






好用的插件
1. sider:帮你显示视频的文字,方便自己的总结
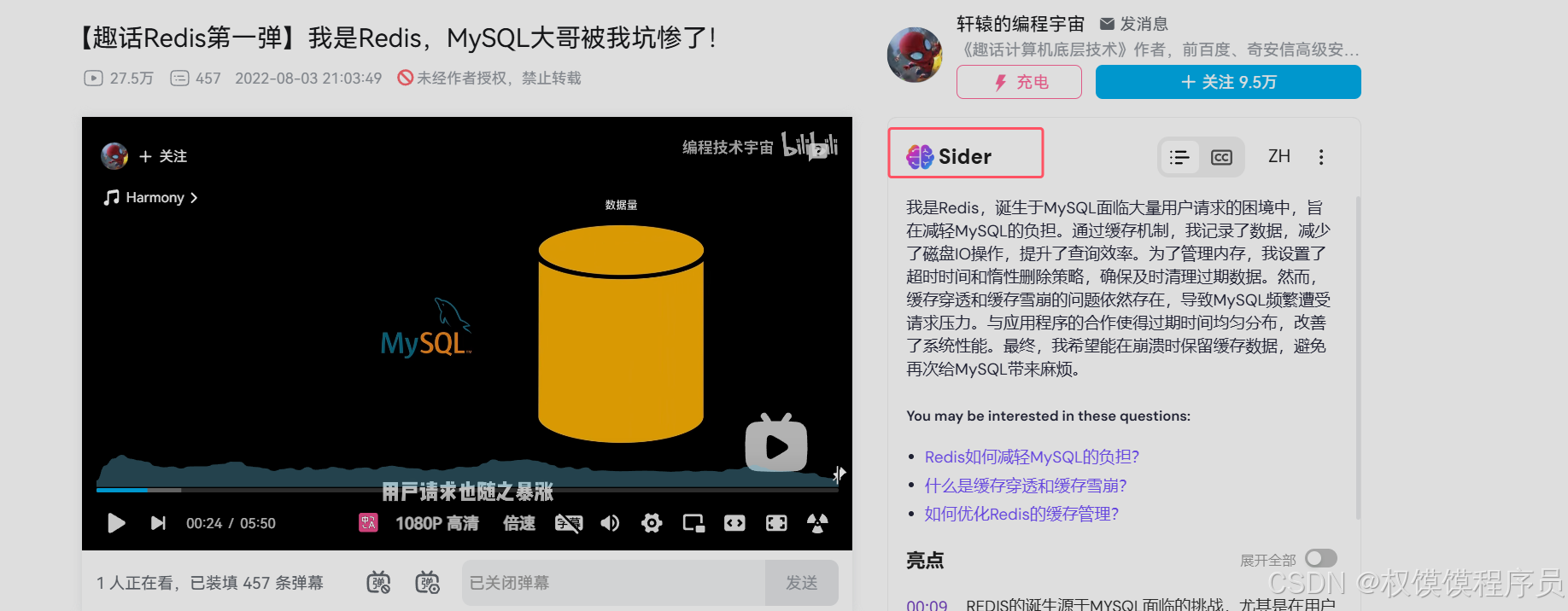
redis为何诞生
- 可以模仿 CPU 给数据库加一个缓存
- redis的登记数据是存在内存中的,不用再和Mysql执行IO操作了
redis的更新:随着问题的出现
- 遇到问题:内存可能会存满,
-
- 给缓存设置过期时间,不能全部都扫一遍(扫描需要删除的键值),只是随机选择一部分释放
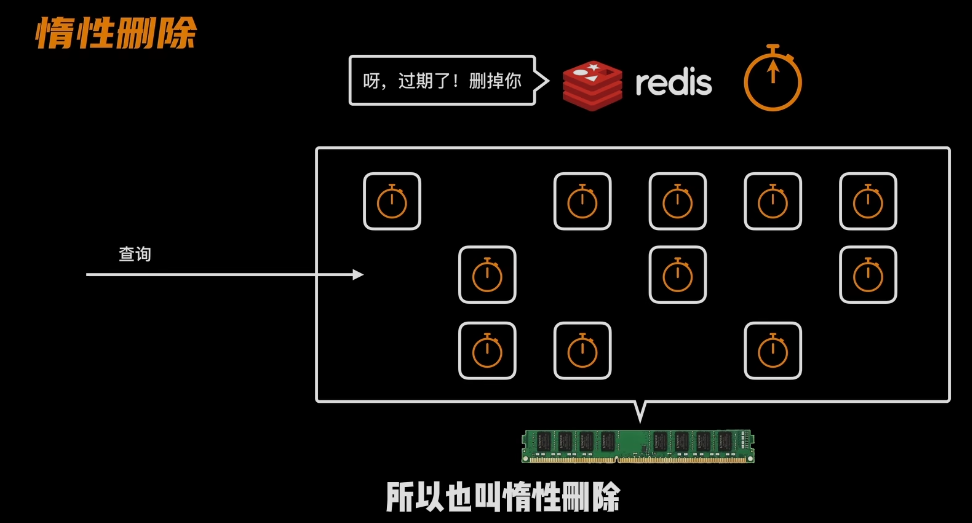
- 问题出现:有的键值运气好,没有被扫描到
-
