






最近在做项目的时候用到了条件查询文章类的需求,但是MySQL的条件查询有一点死板,中间如果少几个词就会查询不到,所以我们需要一个智能的分词的,elasticsearch无疑是最好的选择,刚好我前两天发了docker安装MySQL的教程,今天发一篇docker安装elasticsearch整套的教程
按照国际惯例,我们先打开相应的官方文档,我这儿选择的是7.17版本的文档
elasticsearch:Quick start | Elasticsearch Guide [7.17] | Elastic
ikun啊对不起打错了,ik:GitHub - infinilabs/analysis-ik at 7.x
kibana:Kibana concepts | Kibana Guide [7.17] | Elastic
安装elasticsearch
先安装elasticsearch,我们打开官方文档,打开 Quick start > Set up Elasticsearch > Install Elasticsearch with Docker
拉取镜像
找到步骤之后,我们先进行国际规则的第一步,拉取镜像
docker pull elasticsearch:7.17.21我们等他拉取完成
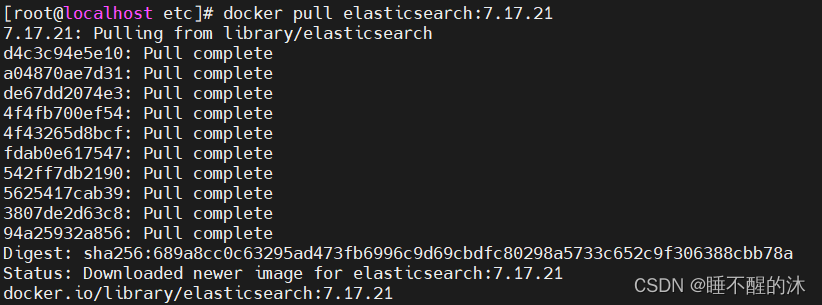
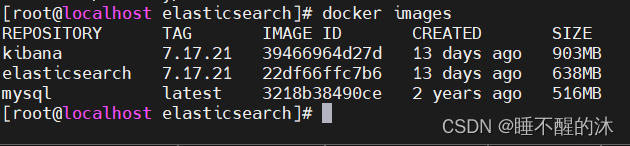
我们输入 docker images 确认一下是否下载成功
创建数据卷存放数据及配置文件的文件夹
数据卷简单来说就是跟容器内映射的文件夹,当你修改外部文件夹时,容器内的文件架也会改变
mkdir -p /opt/elasticsearch/elasticsearch/data/
mkdir -p /opt/elasticsearch/elasticsearch/config/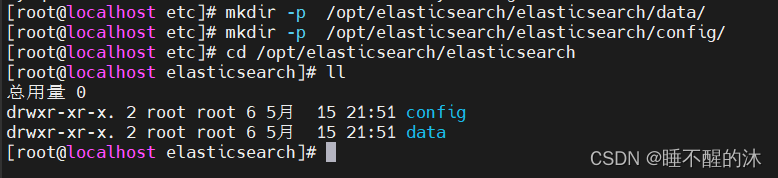
数据卷相关 官方文档:docker volume | Docker Docs
| 命令 | 说明 |
|---|---|
| docker volume create | 创建数据卷 |
| docker volume ls | 查看所有数据卷 |
| docker volume rm | 删除指定数据卷 |
| docker volume inspect | 查看某个数据卷的详情 |
| docker volume prune | 清除数据卷 |
创建文件夹完成以后,我们创建需要挂载的配置文件
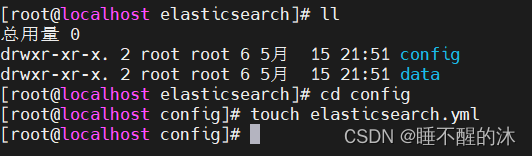
向配置文件写入配置

http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"写入完成之后,我们来给文件夹改一下相关权限,要不然挂载的时候会报错
chmod -R 777 /opt/elasticsearch/elasticsearch/启动 elasticsearch 镜像
我们做一下启动前的准备
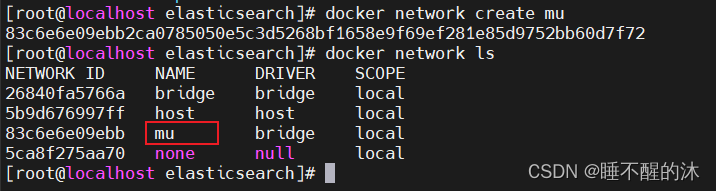
先创建Docker网络,是Docker容器之间和容器与外部网络之间的通信和连接的一种机制,有了他就可以让容器在同一个网络下进行通信
docker对于网络的文档在这边:docker network | Docker Docs
| 命令 | 说明 |
|---|---|
| docker network create | 创建一个网络 docker |
| docker network ls | 查看所有网络 |
| docker network rm | 删除指定网络 |
| docker network prune | 清除未使用的网络 |
| docker network connect | 使指定容器连接加入某网络 |
| docker network disconnect | 使指定容器连接离开某网络 |
| docker network inspect | 查看网络详细信息 |
或者我们直接help一下,也会有相对于的命令
接下来我们创建一个网络
elasticsearch 启动!
