










PySpark Documentation — PySpark 3.3.0 documentation https://spark.apache.org/docs/latest/api/python/
https://spark.apache.org/docs/latest/api/python/
前言 - Spark
1. 运行pyspark的各种方式
1,通过pyspark进入pyspark单机交互式环境。
这种方式一般用来测试代码。
也可以指定jupyter或者ipython为交互环境。
2,通过spark-submit提交Spark任务到集群运行。
这种方式可以提交Python脚本或者Jar包到集群上让成百上千个机器运行任务。
这也是工业界生产中通常使用spark的方式。
3,通过zepplin notebook交互式执行。
zepplin是jupyter notebook的apache对应产品。
4, Python安装findspark和pyspark库。
可以在jupyter和其它Python环境中像调用普通库一样地调用pyspark库。
2. Spark基本概念
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系。
- Driver Program:控制程序,负责为Application构建DAG图。
- Cluster Manager:集群资源管理中心,负责分配计算资源。
- Worker Node:工作节点,负责完成具体计算。
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task,并为应用程序存储数据。
- Application:用户编写的Spark应用程序,一个Application包含多个Job。
- Job:作业,一个Job包含多个RDD及作用于相应RDD上的各种操作。
- Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
- Task:任务,运行在Executor上的工作单元,是Executor中的一个线程。
- 总结:Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成。Stage是作业调度的基本单位。
3. PySpark架构设计
pyspark,为了不破坏Spark已有的运行时架构,Spark在外围包装一层Python API。在Driver端,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序。在Executor端,则不需要借助Py4j,因为Executor端运行的Task逻辑是由Driver发过来的,那是序列化后的字节码。
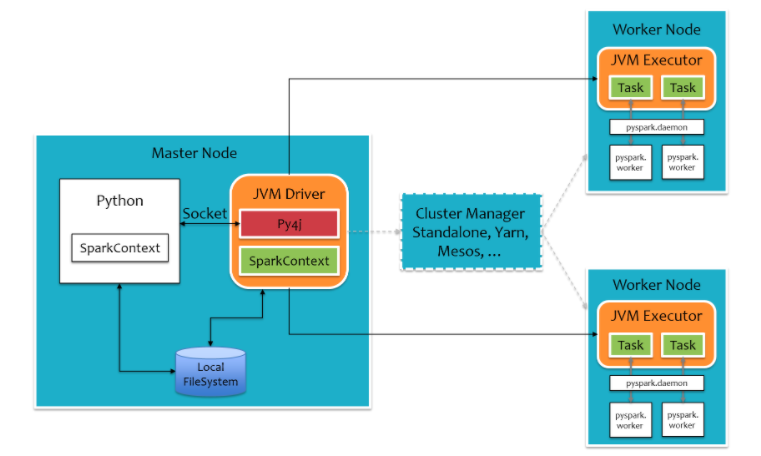
4. Spark运行流程
- Application首先被Driver构建DAG图并分解成Stage。
- 然后Driver向Cluster Manager申请资源。
- Cluster Manager向某些Work Node发送征召信号。
- 被征召的Work Node启动Executor进程响应征召,并向Driver申请任务。
- Driver分配Task给Work Node。
- Executor以Stage为单位执行Task,期间Driver进行监控。
- Driver收到Executor任务完成的信号后向Cluster Manager发送注销信号。
- Cluster Manager向Work Node发送释放资源信号。
- Work Node对应Executor停止运行。

5. RDD数据结构
RDD,Resilient Distributed Dataset,弹性分布式数据集,它是记录的只读分区集合,是Spark的基本数据结构。RDD代表一个不可变、可分区、里面的元素可并行计算的集合。
一般有两种方式创建RDD,第一种是读取文件中的数据生成RDD,第二种则是通过将内存中的对象并行化得到RDD。
#通过读取文件生成RDD
