







通常情况下,32x 系统下的内存大小是 4G,进程在查找数据时的地址我们认为它是一个真正的地址,其实不是,我们所能看到的地址,包括堆栈、变量等等,它们的地址其实都是虚拟地址,可以总结的说,在语言层面上见到的地址都是虚拟地址。物理地址用户看不到,由操作系统控制,以虚拟找物理。
那进程是如何通过虚拟地址查找数据的呢?下面我们来讲解一下。
进程地址空间:
程序地址空间准确来说应该叫:进程地址空间。当一个可执行程序加载到内存中,创建对应的进程控制块 PCB,也就是 task_struct,还会创建一个进程地址空间 mm_struct ,mm_struct 中有该进程的栈区、堆区、代码段等等。所以说, mm_struct 是 task_struct 中的一部分。
mm_struct 中的每个区域如何划分呢,其实它就是一个虚拟地址,就像小时候画分界线一样,每个区域都有开头及结尾,start 和 end 。
进程的代码以及数据,都加载到了内存上,也就是物理内存,进程的运行需要从加载到内存的代码中提取代码,而为了防止破坏内存,操作系统不会让用户直接从物理内存中拿数据和放数据,那如何进行信息的交互呢?这时候,会有一个叫页表的关键角色,帮助进程对数据代码进行操作。
进程通过 mm_struct 中的虚拟地址,再通过页表的映射关系(哈希),再物理内存中找到对应的数据和代码,再进行下一步执行。
为什么要那么麻烦,就不能直接再物理内存上进行增删查改吗?其实之所以这么做,最大的原因是为了让内存管理(物理内存)与 mm_struct(操作系统)之间进行解耦。当虚拟内存出现问题时,在页表就给你拦住了,不会影响到物理内存。
那如果创建了子进程,需要进行复制父进程的代码和数据吗?
不用的,这样太浪费空间了,子进程未必会执行父进程的部分代码,子进程会创建后构建对应的 PCB、mm_struct、页表,但是代码共享,数据共享。
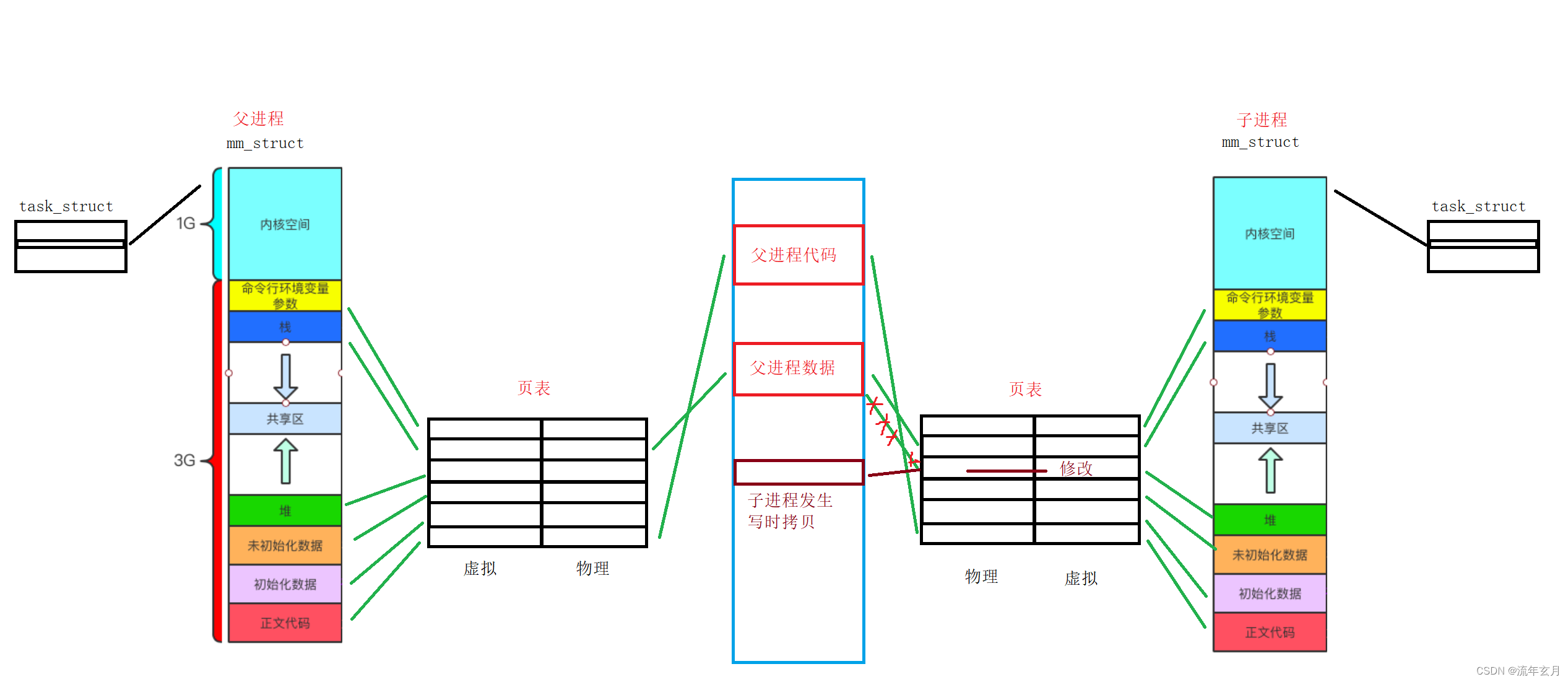
写时拷贝:
