







目录
- 语音合成概述
- 语音信号基础
- 语音特征提取
- 音库制作和文本前端
- 声学模型
- 声码器
一、语音合成概述
语音信号的产生分为两个阶段,信息编码和生理控制。首先在大脑中出现某种想要表达的想法,然后由大脑将其编码为具体的语言文字序列,及语音中可能存在的强调、重读等韵律信息。经过语言的组织,大脑通过控制发音器官肌肉的运动,产生出相应的语音信号。其中第一阶段主要涉及人脑语言处理方面,第二阶段涉及语音信号产生的生理机制。
从滤波的角度,人体涉及发音的器官可以分为两部分:激励系统和声道系统。激励系统中,储存于肺部的空气源,经过胸腔的压缩排出,经过气管进入声带,根据发音单元决定是否产生振动,形成准周期的脉冲空气激励流或噪声空气激励流。这些空气流作为激励,进入声道系统,被频率整形,形成不同的声音。声道系统包括咽喉、口腔(舌、唇、颌和口)组成,可能还包括鼻道。不同周期的脉冲空气流或者噪声空气流,以及不同声道器官的位置决定了产生的声音。因此,语音合成中通常将语音的建模分解为激励建模和声道建模。
1. 语音合成的历史和研究方法
语音合成系统分为两部分,分别称为文本前端和后端。文本前端主要负责在语言层、语法层、语义层对输入文本进行文本分析;后端主要是从信号处理、模式识别、机器学习等角度,在语音层面上进行韵律特征建模,声学特征建模,然后进行声学预测或者在音库中进行单元挑选,最终经过合成器或者波形拼接等方法合成语音。


根据语音合成研究的历史,语音合成研究方法可以分为:机械式语音合成器、电子式语音合成器、共振峰参数合成器、基于波形拼接的语音合成(Concatenative Speech Synthesis)、统计参数语音合成(Statistical Parametric Speech Synthesis,SPSS)、以及神经网络语音合成。
早期的语音合成方法由于模型简单,系统复杂等原因,难以在实际场景应用。随着计算机技术的发展,基于波形拼接的语音合成被提出。基于波形拼接的语音合成 Concatenative Speech Synthesis的基本原理是首先构建一个音库,在合成阶段,通过对合成文本的分析,按照一定的准则,从音库中挑选出与待合成语音相似的声学单元,对这些声学单元进行少量调整,拼接得到合成的语音。早期的波形拼接系统受限于音库大小、挑选算法、拼接调整的限制,合成语音质量较低。1990年,基于同步叠加的时域波形修改算法被提出,解决了声学单元拼接处的局部不连续问题。更进一步,基于大语料库的波形拼接语音合成方法被提出,采用更精细的挑选策略,将语音音库极大地拓展,大幅提升了合成语音的自然度。由于直接使用发音人的原始语音,基于波形拼接的语音合成方法合成语音的音质接近自然语音,被广泛应用。但其缺点也较为明显,包括音库制作时间长、需要保存整个音库、拓展性差、合成语音自然度受音库和挑选算法影响,鲁棒性不高等。
随着统计建模理论的完善,以及对语音信号理解的深入,基于统计参数的语音合成方法(Statistical Parametric Speech Synthesis,SPSS)被提出。其基本原理是使用统计模型,对语音的参数化表征进行建模。在合成阶段,给定待合成文本,使用统计模型预测出对应的声学参数,经过声码器vocoder合成语音波形。统计参数语音合成方法是目前的主流语音合成方法之一。统计参数音合成方法的优点很多,包括只需要较少的人工干预,能够快速地自动构建系统,同时具有较强的灵活性,能够适应不同发音人,不同发音风格,多语种的语音合成,具有较强的鲁棒性等。由于语音参数化表示以及统计建模的平均效应,统计参数语音合成方法生成的语音自然度相比自然语音通常会有一定的差距。基于隐马尔科夫HMM的统计参数语音合成方法是发展最为完善的一种。基于HMM的统计参数语音合成系统能够同时对语音的基频、频谱和时长进行建模,生成出连续流畅且可懂度高的语音,被广泛应用,但其合成音质较差。
和统计参数语音合成系统类似,深度学习语音合成系统也可大致分为两个部分:文本前端和声学后端。文本前端的主要作用是文本预处理,如:为文本添加韵律信息,并将文本词面转化为语言学特征序列(Linguistic Feature Sequence);声学后端又可以分为声学特征生成网络和声码器,其中声学特征生成网络根据文本前端输出的信息产生声学特征,如:将语言学特征序列映射到梅尔频谱Mel 或线性谱;声码器利用频谱等声学特征,生成语音样本点并重建时域波形,如:将梅尔频谱恢复为对应的语音。近年来,也出现了完全端到端的语音合成系统,将声学特征生成网络和声码器和合并起来,声学后端成为一个整体,直接将语言学特征序列,甚至文本词面端到端转换为语音波形。
2. 语音合成各部分
2.1. 文本前端
文本前端的作用是从文本中提取发音和语言学信息,其任务至少包括以下四点。
(a). 文本正则化
在语音合成中,用于合成的文本存在特殊符号、阿拉伯数字等,需要把符号转换为文本。如“1.5 元” 需要转换成“一点五元”,方便后续的语言学分析。
(b). 韵律预测
该模块的主要作用是添加句子中韵律停顿或起伏。如“在抗击新型冠状病毒的战役中,党和人民群众经受了一次次的考验”,如果停顿信息不准确就会出现:“在/抗击/新型冠状病毒/的/战役中,党/和/人民群众/经受了/一次/次/的/考验”。“一次次”的地方存在一个错误停顿,这将会导致合成语音不自然,如果严重些甚至会影响语义信息的传达。
(c). 字形转音素
文字转化为发音信息。比如“中国”是汉字表示,需要先将其转化为拼音“zhong1 guo2”,以帮助后续的声学模型更加准确地获知每个汉字的发音情况。
(d). 多音字和变调
许多语言中都有多音字的现象,比如“模型”和“模样”,这里“模”字的发音就存在差异。另外,汉字中又存在变调现象,如“一个”和“看一看”中的“一”发音音调不同。所以在输入一个句子的时候,文本前端就需要准确判断出文字中的特殊发音情况,否则可能会导致后续的声学模型合成错误的声学特征,进而生成不正确的语音。
2.2. 声学特征生成网络 Acoustic model
声学特征生成网络根据文本前端的发音信息,产生声学特征,如梅尔频谱或线性谱。近年来,基于深度学习的生成网络甚至可以去除文本前端,直接由英文等文本生成对应的频谱。但是一般来说,因为中文字形和读音关联寥寥,因此中文语音合成系统大多无法抛弃文本前端,换言之,直接将中文文本输入到声学特征生成网络中是不可行的。基于深度学习的声学特征生成网络发展迅速,比较有代表性的模型有Tacotron系列,FastSpeech系列等。近年来,也涌现出类似于VITS的语音合成模型,将声学特征生成网络和声码器融合在一起,直接将文本映射为语音波形。
2.3. 声码器 Vocoder
通过声学特征产生语音波形的系统被称作声码器,声码器是决定语音质量的一个重要因素。一般而言,声码器可以分为以下4类:纯信号处理,如Griffin-Lim、STRAIGHT和WORLD;自回归深度网络模型,如WaveNet和WaveRNN;非自回归模型,如Parallel WaveNet、ClariNet和WaveGlow;基于生成对抗网络(Generative Adversarial Network,GAN)的模型,如MelGAN、Parallel WaveGAN和HiFiGAN。
3. 语音合成评价指标
对合成语音的质量评价,主要可以分为主观和客观评价。主观评价是通过人类对语音进行打分,比如平均意见得分(Mean Opinion Score,MOS)、众包平均意见得分(CrowdMOS,CMOS)和ABX测试。客观评价是通过计算机自动给出语音音质的评估,在语音合成领域研究的比较少,论文中常常通过展示频谱细节,计算梅尔倒谱失真(Mel Cepstral Distortion,MCD)等方法作为客观评价。客观评价还可以分为有参考和无参考质量评估,这两者的主要判别依据在于该方法是否需要标准信号。有参考评估方法除了待评测信号,还需要一个音质优异的,可以认为没有损伤的参考信号。常见的有参考质量评估主要有ITU-T P.861 (MNB)、ITU-T P.862 (PESQ)、ITU-T P.863 (POLQA)、STOI和BSSEval。无参考评估方法则不需要参考信号,直接根据待评估信号,给出质量评分,无参考评估方法还可以分为基于信号、基于参数以及基于深度学习的质量评估方法。常见的基于信号的无参考质量评估包括ITU-T P.563和ANIQUE+,基于参数的方法有ITU-T G.107(E-Model)。近年来,深度学习也逐步应用到无参考质量评估中,如:AutoMOS、QualityNet、NISQA和MOSNet。
主观评价中的MOS评测是一种较为宽泛的说法,由于给出评测分数的主体是人类,因此可以灵活测试语音的不同方面。比如在语音合成领域,主要有自然度MOS(MOS of Naturalness)和相似度MOS(MOS of Similarity)。但是人类给出的评分结果受到的干扰因素较多,谷歌对合成语音的主观评估方法进行了比较,在评估较长语音中的单个句子时,音频样本的呈现形式会显著影响参与人员给出的结果。比如仅提供单个句子而不提供上下文,与相同句子给出语境相比,被测人员给出的评分差异显著。国际电信联盟(International Telecommunication Union,ITU)将MOS评测规范化为ITU-T P.800,其中绝对等级评分(Absolute Category Rating,ACR)应用最为广泛,ACR的详细评估标准有5.0-1.0从优到劣。
在使用ACR方法对语音质量进行评价时,参与评测的人员(简称被试)对语音整体质量进行打分,分值范围为1~5分,分数越大表示语音质量越好。MOS大于4时,可以认为该音质受到大部分被试的认可,音质较好;若MOS低于3,则该语音有比较大的缺陷,大部分被试并不满意该音质。
二、语音信号基础
1. 语音基本概念
声波通过空气传播,被麦克风接收,通过 采样、量化、编码转换为离散的数字信号,即波形文件。音量、音高和音色是声音的基本属性。
1.1 能量
音频的能量通常指的是时域上每帧的能量,幅度的平方。在简单的语音活动检测(Voice Activity Detection,VAD)中,直接利用能量特征:能量大的音频片段是语音,能量小的音频片段是非语音(包括噪音、静音段等)。这种VAD的局限性比较大,正确率也不高,对噪音非常敏感。
1.2 短时能量
短时能量体现的是信号在不同时刻的强弱程度。设第 n 帧语音信号的短时能量用 表示,则其计算公式为:
上式中, 为帧长,
为该帧中的样本点。
1.3 声强和声强级 sound intensity或acoustic intensity
单位时间内通过垂直于声波传播方向的单位面积的平均声能,称作声强,声强用 I 表示,单位为“瓦/平米”。实验研究表明,人对声音的强弱感觉并不是与声强成正比,而是与其对数成正比,所以一般声强用声强级来表示:
其中,I为声强, 称为基本声强,声强级的常用单位是分贝(dB)。
1.4 响度 loudness
响度是一种主观心理量,是人类主观感觉到的声音强弱程度,又称音量。响度与声强和频率有关。一般来说,声音频率一定时,声强越强,响度也越大。相同的声强,频率不同时,响度也可能不同。响度若用对数值表示,即为响度级,响度级的单位定义为方,符号为phon。根据国际协议规定,0dB声强级的1000Hz纯音的响度级定义为0 phon,n dB声强级的1000Hz纯音的响度级就是n phon。其它频率的声强级与响度级的对应关系要从如图等响度曲线查出。