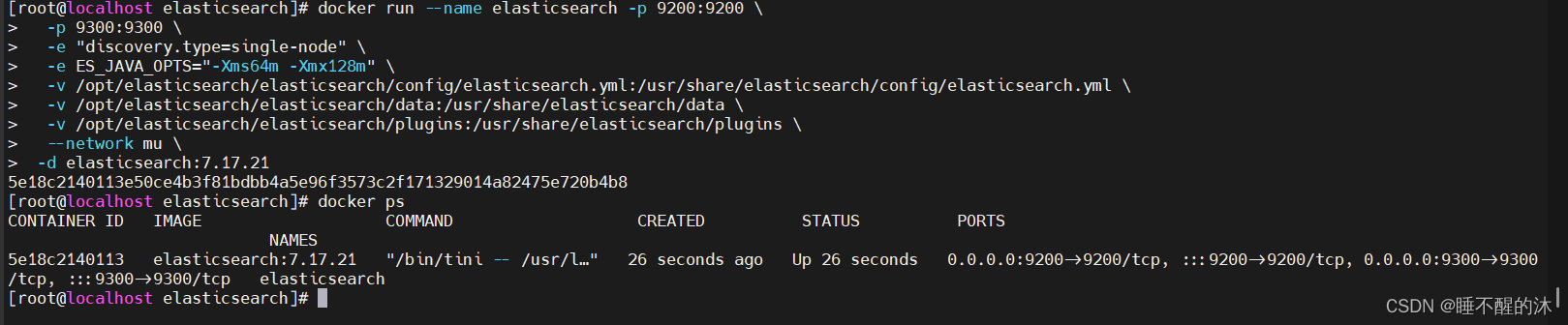
接下来我们启动原啊不对是elasticsearch
docker run --name elasticsearch -p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /opt/elasticsearch/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /opt/elasticsearch/elasticsearch/data:/usr/share/elasticsearch/data \
-v /opt/elasticsearch/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--network mu \
elasticsearch:7.17.21只要文件 能够对应上就可以了,外部文件名字不重要
在浏览器访问你的Linux的9200端口,如果出来数据就是成功了
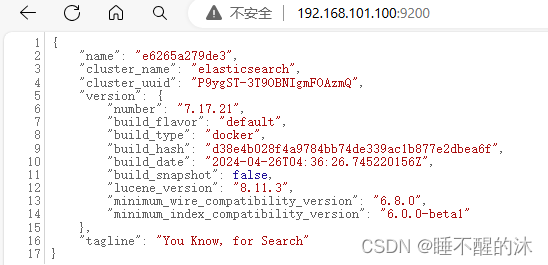
安装ik分词器
有人可能会好奇,为什么都下载好了elasticsearch,那再下载一个可视化不久好了,为什么还要下插件呢?
网上的ik介绍蛮多的,我这儿就一句话
ik分词器,更适合中国宝宝的分词器...
