







Week1
Topic: Introduction & Big data lifecycle
1. Definition of Big Data
Big Data is a field dedicated to the analysis, processing, and storage of large collections of data that frequently originate from disparate sources.
2. Terminology
2.1 Datasets
Collections or groups of related data are generally referred to as datasets. Each group or dataset member (datum) shares the same set of attributes or properties as others in the same dataset.
2.2 Data Analysis
Data analysis is the process of examining data to find facts, relationships, patterns, insights and/or trends. The overall goal of data analysis is to support better decisionmaking.
3. Big Data Characteristics
- volume:Volume is the big data dimension that relates to the sheer size of big data.
- velocity:Velocity refers to the increasing speed at which big data is created and the increasing speed at which the data needs to be stored and analyzed.
- variety:includes structured data in the form of financial transactions, semi-structured data in the form of emails and unstructured data in the form of images.
- veracity:Veracity refers to the quality or fidelity of data.(Reliability,Accuracy)
- value:intuitively related to the veracity characteristic in that the higher the data fidelity, the more value it holds for the business.
4. Different Types of Data
- Structured Data:banking transactions, invoices, and customer records
- Unstructured Data:media files that contain image, audio or video data.
- Semi-structured Data:XML and JSON files(hierarchical or graph-based)
- Metadata:XML tags providing the author and creation date of a document OR attributes providing the file size and resolution of a digital photograph
5. Considerations of Big Data
- Privacy
- Security:authentication and authorization mechanisms;data access levels
- Provenance:source of the data and how it has been processed
- Distinct Performance Challenges:long query times;network bandwidth
- Distinct Methodology:e.g., an iterative approach may be used to enable business personnel to provide IT personnel with feedback on a periodic basis.
6. Categories of Analytics
- descriptive analytics:It summarizes and highlights patterns in current and historical data.
- diagnostic analytics:the process of using data to determine the causes of trends and correlations between variables.
- predictive analytics:a branch of advanced analytics that makes predictions about future events, behaviors, and outcomes
- prescriptive analytics:a form of data analytics that uses past performance and trends to determine what needs to be done to achieve future goals.
7. Big Data Analytics Life Cycle(*Important!)
- Business Case Evaluation
- Data Identification:identifying the datasets required for the analysis project and their sources.
- Data Acquisition & Filtering:Metadata can be added via automation to data from both internal and external data sources to improve the classification and querying.
- Data Extraction:转换过滤格式和数据
- Data Validation & Cleansing:via an offline ETL operation in batch analytics
- Data Aggregation & Representation:integrating multiple datasets
- Data Analysis
- Data Visualization
- Utilization of Analysis Results:encapsulate new insights and understandings about the nature of the patterns and relationships that exist within the data.
Week2
Topic:Big Data Analytics
Types of Analysis
- quantitative analysis
- qualitative analysis
- data mining
- statistical analysis
- machine learning:Clustering, Classification, ….
- semantic analysis
- visual analysis
1. Quantitative Analysis
- Quantitative analysis is a data analysis technique that focuses on quantifying the patterns and correlations found in the data.
- Quantitative analysis produces numerical results.
2. Qualitative Analysis
- Qualitative analysis is a data analysis technique that focuses on describing various data qualities using words.
- The output of qualitative analysis is a description of the relationship using words
3. Data Mining
- Data mining is a specialized form of data analysis that targets large datasets.
- Data mining forms the basis for predictive analytics and business intelligence (BI).
4. Statistical Analysis
- Statistical analysis uses statistical methods based on mathematical formulas as a means for analyzing data
- Statistical analysis is most often quantitative.
- It can also be used to infer patterns and relationships within the dataset, such as regression and correlation.
• A/B Testing • Correlation • Regression • Filtering
5. Classification
Common basic classification algorithms • kNN • Decision tree • Naïve bayes
6. Semantics Analytics
• Natural Language Processing • Text Analytics • Sentiment Analysis
7. Visual Analysis
• Heat Maps • Time Series Plots • Network Graphs • Spatial Data Mapping Heat
Week3
Topic: Big Data Processing & Big Data Technology
1. Parallel & Distributed Data Processing
- Parallel data processing can be achieved through multiple networked machines. It is more typically achieved within the confines of a single machine with multiple processors or cores.
- However, distributed data processing is always achieved through physically separate machines that are networked together as a cluster.
2. Hadoop
- Enable Scalability:Hadoop provides scalability to store large volumes of data on commodity hardware.
- Handle Fault Tolerance:Hadoop has the ability to gracefully recover from these problems.
