






volatile实现多线程变量共享
在多线程中,变量的值都是独立的,但添加了volatile这访问修饰符的变量,别的线程也可以获取到对应的值了,volatile是如何实现的呢?我们就从这开始聊聊java多线程
这里就要聊聊多线程的内存结构了从jvm内存模型说起了。
细说的话通过上面可以看到对应的内容,这简单说下相关的部分。
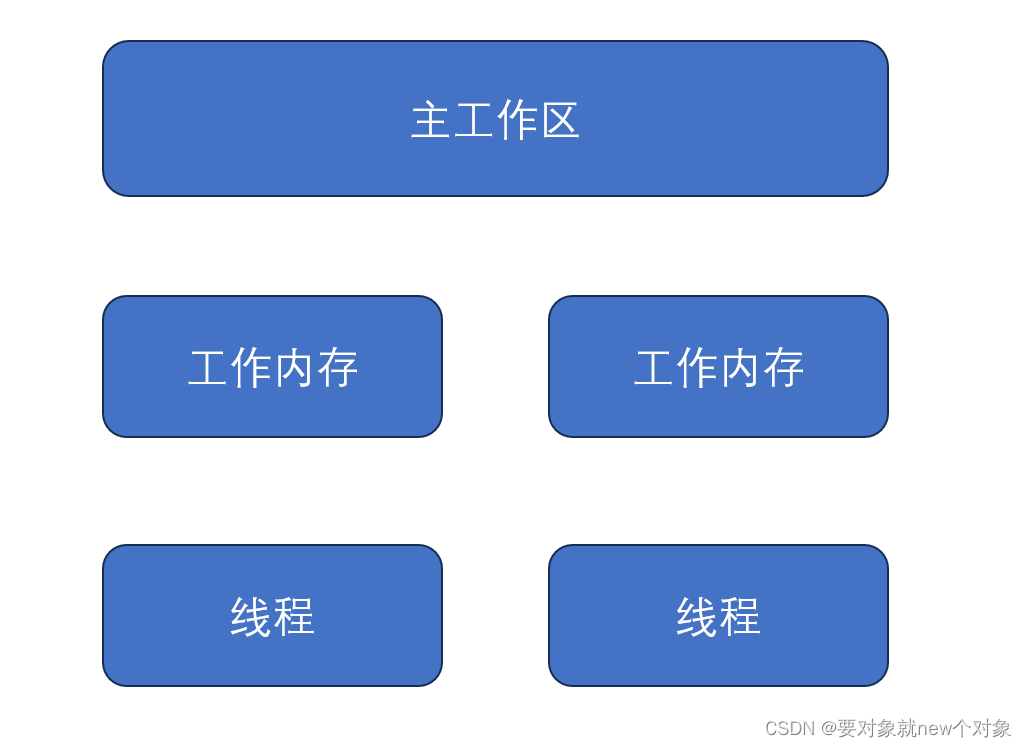
如上图所示,有几个关键点:
- 所有线程的共享变量都存储在主内存中,每个线程都有一个专属于自己的工作内存,每个线程都不会直接操作主内存中的变量,而是将主内存上的变量放进自己的工作内存中,只操作工作内存的数据。
- 当对工作内存修改完毕后,再将修改后的结果放回到主内存中。
- 每个线程都只能操作自己工作内存中的变量,无法直接访问其他工作内存的变量。
- 线程间的变量传值只能依赖主内存完成。
volatile操作有2个特点:
1.保证可见性,无法保证原子性。
保证线程更新变量后能立刻被其他线程读到,用于保证线程读到的变量一定是最新的。
内部原理为线程修改了自己工作内存的变量后,会被立即将结果刷新会主内存中。同时其他线程读到该变量的值也作废,强制重新从主内存中读取该变量的值。
所以多个线程访问同一个有volatile访问修饰符的变量,能随时拿到最新的变量值,保证了可见性。
即对 volatile 修饰的变量进行操作,无法保证多线程的安全,因为volatile 只负责保证被操作变量的原子性,如果想要保证原子性需要配合synchronized来使用。synchronized
2.有序性
每一行代码的执行顺序并不一定按照我们编写的顺序执行,为了提高执行效率,JVM 和 CPU 会对指令进行重新排序。而 volatile 会禁止 jvm 和 cpu 对其修饰的变量进行重排序,从而到达有序性。
而实现禁止指令重排,是通过内存屏蔽来实现的。
内存屏蔽
由于现代的操作系统都是多处理器.而每一个处理器都有自己的缓存,并且这些缓存并不是实时都与内存发生信息交换.这样就可能出现一个cpu上的缓存数据与另一个cpu上的缓存数据不一致的问题.而这样在多线程开发中,就有可能导致出现一些异常行为。
CPU内存屏障主要分为以下三类:
-
写屏障(Store Memory Barrier)
告诉处理器在写屏障之前的所有已经存储在存储缓存(store bufferes)中的数据同步到主内存,简单来说就是使得写屏障之前的指令的结果对写屏障之后的读或者写是可见的。
-
读屏障(Load Memory Barrier)
处理器在读屏障之后的读操作,都在读屏障之后执行。配合写屏障,使得写屏障之前的内存更新对于读屏障之后的读操作是可见的。
-
全屏障(Full Memory Barrier)
确保屏障前的内存读写操作的结果提交到内存之后,再执行屏障后的读写操作。
在JMM 中把内存屏障分为四类
-
LoadLoad屏障
对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
-
StoreStore屏障
对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
-
LoadStore屏障
对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
-
StoreLoad屏障
对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
使用
java中对内存屏障的使用在一般的代码中不太容易见到.常见的有两种.
通过 Synchronized关键字包住的代码区域,当线程进入到该区域读取变量信息时,保证读到的是最新的值。这是因为在同步区内对变量的写入操作,在离开同步区时就将当前线程内的数据刷新到内存中,而对数据的读取也不能从缓存读取,只能从内存中读取,保证了数据的读有效性。这就是插入了StoreStore屏障。
使用了volatile修饰变量,下面是基于保守策略的JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
多线程
多线程实现方式
继承Thread类
public class ExtendThread extends Thread {
public static void main(String[] args) {
//调用Thread类的currentThread()方法获取当前线程
System.out.println(Thread.currentThread().getName() + " " + j);
new ExtendThread().start();
}
public void run() {
//当通过继承Thread类的方式实现多线程时,可以直接使用this获取当前执行的线程
}
}
实现Runnable接口
class RunnableThread implements Runnable{
@Override
public void run() {
}
}
实现Callable接口