ik提供了两个分词算法,一个是 ik_smart 另一个是 ik_max_word
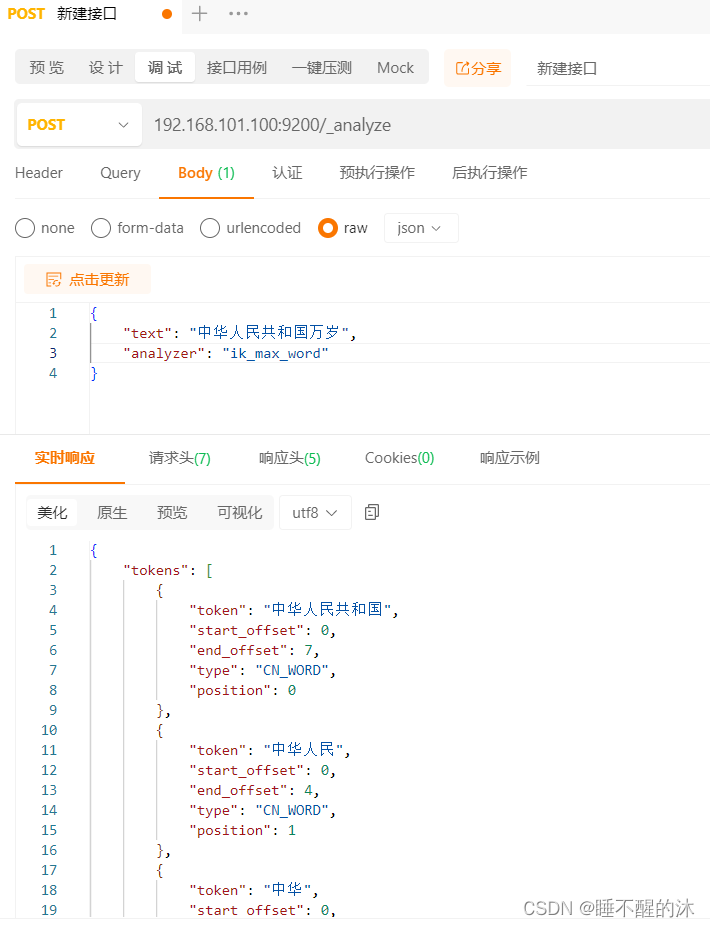
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国万岁”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、共和、国、万岁、万、岁等词语。
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国万岁”拆分为中华人民共和国、万岁。
安装ik分词器
我们用命令进入elasticsearch内部