- Optimized for a Variety Data Types:Hadoop ecosystem has the ability to handle these different data types.
- Facilitate a Shared Environment:Hadoop ecosystem has the ability to facilitate a shared environment.
- Provide Value:The ecosystem includes a wide range of open source projects backed by a large active community.
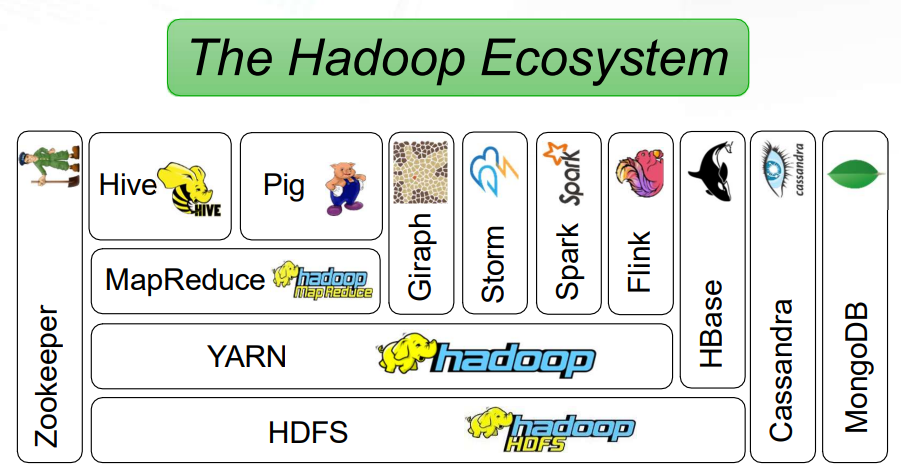
3. MapReduce
- Each MapReduce job is composed of a map task and a reduce task and each task consists of multiple stages.
- This diagram shows the map and reduce task, along with their individual stages.
- Map tasks • map • combine (optional) • partition
- Reduce tasks • shuffle and sort • reduce
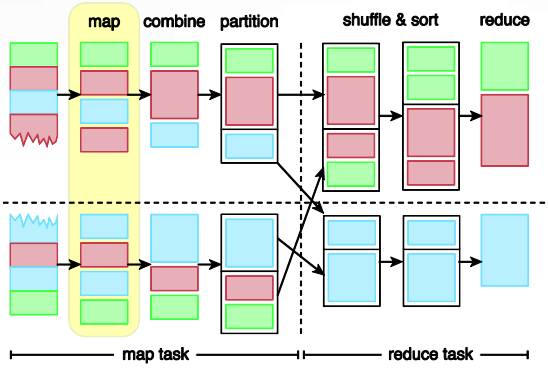
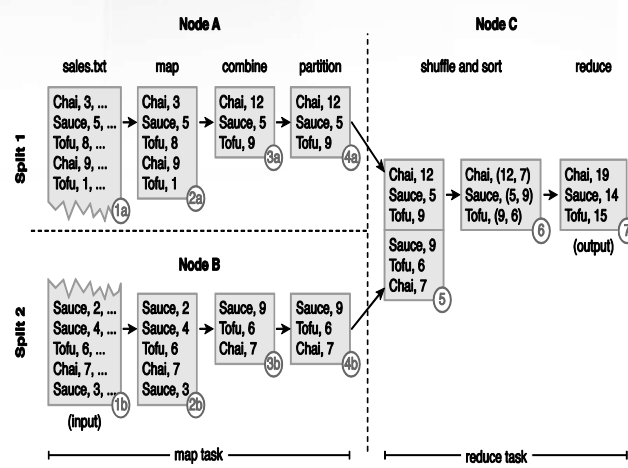
MapReduce works on the principle of divide-andconquer which uses one of the following approaches:
- Task Parallelism – Task parallelism refers to the parallelization of data processing by dividing a task into sub-tasks and running each sub-task on a separate processor, generally on a separate node in a cluster.
- Data Parallelism – Data parallelism refers to the parallelization of data processing by dividing a dataset into multiple datasets and processing each sub-dataset in parallell.
4. Spark
- The Spark Core - core capability is of the Spark Framework are implemented. - support for distributed scheduling, memory management and full tolerance.
- Spark SQL is the component of Spark that provides querying structured and unstructured data through a common query language.
- Spark Streaming is where data manipulations take place in Spark.
- MLlib is Sparks native library for machine learning algorithms as well as model evaluation.