public class CallableThread implements Callable<Object> {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Object> futureTask = new FutureTask<>(new CallableThread());
new Thread(futureTask).start();
System.out.println(futureTask.get().toString());
}
@Override
public Object call() throws Exception {
return "返回内容";
}
}
CPU视角的线程五大状态
新建状态(New)
当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪状态(Runnable)
当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行状态(Running)
当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞状态(Blocked)
处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
等待阻塞 -- 运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead)
线程执行完了或者因异常退出了run()方法又或者调用 stop() 方法,该线程结束生命周期。
java视角的六大线程状态
新建状态(NEW)
当我们创建一个新的Thread对象时,该线程就处于新建状态,例如:Thread t = new Thread();
可运行状态(RUNNABLE)
当线程对象调用start()方法后,线程进入可运行状态。在这个状态下,线程已经做好了准备,随时等待CPU调度执行,这个状态包括了"就绪"和"运行"状态。
阻塞状态(BLOCKED)
线程在等待获取一个锁以进入或重新进入同步代码块时,它会进入阻塞状态。只有当该锁被释放并且线程被调度去获取这个锁,线程才能转换到RUNNABLE状态。
等待状态(WAITING)
线程进入等待状态,是因为它调用了其它线程的join方法,或者调用了无参数的wait方法。在这种情况下,线程会等待另一个线程的操作完成或者等待notify/notifyAll消息。
定时等待状态(TIMED_WAITING)
线程进入定时等待状态,是因为它调用了sleep或者带有指定时间的wait或join方法。在指定的时间过去之后,线程会自动返回RUNNABLE状态。如果它是由于调用wait或join方法进入的定时等待状态,还需要等待notify/notifyAll消息或者等待join的线程终止。
终止状态(TERMINATED)
线程任务执行完毕或者由于异常而结束,线程就会进入终止状态。在这个状态下,线程的生命周期实际上已经结束了,它不能再转换到其他任何状态。
线程池实现原理
线程池参数
public ThreadPoolExecutor(int corePoolSize, //核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, //达到最大线程数数时候,线程池的工作线程空闲后,保持存活的时间
TimeUnit unit, //keepAliveTime的单位
BlockingQueue<Runnable> workQueue, //柱塞队列
RejectedExecutionHandler handler //饱和策略
)
样例
new ThreadPoolExecutor(41,41,60,
TimeUnit.MINUTES, new LinkedBlockingQueue<Runnable>(10),new ThreadPoolExecutor.AbortPolicy());
创建的线程池具体配置为:核心线程数量为41个(我的电脑是20核的,假设业务场景为CPU密集,后面也介绍如何设置核心线程数);最大线程数量为41个;阻塞队列的长度为10,到最大线程数数时空闲线程60秒回收,饱和策略为线程池饱和后不处理,直接抛出异常。
我们通过queue.size()的方法来获取阻塞队列中的任务数。
运行原理
刚开始都是在创建新的线程,达到核心线程数量41个后,新的任务进来后不再创建新的线程,而是将任务加入工作队列,任务队列到达上线10个后,新的任务又会创建新的普通线程,直到达到线程池最大的线程数量41个,后面的任务则根据配置的饱和策略来处理。我们这里没有具体配置,使用的是默认的配置AbortPolicy:直接抛出异常。
BlockingQueue 阻塞队列
| 队列 | 描述 |
|---|---|
| ArrayBlockingQueue | 是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。 |
| LinkedBlockingQueue | 一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue,静态工厂方法Executors.newFixedThreadPool()使用了这个队列。 |