docker exec -it elasticsearch /bin/bash
我们去官网寻找一下我们这个版本的ik分词器,尽量用版本一致的插件,以防出问题
好消息:找到了 坏消息:没有我们的版本
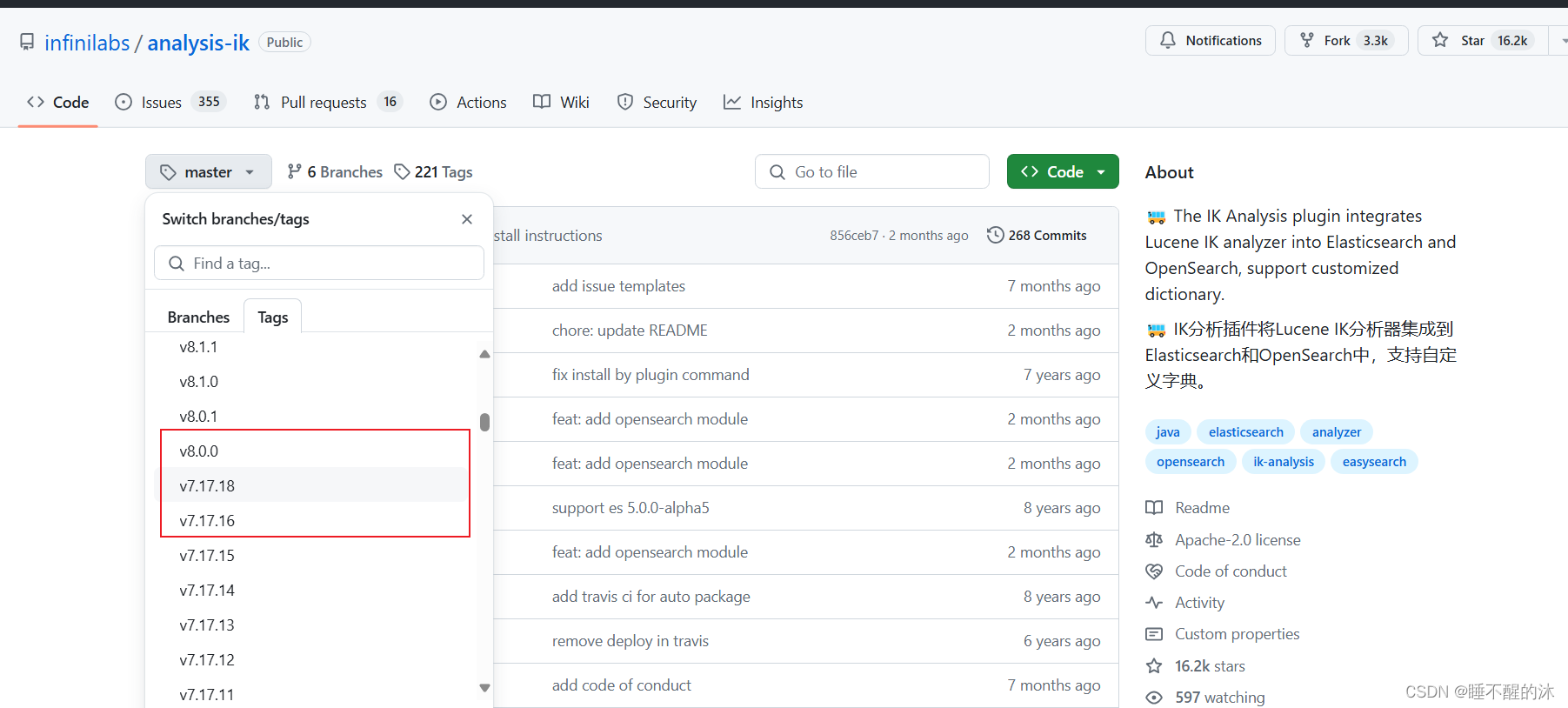
但是我在install那边找到了
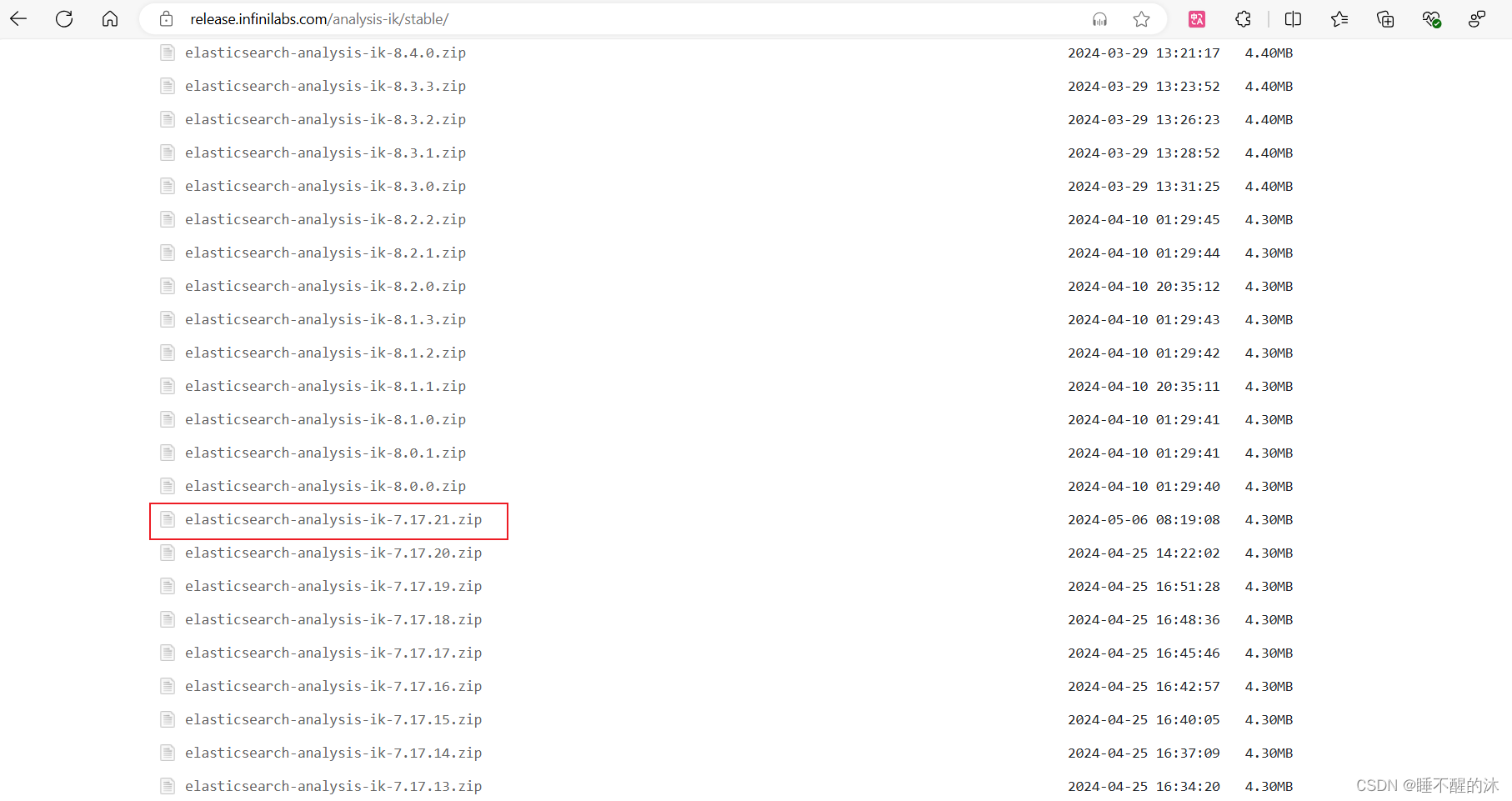
那我们直接把地址换成这边的Index of: analysis-ik/stable/ (infinilabs.com)
./bin/elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.17.21.zip
下载成功!!!