rdd = sc.textFile("hdfs://data_warehouse/test/data")
#通过将内存中的对象并行化得到RDD
arr = [1,2,3,4,5]
rdd = sc.parallelize(arr)RDD的操作有两种类型,即Transformation操作和Action操作。转换操作是从已经存在的RDD创建一个新的RDD,而行动操作是在RDD上进行计算后返回结果到 Driver。
Transformation操作都具有 Lazy 特性,即 Spark 不会立刻进行实际的计算,只会记录执行的轨迹,只有触发Action操作的时候,它才会根据 DAG 图真正执行。
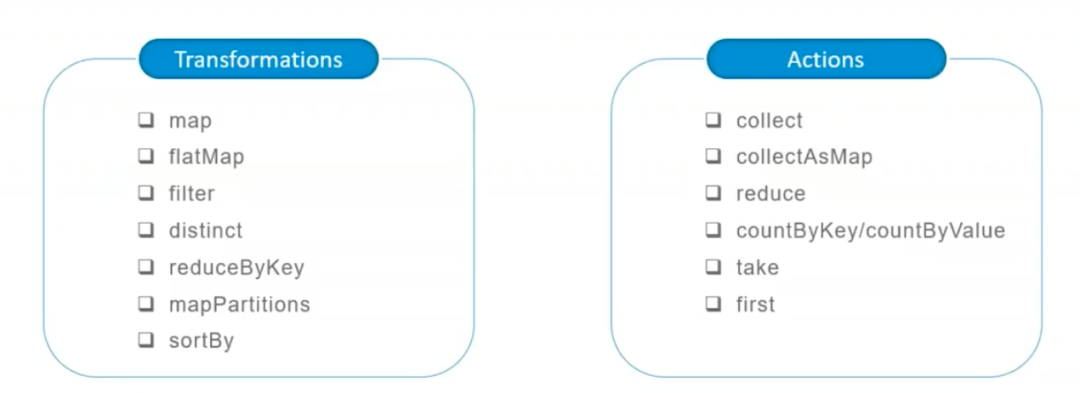
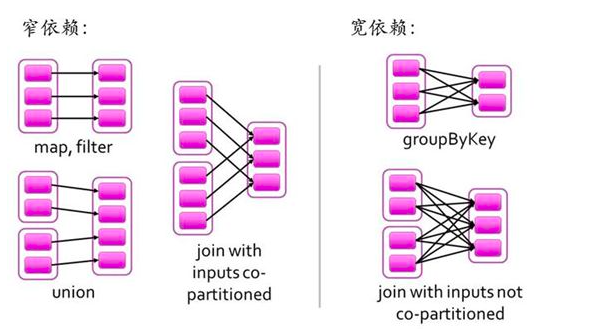
操作确定了RDD之间的依赖关系。
RDD之间的依赖关系有两种类型,即窄依赖和宽依赖。窄依赖时,父RDD的分区和子RDD的分区的关系是一对一或者多对一的关系。而宽依赖时,父RDD的分区和子RDD的分区是一对多或者多对多的关系。
宽依赖关系相关的操作一般具有shuffle过程,即通过一个Patitioner函数将父RDD中每个分区上key不同的记录分发到不同的子RDD分区。
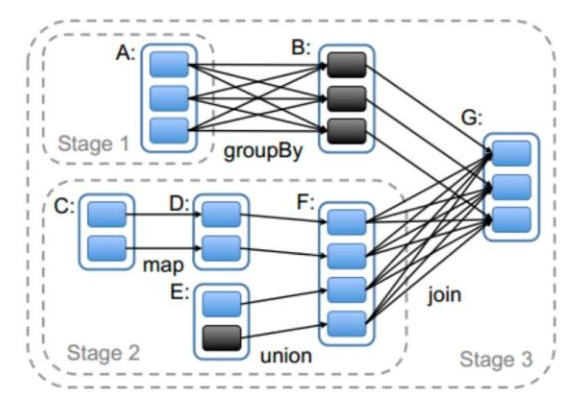
依赖关系确定了DAG切分成Stage的方式。
切割规则:从后往前,遇到宽依赖就切割Stage。
RDD之间的依赖关系形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分成相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
6. 代码例子
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
print("spark version:",pyspark.__version__)
rdd = sc.parallelize(["hello","spark"])
print(rdd.reduce(lambda x,y:x+' '+y))
#wordcount例子
rdd_line = sc.textFile("/home/data/hello.txt")
rdd_word = rdd_line.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda t:(t,1))
rdd_count = rdd_one.reduceByKey(lambda x,y:x+y)
rdd_count.collect() 一、RDD编程
- 创建RDD
- 常用Action操作
- 常用Transformation操作
- 常用PairRDD的转换操作
- 缓存操作
- 共享变量
- 分区操作
二、SparkSQL编程
- RDD和DataFrame的对比
- 创建DataFrame
- DataFrame保存成文件
- DataFrame的API交互
- DataFrame的SQL交互
三、Spark性能调优方法
一般来说,如果有可能,用户应当尽可能多地使用SparkSQL以取得更好的性能。
主要原因是SparkSQL是一种声明式编程风格,背后的计算引擎会自动做大量的性能优化工作。基于RDD的Spark的性能调优属于坑非常深的领域,并且很容易踩到。
可以用下面三个公式来近似估计spark任务的执行时间:
可以用下面二个公式来说明spark在executor上的内存分配:
四、分布式实现代码
五、MLlib机器学习
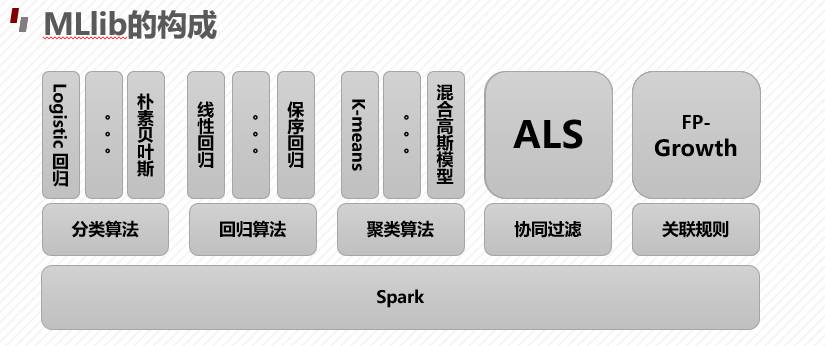
- DataFrame: MLlib中数据的存储形式,其列可以存储特征向量,标签,以及原始的文本,图像。
- Transformer:转换器。具有transform方法。通过附加一个或多个列将一个DataFrame转换成另外一个DataFrame。
- Estimator:估计器。具有fit方法。它接受一个DataFrame数据作为输入后经过训练,产生一个转换器Transformer。
