







1、主机规划
| 主机名 | IP | 部署软件 | 备注 |
| server01 | 192.168.1.4 | ELK | ELK软件版本要一致 |
| server02 | 192.168.1.5 | http+filebeat | 使用filebeat收集日志 |
| server03 | 192.168.1.6 | kafka+zookeeper | 这里部署单节点 |
2、环境配置
时间同步
ntpdate ntp1.aliyun.com #在台主机执行![]()
3、安装jdk1.8
由于ELK的3和软件都需要JDK支持,所以只要安装Elasticsearch+Logstash+Kibaba的服务器都要装JDK,jdk版本至少1.8
3.1、解压jdk
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/3.2、配置JDK环境变量
vim /etc/profile #在文件最后加入下面的内容JAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
source /etc/profile #使用环境变量
3.3、查看java环境
java -version

3.4、解压软件包
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz -C /usr/local/
3.5、创建用户
源码包安装Elasticsearch不能用root启动,需要新建一个用户来启动Elasticsearch这里创建普通elk
useradd elk
3.6、给文件授权
chown -R elk:elk /usr/local/elasticsearch-7.3.0/3.7、设置内核参数
修改系统参数,确保系统有足够资源启动ES
vim /etc/sysctl.conf在最后增加
vm.max_map_count=655360
sysctl -p #使配置文件生效
vm.max_map_count = 655360
注:
vm.max_map_count这个参数就是允许一个进程在VMA(Virtual Memory Areas,虚拟内存区域)拥有最大数量,虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量,当达到vm.max_map_count了就是返回out of memory errors。
这个数据通过下面的命令可以查看: cat /proc/sys/vm/max_map_count
可以通过命令cat /proc/{pids}/maps |wc -l来监控,当前进程使用到的vm映射数量
3.8、设置资源参数
vim /ect/security/limits.conf #在文件最后增加以下行# 表示任何一个用户可以打开的最大的文件数量
* soft nofile 65536
* hard nofile 65536
# 表示任何一个用户可以打开的最大的进程数
* soft nproc 65536
* hard nproc 65536
3.9、切换到elk用户
使用普通用户去启动elasticsearch,这是软件强制规定的
su -elk
cd /usr/local/elasticsearch-7.3.0/
ls

3.10、elasticsearch 主配置文件
vim config/elasticsearch.yml
#如果是集群修改如下配置,集群是通过cluster.name自动在9300端口上寻找节点信息的。
cluster.name: my-application #集群名称,同一个集群的标识
node.name: node-1 #节点名称
path.data: /data/elk/data #数据存储位置
path.logs: /data/elk/logs #日志文件的路径
#如果系统为centos6.x操作系统,不支持SecComp,而elasticsearch默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
# 解决办法:在elasticsearch.yml中添加配置项:bootstrap.system_call_filter为false
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0 # ES的监听地址,这样别的机器也可以访问
http.port: 9200 #监听端口,ES节点和外部通讯使用,默认的端口号是9200。
cluster.initial_master_nodes: ["node-1"] #设置一系列符合主节点条件的节点的主机名或IP地址来引导启动
退出普通用户exit
创建数据和日志目录
mkdir -pv /data/elk/{data,logs}
chown -R elk:elk /data/elk/
su - elk
cd /usr/local/elasticsearch-7.3.0/
vim config/jvm.options默认是1g,官方建议对jvm进行一些修改,不然很容易出现OOM,参考官网改参数配置,最好不要超过内存的50%
-Xms1g
-Xmx1g
3.10、启动elasticsearch
在elk普通用户中执行
./bin/elasticsearch
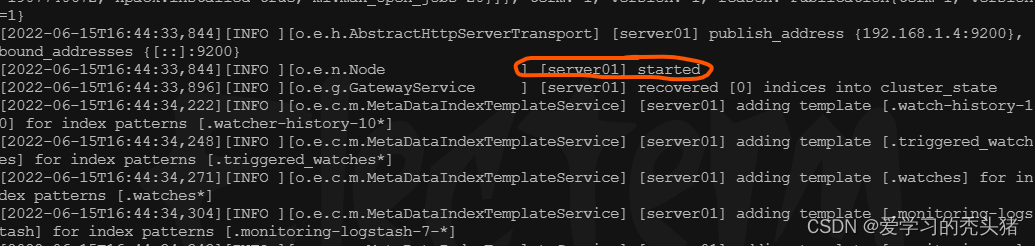
后台启动
nohup /usr/local/elasticsearch-7.3.0/bin/elasticsearch &
或
/usr/local/elasticsearch-7.3.0/bin/elasticsearch -d查看端口
确定elasticsearch的9200端口已经监听,说明已经运行
netstat -anplt | grep java
或
netstat -anplt | grep 9200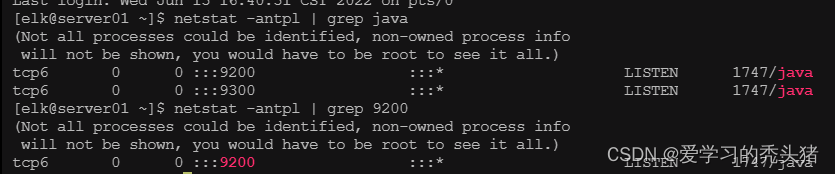
查看进程
jps -m