我们现在退出容器并且重启一下他
docker restart elasticsearch 我们去测试一下是否安装成功
我们去测试一下是否安装成功
ApiPost测试是否安装成功
我们先用apipost新建一个接口,访问一下地址看看是否请求成功(GET请求)
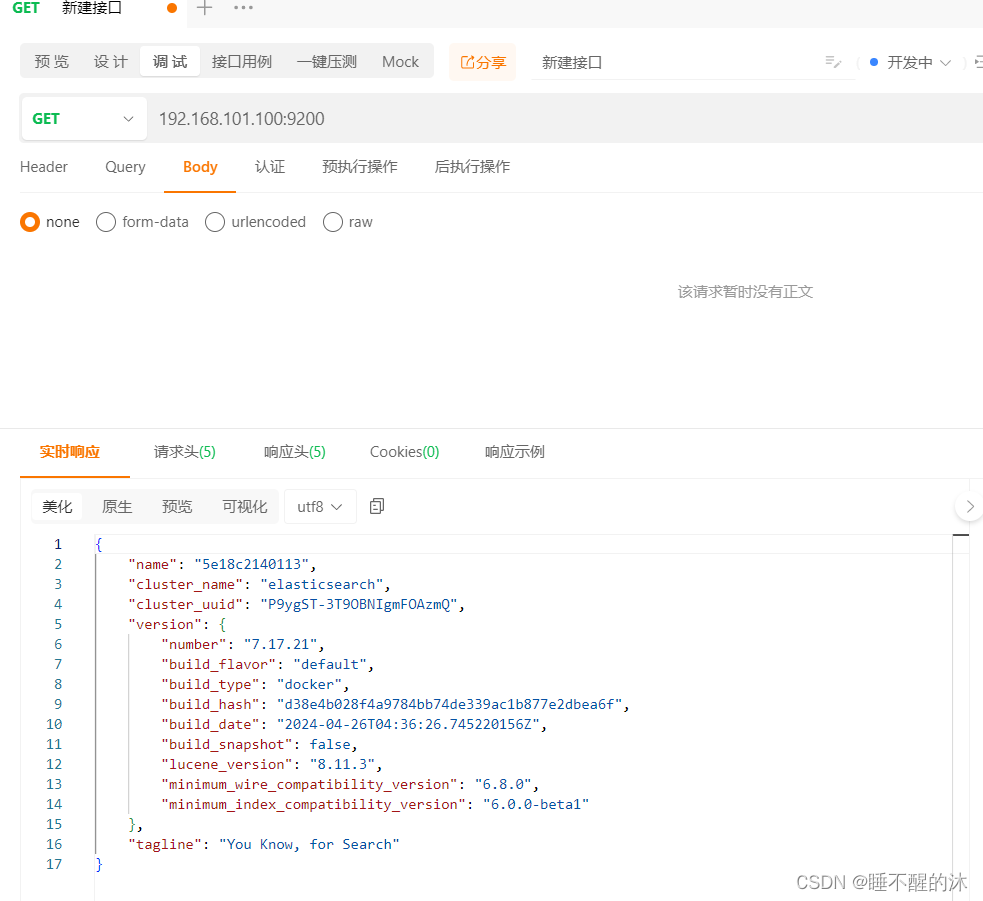
接下来我们测试插件是否安装成功(GET、POST请求都行)
测试”中华人民共和国万岁“成功
测试地址:
192.168.101.100:9200/_analyze测试JSON:
{
"text": "中华人民共和国万岁",
"analyzer": "ik_max_word"
}
我们试试 ik_smart
测试地址:
192.168.101.100:9200/_analyze测试JSON:
{
"text": "中华人民共和国万岁",
"analyzer": "ik_smart"
}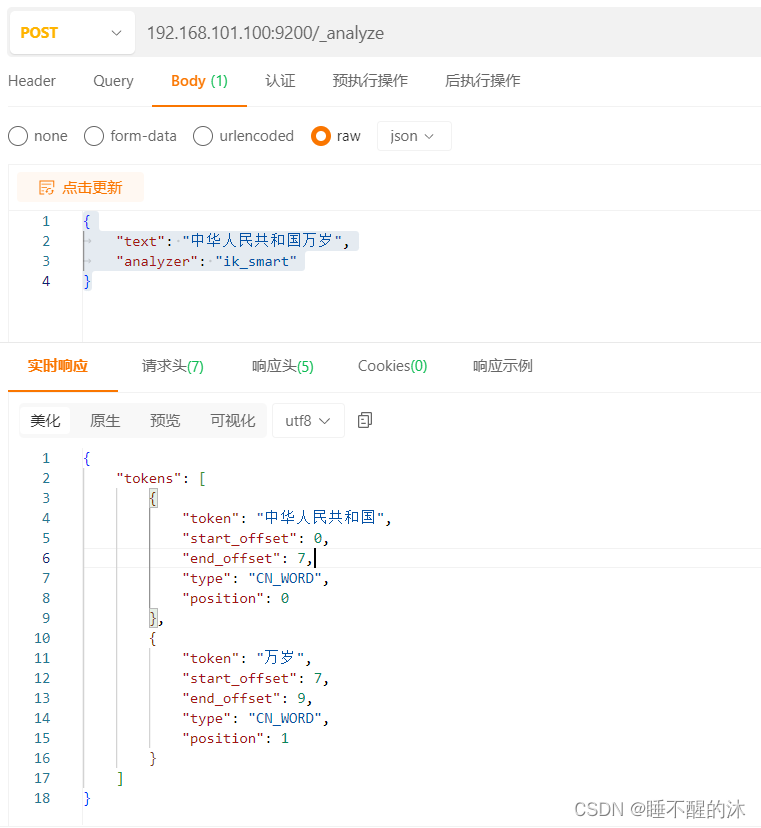 成功安装ikun分词器,我们接下来安装可视化
成功安装ikun分词器,我们接下来安装可视化
安装kibana可视化
其实可视化elasticsearch的有很多,我这里还是按国际惯例安装kibana(其实就是习惯)
我们从官网找到kibana的镜像(一定一定要记得要找版本一致的!!!)