- 使用惰性删除:在查询时,发现其已经过期了,就主动删除
- 问题:有的键值既躲过了随机淘汰算法,又一直没有被访问,迟早要完
-
- 出现了内存淘汰策略


缓存击穿:
- 当查询的数据在redis是不存在的,就会查询数据库
- 因为:又一个热点数据被我删除了,随后就有大量的请求过来了
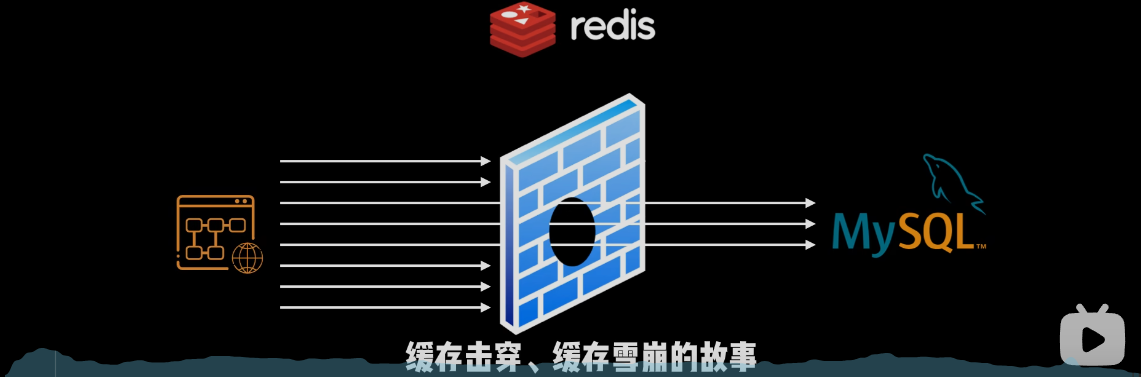
缓存雪崩:
- 因为:在redis同时失效了一大批热点数据,然后有一大批请求打过来,把mysql给打趴下了
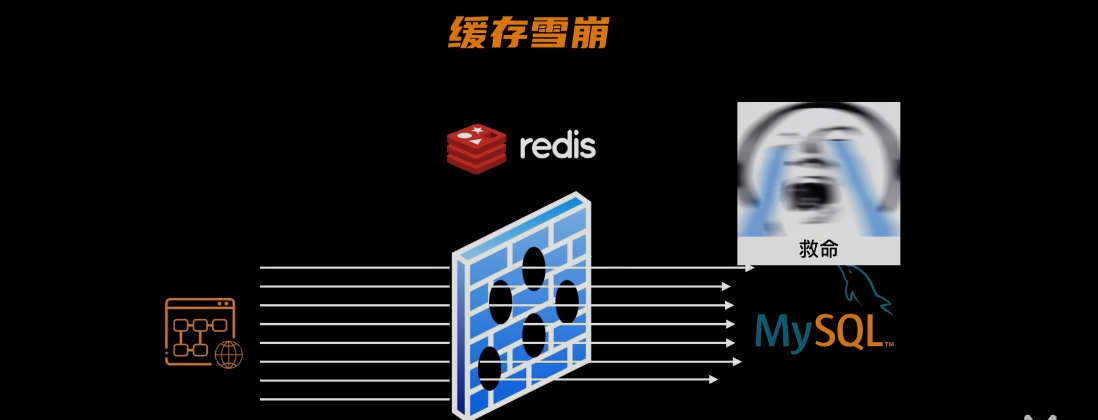
解决问题:
- 把键值的时间随机一下,热点数据永不过期的策略