1.5 过零率
过零率体现的是信号过零点的次数,体现的是频率特性。
其中, 表示帧数,
表示每一帧中的样本点个数,
为符号函数,即
1.6 共振峰 Formant
声门处的准周期激励进入声道时会引起共振特性,产生一组共振频率,这一组共振频率称为共振峰频率或简称共振峰。共振峰包含在语音的频谱包络中,频谱包络的局部极大值就是共振峰。频率最低的共振峰称为第一共振峰,记作$f_1$,频率更高的共振峰称为第二共振峰$f_2$、第三共振峰$f_3$……以此类推。实践中一个元音用三个共振峰表示,复杂的辅音或鼻音,要用五个共振峰。
2. 语言学
语言学研究人类的语言,计算语言学则是一门跨学科的研究领域,试图找出自然语言的规律,建立运算模型,语音合成其实就是计算语言学的子领域之一。在语音合成中,一般需要将文本转换为对应的音素,然后再将音素输入到后端模型中,因此需要为每个语种甚至方言构建恰当合理的音素体系。相关概念如下。
- 音素(phoneme):也称音位,是能够区别意义的最小语音单位,同一音素由不同人/环境阅读,可以形成不同的发音。
- 字素(grapheme):音素对应的文本。
- 发音(phone): 某个音素的具体发音。实际上,phoneme和phone都是指的是音素,音素可具化为实际的音,该过程称为音素的语音体现。一个音素可能包含着几个不同音值的音,因而可以体现为一个音、两个音或更多的同位音。但是在一些论述中,phoneme偏向于表示发音的符号,phone更偏向于符号对应的实际发音,因此phoneme可对应无数个phone。
- 音节(syllable):音节由音素组成。在汉语中,除儿化音外,一个汉字就是一个音节。如wo3(我)是一个音节,zhong1(中)也是一个音节。
3. 音频格式/文件
PCM 脉冲编码调制(Pulse-code modulation)是一种模拟信号的数字化方法。 PCM将信号的强度依照同样的间距分成数段,然后用独特的数字记号(通常是二进制)来量化。使用了模数转换ADC,其得到的结果就是声波数据的采样数据,是一个整数序列,每个整数表示声波的振幅值。
由于采样率比较大,一般每秒几万个点,所以PCM数据是比较大。实际应用中往往会对其进行压缩,比如MP3等等,就是对PCM的一种压缩后的结果。
音频压缩:音频压缩(区别于动态压缩)属于数据压缩的一种,用以减少音频流媒体的传输带宽需求与音频档案的存储大小。按压缩方法可以分为无损压缩和有损压缩。
得到音频采样的整数数据序列后,就需要存储在一个文件中,最常用的文件格式是WAV。
- *.wav: 波形无损压缩格式,是语音合成中音频语料的常用格式,主要的三个参数:采样率,量化位数和通道数(pcm音频流的一些信息)。一般来说,合成语音的采样率采用16kHz、22050Hz、24kHz,对于歌唱合成等高质量合成场景采样率可达到48kHz;量化位数采用16bit;通道数采用1.
- *.flac: Free Lossless Audio Codec,无损音频压缩编码。
- *.mp3: Moving Picture Experts Group Audio Player III,有损压缩。
- *.wma: Window Media Audio,有损压缩。
- *.avi: Audio Video Interleaved,avi文件将音频和视频包含在一个文件容器中,允许音视频同步播放。