当创建时,子进程与父进程一样,是拷贝父进程的代码和数据的,如果要修改数据,不需要拷贝全部的数据,只需拷贝需要修改的数据,拷贝到内存中任意一块对应映射的地方即可(数据的存储是看页表的,物理内存中是随机的一块区域,不是想象中的按顺序开辟)。
进程调度队列:
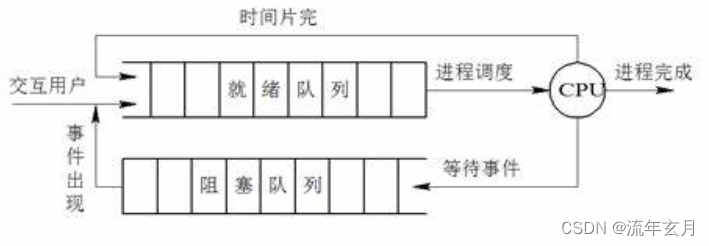
进程调度队列是 CPU 中的一个名为 runqueue 的数据结构,其中包含了 bitmap[5]、queue[140],而 bitmap[5] 是五个字节,5*32 个比特位,用位图来表示 140 个 queue 的列表大小,每一个 queue[] 表示的都是该对应的优先级的进程,里面的进程都是 R 状态的。
相同优先级的基础会放在同一个链表当中链接起来,每次 CPU 会从 [0] 开始遍历,为了更快的切换,一般有两个 queue[],一个是正在调度的,一个是准备调度的,准备调度的 queue 修改好后就变成了正在调度的 queue,来回切换。
为什么要有 queue,因为遍历进程是 O(N) 级别的时间,内存中内存多了,有的是 S,有的 T,这样遍历不方便,所以就把 R 状态的进程单独找出来,每个进程的下一个就是 R 。
总结:
1、什么叫创建进程?
创建进程就是创建 struct task_struct、struct mm_struct、页表。
2、为什么要有地址空间?
不会有任何系统级别的越界问题,页表不会映射你之外的空间,或者查看映射关系有没有。例如进程 1 不小心写到了进程 2。
虚拟地址和页表的作用是保护内存。
3、统一性
每个区域空间范围进程都认为是相同的,也就是栈、变量的区域划分。
4、每个进程都认为自己在独占内存,更好的完成独立性及合理分配空间。
比如打一个 60G 的游戏,内存只有 4G,不可能全加载到内存中,所以当需要的时候再加载到内存,这样更加合理的运用空间,你不用时给别人用。而进程地址空间那边,进程认为自己已经把数据加载进来了,等可执行程序运行到了再加载,叫做延后执行。















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









