






首先介绍一下什么是Filebeat+Kafka+ELK,ELK+Filebeat就是通过Filebeat收集数据,然后通过logstash发送到es上,然后直接发送的话,如果数据过大,或者遇到其他别的一些问题,在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。所以我们使用Kafka通过异步处理请求,从而缓解系统的压力。Kafka就是消息队列,把Filebeat收集的数据输出到Kafka,然后通过logstash把经过消息队列排序的消息有序的发往es储存,从而避免一个时间系统请求过多带来的系统崩盘。
一、环境准备
node1节点(内存4G):192.168.235.101 部署ES、Kibana、Filebeat
node2节点(内存4G):192.168.235.102 部署ES
apache节点:192.168.235.103 部署logstash、apache
zookeeper集群(部署zookeeper):
server1:192.168.235.104
server2:192.168.235.105
server3:192.168.235.106
关闭防火墙
以下实验建立在以上环境当中,已经全部完成,详情见之前博客。
二、安装kafka
在zookeeper集群中三台机子上均要安装

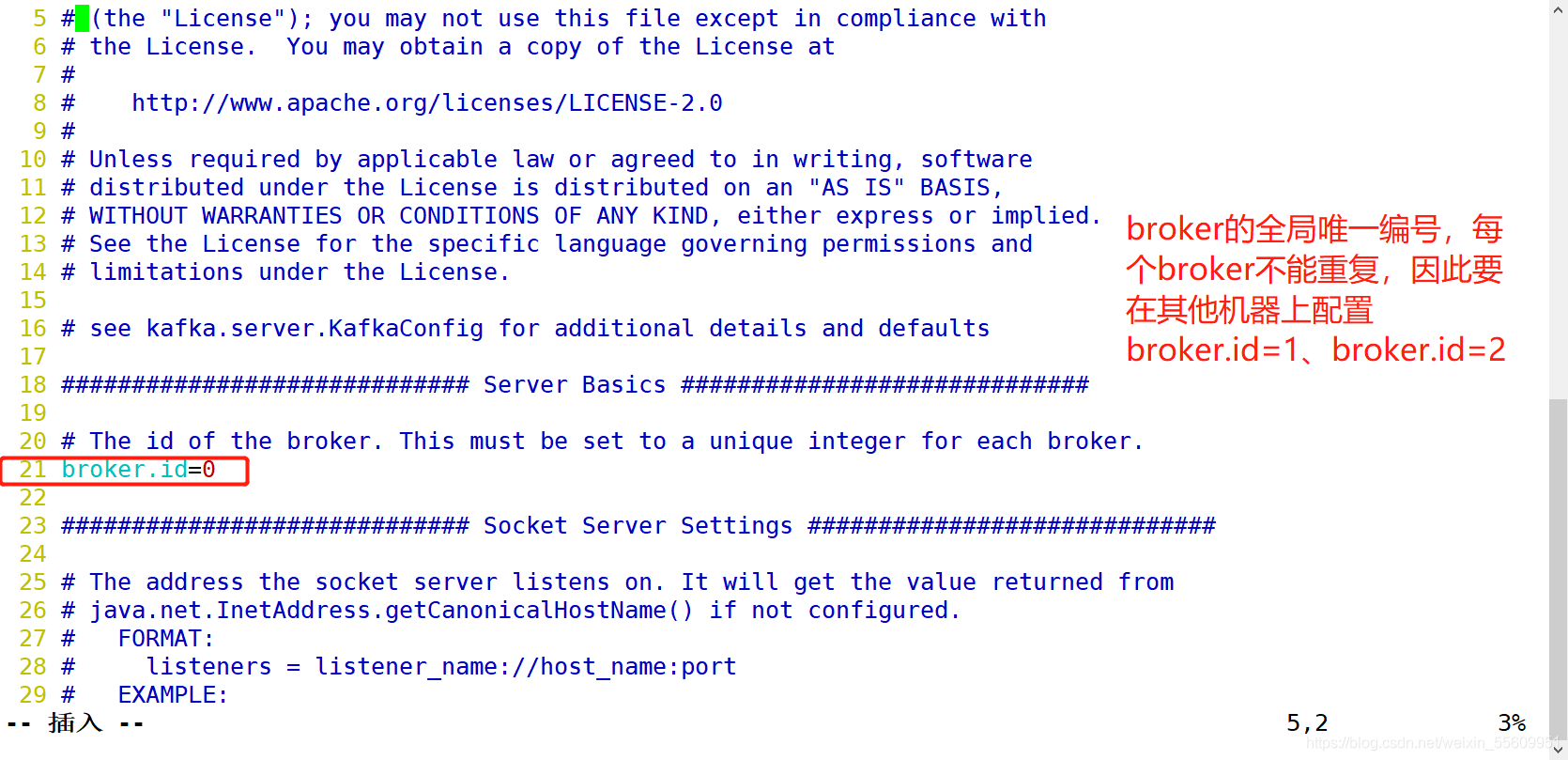