- Pipeline:流水线。具有setStages方法。顺序将多个Transformer和1个Estimator串联起来,得到一个流水线模型。
from pyspark.ml.feature import Tokenizer,HashingTF
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import MulticlassClassificationEvaluator,BinaryClassificationEvaluator
from pyspark.ml import Pipeline,PipelineModel
from pyspark.ml.linalg import Vector
from pyspark.sql import RowSpark MLlib的分布式训练方法有下面几个弊端:
- 采用全局广播的方式,在每轮迭代前广播全部模型参数。众所周知Spark的广播过程非常消耗带宽资源,特别是当模型的参数规模过大时,广播过程和在每个节点都维护一个权重参数副本的过程都是极消耗资源的过程,这导致了Spark在面对复杂模型时的表现不佳;
- 采用阻断式的梯度下降方式,每轮梯度下降由最慢的节点决定。从上面的分析可知,Spark MLlib的mini batch的过程是在所有节点计算完各自的梯度之后,逐层Aggregate最终汇总生成全局的梯度。也就是说,如果由于数据倾斜等问题导致某个节点计算梯度的时间过长,那么这一过程将block其他所有节点无法执行新的任务。这种同步阻断的分布式梯度计算方式,是Spark MLlib并行训练效率较低的主要原因;
- Spark MLlib并不支持复杂网络结构和大量可调超参。事实上,Spark MLlib在其标准库里只支持标准的多层感知机神经网络的训练,并不支持RNN,LSTM等复杂网络结构,而且也无法选择不同的activation function等大量超参。这就导致Spark MLlib在支持深度学习方面的能力欠佳。
1. 数据操作
Sql.dataframe
spark = SparkSession.builder \
.appName("spark") \
.getOrCreate()
df = spark.read.csv('fraudTrain.csv',header=True)
df.printSchema()数据查看
df.count() #查看计数
df.show(truncate=False) #dataframe显示数据处理
df.take(1)
df.select('col')2. 特征工程
缺失值
df.na.drop() # df.dropna()
df.na.fill()编码
from pyspark.ml.feature import Binarizer
#二值化
binarizer = Binarizer(threshold=10, inputCol='humidty', outputCol= 'label')
df = binarizer.transform(df)
df.select('humidty','label').show(4)标准化/归一化
#特征
from pyspark.ml.feature import VectorAssembler
assemble = VectorAssembler(inputCols=featuralist, outputCol='features')
df = assemble.transform(df)
#标准化
from pyspark.ml.feature import StandardScaler
scale = StandardScaler(inputCol='features', outputCol='standardized')
scaler = scale.fit(df)
df = scaler.transform(df)3. 特征选择
Chi-Square selector
4. 机器学习模型
from pyspark.ml import Pipeline