redis:数据持久化
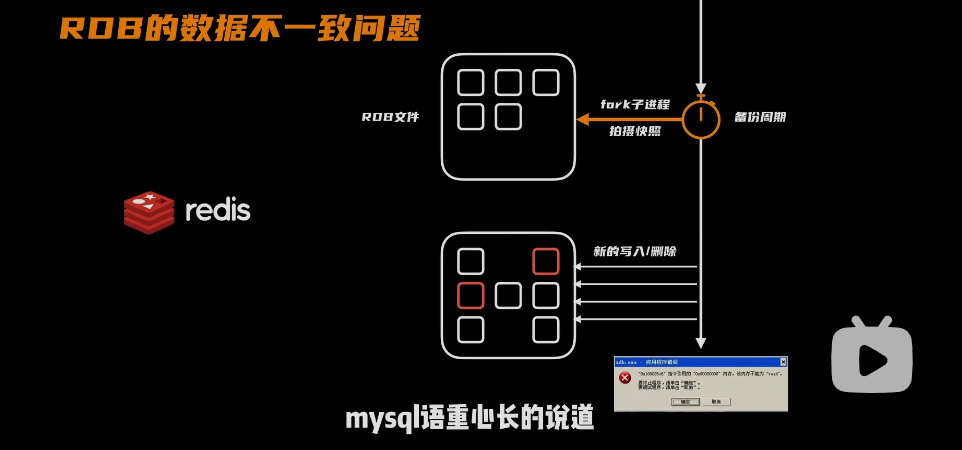
- RDB方案:把数据备份到RDB文件(二进制格式)里面,然后存到硬盘上
- 创建一个子进程来备份数据:按照自己配置的参数

问题出现:按照分钟级别的备份,要丢失很多数据
- 解决:不用在备份时遍历所有的数据,可以记录了我对数据执行更改的所有操作,像是insert、update、delete等等动作
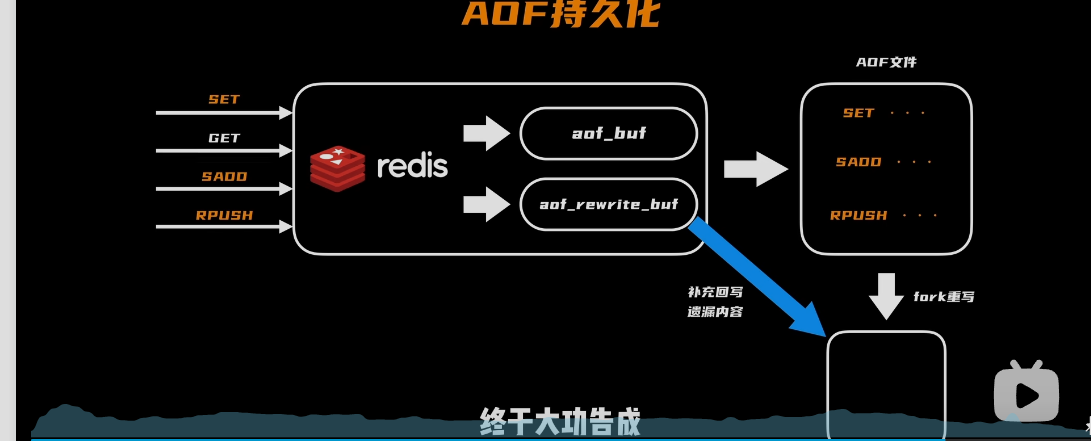
解决问题:AOF持久化
- 把执行所有写入命令记录下来,但是多久执行一次呢?→aof_buf就问世了