- GraphX is the graph analytics library of Spark

4.1 Resilient Distributed Datasets (RDD)
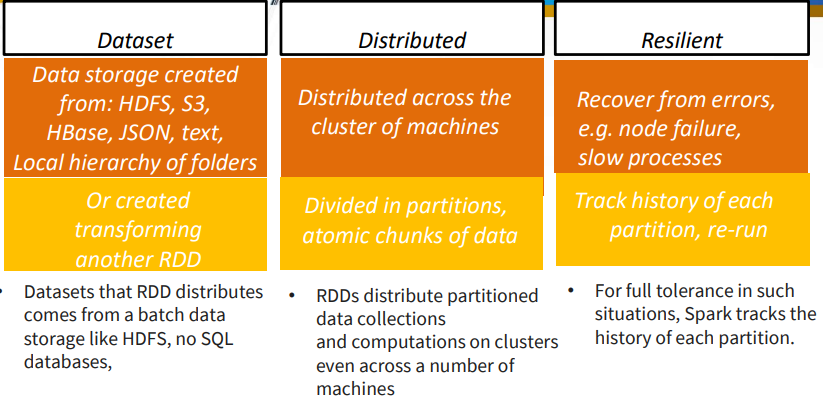
5. File Systems and Distributed File Systems
- A cluster is a tightly coupled collection of servers, or nodes. These servers usually have the same hardware specifications and are connected together via a network to work as a single unit
- A file system is the method of storing and organizing data on a storage device. A file system provides a logical view of the data stored on the storage device and presents it as a tree structure of directories and files.
- A distributed file system is a file system that can store large files spread across the nodes of a cluster.
5.1 RDBMS Databases
Relational database management systems (RDBMSs) are good for handling transactional workloads involving small amounts of data with random read/write properties.
The use of the application logic to join data retrieved from multiple shards.
- A user requests multiple records (id = 1, 3) and the application logic is used to determine which shards need to be read.
- It is determined by the application logic that both Shard A and Shard B need to be read.
- The data is read and joined by the application.
- Finally, the data is returned to the user.
5.2 NoSQL
- A Not-only SQL (NoSQL) database is a nonrelational database that is highly scalable, faulttolerant and specifically designed to house semi-structured and unstructured data.
- NoSQL refers to technologies used to develop next generation nonrelational databases that are highly scalable and fault-tolerant
- A NoSQL database often provides an API-based query interface that can be called from within an application.
- NoSQL databases also support query languages other than Structured Query Language (SQL) because SQL was designed to query structured data stored within a relational database.
5.3 Sharding(分区)
- Sharding is the process of horizontally partitioning a large dataset into a collection of smaller, more manageable datasets called shards.
- The shards are distributed across multiple nodes, where a node is a server or a machine
- Each shard is stored on a separate node and each node is responsible for only the data stored on it.
- Each shard shares the same schema, and all shards collectively represent the complete dataset.
- A benefit of sharding is that it provides partial tolerance toward failures. In case of a node failure, only data stored on that node is affected.
5.4 Replication
- Replication stores multiple copies of a dataset, known as replicas, on multiple nodes
- Replication provides scalability and availability due to the fact that the same data is replicated on various nodes.
- Fault tolerance is also achieved since data redundancy ensures that data is not lost when an individual node fails.
- Two methods to implement replication: • master-slave • peer-to-peer
5.5 Master-Slave
- During master-slave replication, nodes are arranged in a master-slave configuration, and all data is written to a master node.
- Once saved, the data is replicated over to multiple slave nodes.
- All external write requests, including insert, update and delete, occur on the master node, whereas read requests can be fulfilled by any slave node.
5.6 Peer-to-Peer
- With peer-to-peer replication, all nodes operate at the same level. There is not a master-slave relationship between the nodes. Each node, peer, is equally capable of handling reads and writes. Each write is copied to all peers
- Peer-to-peer replication is prone to write inconsistencies that occur as a result of a simultaneous update of the same data across multiple peers.
- This can be addressed by implementing either a pessimistic or optimistic concurrency strategy.
6. The Hadoop Distributed File System (HDFS)
- HDFS achieves scalability by partitioning or splitting large files across multiple computers.
- This allows parallel access to very large files since the computations run in parallel on each node where the data is stored.
7. In-Memory Storage Devices
- An in-memory storage device generally utilizes RAM, the main memory of a computer, as its storage medium to provide fast data access.
- The growing capacity and decreasing cost of RAM, coupled with the increasing read/write speed of solid state hard drives, has made it possible to develop in-memory data storage solutions
- Storage of data in memory eliminates the latency of disk I/O and the data transfer time between the main memory and the hard drive.