4. 数字信号处理
4.1. 模数转换 Analog to Digital Converter,ADC
模拟信号到数字信号的转换(Analog to Digital Converter,ADC)称为模数转换。
奈奎斯特(Nyquist)采样定理:要从抽样信号中无失真地恢复原信号,抽样频率应大于2倍信号最高频率。抽样频率小于2倍频谱最高频率时,信号的频谱有混叠。抽样频率大于2倍频谱最高频率时,信号的频谱无混叠。如果对语音模拟信号进行采样率为16000Hz的采样,得到的离散信号中包含的最大频率为8000Hz。
模拟信号 到 数字信号转换 (analog-to-digital conversion,A/D转化,模数转换)的过程分为两步:
- 采样/抽样 sampling
- 量化 quantization:把实数值表示为整数的过程
声波是时间上的连续变化,而计算机只能处理离散数据,是无法记录和处理连续值的。 解决方法就是每隔固定时间(很短)从记录当前波形的幅值并记录下,就把连续值进行了离散化,这个过程就是抽样,每秒钟采集的样本点数称为采样率。

量化位数:
声音采集卡通过采集到声波幅值是实数值,这个实数值是某个区间内[-m,m]之间的连续值,通过采样得到一个个离散的点, 但这些离散点的值是实数值,需要把实数值数转换成整数,整数再转换成二进制进行存储,存储二进制时的位数就是量化位数。 比如用10位(10bit)、16位(16bit)、20位(20bit)、24位(24bit)、32位(32bit)等等进行存储。
实数值转换为离散值的方法就是,把实数区间[-m,m](无穷个值)映射到一个整型区间[-n,n](加上0,一共有2n+1个值), 实数区间[-m,m]分割成2n+1个子区间,对应子区间的整数作为映射输出值。
整型数的位数多少影响着保存数据的精度,位数越多能存储整数区间也就越大,能表示的实数精度就越高,录制和回放的声音就越真实。
通常市面上是这样说,16bit/24bit/32bit。数值越高声音越好。位数多少决定了n的大小(空间大小)。
比如:
16bit位宽,n值为 2^15−1=32767 (为什么是15而不是16?因为有一位是符号位。为什么减1,因为去掉0),32767 代表最大幅值;
32bit位宽,n值为 2^31−1=2147483647 ,2147483647代表最大幅值。
重点来了 ,32767 和 2147483647 都代表最大幅值,两者对应幅值是一样的。 也就是说不同采样音频数据的幅值不可比较。
位宽越大,精度越高,声音的音质越好。与声音大小(幅值大小)无关
4.2. 频谱泄露 spectral leakage
音频处理中,经常需要利用傅里叶变换将时域信号转换到频域,而一次快速傅里叶变换(FFT)只能处理有限长的时域信号,但语音信号通常是长的,所以需要将原始语音截断成一帧一帧长度的数据块。这个过程叫 信号截断,也叫{ 分帧 frame segmentation}。分完帧后再对每帧做FFT,得到对应的频域信号。FFT是离散傅里叶变换(DFT)的快速计算方式,而做DFT有一个先验条件:分帧得到的数据块必须是整数周期的信号,也即是每次截断得到的信号要求是周期主值序列。
但做分帧时,很难满足 周期截断,因此就会导致 { 频谱泄露}。要解决非周期截断导致的频谱泄露是比较困难的,可以通过 { 加窗}尽可能减少频谱泄露带来的影响。窗类型可以分为汉宁窗、汉明窗、平顶窗等。虽然加窗能够减少频谱泄露,但加窗衰减了每帧信号的能量,特别是边界处的能量,这时加一个合成窗,且overlap-add,便可以补回能量。
4.3. 频率分辨率
频率分辨率是指将两个相邻谱峰分开的能力,在实际应用中是指分辨两个不同频率信号的最小间隔。
三、语音特征提取
原始信号是不定长的时序信号,不适合作为机器学习的输入。因此一般需要将原始波形转换为特定的特征向量表示,该过程称为语音特征提取。
1. 预处理
包括预加重、分帧和加窗。
1.1 预加重 pre-emphasis
语音经过说话人的口唇辐射发出,受到唇端辐射抑制,高频能量明显降低。一般来说,当语音信号的频率提高两倍时,其功率谱的幅度下降约6dB,即语音信号的高频部分受到的抑制影响较大。在进行语音信号的分析和处理时,可采用预加重(pre-emphasis)的方法补偿语音信号高频部分的振幅,在傅里叶变换操作中避免数值问题,本质是施加高通滤波器。假设输入信号第 个采样点为
,则预加重公式如下:
其中, 是预加重系数,一般取
或
。
1.2 分帧 Frame Segmentation
语音信号是非平稳信号,考虑到发浊音时声带有规律振动,即基音频率在短时范围内时相对固定的,因此可以认为语音信号具有短时平稳特性,一般认为10ms~50ms的语音信号片段是一个准稳态过程(可以近似看为周期性的。所以我们可以把长序列数据切片,每片称为一帧 frame。)。短时分析采用分帧方式,一般每帧帧长为20ms或50ms。假设语音采样率为16kHz,帧长为20ms,则一帧有 16000 x 0.02=320 个样本点。
相邻两帧之间的基音有可能发生变化,如两个音节之间,或者声母向韵母过渡。为确保声学特征参数的平滑性,一般采用重叠取帧的方式,即相邻帧之间存在重叠部分。一般来说,帧长和帧移的比例为 1:4 或 1:5 。
短时分析:虽然语音信号具有时变特性,但是在一个短时间范围内(一般认为在 10-30ms)其特性基本保持相对稳定,即语音具有短时平稳性。所以任何语音信号的分析和处理必须建立在 “短时” 的基础上,即进行“短时分析”。
1.3 加窗
分帧相当于对语音信号加矩形窗,矩形窗在时域上对信号进行截断,在边界处存在多个旁瓣,会发生频谱泄露 spectral leakage。
频谱泄露:
音频处理中,经常需要利用傅里叶变换将时域信号转换到频域,而一次快速傅里叶变换(FFT)只能处理有限长的时域信号,但语音信号通常是长的,所以需要将原始语音截断成一帧一帧长度的数据块。这个过程叫信号截断,也叫分帧(frame segmentation)。分完帧后再对每帧做 FFT,得到对应的频域信号。FFT 是离散傅里叶变换(DFT)的快速计算方式,而做 DFT 有一个先验条件:分帧得到的数据块必须是整数周期的信号,也即是每次截断得到的信号要求是周期主值序列。但做分帧时,很难满足周期截断,因此就会导致频谱泄露。一句话,频谱泄露就是分析结果中,出现了本来没有的频率分量。比如说,50Hz 的纯正弦波,本来只有一种频率分量,分析结果却包含了与 50Hz 频率相近的其它频率分量。
非周期的无限长序列,任意截取一段有限长的序列,都不能代表实际信号,分析结果当然与实际信号不一致!也就是会造成频谱泄露。而周期的无限长序列,假设截取的是正好一个或整数个信号周期的序列,这个有限长序列就可以代表原无限长序列,如果分析的方法得当的话,分析结果应该与实际信号一致!因此也就不会造成频谱泄露。
为了减少频谱泄露,通常对分帧之后的信号进行其它形式的加窗操作。加窗主要是为了使时域信号似乎更好地满足 FFT 处理的周期性要求,减少泄漏(加窗不能消除泄漏,只能减少


