每次请求过来后,都要统计滑动窗口内所有小窗的请求总量。
2,实现原理
-
将单位时间划分为多个区间,一般都是均分为多个小的时间段;
-
每一个区间内都有一个计数器,有一个请求落在该区间内,则该区间内的计数器就会加一;
-
每过一个时间段,时间窗口就会往右滑动一格,抛弃最老的一个区间,并纳入新的一个区间;
-
计算整个时间窗口内的请求总数时会累加所有的时间片段内的计数器,计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
3,代码实现
下面是基于以上滑动窗口思路实现的简单的滑动窗口限流工具类。
package com.wdbyte.rate.limiter;
import java.time.LocalTime;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 滑动窗口限流工具类
*
* @author https://www.wdbyte.com
*/
public class RateLimiterSlidingWindow {
/**
* 阈值
*/
private int qps = 2;
/**
* 时间窗口总大小(毫秒)
*/
private long windowSize = 1000;
/**
* 多少个子窗口
*/
private Integer windowCount = 10;
/**
* 窗口列表
*/
private WindowInfo[] windowArray = new WindowInfo[windowCount];
public RateLimiterSlidingWindow(int qps) {
this.qps = qps;
long currentTimeMillis = System.currentTimeMillis();
for (int i = 0; i < windowArray.length; i++) {
windowArray[i] = new WindowInfo(currentTimeMillis, new AtomicInteger(0));
}
}
/**
* 1. 计算当前时间窗口
* 2. 更新当前窗口计数 & 重置过期窗口计数
* 3. 当前 QPS 是否超过限制
*
* @return
*/
public synchronized boolean tryAcquire() {
long currentTimeMillis = System.currentTimeMillis();
// 1. 计算当前时间窗口
int currentIndex = (int)(currentTimeMillis % windowSize / (windowSize / windowCount));
// 2. 更新当前窗口计数 & 重置过期窗口计数
int sum = 0;
for (int i = 0; i < windowArray.length; i++) {
WindowInfo windowInfo = windowArray[i];
if ((currentTimeMillis - windowInfo.getTime()) > windowSize) {
windowInfo.getNumber().set(0);
windowInfo.setTime(currentTimeMillis);
}
if (currentIndex == i && windowInfo.getNumber().get() < qps) {
windowInfo.getNumber().incrementAndGet();
}
sum = sum + windowInfo.getNumber().get();
}
// 3. 当前 QPS 是否超过限制
return sum <= qps;
}
private class WindowInfo {
// 窗口开始时间
private Long time;
// 计数器
private AtomicInteger number;
public WindowInfo(long time, AtomicInteger number) {
this.time = time;
this.number = number;
}
// get...set...
}
}
下面是测试用例,设置 QPS 为 2,测试次数 20 次,每次间隔 300 毫秒,预计成功次数在 12 次左右。
public static void main(String[] args) throws InterruptedException {
int qps = 2, count = 20, sleep = 300, success = count * sleep / 1000 * qps;
System.out.println(String.format("当前QPS限制为:%d,当前测试次数:%d,间隔:%dms,预计成功次数:%d", qps, count, sleep, success));
success = 0;
RateLimiterSlidingWindow myRateLimiter = new RateLimiterSlidingWindow(qps);
for (int i = 0; i < count; i++) {
Thread.sleep(sleep);
if (myRateLimiter.tryAcquire()) {
success++;
if (success % qps == 0) {
System.out.println(LocalTime.now() + ": success, ");
} else {
System.out.print(LocalTime.now() + ": success, ");
}
} else {
System.out.println(LocalTime.now() + ": fail");
}
}
System.out.println();
System.out.println("实际测试成功次数:" + success);
}
下面是测试的结果。
当前QPS限制为:2,当前测试次数:20,间隔:300ms,预计成功次数:12 16:04:27.077782: success, 16:04:27.380715: success, 16:04:27.684244: fail 16:04:27.989579: success, 16:04:28.293347: success, 16:04:28.597658: fail 16:04:28.901688: fail 16:04:29.205262: success, 16:04:29.507117: success, 16:04:29.812188: fail 16:04:30.115316: fail 16:04:30.420596: success, 16:04:30.725897: success, 16:04:31.028599: fail 16:04:31.331047: fail 16:04:31.634127: success, 16:04:31.939411: success, 16:04:32.242380: fail 16:04:32.547626: fail 16:04:32.847965: success, 实际测试成功次数:11
滑动窗口限流算法的优缺点
优点:
简单易懂 精度高(通过调整时间窗口的大小来实现不同的限流效果) 可扩展性强(可以非常容易地与其他限流算法结合使用)
缺点:
突发流量无法处理(无法应对短时间内的大量请求,但是一旦到达限流后,请求都会直接暴力被拒绝。酱紫我们会损失一部分请求,这其实对于产品来说,并不太友好),需要合理调整时间窗口大小。
存在的问题
那么滑动窗口限流法是完美的吗?细心观察我们应该能马上发现问题,如下图:设置1s内只能250请求。分割5个子窗口。
0ms-1000ms、200ms-1200ms的请求在我们设置的阈值内,但是100ms-1100ms的请求一共是350,远超过了我们所设置的阈值。
滑动时间窗口限流法其实就是计数器算法的一个变种,依然存在临界值的问题。并且流量的过渡是否平滑依赖于我们设置的窗口格数,格数越多,统计越精确。
格子的数量影响着滑动窗口算法的精度,依然有时间片的概念,无法根本解决临界点问题。
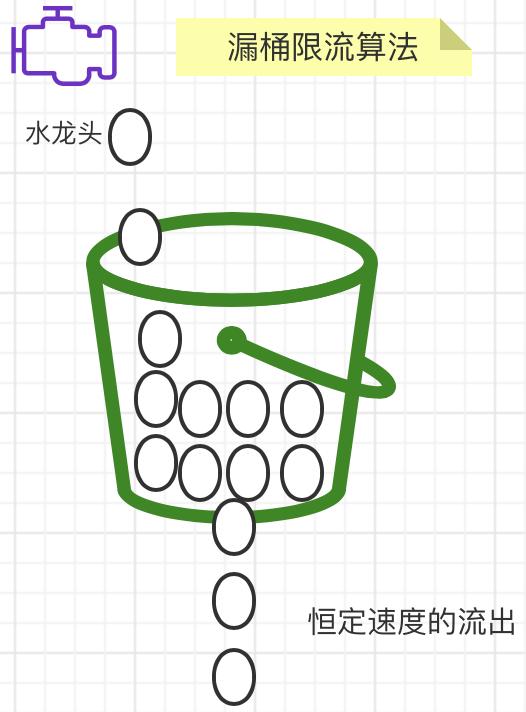
4.3:漏桶限流算法
1,什么是漏桶限流算法?
漏桶(Leaky Bucket)算法是水先进入到漏桶里,漏桶再以一定的速率出水,当流入水的数量大于流出水时,多余的水直接溢出。把水换成请求来看,漏桶相当于服务器队列,但请求量大于限流阈值时,多出来的请求就会被拒绝服务。漏桶算法使用队列实现,可以以固定的速率控制流量的访问速度,可以做到流量的平整化处理。
桶就相当于一个队列,请求先放到桶里,等待执行。桶满了则拒绝
2,实现原理:
-
将每个请求放入固定大小的队列进行中
-
队列以固定速率向外流出请求,如果队列为空则停止流出。
-
如队列满了则多余的请求会被直接拒绝
主要的作用:
【1】 控制数据注入网络的速度。 【2】 平滑网络上的突发流量。
漏桶限流算法的核心就是:不管上面的水流速度有多块,漏桶水滴的流出速度始终保持不变。消息中间件就采用的漏桶限流的思想。如图所示:
3,代码实现:
public class LeakyBucketRateLimiter {
private RedissonClient redissonClient = RedissonConfig.getInstance();
private static final String KEY_PREFIX = "LeakyBucket:";
/**
* 桶的大小
*/
private Long bucketSize;
/**
* 漏水速率,单位:个/秒
*/
private Long leakRate;
//控制流速
public LeakyBucketRateLimiter(Long bucketSize, Long leakRate) {
this.bucketSize = bucketSize;
this.leakRate = leakRate;
//这里启动一个定时任务,每s执行一次
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleAtFixedRate(this::leakWater, 0, 1, TimeUnit.SECONDS);
}
/**
* 漏水
*/
public void leakWater() {
RSet<String> pathSet = redissonClient.getSet(KEY_PREFIX + ":pathSet");
//遍历所有path,删除旧请求
for(String path : pathSet){
RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(KEY_PREFIX + path);
// 获取当前时间
long now = System.currentTimeMillis();
// 删除旧的请求
bucket.removeRangeByScore(0, true,now - 1000 * leakRate,true);
}
}
public boolean triggerLimit(String path) {
//加锁,防止并发初始化问题
RLock rLock = redissonClient.getLock(KEY_PREFIX + "LOCK:" + path);
try {
rLock.lock(100,TimeUnit.MILLISECONDS);
String redisKey = KEY_PREFIX + path;
RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(redisKey);
//这里用一个set,来存储所有path
RSet<String> pathSet = redissonClient.getSet(KEY_PREFIX + ":pathSet");
pathSet.add(path);
// 获取当前时间
long now = System.currentTimeMillis();
// 检查桶是否已满
if (bucket.size() < bucketSize) {
// 桶未满,添加一个元素到桶中
bucket.add(now, now);
return false;
}
// 桶已满,触发限流
System.out.println("[triggerLimit] path:"+path+" bucket size:"+bucket.size());
return true;
} finally {
rLock.unlock();
}
}
}
在代码实现里,我们用了 RSet 来存储 path,这样一来,一个定时任务,就可以搞定所有 path 对应的桶的出水,而不用每个桶都创建一个一个定时任务。
这里我直接用 ScheduledExecutorService 启动了一个定时任务,1s跑一次,当然集群环境下,每台机器都跑一个定时任务,对性能是极大的浪费,而且不好管理,我们可以用分布式定时任务,比如 xxl-job 去执行 leakWater。
测试:
public class LeakyBucketRateLimiterTest {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10));
LeakyBucketRateLimiter leakyBucketRateLimiter = new LeakyBucketRateLimiter(10L, 1L);
for (int i = 0; i < 8; i++) {
CountDownLatch countDownLatch = new CountDownLatch(20);
for (int j = 0; j < 20; j++) {
threadPoolExecutor.execute(() -> {
boolean isLimit = leakyBucketRateLimiter.triggerLimit("/test");
System.out.println(isLimit);
countDownLatch.countDown();
});
}
countDownLatch.await();
//休眠10s
TimeUnit.SECONDS.sleep(10L);
}
}
}
优点:
漏桶算法能够有效防止网络拥塞,实现也比较简单。是能够以固定的速率去控制流量,稳定性比较好。
缺点:
因为漏桶的出水速率是固定的,假如突然来了大量的请求,那么只能丢弃超量的请求,即使下游能处理更大的流量,没法充分利用系统资源。
4.4:令牌桶限流算法
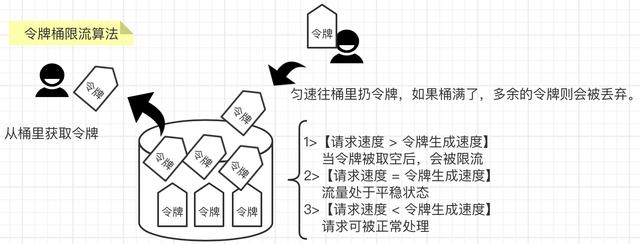
1,什么是令牌桶限流算法?
令牌桶算法是基于漏桶之上的一种改进版本,在令牌桶中,令牌代表当前系统允许的请求上限,令牌会匀速被放入桶中。当桶满了之后,新的令牌就会被丢弃
常用的 Google 的 Java 开发工具包 Guava 中的限流工具类 RateLimiter 和 Redisson 的限流 就是令牌桶的一个实现。令牌桶的实现思路类似于生产者和消费之间的关系。系统服务作为生产者,按照指定频率向桶(容器)中添加令牌,如 QPS 为 2,每 500ms 向桶中添加一个令牌,如果桶中令牌数量达到阈值,则不再添加。当然还有阿里开源的 Sentinel 就是不错的工具,Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
请求执行作为消费者,每个请求都需要去桶中拿取一个令牌,取到令牌则继续执行;如果桶中无令牌可取,就触发拒绝策略,可以是超时等待,也可以是直接拒绝本次请求,由此达到限流目的。
2,实现原理:
-
令牌以固定速率生成并放入到令牌桶中;
-
如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
-
如果桶空了,则拒绝该请求
系统会以恒定速度(r tokens/sec)往固定容量的令牌桶中放入令牌。令牌桶有固定的大小,如果令牌桶被填满,则会丢弃令牌。
会存在三种情况:
【请求速度 大于 令牌生成速度】当令牌被取空后,会被限流 【请求速度 等于 令牌生成速度】流量处于平稳状态 【请求速度 小于 令牌生成速度】请求可被正常处理,桶满则丢弃令牌
如图所示:
3,代码实现
首先是要发放令牌,要固定速率,那我们又得开个线程,定时往桶里投令牌,然后 Redission 提供了令牌桶算法的实现。
RateLimiter 限流体验:
public class TokenBucketRateLimiter {
public static final String KEY = "TokenBucketRateLimiter:";
/**
* 阈值
*/
private Long limit;
/**
* 添加令牌的速率,单位:个/秒
*/
private Long tokenRate;
public TokenBucketRateLimiter(Long limit, Long tokenRate) {
this.limit = limit;
this.tokenRate = tokenRate;
}
/**
* 限流算法
*/
public boolean triggerLimit(String path){
RedissonClient redissonClient = RedissonConfig.getInstance();
RRateLimiter rateLimiter = redissonClient.getRateLimiter(KEY + path);
// 初始化,设置速率模式,速率,间隔,间隔单位
rateLimiter.trySetRate(RateType.OVERALL, limit, tokenRate, RateIntervalUnit.SECONDS);
// 获取令牌
return rateLimiter.tryAcquire();
}
}
测试:
public class TokenBucketRateLimiterTest {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10));
TokenBucketRateLimiter tokenBucketRateLimiter = new TokenBucketRateLimiter(10L, 1L);
for (int i = 0; i < 8; i++) {
CountDownLatch countDownLatch = new CountDownLatch(20);
for (int j = 0; j < 20; j++) {
threadPoolExecutor.execute(() -> {
boolean isLimit = tokenBucketRateLimiter.triggerLimit("/test");
System.out.println(isLimit);
countDownLatch.countDown();
});
}
countDownLatch.await();
//休眠10s
TimeUnit.SECONDS.sleep(10L);
}
}
}
代码中限制 QPS 为 2,也就是每隔 500ms 生成一个令牌,但是程序每隔 250ms 获取一次令牌,所以两次获取中只有一次会成功。
17:19:06.797557:true 17:19:07.061419:false 17:19:07.316283:true 17:19:07.566746:false 17:19:07.817035:true 17:19:08.072483:false 17:19:08.326347:true 17:19:08.577661:false 17:19:08.830252:true 17:19:09.085327:false
思考
虽然演示了 Google Guava 工具包中的 RateLimiter 的实现,但是我们需要思考一个问题,就是令牌的添加方式,如果按照指定间隔添加令牌,那么需要开一个线程去定时添加,如果有很多个接口很多个 RateLimiter 实例,线程数会随之增加,这显然不是一个好的办法。显然 Google 也考虑到了这个问题,在 RateLimiter 中,是在每次令牌获取时才进行计算令牌是否足够的。它通过存储的下一个令牌生成的时间,和当前获取令牌的时间差,再结合阈值,去计算令牌是否足够,同时再记录下一个令牌的生成时间以便下一次调用。
下面是 Guava 中 RateLimiter 类的子类 SmoothRateLimiter 的 resync() 方法的代码分析,可以看到其中的令牌计算逻辑。
void resync(long nowMicros) { // 当前微秒时间
// 当前时间是否大于下一个令牌生成时间
if (nowMicros > this.nextFreeTicketMicros) {
// 可生成的令牌数 newPermits = (当前时间 - 下一个令牌生成时间)/ 令牌生成时间间隔。
// 如果 QPS 为2,这里的 coolDownIntervalMicros 就是 500000.0 微秒(500ms)
double newPermits = (double)(nowMicros - this.nextFreeTicketMicros) / this.coolDownIntervalMicros();
// 更新令牌库存 storedPermits。
this.storedPermits = Math.min(this.maxPermits, this.storedPermits + newPermits);
// 更新下一个令牌生成时间 nextFreeTicketMicros
this.nextFreeTicketMicros = nowMicros;
}
}
优点:
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
与漏桶算法相比,有可能导致短时间内的请求数上升(因为拿到令牌后,就可以访问接口,存在一瞬间将所有令牌拿走的情况),但不会有计数算法那样高的峰值(因为令牌数量是匀速增加的)。所以在应对突发流量的时候令牌桶表现的更佳。
一般自己调用自己的接口,接口会有一定的伸缩性,令牌桶算法,主要用来保护自己的服务器接口。
缺点:
例如令牌桶,假如系统上线时没有预热,那么可能会出现由于此时桶中还没有令牌,而导致请求被误杀的情况;
4.5:Redis 分布式限流
Redis 是一个开源的内存数据库,可以用来作为数据库、缓存、消息中间件等。Redis 是单线程的,又在内存中操作,所以速度极快,得益于 Redis 的各种特性,所以使用 Redis 实现一个限流工具是十分方便的。
下面的演示都基于Spring Boot 项目,并需要以下依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
代码实现:
public class RedissonConfig {
private static final String REDIS_ADDRESS = "redis://127.0.0.1:6379";
private static volatile RedissonClient redissonClient;
public static RedissonClient getInstance(){
if (redissonClient == null){
synchronized (RedissonConfig.class){
if (redissonClient == null){
Config config = new Config();
config.useSingleServer().setAddress(REDIS_ADDRESS);
redissonClient = Redisson.create(config);
return redissonClient;
}
}
}
return redissonClient;
}
}
实际上redis可以通过三种方式实现限流的目的,分别是
1、计数器算法
计数器算法是Redis实现限流的常见手段,其核心思想为统计单位时间内的请求数量并与阈值进行比较,当达到阈值时就拒绝后续访问,从而起到限制流量的目的。具体实现方法如下:
1.1 使用Redis的原子操作incr操作,实现计数器的自增。
1.2 通过Redis对key设置过期时间,例如设置一分钟后过期。
1.3 当计算器的值超过限制阈值时,拒绝访问,否则可以继续访问并重置计数器值。
需要注意的是,由于计数器算法只记录请求数量,无法区分不同类型的请求,可能会存在被恶意用户绕过的可能性。因此,这种方法适用于单一请求的场景,如接口限流。
/**
* @author: shenz
* @create: 2023-07-26 14:41
**/
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate redisTemplate;
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm");
@GetMapping("/Fixed")
public String testFixedWindow() {
String now = formatter.format(LocalDateTime.now());
Long count = redisTemplate.opsForValue().increment(now + ":fixed");
if (count > 5) {
return "不好意思,服务器正忙,请一分钟后再试......";
} else {
return "服务端正在处理";
}
}
}
2、漏桶算法
漏桶算法也是一种流量控制算法,和计数器算法相比,漏桶算法会对请求进行一个统一的速率限制,而非单纯地限制访问量。其主要思想为模拟水桶中的水流量,加入一个固定的速率加入水,如果水桶满了,就拒绝后续的请求,否则按照固定的速率处理请求。具体实现方法如下:
2.1 将漏桶看作一个固定大小的容器,以固定的速率漏出水。
2.2 使用Redis的List数据类型,将每个请求按照时间顺序加入List中,即水流进入水桶的过程。
2.3 使用Redis的过期机制,将List中已经达到一定时间的请求移出,即水从桶中漏出的过程。
2.4 当请求加入List时,判断List的长度是否达到桶的最大限制,如果超过限制,就拒绝请求,否则可以正常处理。
漏桶算法可用于应对各种请求,由于限制速率而非请求数量,不容易被恶意用户绕过,常用于对整个应用的限流控制。
/**
* @author: shenz
* @create: 2023-07-26 14:41
**/
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping("/Sliding")
public String testSlidingWindow() {
Long currentTime = System.currentTimeMillis();
System.out.println(currentTime);
if (redisTemplate.hasKey("limit")) {
// intervalTime是限流的时间
Long intervalTime = 60000L;
Integer count = redisTemplate.opsForZSet().rangeByScore("limit", currentTime - intervalTime, currentTime).size();
System.out.println(count);
if (count != null && count > 5) {
return "每分钟最多只能访问5次";
}
}
redisTemplate.opsForZSet().add("limit", UUID.randomUUID().toString(), currentTime);
return "访问成功";
}
}
3、令牌桶算法
令牌桶算法也属于流量控制算法,其主要思想为固定速率向令牌桶中添加令牌,一个请求需要获取令牌才能执行,当令牌桶中没有令牌时,请求将被拒绝。具体实现方法如下:
3.1 使用Redis的List数据类型,将一定数量的令牌添加到List中,表示令牌桶的容量。
3.2 使用Redis过期机制,每当有请求到来时,如果List中还有令牌,则可以正常处理请求,并从List中移除一个令牌,否则拒绝请求。
3.3 当令牌生成速度过快或者请求到来速度过慢时,可能会出现令牌桶溢出的情况。因此,可使用Redis的有序集合数据类型,记录每次执行的时间和执行次数,用于在下一次添加令牌时,调整添加令牌的数量,以适应实际情况。
令牌桶算法不仅能够限制并发数,而且可以控制请求速率,比较适合对底层资源进行保护,比如数据库连接池、磁盘IO等。
代码实现:
/**
* @author: shenz
* @create: 2023-07-26 14:41
**/
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private Redisson redisson;
@GetMapping("/Token")
public String testTokenBucket() {
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
// 最大流速 = 每10秒钟产生1个令牌
rateLimiter.trySetRate(RateType.OVERALL, 1, 10, RateIntervalUnit.SECONDS);
//需要1个令牌
if (rateLimiter.tryAcquire(1)) {
return "令牌桶里面有可使用的令牌";
}
return "不好意思,请过十秒钟再来~~~~~~~";
}
}
总结:
实际上主要分为窗口限流和桶限流两者各有优势。
-
窗口算法实现简单,逻辑清晰,可以很直观的得到当前的 QPS 情况,但是会有时间窗口的临界突变问题,而且不像桶一样有队列可以缓冲。
-
桶算法虽然稍微复杂,不好统计 QPS 情况,但是桶算法也有优势所在。
-
-
漏桶模式消费速率恒定,可以很好的保护自身系统,可以对流量进行整形,但是面对突发流量不能快速响应。
-
令牌桶模式可以面对突发流量,但是启动时会有缓慢加速的过程,不过常见的开源工具中已经对此优化。
-
细节比较:
-
固定窗口:实现简单,适用于流量相对均匀分布,对限流准确度要求不严格的场景。
-
滑动窗口:适用于对准确性和性能有一定的要求场景,可以调整子窗口数量来权衡性能和准确度
-
漏桶:适用于流量绝对平滑的场景
-
令牌桶:适用于流量整体平滑的情况下,同时也可以满足一定的突发流程场景
市面上也有很多好用的开源限流工具:
-
Guava RateLimiter ,基于令牌桶算法限流,当然是单机的;
-
Sentinel ,基于滑动窗口限流,支持单机,也支持集群
-
网关限流,很多网关自带限流方法,比如Spring Cloud Gateway、Nginx
可靠消息最终一致性、最大努力通知
可靠消息最终一致性方案是指当事务发起方执行完成本地事务后发出一条消息到消息中间件,事务参与方(消息消费者)一定能够接收到消息并处理事务成功。
此方案强调的是只要消息发给事务参与方,则最终事务一定要达到一致。此方案用到MQ来确保最终一致性。

可靠消息最终一致性:基于本地消息表
本地消息表,作为可靠消息最终一致性的一种典型实现方案。最初由eBay提出,其亦是对BASE理论的体现、实践。其基本原理、思路很简单。这里以订单服务、库存服务为例展开说明。当客户下单后,需要先通过订单服务在订单表中插入一条订单记录,再通过库存服务实现对库存表中库存记录的扣减。但这里即会存在一个问题,由于订单表、库存表分别位于订单服务、库存服务的数据库。传统的本地事务显然无法解决这种跨服务、跨数据库的场景。而基于本地消息表的分布式事务方案则可以在对业务改动尽可能小的前提下保障数据的最终一致性
具体地,在事务发起方即这里订单服务的数据库中再增加一张本地消息表。向订单表中插入订单记录的同时,在本地消息表中也插入一条表示订单创建成功的记录。
由于此时订单表、本地消息表位于同一数据库当中,可以直接通过一个本地事务来保证对这两张表操作的原子性
与此同时,在订单服务中添加一个定时任务,不停轮询、处理本地消息表。具体地,将消息表中未被成功处理的记录通过MQ投递至库存服务。而库存服务在从MQ中接收到订单创建成功的消息后,对库存表进行库存扣减操作。在库存服务完成扣减后,通过某种方式告诉订单服务该条消息已经被成功消费、处理。这样订单服务即可将本地消息表中相关记录标记为成功处理的状态,以避免定时任务重复投递。这里库存服务确认消息消费成功的实现方式,可以直接通过MQ的Ack消息确认机制实现,也可以让库存服务再向订单服务发送一个处理完毕的消息来完成。
整个方案的示意图如下所示

可以看到,基于本地消息表的可靠消息最终一致性方案非常简单。
但在具体业务实践过程还是有一些需要注意的地方:
-
库存服务的库存扣减需要保证幂等性,一方面由于MQ存在自动重试机制,另一方面,当订单服务未收到库存服务对本次消息的消费确认时,则可能会导致定时任务下一次继续投递该消息至库存服务
-
根据实际业务需要,本地消息表中记录还应该设置一个合理的最大处理等待时间,以及时发现长时间无法得到有效处理的本地消息记录
可靠消息最终一致性:基于RocketMQ的事务消息
通过基于本地消息表的可靠消息最终一致性方案可以看出,其本质上是通过引入本地消息表来保证本地事务与发送消息的原子性。
那如果说MQ本身能够直接保证消息发送与本地事务的原子性岂不是更方便了,为此在RocketMQ中提供了所谓的事务消息。这里我们来介绍下其基本机制,流程图如下所示