注:
单个节点可以作为一个运行中的Elasticsearch的实例。而一个集群是一组拥有相同cluster.name的节点,(单独的节点也可以组成一个集群)可以在elasticsearch.yml配置文件中修改cluster.name,该节点启动时加载(需要重启服务后才会生效)。
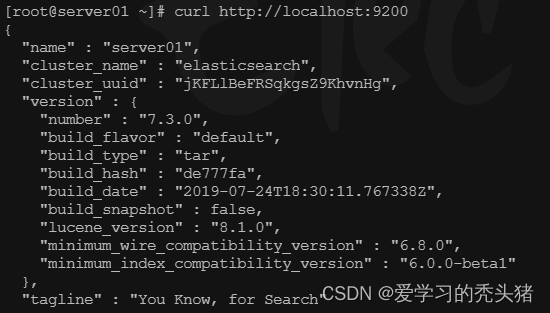
3.11、测试elasticsearch
curl http://localhost:9200
加入开机启动
vim /etc/init.d/elasticsearch
#!/bin/sh
#chkconfig: 2345 80 05
#description: elasticsearch
export JAVA_BIN=/usr/local/jdk1.8.0_171/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
case "$1" in
start)
su elk<<!
cd /usr/local/elasticsearch-7.3.0/
./bin/elasticsearch -d
!
echo "elasticsearch startup"
;;
stop)
es_pid=`jps | grep Elasticsearch | awk '{print $1}'`
kill -9 $es_pid
echo "elasticsearch stopped"
;;
restart)
es_pid=`jps | grep Elasticsearch | awk '{print $1}'`
kill -9 $es_pid
echo "elasticsearch stopped"
su elk<<!
cd /usr/local/elasticsearch-7.3.0/
./bin/elasticsearch -d
!
echo "elasticsearch startup"
;;
*)
echo "start|stop|restart"
;;
esac
exit $?
su elk<<! 切换为elk用户执行下面的命令,<<! 相当于<<EOF
注意:
以上脚本的用户为elk,如果你的用户不是,则需要替换
以上脚本的JAVA_BIN以及elasticsearch_home如果不同请替换
chmod +x /etc/init.d/elasticsearch #给脚本增加权限
chkconfig --add /etc/init.d/elasticearch
测试脚本
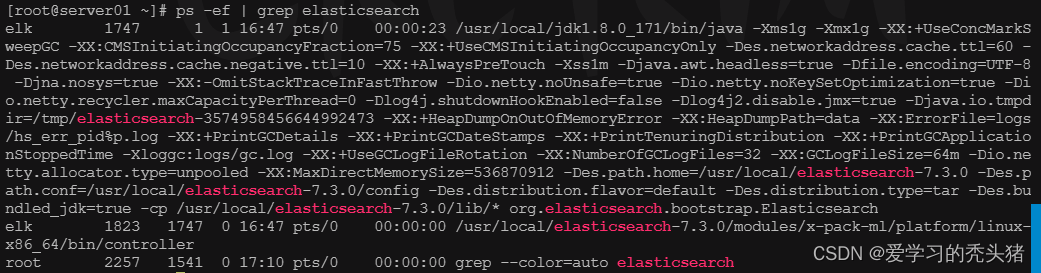
systemctl restart elasticesarch
pa -aux | grep elasticsearch
4安装logstash
下载并安装Logstash,安装logstash只需将它解压的对应目录即可,例如:/usr/local下:
tar zxf logstash-7.3.0.tar.gz -C/usr/local/
Logstash管道有两个必需的元素,input和output,以及一个可选的元素,filter。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
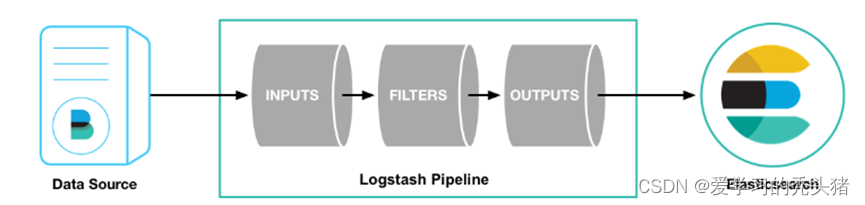
首先,我们通过运行最基本的Logstash管道来测试您的Logstash安装。
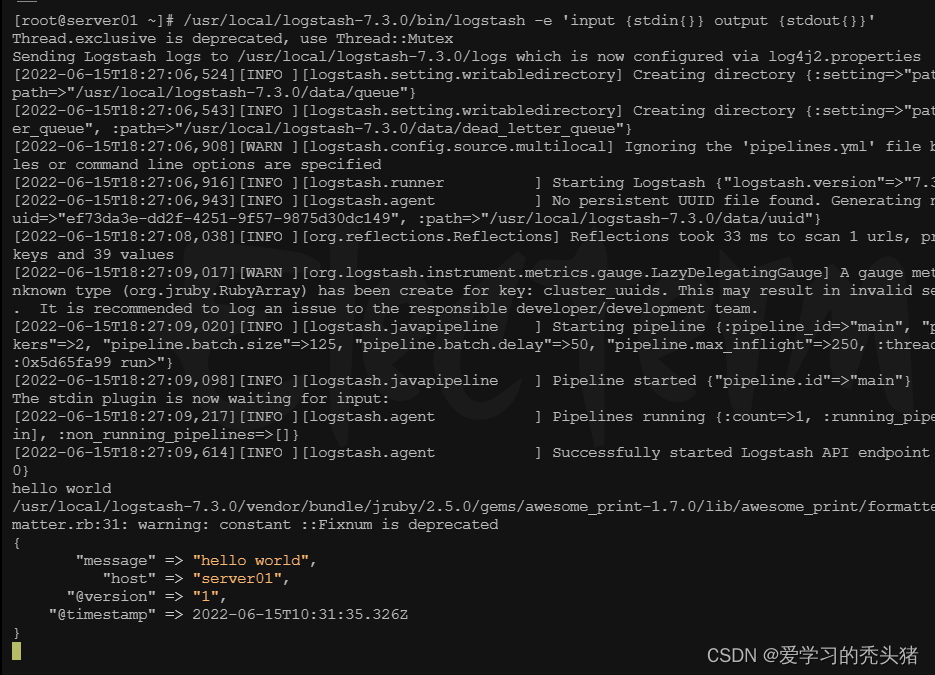
注:stdin 标准输入,stdout标准输出。
我们可以看到,我们输入什么内容,logstash按照某种格式输出,其中-e参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。使用CTRL-C命令可以退出之前运行的Logstash。
4.1、生成配置文件
使用-e参数在命令中指定配置是很常见的方式,不过如果需要配置更多的则需要很长的内容,这种情况下我们首先创建一个简单的配置文件,并且指定logstash使用整个配置文件。
如在logstash安装目录下创建配置文件logstash.conf,文件内容如下
input { #input plugin让logstash可以读取特定的事件源。
file { #file 从文件读取数据
path => "/var/log/messages" #收集来源,这里从输入的文件路径收集系统日志。可以用/var/log/*.log,/var/log/**/*.log,如果是/var/log则是/var/log/*.log。
type => "messages_log" #通用选项. 用于激活过滤器。
start_position => "end" #start_position 选择logstash开始读取文件的位置,begining或者end。默认是end,end从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
}
}
filter { #过滤器插件,对事件执行中间处理、过滤,为空不过滤。
}
output { #输出插件,将事件发送到特定目标。
elasticsearch { #将事件发送到es,在es中存储日志
hosts => ["192.168.1.4:9200"]