常用的窗函数有:汉明(Hamming)窗、汉宁(Hanning)窗和布莱克曼(Blackman)窗等。
汉明窗的窗函数为:
其中, ,
是窗的长度。
汉宁窗的窗函数为:
其中, ,
是窗的长度。

为了减少泄漏,可采用不同的窗函数来进行信号截取,因而,泄漏与窗函数的频谱特征相关的。窗函数的典型频谱特征如下图所示:

各种窗函数频谱特征的主要差别在于:主瓣宽度(也称为有效噪声带宽,ENBW)、幅值失真度、最高旁瓣高度和旁瓣衰减速率等参数。加窗的主要想法是用比较光滑的窗函数代替截取信号样本的矩形窗函数,也就是对截断后的时域信号进行特定的不等计权,使被截断后的时域波形两端突变变得平滑些,以此压低谱窗的旁瓣。因为旁瓣泄露量最大,旁瓣小了泄露也相应减少了。
加窗的代价是一帧信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。
相邻两帧的起始位置的时间差叫做帧移,常见的取法是取为帧长的一半,或者固定取为 10 毫秒。
加窗函数的原则
加窗函数时,应使窗函数频谱的主瓣宽度应尽量窄,以获得高的频率分辨能力;旁瓣衰减应尽量大,以减少频谱拖尾,但通常都不能同时满足这两个要求。各种窗的差别主要在于集中于主瓣的能量和分散在所有旁瓣的能量之比。
窗的选择取决于分析的目标和被分析信号的类型。一般说,有效噪声频带越宽,频率分辨能力越差,越难于分清有相同幅值的邻近频率。选择性(即分辨出强分量频率邻近的弱分量的能力)的提高与旁瓣的衰减率有关。通常,有效噪声带宽窄的窗,其旁瓣的衰减率较低,因此窗的选择是在二者中取折衷。
因而,窗函数的选择一般原则如下:
1. 如果截断的信号仍为周期信号,则不存在泄漏,无须加窗,相当于加矩形窗。
2. 如果信号是随机信号或者未知信号,或者有多个频率分量,测试关注的是频率点而非能量大小,建议选择汉宁窗,像LMS Test.Lab中默认加的就是汉宁窗。
3. 对于校准目的,则要求幅值精确,平顶窗是个不错的选择。
4. 如果同时要求幅值精度和频率精度,可选择凯塞窗。
5. 如果检测两个频率相近、幅值不同的信号,建议用布莱克曼窗。
6. 锤击法试验力信号加力窗,响应可加指数窗。
2. 短时傅里叶变换STFT
人类听觉系统与频谱分析紧密相关,对语音信号进行频谱分析,是认识和处理语音信号的重要方法。声音从频率上可以分为纯音和复合音,纯音只包含一种频率的声音(基音),而没有倍音。复合音是除了基音之外,还包含多种倍音的声音。大部分语音都是复合音,涉及多个频率段,可以通过傅里叶变换进行频谱分析。
把音频的每一帧利用快速傅里叶变换FFT转化成频域数据。时域信号->分帧->每一帧单独处理->加窗->FFT->频域结果(复数)->所有帧结果拼接成时间序列


公式推导:
每个频率的信号可以用正弦波表示,采用正弦函数建模。基于欧拉公式,可以将正弦函数对应到统一的指数形式:
正弦函数具有正交性,即任意两个不同频率的正弦波乘积,在两者的公共周期内积分等于零。正交性用复指数运算表示如下:
基于正弦函数的正交性,通过相关处理可以从语音信号分离出对应不同频率的正弦信号。对于离散采样的语音信号,可以采用离散傅里叶变换(DFT)。DFT的第 k 个点计算如下:
其中, 是时域波形第 n 个采样点值,
是第 k 个傅里叶频谱值, N 是采样点序列的点数,K 是频谱系数的点数,且
。利用DFT获得的频谱值通常是复数形式,这是因为上式中,
则
其中,
N 个采样点序列组成的时域信号经过DFT之后,对应 K 个频率点。经DFT变换得到信号的频谱表示,其频谱幅值和相位随着频率变化而变化。
在语音信号处理中主要关注信号的频谱幅值,也称为振幅频谱/振幅谱:
能量频谱/能量谱是振幅频谱的平方:
各种声源发出的声音大多由许多不同强度、不同频率的声音组成复合音,在复合音中,不同频率成分与能量分布的关系称为声音的频谱,利用频谱图表示各频率成分与能量分布之间的关系,频谱图横轴是频率(Hz),纵轴是幅度(dB)。
通过对频域信号进行逆傅里叶变换(IDFT),可以恢复时域信号:
离散傅里叶变换(DFT)的计算复杂度为 ,可以采用快速傅里叶变换(FFT),简化计算复杂度,在
的时间内计算出DFT。在实际应用中,对语音信号进行分帧加窗处理,将其分割成一帧帧的离散序列,可视为短时傅里叶变换(STFT):
其中, K 是DFT后的频率点个数, k 是频率索引, 。
建立起索引为
的时域信号,与索引为 k 的频域信号之间的关系。