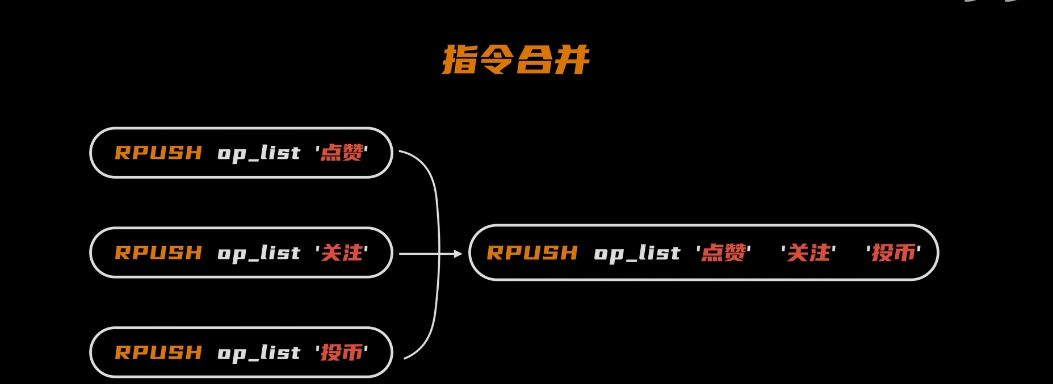
问题:AOF文件会越来越大
-
- 开始尝试去掉冗余的指令,后面发现工作量太大了;发现很多中间状态都是不需要的,为何不记录最终的状态呢?比如三条指令合并
问题:AOF重写数据不一致的问题
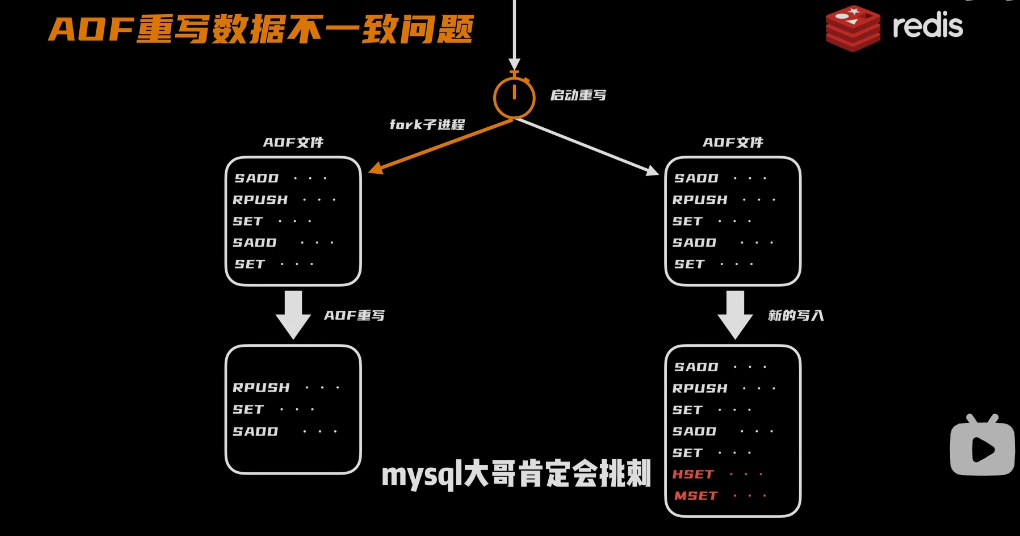
解决问题:
- 在重写子进程开始时,后面的写入操作放入aof_rewrite_buf缓存区中,等fork子进程重写完成,在把重写缓存区的数据同步的AOF文件中,在进行重命名
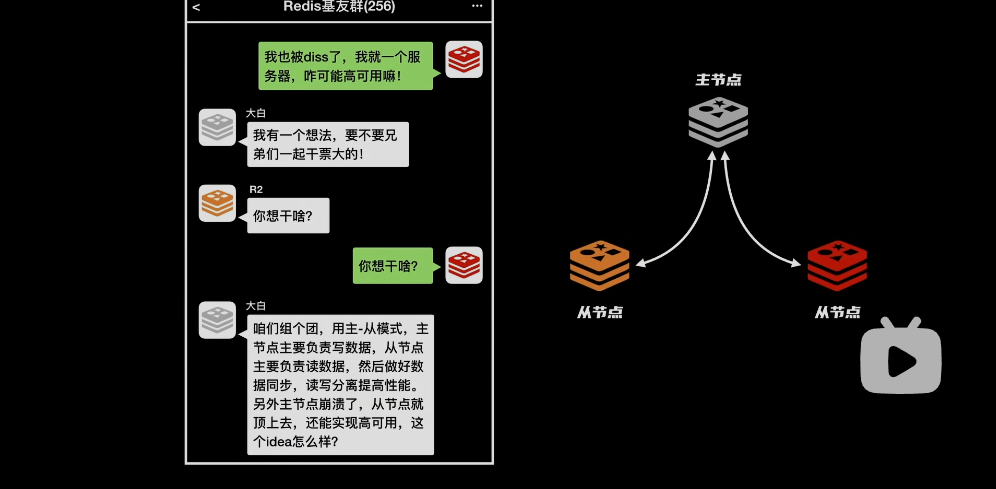