index => "var-massages-%{+yyyy.MM.dd}" #index表示事件写入的索引。可以按照日志来创建索引,以便于删旧数据和按时间来搜索日志
}
stdout { codec => rubydebug } # stdout标准输出,输出到当前终端显示屏
}
注:上述文件复制时必须去除多余空格,保持yml文件规范。这个配置文件只是简单测试logstash收集日志功能。
4.3、做软连接
ln -s /usr/local/logstash-7.3.0/bin/* /usr/local/bin/、
4.4、启动logstash
logstash -f /usr/local/logstash-7.3.0/config/logstash.conf
使用echo命令模拟写入日志,另外打开一个终端,执行下面的命令。
echo "$(date) hello world" >> /var/log/messages
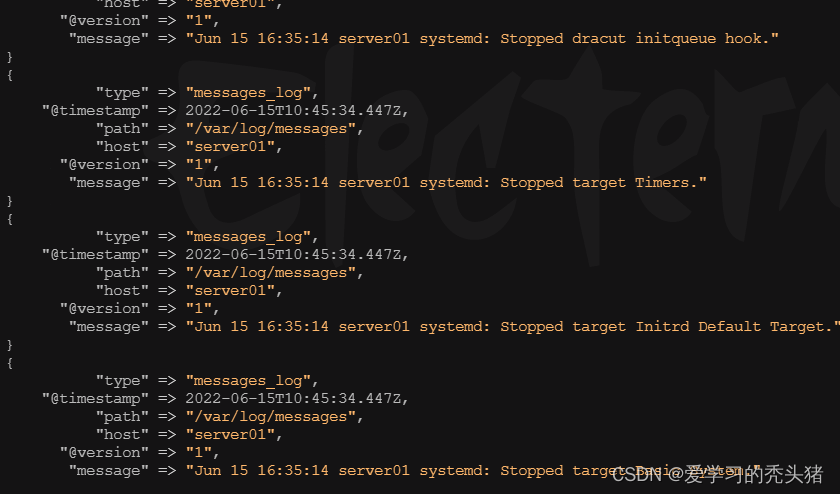
我们可以使用curl命令请求来查看ES是否接受到了
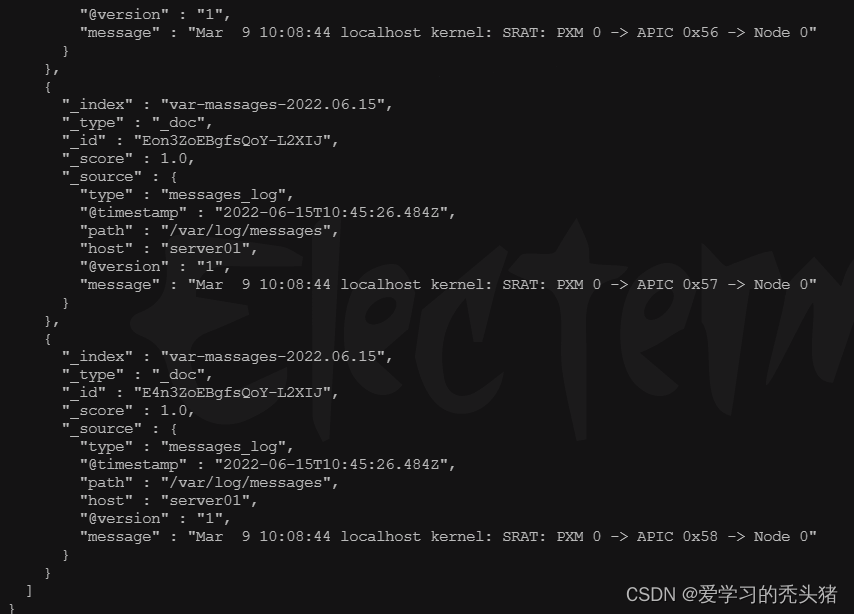
curl http://192.168.1.11:9200/_search?pretty
常用启动参数:
-e:立即执行,使用命令行里的配置参数启动实例。
例如 logstash -e 'input {stdin{}} output {stdout{}}'
-f:指定启动实例的配置文件。
例如logstash -f /usr/local/logstash-7.3.0/config/logstash.conf
-t:测试配置文件的正确性
例如logstash -f /usr/local/logstash-7.3.0/config/logstash.conf -t
开机启动
cho "source /etc/profile" >> /etc/rc.local #让开机加载java环境
echo "nohup logstash -f /usr/local/logstash-7.3.0/config/logstash.conf &" >> /etc/rc.local
chmod +x /etc/rc.local
5、安装kibana
下载kibana后,解压到对应的目录就完成kibana的安装
tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz -C /usr/local/
server.port: 5601
server.host: "192.168.1.11"
elasticsearch.hosts: ["http://192.168.1.11:9200"] #修改elasticsearch地址,多个服务器请用逗号隔开。
启动服务
/usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root
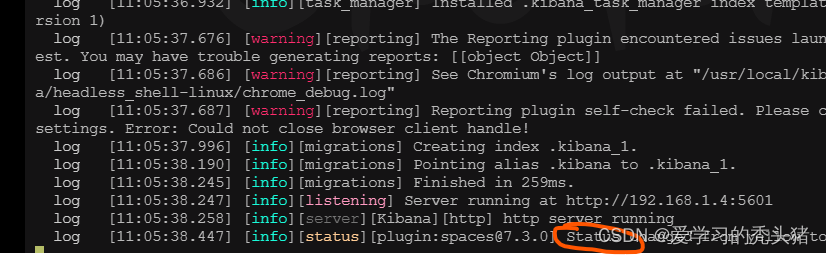
设置后台启动 使用nohup配合
nohup /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root &![]()
增添开机自启
echo "nohup /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root &" >> /etc/rc.local
2、部署nginx+filebeat
在server02上部署的nginx服务器,然后安装filebeat,使用filebeat收集nginx日志文件,把收集到的日志发送给logstash,让logstash过滤日志,吧过滤完的日志保存到elasticsearch,通过kibana展示出来
2.1、安装nginx
2.1.1、安装nginx依赖包
yum install -y gcc gcc-c++ autoconf automake zlib zlib-devel openssl openssl-devel pcre pcre-devel创建用户与组
groupadd www
useradd -g www www -s /sbin/nologin解压包
tar zxf nginx-1.10.3.tar.gz
cd nginx-1.10.3/预编译
./configure --preix=/usr/local/nginx
--with-http_dav_module --with-http_stub_status_module --with-http_addition_module --with-http_sub_module --with-http_flv_module --with-http_mp4_module --with-pcre --with-http_ssl_module --with-http_gzip_static_module --user=www --group=www
make && make install
ln -s /usr/local/nginx/sbin/nginx usr/local/sbin/启动nginx
nginx
查看端口号
netstat -anptl | grep nginx