3. 听觉特性 (Bark尺度与Mel尺度)
3.1 梅尔滤波
人类对不同频率的语音有不同的感知能力:
1kHz以下,人耳感知与频率成线性关系。
1kHz以上,人耳感知与频率成对数关系。
因此,人耳对低频信号比高频信号更为敏感。因此根据人耳的特性提出了一种mel刻度,即定义1个mel刻度相当于人对1kHz音频感知程度的千分之一,mel刻度表达的是,从线性频率到“感知频率”的转换关系: (频率f单位是1kHz)
3.2 Bark滤波
声音的响度,反映人对不同频率成分声强/声音强弱的主观感受。响度与声强、频率的关系可以用{ 等响度轮廓曲线}表示。
人耳对响度的感知有一个范围,当声音低于某个响度时,人耳是无法感知到的,这个响度值称为听觉阈值,或称听阈。在实际环境中,但一个较强信号(掩蔽音)存在时,听阈就不等于安静时的阈值,而是有所提高。这意味着,邻近频率的两个声音信号,弱响度的声音信号会被强响度的声音信号所掩蔽(Mask),这就是{ 频域掩蔽 simultaneous masking}。
根据听觉频域分辨率和频域掩蔽的特点,定义能够引起听觉主观变化的频率带宽为一个{
临界频带 Critical band}。一个临界频带的宽度被称为一个Bark,Bark频率 和线性频率
的对应关系定义如下:
其中,线性频率 f 的单位为Hz,临界频带 的单位为Bark。
Bark(巴克)频率尺度是以Hz为单位,把频率映射到心理声学的24个临界频带上,第25个临界频带占据约:16K~20kHz的频率,1个临界频带的宽度等于一个Bark,简单的说,Bark尺度是把物理频率转换到心理声学的频率。Bark尺度频率的中心频率与临界带宽边界频率如下表所示:
| 临界频带 | 频率/Hz | ||
| Bark频带 | 中心频率 | 下界频率 | 上界频率 |
| 1 | 50 | 0 | 100 |
| 2 | 150 | 100 | 200 |
| 3 | 250 | 200 | 300 |
| 4 | 350 | 300 | 400 |
| 5 | 450 | 400 | 510 |
| 6 | 570 | 510 | 630 |
| 7 | 700 | 630 | 770 |
| 8 | 840 | 770 | 920 |
| 9 | 1000 | 920 | 1080 |
| 10 | 1170 | 1080 | 1270 |
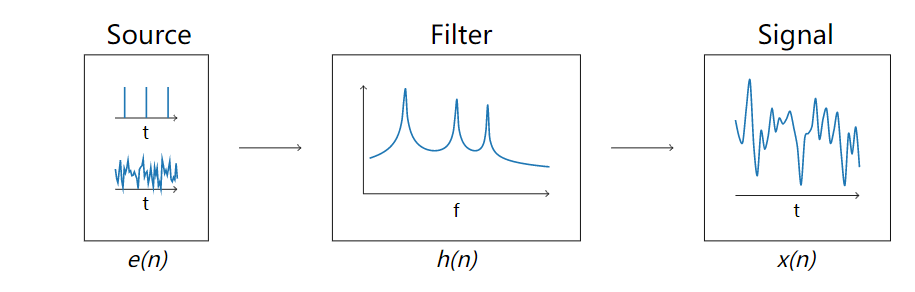
4. 倒谱分析 Cepstral Analysis
语音信号的产生模型包括发生源(Source)和滤波器(Filter)。人在发声时,肺部空气受到挤压形成气流,气流通过声门(声带)振动产生声门源激励 。对于浊音,激励
是以基音周期重复的单位冲激;对于清音,
是平稳白噪声。该激励信号
经过咽喉、口腔形成声道的共振和调制,特别是舌头能够改变声道的容积,从而改变发音,形成不同频率的声音。气流、声门可以等效为一个激励源,声道等效为一个时变滤波器,语音信号
可以被看成激励信号
与时变滤波器的单位响应
的卷积:
已知语音信号 ,待求出上式中参与卷积的各个信号分量,也就是解卷积处理。除了线性预测方法外,还可以采用倒谱分析(Cepstral Analysis)实现解卷积处理。倒谱分析,又称为同态滤波,采用时频变换,得到对数功率谱,再进行逆变换,分析出倒谱域的倒谱系数。
同态滤波的处理过程如下:
- 傅里叶变换。将时域的卷积信号转换为频域的乘积信号:
- 对数运算。将乘积信号转换为加性信号:
- 傅里叶反变换。得到时域的语音信号{
倒谱}。(倒谱域)

log X[k] 代表频谱(梅尔普),log H[k]代表频谱包络,log E[k]代表频谱细节

可以看成 “每秒 4 个周期的正弦波”,
于是在伪频率轴上的 4Hz 上给一个峰值

可以看成 “每秒 100 个周期的正弦波”,
于是在伪频率轴上的 100Hz 上给一个峰值
在实际应用中,考虑到离散余弦变换(DCT)具有最优的去相关性能,能够将信号能量集中到极少数的变换系数上,特别是能够将大多数的自然信号(包括声音和图像)的能量都集中在离散余弦变换后的低频部分。一般采用DCT反变换代替傅里叶反变换,上式可以改写成:
其中, 是DFT变换系数, N 是DFT系数的个数, M 是DCT变换的个数。
此时, 是复倒谱信号,可采用逆运算,恢复出语音信号,但DCT不可逆,从倒谱信号
不可还原出语音
。
MFCC:对线性声谱图应用mel滤波器后,取log,得到log梅尔声谱图,然后对log滤波能量(log梅尔声谱)做DCT离散余弦变换,然后保留第2到第13个系数,得到的这12个系数就是MFCC。
有些论文提到的 DCT(离散傅里叶变换)和 STFT(短时傅里叶变换)其实是差不多的东西。STFT 就是对一系列加窗数据做 FFT。而 DCT 跟 FFT 的关系就是:FFT 是实现 DCT 的一种快速算法。
5. 常见的声学特征
在语音合成中,常用的声学特征有梅尔频谱(Mel-Spectrogram)/滤波器组(Filter-bank,Fank),梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC)等。