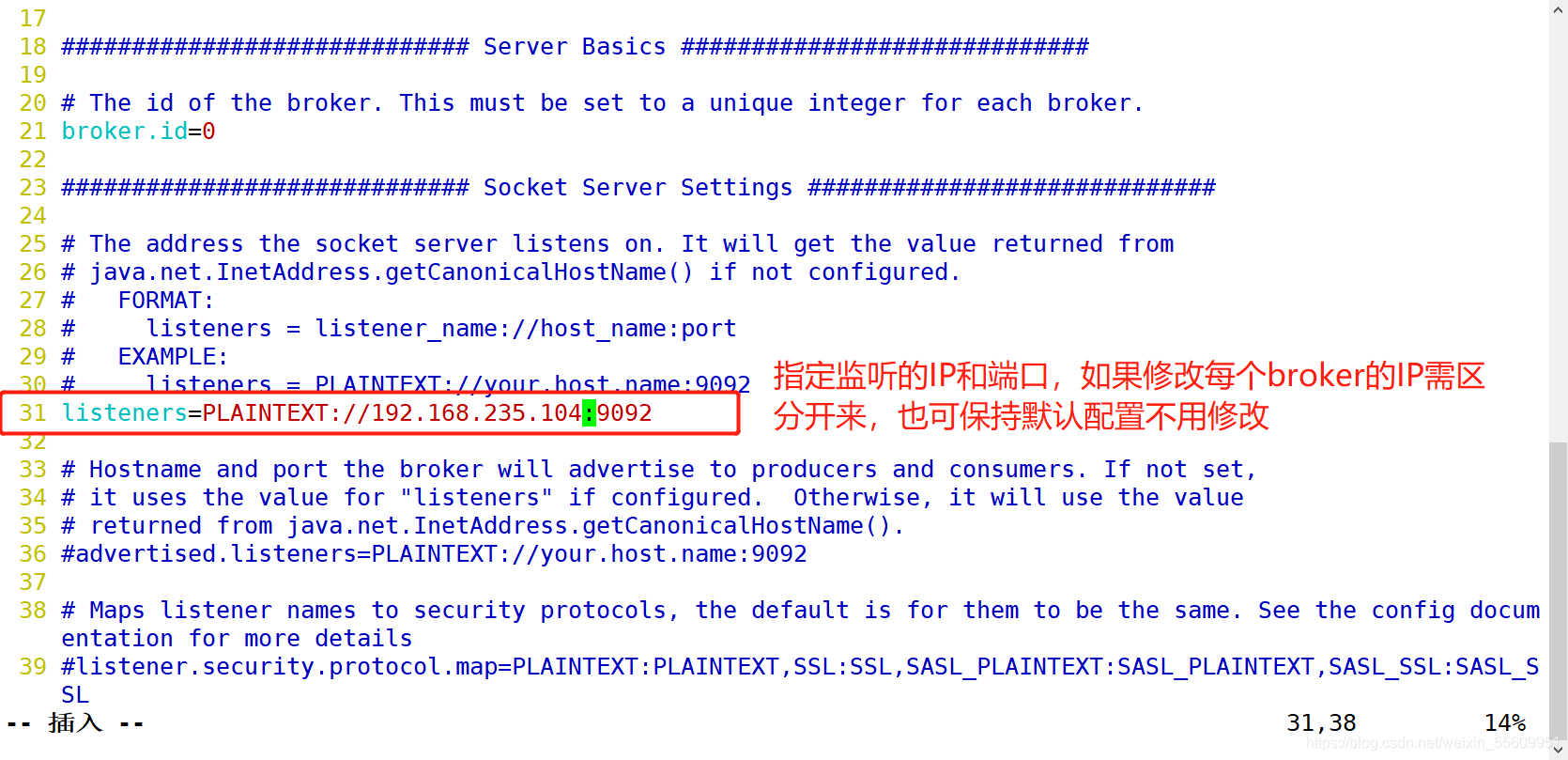
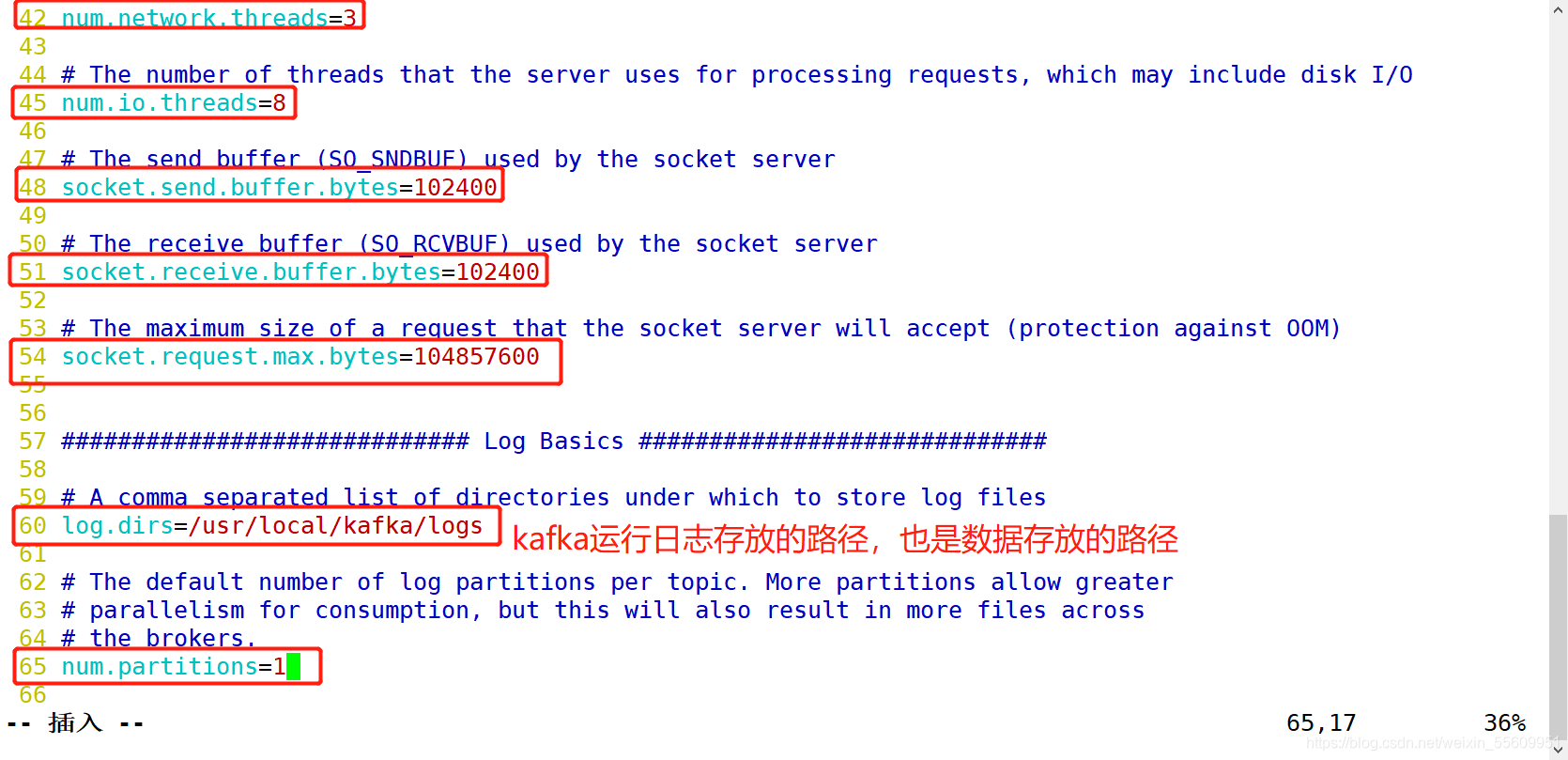
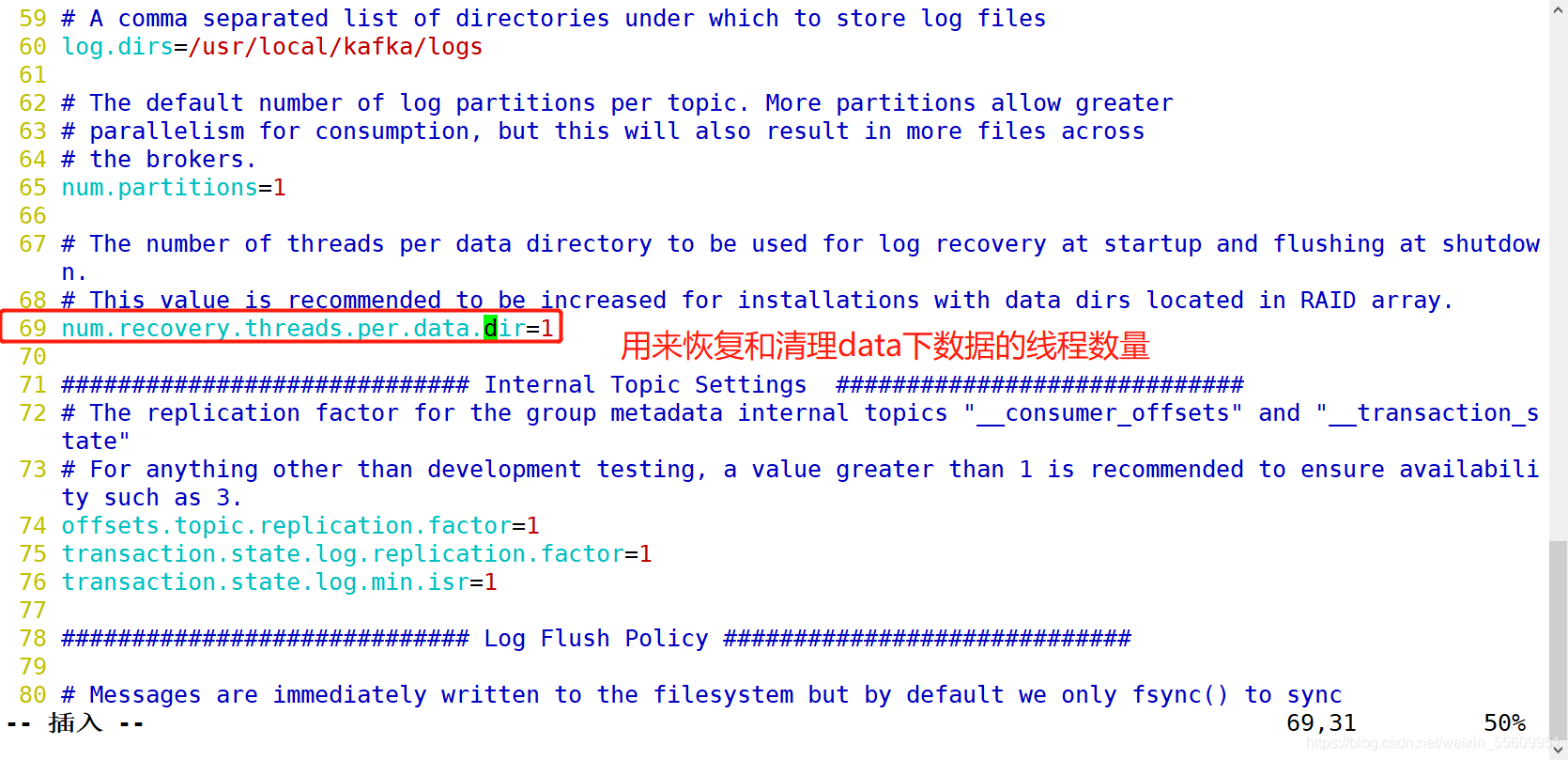
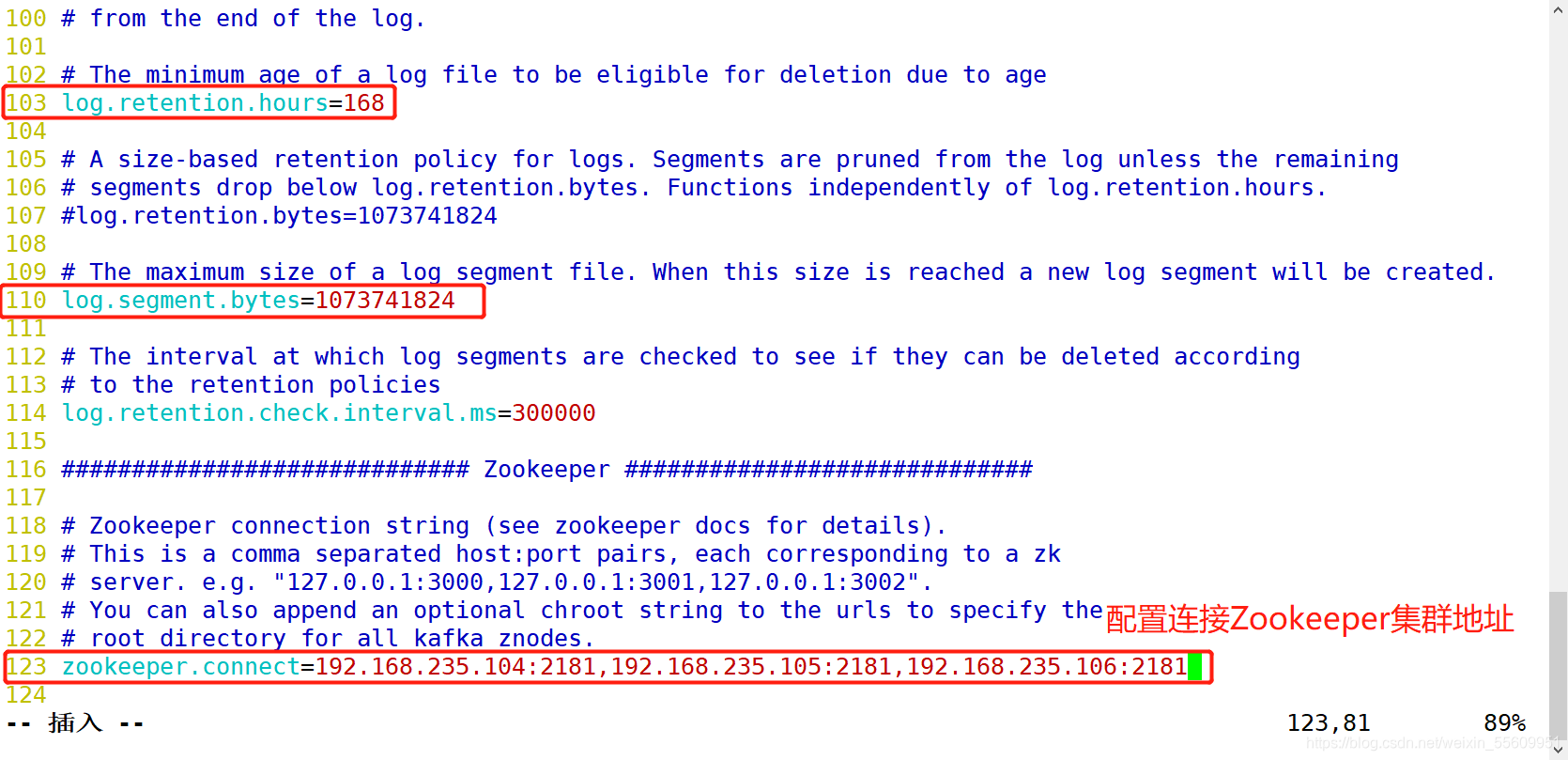
修改配置文件

修改环境变量



配置启动脚本

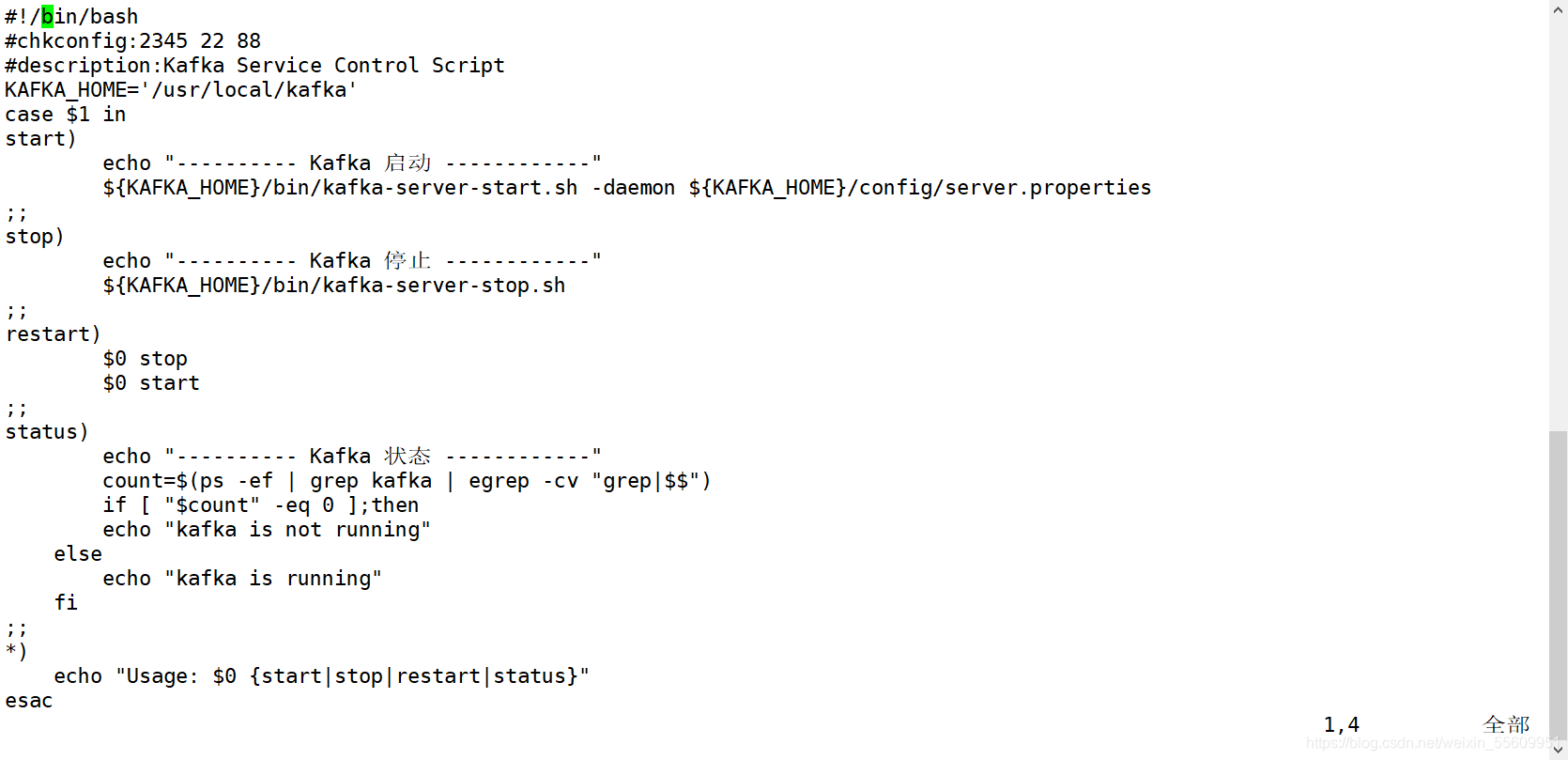
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac

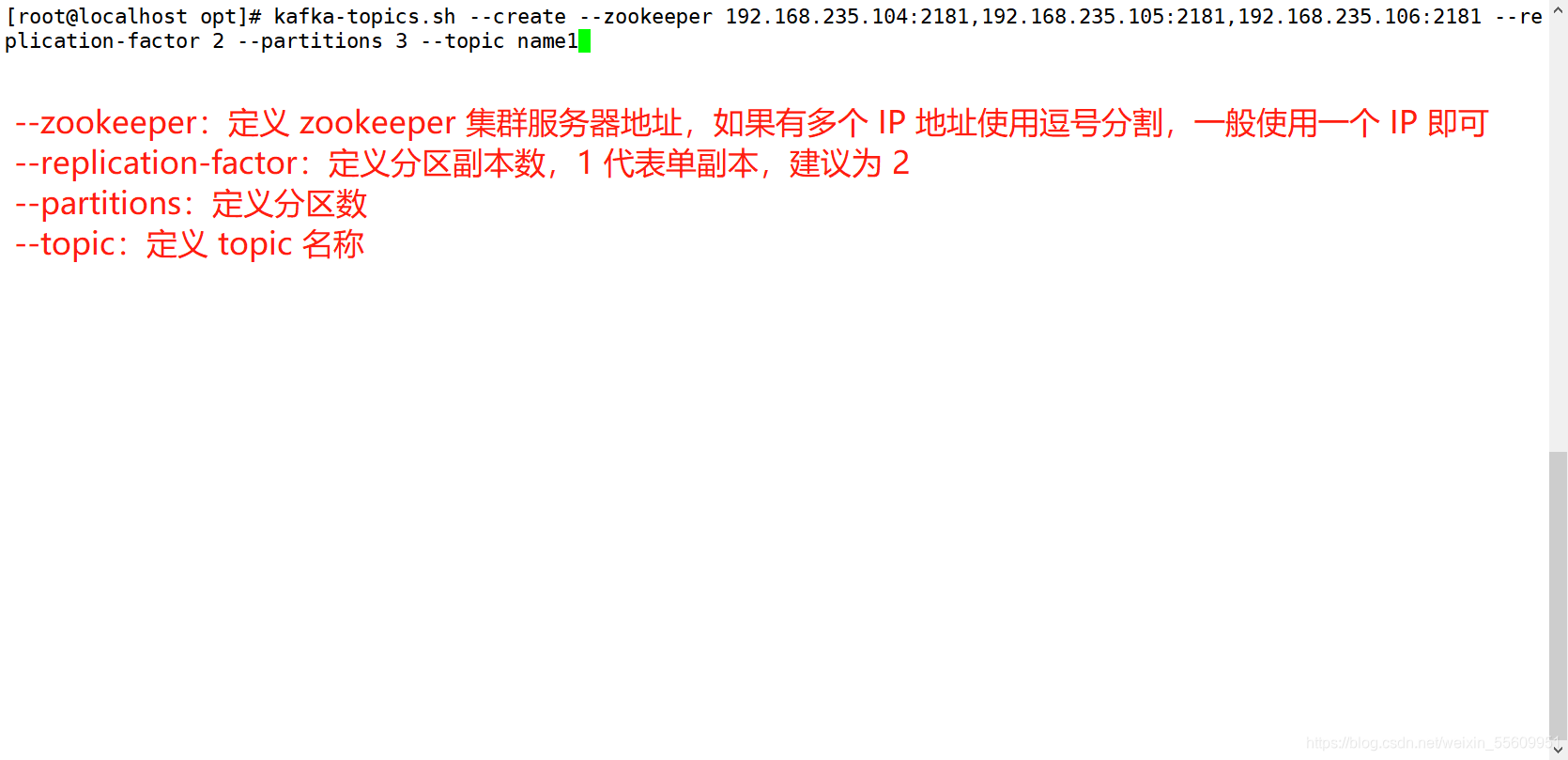