访问测试页
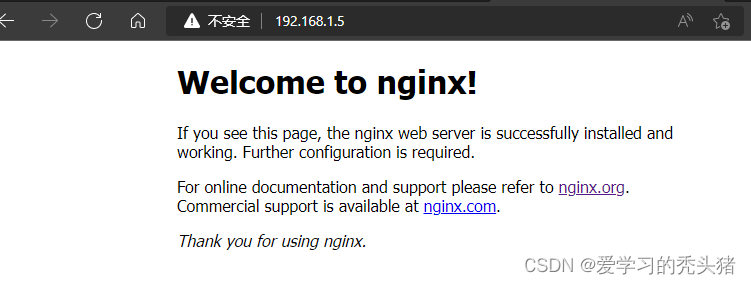
2.2、安装filebeat
解压软件包
tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz -C /usr/local/
改名
mv /usr/local/filebeat-7.3.0-linux-x86_64 /usr/local/filebeat
修改配置文件
vim /usr/local/filebeat/filebeat.yml
- type: log # type: log 读取日志文件的每一行(默认)
enabled: true #enabled: true 该配置是否生效,如果改为false,将不收集该配置的日志
paths: # paths: 要抓取日志的全路径
- /usr/local/nginx/logs/*.log #添加收集httpd服务日志
#- /var/log/* #将该行注释掉
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch: # Elasticsearch这部分全部注释掉
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#----------------------------- Logstash output --------------------------------
output.logstash: #取消注释,把日志放到logstash中
# The Logstash hosts
hosts: ["192.168.1.4:5044"] #取消注释,输出到Logstash的地址和端口
#logging.level: warning #调整日志级别
设置开机自启
echo "cd /usr/local/filebeat/ && ./filebeat -e -c filebeat.yml & " >> /etc/rc.local
2.3、配置logsash
vim /usr/local/logstash-7.3.0/config/http_logstash.conf
input{
beats { #从Elastic beats接收事件
codec => plain{charset => "UTF-8"} #设置编解码器为utf8
port => "5044" #要监听的端口
}
}
output {
stdout { #标准输出,把收集的日志在当前终端显示,方便测试服务连通性
codec => "rubydebug" #编解码器为rubydebug
}
elasticsearch { #把收集的日志发送给elasticsearch
hosts => [ "192.168.1.4:9200" ] # elasticsearch的服务器地址
index => "nginx-logs-%{+YYYY.MM.dd}" #创建索引
}
}
启动logstash
logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf
如果报错:已经存在一个实例了退出l