from pyspark.ml.clustering import KMeans
from pyspark.ml.classification import LogisticRegressiondt
from pyspark.ml.regression import DecisionTreeRegressor
#逻辑回归
blor = LogisticRegression()
blorModel = blor.fit(df)
blorModel.evaluate(df).accuracy == blorModel.summary.accuracy
blorModel.predict(df)
blorModel.transform(df).prediction
#决策树回归
dt = DecisionTreeRegressor(maxDepth=2)
model = dt.fit(df)
model.featureImportances5. 模型评估
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(rawPredictionCol= 'rawPrediction')
evaluator.evaluate(dataset)6. 文本挖掘
词频统计 TF-IDF
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。


TF-IDF实际上是:TF * IDF。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
from pyspark.ml.feature import HashingTF, IDF, Tokenizer, CountVectorizer
from pyspark.ml.feature import StringIndexer
#1. HashingTF + IDF + Logistic Regression.
#2. CountVectorizer + IDF + Logistic Regression.
#分词
tokenizer = Tokenizer(inputCol='text',outputCol="words")
df= tokenizer.transform(df)
# numFeatures特征数上限,不同word的数量
hashtf = HashingTF(numFeatures=2**16, inputCol='words', outputCol="tf")
hashingTF.transform(df).head().features
# => SparseVector(10, {5: 1.0, 7: 1.0, 8: 1.0})
# 逆向文件频率
idf= IDF(minDocFreq=5, inputCol='tf', outputCol="features")
model = idf.fit(df)
model.transform(df)
# 将string列映射为 label [0, numLabels) 0是频率最高的
# 也可以将numeric列映射为带标签string
indexer=StringIndexer(inputCol="target", outputCol="label",stringOrderType="frequencyDesc")
model = indexer.fit(df)
df= model.transform(df)
#
CountVectorizer()六、基于pySpark的Pandas API
References
PySpark | Spark框架简述 | Spark环境搭建_跟乌龟赛跑的博客-CSDN博客_pyspark
【Pyspark教程】SQL、MLlib、Core等模块基础使用_山顶夕景的博客-CSDN博客_pyspark
【PySpark调优】 3万字长文,PySpark入门级学习教程,框架思维_CSDN博客















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