| SynchronousQueue | 一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个列。 |
| PriorityBlockingQueue | 一个具有优先级的无限阻塞队列。 |
RejectedExecutionHandler 饱和策略
当队列和线程池都满了,说明线程池处于饱和状态,那么必须对新提交的任务采用一种特殊的策略来进行处理。这个策略默认配置是AbortPolicy,表示无法处理新的任务而抛出异常。JAVA提供了4中策略:
| 饱和策略 | 描述 |
|---|---|
| AbortPolicy | 直接抛出异常(不传时,默认) |
| CallerRunsPolicy | 只用调用所在的线程运行任务 |
| DiscardOldestPolicy | 丢弃队列里最近的一个任务,并执行当前任务 |
| DiscardPolicy | 不处理,丢弃掉 |
核心线程数设置
1. CPU密集型任务
对于CPU密集型任务(即计算密集型任务,它们的特点是需要大量的CPU运算):
核心线程数和最大线程数:通常设置为CPU核心数加1,这样可以使CPU的利用率最大化,同时避免由于线程上下文切换带来的额外开销。例如,如果你的机器有8个CPU核心,你可以设置线程池的核心线程数和最大线程数均为9。
2. IO密集型任务
对于IO密集型任务(即这类任务可能会阻塞,并在执行期间等待IO操作,如数据库操作、文件操作或网络通信):
核心线程数和最大线程数:可以设置得更高,因为IO密集型任务并不是一直在进行计算。一个常用的配置是将线程数设置为CPU核心数的两倍加1。但具体数值还需要根据实际IO的等待时间和响应时间来调整。
线程池五种状态
| 状态 | 状态说明 | 状态切换 |
|---|---|---|
| RUNNING | 线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理 | 线程池的初始化状态是RUNNING。线程池被一旦被创建,就处于RUNNING状态,且线程池中的任务数为0 |
| SHUTDOWN | 线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务 | 调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN |
| STOP | 线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务 | 调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN )-> STOP |
| TIDYING | 当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现 | 当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。 当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING |
| TERMINATED | 线程池彻底终止,就变成TERMINATED状态 | 线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED |
向线程池提交任务
以使用两个方法向线程池提交任务,分别为execute()和submit()方法
| 方法 | 描述 |
|---|---|
| execute | 提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功 |
| submit | 提交需要返回值的任务 |
例如:
线程池声明
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(41,82,60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(),new ThreadPoolExecutor.AbortPolicy());
execute方法
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
//线程实现
}
});
submit方法
Future callfuture = threadPoolExecutor.submit(new Callable<Object>(){
@Override
public Object call() throws Exception {
return "执行结束,返回值为1";
}
});
callfuture.get();
Future可以通过get方法获取返回内容,但执行future.get()会阻塞,它会等到所有的线程全部执行结束后获取。
结束线程池
ThreadPoolExecutor提供了两个方法,用于线程池的关闭,分别是shutdown()和shutdownNow(),它们的原理是遍历线
程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程