我们打开官方文档,打开 Quick start > Set up > install Kibana > install Kibana with Docker
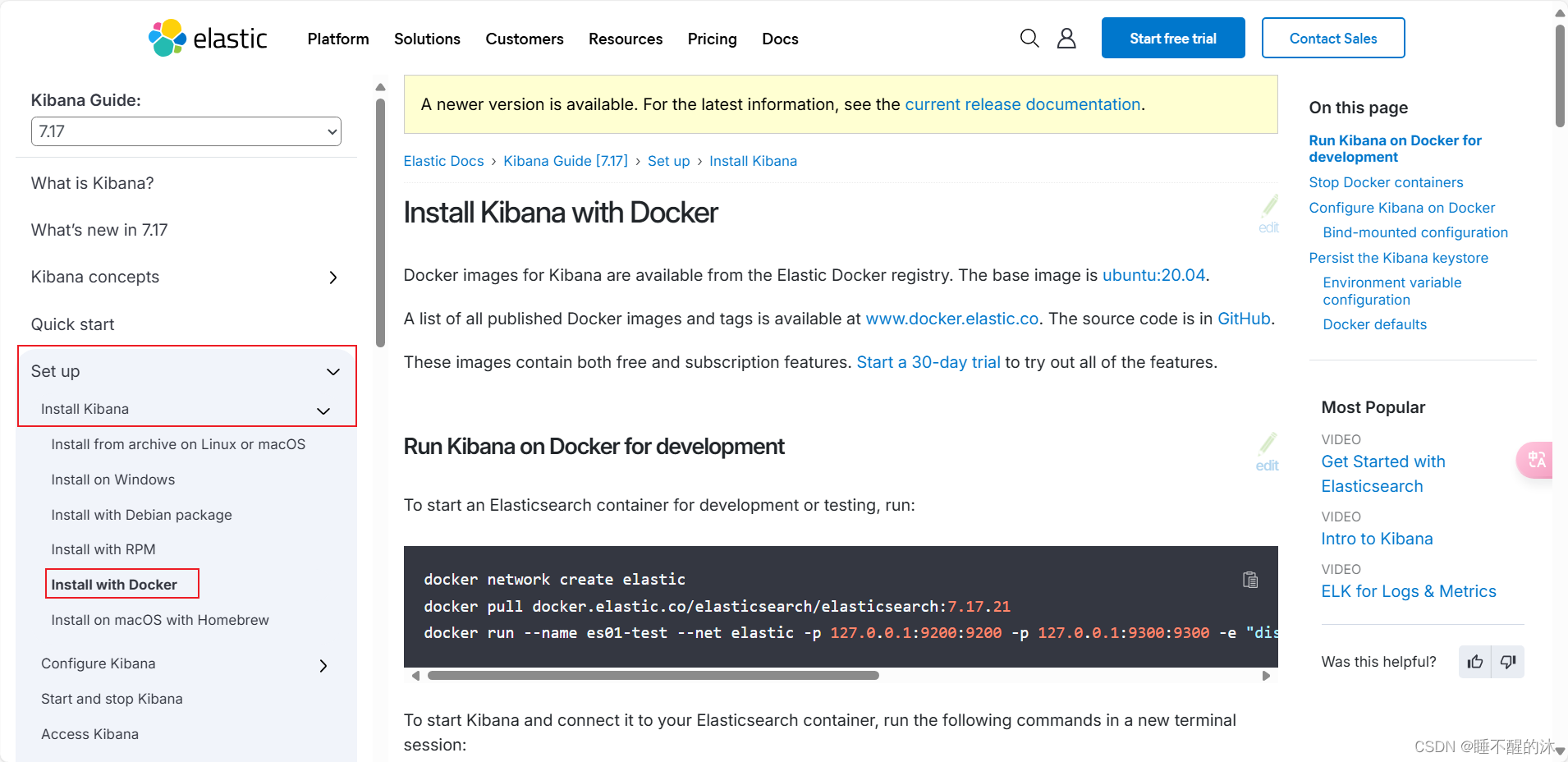
拉取镜像
我们按照国际规则第一步,先拉取镜像资源
官方这边让先创建network,我们之前自己创建了,在这儿就不创建了,往下滑找到kibana的拉取命令(上面是 elasticsearch 的不要拉取错了)
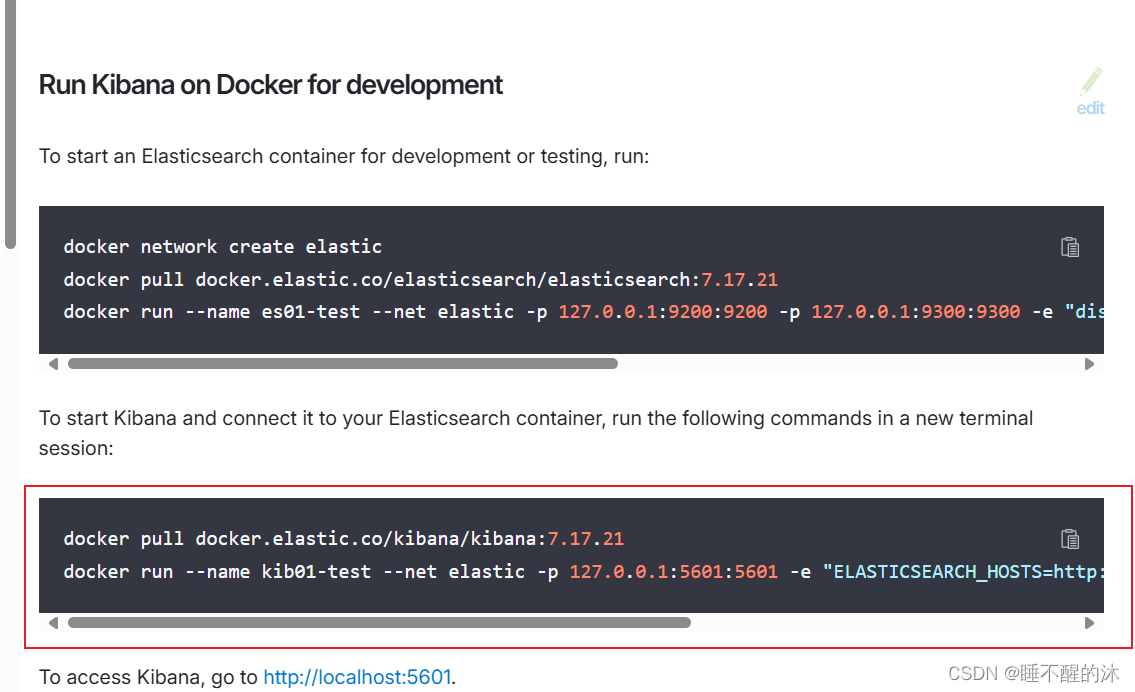
docker pull kibana:7.17.21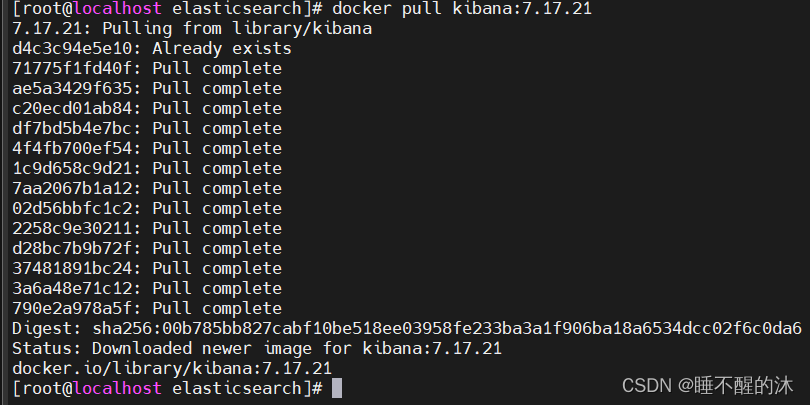
我们输入 docker images 确认一下是否下载成功