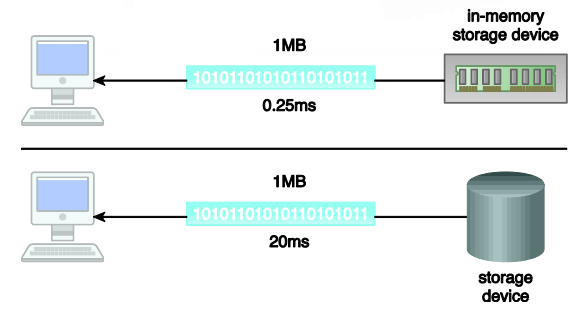
- An in-memory storage device enables in-memory analytics, which refers to in-memory analysis of data.
- A Big Data in-memory storage device is implemented over a cluster, providing high availability and redundancy.
- Therefore, horizontal scalability can be achieved by simply adding more nodes or memory.
- In-memory storage devices can be implemented as: • In-Memory Data Grid (IMDG) • In-Memory Database (IMDB)
Week4
Topic: The Security Big Picture – Privacy and Security in Big Data
1. Dealing with Big Data Analytics (Scalability, Reliability and Performance)
1.1 Cluster and Cloud Computing Architecture
- Private Cloud (On-Premise)
- Public Cloud
- Hybrid Cloud
- Virtual Private Cloud (Not, On-Premise)
1.2 Cloud Computing Model
- Infrastructure as a Service (IaaS)
- Platform as a Service (PaaS)
- Software as a Service (SaaS)
- Others
2. Dealing with Big Data Analytics (Privacy, Security and Governance)
- Confidentiality, Integrity, Availability (CIA) and beyond • Database Scenario • Big Data Scenario
- PII (Personally Identifiable Information)
3. Security Goals
- Confidentiality:Only those who are authorized have access to specific assets and that those who are unauthorized are actively prevented from obtaining access. (both at rest and in-transit)
- Integrity:Ensuring that data has not been tampered with and, therefore, can be trusted. It is correct, authentic, and reliable.
- Availability:Availability means that networks, systems, and applications are up and running. It ensures that authorized users have timely, reliable access to resources when they are needed.
4. Beyond CIA – AAA and Non-repudiation
- Authentication:Authentication involves a user providing information about who they are. Users present login credentials that affirm they are who they claim.
- Authorization:Authorization follows authentication. During authorization, a user can be granted privileges to access certain assets (areas of a network or system, etc.).
- Accounting:Accounting keeps track of user activity while users are logged in to a network by tracking information such as how long they were logged in, the data they sent or received, their Internet Protocol (IP) address, the Uniform Resource Identifier (URI) they used, and the different services they accessed. Useful for Auditing.
- Non-Repudiation:Assurance that the sender of information is provided with proof of delivery and the recipient is provided with proof of the sender’s identity, so neither can later deny having processed the information.
5. Encryption
5.1 CONFIDENTIALITY
- Data at rest (data stored on a disk) • Securing Password
- Data in transit (when we are transmitting data from one place to the other)
5.2 Characteristics of Encryption Algorithms
- Efficient: It must minimize the amount of memory and time required to run it.
- Reliable: We can have 2 ways to ensure the eavesdropper can not decrypt the data without the decryption key:
Make the algorithm secret. The opponent does not know how to decrypt the data. The keys further protects it.
Make the algorithm public. The opponent knows how to decrypt the data but has no known weaknesses and the only way to decrypt the data is to try all possible keys. This types of attacks are known as “brute force” attacks.
6. Cryptographic Protocols
- Messages should be transmitted to destination
- Only the recipient should see it
- Only the recipient should get it
- Proof of the sender’s identity
- Message shouldn’t be corrupted in transit
- Message should be sent/received once only
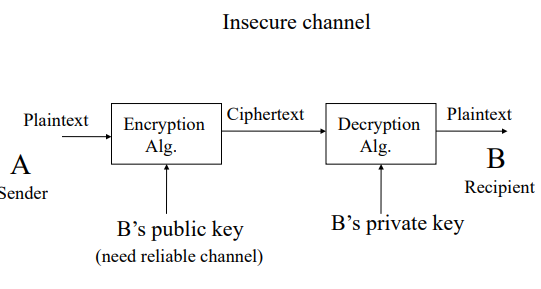
7. Conventional Encryption Principles
An encryption scheme has five ingredients:
- Plaintext (P):a message in its original form
- Encryption algorithm (E)
- Secret Key (K)
- Ciphertext (C):an encrypted message
- Decryption algorithm (D)
7.1 Symmetric Encryption 对称加密
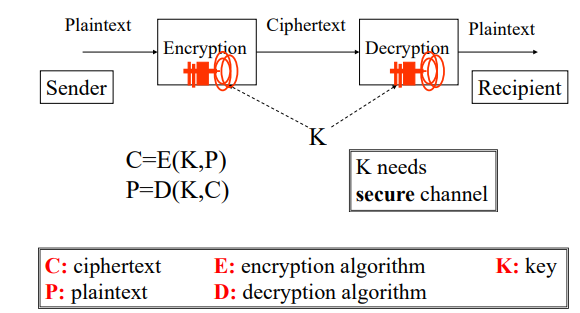
7.2 Asymmetric Encryption 非对称加密

8. Key Management Challenges
- Symmetric vs. Asymmetric
- How many keys?