redis帮手:多几个实例
主-从模式:
- 让redis高可用,主节点负责写数据,从节点负责读数据
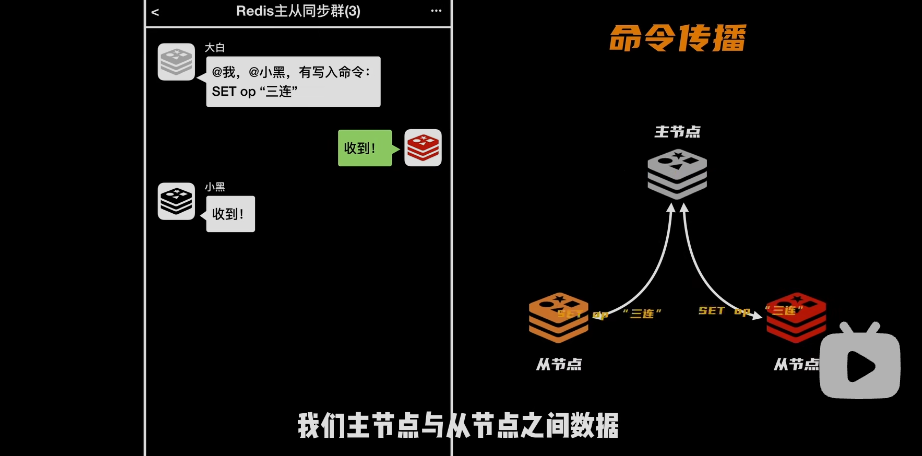
命令传播:
- 从节点先同步RDB的数据,然后主节点缓存了一些删除、修改指令,也会把这些命令挨个通知到从节点
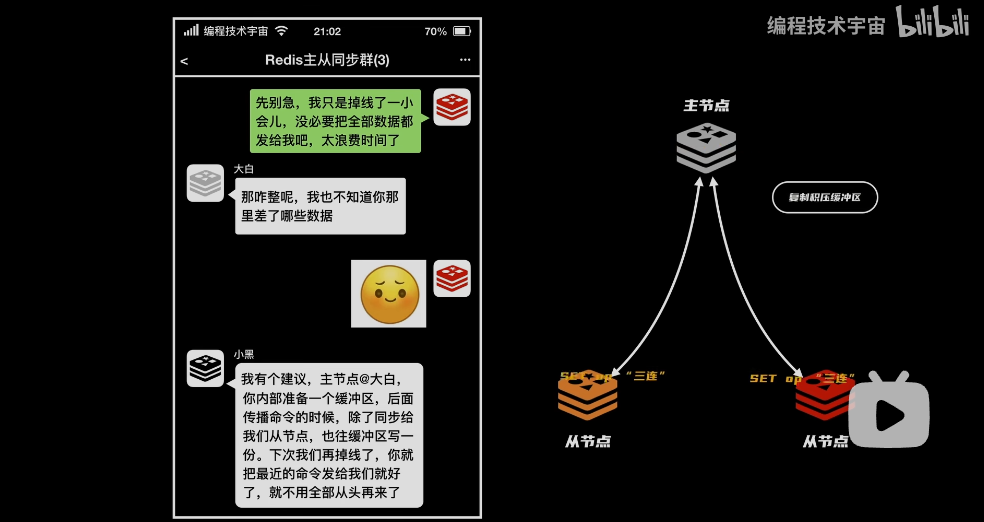
问题:一个从节点不小心掉线了,需要主节点同步最新的RDB文件吗?
- 解决:主节点在传播指令时,也把数据同步一份到缓冲区,然后从节点掉线后,同步数据就不需要从头再来了
问题:主节点缓存的数据是从节点需要的吗?能不能对得上呢?