创建topic
查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.235.104:2181,192.168.235.105:2181,192.168.235.106:2181
查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.235.104:2181,192.168.235.105:2181,192.168.235.106:2181
发布消息
kafka-console-producer.sh --broker-list 192.168.235.104:9092,192.168.235.105:9092,192.168.235.106:9092 --topic name1
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.235.104:9092,192.168.235.105:9092,192.168.235.106:9092 --topic name1 --from-beginning
--from-beginning:会把主题中以往所有的数据都读取出来
修改分区数
kafka-topics.sh --zookeeper 192.168.235.104:2181,192.168.235.105:2181,192.168.235.106:2181 --alter --topic name1 --partitions 6
删除 topic
kafka-topics.sh --delete --zookeeper 192.168.235.104:2181,192.168.235.105:2181,192.168.235.106:2181 --topic name1
三、Filebeat+Kafka+ELK
修改Filebeat配置文件

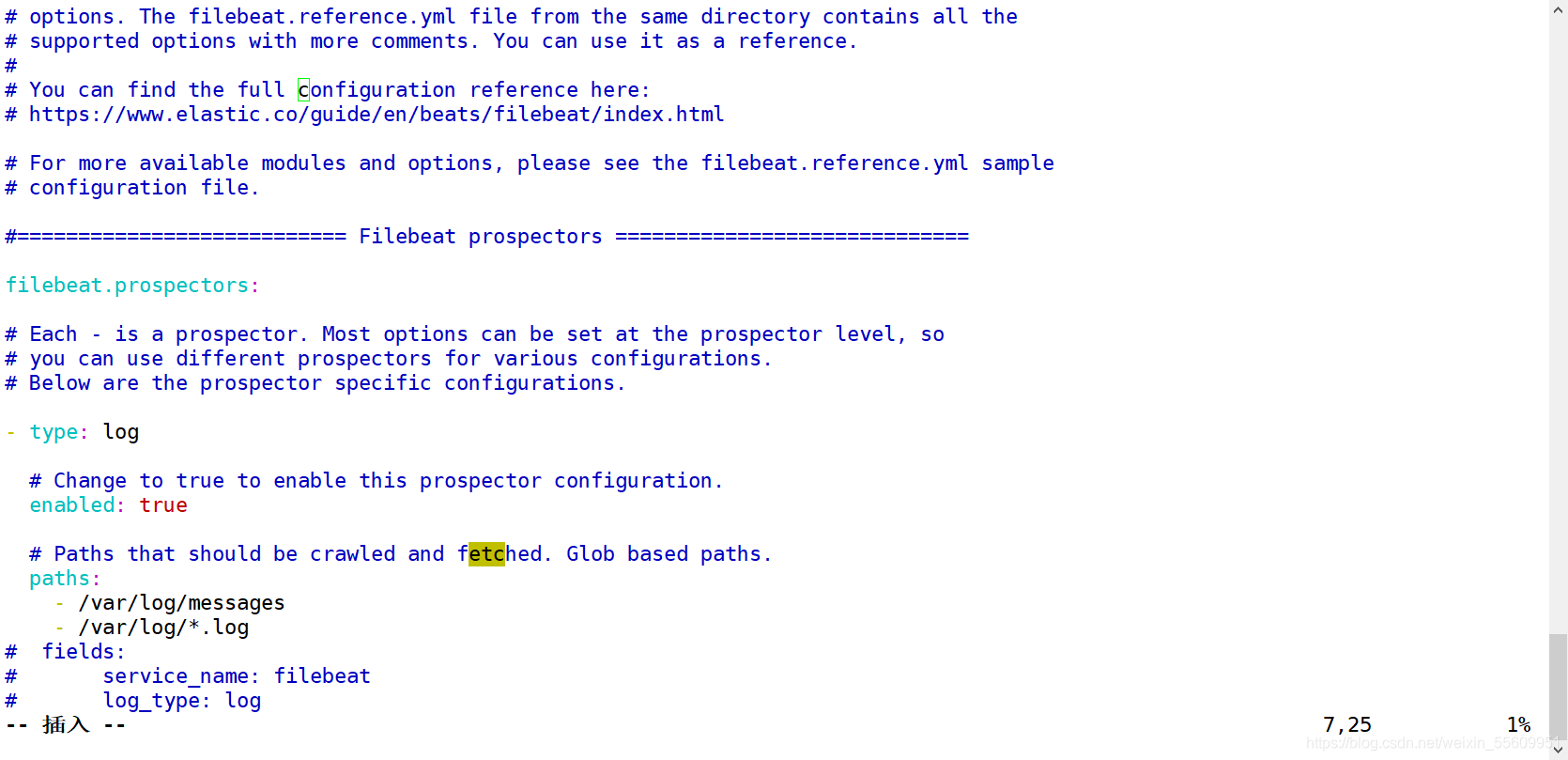
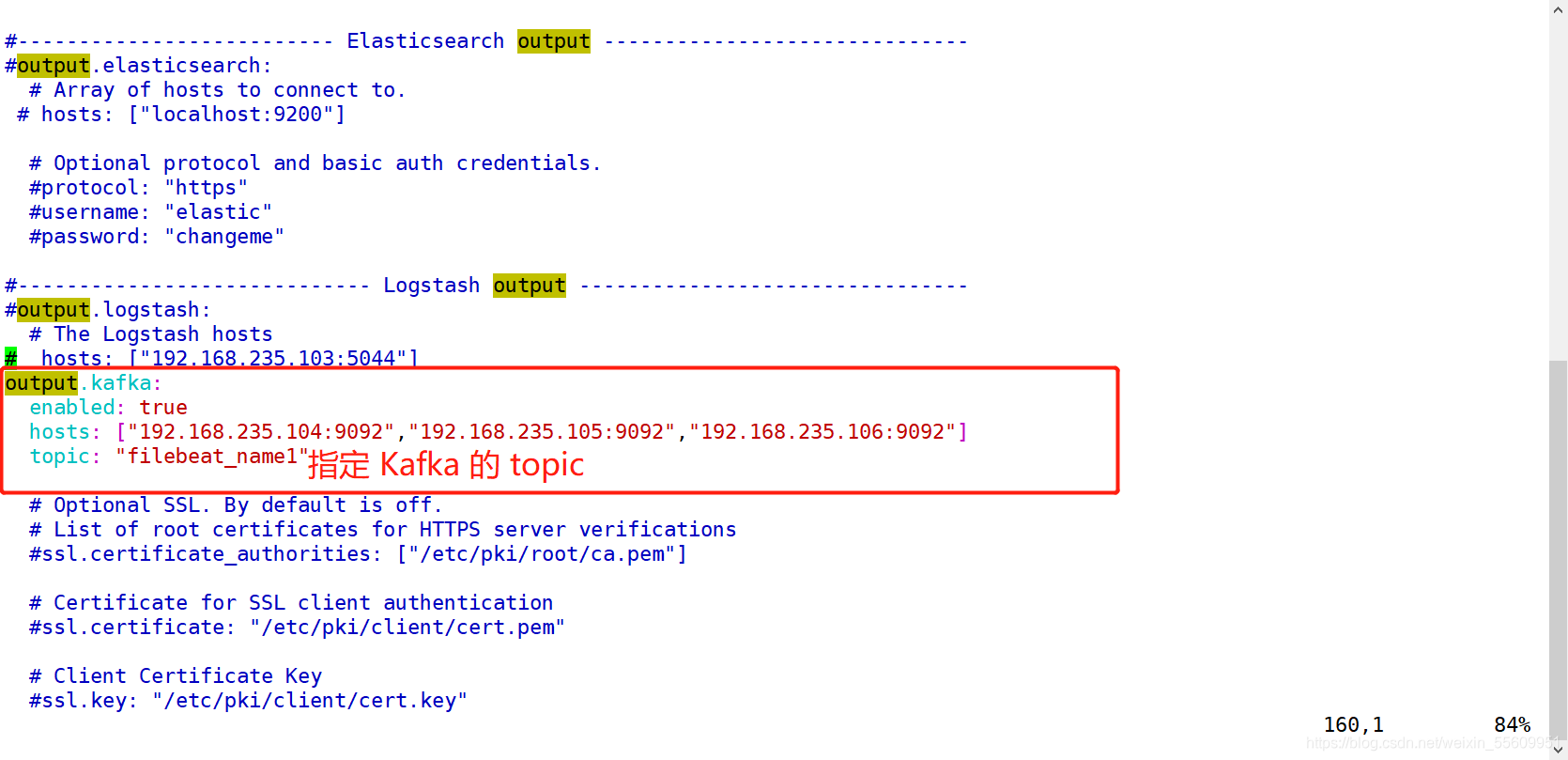
启动 filebeat

在logstash上新建一个配置文件

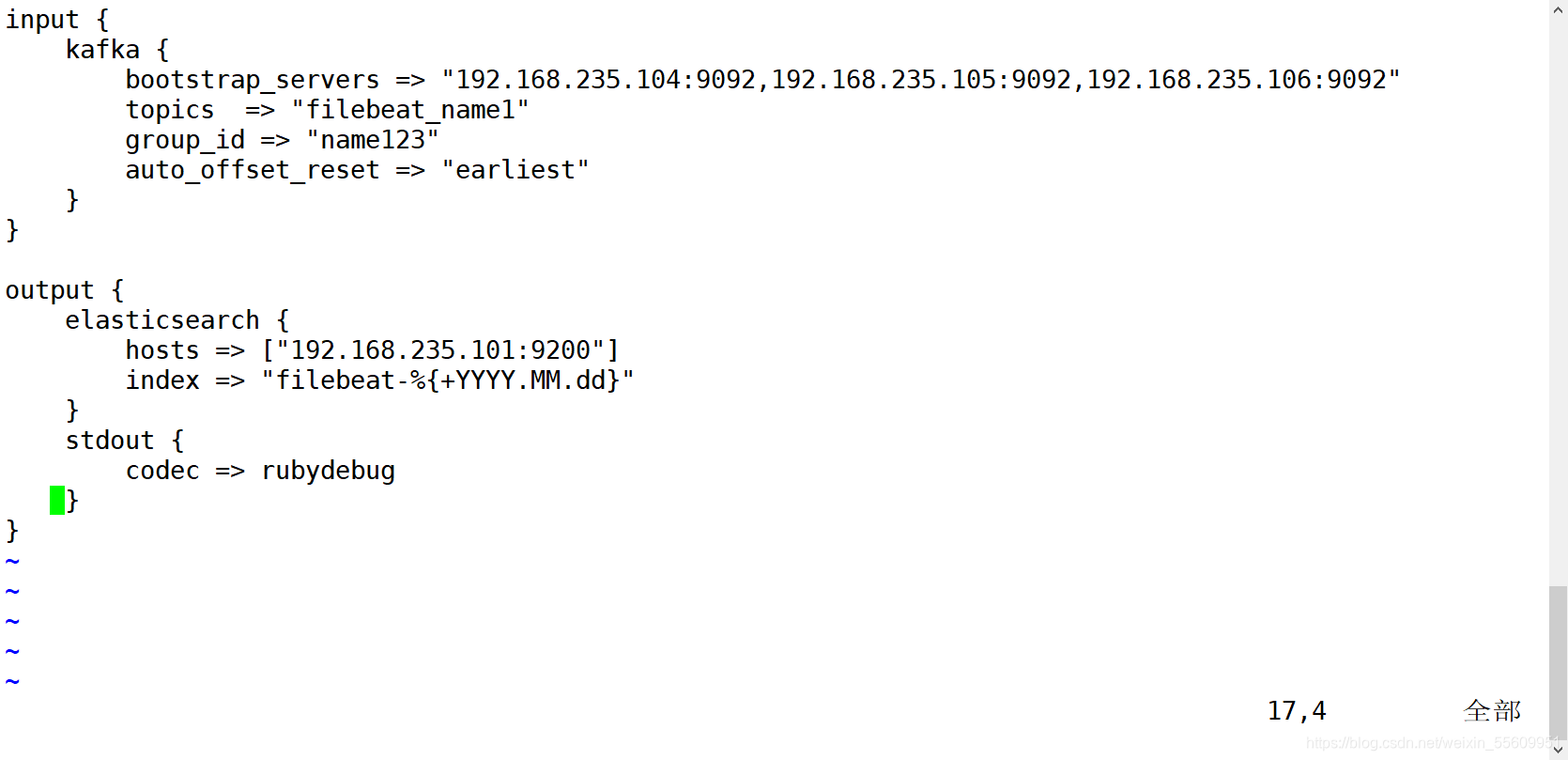