解决方法:
杀死上一个logstash进程,因为我们之前已经启用了一个logstash,所以杀死之前的进程,再启动logstash。或者使用选项--path.data=/dir为要启动的logstash实例指定一个路径。

这里可以看到 filebeat发过来的消息,如果没有新信息,可以去刷新nginx网页
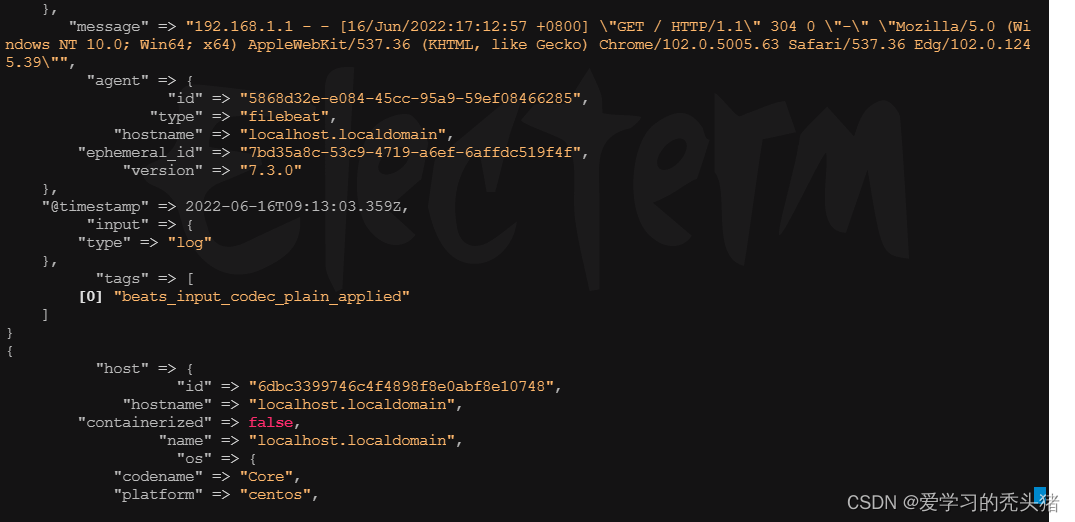 2.4、kibana配置
2.4、kibana配置
http://192.168.1.4:5601
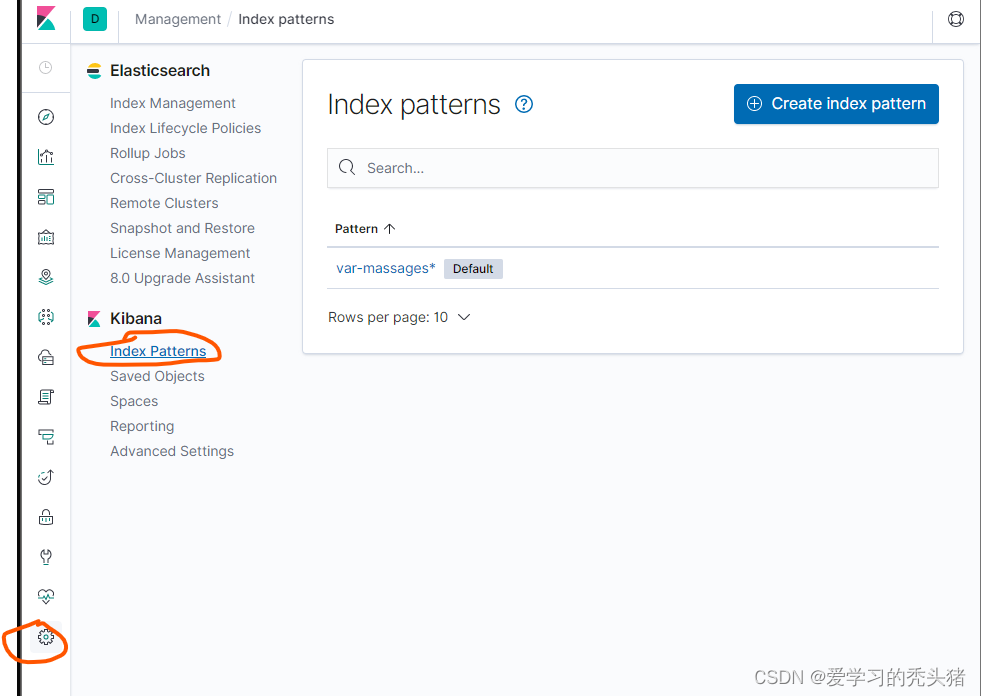