- 解决:使用游标偏移量,后面比较各自的偏移量
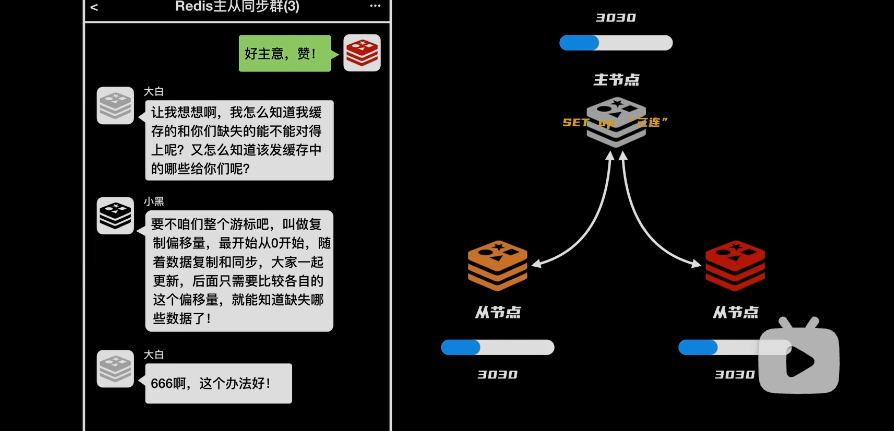
问题:当主节点挂了,还要手动选择从节点来当主节点
- 哨兵 sentinel 是管理员,有多个管理员,主要复杂 ping 下面的小弟,R1/R2/R3,每隔10s看他们挂了没

- 如果一个管理员发现ping不上,判定为主观掉线,当3个管理员都ping不上时,在进行故障转移

怎么进行故障转移:
- 把主节点变成从节点
- 在从节点选择一个来当主节点
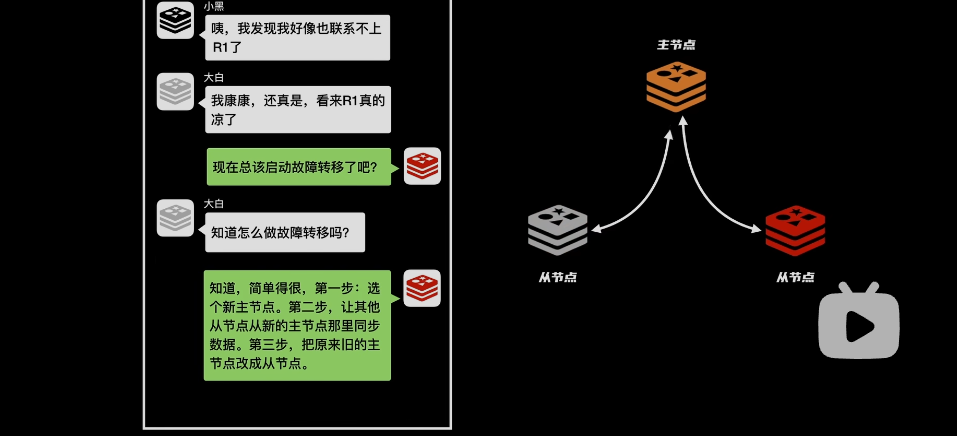
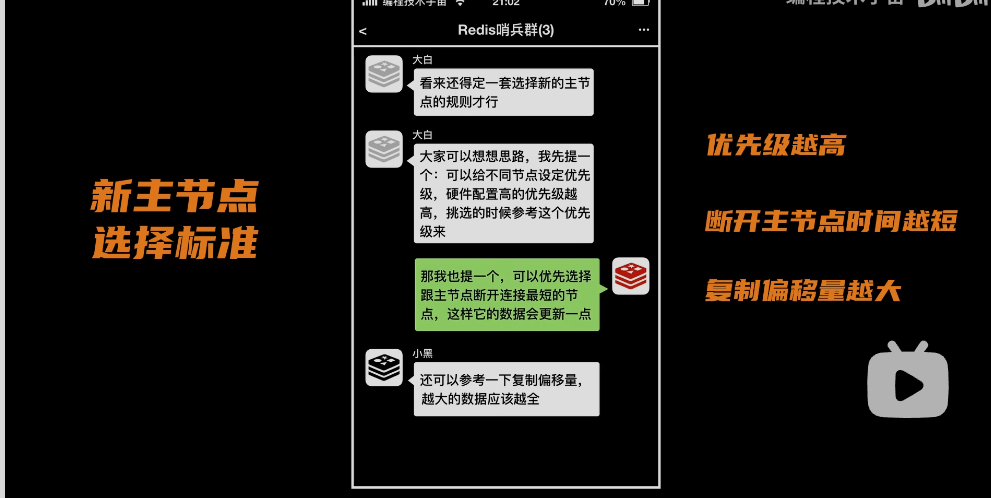
问题:管理员怎么选择主节点
- 可以根据从节点的硬件配置来设置优先级,
- 根据跟主节点断开时间,断开时间越短,优先级是越高的
- 根据游标偏移量,偏移量越大的数据是越全的,优先级是越高的
最终实现:完成了故障转移、构成了一个高可用的缓存服务
- 问题:不同的节点可以缓存不同的数据的,不用每一个节点都缓存所有的数据,不然浪费空间的
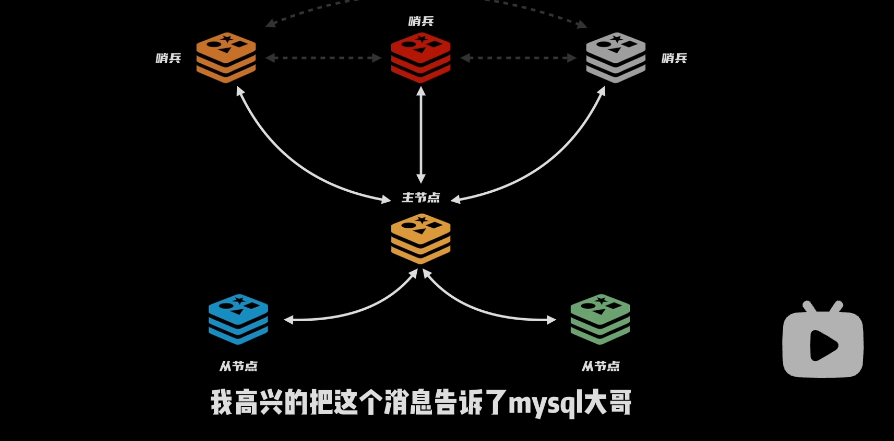
Redis集群是怎么如何工作的呢?
