







近年来,大语言模型(Large Language Model, LLM)日益强大的性能吸引了各行各业的关注,并逐步在各种领域得到了广泛应用。为了节省大模型部署的成本,降低大模型服务延迟,越来越多的研究聚焦于大语言模型轻量化,试图平衡大语言模型的性能与效率。
剪枝是实现模型轻量化的重要技术之一,它通过删去模型中重要性较低的参数减少模型的参数量。近期,学术界提出了多种剪枝技术,这些方法利用少量校准数据(一般是128条2048个token的文本)无需迭代式的训练就能度量并识别出重要性较低的参数,一般被称为训练后剪枝。训练后剪枝的目标如下: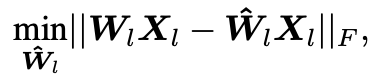 其中 是第 层的参数, 是第 层的输入表示, 与校准数据相关, 是第 层的剪枝后的参数。训练后剪枝包括两个主要要素:校准数据与剪枝算法。校准数据影响了剪枝算法的目标函数, 剪枝算法则是寻找目标函数的最优解。目前剪枝算法的改进使得模型剪枝不断逼近最优解,但是如果我们的目标函数受到校准数据的影响本就存在偏差呢?
其中 是第 层的参数, 是第 层的输入表示, 与校准数据相关, 是第 层的剪枝后的参数。训练后剪枝包括两个主要要素:校准数据与剪枝算法。校准数据影响了剪枝算法的目标函数, 剪枝算法则是寻找目标函数的最优解。目前剪枝算法的改进使得模型剪枝不断逼近最优解,但是如果我们的目标函数受到校准数据的影响本就存在偏差呢?
论文:Beware of Calibration Data for Pruning Large Language Models
链接:https://arxiv.org/abs/2410.17711
发现
我们在DCLM-7B模型上对比了剪枝算法与校准数据分别对剪枝性能的影响。图1(a)展示了5种近期最有代表性和竞争力的剪枝算法,我们遵循相关论文中的常规设置,从C4数据中采样128条序列长度为2048的校准数据;图1(b)展示了SparseGPT方法使用5种不同校准数据的性能差异。通过这个实验我们得到两个重要发现:
- C4并非是最优的校准数据选择,可以通过选取更好的校准数据,为剪枝算法的性能带来一个百分点的显著提升;
- 校准数据的影响超过剪枝算法的影响,如果选用的校准数据不合适,原本具有竞争力的剪枝算法也会失效。
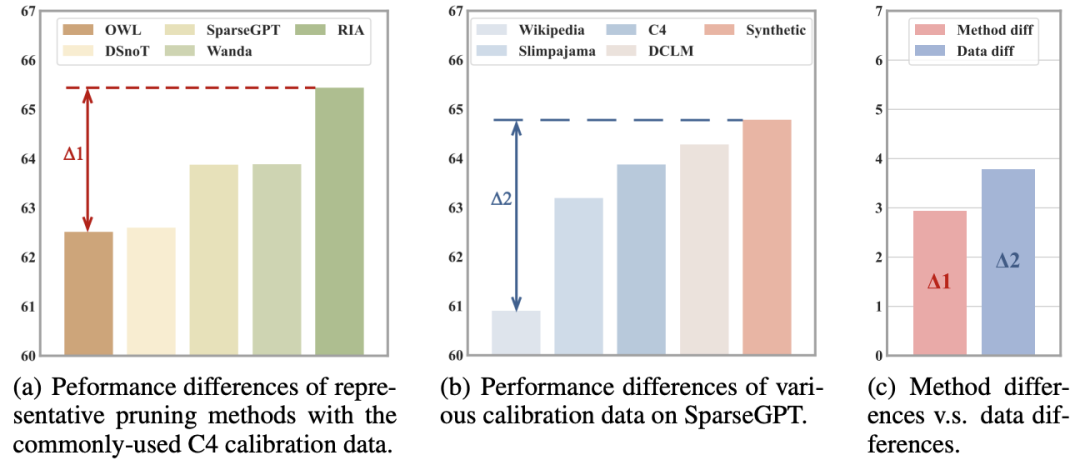 图1 剪枝算法与校准数据对剪枝性能的影响
图1 剪枝算法与校准数据对剪枝性能的影响
因此,我们认为研究者在不断提出新剪枝算法的同时,也有必要对校准数据进行更深入的研究。在本文中,我们试图回答关于校准数据的以下三个问题:
- 问题1:校准数据在不同剪枝设置下对剪枝性能的影响有多大?
- 问题2:校准数据量如何影响压缩模型的性能?
- 问题3:什么样的数据适合作为校准数据?
实证研究
我们在DCLM-7B上进行实验,因为它是目前唯一开源了全部预训练数据且性能足够强大的LLM,透明的预训练数据有助于我们研究影响校准数据性能的因素(OPT系列虽然也开源了数据,但其性能与目前广泛使用的LLMs相去甚远,它的剪枝现象不一定适用于当前的LLMs)。
问题1
我们分别从稀疏比和稀疏类型两个方面比较在不同剪枝设置下校准数据的影响。图2展
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