事务发起方首先会将事务消息发送到RocketMQ当中,但此时该条消息并不会对消费者可见,即所谓的半消息。
当RocketMQ确定消息已经发送成功后,事务发起方即会开始执行本地事务。
同时根据本地事务的执行结果,告知给RocketMQ相应的状态信息——commit、rollback。
具体地,当RocketMQ得到commit状态,则会将之前的事务消息转为对消费者可见、并开始投递;
当RocketMQ得到rollback状态,则会相应的删除之前的事务消息,保证了本地事务回滚的同时消息也不会投递到消费者侧,保障了二者的原子性。进一步地,如果RocketMQ未收到本地事务的执行状态时,则会通过事务回查机制定时检查本地事务的状态
案例搭建
这里利用Docker Compose搭建RocketMQ环境
# Compose 版本
version: '3.8'
# 定义Docker服务
services:
# Rocket MQ Name Server
RocketMQ-NameServer:
image: foxiswho/rocketmq:4.8.0
container_name: RocketMQ-NameServer
ports:
- "9876:9876"
command: sh mqnamesrv
networks:
rocket_mq_net:
ipv4_address: 130.130.131.10
# Rocket MQ Broker
RocketMQ-Broker:
image: foxiswho/rocketmq:4.8.0
container_name: RocketMQ-Broker
ports:
- "10909:10909"
- "10911:10911"
- "10912:10912"
environment:
NAMESRV_ADDR: "130.130.131.10:9876"
command: sh mqbroker -c /home/rocketmq/rocketmq-4.8.0/conf/broker.conf
depends_on:
- RocketMQ-NameServer
networks:
rocket_mq_net:
ipv4_address: 130.130.131.11
# Rocket MQ Console
RocketMQ-Console:
image: styletang/rocketmq-console-ng:1.0.0
container_name: RocketMQ-Console
ports:
- 8080:8080
environment:
JAVA_OPTS: "-Drocketmq.namesrv.addr=130.130.131.10:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false"
depends_on:
- RocketMQ-NameServer
networks:
rocket_mq_net:
ipv4_address: 130.130.131.12
# 定义网络
networks:
rocket_mq_net:
ipam:
config:
- subnet: 130.130.131.0/24
然后进入RocketMQ Broker容器,将配置文件broker.conf中的brokerIP1设置为宿主机IP,如下所示

订单服务
这里通过SpringBoot搭建一个事务的发起方——即订单服务。首先在POM中引入RocketMQ相关依赖
<dependencyManagement>
<dependencies>
<!--Spring Boot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.3.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Rocket MQ -->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
同时在application.yml中添加关于RocketMQ相关的配置,这里为避免由于消息发送超时而导致失败,调大了关于生产者发送超时时间的配置
rocketmq:
name-server: 127.0.0.1:9876
producer:
# 默认生产者组名
group: order-service
# 生产者发送超时时间, Unit: ms
send-message-timeout: 600000
需要注意的是,从RocketMQ-Spring 2.1.0版本之后,注解@RocketMQTransactionListener不能设置txProducerGroup、ak、sk,这些值均与对应的RocketMQTemplate保持一致。换言之,由于不同事务流程的事务消息需要使用不同的生产者组来发送,故为了设置生产者组名。需要通过@ExtRocketMQTemplateConfiguration注解来定义非标的RocketMQTemplate。定义非标的RocketMQTemplate时可自定义相关属性,如果不定义,它们取全局的配置属性值或默认值。由于该注解已继承自@Component注解,故无需开发者重复添加即可完成相应的实例化。这里我们自定义该非标实例的生产者组名
/**
* 自定义非标的RocketMQTemplate, Bean名与所定义的类名相同(但首字母小写)
*/
@ExtRocketMQTemplateConfiguration(group="tx-order-create")
public class ExtRocketMQTemplate1 extends RocketMQTemplate {
}
下面既是创建订单过程中本地事务的方法。对于RocketMQ回查本地事务执行结果时,则有两种思路,要么判断订单表中是否存在相关订单记录;要么单独增加一张事务日志表,每笔订单创建完成后向事务日志表插入相应事务ID的记录,这样回查时只需在事务日志表中判定是否存在相应事务ID的记录即可。而订单表、事务日志表由于在同一数据库下,可以直接利用本地事务保证原子性。这里我们采用后者的思路,即创建订单时,不仅在订单表插入订单记录,也在事务日志表中插入一条相应的记录。实现如下所示
@Service
@Slf4j
public class OrderService {
@Autowired
private TransactionLogMapper transactionLogMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 创建订单
* @param order 订单记录
* @param txid 事务ID
*/
@Transactional
public void createOrder(Order order, String txid) {
// 创建订单
int result = orderMapper.insert(order);
// 插入失败
if( result!=1 ) {
new RuntimeException("create order fail");
}
// 写入事务日志
transactionLogMapper.insert( new TransactionLog(txid) );
}
}
...
/**
* 订单记录
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_order")
public class Order {
@TableId(type = IdType.AUTO)
private Integer id;
/**
* 订单编号
*/
private String orderNum;
/**
* 商品名称
*/
private String name;
/**
* 商品数
*/
private Integer count;
}
...
/**
* 事务日志
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_transaction_log")
public class TransactionLog {
@TableId(type = IdType.AUTO)
private int id;
/**
* 事务ID
*/
private String txid;
public TransactionLog(String txid) {
this.txid = txid;
}
}
然后定义事务消息的发送者OrderProducerService,通过刚刚定义的非标rocketMQTemplate发送事务消息到RocketMQ。
与此同时,还需要通过实现RocketMQLocalTransactionListener接口的executeLocalTransaction、checkLocalTransaction方法以用于调用业务Service执行本地事务、回查本地事务执行结果。特别地,在RocketMQLocalTransactionListener实现类上需要添加@RocketMQTransactionListener注解,并通过rocketMQTemplateBeanName属性指定相应的rocketMQTemplate实例名
@Service
@Slf4j
public class OrderProducerService {
/*
* 按名注入, 使用非标的rocketMQTemplate
*/
@Qualifier("extRocketMQTemplate1")
@Autowired
private RocketMQTemplate extRocketMQTemplate;
/**
* 发送事务消息
* @param order
* @param txid
*/
public void sendTransactionMsg(Order order, String txid) {
Message<Order> message = MessageBuilder
.withPayload( order )
.setHeader("txid", txid)
.build();
String topic = "order_create";
TransactionSendResult sendResult = extRocketMQTemplate.sendMessageInTransaction(topic, message, null);
LocalTransactionState localTransactionState = sendResult.getLocalTransactionState();
log.info("sendResult: {}", JSON.toJSON(sendResult));
}
@RocketMQTransactionListener(rocketMQTemplateBeanName="extRocketMQTemplate1")
public static class OrderTransactionListenerImpl implements RocketMQLocalTransactionListener {
@Autowired
private OrderService orderService;
@Autowired
private TransactionLogMapper transactionLogMapper;
/**
* 执行本地事务
* @param msg
* @param arg
* @return
*/
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
RocketMQLocalTransactionState state = RocketMQLocalTransactionState.COMMIT;
try {
String payload = new String((byte[]) msg.getPayload());
Order order = JSON.parseObject(payload, Order.class);
String txid = (String) msg.getHeaders().get("txid");
// 通过业务Service执行本地事务
orderService.createOrder(order, txid);
} catch (Exception e) {
// 本地事务执行失败, 故向RocketMQ返回 rollback 状态
log.info("Happen Exception: {}", e.getMessage());
state = RocketMQLocalTransactionState.ROLLBACK;
}
return state;
}
/**
* 回查本地事务的结果
* @param msg
* @return
*/
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
// 获取事务ID
String txid = (String) msg.getHeaders().get("txid");
List<TransactionLog> transactionLogList = transactionLogMapper.selectList(
new QueryWrapper<TransactionLog>().eq("txid", txid)
);
// 事务日志表中无该事务ID的记录
if( CollectionUtils.isEmpty(transactionLogList) ) {
return RocketMQLocalTransactionState.ROLLBACK;
}
return RocketMQLocalTransactionState.COMMIT;
}
}
}
最后提供一个Controller接口便于测试
@RestController
@RequestMapping("order")
@Slf4j
public class OrderController {
@Autowired
private OrderProducerService orderProducerService;
@RequestMapping("/create")
public String create(@RequestParam(required=false) Integer id) {
Order order = Order.builder()
.orderNum( UUID.randomUUID().toString() )
.name("iPhone 13 Pro")
.count(2)
.build();
// 生成一个事务ID
String txid = UUID.randomUUID().toString();
orderProducerService.sendTransactionMsg(order, txid);
return "order create complete";
}
}
库存服务
而对于库存服务而言,同样需要向POM中添加RocketMQ相关依赖。此处不再赘述。然后通过@RocketMQMessageListener实现消息的监听、消费即可。需要注意的是由于RocketMQ消费者端的重试机制,故为避免重复消费,消费者侧在进行库存扣减时需要保证幂等性
@Service
@Slf4j
@RocketMQMessageListener(topic = "order_create", consumerGroup = "consumerGroup1")
public class OrderConsumerService implements RocketMQListener<Order> {
@Override
public void onMessage(Order order) {
log.info("[Consumer]: {} ", order);
// 业务处理: 扣减库存
...
}
}
最大努力通知
最大努力通知,亦被称作为Best-Effort Delivery最大努力交付,其同样对是柔性事务思想的实践。
常用于对调用结果进行异步通知的业务中,特别是与第三方系统进行对接的过程中。
这里,我们以电商平台通过第三方银行系统完成支付为例展开说明介绍,示意图如下所示

首先我们电商平台的订单服务会通过调用第三方银行系统的支付服务完成订单款项的支付,由于这里支付结果是异步获取的。所以需要等待银行系统在完成相关支付业务后,通过回调接口来通知我们系统的支付结果。
但很多时候由于存在网络异常、回调接口发生异常等意外因素,第三方为了尽最大努力进行结果通知,往往会将相关结果通过MQ投递到通知服务,以便单独进行重复、多次的结果通知
但如果我们从第三方系统的角度考虑,如果调用回调接口一直失败,总不能一直这么重试下去啊。所以在最大努力通知的方案中,不仅需要通知的发起方(即这里的第三方银行系统)提供结果通知的重试机制,还需要给通知的接受方(即这里的电商平台)提供一个用于主动进行结果查询的接口。这样即使当银行系统的通知次数达到阈值,不再调用回调接口进行结果通知时,我方服务也可以在之后通过银行系统的查询接口获取相应结果
总结:
可靠消息最终一致性就是保证消息从生产方经过消息中间件传递到消费方的一致性,本案例使用了 RocketMQ作为消息中间件,RocketMQ主要解决了两个功能: 【1】本地事务与消息发送的原子性问题; 【2】事务参与方接收消息的可靠性; 可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦。
上面案例讲到了可靠消息最终一致性的方案用到RocketMQ事务消息,接下来我们详细分析下
RocketMQ在分布式事务中的应用
在分布式系统中,事务处理是一项复杂而关键的任务。传统的 ACID 事务难以跨多个服务和数据库进行操作。RocketMQ 是一个分布式消息中间件,通过其半消息机制,我们可以实现分布式事务的一致性和可靠性。
1.RocketMQ 半消息概述
2.1 半消息的定义
使用普通消息和订单事务无法保证一致的原因,本质上是由于普通消息无法像单机数据库事务一样,具备提交、回滚和统一协调的能力。 而基于 RocketMQ 的分布式事务消息功能,在普通消息基础上,支持二阶段的提交能力。将二阶段提交和本地事务绑定,实现全局提交结果的一致性。
事务消息发送分为两个阶段。第一阶段会发送一个半事务消息,半事务消息是指暂不能投递的消息,生产者已经成功地将消息发送到了 Broker,但是Broker 未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,如果发送成功则执行本地事务,并根据本地事务执行成功与否,向 Broker 半事务消息状态(commit或者rollback),半事务消息只有 commit 状态才会真正向下游投递。
如果由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,Broker 端会通过扫描发现某条消息长期处于“半事务消息”时,需要主动向消息生产者询问该消息的最终状态(Commit或是Rollback)。这样最终保证了本地事务执行成功,下游就能收到消息,本地事务执行失败,下游就收不到消息。总而保证了上下游数据的一致性。
2.2 半消息的工作原理
事务消息发送步骤如下:
-
生产者将half message半事务消息发送至 RocketMQ Broker。
-
RocketMQ Broker 将消息持久化成功之后,向生产者返回 Ack 确认消息已经发送成功,此时消息暂不能投递,为半事务消息。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
-
二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
-
二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
5.在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
6.需要注意的是,服务端仅仅会按照参数尝试指定次数,超过次数后事务会强制回滚,因此未决事务的回查时效性非常关键,需要按照业务的实际风险来设置。
事务消息回查步骤如下:
-
生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。(生产者提供回查记录表不用查复杂业务逻辑)
-
生产者根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理。
-
消费者主要注意不要重复消息,即消息幂等性消费即可
3. 代码实践
3.1 RocketMQ 事务生产者配置
首先,配置 RocketMQ 事务生产者的相关参数,包括 nameserver 地址、生产者组、事务监听器等。
TransactionMQProducer producer = new TransactionMQProducer("transaction_producer_group");
producer.setNamesrvAddr("localhost:9876");
producer.setTransactionListener(new TransactionListenerImpl());
producer.start();
3.2 事务消息的发送
在发送事务消息时,需要使用 TransactionSendResult 的 sendMessageInTransaction 方法,并指定一个实现了 TransactionListener 接口的类。
Message message = new Message("transaction_topic", "transaction_tag", "Transaction Message".getBytes());
TransactionSendResult sendResult = producer.sendMessageInTransaction(message, null);
3.3 事务监听器的实现
在实现 TransactionListener 接口的类中,需要编写本地事务逻辑和消息回查逻辑。
public class TransactionListenerImpl implements TransactionListener {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 执行本地事务逻辑
// 在这里编写执行本地事务的代码,包括数据库操作、服务调用等。
// 本地事务成功,返回 COMMIT_MESSAGE
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
// 本地事务失败,返回 ROLLBACK_MESSAGE
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 消息回查逻辑
// 在这里编写消息回查的代码,根据本地事务的状态返回 COMMIT_MESSAGE、ROLLBACK_MESSAGE 或 UNKNOW。
}
}
3.4 消费者的消息确认
在消费者端,接收到消息后,需要根据本地事务的状态进行确认。
public class MessageListenerImpl implements MessageListenerConcurrently {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
// 处理消息
// 在这里编写处理消息的代码,包括业务逻辑的执行等。
// 根据本地事务状态确认消息
if (transactionState == LocalTransactionState.COMMIT_MESSAGE) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} else if (transactionState == LocalTransactionState.ROLLBACK_MESSAGE) {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}
4. 注意事项
在使用 RocketMQ 的半消息实现分布式事务时,需要注意以下几点:
-
设置合适的回查间隔和次数:根据业务需求和系统性能,设置合理的消息回查间隔和次数,以保证事务的最终一致性。
-
处理消息重复问题:由于消息回查机制的存在,可能会出现消息重复的情况。在消费者端,需要考虑如何处理重复消息,以避免对业务造成影响。
-
保证消息的幂等性:在消息的处理过程中,需要保证消息的幂等性,以防止重复处理已经成功的消息。
-
监控和报警:建立合适的监控和报警机制,及时发现和处理异常情况,保证系统的稳定性和可靠性。
5. 总结
如何使用 RocketMQ 的半消息机制实现分布式事务。通过发送半消息、执行本地事务逻辑、消息回查和消息确认,可以保证消息的可靠处理和一致性。同时,提供了具体的代码示例和最佳实践,帮助读者更好地理解和应用 RocketMQ 的半消息机制。
使用 RocketMQ 的半消息实现分布式事务可以有效解决传统事务在分布式系统中的挑战,并提高系统的可靠性和一致性。在实际应用中,需要根据具体场景进行适当的调整和优化,以满足系统的需求。
注册中心
1. 概念
需求:当一个服务提供者 Service 部署了多个实例交给 User 远程调用时:
服务消费者 User 应该调用哪个实例,如何获取其对应地址和端口? User 如何获知实例是否健康? 注册中心作用: 帮助管理服务,并帮助服务调用者选择并调用服务 实时监测服务实例是否健康
解决方案:
关于注册中心的解决方案,dubbo 支持了 Zookeeper、Redis、Multicast 和 Simple,官方推荐 Zookeeper。Spring Cloud 支持了 Zookeeper、Consul 和 Eureka,官方推荐 Eureka。
Eureka(后面有相信讲解):
微服务之间存在互相调用,既然涉及到调用,那么需要考虑网络通信,进而需要知道各个服务的地址、端口等基础信息。
因此,「注册中心」应运而生,其专门用于处理服务注册、服务信息查找、服务上下线通知。
构成:
eureka-server:服务端,注册中心 记录服务信息,心跳监控 eureka-client:客户端, 服务提供者(注册到服务端,定期向服务端发送心跳)、服务消费者(从服务端拉取服务列表,基于负载均衡选择服务)
作用:
服务注册: Service实例启动后,会将自己的信息注册到注册中心
服务提供者将地址、接口、分组等信息存放在注册中心模块,当服务上线、下线均会通知注册中心
服务发现: 消费端 根据 实例名 获取 Service 地址列表
客户端需要订阅注册中心。在需要远程调用时,从注册中心中获取信息,然后进行方法调用
负载均衡:消费端根据负载均衡算法从服务端地址列表中 选择一个服务实例 心跳检查: Service实例 每隔一段时间(默认30s)就会向 eureka服务端 发起请求,报告自己的状态,当超过一段时间没向 eureka服务端 发送心跳,eureka 就会将此实例从 地址列表中剔除
动态扩容与缩容:在注册中心中注册的服务实例信息可以方便地进行动态的增加和减少。当有新的服务实例上线时,可以自动地将其注册到注册中心。当服务实例下线时,注册中心会将其从服务列表中删除。
提供服务的上下线管理、服务配置管理、服务健康检查等功能,以保证服务的可靠性和稳定性
使用注册中心有以下优势和好处:
-
服务自动发现和负载均衡:服务消费者无需手动配置目标服务的地址,而是通过注册中心动态获取可用的服务实例,并通过负载均衡算法选择合适的实例进行调用。
-
服务弹性和可扩展性:新的服务实例可以动态注册,并在发生故障或需要扩展时快速提供更多的实例,从而提供更高的服务弹性和可扩展性。
-
中心化管理和监控:注册中心提供了中心化的服务管理和监控功能,可以对服务实例的状态、健康状况和流量等进行监控和管理。
-
降低耦合和提高灵活性:服务间的通信不再直接依赖硬编码的地址,而是通过注册中心进行解耦,使得服务的部署和变更更加灵活和可控。
常见注册中心:
Zookeeper
Zookeeper 通过 znode 节点来存储数据。因此可以利用这一特性进行服务注册,节点用于存储服务 IP、端口、协议等信息。
例如:服务提供者上线时,Zookeeper 创建该节点 - /provider/{serviceName}:{ip}:{port} Zookeeper 提供 Watcher 机制,可以监听相应的节点路径。因此我们可以利用这一机制监听对应的路径,一旦路径上的数据发生了变化,我们便向其他订阅该服务的服务发送数据变更消息。收到消息的服务便去更新本地缓存列表。
Zookeeper 提供心跳检测功能,定时向各个服务提供者发送心跳请求,确保各个服务存活。如果服务一直未响应,则说明服务挂了,将该节点删除。
Zookeeper 遵循一致性原则,即 「CP」
对于注册中心而言,最重要的是可用性,我们需要随时能够获取到服务提供者的信息,即使它可能是几分钟以前的旧信息。 但是 Zookeeper 由于其核心算法是 ZAB,主要适用于分布式协调系统(分布式配置、集群管理等场景)。当 master 节点故障后,剩余节点会重新进行 leader 选举,导致在选举期间整个 Zookeeper 集群不可用。
Nacos
服务提供者启动时,会向 Nacos Server 注册当前服务信息,并建立心跳机制,检测服务状态。
服务消费者启动时,从 Nacos Server 中读取订阅服务的实例列表,缓存到本地。并开启定时任务,每隔 10s 轮询一次服务列表并更新。
Nacos Server 采用 Map 保存实例信息。当配置持久化后,该信息会被保存到数据库中。
对于服务健康检查,Nacos 提供了 agent 上报与服务端主动监测两种模式
Nacos 支持 CP 和 AP 架构,根据 ephemeral 配置决定
ephemeral = true,则为 AP ephemeral = false,则为 CP
Eureka
服务提供者启动时,会到 Eureka Server 去注册服务 服务消费者会从 Eureka Server 中定时以全量或增量的方式获取服务提供者信息,并缓存到本地 各个服务会每隔 30s 向 Eureka Server 发送一次心跳请求,确认当前服务正常运行。若 90s 内 Eureka Server 未收到心跳请求,则将对应服务节点剔除。 Eureka 遵循可用性原则,即「AP」。 Eureka 为「去中心化结构」,没有 master / slave 节点之分。只要还有一个 Eureka 节点存活,就仍然可以保证服务可用。但是可能会出现数据不一致的情况,即查到的信息不是最新的。 Eureka 节点收到请求后,会在集群节点间进行复制操作,复制到其他节点中。
Consul
服务提供者启动时,会向 Consul Server 发送一个 Post 请求,注册当前服务信息
服务消费者发起远程调用时,会向 Consul Server 发送一个 Get 请求,获取对应服务的全部节点信息
Consul Server 每隔 10s 会向服务提供者发送健康检查请求,确保服务存活,并更新服务节点列表信息。
Consul 遵循一致性原则,即「CP」
2.数据存储结构
首先注册中心都是k-v的存储结构。存储结构基本类似 key存储服务名:value(map)存储服务ip 端口 配置信息等
zookeeper数据存储结构图
zookeeper 中所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。
整体结构类似于 linux 文件系统的模式以树形结构存储。其中根路径以 / 开头。
进入 zookeeper 安装的 bin 目录,通过sh zkCli.sh打开命令行终端
./zkCli.sh -server localhost:2181
执行 “ls /” 命令显示: 在默认情况下 根目录 / 下只有zookeeper一个节点,我们也可以手动的加节点 可以通过get命令来查看节点的值
其中第一行显示的 abc 是该节点的 value 值。
Znode的组成部分
Znode 的data(数据)
get /test
Znode的acl(权限)
Znode的stat(元数据)
-
cZxid 创建节点时的事务ID
-
ctime 创建节点时的时间
-
mZxid 最后修改节点时的事务ID
-
mtime 最后修改节点时的时间
-
pZxid 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid)
-
cversion 子节点版本号,子节点每次修改版本号加1
-
dataversion 数据版本号,数据每次修改该版本号加1
-
aclversion 权限版本号,权限每次修改该版本号加1
-
ephemeralOwner 创建该临时节点的会话的sessionID。(如果该节点是持久节点,那么这个属性值为0)
-
dataLength 该节点的数据长度
-
numChildren 该节点拥有子节点的数量(只统计直接子节点的数量) 了解上面状态属性值,我们对 /test 节点做一次修改,执行命令 set /test ccc
set /test ccc
对比上面结果,可以看到 mZxid、mtime、dataVersion 都发生了变化。
Zonde的child(子节点)
ls /节点路径 ls /test 获取test节点的子节点
Znode节点类型 在3.6.2版本中
-
PERSISTENT:持久化节点,在会话结束后依然存在,不会随客户端的断开而自动删除,默认类型
-
PERSISTENT_SEQUENTIAL:持久序号节点,创建出的节点,根据创建先后顺序,会在节点后带一个数值,znode的名字将被附加一个单调递增的数字,越往后数值越大,适用于分布式锁的应用场景
-
EPHEMERAL:临时节点,当客户端断开时自动删除,通过这个特性,zk可以实现服务注册与发现的效果
-
EPHEMERAL_SEQUENTIAL:带序号的临时节点,znode的名字将被附加一个单调递增的数字
-
CONTAINER(3.5.3版本新增):Container容器节点,当容器中没有任何子节点,该容器节点会被zk定期删除(60s)
-
PERSISTENT_WITH_TTL:zookeeper的扩展类型,如果znode在给定的TTL内没有被修改,它将在没有子节点时被删除。要想使用该类型,必须在zookeeper的bin/zkService.sh中的启动zookeeper的java环境中设置环境变量zookeeper.extendedTypesEnabled=true(具体做法在下边),否则KeeperErrorCode = Unimplemented for /**。
-
PERSISTENT_SEQUENTIAL_WITH_TTL:同上,是不过是带序号的
eureka数据存储结构图
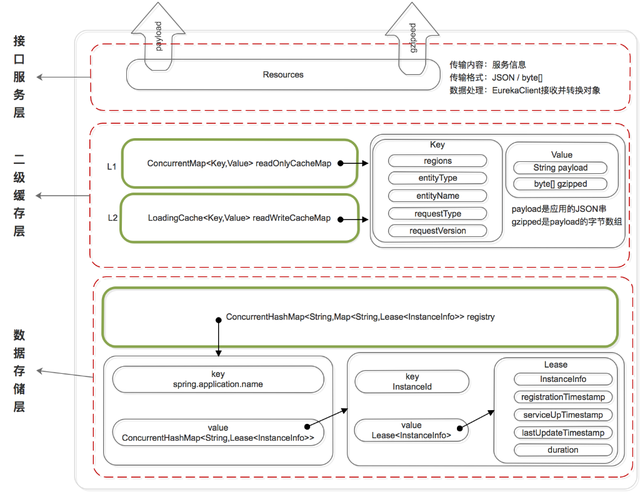
-
Eureka 的数据存储分了两层:数据存储层和缓存层。
Eureka Client 在拉取服务信息时,先从缓存层获取(相当于 Redis),如果获取不到,先把数据存储层的数据加载到缓存中(相当于 Mysql),再从缓存中获取。值得注意的是,数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到 Eureka Client 的数据结构。
(1)数据存储层
第一层的 key 是spring.application.name,value 是第二层 ConcurrentHashMap;第二层 ConcurrentHashMap 的 key 是服务的 InstanceId,value 是 Lease 对象;Lease 对象包含了服务详情和服务治理相关的属性。
-
更新一级缓存:
Eureka Server 内置了一个 TimerTask,定时将二级缓存中的数据同步到一级缓存(这个动作包括了删除和加载)。
(2)二级缓存层
一级缓存:ConcurrentHashMap<Key,Value> readOnlyCacheMap,本质上是 HashMap,无过期时间,保存服务信息的对外输出数据结构。
二级缓存:Loading<Key,Value> readWriteCacheMap,本质上是 guava 的缓存,包含失效机制,保存服务信息的对外输出数据结构。
-
二级缓存的更新机制:
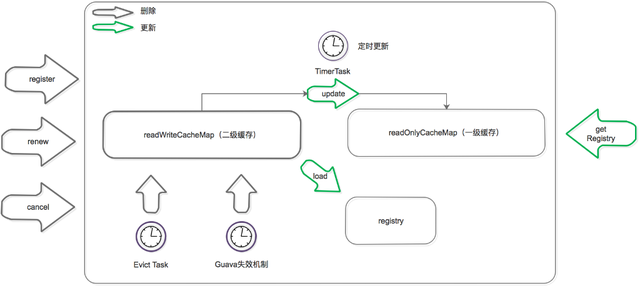
eureka二级缓存的更新机制
-
删除二级缓存:
1、Eureka Client 发送 register、renew 和 cancel 请求并更新 registry 注册表之后,删除二级缓存;2、Eureka Server 自身的 Evict Task 剔除服务后,删除二级缓存;3、二级缓存本身设置了 guava 的失效机制,隔一段时间后自己自动失效;
-
加载二级缓存:
1、Eureka Client 发送 getRegistry 请求后,如果二级缓存中没有,就触发 guava 的 load,即从 registry 中获取原始服务信息后进行处理加工,再加载到二级缓存中。2、Eureka Server 更新一级缓存的时候,如果二级缓存没有数据,也会触发 guava 的 load。
-
重点关注:ResponseCacheImpl类
3、eureka高可用原理分析
-
前面讲了eureka是基于AWS开发出来的框架,因此eureka天生的支持region和availabilityZone的概念。
1、默认情况下面不同region是相互隔离的,region之间的数据是不会复制的,但是eureka client提供了fetch-remote-regions-registry配置,作用是拉取远程的注册信息到本地2、availabilityZone,eureka中默认eureka-client-prefer-zone-eureka配置为true,也就是拉取serverUrl时候,默认选取和应用实例同一个zone的eureka server列表。
1、客户端高可用原理
(1)在client启动之前,如果没有eureka server,则通过配置eureka.client.back-registry-impl从备份的registry读取关键服务的信息。(2)在client启动后,如果运行时候server全部挂掉了,本地内存有localRegion之前获取的数据。(3)如果是server部分挂了。如果预计恢复时间比较长,可以人工介入,通过配置中心人工摘除服务(但是基本不用这样做)。在client中会维护一份不可用的server列表,一旦心跳时候失败,当该列表的大小超过指定的阈值时候就会进行重新清空,重新清空后,client会进行重试(默认3次)
2、服务端高可用原理
-
服务端采用peer to peer的架构模式,原则上就是高可用的。同时服务端还可以通过配置remoteRegionUrlsWithName来支持拉取远程的region实例,如果当前的region挂了,会自动fallback到远程的region获取数据
-
同时服务端采用renew租约和定时心跳的方式保护注册信息(self preservation机制
4.服务搭建
依赖导入
依赖:
springboot 与 springcloud 的版本对应关系 
父项目依赖 我用的是2.6.11版本的springboot,所以要选择2021.0.5版本的springcloud
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring.cloud-version>2021.0.5</spring.cloud-version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
子项目依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
-
配置文件 我们需要将 eureka 注册到spring容器中,所以需要在配置文件中做相关配置。
server:
port: 8099
spring:
application:
name: eureka_server
eureka:
client:
# 配置eureka服务地址
service-url:
defaultZone: http://127.0.0.1:8099/eureka
-
启动项目 为了让项目能启动 eureka,需要在启动类上加一个注解:
3. @EnableEurekaServer
@SpringBootApplication
@EnableEurekaServer
public class ServerApplication {
public static void main(String[] args) {
SpringApplication.run(ServerApplication.class, args);
}
}
启动项目,访问地址:http://127.0.0.1:8099:
启动项目,访问地址:http://127.0.0.1:8099:
注册的服务名称就是配置文件中的名称的大写。
-
服务注册
在上一步,已经将 eureka-server (eureka服务中心)搭建完毕,现在就开始注册服务实例了。
-
依赖导入
注意:
无论是 服务提供者 还是 服务消费者,他们的身份都是 eureka-client
记得添加 spring-boot-starter-web 的依赖,不然会报错:Field optionalArgs in org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration$RefreshableEurekaClientConfiguration required a bean of type ‘com.netflix.discovery.AbstractDiscoveryClientOptionalArgs’ that could not be found.
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
服务发现、服务注册统一都封装在eureka-client依赖。
-
配置文件
需要在配置文件中配置 eureka-server 的地址。
spring:
application:
name: service_provider
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8099/eureka
-
启动多个实例
为了让项目能启动 eureka,需要在启动类上加一个注解:
3. @EnableEurekaClient。
@SpringBootApplication
@EnableEurekaClient
public class ProviderApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderApplication.class, args);
}
}
我们可以通过 IDEA 自带功能模仿启动多个服务实例。
我们可以通过 IDEA 自带功能模仿启动多个服务实例。
打开 Service 面板
复制原来的 provider 启动配置
查看 eureka注册中心
-
服务发现
-
依赖导入
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
-
配置文件
spring:
application:
name: service_user
server:
port: 8084
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8099/eureka
服务拉取和负载均衡
服务拉取:
修改 controller 代码,将 url 路径的 ip、端口 修改为 服务名:
@RestController
@RequestMapping("user")
public class UserController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public Book getBookById(@PathVariable("id") Integer id) {
// String url = "http://127.0.0.1:8081/provider" + id;
String url = "http://service_provider/provider";
if (id != null) {
url = url + id;
}
Book book = restTemplate.getForObject(url, Book.class);
return book;
}
}
注册 RestTemplate 的时候加上注解 @LoadBalanced
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
接口调用:
@RestController
@RequestMapping("user")
public class UserController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public Book getBookById(@PathVariable("id") Integer id) {
// String url = "http://127.0.0.1:8081/provider" + id;
String url = "http://PROVIDER/pro/";
if (id != null) {
url = url + id;
}
Book book = restTemplate.getForObject(url, Book.class);
return book;
}
}
访问接口:
访问报错:
解决方案: 命名别带下划线。