- 问题:哨兵模式、主次模式只能解决高可用的问题,但是解决不了数据量大的问题,都存储了全量的数据
解决:变成一个大的缓存服务器,每一个集群存储一部分数据
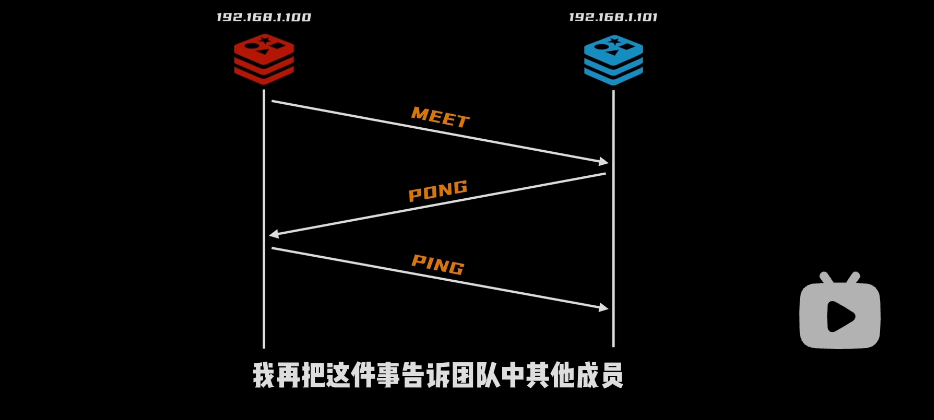
问题:在集群进行团队建设后,怎么加入新的集群
- 要告诉我 ip 和端口:进行三次握手,MEET,pong,ping(回显)
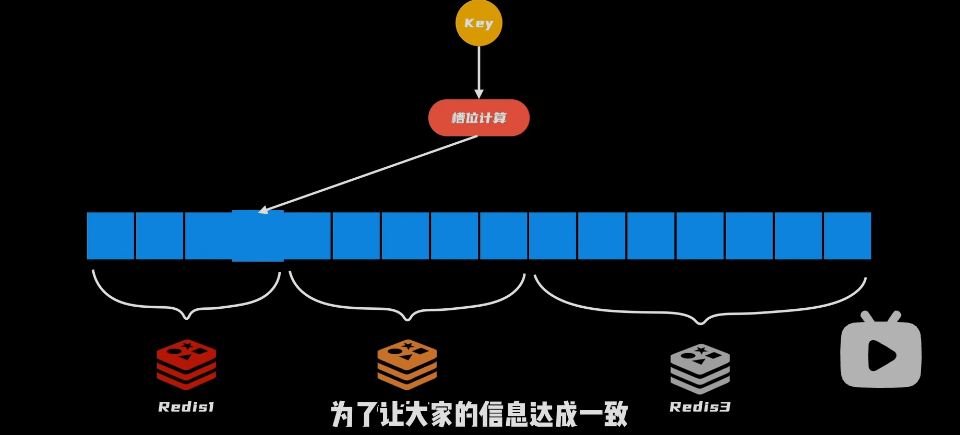
问题:集群有了,得解决存储问题
- 模仿哈希表,总共有16384个哈希桶,也叫做槽位
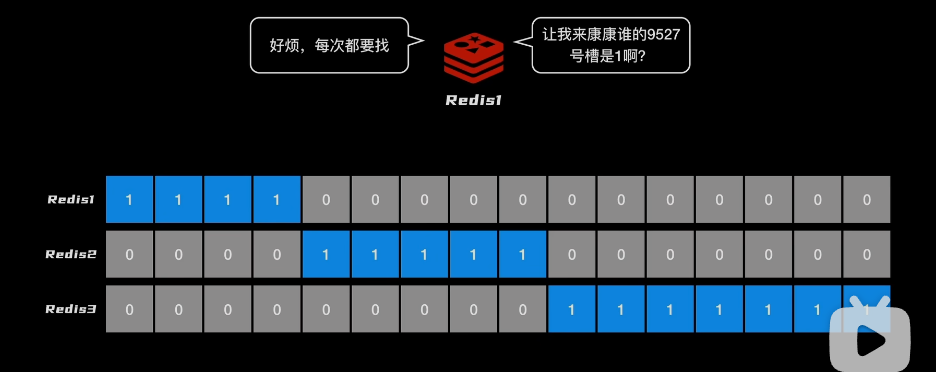
问题:为了达成数据一致,要告诉谁负责哪些槽位,1万多个槽位,数据量有点大