- How to exchange the keys securely
8.1 Diffie-Hellman Key Exchange Protocol 密钥交换算法

缺点:没有提供双方身份的任何信息. 它是计算密集性的,因此容易遭受阻塞性攻击,即对手请求大量的密钥.受攻击者花费了相对多的计算资源来求解无用的幂系数而不是在做真正的工作. 没办法防止重演攻击. 容易遭受中间人的攻击
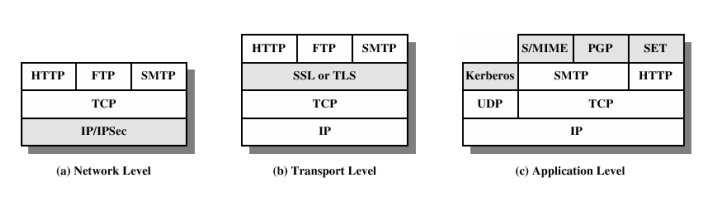
9. SSL (Secure Socket Layer)
由非对称加密获得对称密钥
- Server sends a copy of its asymmetric public key.
- Browser creates a symmetric session key and encrypts it with the server’s asymmetric public key.
- Server decrypts the asymmetric public key with its asymmetric private key to get the symmetric session key.
- Server and Browser now encrypt and decrypt all transmitted data with the symmetric session key. This allows for a secure channel because only the browser and the server know the symmetric session key, and the session key is only used for that session. If the browser was to connect to the same server the next day, a new session key would be created.
10. Public Key Infrastructure (PKI) 公钥基础设施
A PKI consist of programs, protocols, procedures, public key encryption mechanisms, database, data formats. This comprehensive structure allow people to communicate in a secure and predictable manner.
Based on 2 main aspects:
- Public key cryptology
- X.509 standard protocols.
The security services it provides are:
- Authentication
- Confidentiality
- Integrity
- Non-repudiation
To be part of a PKI a user or service needs a “Digital Certificate”. 数字证书证明身份
The digital certificate contains the credential of the entity, identifying information and its public key. The certificate was signed by a trusted third party called the “Certificate Authority” (CA)
PKI is used as foundation for other applications such as: /MIME, IPSec, SSL/TLS, and SET.
PKI Limitations: just depends on user ID and pass phrase; CA trustable or not
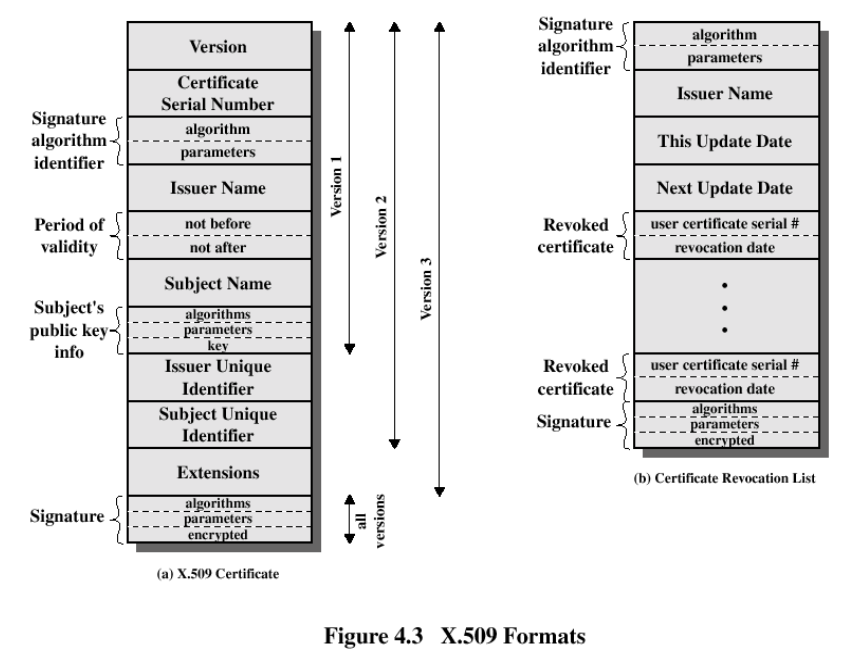
11. Public v.s. Private CA
Private CA Advantages:
- No need to spend annual $$ for renewal.