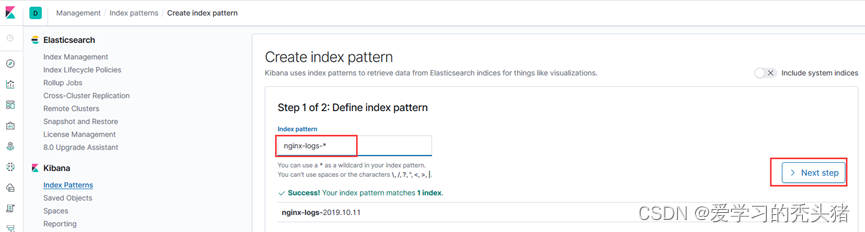

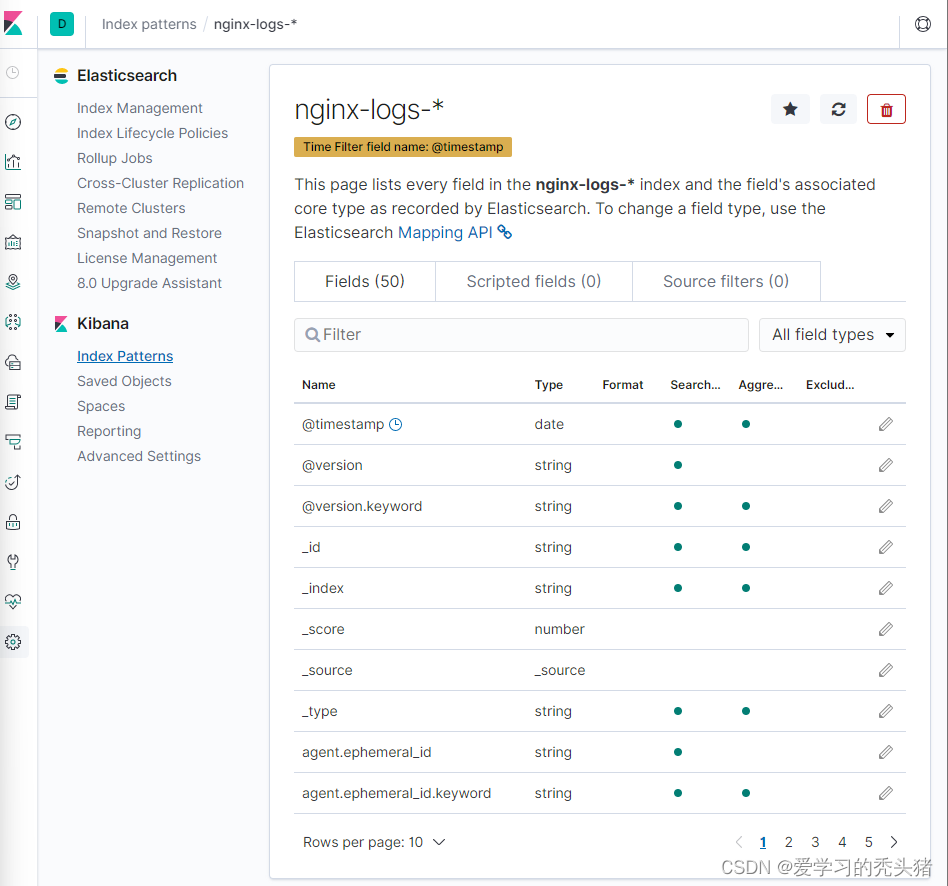
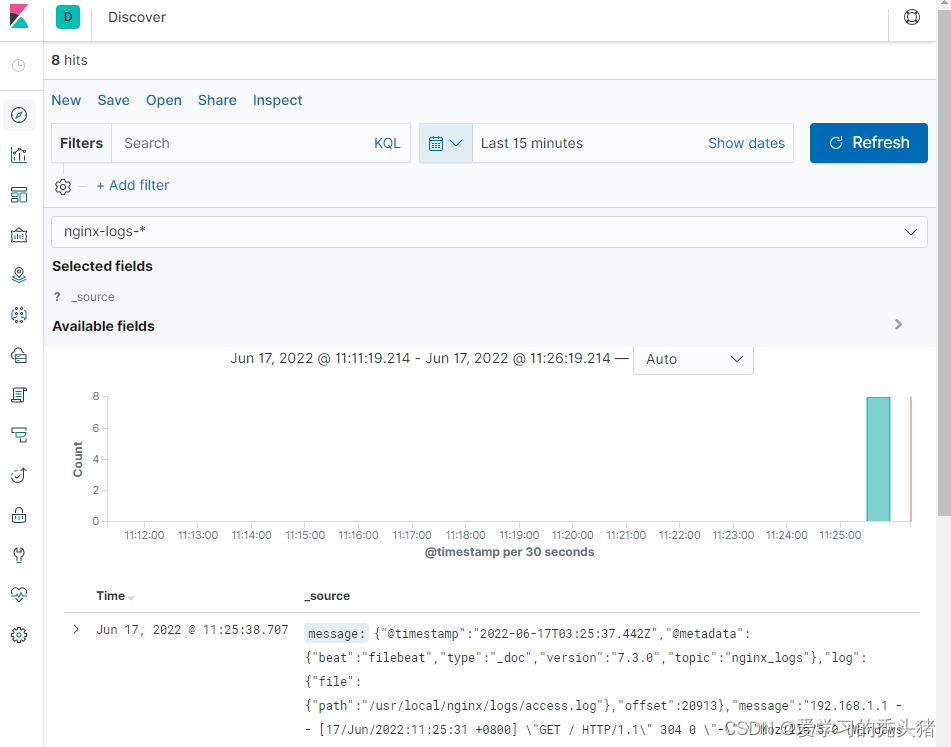
查看日志
打开新建的检索去查看收集到的日志,可以通过刚才增加的时间过滤器查看你想看的日志
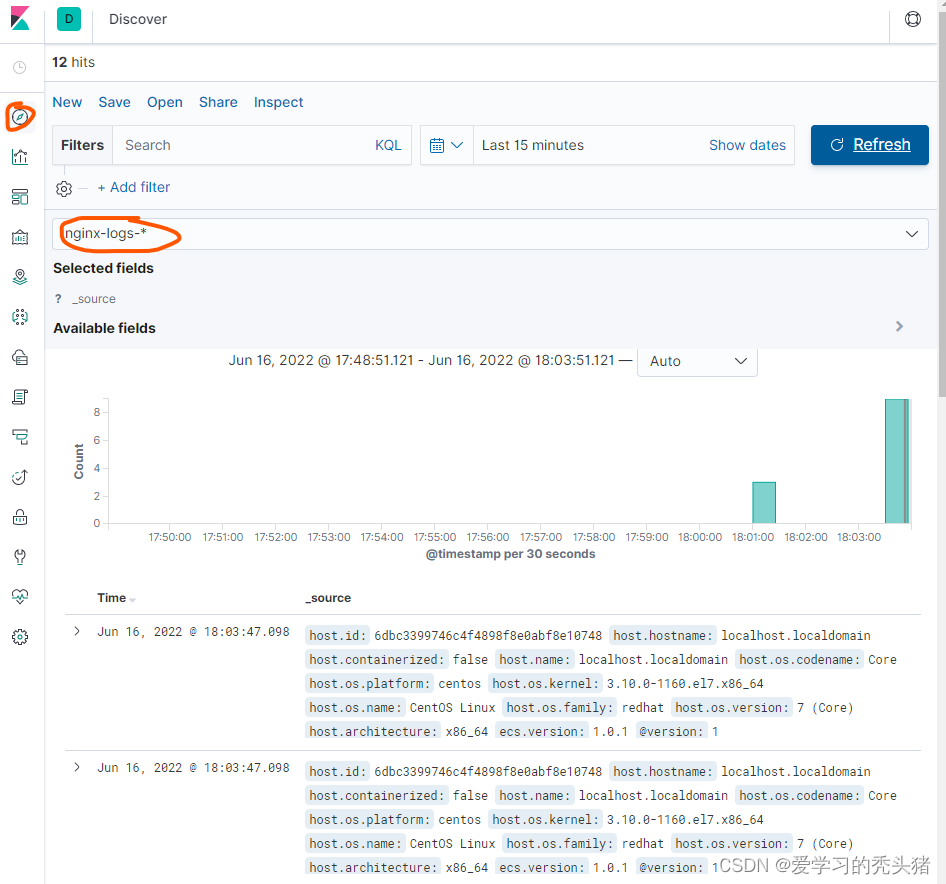
增加过滤器
我们可以在搜到的日志添加过滤器,过滤出我们想要的内容,比如,我想看下nginx的错误日志,那么添加一个log.file.path为/usr/local/nginx/logs/error.log的过滤器,如果我们监控的服务器比较多,我可以查看特定的主机的nginx错误日志
1、增加类型为log.file.path的过滤器