多测试几下接口,可以发现,user一会儿调用的是 provider:8081 一会儿调用的是 provider:8082。这就是负载均衡算法选择的。
-
小结
eureka-server 搭建:
引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
启动类添加 @EnableEurekaServer
启动类添加 @EnableEurekaServer
配置文件配置 eureka 地址
server:
port: 8099
spring:
application:
name: server
eureka:
client:
# 配置eureka服务地址
service-url:
defaultZone: http://127.0.0.1:8099/eureka
服务注册:
服务注册:
引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
启动类添加 @EnableEurekaClient 配置文件配置 eureka 地址
server:
port: 8081
spring:
application:
name: provider
eureka:
client:
# 配置eureka服务地址
service-url:
defaultZone: http://127.0.0.1:8099/eureka
服务发现:
启动类添加 @EnableEurekaClient 配置文件配置 eureka 地址
服务发现:
引入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
启动类添加 @EnableEurekaClient 配置文件配置 eureka 地址
server:
port: 8089
spring:
application:
name: user
eureka:
client:
# 配置eureka服务地址
service-url:
defaultZone: http://127.0.0.1:8099/eureka
启动类添加 @EnableEurekaClient 配置文件配置 eureka 地址
-
Ribbon
-
负载均衡流程 Ribbon负载均衡流程图:
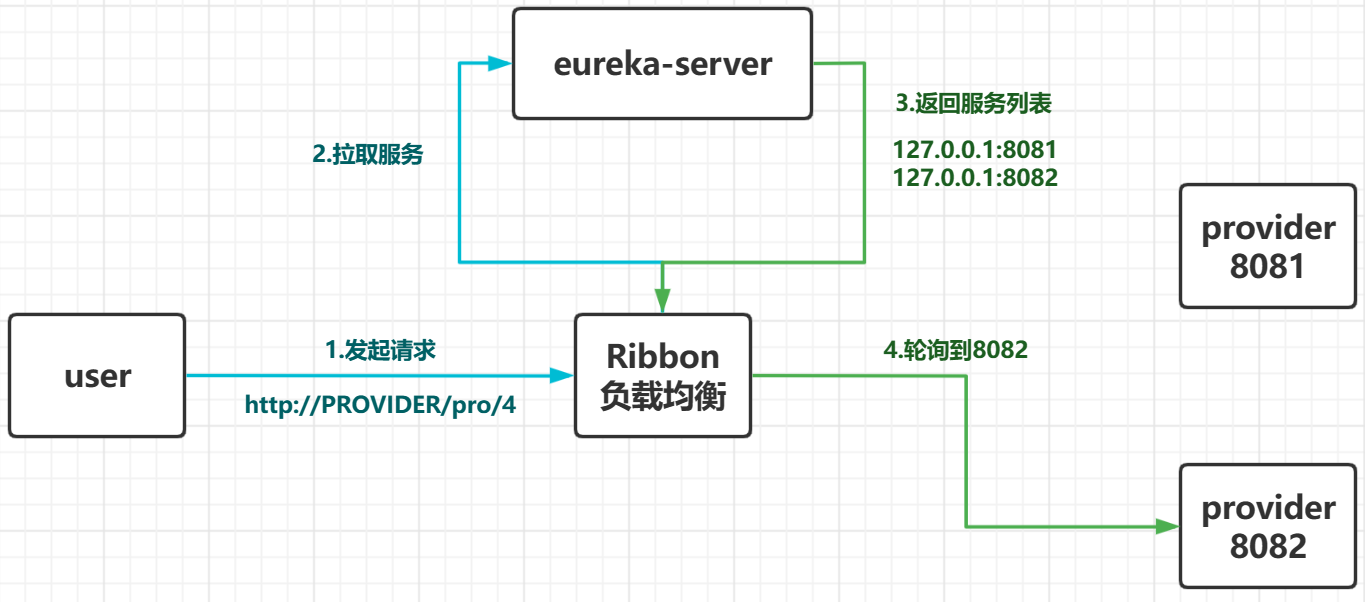
http://PROVIDER/pro/4 并非真实的地址,这个需要Ribbon负载均衡去拦截,然后选择具体的服务地址。而,Ribbon就是通过 LoadBalancerInterceptor 的 intercept 方法来实现拦截请求并解析选择地址。
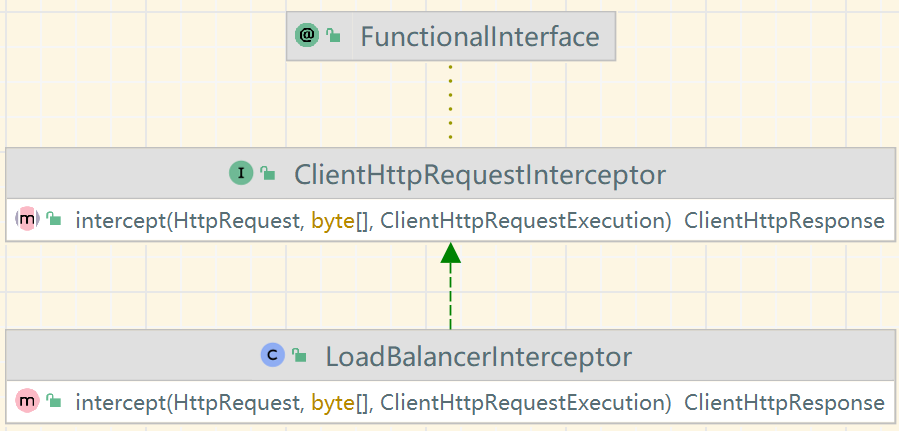
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));
}
负载均衡流程:
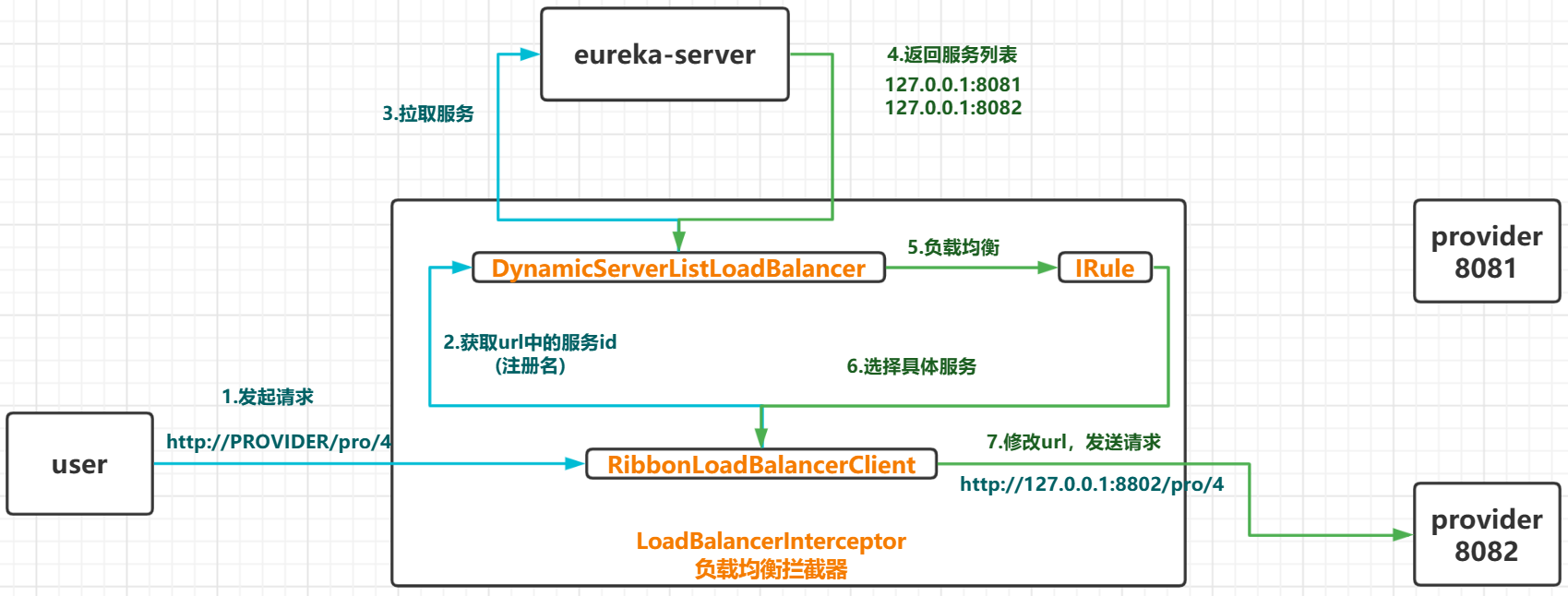
-
负载均衡策略 Ribbon的负载均衡策略是由 IRule 接口来定义的。
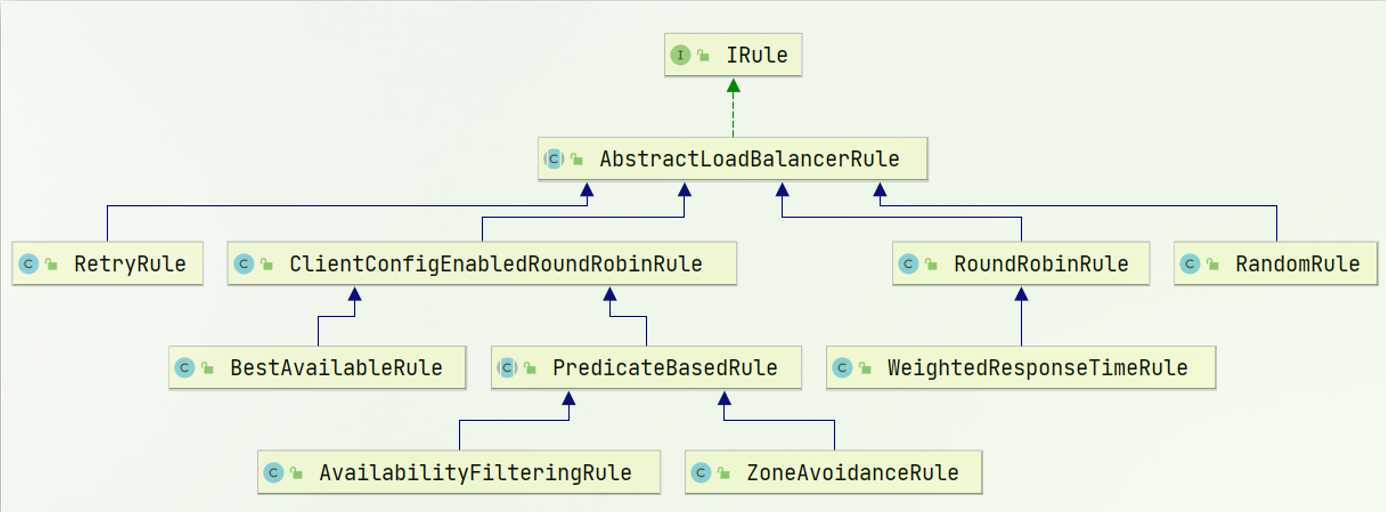
IRule常见规则:
自定义负载均衡策略:
方式一: 在user中,@Bean 注入自定义 IRule
@Bean
public IRule randomRule(){
return new RandomRule();
}
方式二: 在user,配置文件修改 IRule
provider: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意: 方式一的作用范围是:在访问任何微服务的时候,都是使用 RandomRule 负载均衡策略;方式二的作用范围是:在访问 provider 微服务的时候才是采用 RandomRule 策略,其他的还是使用默认策略。
-
加载策略 Ribbon默认采用懒加载,即会在第一次访问时才会去创建 LoadBalanceClient ,所以会在第一次请求的时候花上较长的等待时间。
可以通过配置文件更改加载策略为饿加载策略,即初始化时就创建 LoadBalanceClient ,降低第一次访问的耗时。
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients: provider # 指定饥饿加载的服务名称
微服务的各个组件和常见实现:
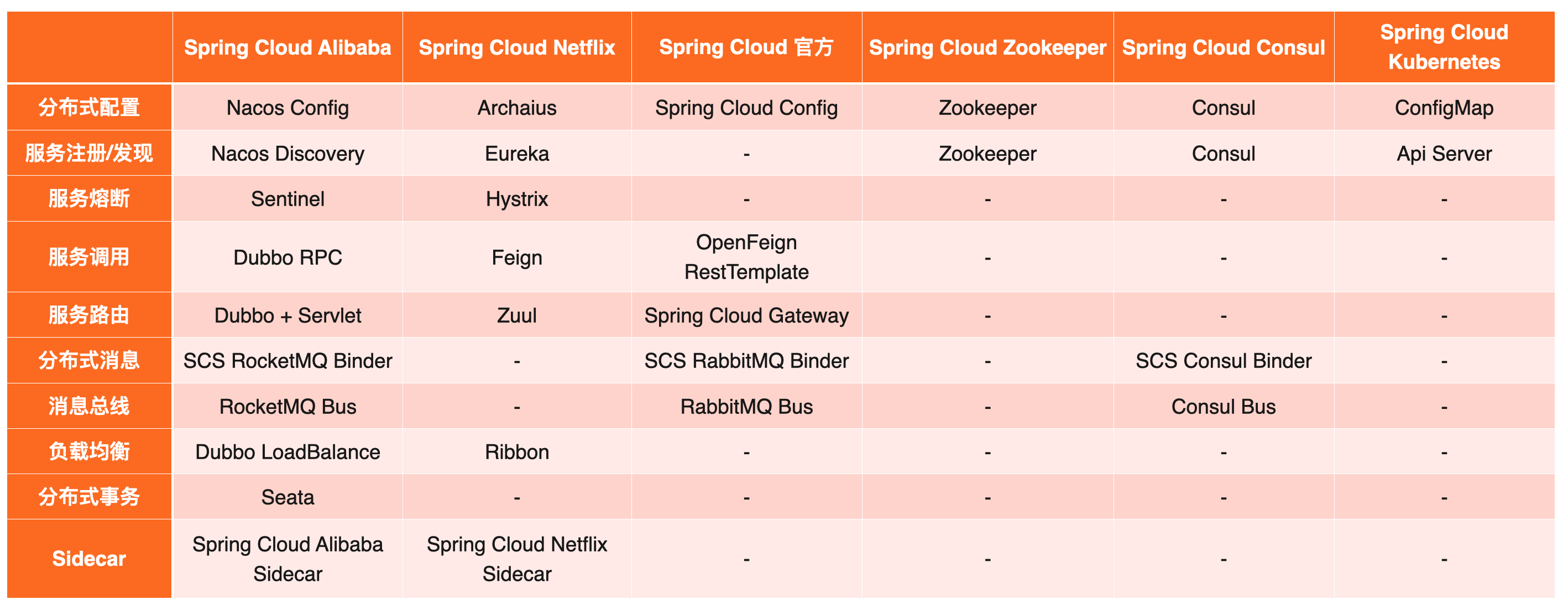
-
注册中心:用于服务的注册与发现,管理微服务的地址信息。常见的实现包括:
-
-
Spring Cloud Netflix:Eureka、Consul
-
Spring Cloud Alibaba:Nacos
-
-
配置中心:用于集中管理微服务的配置信息,可以动态修改配置而不需要重启服务。常见的实现包括:
-
-
Spring Cloud Netflix:Spring Cloud Config
-
Spring Cloud Alibaba:Nacos Config
-
-
远程调用:用于在不同的微服务之间进行通信和协作。常见的实现保包括:
-
-
RESTful API:如RestTemplate、Feign
-
RPC(远程过程调用):如Dubbo、gRPC
-
-
API网关:作为微服务架构的入口,统一暴露服务,并提供路由、负载均衡、安全认证等功能。常见的实现包括:
-
-
Spring Cloud Netflix:Zuul、Gateway
-
Spring Cloud Alibaba:Gateway、Apisix等
-
-
分布式事务:保证跨多个微服务的一致性和原子性操作。常见的实现包括:
-
-
Spring Cloud Alibaba:Seata
-
-
熔断器:用于防止微服务之间的故障扩散,提高系统的容错能力。常见的实现包括:
-
-
Spring Cloud Netflix:Hystrix
-
Spring Cloud Alibaba:Sentinel、Resilience4j
-
-
限流和降级:用于防止微服务过载,对请求进行限制和降级处理。常见的实现包括:
-
-
Spring Cloud Netflix:Hystrix
-
Spring Cloud Alibaba:Sentinel
-
-
分布式追踪和监控:用于跟踪和监控微服务的请求流程和性能指标。常见的实现包括:
-
-
Spring Cloud Netflix:Spring Cloud Sleuth + Zipkin
-
Spring Cloud Alibaba:SkyWalking、Sentinel Dashboard
-
RESTful风格
是一种基于HTTP协议设计Web API的软件架构风格,由Roy Fielding在2000年提出。
REST全称为Representational State Transfer,中文为表现层状态转移
它强调使用HTTP动词来表示对资源的操作(GET、POST、PUT、PATCH、DELETE等),并通过URI表示资源的唯一标识符。
用于在不同的微服务之间进行通信和协作。常见的实现包括:
-
-
RESTful API:如RestTemplate、Feign
-
RPC(远程过程调用):如Dubbo、gRPC
-
REST是就是将一个接口动作的描述进行拆分,拆分成资源与动作两个部分。其中,资源就是对描述资源位置,资源表征则是这些资源应该如何展示出来(具体是JSON还是XML),而状态转移则可以简单的理解成正对这个资源所进行的动作。
REST的正是通过将这两种核心定义的逻辑进行分离、标准化,从而让对于“接口”、“操作”的定义更加便于理解
资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
RESTful优势
轻量,直接基于http的GET、POST、PUT、DELETE,不再需要任何别的诸如消息协议;面向资源,一目了然,具有自解释性。
一、RESTful API的设计原则
RESTful API的设计遵循以下几个原则:
-
基于资源:将数据和功能抽象成资源,并通过URI来唯一标识资源。例如,一个用户资源可以通过URL“/users/{id}”来访问,其中“{id}”表示该用户的唯一标识符。
-
使用HTTP动词:使用HTTP动词来表示对资源的操作,如GET(获取资源)、POST(创建资源)、PUT(更新资源)和DELETE(删除资源)等。
-
无状态:每个请求都包含足够的信息来完成请求,服务器不需要保存任何上下文信息。
-
统一接口:使用统一的接口来简化客户端与服务器之间的交互,包括资源标识符、资源操作和响应消息的格式。
-
可缓存性:客户端可以缓存响应,以提高性能和减少网络流量。
-
分层系统:将系统分为多个层次,每个层次处理特定的功能。
RESTful风格的API设计具有良好的可读性、易用性和可扩展性,广泛应用于Web应用程序和移动应用程序的API设计中。
误区
RESTful架构有一些典型的设计误区。
最常见的一种设计错误,就是URI包含动词。因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计错了,正确的写法应该是/posts/1,然后用GET方法表示show。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户1向账户2汇款500元,错误的URI是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词transfer改成名词transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1 Host: 127.0.0.1 from=1&to=2&amount=500.00
另一个设计误区,就是在URI中加入版本号:
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services:Versioning REST Services | Hypermedia as the Engine of Application State | InformIT):
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
二、使用到的注解
(1)@RequestMapping
-
类型 方法注解
-
位置 SpringMVC控制器方法定义上方
-
作用 设置当前控制器方法请求访问路径
-
范例
@RequestMapping(value = "/users", method = RequestMethod.GET)
@ResponseBody
public String save()
{
System.out.println("save user");
return " '{'module': 'user save' }' ";
}
-
属性
-
value 请求访问路径
-
method http请求动作,标准动作(GET、POST、PUT、DELETE)
(2)@PathVariable
-
类型 形参注解
-
位置 SpringMVC控制器方法形参定义前面
-
作用 绑定路径参数与处理器方法形参间的关系,要求路径参数名与形参名一一对应
-
范例
@RequestMapping(value = "users/{id}", method = RequestMethod.DELETE)
@ResponseBody
public String delete(@PathVariable Integer id) // PathVariable 路径参数 id对应路径中的id
{
System.out.println("delete user");
return "'{'module': 'user delete'}'";
}
(3)@RestControll
-
类型 类注解
-
位置 基于SpringMVC的RESTful开发控制器类定义上方
-
作用 设置当前控制器类为RESTful风格,等同于 @Controller 与 @ResponseBody两个注解的组合功能
-
范例
@RestController
public class UserController
{
@RequestMapping(value = "/users",method = RequestMethod.GET)
public String save()
{
System.out.println("save user");
return " '{'module': 'user save' }' ";
}
(4)@GetMapping @PostMapping @PutMapping @DeleteMapping
-
类型 方法注解
-
位置 基于SpringMVC的RESTful开发控制器方法定义上方
-
作用 设置当前控制器方法请求访问路径与请求动作,每种对应一个请求动作
-
范例
@RestController
@RequestMapping("/users") // 下面的每个控制器方法的请求路径都有前缀 /users
public class UserController
{
@GetMapping("/{id}")
public String getById(@PathVariable Integer id)
{
return "getById";
}
}
(5)@RequestBody @RequestParam @PathVariable
区别
-
RequestParam 用于接收URL地址传参或表单传参
-
RequestBody 用于接收JSON数据
-
PathVariable 用于接收路径参数,使用 {参数名} 描述路径参数
应用
-
-
后期开发中,发送请求参数超过1个时,以JSON格式为主,所以@RequestBody应用较广泛
-
如果发送非JSON格式数据,选用 @RequestParam 接收请求参数
-
当参数数量只有一个时,或为数字时,可以采用 @PathVariable接收请求路径变量,通常传递id值
-
三、综合案例
这里提供一个简单的Java示例,用于实现一个基本的RESTful API。假设我们正在开发一个学生管理系统,需要使用RESTful API来实现对学生资源的增删改查操作。
首先,我们需要定义一个表示学生信息的Java类:
public class Student {
private int id;
private String name;
private int age;
public Student() { }
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
// Getters and setters
}
然后,我们需要创建一个控制器类来处理客户端请求:
@RestController
@RequestMapping("/students")
public class StudentController {
// Mock data - replace with database queries later
private static List<Student> students = new ArrayList<>(Arrays.asList(
new Student(1, "Alice", 20),
new Student(2, "Bob", 21),
new Student(3, "Charlie", 22)
));
// GET /students - get all students
@GetMapping("")
public List<Student> getAllStudents() {
return students;
}
// GET /students/{id} - get a student by id
@GetMapping("/{id}")
public Student getStudentById(@PathVariable int id) {
for (Student s : students) {
if (s.getId() == id) {
return s;
}
}
return null; // Return null if student not found
}
// POST /students - create a new student
@PostMapping("")
public ResponseEntity<String> createStudent(@RequestBody Student student) {
students.add(student);
return ResponseEntity.status(HttpStatus.CREATED).build();
}
// PUT /students/{id} - update an existing student
@PutMapping("/{id}")
public ResponseEntity<String> updateStudent(@PathVariable int id, @RequestBody Student updatedStudent) {
for (int i = 0; i < students.size(); i++) {
if (students.get(i).getId() == id) {
students.set(i, updatedStudent);
return ResponseEntity.status(HttpStatus.OK).build();
}
}
return ResponseEntity.status(HttpStatus.NOT_FOUND).build(); // Return 404 if student not found
}
// DELETE /students/{id} - delete a student by id
@DeleteMapping("/{id}")
public ResponseEntity<String> deleteStudentById(@PathVariable int id) {
for (int i = 0; i < students.size(); i++) {
if (students.get(i).getId() == id) {
students.remove(i);
return ResponseEntity.status(HttpStatus.OK).build();
}
}
return ResponseEntity.status(HttpStatus.NOT_FOUND).build(); // Return 404 if student not found
}
}
这个控制器类中定义了四个HTTP方法,分别处理对学生资源的不同操作。我们使用Spring Boot框架和Spring MVC模块来实现RESTful API,并使用注解来定义路由和请求处理逻辑。
最后,我们需要在应用程序的入口点(如Spring Boot的main方法)中启动应用程序:
@SpringBootApplication
public class StudentManagementSystemApplication {
public static void main(String[] args) {
SpringApplication.run(StudentManagementSystemApplication.class, args);
}
}
这样,我们就创建了一个简单的RESTful API,可以通过发送HTTP请求来执行学生管理系统的基本操作
熔断
1.1 熔断来源
词典解释:保险丝烧断 保险丝也被称为熔断器。
在90年代很多电闸都有保险丝,现在都是空气开关,当电压出现短路问题时,保险丝过热,因为是铅丝熔点低于铜铁,所以短路造成线路温度升高,导致铅丝融化,线路断开。此刻电路主动断开,我们的电器就会受到到保护。否则,可能造成火灾等严重后果。
保险丝就是一个自我保护装置,保护整个电路。此概念被引入多个行业,我们要了解的是分布式系统中的熔断。
1.2 分布式系统中的熔断
在分布式系统中,不同的服务互相依赖,某些服务需要依赖下游服务,下游服务不管是内部系统还是第三方服务,如果出现问题,我们还是盲目地持续地去请求,即使失败了多次,还是不断的去请求,去等待,就可能造成系统更严重的问题。
1、等待增加了整个链路的请求时间。
2、下游系统有问题,不断的请求导致下游系统有持续的访问压力难以恢复。
3、等待时间过长造成上游服务线程阻塞,CPU被拉满等问题。
4、可能导致服务雪崩。
1.3 熔断的作用
熔断模式可以防止应用程序不断地尝试请求下游可能超时和失败的服务,可以不必等待下游服务的修复而达到应用程序可执行的状态。
1.4为什么要使用熔断器
熔断器模式最重要的是能让应用程序自我诊断下游系统的错误是否已经修正,如果没有,不放量去请求,如果请求成功了,慢慢的增加请求,再次尝试调用。
熔断机制是一种保护分布式系统可用性的重要手段。通过快速切断对故障服务的请求,熔断机制可以避免故障扩散,保护整个系统的稳定性。同时,熔断机制还可以提供更好的用户体验,避免用户长时间等待或者看到错误提示。在分布式系统中,合理使用熔断机制可以提高系统的可靠性和稳定性,为用户提供更好的服务。
熔断有三种状态:
1.Closed:关闭状态
所有请求都正常访问。
2.Open:打开状态 所有请求都会被降级
在关闭状态下,熔断器会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全打开。一般默认失败比例的阈值是50%,请求次数最少不低于20次。
3.Half Open:半开状态 允许部分请求通过
open状态不是永久的,在熔断器开启状态打开后会进入休眠时间(一般默认是5S)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会完全关闭断路器,否则继续保持打开,再次进行休眠计时。
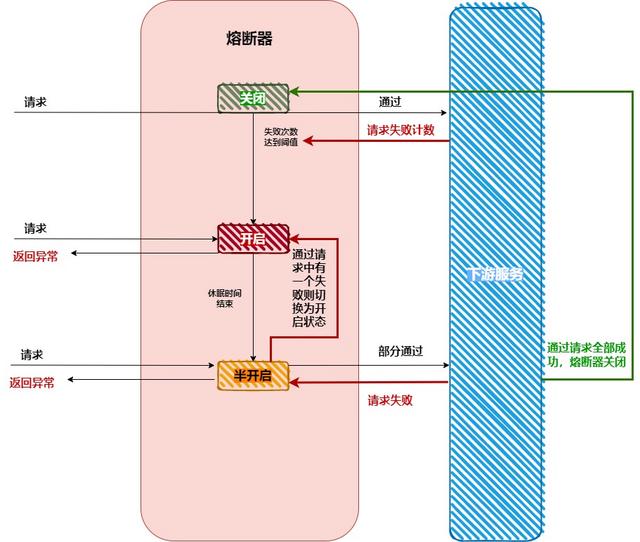
熔断器开源组件
1.Hystrix
Hystrix(豪猪--->身上很多刺--->保护自己),宣“defend your app”,是由Netflflix开源的个延迟和容错库,于隔离访问远程系统、服务或者第三库,防级联失败,从而提升系统的可性与容错性。Hystrix主要通过以下几点实现延迟和容错。
包裹请求:使⽤HystrixCommand包裹对依赖的调⽤逻辑。 ⾃动投递微服务⽅法(@HystrixCommand 添加Hystrix控制) ——调⽤简历微服务跳闸机制:当某服务的错误率超过⼀定的阈值时,Hystrix可以跳闸,停⽌请求该服务⼀段时间。
资源隔离:Hystrix为每个依赖都维护了⼀个⼩型的线程池(舱壁模式)(或者信号量)。如果该线程池已满, 发往该依赖的请求就被⽴即拒绝,⽽不是排队等待,从⽽加速失败判定。
监控:Hystrix可以近乎实时地监控运⾏指标和配置的变化,例如成功、失败、超时、以及被拒绝 的请求等。
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执⾏回退逻辑。回退逻辑由开发⼈员 ⾃⾏提供,例如返回⼀个缺省值。
⾃我修复:断路器打开⼀段时间后,会⾃动进⼊“半开”状态。
2.Resilience4j
Resilience4j是一款轻量级,易于使用的容错库,其灵感来自于Netflix Hystrix,但是专为Java 8和函数式编程而设计。轻量级,因为库只使用了Vavr,它没有任何其他外部依赖下。相比之下,Netflix Hystrix对Archaius具有编译依赖性,Archaius具有更多的外部库依赖性,例如Guava和Apache Commons Configuration。
Resilience4j与Hystrix主要区别:
1.Hystrix调用必须被封装到HystrixCommand里,Resilience4j以装饰器的方式提供对函数式接口、lambda表达式等的嵌套装饰,因此你可以用简洁的方式组合多种高可用机制。
2.Hystrix采用滑动窗口方式统计频次,Resilience4j采用环形缓冲区
3.半开启状态下,Hystrix进使用一次执行判断是否进行状态转换,Resilience4j则可配置执行次数与阈值,通过配置参数执行判断是否进行状态转换,这种方式提高了熔断机制的稳定性。
4.Hystrix采用基于线程池和信号量的隔离,而resilience4j只提供基于信号量的隔离
3.Sentinel
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应过载保护、热点流量防护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
-
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
-
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
-
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
-
完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Hystrix健康统计滑动窗口的执行流程:
1)HystrixCommand命令器的执行结果(失败、成功)会以事件的形式通过RxJava事件流弹射出去,形成执行完成事件流。2)桶计数流以事件流作为来源,将事件流中的事件按照固定时间长度(桶时间间隔)划分成滚动窗口,并对时间桶滚动窗口内的事件按照类型进行累积,完成之后将桶数据弹射出去,形成桶计数流。3)桶滑动统计流以桶计数流作为来源,按照步长为1、长度为设定的桶数(配置的滑动窗口桶数)的规则划分滑动窗口,并对滑动窗口内的所有的桶数据按照各事件类型进行汇总,汇总成最终的窗口健康数据并弹射出去,形成最终的桶滑动统计流,作为Hystrix熔断器进行状态转换的数据支撑。
代码实现