- Can generate large number of certificates at little/no additional costs.
Public CA Advantages:
- Will be recognized as valid by all Internet Users.
- No need to support CA servers internally.
- No need to manage registration of users and certificate revocation internally.
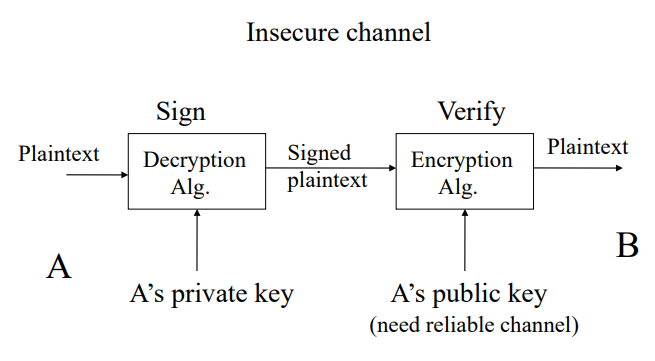
12. Digital Signatures
A digital signature is a technology that is used to verify the authenticity of a specific digital document, message, or transaction. It provides the recipient with a guarantee that the message was created by the sender and has not been modified by a third party.
13. Digital certificates
Digital certificates work in the same way as ID cards, such as passports and driving licenses. Government issue digital certificates. When someone requests it, the authority checks the identity of the requesting person, certifies that it meets all the requirements for obtaining the certificate, and then issues it.
Digital Certificate contains:
- Name of the certificate holder.
- Serial number which is used to uniquely identify a certificate, the individual or the entity identified by the certificate
- Expiration dates.
- Copy of certificate holder’s public key. (used for decrypting messages and digital signatures)
- Digital Signature of the certificate-issuing authority
14. Cryptographic Hash Functions (Addressing Data Integrity)
14.1 Hash Function
Properties of a HASH function H:
- H can be applied to a block of data at any size
- H produces a fixed length output
- H(x) is easy to compute for any given x.
- For any given value h, it is computationally infeasible to find x such that H(x) = h
- For any given block x, it is computationally infeasible to find with H(y) = H(x).
- It is computationally infeasible to find any pair (x, y) such that H(x) = H(y)
哈希加密算法没有 authentication services
Goal: we want the sender to create a hash based on the message and some other information that will prove that the legitimate sender is actually the one that create the hash and that the message or hash was not modified in transit.
These services will be provided by a Message Authentication Code (MAC), Authentication and Key Agreement (AKA), and Hash Message Authentication Code (HMAC).
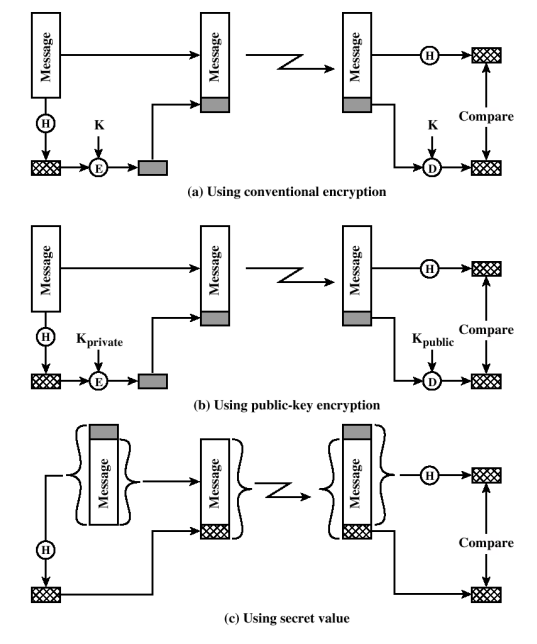
14.2 Message Authentication Code
3 popular solutions:
- Conventional Encryption. If 2 parties share an encryption key: the sender can encrypt the hash and send it. The receiver then decrypts it and recalculate the message hash. If it matches: it proves that the party that possessed the encryption key created the message and the hash. 非对称加密哈希序列
- Asymmetric Encryption. Same idea but the sender uses his private key to encrypt the hash. The receiving party uses the sender’s public key to decrypt the hash and verify it.