3、部署kfaka
为了防止搜集的志信息太多或者是服务器down机导致的信息丢失,我们这里引入kafka消息队列服务器,我们这里搭建单节点的kafka,生产环境中应该使用集群方式部署。部署过程参考kafka文档
3.1、部署jdk
在1.3主机上部署jdk
解压jdk
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/
3.2、配置JDK环境变量
vim /etc/profile #在文件最后加入一下行
JAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
source /etc/profile #使环境变量生效
查看java环境
java -version

3.3、安装zookeeper
配置hosts文件
vim /etc/hosts
192.168.1.7 server03 #在最后一行增加
解压zookeeper
tar -zxf apache-zookeeper-3.5.5-bin.tar.gz -C /usr/local/
创建快照日志文件存放目录
mkdir -p /data/zk/data
创建事务日志存放日志
mkdir -p /data/zk/datalog
3.4、生成配置文件
cd /usr/local/apache-zookeeper-3.5.5-bin/conf/
cp zoo_sample.cfg zoo.cfg #复制一份zoo_sample.cfg文件并命名为zoo.cfg
3.5、修改主配置文件zoo.cfg
vim zoo.cfg
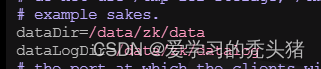
dataDir=/data/zk/data #修改这一行为我们创建的目录
dataLogDir=/data/zk/datalog #添加这一行
3.6、配置环境变量
这里必须是修改配置文件添加path环境变量,不然启动报错
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.5-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
source /etc/profile #配置文件生效
启动zookeeper
zkserver.sh start

验证

增加开机自启
在/lib/systemd/system/文件夹下创建一个启动脚本zookeeper.service
vim /lib/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper service
After=network.target
[Service]
Type=forking
Environment="JAVA_HOME=/usr/local/jdk1.8.0_171"
User=root
Group=root
ExecStart=/usr/local/apache-zookeeper-3.5.5-bin/bin/zkServer.sh start
ExecStop=/usr/local/apache-zookeeper-3.5.5-bin/bin/zkServer.sh stop
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable zookeeper
测试
jps
kill 12463

systemctl start zookeeper

3.7、kafka单节点broker部署
解压
tar -zxvf kafka_2.12-2.2.0.tgz -C /usr/local/
修改配置文件
vim /usr/local/kafka_2.12-2.2.0/config/server.properties
# broker的全局唯一编号,不能重复
broker.id=0
# 监听
listeners=PLAINTEXT://:9092 #开启此项
# 日志目录
log.dirs=/data/kafka/log #修改日志目录
# 配置zookeeper的连接(如果不是本机,需要该为ip或主机名)
zookeeper.connect=localhost:2181
创建日志目录
mkdir -p /data/kafka/log #在文件后面加入以下几行
export KAFKA_HOME=/usr/local/kafka_2.12-2.2.0
export PATH=$KAFKA_HOME/bin:$PATH
source /etc/profile #使配置文件生效
设置开机自启
在/lib/systemd/system/文件夹下创建一个启动脚本kafka.service
vim /lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
Type=simple
Environment="PATH=/usr/local/jdk1.8.0_171/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
User=root
Group=root
ExecStart=/usr/local/kafka_2.12-2.2.0/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.2.0/config/server.properties
ExecStop=/usr/local/kafka_2.12-2.2.0/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable kafka