- 让每个槽位由 1 bit来负责,由自己负责的是1
- 问题:虽然传输室快了,但是当读写时,总不能在1万多个看哪一个是1吧
问题:使用空间换时间
- 由一个超大的数组,来存储每一个槽位是由哪一个redis集群来控制的,cluster
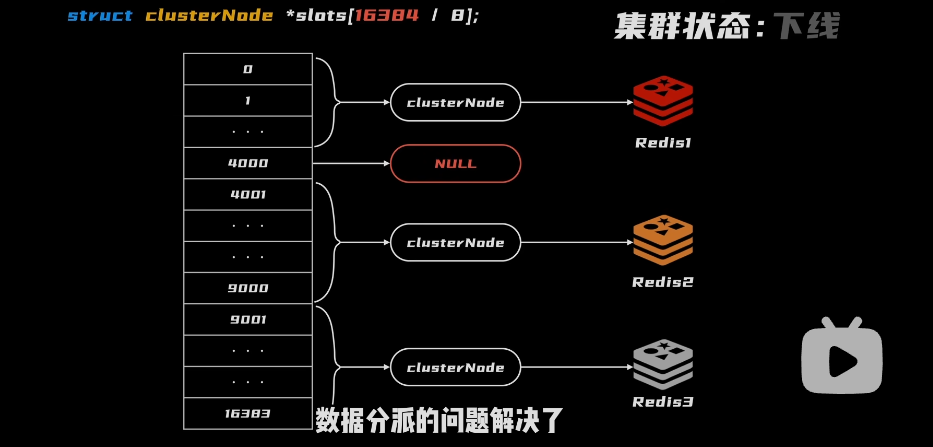
- 数据在读写时,先检查是否由我负责,MOVEO
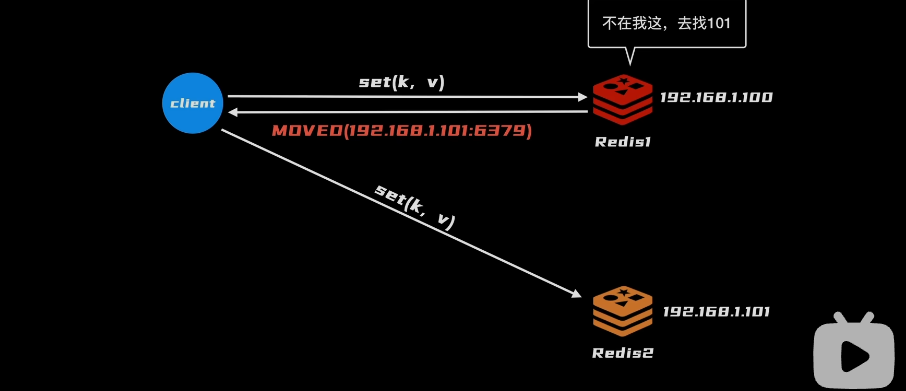
问题:集群中万一挂了一个,就要整体下线了
- 需要一个 backup (支援,备用品),需要一些从节点


















 3643
3643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