降级
服务降级
由于爆炸性的流量冲击,对一些服务进行有策略的放弃(备用方案),以此缓解系统压力,保证目前主要业务的正常运行。它主要是针对非正常情况下的应急服务措施:当此时一些业务服务无法执行时,给出一个统一的返回结果。
为什么要降级?
降级最主要解决的是资源不足和访问量增加的矛盾,在有限的资源情况下,可以应对高并发大量请求。那么在有限的资源情况下,想要达到以上效果就需要对一些服务功能进行一些限制,放弃一些功能,保证整个系统能够平稳运行。
降级的方式有哪些?
1、将强一致性变成最终一致性,不需要强一致性的功能,可以通过消息队列进行削峰填谷,变为最终一致性达到应用程序想要的效果。
2、停止访问一些次要功能,释放出更多资源。比如双十一不让退货等。
3、简化功能流程,把一些复杂的流程简化。提高访问效率。
4,降级评判 对于服务是否进行降级,首先要判定当前的服务是否能够在降级下不影响整体系统的允许(比如购物车添加功能,不太适合降级)
5,降级等级 降级按照是否自动化可分为:自动开关降级和人工开关降级 降级按照功能分为:读服务降级和写服务降级 降级按照处于系统层次可分为:多级降级
总的来说降级方式:
延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。 在粒度范围内关闭服务(片段降级或服务功能降级):比如关闭相关文章的推荐,直接关闭推荐区 页面异步请求降级:比如商品详情页上有推荐信息/配送至等异步加载的请求,如果这些信息响应慢或者后端服务有问题,可以进行降级; 页面跳转(页面降级):比如可以有相关文章推荐,但是更多的页面则直接跳转到某一个地址 写降级:比如秒杀抢购,我们可以只进行Cache的更新,然后异步同步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
自动降级的条件
-
调用失败次数达到阈值
-
请求响应超时时间达到阈值
-
请求下游服务发生故障通过状态码
-
流量达到阈值触发服务降级
怎样实现降级?
降级开源组件:sentinel和Hystrix
手动降级:可采用系统配置开关来控制
熔断和降级的区别:
其实可以认为:服务熔断是服务降级的措施。
1,服务熔断和服务降级的比较 1,服务熔断对服务提供了proxy,防止服务不可能时,出现串联故障(cascading failure),导致雪崩效应。 2,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑。
共性:都是系统自我保护的一种机制
目的 -> 都是从可用性、可靠性出发,提高系统的容错能力。 最终表现->使某一些应用不可达或不可用,来保证整体系统稳定。 粒度 -> 一般都是服务级别,但也有细粒度的层面:如做到数据持久层、只许查询不许增删改等。 自治 -> 对其自治性要求很高。都要求具有较高的自动处理机制。
区别:
它们的区别主要体现在以下几点:
1.概念不同
1.1 熔断概念
“熔断”一词早期来自股票市场。熔断(Circuit Breaker)也叫自动停盘机制,是指当股指波幅达到规定的熔断点时,交易所为控制风险采取的暂停交易措施。比如 2020 年 3 月 9 日,纽约股市开盘出现暴跌,随后跌幅达到 7% 上限,触发熔断机制,停止交易 15 分钟,恢复交易后跌幅有所减缓。
而熔断在程序中,表示“断开”的意思。如发生了某事件,程序为了整体的稳定性,所以暂时(断开)停止服务一段时间,以保证程序可用时再被使用。
如果没有熔断机制的话,会导致联机故障和服务雪崩等问题,如下图所示:
1.2 降级概念
降级(Degradation)降低级别的意思,它是指程序在出现问题时,仍能保证有限功能可用的一种机制。
比如电商交易系统在双 11 时,使用的人比较多,此时如果开放所有功能,可能会导致系统不可用,所以此时可以开启降级功能,优先保证支付功能可用,而其他非核心功能,如评论、物流、商品介绍等功能可以暂时关闭。
所以,从上述信息可以看出:降级是一种退而求其次的选择,而熔断却是整体不可用。
2.触发条件不同
不同框架的熔断和降级的触发条件是不同的,本文咱们以经典的 Spring Cloud 组件 Hystrix 为例,来说明触发条件的问题。
2.1 Hystrix 熔断触发条件
默认情况 hystrix 如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔 5 秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求。
2.2 Hystrix 降级触发条件
默认情况下,hystrix 在以下 4 种条件下都会触发降级机制:
方法抛出 HystrixBadRequestException
方法调用超时
熔断器开启拦截调用
线程池或队列或信号量已满
虽然 hystrix 组件的触发机制,不能代表所有的熔断和降级机制,但足矣说明此问题。
3.归属关系不同
熔断时可能会调用降级机制,而降级时通常不会调用熔断机制。因为熔断是从全局出发,为了保证系统稳定性而停用服务,而降级是退而求其次,提供一种保底的解决方案,所以它们的归属关系是不同(熔断 > 降级)。
题外话 当然,某些框架如 Sentinel,它早期在 Dashboard 控制台中可能叫“降级”,但在新版中新版本又叫“熔断”,如下图所示:但在两个版本中都是通过同一个异常类型 DegradeException 来监听的,如下代码所示:所以,在 Sentinel 中,熔断和降级功能指的都是同一件事,也侧面证明了“熔断”和“降级”概念的相似性。但我们要知道它们本质上是不同的,就像两个双胞胎,不能因为他们长得像,就说他们是同一个人。
总结
熔断和降级都是程序在我保护的一种机制,但二者在概念、触发条件、归属关系上都是不同的。熔断更偏向于全局视角的自我保护(机制),而降级则偏向于具体模块“退而请其次”的解决方案。
微服务设计
微服务划分目标
首先要明白,服务不是越细越好,服务划分的第一要素是先以业务域拆分,再以技术视角拆分,结合团队的规模、能力确定服务间的关系与边界。
我们常说服务的合理划分是微服务成功的重中之重,一个合理的服务划分应该符合一下几点:
1,符合团队结构:
服务的落地与维护靠人,靠的是执行团队(包含业务、产品、技术、测试与运维团队),所以服务的设定一定是与团队结构相辅相成的,同一个系统不同的执行团队往往会有不同的且都合理的服务划分方案
2,业务边界清晰:
各服务有清晰的责任及边界,一个服务对应一块业务,服务间多为单向依赖
3,最小化地变更:
新增或变更业务上有很明确的服务对应,或是新增服务或是扩展某些服务,很少出现既可以在这个服务上实现也可以在那个服务上实现这种摸棱两可的情况,在符合上述条件前提下某一业务需求地变更受影响的服务应该尽可能地少
4,最大化地复用:
服务的复用是服务化的一个重大优势,服务设定要考虑复用的场景,在符合上述条件的前提下应该尽可能最大化地实现服务复用
5,性能稳定简洁:
上述条件更多的是业务导向,从技术上服务设定的核心要关注对性能的影响、是否稳定及架构是否简洁,是否要引入额外的中间件等. 除了业务导向的考虑外,服务的设定还需关注技术方面。这包括对性能的影响、稳定性、架构的简洁性以及是否引入额外的中间件等。确保服务设计不仅满足业务需求,还具备良好的技术特性。
我们需要清楚地认识到,服务的划分不是追求细粒度的划分越好,而是首先以业务域为基础进行拆分,然后结合技术视角,考虑团队规模和能力来明确定义服务之间的关系和边界。

对车贷系统来说,尽管上图业务服务单元的相对原子化可能是理想的,但在实际拆分时需要考虑业务和团队的复杂性。以下是对这两个方面的问题的更深入探讨:
-
业务上的考虑:
-
一需求一个服务原则: 确实,维持一个需求影响一个服务的原则有助于实现快速版本迭代。然而,在贷款流程中,贷款申请、审核、放款是相互依赖的,一个需求可能需要跨足这三个服务。这可能导致服务之间的高度耦合,增加了处理变更的复杂性
-
领域边界的重新考虑: 可以重新审视贷款流程的领域边界,尝试在领域边界上找到更合理的划分,以减少一个需求对多个服务的影响。这可能需要一定的业务流程优化和重新设计,以更好地匹配微服务的原则。
-
团队上的考虑:
-
成员规模和技能水平: 考虑到团队规模和技能水平的限制,过于细粒度的服务拆分可能导致开发和维护的困难。团队成员可能需要同时涉及多个服务,增加了团队的协作成本。
-
合理权衡
: 在拆分服务时,需要权衡服务的粒度。可以采用渐进式的拆分策略,先从业务较为独立的领域开始,逐步细化。确保每个服务都是可管理和可维护的,并适应团队的规模和技能水平。
我们重新划分下边界:

我们划分成四个服务:基础服务包含客户信息管理、合作商渠道管理及用户权限管理,所有贷款流程相关的都放在贷款服务,还款、催收等划到贷后服务,数据分析独立成一个服务。这样服务边界更清晰了,但是有如下几个问题:
-
所有服务都会依赖用户权限管理
-
登录、注册、催收等都需要发短信
-
所有系统都要文件上传
可见存在一些服务是公共的,针对这个情况我们可以再以技术视角做垂直拆分:

尽管我们已经在业务域和技术域上做了简单的服务边界划分,看似符合要求,但从架构的全局观上仍存在较大问题。主要问题在于对业务规划的理解不够深刻。随着业务的成熟,存量客户的维系和新客户的拓展将成为关键焦点。通常情况下,会引入配套的精确化营销系统(或类似系统),同时数据化经分系统将成为核心,为各类决策提供数据支持。然而,当前的架构并未清晰体现出业务系统的边界。因此我们再次修正下:

团队的整体能力是要考虑一个重要因素,一般而言团队的整体能力与服务的数量成正比,反之极容易导致架构失控。
检查合理性
服务划分完毕要做进行以下几方面的检查确保服务划分的合理性。
1、领域检查
什么是领域:
我习惯描述的是财务领域、人力领域、房地产领域、金融领域等,而在领域内,各种业务规则、业务知识盛行,如何有效的把控规则的变化,应对复杂知识,有一个很关键的四字词语,分而治之。分治法在很多场景下体现了其强大的作用力。领域本身很大很复杂,那就拆分,得到更小的领域,也即子域,如同递归调用一般,将一个复杂问题拆分单独求解,而最终将解汇总得到复杂问题解。
怎么拆,拆成怎么样合适,依据什么拆,这些在领域驱动设计中有了一套答案,虽然领域驱动设计不是银弹,但可以说的上是一套极好的系统方法论或称为架构设计的方法论。
领域驱动设计常以战略设计与战术设计来将整个领域展现的淋漓尽致,其作用范围既面向业务也面向技术。从战略角度(个人更喜欢称其为上帝视角)去规划系统、划分领域。而从战术角度则从技术层面来指导我们该如何去设计。
领域检查可以为我们的服务划分提供方向性的指导,使服务划分更明确、各有规划性。
领域驱动设计:DDD(Domain-driven design)是一套综合软件系统分析和设计的面向对象建模方法。
领域驱动设计强调以"领域"为核心驱动力,通过模型驱动设计来保障领域模型与程序设计的一致,领域模型不应该包含任何技术实现因素,模型中的对象真实的表达了领域概念,却不受技术实现的约束,领域模型本身和技术无关,领域驱动从设计上划分为战略设计和战术设计。
领域通用语言检查:(Ubiquitous Language)开发人员满脑子都是类、方法、算法、模式、架构,等等,总是想将实际生活中的概念和程序工件进行对应。但是领域专家通常对这一无所知,他们对软件类库、框架、持久化甚至数据库没有什么概念。他们只了解他们特有的领域专业技能。核心的原则是使用一种基于模型的语言。因为模型是软件满足领域的共同点,它很适合作为这种通用语言的构造基础。使用模型作为语言的核心骨架,要求团队在进行所有的交流是都使用一致的语言,在代码中也是这样。
确保在一个领域内产研描述的同一个对象就是同一个对象,比如质量验收中的巡检,北京的“鲁班行动”由于历史原因既是鲁班巡检也是验后巡检,都是同一类人在做(品质监察),西部的从验收模版就进行了区分鲁班巡检和验后巡检吗,这就是典型的同一个领域内语言描述不统一,导致的问题也很多既有线上数据记录错误也有BI侧的同学统计出错,反复确认该问题。
界限上下文检查:从业务特征上对领域进行划分形成子域,检查界限上下文是否划分合理。代码层面是否按照界限上下文进行继承关系、实体、聚合、值对象、领域服务等设计。比如我们的很多老的不同的服务都是共用一个DB这个现象不管是在微服务设计还是领域驱动设计范式里都是不提倡的。
领域防腐层检查:防腐层隔离不仅是为了保护自身领域模型免受其他领域模型的代码的侵害,还在于分离不同的域并确保它们在将来保持分离。咱们目前很多项目没有防腐层概念设计,导致大部分同学在开发的时候就是堆砌代码而不在意领域范围内结构的完整性,最终导致代码风格迥异,从系统上边界混淆。
领域对象、领域上下文不明确导致,定则生成业务(其实是统一业务)拆分在不同的领域服务里,带来的影响也有很多不便:
定则业务从技术层面没有收口出了问题排查就要拉多方逐一确认,只有很熟悉代码的同学才知道原来“主材补退货”的定则是否生成是供应链服务控制的!!!但是产品同学肯定不知道。 后期技术同学维护交接容易遗漏,后期迭代开发容易遗漏影响面。 产品迭代需要不同的团队支持,其实是同一个业务,这也是不太合理的情况。

领域建模对服务的划分有非常重要的指导意义,即使我们不用DDD也应该多少了解领域模型设计
举一个例子:某国内知名的垂直电商公司的CTO公开讲他们订单与优惠券的设计演进,第一个版本核心结构如下:

这一版很简单也很好理解,问题在于它将优惠券与店铺铺绑定,但优惠券有针对商品的、店铺的和平台的,比如X商铺A商品5折、X商铺满100减20,平台满200减20等,上面的结构明显不符合要求,所以他们改成如下结构:

做法是将订单拆分成针对商品、店铺及平台(支付)的三类,一个支付订单可以包含一个或多个店铺订单,一个店铺订单可以包含一个或多个商品订单。
问题解决了吗?
的确从功能上看是满足了,但这种做法的后患是订单与优惠券完全绑定了,订单被优惠券绑架了,如果业务上又出现了针对不同类目的优惠(这很常见)那是不是又要加入类目级订单?