3.8、配置filebeat
修改配置文件
我们这里修改filebeat配置文件,把filebeat收集到的nginx日志保存到kafka消息队列中。把output.elasticsearch和output.logstash都给注释掉,添加kafka项
vim /usr/local/filebeat/filebeat.yml
- type: log
enabled: true #开启此配置
paths:
- /usr/local/nginx/logs/*.log #添加收集nginx服务日志
#- /var/log/*.log #注释该行
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch: # Elasticsearch这部分全部注释掉
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#----------------------------- Logstash output --------------------------------
#output.logstash: # logstash这部分全部注释掉
# The Logstash hosts
#hosts: ["192.168.1.11:5044"]
#在Logstash后面添加如下行
#----------------------------- KAFKA output --------------------------------
output.kafka: #把日志发送给kafka
enabled: true #开启kafka模块
hosts: ["192.168.1.13:9092"] #填写kafka服务器地址
topic: nginx_logs #填写kafka的topic(主题),自定义的
#logging.level: warning #调整日志级别
把output.elasticsearch和output.logstash都给注释掉,然后在output.logstash结尾添加KAFKA output,把日志数据发送给kafka。需要注意的是kafka中如果不存在这个topic,则会自动创建。如果有多个kafka服务器,可用逗号分隔。
修改hosts文件
vim /etc/hosts
192.168.1.5 server02
192.168.1.7 server03
重启filebeat
ps -ef | grep filebeat | grep -v "grep"
使用kill杀掉进程然后
cd /usr/local/filebeat/ && nohup ./filebeat -e -c filebeat.yml & #重新启动filebeat

3.9、 查看kafka上所有的topic信息
在kafka服务器上查看filebeat保存的数据,topice为nginx_log

启动一个消费者获取信息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nginx_logs --from-beginning
启动一个消费者去查看filebeat发送过来的消息,能看到消息说明我们的filebeat的output.kafka配置成功。接下来配置logstash去kafka消费数据。
3.10、配置logstash
配置logstash去kafka拿取数据,进行数据格式化,然后把格式化的数据保存到Elasticsearch,通过kibana展示给用户。kibana是通过Elasticsearch进行日志搜索的。
filebeat中message要么是一段字符串,要么在日志生成的时候拼接成json,然后在filebeat中指定为json。但是大部分系统日志无法去修改日志格式,filebeat则无法通过正则去匹配出对应的field,这时需要结合logstash的grok来过滤。
Logstash filter 的使用:
下面会单独讲
增加hosts解析
vim /etc/hosts

修改logstach配置文件
vim /usr/local/logstash-7.3.0/config/http_logstash.conf
input{
kafka {
codec => plain{charset => "UTF-8"}
bootstrap_servers => "192.168.1.13:9092"
client_id => "httpd_logs" #这里设置client.id和group.id是为了做标识
group_id => "httpd_logs"
consumer_threads => 5 #设置消费kafka数据时开启的线程数,一个partition对应一个消费者消费,设置多了不影响,在kafka中一个进程对应一个线程
auto_offset_reset => "latest" #从最新的偏移量开始消费
decorate_events => true #此属性会将当前topic,offset,group,partition等信息>也带到message中
topics => "nginx_logs"
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.1.11:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}
可以使用相同的group_id 方式运行多个logstash实例。
以跨物理机分布负载。主题中的消息将分发到具有相同的所有Logstash实例group_id
重启logstash
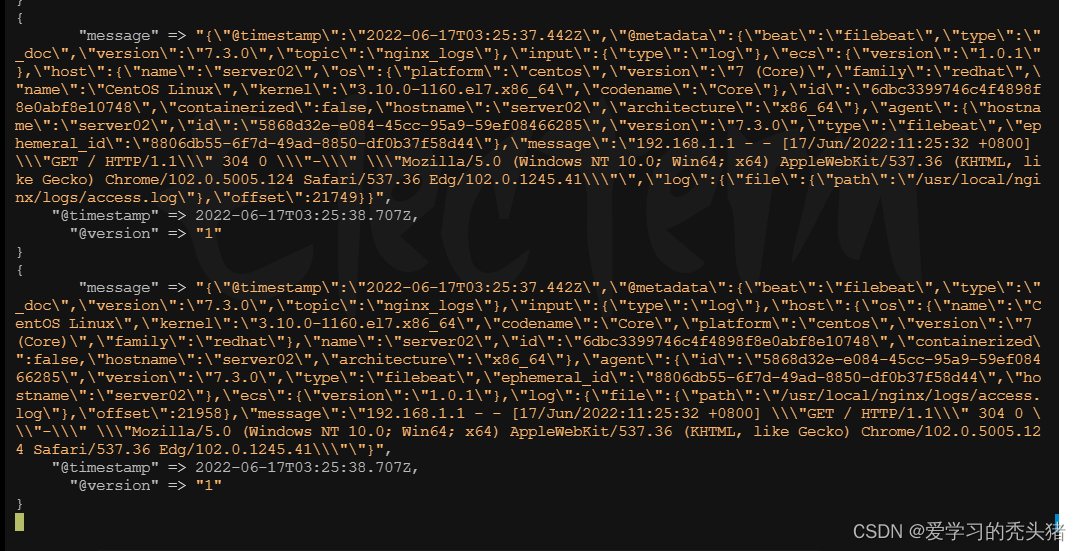
测试















 2327
2327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