5.1 FBank (滤波器组 Filter Banks)
FBank的特征提取过程如下:
- 将信号进行预加重、分帧、加窗,然后进行短时傅里叶变换(STFT)获得对应的频谱。
- 求频谱的平方,即能量谱。进行梅尔滤波,即将每个滤波频带内的能量进行叠加,第
个滤波器输出功率谱为
。
- 将每个滤波器的输出取对数,得到相应频带的对数功率谱。
FBank特征本质上是对数功率谱,包括低频和高频信息。相比于语谱图,FBank经过了梅尔滤波,依据人耳听觉特性进行了压缩,抑制了一部分人耳无法感知的冗余信息。
5.2 MFCC 梅尔频率的倒谱系数(Mel Frequency Cepstral Coefficents)
MFCC和FBank唯一的不同就在于,获得FBank特征之后,再经过反离散余弦变换,就得到 个MFCC系数。在实际操作中,得到的
个MFCC特征值可以作为静态特征,再对这些静态特征做一阶和二阶差分,得到相应的静态特征。
在这之前常用的是线性预测系数 Linear Prediction Coefficients(LPCs)和线性预测倒谱系数(LPCCs),特别是用在 HMM 上。
获得 MFCC 的步骤:首先分帧加窗,然后对每一帧做 FFT 后得到(单帧)能量谱(线性声谱图:STFT 声谱图和 CQT 声谱图),对线性声谱图应用梅尔滤波器后然后取 log 得到 log 梅尔声谱图,然后对 log 滤波能量(log 梅尔声谱)做 DCT,离散余弦变换(傅里叶变换的一种),然后保留第二个到第 13 个系数,得到的这 12 个系数就是 MFCC。
梅尔声谱图
计算mel滤波器组
非人声领域常用的是等高梅尔滤波器(Mel-filter bank with same bank height),如上图。而根据人耳对低频和高频的敏感度不一致,对于低频更加敏感,对于高频不敏感这个特性,在人声领域我们一般使用等面积梅尔滤波器(Mel-filter bank with same bank area),但是如果其用到非人声领域,就会丢掉很多高频信息。
Mel滤波器组就是一系列的三角形滤波器,通常有40个或80个,在中心频率点响应值为1,在两边的滤波器中心点衰减到0,如下图:
具体公式可以写为:m是以Mel为单位的感知频率,f 是以Hz为单位的实际频率




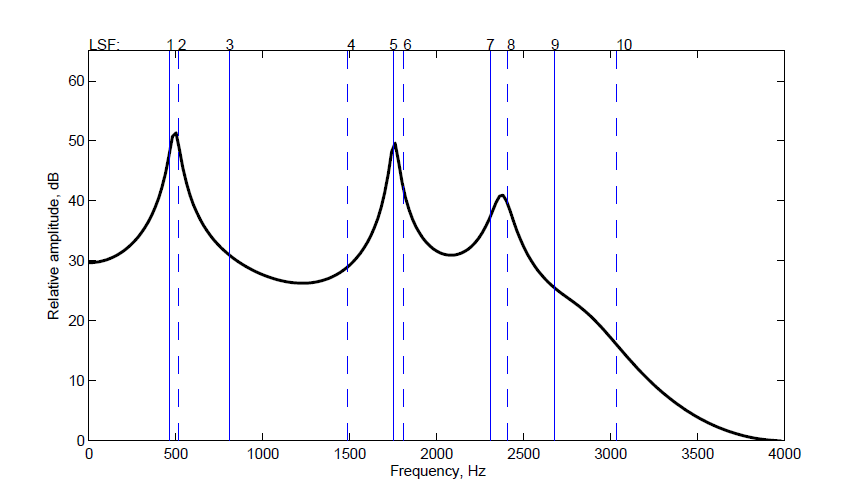
LPC/LSP/LSF之间的关系(从线性预测编码到线谱频率)
线性预测编码(Linear Predictive coding ,LPC),是一种用于语音信号压缩和分析的方法。在LPC模型中,语音信号被看作是由若干个共振峰和各自对应的带通滤波器的输出叠加而成的。LPC算法估计线性滤波器的系数,该滤波器可以近似信号的谱包络,这些系数被称为线性预测系数(Linear Predictive Coefficients,LPCs)。线性预测系数一般用于描述这些带通滤波器的特性,包括各自的带宽、增益和位置等。线谱对(Line Spectral Pairs,LSP)是对线性预测系数的直接数学变换,即对线性预测系数LPCs进行表征。LSP具有良好的量化特性和高效性的表达性,因此在语音编码中被广泛运用。线谱对中单独的线通常被称为线谱频率(line spectral frequencies, LSF)。
The LPC Model
LPC模型可以视为一个全极点共振模型all-pole model,它对信号的频谱包络进行建模,将信号的频谱包络表示为一系列极点,每个极点对应于信号的谐振频率。LPC 的最初目标是模拟人声的生成,它是一个source-filter模型,其中source对声带建模,filter则对声道建模,如下图所示。
LPC 模型的阶数是滤波器中的极点数或共振峰数。通常每个共振峰包含两个极点。添加两到四个极点以表示源特性。LPC阶数与音频文件的采样率有关, 我们可以直接近似计算LPC的阶数N Poles = SR/(F0max*0.25)。
The LSP Representation线性预测求解对LPCs进行表征,由LPC系数推导LSF。在人类实际讲话过程声门并不是完全打开或者闭合的。因此,实际共振发生在LSP奇数和偶数两个极端条件之间某个位置的频率。如下图所示,我们在20ms的语音频谱上绘制LSF(奇数用实线表示,偶数虚数表示)显而易见频谱中的峰值往往被狭窄的LSP夹在中间,但频谱中的局部极小值往往没有LSP在其周围。正是这种特性使得LPC在语音分析、语音分类语音编解码领域被广泛应用。
5.3 deltas,deltas-deltas 一阶差分和二阶差分
也被称为微分系数和加速度系数(differential and acceleration coefficients)。使用它们的原因是,MFCC 只是描述了一帧语音上的能量谱包络,但是语音信号似乎有一些动态上的信息,也就是 MFCC 随着时间的改变而改变的轨迹。有证明说计算 MFCC 轨迹并把它们加到原始特征中可以提高语音识别的表现。
以下是 deltas 的一个计算公式,其中 t 表示第几帧(in terms of the static coefficients to
),N 通常取 2,c 指的就是 MFCC 中的某个系数。deltas-deltas 就是在 deltas 上再计算以此 deltas。