- Shared Secret Value. Add a “shared secret” to the message, calculate the hash on (message || shared secret) then send message and hash. The receiver can only check the hash if he has the shared secret. Advantage: faster than encryption.
15. Countermeasures: Defense in Depth or Multi-layer Security Principle
Layering security defences in an application can reduce the chance of a successful attack. Incorporating redundant security mechanisms requires an attacker to circumvent each mechanism to gain access to a digital asset.
For example, a software system with authentication checks may prevent an attacker that has subverted a firewall. Defending an application with multiple layers can prevent a single point of failure that compromises the security of the application.
- Least Privilege and Need to Know
- Separation of Duties and Job Rotation
- Acceptable Use Policy
16. Threat, Vulnerability, Risk
A computer based system has three separated but valuable components: hardware, software, and data.
- Threat: potential occurrence that can have an undesired effect on the system. – a set of circumstances that has the potential to cause loss or harm.
- Vulnerability: characteristics of the system that makes is possible for a threat to potentially occur. – a weakness in the security system that could be exploited to cause harm or loss.
- Risk: measure of the possibility of security breaches and severity of the damage
Week5
Topic: Kerberos and other Application Layer Security Protocol
1. Outline
Centralized Authentication
– Kerberos – RADIUS – TACACS+
Terminal access: SSH

2. Application Layer Security
2.1 Application Layer
- Provides services for an application to send and recieve data over the network, e.g., telnet (port 23), mail (port 25)
- Interface to the transport layer:Operating system dependent, Socket interface
2.2 Advantages
- Executing in the context of the user:easy access to user’s credentials
- Complete access to data:easier to ensure nonrepudation and small security granularity
- Application-based security
2.3 Disadvantages
- Implemented in end hosts
- Need for each application:Expensive; Greater probability of making mistake
3. Centralized Authentication
Centralized server maintains all authorizations for users regardless of where user is located and how user connects to network
Most common methods:
- Kerberos
- RADIUS (Remote Authentication Dial-In User Service)
- TACACS+ (Terminal Access Controller Access Control System)
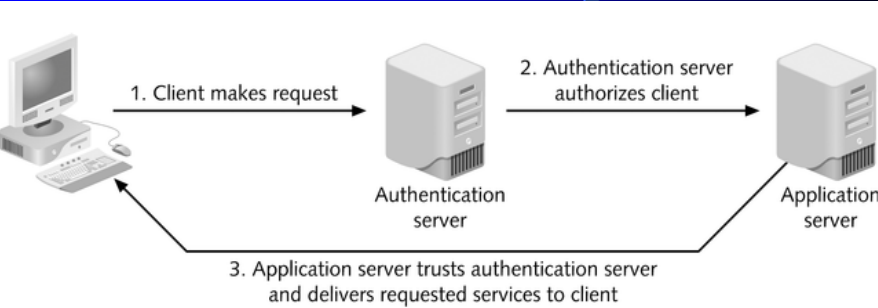
4. Kerberos
4.1 Overview
- Key benefit of Kerberos: it can provide a single sign-on system for distributed and heterogeneous environments.
- Based on symmetric crypto key and provide end- to-end security. Passwords are never transmitted. 对称密钥
4.2 Kerberos Authentication
Assume an open distributed environment in which users at workstations wish to access services on servers distributed throughout the network
- Servers should be able to restrict access to authorized users and
- Servers should be able to authenticate requests for services
- Servers should be able to provide Single Sign On (SSO)
4.3 Kerberos Threats
- A User gains access to workstation and pretends to be another user operating from that workstation
- A User may alter the network address of a workstation so that the requests form the altered workstation appear to come from the impersonated workstation.
- A User may eavesdrop on exchanges and use a replay attack to gain access to a server or to disrupt operation.
4.4 Requirements
- Secure (Inability for an intruder to impersonate a user or eavesdrop)
- Reliable (Via distributed architecture)
- Transparent (User and applications should not be aware of it).
- Scalable (Again via distributed architecture)
- Trusted Third Party authentication service
4.5 Kerberos Authentication Environment
A full-service Kerberos environment consists of:
- A number of application servers which provide services
- A number of clients which request for services
- Kerberos server(s) (KS) :
– The KS has users’ IDs and hashed passwords
– The KS shares a secret key with each application server
– All application servers are registered with KS
4.6 Kerberos Components
- Key Distribution Center (KDC) – Authentication server (AS) – Ticket-granting server (TGS)
- Database: users’ identifiers + secret key shared between KDC and user
- Need physical security
4.7 Ticketing System
KDC issues tickets that clients and servers can use to mutually authenticate themselves and agree on shared secrets.