引入一张订单优惠券的关联表(Order Coupon)即可,核心域只关注订单,各类活动的处理在运营活动域中操作。 就这么简单?
是的,从领域处理上就是这样,但要支持我们的需求需要有些特殊的处理,在关联表要引入事务ID,同一次操作事务ID相同。 领域检查可以为我们的服务划分提供方向性的指导,使服务划分更明确、各有规划性。
以下是在微服务架构中使用DDD的一些简洁的步骤:
-
定义微服务边界,每个微服务对应一个限界上下文,有自己的领域模型和语言。
-
使用领域模型来建模每个微服务的核心业务逻辑,包括实体、值对象、聚合、领域服务等。并定义它们之间的关系和交互。
-
明确微服务之间的接口和通信协议,如HTTP/REST或AMQP等。基于领域模型定义接口。
-
使用事件驱动架构来确保微服务之间的数据同步。
-
每个微服务拥有自己的仓库与工厂,负责数据的管理和持久化。
-
团队结构应该反映微服务的划分,每个团队专注于自己的微服务。
-
自动化部署和运维,使用监控工具来跟踪微服务性能。
-
不断迭代和改进微服务,根据反馈优化系统。
总之,在微服务架构中使用领域驱动设计可以提高系统的可维护性和可扩展性,通过定义领域模型、识别限界上下文、设计聚合根和聚合、实现领域服务、实现微服务接口、使用通信协议进行微服务交互以及实现数据存储等步骤来构建出高质量的微服务架构。
2、依赖DAG检查
DAG在数学上是有向无环图,指从任何一点出发都不会回到这个点,即不存在环路,我们服务的依赖也应如此。服务间要尽量避免双向或循环依赖,否则可能会导致灾难性的后果。
质量领域中的业主线下验收就存在一个有向环图,下图中第一个就是业主发起线下申请人出现的有向有环图问题,究其原因就是系统边界划分不清晰导致质量领域事件出现在了验收单领域里,增加了系统间交互的复杂性和系统边界模糊,调用链路复杂等情况发生。
经过领域界限上下文重新规划和代码优化之后的教系统交付如下图二,可以看到边界清晰了,系统交互简化了,调用链路也减少了。
图一
图二
在微服务架构中,同层服务之间的相互依赖是一个容易被忽视但又非常重要的问题。当服务之间存在双向依赖时,一个服务的变更可能会波及到多个服务,导致修改、测试和部署的复杂性急剧增加。这种情况尤其容易发生在服务之间形成复杂的依赖网络时。

上图是在项目改造前的服务依赖图中,存在严重的双向依赖问题,直接导致了自动化部署困难、需求响应缓慢等多方面的挑战。一个设计精良的系统通常会采用服务分层的方式,将业务层与基础能力层分离。在这种设计中,业务层位于系统的顶层,而基础能力服务位于底层。上层服务可以调用底层服务,但底层服务不依赖于上层服务,因此各服务之间不存在相互依赖的问题。
错误处理依赖关系可能导致以下问题:
-
响应速度变缓慢: 当服务之间存在双向依赖时,一个需求的变更可能波及多个服务,导致对变更的响应速度变得缓慢。
-
系统可用性下降: 由于无法有效制定降级方案,双向依赖可能使一个服务的问题影响整个系统的可用性。缺乏有效的容错机制可能导致系统无法在部分服务故障时正常运行。
-
架构难以扩展: 双向依赖可能导致整体架构变得难以扩展。一个服务的变更可能引发系统中多个服务的变动,使得公共服务难以抽象,业务服务难以进行重构。
具体到车贷系统可能存在的情况是贷款和贷后服务中存在一定双向依赖:

贷款申请时先做前置判断:如果该顾客尚有未完成的贷款则拒绝本次申请,在催收巡检时需要获取已放款的订单来确定要处理的数据,很不幸的是它们彼此存在于两个服务中。解决的方法有三种:
-
直接查询数据库而不是调用服务 这是最直接暴力的做法,但带来的问题也很明显,如果操作的业务很复杂会导致代码冗余,即两个服务都要存有相同的代码,另外从服务隔离的角度看也不很合理
-
做数据冗余 以上例而言,在贷中服务放款完成后将这一数据同步给贷后服务,在贷后服务中冗余一份,这样后续做催收巡检时就不需要再请求贷中服务了,当然这会带来数据同步处理的需求
!比较有争议的问题:服务间的数据库是否需要独立? 主张独立的观点认为所有调用都应该是服务接口调用,不应该直接查询非本服务所属的数据表,这样才能最大化地实现能力复用,也最能保证服务解耦,反对的观点认为这带来过多的资源消耗及精力投入,现实情况存在比较多的跨服务查询,比如贷后服务中查询用户还款列表时就需要用到贷款服务的贷款信息表,过分地强调隔离会使系统设计更为复杂,得不偿失。 笔者在此不评论两个观点的是非,在实践中,笔者一般采用系统间数据隔离(分库),系统内各服务数据共享(同一库)。
-
增加抽象层
架构设计中绝大部分问题都可以通过增加一层解决,这也笔者认为最优雅的方法。如下图,我们可以增加公共业务服务这一层,在其上实现订单服务,这样就上述的需求而言通过订单服务实现了完全的解耦

完成DAG检查后我们的服务划分演进成了如下形式:

我们为信贷系统增加了数据服务层,添加了三个数据服务,分别提供对金融产品、申请用户、订单的数据操作。
⚠ 增加抽象层从单纯的架构层面上无疑是最优雅的,但这也增加了服务维护难度,必须要结合团队能力综合考虑,如果团队配置相对单薄那么直接查接口方案短期内可能更为适合。
3、分布式事务检查
分布式事务调用的成本很高,服务拆分尽量避免产生跨服务事务,能合则合。如无法合并则优先考虑TCC或基于MQ的柔性事务,尽可能规避2PC等对性能影响很大的事务方案。TCC可完全替换2PC,但开发成本偏高,需要调用各方都同步修改以支持Try、Confirm和Cancel操作,某些场景会调用三方服务,其代码不受我们控制,此时可以考虑使用MQ实现异步消息和补偿性事务。咱们的业务比较复杂系统间的交互协作比较多,分布式事务在所难免。
举一个比较典型的case就是,验收报告确认的时候,因为会产生延期会同步修改排期时间(排期领域)、有验收不合格项会记录整改工单(整改领域)、同步修改验收报告为代项目经理确认或待业主确认(验收单领域)、有延期赔付的话需要确认延期赔付(服务承诺领域)等等,者么多的领域服务调用都要确保成功才能算该节点验收通过,采用分布式事务显然成本很大,必然导致接口耗时增加很多影响接口性能和系统稳定。
咱们具体看看一下这几个领域的特点。其中排期领域和整改领域是同一类领域在发生错误或者修改的时候要做到始终以最后一次提交为准,那就要领域服务内做到“幂等”。最好能从产品层面达成一致,比我们整改领域就是和产品同学达成产研层面的一致:始终以最后一次提交的整改为准。我们会记录本次验收提交的整改单,若有重复提交只记录最后一次提交的整改。当然这是在业务场景教低频的情况下的解决方案,大家按照自己的实际的情况采用最适合自己业务场景的技术方案。
而验收单领域、延期赔付(服务承诺领域)就是同步更新操作,天然的幂等操作。在这种业务场景下即使重复提交也是更新到目标状态所以也是没有问题。
-
分布式事务成本高昂: 在分布式系统中,由于各种原因,实施跨服务的分布式事务通常会导致性能和复杂性上的负担。因此,服务拆分时应尽量避免跨服务事务,而是考虑其他替代方案。
-
合并服务的可能性: 在服务设计中,应当优先考虑服务的合并,以避免不必要的跨服务事务。合并服务有助于简化系统架构,减少分布式事务的需求。
-
TCC和基于MQ的柔性事务: 在无法避免分布式事务的情况下,可以考虑采用 TCC(Try-Confirm-Cancel)或基于消息队列的柔性事务。这些方法可以降低事务的一致性要求,减少对性能的负面影响。
-
TCC替代2PC: TCC是一种替代2PC对性能影响很大的的方案,尽管它提供了更灵活的事务管理方式,但开发成本相对较高。在采用TCC时,需要确保各方服务能够同步支持Try、Confirm和Cancel操作。
-
异步消息和补偿性事务: 针对无法控制的第三方服务,采用基于消息队列的异步消息和补偿性事务是一种有效的策略。这种方式通过将事务操作转换为消息,并在需要时执行补偿操作,实现了松耦合的分布式事务管理。
总体而言,这样的设计考虑更加注重系统的弹性和性能,通过选择合适的事务模型以及采用异步消息机制,有助于在分布式环境中降低事务的复杂性和开发成本。车贷系统目前基本基于MQ和钉钉告警结合的补偿性事务。
4、性能分布检查
对于特别耗资源的操作应尽量独立。比如上文提到车贷系统使用了bcrypt(一种基于Blowfish算法的散列函数,类似MD5,但Hash时极为消耗CPU),导致系统注册服务的TPS严重下降,这时就应该考虑把这个签名操作对独立成服务,为这一服务部署更多节点,并且可以为其独立购买计算优化型云主机。
车贷系统需要近实时地同步GPS追踪器厂商的GPS轨迹数据,这一操作本应归属于贷后服务的贷后数据采集,但由于此操作对TPS、IO要求极高,会占用贷后服务绝大部分的资源,可重要性却次之,即使此功能临时下线对主体业务也不会有太大影响,所以有必要独立成服务,因此我们的服务划分又有新的变化:

5、稳定(易变)性检查
一个服务中如存在稳定和不稳定的模块,应该将两者拆分。这部分也是暂时没有在咱们的业务场景中遇到,基本上都分别部署的,质量领域中目前验收模版配置是频繁发生的也是单独拆分成子领域迭代,验收模版配置的变更不会影响验收应用层,大家在进行领域划分系统设计的时候关注这方面的影响即可。
比如某个母婴电商首页配置做改造优化。此系统有很多运营活动,在不同时期,需要整个首页根据运营策略进行变化。之前方案是每个版本变化,投入大量开发改造首页,导致成本高不能急时响应,运营活动无法快速开展。配置变化中寻找不变的点,就是组件大部分可重用,比如类目块,商品块,活动块,轮播条等。为此为此在设计把其独立成Widget服务,它的变更不会影响核心服务。而是运营通过配置页面的组合搭配就可以完成运营策略首页配置。 车贷系统在运营过程中,我们注意到一些接入的服务商,特别是短信服务商和三要素验证供应商,响应速度较慢且不够稳定。现代软件研发中,我们有许多第三方服务可供选择,这使得我们可以快速高效地构建服务。然而,随之而来的问题是如何有效地管理和监控这些服务。
举例来说,对于短信服务,国内存在许多供应商,它们提供了各种各样的服务。由于政策和运营商策略的影响,没有一家短信供应商可以保证100%的触达率。因此,在项目中我们常常会选择接入多个供应商,并采用一定的策略来确保最大化触达率。
对于其他关键流程,比如电子合同和人脸比对,它们在贷款流程中扮演着不可或缺的角色。由于这些服务的可用性对于我们的业务至关重要,我们采取了多供应商备份的策略,并保留了自己的调用记录。这样一来,我们可以在一个供应商出现问题时迅速切换到备用供应商,确保服务的连续性,尽量减少对业务的影响。
解决方案
-
独立封装服务: 将三方服务独立封装,使其对外提供统一的接口。这有助于隔离服务变化,提高服务的可替换性和可维护性。
-
内部处理差异: 在服务内部处理不同三方服务之间的接口和规则差异。这可以通过适当的抽象和封装来实现,确保上层业务服务不受底层三方服务的影响。
-
自动切换备用服务: 实现自动切换到备用三方服务的机制。这可以通过实施健康检查、监控服务可用性,并在主服务不可用时切换到备用服务来实现。
-
服务与业务解耦
: 将这些服务设计为与业务无关的公共服务。这意味着它们提供的功能是通用的,可以在多个业务场景中重复使用,提高了服务的通用性和可重用性。
所以这些三方服务都应该独立,服务对外提供相对统一的接口,服务内部去对接不同的三方服务,消化不同三方服务在接口、规则上的差异,确保一个三方服务不可用时可以自动切换到备用三方服务上。并且这些服务与业务无关,非常适合封装成公共服务,故我们的服务划分又可修改成:

6、调用链检查
服务间调用有IO消耗且不易追踪,应控制调用链路的长度。通过服务间的调用链路可以很清晰的发现历史无效代码的调用,需求迭代查产生的无效逻辑,以及潜藏的重复调用、循环依赖、以及系统可优化点等等。如下图就是一个验收提交的case,由于迭代时间太长,其中有很多废弃的逻辑没有删除,代码臃肿不说调用其他服务的接口、发送的消息、都是资源成本,若能及时梳理清楚代码整洁性提高了,维护成本降低,切服务稳定性也有了提升。
服务间调用有IO消耗且不易追踪,应控制调用链路的长度。以笔者的经验,一般的请求—响应类操作应该在4层以内比较合适,比如:应用服务网关——>业务服务——>(业务)数据服务——>公共服务。
当然调用链路的长短也要看情况,比如风控系统(见下图),它的一次风控决策最多就需要6层调用,请求从网关Gateway路由到流量控制器(Flow Controller),流量控制器负责在合适的时机发送请求事件到决策处理器(Decision Processor),决策处理器根据决策规则要求发布因子获取事件给因子服务(Factor),因子服务返回对应的因子数据给决策处理器以进行规则运算并异步回调业务请求方。但这一流程中如果因子数据不存在则因子服务要先请求数据采集分发器(Collect Dispatcher),数据采集分发器分发要采集的数据给对应的采集器,采集完成后逐级返回。这一系统通过MQ实现完全异步化处理,多层调用是为服务解耦,符合上述服务划分的要求,同时又因为是异步回调的方式,对实时性要求不高,所以这样的调用链路是可接受的。

服务的划分是微服务设计的第一步,也是成功实斥的关键。架构设计不应该仅仅关注技术层面,人的因素,包括团队和项目的特定因素,往往更为重要。原则为我们提供了大的方向,但具体的实践需要根据实际情况来调整。这就需要架构师在设计过程中具备灵活性和判断力,根据具体的情况进行度的把握。架构师的能力和经验将在如何平衡原则和实际需求之间进行权衡时得到考验。
项目案例:
线上教育机构CRM按照流程划分主要是获客-跟进-转化-签约-服务。按照领域进行抽象,可以分为售前,售中,售后。
服务
按照服务来划分,主要有投放服务、营销活动服务、呼叫服务、客户管理、日程管理、消息提醒、订单、合同、工单、销售效果分析。
功能
每个服务有更细粒度的功能。比如 投放服务:提供多渠道投放方式,百度,头条,微信等,投放分析。营销活动服务:营销落地页,开学季优惠活动,抽奖活动,优惠券活动。客户管理服务:客户档案,销售机会,销售看板。其他不再赘述。
人员
目前业务还是在初级阶段,负责这块的开发总共有6人,3个后端,2个前端,一个测试。
服务划分
基于以上考虑,服务划分为以下6个服务。
考虑到只需要一个pc工作台,市场人员、销售人员都用同一个工作台,应用系统这一层不需要。然后核心领域分为售前(市场人员)、售中(客服,销售)、售后(客服,财务)三个服务,每个开发负责一个服务。同时抽象出3个通用基础能力服务,每个开发负责一个。
-
公司内部的账号系统 提供统一的账号管理能力,组织架构能力,权限管理能力。
2. 服务系统 通用的一些工具能力,比如隐私号、坐席呼叫、待办、消息提醒等能力。这些并不属于同一个领域,但是考虑到当前阶段,服务不宜拆分的过细。所以都放在同一个服务中。
3.数据分析 各个模块都需要数据分析,所以抽象出一个单独能力,统一处理。
演进
经过半年的发展,业务蒸蒸日上,需求越来越多。人员也在逐步扩展。后端人员扩大到了10人。原有的微服务架构逐渐不太适应。因此需要进行适当调整。经过分析,当前业务重点是
-
售前 两个核心指标一个是有效线索量,一个是单个线索成本
2. 售中 售中决定了线索能否转化为订单。目前对应的运营人员最多,客服100人,销售300人。提高运营人员效率是重点。
3. 售后 工单响应时长
售前这块基本系统功能已搭建完毕,通用的营销工具已经有了,市场人员可以进行组件组合,搭建不同营销页,然后根据投放效果进行适当调整。服务比较稳定了,所以这块有2个开发即可。主要负责营销工具开发。
售后相对也比较稳定了,2个开发。售中是重点,需求迭代也比较多,6个开发。之前只有一个微服务,开发效率比较低了。需要进行适当拆分。增加3个服务
1.应用系统增加一个移动工作台 因为销售人员经常在外部,所以需要移动端,而移动端通常是销售管理活动中的操作类功能。pc端则是查看分析。
2.核心领域层增加一个售中服务域
售中拆成2个服务,一个是线索域,主要围绕着公海、私海,线索推荐。另外一个是服务域,是面向销售日常活动的。如活动,拜访,小记,客户标签等。
3 .基础能力层增加一个流程引擎服务 各个角色人员需要经常发起审批,流程编排,所以新构建一个基础能力,流程引擎。能够服务于整个crm业务,同时如果公司其他业务需要,可以提供给其他业务使用。
微服务的设计原则
简介:
微服务架构近年来越来越受欢迎。主要是因为它提供了高可扩展性、容错性和更快速的产品上线效率。
微服务架构开发有许多优势,但要确保为微服务系统成功实施就需要遵循一些设计原则。包括但不限于上面介绍的几个原则,如:SRP、松耦合、API优先设计、容器化、DDD、CI/CD、容错和弹性机制、EDA、安全性、监控和日志等。

下面给大家详细讲解几个主要的原则:
1、单一职责原则:
每个微服务应该只负责一个明确的业务功能,而不是多个功能。这样可以使每个服务的代码和功能更加专注和可控。
解决方案:
-
定义清晰的服务边界,以确保每个服务都只处理特定的功能。
-
拆分复杂的服务为更小的、更易管理的服务。
-
避免在一个服务中实现多个业务功能。
-
保持每个服务的代码库的大小适中。

2、松耦合原则:
每个微服务应该是松耦合的,也就是说,它们应该能够独立运行,而不会影响其他服务。这样可以提高系统的可伸缩性和可维护性。
另外,每个微服务也都应该只管理自己的数据,每个微服务都有自己的数据库来存储数据,以确保可扩展性和可靠性。要避免与其他微服务共享数据库,因为这可能会导致数据不一致,并且会使故障排查变得非常困难。
解决方案:
-
使用轻量级通信协议,例如REST API或消息传递。
-
使用服务发现和注册机制,例如Zookeeper或Consul,以便服务之间相互发现和通信。
-
使用异步消息传递机制,例如Kafka或RabbitMQ,以实现松耦合的服务通信。
-
实现API网关,以控制服务之间的通信和数据流动。
3、可组合原则:
每个微服务应该能够与其他服务组合使用,以构建更复杂的应用程序和业务流程。
微服务应该围绕着API进行设计。在实现服务之前,应该首先设计好API。这样做是为了确保服务设计结果最终能够被其他服务或者客户端使用。
解决方案:
-
实现服务接口和API设计的一致性和标准化,以便其他服务可以轻松地集成和使用。
-
使用分布式事务机制,例如Saga模式,以确保多个服务之间的数据一致性。
-
使用事件驱动架构,例如CQRS模式,以便不同的服务可以对相同的事件做出反应,并共享业务逻辑。
-
实现版本控制机制,以便在不破坏现有集成的情况下对服务进行升级和更新。
4、可替换原则:
每个微服务应该是可替换的,也就是说,可以轻松地替换或重构服务,而不会对整个系统造成太大的影响。
微服务架构应该具备较高的容错和弹性伸缩能力。这样微服务才能够优雅地处理故障,并从故障中快速恢复。这样做的另一个好处是:不会因为一个微服务出现故障而影响整个系统的运行。
5、持续集成和持续部署(CI/CD)
CI/CD是一种软件开发运维过程实践,打通开发和运维环节,实现应用程序的构建、测试和部署自动化。任何微服务都应该是可持续部署的,实现微服务的快速高效部署,缩短了微服务上线时间。
以下是微服务的19个
解决方案:
-
定义清晰的服务边界,以确保每个服务都只处理特定的功能。
-
拆分复杂的服务为更小的、更易管理的服务。
-
避免在一个服务中实现多个业务功能。
-
保持每个服务的代码库的大小适中。
-
使用轻量级通信协议,例如REST API或消息传递。
-
使用服务发现和注册机制,例如Zookeeper或Consul,以便服务之间相互发现和通信。
-
使用异步消息传递机制,例如Kafka或RabbitMQ,以实现松耦合的服务通信。
-
实现API网关,以控制服务之间的通信和数据流动。
-
实现服务接口和API设计的一致性和标准化,以便其他服务可以轻松地集成和使用。
-
使用分布式事务机制,例如Saga模式,以确保多个服务之间的数据一致性。
-
使用事件驱动架构,例如CQRS模式,以便不同的服务可以对相同的事件作出反应,并共享业务逻辑。
-
实现版本控制机制,以便在不破坏现有集成的情况下对服务进行升级和更新。
-
实现容器化技术,例如Docker或Kubernetes,以便轻松地部署和管理服务。
-
实现监控和日志记录机制,以便快速检测和修复服务问题。
-
实现自动化测试机制,包括单元测试、集成测试和端到端测试,以确保服务的正确性和稳定性。
-
使用灰度发布和AB测试技术,以逐步推出新功能和服务,并降低风险。
-
使用负载均衡和自动扩展技术,以确保服务的可伸缩性和高可用性。
-
使用安全认证和授权机制,以保护服务和数据的安全性。
-
使用性能优化和调优技术,以确保服务的高性能和响应速度。
最大努力通知( Best-effort delivery)
是最简单的一种柔性事务,是分布式事务中对一致性要求最低的一种,适用于一些最终一致性时间敏感度低的业务,且被动方处理结果 不影响主动方的处理结果。典型的使用场景:如银行通知、商户通知等。
最大努力通知的目标:发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。
最大努力通知型的实现方案,一般符合以下特点
特点:
1、不可靠消息:业务活动主动方,在完成业务处理之后,向业务活动的被动方发送消息,直到通知N次后不再通知,允许消息丢失(不可靠消息)。
2、定期校对:业务活动的被动方,根据定时策略,向业务活动主动方查询(主动方提供查询接口),恢复丢失的业务消息。
最大努力通知方案需要实现如下功能:
1、消息重复通知机制。因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知。
2、消息校对机制。如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息信息来满足需求。
最大努力通知方案主要也是借助MQ消息系统来进行事务控制,这一点与可靠消息最终一致方案一样。看来MQ中间件确实在一个分布式系统架构中,扮演者重要的角色。最大努力通知方案是比较简单的分布式事务方案,它本质上就是通过定期校对,实现数据一致性。
常见的充值案例:
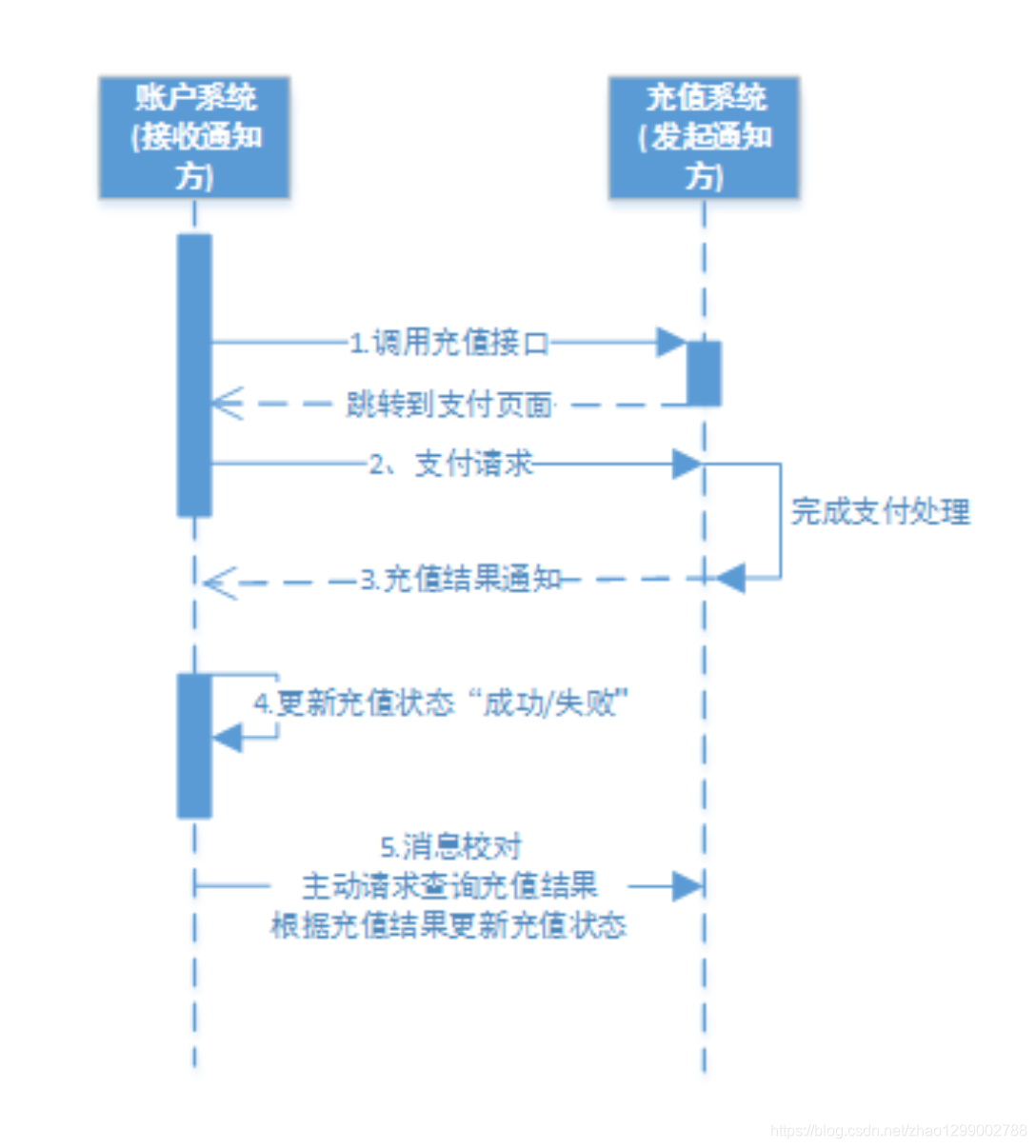
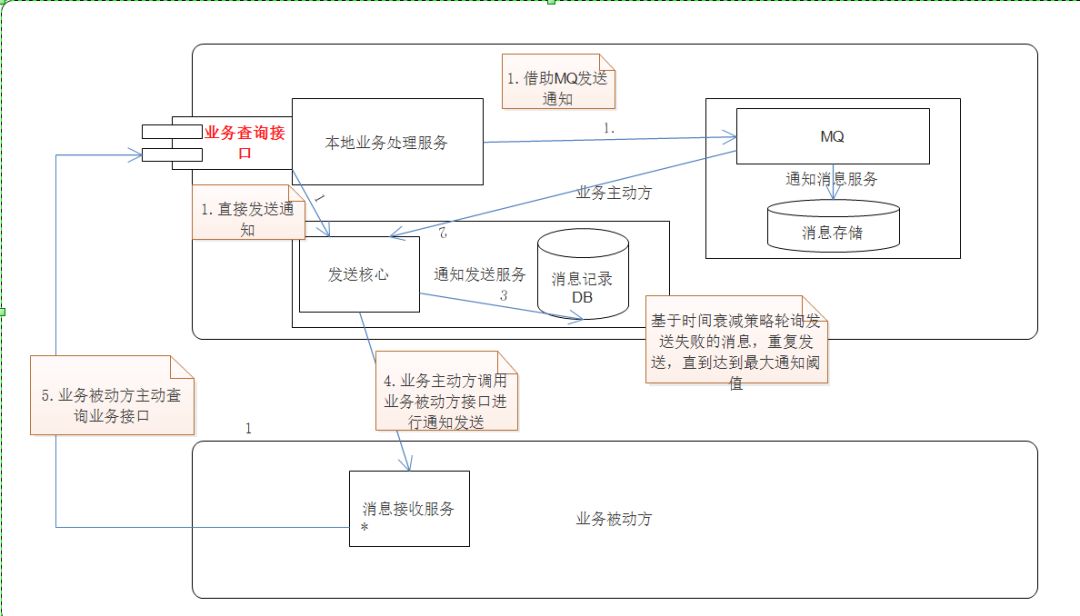
代表案例支付流程
-
用户在浏览器发起充值请求
-
电商服务生成充值订单,状态为0:待支付(0:待支付、100:支付成功、200:支付失败)
-
电商服务携带订单信息请求支付宝,生成支付宝订单,组装支付宝支付请求地址(订单信息、支付成功之后展示给用户的页面return_url、支付异步通知地址notify_url),将组装的信息返回给用户
-
用户浏览器跳转至支付宝支付页面,确认支付
-
支付宝携带支付结果同步回调return_url,return_url将支付结果展示给用户
示意图如下所示