对 MFCC 中每个系数都做这样的计算,最后会得到 12 个一阶差分和 12 个二阶差分,我们通常在论文中看到的 “MFCC 以及它们的一阶差分和二阶差分” 指的就是这个
6. 时频域分析方法
声音信号本是一维的时域信号,直观上很难看出频率变化规律。傅里叶变换可把它变到频域上,虽然可看出信号的频率分布,但是丢失了时域信息,无法看出频率分布随时间的变化。为了解决这个问题,很多时频分析手段应运而生,如短时傅里叶STFT,小波,Wigner分布等都是常用的时频域分析方法。
四、音库制作和文本前端
1. 音库制作
音库的制作一般包括发音人选型、录音文本收集、音频录制、语料整理、标注,共5个步骤。音库的制作对整个语音合成系统的建设较为重要,音库如果建设较差,比如发音人风格难以接受、标注和实际音频不符,之后的努力只会事倍功半。
- 发音人选型:风格 + 音色
根据应用场景选择录音风格、发音人等。首先,语音合成系统在不同场景下,对训练语料的要求有所不同。比如新闻播报场景下,要求发音人播报风;有声书合成场景下,要求发音人抑扬顿挫,富有感情;在车载等领域,则要求交互风;在情感语音合成则要求录制不同情感的语音;甚至在一些特定场景下,比如二次元领域,则要求可爱风等等。其次,不同的发音人对最终的合成语音自然度也有影响,部分发音人发音苍老、低沉,即使同样的文本、声学模型和声码器,最优的超参数,母语者也倾向于给予较低的自然度打分。因此,在音库录音之初,就可以发布有关于录音样品的平均意见得分评测,让母语者或者需求方选择合适的发音人和录音风格。虽然目前后端模型有一些迁移风格、说话人的能力,但最好从源头就做好。 - 录音文本收集: 音素 + 低频词汇 + 文本质量
在一个语种的语音合成建设之初,就可以同步收集该语种对应的大文本。大文本不仅仅可以筛选录音文本,还可以从中提取词条、统计词频、制作词典、标注韵律、构建测试集等等。录音文本的选择一般遵循以下几个原则:- 音素覆盖。这就要求在录音开始之前,就需要构建起来一套基础的文本前端,最起码要有简单的文本转音素(G2P)系统。大部分语种的字符或者字符组合会有较为固定的发音,比如英语中的h总是会发[h]的音,o总是会发[eu]的音,如果找不到公开、即时可用的文本转音素系统,可以根据规则构建。用于录音的文本要保持多样性,音素或者音素组合要尽可能覆盖全,可以统计音素序列中的N-Gram,确保某些音素或者音素组合出现频次过高,而某些音素或音素组合又鲜少出现。
- 场景定制。如果是通用语音合成,需要确保百科、新闻、对话、高频词、基数词和序数词等数字串、包含常用外来词(如包含英语单词)的句子要有所覆盖;如果是特定场景,比如车载领域,则可以收集车载播报的常用话术、专业术语(比如油量、胎压等)、音乐名或歌手名、地名和新闻播报,在特定场景下,需要对业务有一定的理解,并且在一开始就要和需求方紧密沟通。
- 文本正确性。录音文本确保拼写无误,内容正确,比如需要删除脏话、不符合宗教信仰或政治不正确的语句等。
- 音频录制: 环境 + 发音干净
音频的录制对合成语音的表现较为重要,较差的语音甚至会导致端到端声学模型无法正常收敛。用于训练的录音至少要保证录音环境和设备始终保持一致,无混响、背景噪音;原始录音不可截幅;如果希望合成出来的语音干净,则要删除含口水音、呼吸音、杂音、模糊等,但对于目前的端到端合成模型,有时会学习到在合适的位置合成呼吸音、口水音,反而会增加语音自然度。录音尽可能不要事先处理,语速的调节尚可,但调节音效等有时会造成奇怪的问题,甚至导致声学模型无法收敛。音频的录制可以参考录音公司的标准,购买专业麦克风,并保持录音环境安静即可。在音库录制过程中,可尽早提前尝试声学模型,比如音库录制2个小时语音后,就可尝试训练基线语音合成系统,以防止录音不符合最终的需求。 - 语料整理: 文本语音对应正确 + 语料质量
检查文本和录制的语音是否一一对应,录制的音频本身一句话是否能量渐弱,参与训练的语音前后静音段要保持一致,能量要进行规范化。可使用预训练的语音活动检测(Voice Activity Detection,VAD)工具,或者直接根据语音起止的电平值确定前后静音段。可以使用一些开源的工具,比如{pyloudnorm}统一所有语音的整体能量,这将有助于声学模型的收敛。当然,在声学模型模型训练时,首先就要对所有语料计算均值方差,进行统一的规范化,但是这里最好实现统一能量水平,防止一句话前后能量不一致。 - 标注: 检查文本语音匹配,对齐。
标注是所有模型都会遇到的问题,但语音合成中所有语料,特别是音素、音素时长让人类一一标注是不现实的,一般是利用文本前端产生一个基线的音素序列和音素时长,然后让人类参与检查。语音合成中的标注要检查以下几点:- 音素层级。检查语音和音素的一致性;检查重音或音调标注;调整音素边界。
- 单词层级。检查单词的弱化读音情形,比如car[r]某些发音人完全弱读[r],根据录音删除该音素[r],或者给予一个新的音素;外来词和缩略词的发音情况,不同音库可能有不同的处理方法;调整单词边界。
- 句子层级。增删停顿,确保和实际录音一致。
标注人员可以采用{Praat}进行可视化标注和检查。

总而言之,录音完成后,音素序列跟着录音走,语音如何发音,音素序列就严格按照语音标注,实在不行就发回重录。在语音合成中,同样的音频,不同场景的标注有可能是有细微变化的。比如在新闻播报场景下,发音风格比较平淡,某些细微的停顿和韵律变化可以不用在意,标注上也可以不体现;但是在交互或者小说领域,发音风格的变化较为丰富,对韵律和情感控制要求较高,因此标注可能更为精细,甚至会增加额外的标注信息,停顿、韵律等信息的标注可能和播报风有所不同。
2. 文本前端
在实际的生产环境中,直接文本到语音会带来较大的不可控风险,比如“love”/lʌv/读成了/lɪv/,如何快速纠正类似的发音错误;“2kg”如何指定模型读成“两千克”,而非“二kg”等。因此在实际的语音合成系统中,通常会为语音合成系统添加文本前端,主要作用是将文本转换为音素,甚至会添加一些韵律标识构成语言学特征(linguistic feature),以便声学模型更好地建立文本到语音的映射。
文本前端的主要组成:
文本前端一般遵循文本,到规范化文本,到音素这3个基本步骤,同时会从文本和规范化文本中预测韵律。音素和韵律标识统称为语言学特征(linguistic feature)。文本前端的输出作为下游声学模型和声码器的输入,如果发生发音错误等问题,大部分情况下直接修正音素序列即可,大大降低了问题解决的难度。一般来说,文本前端可分为以下五个部分:
- 文本预处理:主要是解决文本中书写错误、一些语种中同形异码等问题。
- 文本归一化:主要解决文本中的特殊符号读法,比如“2kg”转换为“两千克”,另外还要处理一些语种比如波兰语、俄语中的性数格变化。
- 分词:一些语种比如中文、藏语、日语、泰语、越南语、维吾尔语、朝鲜语等并非以空格作为词边界,通常需要分词以便后续的处理,但世界上大部分语种都以空格为词边界,该步骤可省略。
- 文本转音素(G2P):将文本转换为注音,比如“中国”转化为“zhong1 guo2”。
- 韵律分析:语音中每个音素的发音时长不同,停顿也不同。将文本转换为音素之后,通常会加入一定的韵律信息,以帮助声学模型提升合成语音的自然度,加入的韵律信息可以分为音素(L0)、单词(L1)、breath break(L3)和句子(L4)四个韵律层级。
五、声学模型 Acoustic model
现代工业级神经网络语音合成系统主要包括三个部分:文本前端、声学模型和声码器,文本输入到文本前端中,将文本转换为音素、韵律边界等文本特征。文本特征输入到声学模型,转换为对应的声学特征。声学特征输入到声码器,重建为原始波形。
1. Tacotron1