| 方法 | 描述 |
|---|---|
| shutdown() | 不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务 |
| shutdownNow() | 立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务 只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务 |
shutdown,只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线
程,等待执行任务的线程完成。
线程池种类
通过观察源码,其中四种线程的创建都是创建一个ThreadPoolExecutor。其中ThreadPoolExecutor是ExecutorService接口的实现类。
定长线程池(FixedThreadPool )
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(10);
- 它是一种固定大小的线程池;
- corePoolSize和maximunPoolSize都为用户设定的线程数量nThreads;
- keepAliveTime为0,意味着一旦有多余的空闲线程,就会被立即停止掉;但这里keepAliveTime无效;
- 阻塞队列采用了LinkedBlockingQueue,它是一个无界队列;
- 由于阻塞队列是一个无界队列,因此永远不可能拒绝任务;
- 由于采用了无界队列,实际线程数量将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。
可缓存线程池(CachedThreadPool)
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
- 它是一个可以无限扩大的线程池;
- 它比较适合处理执行时间比较小的任务;
- corePoolSize为0,maximumPoolSize为无限大,意味着线程数量可以无限大;
- keepAliveTime为60S,意味着线程空闲时间超过60S就会被杀死;
- 采用SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。
单一线程池(SingleThreadExecutor)
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
- 它只会创建一条工作线程处理任务;
- 采用的阻塞队列为LinkedBlockingQueue;
可调度的线程池(ScheduledThreadPool)
它用来处理延时任务或定时任务
Executors.newScheduledThreadPool(10);
它接收SchduledFutureTask类型的任务,有两种提交任务的方式:
scheduledAtFixedRate
scheduledExecutor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("执行内容");
}
},1,5,TimeUnit.SECONDS);
scheduledWithFixedDelay
scheduledExecutor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println("执行内容");
}
},1,5,TimeUnit.SECONDS);
- scheduleAtFixedRate 方法的执行是按照固定时间间隔进行执行的,我们可以理解为等差数列的执行方式,假设 n 为初始延迟,即 n 执行,n + period 执行,然后 n + 2 * period 执行,依次往后。但是必须等待上个任务执行完毕,下个任务才能开始执行,即实际上是这么执行的,假设 run 是任务执行时间,则 n 执行,然后 n + max(period,run) 依次执行。
- scheduleWithFixedDelay 方法的执行是上个任务执行完,然后过 delay 时间后执行下个任务,假设 n 为初始延迟,即 n 执行,n + run + delay 执行,然后 n + 2 * (run + delay) 执行。
- 两种方法都是遇到异常后,后序都无法再执行。
SchduledFutureTask接收的参数:
- time:任务开始的时间
- sequenceNumber:任务的序号
- period:任务执行的时间间隔
它采用DelayQueue存储等待的任务
- DelayQueue内部封装了一个PriorityQueue,它会根据time的先后时间排序,若time相同则根据sequenceNumber排序;
- DelayQueue也是一个无界队列;
工作线程的执行过程:
- 工作线程会从DelayQueue取已经到期的任务去执行;
- 执行结束后重新设置任务的到期时间,再次放回DelayQueue















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