首先我们电商平台的订单服务会通过调用第三方银行系统的支付服务完成订单款项的支付,由于这里支付结果是异步获取的。所以需要等待银行系统在完成相关支付业务后,通过回调接口来通知我们系统的支付结果。但很多时候由于存在网络异常、回调接口发生异常等意外因素,第三方为了尽最大努力进行结果通知,往往会将相关结果通过MQ投递到通知服务,以便单独进行重复、多次的结果通知
但如果我们从第三方系统的角度考虑,如果调用回调接口一直失败,总不能一直这么重试下去啊。
所以在最大努力通知的方案中,不仅需要通知的发起方(即这里的第三方银行系统)提供结果通知的重试机制,还需要给通知的接受方(即这里的电商平台)提供一个用于主动进行结果查询的接口。这样即使当银行系统的通知次数达到阈值,不再调用回调接口进行结果通知时,我方服务也可以在之后通过银行系统的查询接口获取相应结果
支付宝将支付结果异步通知给商户
用户支付流程完毕之后,此时支付宝中支付订单已经支付完毕,但电商中的充值订单状态还是0(待支付),此时支付宝会通过异步的方式将支付结果通知给notify_url,通知的过程中可能由于网络问题,导致支付宝通知失败,此时支付宝会通过多次衰减式的重试,尽最大努力将结果通知给商户,这个过程就是最大努力通知型。
商户接收到支付宝通知之后,通过幂等性的方式对本地订单进行处理,然后告知支付宝,处理成功,之后支付宝将不再通知。
什么是衰减式的通知
比如支付宝最大会尝试通知100次,每次通知时间间隔会递增。比如第1次失败之后,隔10s进行第2次通知,第2次失败之后,隔30s进行第三次通知,间隔时间依次递增的方式进行通知。
为什么需要进行异步通知
支付宝支付成功之后会携带支付结果同步调用return_url这个地址,那么商户直接在这个return_url中去处理一下本地订单状态不就可以了么?
这种做法可以,但是有可能用户的网络不好,调用return_url失败了,此时还得依靠异步通知notify_url的方式将支付结果告知商户。
如果支付宝一直通知不成功怎么办
商户可以主动去调用支付宝的查询接口,查询订单的支付状态。
最大努力通知的解决方案
最大努力通知方案设计上比较简单,主要是由两部分构成。1.实时消息服务(MQ):接收主动方发送的MQ消息。2.通知服务子系统:监听MQ消息,当收到消息后,向被动方发送通知(一般是URL方式),同时生成通知记录。如果没有接收到被动方的返回消息,就根据通知记录进行重复通知。仅适用于实时性不太高的场合:最大努力通知方案实现方式比较简单,本质上就是通过定期校对,适用于数据一致性时间要求不太高的场合,其实不把它看作是分布式事务方案,只认为是一种跨平台的数据处理方案也是可以的。
方案1:利用 MQ的 ack机制,由 MQ向接收通知方发送通知
1、发起通知方将通知发给MQ。使用普通消息机制将通知发给MQ。注意:如果消息没有发出去可由接收通知方主动请求发起通知方查询业务执行结果。
2、接收通知方监听 MQ。
3、接收通知方接收消息,业务处理完成回应ack。
4、消息重复机制(consumer-mq)的应用:接收通知方若没有回应ack则MQ会重复通知。MQ会按照间隔1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔 (如果MQ采用rocketMq,在broker中可进行配置),直到达到通知要求的时间窗口上限。
5、消息校对机制(consumer-producer)的应用:接收通知方可通过消息校验接口来校验消息的一致性。
注意1:消息重复机制 mq-consumer:通知发起方将消息生产到MQ中,通知接收方来取出消息,如果没有来取,MQ按时间间隔通知。注意2:消息重复机制 mq-consumer:去做通知的是MQ,而不是通知发起方。
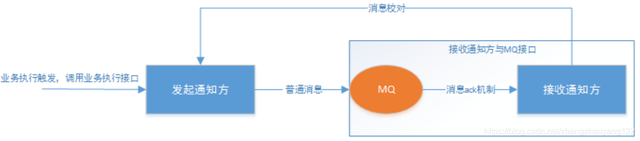
方案2:利用 MQ的 ack机制,应用程序向接收通知方发送通知
1、发起通知方将通知发给MQ。使用可靠消息一致方案中的事务消息保证本地事务与消息的原子性,最终将通知先发给MQ。2、通知程序监听 MQ,接收MQ的消息。区别:方案1中接收通知方直接监听MQ,方案2中由通知程序监听MQ。**消息重复机制(mq-application):通知程序若没有回应ack则MQ会重复通知。3、通知程序收到通知后,通过互联网接口协议(如http) 调用 接收通知方案接口,完成通知。通知程序 调用 接收通知方接口成功就表示通知成功,即消费MQ消息成功,MQ将不再向通知程序投递通知消息。4、消息校对机制(consumer-producer)**:接收通知方可通过消息校对接口来校对消息的一致性。
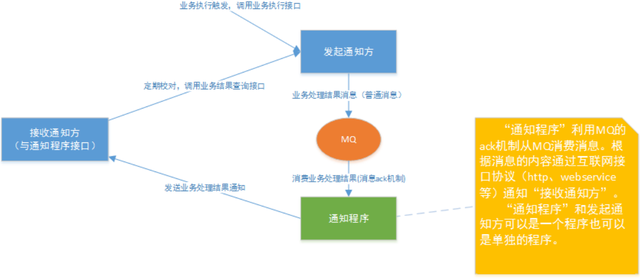
方案1和方案2区别:
方案1和方案2的不同点:
消息重复机制不同,消息校对机制是相同的
1、消息重复机制:
方案1中接收通知方与MQ接口(mq-consumer),即接收通知方案监听 MQ,此方案主要应用producer与内部应用consumer之间的通知。
2、消息重复机制:
方案2中由通知程序与MQ接口(mq-application),通知程序监听MQ,收到MQ的消息后由通知程序通过互联网接口协议调用接收通知方。此方案主要应用producer与外部应用application之间的通知,例如支付宝、微信的支付结果通知。
最大努力通知方案的实现
1.业务活动的主动方,在完成业务处理之后,向业务活动的被动方发送消息,允许消息丢失。2.主动方可以设置时间阶梯型通知规则,在通知失败后按规则重复通知,直到通知N次后不再通知。3.主动方提供校对查询接口给被动方按需校对查询,用于恢复丢失的业务消息。4.业务活动的被动方如果正常接收了数据,就正常返回响应,并结束事务。5.如果被动方没有正常接收,根据定时策略,向业务活动主动方查询,恢复丢失的业务消息。
最大努力通知方案的特点
1.用到的服务模式:可查询操作、幂等操作。2.被动方的处理结果不影响主动方的处理结果;3.适用于对业务最终一致性的时间敏感度低的系统;4.适合跨企业的系统间的操作,或者企业内部比较独立的系统间的操作,比如银行通知、商户通知等;
RocketMQ实现最大努力通知型事务
通过 RocketMQ中间件实现最大努力通知分布式事务,模拟转账过程。
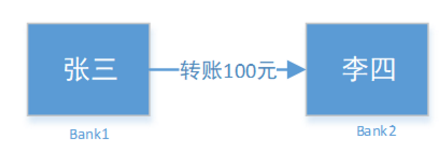
两个账户在分别在不同的银行(张三在bank1、李四在bank2),bank1、bank2是两个微服务。交易过程是,张三给李四转账指定金额。
上述交易,张三扣减金额与给bank2发转账消息,两个操作必须是一个整体性的事务。
交互流程如下:
1、Bank1向MQ Server发送转账消息
2、Bank1执行本地事务,扣减金额
3、Bank2接收消息,执行本地事务,添加金额
4、当转账指定金额时候,模拟发生异常的情况。
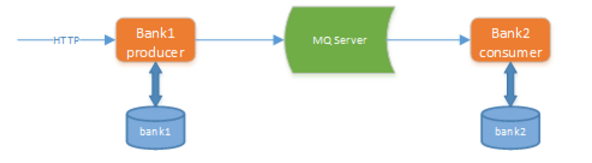
最大努力通知与可靠消息一致性有什么不同
解决方案思想不同 可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收方,消息的可靠性关键有发起方来保证。 最大努力通知,发起通知方尽最大努力将业务处理结果通知给接收方,但是可能消息接收不到,此时需要接收方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。 两者的业务应用场景不同 可靠消息一致性关注的是交易过程的事务一致性,以异步的方式完成校验。 最大努力通知关注的是交易后的通知事务,即将交易结果可靠的通知出去。 技术解决方向不同 可靠消息一致性要解决消息从发出到接收的一致性,即消息发出并且被接收到。 最大努力通知无法保证消息从发出到接收的一致性,只提供消息接收的可靠机制。可靠机制是,最大努力将消息通知给接收方,当消息无法被接收时,由接收方主动查询消息(业务处理结果)。
案例代码:
安装RocketMQ
启动rocketMQ报错: 错误:找不到或无法加载主类 Files\Java\jdk1.8.0_131\jre\lib\ext

原因:JAVA_HOME的环境变量包含空格
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_131
解决方法:修改runserver.cmd和runbroker.cmd文件
两个文件都做这样的修改,然后重新启动,就不会报那个错误了 。 注意最下面的%CLASSPATH%也是引用的上面定义的变量,也需要有双引号。否则可能也会报那个错误。
环境搭建
这里利用Docker Compose搭建RocketMQ环境
# Compose 版本
version: '3.8'
# 定义Docker服务
services:
# Rocket MQ Name Server
RocketMQ-NameServer:
image: foxiswho/rocketmq:4.8.0
container_name: RocketMQ-NameServer
ports:
- "9876:9876"
command: sh mqnamesrv
networks:
rocket_mq_net:
ipv4_address: 130.130.131.10
# Rocket MQ Broker
RocketMQ-Broker:
image: foxiswho/rocketmq:4.8.0
container_name: RocketMQ-Broker
ports:
- "10909:10909"
- "10911:10911"
- "10912:10912"
environment:
NAMESRV_ADDR: "130.130.131.10:9876"
command: sh mqbroker -c /home/rocketmq/rocketmq-4.8.0/conf/broker.conf
depends_on:
- RocketMQ-NameServer
networks:
rocket_mq_net:
ipv4_address: 130.130.131.11
# Rocket MQ Console
RocketMQ-Console:
image: styletang/rocketmq-console-ng:1.0.0
container_name: RocketMQ-Console
ports:
- 8080:8080
environment:
JAVA_OPTS: "-Drocketmq.namesrv.addr=130.130.131.10:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false"
depends_on:
- RocketMQ-NameServer
networks:
rocket_mq_net:
ipv4_address: 130.130.131.12
# 定义网络
networks:
rocket_mq_net:
ipam:
config:
- subnet: 130.130.131.0/24
然后进入RocketMQ Broker容器,将配置文件broker.conf中的brokerIP1设置为宿主机IP
订单服务
这里通过SpringBoot搭建一个事务的发起方——即订单服务。首先在POM中引入RocketMQ相关依赖
<dependencyManagement>
<dependencies>
<!--Spring Boot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.3.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Rocket MQ -->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
同时在application.yml中添加关于RocketMQ相关的配置,这里为避免由于消息发送超时而导致失败,调大了关于生产者发送超时时间的配置
rocketmq:
name-server: 127.0.0.1:9876
producer:
# 默认生产者组名
group: order-service
# 生产者发送超时时间, Unit: ms
send-message-timeout: 600000
需要注意的是,从RocketMQ-Spring 2.1.0版本之后,注解@RocketMQTransactionListener不能设置txProducerGroup、ak、sk,这些值均与对应的RocketMQTemplate保持一致。换言之,由于不同事务流程的事务消息需要使用不同的生产者组来发送,故为了设置生产者组名。需要通过@ExtRocketMQTemplateConfiguration注解来定义非标的RocketMQTemplate。定义非标的RocketMQTemplate时可自定义相关属性,如果不定义,它们取全局的配置属性值或默认值。由于该注解已继承自@Component注解,故无需开发者重复添加即可完成相应的实例化。这里我们自定义该非标实例的生产者组名
/**
* 自定义非标的RocketMQTemplate, Bean名与所定义的类名相同(但首字母小写)
*/
@ExtRocketMQTemplateConfiguration(group="tx-order-create")
public class ExtRocketMQTemplate1 extends RocketMQTemplate {
}
下面既是创建订单过程中本地事务的方法。对于RocketMQ回查本地事务执行结果时,则有两种思路,要么判断订单表中是否存在相关订单记录;要么单独增加一张事务日志表,每笔订单创建完成后向事务日志表插入相应事务ID的记录,这样回查时只需在事务日志表中判定是否存在相应事务ID的记录即可。而订单表、事务日志表由于在同一数据库下,可以直接利用本地事务保证原子性。这里我们采用后者的思路,即创建订单时,不仅在订单表插入订单记录,也在事务日志表中插入一条相应的记录。实现如下所示
@Service
@Slf4j
public class OrderService {
@Autowired
private TransactionLogMapper transactionLogMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 创建订单
* @param order 订单记录
* @param txid 事务ID
*/
@Transactional
public void createOrder(Order order, String txid) {
// 创建订单
int result = orderMapper.insert(order);
// 插入失败
if( result!=1 ) {
new RuntimeException("create order fail");
}
// 写入事务日志
transactionLogMapper.insert( new TransactionLog(txid) );
}
}
...
/**
* 订单记录
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_order")
public class Order {
@TableId(type = IdType.AUTO)
private Integer id;
/**
* 订单编号
*/
private String orderNum;
/**
* 商品名称
*/
private String name;
/**
* 商品数
*/
private Integer count;
}
...
/**
* 事务日志
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_transaction_log")
public class TransactionLog {
@TableId(type = IdType.AUTO)
private int id;
/**
* 事务ID
*/
private String txid;
public TransactionLog(String txid) {
this.txid = txid;
}
}
然后定义事务消息的发送者OrderProducerService,通过刚刚定义的非标rocketMQTemplate发送事务消息到RocketMQ。与此同时,还需要通过实现RocketMQLocalTransactionListener接口的executeLocalTransaction、checkLocalTransaction方法以用于调用业务Service执行本地事务、回查本地事务执行结果。特别地,在RocketMQLocalTransactionListener实现类上需要添加@RocketMQTransactionListener注解,并通过rocketMQTemplateBeanName属性指定相应的rocketMQTemplate实例名
@Service
@Slf4j
public class OrderProducerService {
/*
* 按名注入, 使用非标的rocketMQTemplate
*/
@Qualifier("extRocketMQTemplate1")
@Autowired
private RocketMQTemplate extRocketMQTemplate;
/**
* 发送事务消息
* @param order
* @param txid
*/
public void sendTransactionMsg(Order order, String txid) {
Message<Order> message = MessageBuilder
.withPayload( order )
.setHeader("txid", txid)
.build();
String topic = "order_create";
TransactionSendResult sendResult = extRocketMQTemplate.sendMessageInTransaction(topic, message, null);
LocalTransactionState localTransactionState = sendResult.getLocalTransactionState();
log.info("sendResult: {}", JSON.toJSON(sendResult));
}
@RocketMQTransactionListener(rocketMQTemplateBeanName="extRocketMQTemplate1")
public static class OrderTransactionListenerImpl implements RocketMQLocalTransactionListener {
@Autowired
private OrderService orderService;
@Autowired
private TransactionLogMapper transactionLogMapper;
/**
* 执行本地事务
* @param msg
* @param arg
* @return
*/
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
RocketMQLocalTransactionState state = RocketMQLocalTransactionState.COMMIT;
try {
String payload = new String((byte[]) msg.getPayload());
Order order = JSON.parseObject(payload, Order.class);
String txid = (String) msg.getHeaders().get("txid");
// 通过业务Service执行本地事务
orderService.createOrder(order, txid);
} catch (Exception e) {
// 本地事务执行失败, 故向RocketMQ返回 rollback 状态
log.info("Happen Exception: {}", e.getMessage());
state = RocketMQLocalTransactionState.ROLLBACK;
}
return state;
}
/**
* 回查本地事务的结果
* @param msg
* @return
*/
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
// 获取事务ID
String txid = (String) msg.getHeaders().get("txid");
List<TransactionLog> transactionLogList = transactionLogMapper.selectList(
new QueryWrapper<TransactionLog>().eq("txid", txid)
);
// 事务日志表中无该事务ID的记录
if( CollectionUtils.isEmpty(transactionLogList) ) {
return RocketMQLocalTransactionState.ROLLBACK;
}
return RocketMQLocalTransactionState.COMMIT;
}
}
}
最后提供一个Controller接口便于测试
@RestController
@RequestMapping("order")
@Slf4j
public class OrderController {
@Autowired
private OrderProducerService orderProducerService;
@RequestMapping("/create")
public String create(@RequestParam(required=false) Integer id) {
Order order = Order.builder()
.orderNum( UUID.randomUUID().toString() )
.name("iPhone 13 Pro")
.count(2)
.build();
// 生成一个事务ID
String txid = UUID.randomUUID().toString();
orderProducerService.sendTransactionMsg(order, txid);
return "order create complete";
}
}
库存服务
而对于库存服务而言,同样需要向POM中添加RocketMQ相关依赖。此处不再赘述。然后通过@RocketMQMessageListener实现消息的监听、消费即可。需要注意的是由于RocketMQ消费者端的重试机制,故为避免重复消费,消费者侧在进行库存扣减时需要保证幂等性
@Service
@Slf4j
@RocketMQMessageListener(topic = "order_create", consumerGroup = "consumerGroup1")
public class OrderConsumerService implements RocketMQListener<Order> {
@Override
public void onMessage(Order order) {
log.info("[Consumer]: {} ", order);
// 业务处理: 扣减库存
...
}
}
小结
最大努力通知方案是分布式事务中对一致性要求最低的一种,适用于一些最终一致性时间敏感度低的业务;
允许发起通知方处理业务失败,在接收通知方收到通知后积极进行失败处理,无论发起通知方如何处理结果都会不影响到接收通知方的后 续处理;发起通知方需提供查询执行情况接口,用于接收通知方校对结果。典型的使用场景:银行通知、支付结果 通知等。
最大努力通知方案需要实现如下功能 : 1、消息重复通知机制。 2、消息校对机制。
Dubbo和Spring Cloud的选择
1、两者对比
支持微服务的技术栈非常多,当前最流行的就是Dubbo和SpringCloud,至于如何选择,我们可以做如下优缺点的比较再做判断。
首先看一下组件对比图:
当然我们不能从支持的组件更加完善就简单判断首选SpringCloud,我们深入从整体架构,核心要素,协议,服务依赖,组件流程详细比较
Dubbo和Spring Cloud的优缺点:
1)、从整体架构上来看
Dubbo的架构图是这样的,
Provider: 暴露服务的提供方,可以通过jar或者容器的方式启动服务
Consumer:调用远程服务的服务消费方。
Registry: 服务注册中心和发现中心。
Monitor: 统计服务和调用次数,调用时间监控中心。(dubbo的控制台页面中可以显示,目前只有一个简单版本)
Container:服务运行的容器。
而Spring Cloud的架构图是这样的
Service Provider: 暴露服务的提供方。
Service Consumer:调用远程服务的服务消费方。
EureKa Server: 服务注册中心和服务发现中心。
点评:
Dubbo和SpringCloud的模式都比较接近,都需要服务提供方,注册中心,服务消费方。但SpringCLoud具备更为完善的组件。
2)、从核心要素来看
Dubbo只是实现了服务治理,而Spring Cloud子项目分别覆盖了微服务架构下的众多部件,而服务治理只是其中的一个方面。
Dubbo提供了各种Filter,对于上述中“无”的要素,可以通过扩展Filter来完善。
例如:
1.分布式配置:可以使用淘宝的diamond、百度的disconf来实现分布式配置管理
2.服务跟踪:可以使用京东开源的Hydra,或者扩展Filter用Zippin来做服务跟踪
3.批量任务:可以使用当当开源的Elastic-Job、tbschedule
点评:
从核心要素来看,Spring Cloud 更胜一筹,在开发过程中只要整合Spring Cloud的子项目就可以顺利的完成各种组件的融合,而Dubbo需要通过实现各种Filter来做定制,开发成本以及技术难度略高。
3)、从协议上看
1、Dubbo:使用RPC通讯协议,提供序列化方式如下:
Dubbo缺省协议采用单一长连接和JNIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
rmi:RMI协议采用JDK标准的java.rmi.*实现,采用阻塞式短连接和JDK标准序列化方式
Hessian:Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现
http:采用Spring的HttpInvoker实现
Webservice:基于CXF的frontend-simple和transports-http实现
2、Spring Cloud:Spring Cloud 使用HTTP协议的REST API
点评:
Dubbo默认采用的是单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。Dubbo还支持其他各种通信协议,而Spring Cloud 使用HTTP协议的REST API。因此,在通信速度上Dubbo略胜。
4)、从服务依赖方式看
1,Dubbo:服务提供方与消费方通过接口的方式依赖,服务调用设计如下:
interface层:服务接口层,定义了服务对外提供的所有接口
Molel层:服务的DTO对象层,
business层:业务实现层,实现interface接口并且和DB交互
因此需要为每个微服务定义了各自的interface接口,并通过持续集成发布到私有仓库中,调用方应用对微服务提供的抽象接口存在强依赖关系,开发、测试、集成环境都需要严格的管理版本依赖。
通过maven的install & deploy命令把interface和Model层发布到仓库中,服务调用方只需要依赖interface和model层即可。在开发调试阶段只发布Snapshot版本。等到服务调试完成再发布Release版本,通过版本号来区分每次迭代的版本。通过xml配置方式即可方面接入dubbo,对程序无入侵。
Dubbo接口依赖方式
2,SpringCloud:
服务提供方和服务消费方通过json方式交互,因此只需要定义好相关json字段即可,消费方和提供方无接口依赖。通过注解方式来实现服务配置,对于程序有一定入侵。
点评:
Dubbo服务依赖比较重,需要有完善的版本管理机制,但是程序入侵少。而Spring Cloud是自有生态,省略了版本管理的问题,它使用JSON进行交互,为跨平台调用奠定了基础。
5)、从组件运行流程看
1,dubbo组件运行流程
图中的Dubbo的每个组件都是需要部署在单独的服务器上, 用来接收前端请求、聚合服务,并批量调用后台原子服务。每个Service层和单独的DB交互。
gateWay:前置网关,具体业务操作,gateWay通过dubbo提供的负载均衡机制自动完成
Service:原子服务,只提供该业务相关的原子服务
Zookeeper:原子服务注册到zk上
2,SpringCloud 组件运行流程:
所有请求都统一通过 API 网关(Zuul)来访问内部服务。
网关接收到请求后,从注册中心(Eureka)获取可用服务。
由 Ribbon 进行均衡负载后,分发到后端的具体实例。
微服务之间通过 Feign 进行通信处理业务。
Spring Cloud所有请求都统一通过 API 网关(Zuul)来访问内部服务。网关接收到请求后,从注册中心(Eureka)获取可用服务。由 Ribbon 进行均衡负载后,分发到后端的具体实例。微服务之间通过 Feign 进行通信处理业务。
点评:
业务部署方式相同,都需要前置一个网关来隔绝外部直接调用原子服务的风险。Dubbo需要自己开发一套API 网关,而SpringCloud则可以通过Zuul配置即可完成网关定制。使用方式上Spring Cloud略胜一筹。
总结:
Dubbo出生于阿里系,是阿里巴巴服务化治理的核心框架,并被广泛应用于中国各互联网公司;只需要通过spring配置的方式即可完成服务化,对于应用无入侵。设计的目的还是服务于自身的业务为主。虽然阿里内部原因dubbo曾经一度暂停维护版本,但是框架本身的成熟度以及文档的完善程度,完全能满足各大互联网公司的业务需求。如果我们需要使用配置中心、分布式跟踪这些内容都需要自己去集成,这样无形中增加了使用Dubbo 的难度。
Spring Cloud 是大名鼎鼎的 Spring 家族的产品, 专注于企业级开源框架的研发。 Spring Cloud 自从发展到现在,仍然在不断的高速发展,几乎考虑了服务治理的方方面面,开发起来非常的便利和简单。
但是,两者的业务部署方式相同,都需要前置一个网关来隔绝外部直接调用原子服务的风险。Dubbo需要自己开发一套API 网关,而Spring Cloud则可以通过Zuul配置就可以完成网关定制。所以,从使用方式上Spring Cloud更加方便。
Ribbon负载均衡
概念:
负载均衡机制是高可用网络的关键组件。
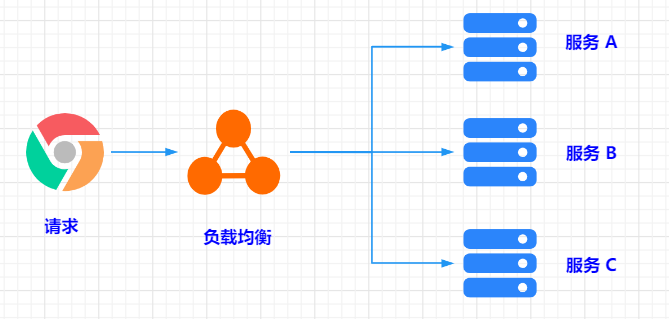
负载均衡的两个基本点:
-
选择哪个服务器来处理客户端请求。
-
将客户端请求转发出去。
一个核心原理:通过硬件或软件的方式维护一个服务列表清单。当用户发送请求时,会将请求发送给负载均衡器,然后根据负载均衡算法从可用的服务列表中选出一台服务器的地址,将请求进行转发,完成负载功能。
Ribbon 主要有五大功能组件:
ServerList服务列表:ServerList 主要用来获取所有服务的地址信息,并存到本地。
根据获取服务信息的方式不同,又分为静态存储和动态存储。
静态存储:从配置文件中获取服务节点列表并存储到本地。
动态存储:从注册中心获取服务节点列表并存储到本地
Rule负载均衡策略:
轮循均衡(Round Robin)权重轮询均衡(Weighted Round Robin)随机均衡(Random)响应速度均衡(Response Time)
Ping心跳检查:
IPing 接口类用来检测哪些服务可用。如果不可用了,就剔除这些服务。
实现类主要有这几个:PingUrl、PingConstant、NoOpPing、DummyPing、NIWSDiscoveryPing。
心跳检测策略对象 IPingStrategy,默认实现是轮询检测。
ServerListFilter服务过滤列表:
将获取到的服务列表按照过滤规则过滤。
-
通过 Eureka 的分区规则对服务实例进行过滤。
-
比较服务实例的通信失败数和并发连接数来剔除不够健康的实例。
-
根据所属区域过滤出同区域的服务实例。
ServerListUpdater服务更新列表。
服务列表更新就是 Ribbon 会从注册中心获取最新的注册表信息。是由这个接口 ServerListUpdater 定义的更新操作。而它有两个实现类,也就是有两种更新方式:
-
通过定时任务进行更新。由这个实现类 PollingServerListUpdater 做到的。
-
利用 Eureka 的事件监听器来更新。由这个实现类 EurekaNotificationServerListUpdater 做到的。
Ribbon 源码中关于均衡策略的 UML 类图。
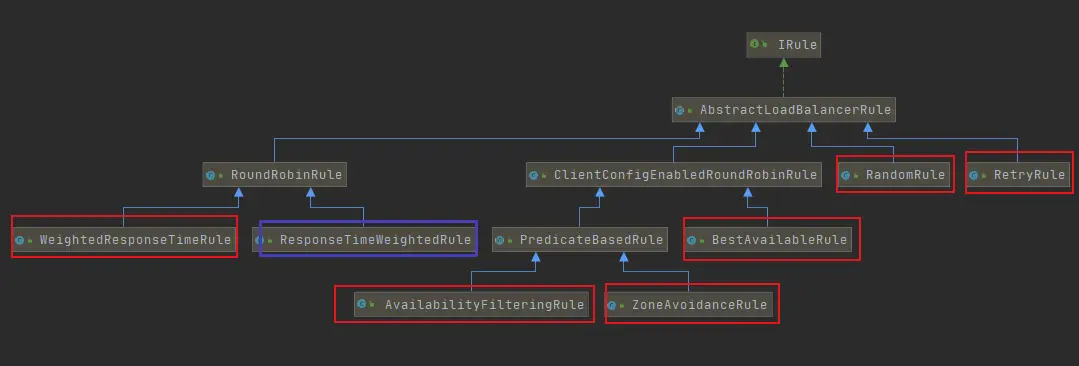
Ribbon 拦截请求的原理
本文最开始提出了一个问题:负载均衡器如何将客户端请求进行拦截然后选择服务器进行转发?
结合上面介绍的 Ribbon 核心组件,我们可以画一张原理图来梳理下 Ribbon 拦截请求的原理:
第一步:Ribbon 拦截所有标注@loadBalance注解的 RestTemplate。RestTemplate 是用来发送 HTTP 请求的。
第二步:将 Ribbon 默认的拦截器 LoadBalancerInterceptor 添加到 RestTemplate 的执行逻辑中,当 RestTemplate 每次发送 HTTP 请求时,都会被 Ribbon 拦截。
第三步:拦截后,Ribbon 会创建一个 ILoadBalancer 实例。
第四步:ILoadBalancer 实例会使用 RibbonClientConfiguration 完成自动配置。就会配置好 IRule,IPing,ServerList。
第五步:Ribbon 会从服务列表中选择一个服务,将请求转发给这个服务。
Ribbon 初始化的原理
当我们去剖析 Ribbon 源码的时候,需要找到一个突破口,而 @LoadBalanced 注解就是一个比较好的入口。
先来一张 Ribbon 初始化的流程图:
Ribbon 初始化过程
添加注解的代码如下所示:
@LoadBalanced
@Bean
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
复制
第一步:Ribbon 有一个自动配置类 LoadBalancerAutoConfiguration,SpringBoot 加载自动配置类,就会去初始化 Ribbon。
第二步:当我们给 RestTemplate 或者 AsyncRestTemplate 添加注解后,Ribbon 初始化时会收集加了 @LoadBalanced 注解的 RestTemplate 和 AsyncRestTemplate ,把它们放到一个 List 里面。
第三步:然后 Ribbon 里面的 RestTemplateCustomizer 会给每个 RestTemplate 进行定制化,也就是加上了拦截器:LoadBalancerInterceptor。
第四步:从 Eureka 注册中心获取服务列表,然后存到 Ribbon 中。
第五步:加载 YMAL 配置文件,配置好负载均衡配置,创建一个 ILoadbalancer 实例。
Ribbon 同步服务列表原理
Ribbon 首次从 Eureka 获取全量注册表后,就会隔一定时间获取注册表。原理图如下:
Ribbon 同步服务列表的原理图
之前我们提到过 Ribbon 的核心组件 ServerListUpdater,用来同步注册表的,它有一个实现类 PollingServerListUpdater ,专门用来做定时同步的。默认1s 后执行一个 Runnable 线程,后面就是每隔 30s 执行 Runnable 线程。这个 Runnable 线程就是去获取 Eureka 注册表的。
Ribbon 心跳检测的原理
Ribbon 的心跳检测原理和 Eureka 还不一样,Ribbon 不是通过每个服务向 Ribbon 发送心跳或者 Ribbon 给每个服务发送心跳来检测服务是否存活的。
先来一张图看下 Ribbon 的心跳检测机制:
Ribbon 心跳检测的原理
Ribbon 心跳检测原理:对自己本地缓存的 Server List 进行遍历,看下每个服务的状态是不是 UP 的。具体的代码就是 isAlive 方法。
核心代码:
isAlive = status.equals(InstanceStatus.UP);
复制
那么多久检测一次呢?
默认每隔 30s 执行以下 PingTask 调度任务,对每个服务执行 isAlive 方法,判断下状态。
一. 源码解读核心接口
-
ILoadBalancer Ribbon通过ILoadBalancer接口对外提供统一的选择服务器(Server)的功能,此接口会根据不同的负载均衡策略(IRule)选择合适的Server返回给使用者。其核心方法如下:
public interface ILoadBalancer {
public void addServers(List<Server> newServers);
public Server chooseServer(Object key);
public void markServerDown(Server server);
public List<Server> getReachableServers();
public List<Server> getAllServers();
}
此接口默认实现类为ZoneAwareLoadBalancer,相关类关系图如下:

-
IRule IRule是负载均衡策略的抽象,ILoadBalancer通过调用IRule的choose()方法返回Server,其核心方法如下:
public interface IRule{
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
实现类有:
-
BestAviableRule 跳过熔断的Server,在剩下的Server中选择并发请求最低的Server
-
ClientConfigEnabledRoundRobinRule、RoundRobinRule 轮询
-
RandomRule 随机选择
-
RetryRule 可重试的策略,可以对其他策略进行重试,默认轮询重试
-
WeightedResponseTimeRule 根据响应时间加权,响应时间越短权重越大
-
AvailabilityFilteringRule 剔除因为连续链接、读失败或链接超过最大限制导致熔断的Server,在剩下读Server中进行轮询。
相关类图如下:

-
IPing IPing用来检测Server是否可用,ILoadBalancer的实现类维护一个Timer每隔10s检测一次Server的可用状态,其核心方法有:
public interface IPing {
public boolean isAlive(Server server);
}
其实现类有:

image
-
IClientConfig IClientConfig主要定义了用于初始化各种客户端和负载均衡器的配置信息,器实现类为DefaultClientConfigImpl。
二. 负载均衡的逻辑实现
1. Server的选择
ILoadBalancer接口的主要实现类为BaseLoadBalancer和ZoneAwareLoadBalancer,ZoneAwareLoadBalancer为BaseLoadBalancer的子类并且其也重写了chooseServer方法,ZoneAwareLoadBalancer从其名称可以看出这个实现类是和Spring Cloud的分区有关的,当分区的数量为1(默认配置)时它直接调用父类BaseLoadBalancer的chooseServer()方法,源码如下:
@Override
public Server chooseServer(Object key) {
if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) {
// 调用父类BaseLoadBalancer的chooseServer()方法
return super.chooseServer(key);
}
// 略
}
类BaseLoadBalancer的chooseServer()方法直接调用IRule接口的choose()方法,源码如下:
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
这里IRule的实现类为ZoneAvoidanceRule,choose()方法的实现在其父类PredicateBasedRule中,如下:
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
从上面源码可以看出,其先调用ILoadBalancer的getAllServers()方法获取所有Server列表,getAllServers()方法的实现在BaseLoadBalancer类中,此类维护了一个List<Server>类型的属性allServerList,所有Server都缓存至此集合中。获取Server列表后调用chooseRoundRobinAfterFiltering()方法返回Server对象。chooseRoundRobinAfterFiltering()方法会根据loadBalancerKey筛选出候选的Server,然后通过轮询的负载均衡策略选出Server,相关源码如下:
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextIndex.get();
int next = (current + 1) % modulo;
if (nextIndex.compareAndSet(current, next) && current < modulo)
return current;
}
}
可以看到其轮询选择Server的策略为获取次数加1然后对Server数量取余得到。
2. Server的状态检测
BaseLoadBalancer类的集合allServerList缓存了所有Server信息,但是这些Server的状态有可能发生变化,比如Server不可用了,Ribbon就需要及时感知到,那么Ribbon是如何感知Server可用不可用的呢? BaseLoadBalancer的构造函数中初始化了一个任务调度器Timer,这个调度器每隔10s执行一次PingTask任务,相关源码如下:
public BaseLoadBalancer(String name, IRule rule, LoadBalancerStats stats,
IPing ping, IPingStrategy pingStrategy) {
this.name = name;
this.ping = ping;
this.pingStrategy = pingStrategy;
setRule(rule);
setupPingTask();
lbStats = stats;
init();
}
void setupPingTask() {
if (canSkipPing()) {
return;
}
if (lbTimer != null) {
lbTimer.cancel();
}
lbTimer = new ShutdownEnabledTimer("NFLoadBalancer-PingTimer-" + name,
true);
lbTimer.schedule(new PingTask(), 0, pingIntervalSeconds * 1000);
forceQuickPing();
}
class PingTask extends TimerTask {
public void run() {
try {
new Pinger(pingStrategy).runPinger();
} catch (Exception e) {
logger.error("LoadBalancer [{}]: Error pinging", name, e);
}
}
}
深入Pinger和SerialPingStrategy的源码可知,最终通过NIWSDiscoveryPing这一IPing实现类判断Server是否可用,NIWSDiscoveryPing的isAlive()方法通过判断与Server关联的InstanceInfo的status是否为UP来判断Server是否可用,其isAlive()方法源码如下:
public boolean isAlive(Server server) {
boolean isAlive = true;
if (server!=null && server instanceof DiscoveryEnabledServer){
DiscoveryEnabledServer dServer = (DiscoveryEnabledServer)server;
InstanceInfo instanceInfo = dServer.getInstanceInfo();
if (instanceInfo!=null){
InstanceStatus status = instanceInfo.getStatus();
if (status!=null){
// 其状态是否为UP
isAlive = status.equals(InstanceStatus.UP);
}
}
}
return isAlive;
}
三、Ribbon的使用姿势
1. RestTemplate + @LoadBalanced
-
使用 提供一个标记@LoadBalanced的RestTemplate Bean,然后直接使用此Bean发起请求即可,如下:
@Configuration
public class Config {
@Bean
@LoadBalanced
RestTemplate restTemplate() {
// 提供一个标记@LoadBalanced的RestTemplat Bean
return new RestTemplate();
}
}
@RestController
public class HelloController {
@Resource
private RestTemplate restTemplate;
@GetMapping("/hi")
public String hi() {
// 直接使用即可
return restTemplate.getForEntity("http://Eureka-Producer/hello", String.class).getBody();
}
}
-
实现原理 当实例化LoadBalancerAutoConfiguration时,给所有标记了@LoadBalanced的RestTemplate Bean设置了拦截器LoadBalancerInterceptor,此实例保存在了RestTemplate的父类InterceptingHttpAccessor的集合List<ClientHttpRequestInterceptor> interceptors中。RestTemplate相关类图如下:

image
设置拦截器LoadBalancerInterceptor源码如下:
@Configuration @ConditionalOnClass(RestTemplate.class) @ConditionalOnBean(LoadBalancerClient.class) @EnableConfigurationProperties(LoadBalancerRetryProperties.class) public class LoadBalancerAutoConfiguration { // 1. 收集到所有标记了@LoadBalanced的RestTemplate @LoadBalanced @Autowired(required = false) private List<RestTemplate> restTemplates = Collections.emptyList(); @Bean public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated( final ObjectProvider<List<RestTemplateCustomizer>> restTemplateCustomizers) { return () -> restTemplateCustomizers.ifAvailable(customizers -> { for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) { for (RestTemplateCustomizer customizer : customizers) { // 3. 对于每一个RestTemplate执行customize()方法 customizer.customize(restTemplate); } } }); } @Bean @ConditionalOnMissingBean public LoadBalancerRequestFactory loadBalancerRequestFactory( LoadBalancerClient loadBalancerClient) { return new LoadBalancerRequestFactory(loadBalancerClient, transformers); } @Configuration @ConditionalOnMissingClass("org.springframework.retry.support.RetryTemplate") static class LoadBalancerInterceptorConfig { @Bean public LoadBalancerInterceptor ribbonInterceptor( LoadBalancerClient loadBalancerClient, LoadBalancerRequestFactory requestFactory) { // 2. 注入LoadBalancerInterceptor return new LoadBalancerInterceptor(loadBalancerClient, requestFactory); } @Bean @ConditionalOnMissingBean public RestTemplateCustomizer restTemplateCustomizer( final LoadBalancerInterceptor loadBalancerInterceptor) { return restTemplate -> { // 4. customize()方法给RestTemplate设置LoadBalancerInterceptor List<ClientHttpRequestInterceptor> list = new ArrayList<>( restTemplate.getInterceptors()); list.add(loadBalancerInterceptor); restTemplate.setInterceptors(list); }; } } // 略 }从上面源码可以看出LoadBalancerInterceptor的构造函数接受两个参数:LoadBalancerClient和LoadBalancerRequestFactory,LoadBalancerRequestFactory的实例在此Configuration中被注入类,而LoadBalancerClient的实例却没有。那么LoadBalancerClient的实例是在哪里实例化的呢?答案是RibbonAutoConfiguration,这个Configuration注入了LoadBalancerClient的实现类RibbonLoadBalancerClient的实例和SpringClientFactory的实例,相关源码如下:
@Bean public SpringClientFactory springClientFactory() { SpringClientFactory factory = new SpringClientFactory(); factory.setConfigurations(this.configurations); return factory; } @Bean @ConditionalOnMissingBean(LoadBalancerClient.class) public LoadBalancerClient loadBalancerClient() { return new RibbonLoadBalancerClient(springClientFactory()); }至此拦截器LoadBalancerInterceptor创建完成并且保存在了RestTemplate的集合属性中,那么RestTemplate是如何利用此拦截器的呢?当我们使用RestTemplate发起请求时最终会调用到RestTemplate的doExecute()方法,此方法会创建ClientHttpRequest对象并调用其execute()方法发起请求,源码如下:
protected <T> T doExecute(URI url, @Nullable HttpMethod method, @Nullable RequestCallback requestCallback, @Nullable ResponseExtractor<T> responseExtractor) throws RestClientException { ClientHttpResponse response = null; try { // 1. 创建ClientHttpRequest。 ClientHttpRequest request = createRequest(url, method); if (requestCallback != null) { requestCallback.doWithRequest(request); } // 2. 执行其execute()方法获取结果。 response = request.execute(); handleResponse(url, method, response); return (responseExtractor != null ? responseExtractor.extractData(response) : null); } catch (IOException ex) { String resource = url.toString(); String query = url.getRawQuery(); resource = (query != null ? resource.substring(0, resource.indexOf('?')) : resource); throw new ResourceAccessException("I/O error on " + method.name() + " request for \"" + resource + "\": " + ex.getMessage(), ex); } finally { if (response != null) { response.close(); } } } protected ClientHttpRequest createRequest(URI url, HttpMethod method) throws IOException { ClientHttpRequest request = getRequestFactory().createRequest(url, method); if (logger.isDebugEnabled()) { logger.debug("HTTP " + method.name() + " " + url); } return request; } @Override public ClientHttpRequestFactory getRequestFactory() { List<ClientHttpRequestInterceptor> interceptors = getInterceptors(); if (!CollectionUtils.isEmpty(interceptors)) { ClientHttpRequestFactory factory = this.interceptingRequestFactory; if (factory == null) { factory = new InterceptingClientHttpRequestFactory(super.getRequestFactory(), interceptors); this.interceptingRequestFactory = factory; } return factory; } else { return super.getRequestFactory(); } }从上面的getRequestFactory()方法可以看到当集合interceptors不为空的时候ClientHttpRequest对象是由类InterceptingClientHttpRequestFactory的createRequest()方法创建出来的,并且集合interceptors作为参数传递到了InterceptingClientHttpRequestFactory中,深入InterceptingClientHttpRequestFactory的createRequest()方法,如下:
public class InterceptingClientHttpRequestFactory extends AbstractClientHttpRequestFactoryWrapper { private final List<ClientHttpRequestInterceptor> interceptors; public InterceptingClientHttpRequestFactory(ClientHttpRequestFactory requestFactory, @Nullable List<ClientHttpRequestInterceptor> interceptors) { super(requestFactory); this.interceptors = (interceptors != null ? interceptors : Collections.emptyList()); } @Override protected ClientHttpRequest createRequest(URI uri, HttpMethod httpMethod, ClientHttpRequestFactory requestFactory) { // 直接返回InterceptingClientHttpRequest对象。 return new InterceptingClientHttpRequest(requestFactory, this.interceptors, uri, httpMethod); } }可以看到拦截器最终传递到了InterceptingClientHttpRequest中,上面说了RestTemplate的doExecute()方法创建了InterceptingClientHttpRequest对象且调用了其execute()方法获取响应结果,深入其execute()方法发现在execute()中直接调用了拦截器的intercept()方法,也即InterceptingClientHttpRequest的intercept()方法,源码如下:
public ClientHttpResponse execute(HttpRequest request, byte[] body) throws IOException { if (this.iterator.hasNext()) { ClientHttpRequestInterceptor nextInterceptor = this.iterator.next(); // 这里调用InterceptingClientHttpRequest的intercept()方法 return nextInterceptor.intercept(request, body, this); } // 略 }也就是说RestTemplate的请求最终是委托给InterceptingClientHttpRequest来处理。那么InterceptingClientHttpRequest是如何利用Ribbon相关接口处理请求的呢?且看InterceptingClientHttpRequest的intercept()方法:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor { private LoadBalancerClient loadBalancer; private LoadBalancerRequestFactory requestFactory; public LoadBalancerInterceptor(LoadBalancerClient loadBalancer, LoadBalancerRequestFactory requestFactory) { this.loadBalancer = loadBalancer; this.requestFactory = requestFactory; } public LoadBalancerInterceptor(LoadBalancerClient loadBalancer) { // for backwards compatibility this(loadBalancer, new LoadBalancerRequestFactory(loadBalancer)); } @Override public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException { final URI originalUri = request.getURI(); String serviceName = originalUri.getHost(); // 直接调用LoadBalancerClient的execute()方法。 return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution)); } }可以看到InterceptingClientHttpRequest的intercept()方法直接调用LoadBalancerClient的execute()方法,LoadBalancerClient是一个接口,这里其实现类为RibbonLoadBalancerClient,上面创建InterceptingClientHttpRequest时提到LoadBalancerAutoConfiguration注入了RibbonLoadBalancerClient Bean,此Bean通过构造函数保存在了LoadBalancerClient中。那么接下来就是LoadBalancerClient的execute()方法了,类是LoadBalancerClient非常有意思,先看下其类图:

image
LoadBalancerClient的execute()方法首先会通过调用SpringClientFactory的getLoadBalancer()方法获取ILoadBalancer,那么此方法是如何返回ILoadBalancer呢?很简单,就是从Spring上下文中获取,那么Spring上下文中的ILoadBalancer时何时注入的呢?答案是RibbonClientConfiguration,此Configuration向Spring上下文注入了以下Bean:
-
ILoadBalancer的实现类ZoneAwareLoadBalancer。
-
IRule的实现类ZoneAvoidanceRule。
-
IClientConfig的实现类DefaultClientConfigImpl。
另外EurekaRibbonClientConfiguration还注入了:
-
ServerList的实现类DomainExtractingServerList和DiscoveryEnabledNIWSServerList。
-
IPing的实现类NIWSDiscoveryPing。
源码如下:
@Bean @ConditionalOnMissingBean public IClientConfig ribbonClientConfig() { DefaultClientConfigImpl config = new DefaultClientConfigImpl(); config.loadProperties(this.name); config.set(CommonClientConfigKey.ConnectTimeout, DEFAULT_CONNECT_TIMEOUT); config.set(CommonClientConfigKey.ReadTimeout, DEFAULT_READ_TIMEOUT); config.set(CommonClientConfigKey.GZipPayload, DEFAULT_GZIP_PAYLOAD); return config; } @Bean @ConditionalOnMissingBean public IRule ribbonRule(IClientConfig config) { if (this.propertiesFactory.isSet(IRule.class, name)) { return this.propertiesFactory.get(IRule.class, config, name); } ZoneAvoidanceRule rule = new ZoneAvoidanceRule(); rule.initWithNiwsConfig(config); return rule; } @Bean @ConditionalOnMissingBean public ServerList<Server> ribbonServerList(IClientConfig config) { if (this.propertiesFactory.isSet(ServerList.class, name)) { return this.propertiesFactory.get(ServerList.class, config, name); } ConfigurationBasedServerList serverList = new ConfigurationBasedServerList(); serverList.initWithNiwsConfig(config); return serverList; } @Bean @ConditionalOnMissingBean public ILoadBalancer ribbonLoadBalancer(IClientConfig config, ServerList<Server> serverList, ServerListFilter<Server> serverListFilter, IRule rule, IPing ping, ServerListUpdater serverListUpdater) { if (this.propertiesFactory.isSet(ILoadBalancer.class, name)) { return this.propertiesFactory.get(ILoadBalancer.class, config, name); } return new ZoneAwareLoadBalancer<>(config, rule, ping, serverList, serverListFilter, serverListUpdater); } @Bean @ConditionalOnMissingBean public IPing ribbonPing(IClientConfig config) { if (this.propertiesFactory.isSet(IPing.class, serviceId)) { return this.propertiesFactory.get(IPing.class, config, serviceId); } NIWSDiscoveryPing ping = new NIWSDiscoveryPing(); ping.initWithNiwsConfig(config); return ping; } @Bean @ConditionalOnMissingBean public ServerList<?> ribbonServerList(IClientConfig config, Provider<EurekaClient> eurekaClientProvider) { if (this.propertiesFactory.isSet(ServerList.class, serviceId)) { return this.propertiesFactory.get(ServerList.class, config, serviceId); } DiscoveryEnabledNIWSServerList discoveryServerList = new DiscoveryEnabledNIWSServerList( config, eurekaClientProvider); DomainExtractingServerList serverList = new DomainExtractingServerList( discoveryServerList, config, this.approximateZoneFromHostname); return serverList; }ZoneAwareLoadBalancer的构造函数通过调用DiscoveryEnabledNIWSServerList的getUpdatedListOfServers()方法获取Server集合,DiscoveryEnabledNIWSServerList维护了一个Provider<EurekaClient>类型的属性eurekaClientProvider,eurekaClientProvider缓存了EurekaClient的实现类CloudEurekaClient的实例,getUpdatedListOfServers()方法通过调用CloudEurekaClient的getInstancesByVipAddress()方法从Eureka Client缓存中获取应用对应的所有InstanceInfo列表。源码如下:
// 缓存了EurekaClient的实现类CloudEurekaClient的实例 private final Provider<EurekaClient> eurekaClientProvider; @Override public List<DiscoveryEnabledServer> getUpdatedListOfServers(){ return obtainServersViaDiscovery(); } private List<DiscoveryEnabledServer> obtainServersViaDiscovery() { List<DiscoveryEnabledServer> serverList = new ArrayList<DiscoveryEnabledServer>(); if (eurekaClientProvider == null || eurekaClientProvider.get() == null) { logger.warn("EurekaClient has not been initialized yet, returning an empty list"); return new ArrayList<DiscoveryEnabledServer>(); } EurekaClient eurekaClient = eurekaClientProvider.get(); if (vipAddresses!=null){ for (String vipAddress : vipAddresses.split(",")) { // if targetRegion is null, it will be interpreted as the same region of client List<InstanceInfo> listOfInstanceInfo = eurekaClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion); for (InstanceInfo ii : listOfInstanceInfo) { if (ii.getStatus().equals(InstanceStatus.UP)) { if(shouldUseOverridePort){ if(logger.isDebugEnabled()){ logger.debug("Overriding port on client name: " + clientName + " to " + overridePort); } InstanceInfo copy = new InstanceInfo(ii); if(isSecure){ ii = new InstanceInfo.Builder(copy).setSecurePort(overridePort).build(); }else{ ii = new InstanceInfo.Builder(copy).setPort(overridePort).build(); } } DiscoveryEnabledServer des = createServer(ii, isSecure, shouldUseIpAddr); serverList.add(des); } } if (serverList.size()>0 && prioritizeVipAddressBasedServers){ break; // if the current vipAddress has servers, we dont use subsequent vipAddress based servers } } } return serverList; }LoadBalancerClient的execute()方法在通过调用SpringClientFactory的getLoadBalancer()方法获取ILoadBalancer后调用其chooseServer()返回一个Server对象,如下:
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint) throws IOException { // 1. 获取ILoadBalancer ILoadBalancer loadBalancer = getLoadBalancer(serviceId); // 2. 通过ILoadBalancer选择一个Server Server server = getServer(loadBalancer, hint); if (server == null) { throw new IllegalStateException("No instances available for " + serviceId); } RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server, serviceId), serverIntrospector(serviceId).getMetadata(server)); // 3. 对Server发起请求 return execute(serviceId, ribbonServer, request); } protected Server getServer(ILoadBalancer loadBalancer, Object hint) { if (loadBalancer == null) { return null; } // Use 'default' on a null hint, or just pass it on? return loadBalancer.chooseServer(hint != null ? hint : "default"); }ZoneAwareLoadBalancer的chooseServer()方法会通过调用ZoneAvoidanceRule的choose()方法返回一个Server,ZoneAvoidanceRule继承类ClientConfigEnabledRoundRobinRule,所以其会根据ZoneAwareLoadBalancer获取的Server列表采用轮询的负载均衡策略选择一个Server返回;最后根据此Server的地址等向其发起请求。 相关类图如下:

image
-
2. Feign接口
相对于RestTemplate+@Loadbalance的方式,我们在使用Spring Cloud的时候使用更多的是Feign接口,因为Feign接口使用起来会更加简单,下面就是一个使用Feign接口调用服务的例子:
// 定义Feign接口
@FeignClient(value = "Eureka-Producer", fallbackFactory = HelloClientFallbackFactory.class)
public interface HelloClient {
@GetMapping("/hello")
String hello();
}
// 订单熔断快速失败回调
@Component
public class HelloClientFallbackFactory implements FallbackFactory<HelloClient>, HelloClient {
@Override
public HelloClient create(Throwable throwable) {
return this;
}
@Override
public String hello() {
return "熔断";
}
}
// 使用
@RestController
public class HelloController {
@Resource
private HelloClient helloClient;
@GetMapping("/hello")
public String hello() {
return helloClient.hello();
}
}
与RestTemplate的通过RibbonLoadBalancerClient获取Server并执行请求类似,Feign接口通过LoadBalancerFeignClient获取Server并执行请求。DefaultFeignLoadBalancedConfiguration会注入LoadBalancerFeignClient Bean,源码如下:
@Configuration
class DefaultFeignLoadBalancedConfiguration {
@Bean
@ConditionalOnMissingBean
public Client feignClient(CachingSpringLoadBalancerFactory cachingFactory,
SpringClientFactory clientFactory) {
return new LoadBalancerFeignClient(new Client.Default(null, null),
cachingFactory, clientFactory);
}
}
那么Feign接口是如何通过LoadBalancerFeignClient实现负载均衡调用的呢?在《Feign源码解析》一文中介绍到Feign接口的代理实现类由FeignClientFactoryBean负责生成,FeignClientFactoryBean实现了FactoryBean,所以其getObject()方法会返回Feign接口的代理实现,getObject()方法会从Spring上下文中获取到LoadBalancerFeignClient,源码如下:
@Override
public Object getObject() throws Exception {
return getTarget();
}
<T> T getTarget() {
FeignContext context = applicationContext.getBean(FeignContext.class);
Feign.Builder builder = feign(context);
if (!StringUtils.hasText(this.url)) {
if (!this.name.startsWith("http")) {
url = "http://" + this.name;
}
else {
url = this.name;
}
url += cleanPath();
return (T) loadBalance(builder, context, new HardCodedTarget<>(this.type,
this.name, url));
}
if (StringUtils.hasText(this.url) && !this.url.startsWith("http")) {
this.url = "http://" + this.url;
}
String url = this.url + cleanPath();
// 从Spring上下文中获取LoadBalancerFeignClient
Client client = getOptional(context, Client.class);
if (client != null) {
if (client instanceof LoadBalancerFeignClient) {
// not load balancing because we have a url,
// but ribbon is on the classpath, so unwrap
client = ((LoadBalancerFeignClient)client).getDelegate();
}
builder.client(client);
}
Targeter targeter = get(context, Targeter.class);
return (T) targeter.target(this, builder, context, new HardCodedTarget<>(
this.type, this.name, url));
}
LoadBalancerFeignClient对外提供服务的接口是execute()方法,那么此方法是何时被Feign接口调用的呢?从《Feign源码解析》一文中可知SynchronousMethodHandler作为MethodHandler的实现在调用Feign接口时进行拦截并执行其invoke()方法,invoke()方法则调用了LoadBalancerFeignClient的execute()方法发起网络请求,相关源码如下:
@Override
public Object invoke(Object[] argv) throws Throwable {
RequestTemplate template = buildTemplateFromArgs.create(argv);
Retryer retryer = this.retryer.clone();
while (true) {
try {
return executeAndDecode(template);
} catch (RetryableException e) {
// 略
continue;
}
}
}
Object executeAndDecode(RequestTemplate template) throws Throwable {
Request request = targetRequest(template);
if (logLevel != Logger.Level.NONE) {
logger.logRequest(metadata.configKey(), logLevel, request);
}
Response response;
long start = System.nanoTime();
try {
// 调用LoadBalancerFeignClient的execute()方法获取响应。
response = client.execute(request, options);
} catch (IOException e) {
if (logLevel != Logger.Level.NONE) {
logger.logIOException(metadata.configKey(), logLevel, e, elapsedTime(start));
}
throw errorExecuting(request, e);
}
// 略
}
那么LoadBalancerFeignClient的execute()方法又是如何利用Ribbon做负载均衡的呢?其通过调用CachingSpringLoadBalancerFactory的create()方法获取FeignLoadBalancer对象,FeignLoadBalancer对象持有一个ILoadBalancer的对象实例,此ILoadBalancer对象实例是CachingSpringLoadBalancerFactory通过调用SpringClientFactory的getLoadBalancer()方法从Spring上下文中获取的,源码如下:
public FeignLoadBalancer create(String clientName) {
FeignLoadBalancer client = this.cache.get(clientName);
if(client != null) {
return client;
}
IClientConfig config = this.factory.getClientConfig(clientName);
ILoadBalancer lb = this.factory.getLoadBalancer(clientName);
ServerIntrospector serverIntrospector = this.factory.getInstance(clientName, ServerIntrospector.class);
client = loadBalancedRetryFactory != null ? new RetryableFeignLoadBalancer(lb, config, serverIntrospector,
loadBalancedRetryFactory) : new FeignLoadBalancer(lb, config, serverIntrospector);
this.cache.put(clientName, client);
return client;
}
创建完FeignLoadBalancer后紧接着接着调用了FeignLoadBalancer的executeWithLoadBalancer()方法,如下:
@Override
public Response execute(Request request, Request.Options options) throws IOException {
URI asUri = URI.create(request.url());
String clientName = asUri.getHost();
URI uriWithoutHost = cleanUrl(request.url(), clientName);
FeignLoadBalancer.RibbonRequest ribbonRequest = new FeignLoadBalancer.RibbonRequest(
this.delegate, request, uriWithoutHost);
IClientConfig requestConfig = getClientConfig(options, clientName);
// 执行FeignLoadBalancer的executeWithLoadBalancer()方法。
return lbClient(clientName).executeWithLoadBalancer(ribbonRequest,
requestConfig).toResponse();
// 略
}
// 创建FeignLoadBalancer对象并返回
private FeignLoadBalancer lbClient(String clientName) {
return this.lbClientFactory.create(clientName);
}
executeWithLoadBalancer()方法的具体实现在类FeignLoadBalancer的父类AbstractLoadBalancerAwareClient中,如下:
public T executeWithLoadBalancer(final S request, final IClientConfig requestConfig) throws ClientException {
LoadBalancerCommand<T> command = buildLoadBalancerCommand(request, requestConfig);
try {
return command.submit(
new ServerOperation<T>() {
@Override
public Observable<T> call(Server server) {
URI finalUri = reconstructURIWithServer(server, request.getUri());
S requestForServer = (S) request.replaceUri(finalUri);
try {
return Observable.just(AbstractLoadBalancerAwareClient.this.execute(requestForServer, requestConfig));
}
catch (Exception e) {
return Observable.error(e);
}
}
})
.toBlocking()
.single();
} catch (Exception e) {
// 略
}
}
executeWithLoadBalancer()方法创建了LoadBalancerCommand对象并且向提交(submit()方法)了一个ServerOperation对象,跟踪LoadBalancerCommand的submit()方法发现其调用了selectServer()方法获取Server,而selectServer()方法则委托给了FeignLoadBalancer的父类LoadBalancerContext的getServerFromLoadBalancer()方法获取Server,如下:
public T executeWithLoadBalancer(final S request, final IClientConfig requestConfig) throws ClientException {
LoadBalancerCommand<T> command = buildLoadBalancerCommand(request, requestConfig);
try {
return command.submit(
new ServerOperation<T>() {
@Override
public Observable<T> call(Server server) {
URI finalUri = reconstructURIWithServer(server, request.getUri());
S requestForServer = (S) request.replaceUri(finalUri);
try {
return Observable.just(AbstractLoadBalancerAwareClient.this.execute(requestForServer, requestConfig));
}
catch (Exception e) {
return Observable.error(e);
}
}
})
.toBlocking()
.single();
} catch (Exception e) {
Throwable t = e.getCause();
if (t instanceof ClientException) {
throw (ClientException) t;
} else {
throw new ClientException(e);
}
}
}
public Observable<T> submit(final ServerOperation<T> operation) {
final ExecutionInfoContext context = new ExecutionInfoContext();
// 略
// 这里当server为null时调用selectServer()获取Server。
Observable<T> o =
(server == null ? selectServer() : Observable.just(server))
.concatMap(new Func1<Server, Observable<T>>() {
@Override
// Called for each server being selected
public Observable<T> call(Server server) {
context.setServer(server);
final ServerStats stats = loadBalancerContext.getServerStats(server);
// Called for each attempt and retry
Observable<T> o = Observable
.just(server)
.concatMap(new Func1<Server, Observable<T>>() {
@Override
public Observable<T> call(final Server server) {
// 略
}
});
// 略
}
private Observable<Server> selectServer() {
return Observable.create(new OnSubscribe<Server>() {
@Override
public void call(Subscriber<? super Server> next) {
try {
// 调用LoadBalancerContext的getServerFromLoadBalancer()获取Server
Server server = loadBalancerContext.getServerFromLoadBalancer(loadBalancerURI, loadBalancerKey);
next.onNext(server);
next.onCompleted();
} catch (Exception e) {
next.onError(e);
}
}
});
}
FeignLoadBalancer和LoadBalancerCommand互相依赖、彼此调用,最终FeignLoadBalancer的父类LoadBalancerContext的getServerFromLoadBalancer()方法返回了Server,此方法通过调用其持有的ILoadBalancer对象的chooseServer()方法获取Server,源码如下:
public Server getServerFromLoadBalancer(@Nullable URI original, @Nullable Object loadBalancerKey) throws ClientException {
String host = null;
int port = -1;
if (original != null) {
host = original.getHost();
}
if (original != null) {
Pair<String, Integer> schemeAndPort = deriveSchemeAndPortFromPartialUri(original);
port = schemeAndPort.second();
}
// 获取ILoadBalancer
ILoadBalancer lb = getLoadBalancer();
// 调用ILoadBalancer的chooseServer()方法获取Server。
Server svc = lb.chooseServer(loadBalancerKey);
if (svc == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Load balancer does not have available server for client: "
+ clientName);
}
host = svc.getHost();
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Invalid Server for :" + svc);
}
logger.debug("{} using LB returned Server: {} for request {}", new Object[]{clientName, svc, original});
return svc;
}
至此终于看到了通过ILoadBalancer获取Server的代码了,相关类图如下:

四、总结
Ribbon通过ILoadBalancer接口提供负载均衡服务,其实现原理为:
-
ILoadBalancer依赖ServerList通过DiscoveryClient从Eureka Client处获取Server列表并缓存这些Server列表。
-
IPing接口定时对ILoadBalancer缓存的Server列表进行检测,判断其是否可用。
-
IRule接口是负载均衡策略的抽象,ILoadBalancer通过IRule选出一个Server。
当使用RestTemplate+@LoadBalanced的方式进行服务调用时,LoadBalancerInterceptor和RibbonLoadBalancerClient作为桥梁结合Ribbon提供负载均衡服务。
当使用Feign接口调用服务时,LoadBalancerFeignClient和FeignLoadBalancer作为调用Ribbon的入口为Feign接口提供负载均衡服务。
不管使用那种姿势,最终都会通过Ribbon的ILoadBalancer接口实现负载均衡。
认证和授权的区别
两者都是非常重要的主题,通常与网络相关联,作为其服务基础架构的关键部分。然而,这两个术语在完全不同的概念上是非常不同的。虽然它们通常使用相同的工具在相同的上下文中使用,但它们彼此完全不同。
身份验证意味着确认您自己的身份,而授权意味着授予对系统的访问权限。简单来说,身份验证是验证您的身份的过程,而授权是验证您有权访问的过程。
什么是认证
认证是关于验证你的凭据,如用户名/邮箱和密码,以验证访问者的身份。系统确定你是否就是你所说的使用凭据。在公共和专用网络中,系统通过登录密码验证用户身份。身份认证通常通过用户名和密码完成,有时与认证可以不仅仅通过密码的形式,也可以通过手机验证码或者生物特征等其他因素。就是验证此用户的身份。解决的是‘我是谁’的问题
认证因素
根据安全级别和应用程序类型,有不同类型的身份验证因素:
单因素身份验证 单因素身份验证是最简单的身份验证方式。它只需要用户名和密码即可允许用户访问系统。
两因素身份验证 顾名思义,它是两级安全;因此它需要两步验证来验证用户。它不仅需要用户名和密码,还需要只有特定用户知道的唯一信息,例如学校名称、最喜欢的目的地。除此之外,它还可以通过发送 OTP 或用户注册号码或电子邮件地址上的唯一链接来验证用户。
多重身份验证 这是最安全、最高级的授权级别。它需要来自不同和独立类别的两个或两个以上的安全级别。这种类型的身份验证通常用于金融组织、银行和执法机构。这确保消除来自第三方或黑客的任何数据暴露者。
在某些应用系统中,为了追求更高的安全性,往往会要求多种认证因素叠加使用,这就是我们经常说的多因素认证。
常见的认证方式:
-
用户名密码认证
-
单点登录或 SSO :是一种允许使用一组凭据访问多个应用程序的方法。它允许用户登录一次,它会自动从同一集中目录登录到所有其他 Web 应用程序
-
手机和短信验证码认证
-
邮箱和邮件验证码认证
-
人脸识别/指纹识别的生物因素认证
-
OTP 认证:在他注册的手机号码或电话号码上获得一个 OTP(一次性密码)或链接
-
Radius 网络认证
什么是授权
授权发生在系统完成身份认证之后,它也被称为 Authz。最终会授予你访问资源(如信息,文件,数据库,资金,位置,几乎任何内容)的完全权限。简单来说,授权决定了你访问系统的能力以及达到的程度。
授权是确定经过身份验证的用户是否可以访问特定资源的过程。它验证你是否有权授予你访问信息,数据库,文件等资源的权限。授权通常在验证后确认你的权限。简单来说,就像给予某人官方许可做某事或任何事情。
就是授予用户权限,能够进行后续的某些访问和操作。解决的是“我能干那些事”的问题。
授权技术
基于角色的访问控制 RBAC 或基于角色的访问控制技术根据用户在组织中的角色或配置文件提供给用户。 它可以实现为系统到系统或用户到系统。
JSON 网络令牌 JSON Web 令牌或 JWT 是一种开放标准,用于以 JSON 对象的形式在各方之间安全地传输数据。 使用私钥/公钥对验证和授权用户。
SAML SAML 代表安全断言标记语言。 它是一种向服务提供商提供授权凭证的开放标准。 这些凭证通过数字签名的 XML 文档进行交换。
OpenID 授权 它帮助客户端在身份验证的基础上验证最终用户的身份。
身份验证 OAuth 是一种授权协议,它使 API 能够对请求的资源进行身份验证和访问。
例如:
验证和确认组织中的邮箱和密码的过程称为认证,但确定哪个员工可以访问哪个楼层称为授权。
假设你正在旅行而且即将登机。当你在登记前出示机票和一些身份证明时,你会收到一张登机牌,证明机场管理局已对你的身份进行了身份验证。
但那不是它。乘务员必须授权你登上你应该乘坐的航班,让你可以进入飞机内部及其资源。
区别图示
认证与授权的主要区别如下所示:
| 认证 | 授权 |
|---|---|
| 身份验证是识别用户以提供对系统的访问的过程。 | 授权是授予访问资源权限的过程。 |
| 验证用户或客户端和服务器。 | 通过定义的策略和规则验证用户是否被允许。 |
| 认证通常在授权之前执行。 | 通常在用户成功通过身份验证后完成。 |
| 认证需要用户的登录详细信息,例如用户名和密码等。 | 授权需要用户的权限或安全级别。 |
| 数据通过令牌 ID 提供。 | 数据通过访问令牌提供。 |
| 认证示例:员工需要输入登录详细信息来验证自己以访问组织电子邮件或软件。 | 示例:员工成功进行身份验证后,他们只能根据其角色和配置文件访问和处理某些功能。 |
| 用户可以根据需要部分更改身份验证凭据。用户不能更改授权权限。 | 权限由系统的所有者/管理员授予用户,他只能更改它。 |
结论
认证(Authentication) 验证用户的身份,而 授权(Authorization) 验证用户的访问和权限。
-
认证是验证确认身份以授予对系统的访问权限。授权确定你是否有权访问资源。
-
认证是验证用户凭据以获得用户访问权限的过程。授权是验证是否允许访问的过程。
-
认证决定用户是否是他声称的用户。授权确定用户可以访问和不访问的内容。
-
认证所需的身份验证通常需要用户名和密码。授权所需的身份验证因素可能有所不同,具体取决于安全级别。
-
身份验证是授权的第一步,因此始终是第一步。授权在成功验证后完成
如果用户不能证明他们的身份,用户就不能访问系统。 如果用户通过证明正确的身份进行了身份验证,但无权执行特定功能,那么用户将无法访问该功能。 但是,这两种安全方法经常一起使用
分布式系统高并发解决方案
什么是高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
二、如何提升系统的并发能力
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:
垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:
提升单机处理能力。垂直扩展的方式又有两种:
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
水平扩展:
只要增加服务器数量,就能线性扩充系统性能。
水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
三、常见的互联网分层架构
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统各层次的水平扩展,又分别是如何实施的呢?
四、分层水平扩展架构实践
反向代理层的水平扩展
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
站点层的水平扩展
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
服务层的水平扩展
服务层的水平扩展,是通过“服务连接池”实现的。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
数据层的水平扩展
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
分库分表读写分离,加入缓存都属于数据层的水平扩展。
互联网数据层常见的水平拆分方式有这么几种,以数据库为例:
按照范围水平拆分
每一个数据服务,存储一定范围的数据,上图为例:
user0库,存储uid范围1-1kw
user1库,存储uid范围1kw-2kw
这个方案的好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(2)数据均衡性较好;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
不足是:
(1) 请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
按照哈希水平拆分
每一个数据库,存储某个key值hash后的部分数据,上图为例:
user0库,存储偶数uid数据
user1库,存储奇数uid数据
这个方案的好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(2)数据均衡性较好;
(3)请求均匀性较好;
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
这里需要注意的是,通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能的方式有本质的不同。
通过水平拆分扩展数据库性能:
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
通过主从同步读写分离扩展数据库性能:
(1)每个服务器上存储的数据量是和总量相同;
(2)n个服务器上的数据都一样,都是全集;
(3)理论上读性能扩充了n倍,写仍然是单点,写性能不变;
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
按照业务水平拆分
根据业务繁忙度可以加入限流,负载均衡,削峰填谷。
限流是指对用户请求进行一定程度的拦截,实现请求延时或者请求丢弃处理,相关的解决方案如下:
-
使用缓存对数据处理层进行限制,存储一些热点数据,加快访问数据的同时也防止了大量请求到达后端数据库,如 Cookie 或 Session 等;
-
使用消息队列(Message Queue,MQ)中间件将一些非即时的流量缓冲到 MQ 中,后续来实现异步处理;
-
使用网络流量高并发处理算法进行流量整形,以服务器能够承受的速率发送到 Web 应用系统后端进行处理;
-
从业务层面上,限制用户单位时间内的频繁访问操作,可以限制一部分冗余请求。
负载均衡主要通过分担负载,通过选用合适的负载均衡策略,将请求分发到不同的服务节点上,解决网络拥堵问题,从而提高网络利用率,充分的利用服务器的各种资源让集群中的节点负载情况处于平衡状态来,提高系统的灵 活性和扩展能力,以达到提高系统整体的并发量的目的,从而使得外部用户体验更佳。常用的负载均衡的调度算法如下:
-
轮询(Round Robin)
-
加权轮询(Weighted Round Robin)
-
最少连接(Least Connections)
-
加权最少连接(Weighted Least Connections)
-
随机(Random)
-
加权随机(Weighted Random)
-
源地址散列(Source Hashing)
-
源地址端口散列(Source&Port Hashing)
削峰填谷高并发处理可以抽象为消费者与生产者模型,当高峰期产出现的时候,消费者很容易出现瞬时流量非常大,但一般情况流量相对较少,这样平时的性能就浪费了。这个时候就可以引入消息队列RabbitMQ,它有三个好处:
-
解耦。生产者无需关注有多少消费者,它只需要和消息队列MQ交互,生成的数据传给MQ即可;
-
异步。生产者将数据交给MQ直接可以返回,消费者什么时候消费,无需专注
-
削峰填谷。MQ有限制消费的机制,比如之前生产者生成速率为3000,但MQ做了一个限制只有1000,那么高峰期的数据就会挤压在MQ里,高峰被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完挤压的消息,这就做“填谷”。
五、总结
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
(5)业务层可以加入限流,负载均衡,削峰填谷等策略
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