创建数据卷存放数据及配置文件的文件夹
老规矩,创建数据卷存放他的配置
mkdir /opt/elasticsearch/kibana/config/ 
创建完成我们给文件夹权限
chmod 777 kibana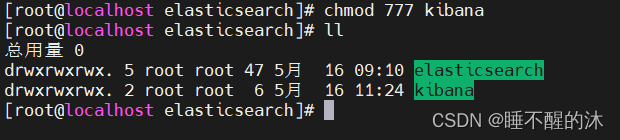
创建kibana的配置文件
touch /opt/elasticsearch/kibana/config/bibana.yml对文件进行编辑
vim /opt/elasticsearch/kibana/config/kibana.yml 
#将以下内容写入kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch:9200"]
kibana.index: ".kibana"接下来我们直接启动kibana
启动 kibana 镜像
docker run \
--name kibana \
--network mu \
-p 5601:5601 \
-v /opt/elasticsearch/kibana/config:/usr/share/kibana/config \
-d kibana:7.17.21 
美国的五星上将麦克阿瑟将军曾经说过,当你的浏览器能够在5601端口访问到可视化界面,就说明你安装成功了
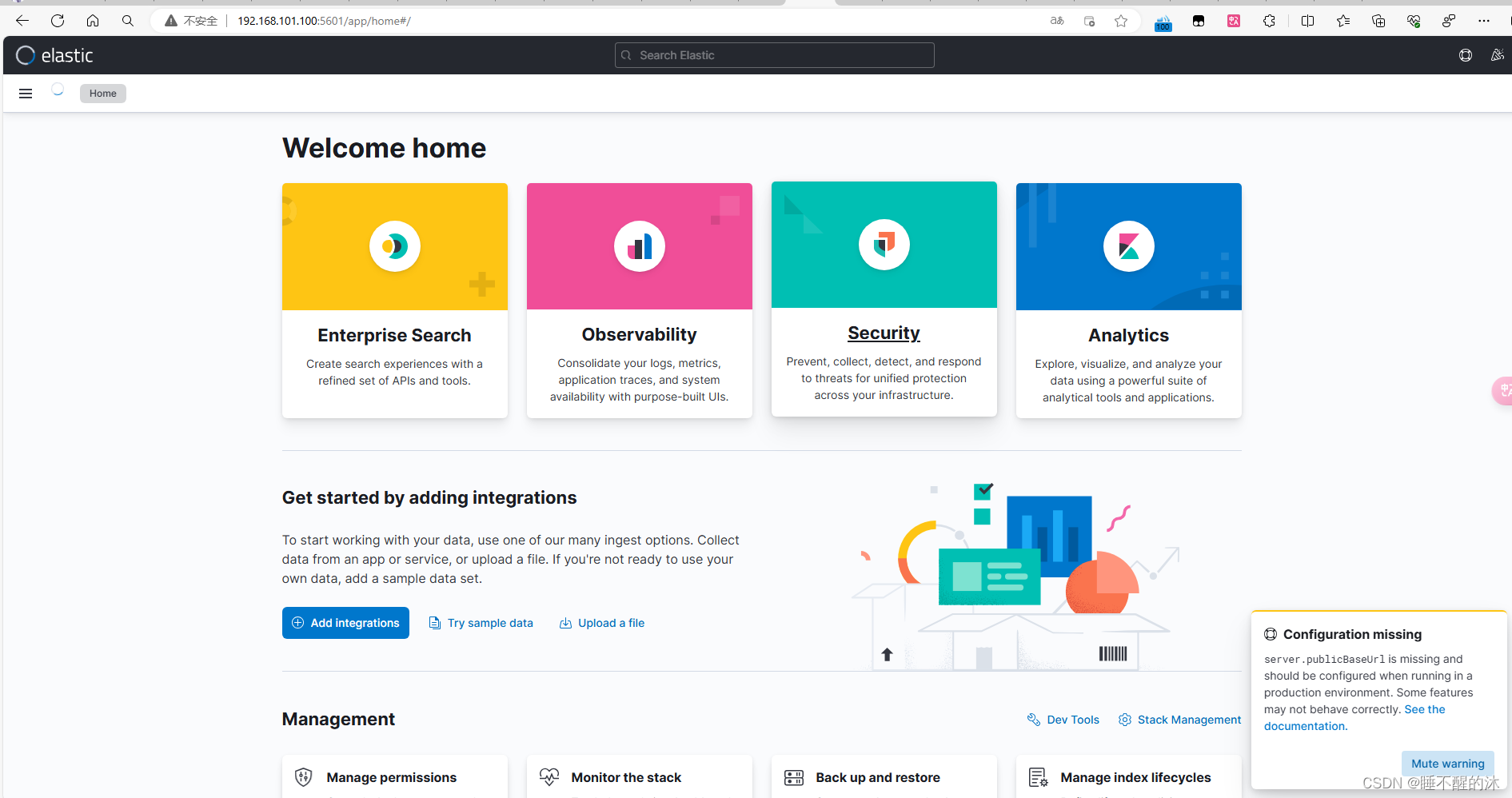















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