input {
kafka {
bootstrap_servers => "192.168.235.104:9092,192.168.235.105:9092,192.168.235.106:9092"
topics => "filebeat_name1"
group_id => "name123"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => ["192.168.235.101:9200"]
index => "filebeat-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
启动 logstash

登录 Kibana
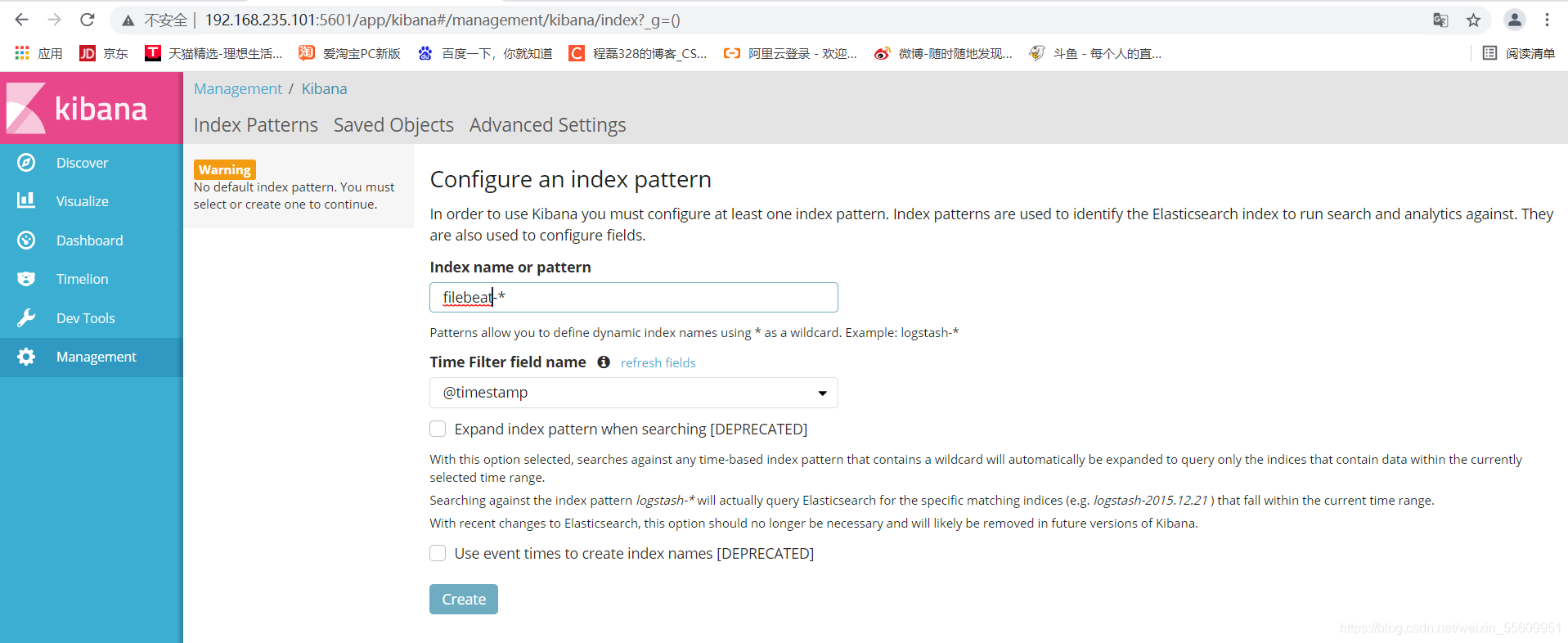
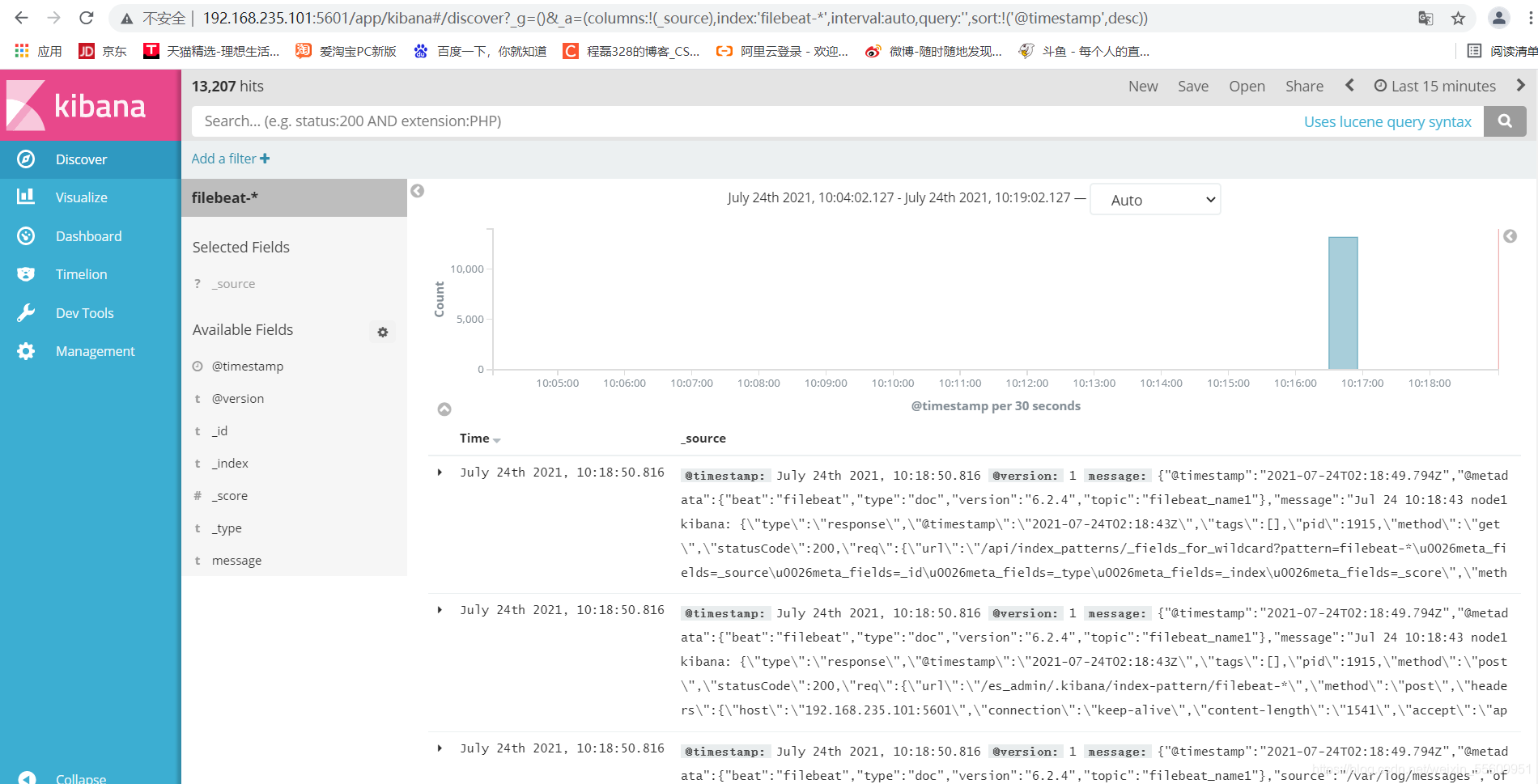
可以查看到node1节点的信息,以上的操作是使用filebeat收集了node1的数据,传送到zookeeper集群,zookeeper这边是通过kafka接受,kafka作为一个消息队列,他可以对数据进行处理,然后传送给通过logstash传送到es中进行储存,最后通过kibana展示出来。














 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