Ticket: – Session key – Name of principal – Expiration time
Ticket types:
- Ticket-granting ticket: issued by AS and used between client and TGS
- Service ticket: issued by TGS and used between client and server
4.8 Kerberos Principals
- Authentication Server (AS) – mutually authenticating with client at login based on longterm key. AS gives client a ticket- granting ticket and short-term key.
- Ticket Granting Server (TGS) – mutually authenticating with client based on short-term key and ticket-granting ticket. TGS then issues tickets giving clients access to further servers demanding authentication.
4.9 Kerberos Issues
- Revocation: ticket granting tickets valid until they expire, typically 10 hours.
- Within realms (domains): long-term keys need to be established between AS and TGS, TGS and Servers and AS and clients.
- Synchronous clocks needed, protected against attacks. Cache of recent messages to protect against replay within clock skew
- Need for on-line AS and TGS, trusted by clients not to eavesdrop.
- Client-AS long-term key often still based on password entry – vulnerable to guessing.
- Short-term keys and ticket-granting tickets located on largely unprotected client hosts.
- Single point of failure* (though this can be made redundant)
- KDC must be scalable
- Secret keys are stored on the workstation, if you can get these keys, you can break things
- Same with session keys
- Traffic is not encrypted if not enabled
4.10 Comparison with SSL

5. Terminal Access: SSH
- Protocols running on top of TCP/IP (Application layer security)
- Security enhanced Telnet
In an enterprise big data deployment, it is preferable that the Hadoop cluster integrates the enterprise Active Directory or Kerberos-based authentication and authorization to enforce IT governance including audit.
推荐论文
- More types and variety of data are stored in BD even before their application and value are fully understood, whereas, under traditional data management, data is often not kept, unless the value and application of the data is foreseen.
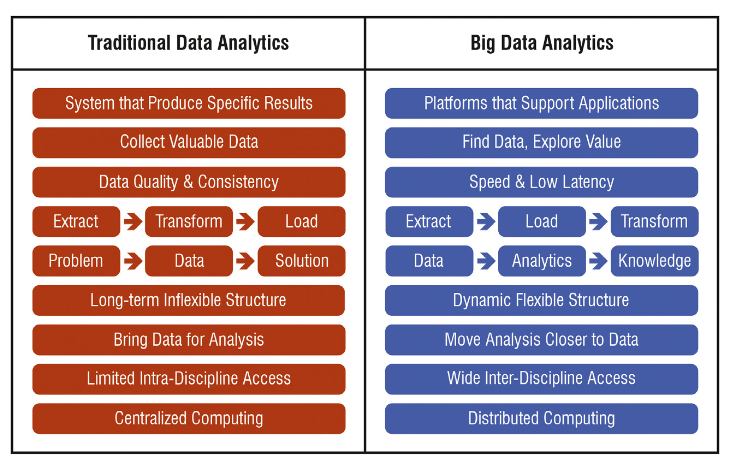
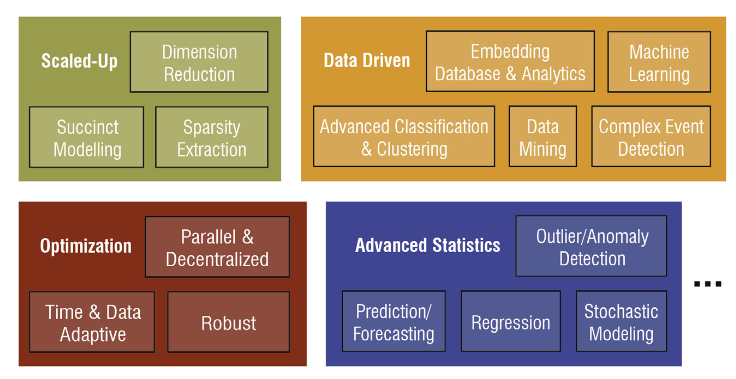
- Broadly speaking, BDA methods aim to achieve a type of enhancement in knowledge or decision, thus, they can be characterized by the intelligence they aim to bring to power industry; these include descriptive, diagnostic, corrective, predictive, prescriptive, adaptive, and distributed analytics
课程版权©限制,禁止搬运转载(大概)
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