1.1 声学特征建模网络
Tacotron-2的声学模型部分采用典型的序列到序列seq2seq结构。编码器是3个卷积层和一个双向LSTM层组成的模块,卷积层给予了模型类似于N-gram感知上下文的能力,并且对不发音字符更加鲁棒。经词嵌入的注音序列首先进入卷积层提取上下文信息,然后送入双向LSTM生成编码器隐状态。编码器隐状态生成后,就会被送入注意力机制,以生成编码向量。我们利用了一种被称为位置敏感注意力(Location Sensitive Attention,LSA),该注意力机制的对齐函数为:
其中, 为待训练参数,
是偏置值,
为上一时间步
的解码器隐状态,
为当前时间步
的编码器隐状态,
为上一个解码步的注意力权重
经卷积获得的位置特征,如下式:
其中, 是经过softmax的注意力权重的累加和。位置敏感注意力机制不但综合了内容方面的信息,而且关注了位置特征。解码过程从输入上一解码步或者真实音频的频谱进入解码器预处理网络开始,到线性映射输出该时间步上的频谱帧结束,模型的解码过程如下图所示。

频谱生成网络的解码器将预处理网络的输出和注意力机制的编码向量做拼接,然后整体送入LSTM中,LSTM的输出用来计算新的编码向量,最后新计算出来的编码向量与LSTM输出做拼接,送入映射层以计算输出。输出有两种形式,一种是频谱帧,另一种是停止符的概率,后者是一个简单二分类问题,决定解码过程是否结束。为了能够有效加速计算,减小内存占用,引入缩减因子r(Reduction Factor),即每一个时间步允许解码器预测r个频谱帧进行输出。解码完成后,送入后处理网络处理以生成最终的梅尔频谱,如下式所示。
其中, 是解码器输出,
表示最终输出的梅尔频谱,
是后处理网络的输出,解码器的输出经过后处理网络之后获得
。
在Tacotron-2原始论文中,直接将梅尔频谱送入声码器WaveNet生成最终的时域波形。但是WaveNet计算复杂度过高,几乎无法实际使用,因此可以使用其它声码器,比如Griffin-Lim、HiFiGAN等。
1.2 CBHG 模块

1.3 损失函数
Tacotron2的损失函数主要包括以下4个方面:
- 1. 进入后处理网络前后的平方损失。
其中, 表示从音频中提取的真实频谱,
分别为进入后处理网络前、后的解码器输出,
为每批的样本数。
- 2. 从CBHG模块中输出线性谱的平方损失。
其中, 是从真实语音中计算获得的线性谱,
是从CBHG模块输出的线性谱。
- 3. 停止符交叉熵
其中, 为停止符真实概率分布,
是解码器线性映射输出的预测分布。
- 4. L2正则化
其中, 为参数总数,
为模型中的参数,这里排除偏置值、RNN以及线性映射中的参数。最终的损失函数为上述4个部分的损失之和,如下式:
2. FastSpeech
FastSpeech是基于Transformer显式时长建模的声学模型,由微软和浙大提出。
1. 模型结构
FastSpeech 2和上代FastSpeech的编解码器均是采用FFT(feed-forward Transformer,前馈Transformer)块。编解码器的输入首先进行位置编码,之后进入FFT块。FFT块主要包括多头注意力模块和位置前馈网络,位置前馈网络可以由若干层Conv1d、LayerNorm和Dropout组成。
论文中提到语音合成是典型的一对多问题,同样的文本可以合成无数种语音。上一代FastSpeech主要通过目标侧使用教师模型的合成频谱而非真实频谱,以简化数据偏差,减少语音中的多样性,从而降低训练难度;向模型提供额外的时长信息两个途径解决一对多的问题。在语音中,音素时长自不必说,直接影响发音长度和整体韵律;音调则是影响情感和韵律的另一个特征;能量则影响频谱的幅度,直接影响音频的音量。在FastSpeech 2中对这三个最重要的语音属性单独建模,从而缓解一对多带来的模型学习目标不确定的问题。

在对时长、基频和能量单独建模时,所使用的网络结构实际是相似的,在论文中称这种语音属性建模网络为变量适配器(Variance Adaptor)。时长预测的输出也作为基频和能量预测的输入。最后,基频预测和能量预测的输出,以及依靠时长信息展开的编码器输入元素加起来,作为下游网络的输入。变量适配器主要是由2层卷积和1层线性映射层组成,每层卷积后加ReLU激活、LayerNorm和Dropout。
同样是通过长度调节器(Length Regulator),利用时长信息将编码器输出长度扩展到频谱长度。具体实现就是根据duration的具体值,直接上采样。一个音素时长为2,就将编码器输出复制2份,给3就直接复制3份,拼接之后作为最终的输出。
对于音高和能量的预测,模块的主干网络相似,但使用方法有所不同。以音高为例,能量的使用方式相似。首先对预测出的实数域音高值进行分桶,映射为一定范围内的自然数集,然后做嵌入。
3. VITS
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。和Tacotron和FastSpeech不同,Tacotron / FastSpeech实际是将字符或音素映射为中间声学表征,比如梅尔频谱,然后通过声码器将梅尔频谱还原为波形,而VITS则直接将字符或音素映射为波形,不需要额外的声码器重建波形,真正的端到端语音合成模型。VITS通过隐变量而非之前的频谱串联语音合成中的声学模型和声码器,在隐变量上进行建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。VITS合成音质较高,并且可以借鉴之前的FastSpeech,单独对音高等特征进行建模,以进一步提升合成语音的质量,是一种非常有潜力的语音合成模型。
3.1 模型整体结构

VITS包括三个部分:
- 后验编码器(Posterior Encoder)。如上图(a)的左下部分所示,在训练时输入线性谱,输出隐变量
,推断时隐变量
产生。VITS的后验编码器采用WaveGlow和Glow-TTS中的非因果WaveNet残差模块。应用于多人模型时,将说话人嵌入向量添加进残差模块,{ 仅用于训练}。这里的隐变量
- 解码器Decoder。如上图(a)左上部分所示,解码器从提取的隐变量
- 先验编码器。如上图(a)右侧部分所示,先验编码器结构比较复杂,作用类似于Tacotron / FastSpeech的声学模型,只不过VITS是将音素映射为中间表示
- 随机时长预测器Stochastic Duration Predictor。如上图(a)右侧中间橙色部分。从条件输入
估算音素时长的分布。应用于多人模型时,在说话人嵌入向量之后添加一个线性层,并将其拼接到文本编码器的输出
- 判别器。实际就是HiFi-GAN的多周期判别器,在上图中未画出,{ 仅用于训练}。目前看来,对于任意语音合成模型,加入判别器辅助都可以显著提升表现。
3.2 变分推断
VITS可以看作是一个最大化变分下界,也即ELBO(Evidence Lower Bound)的条件VAE。
六、声码器(Vocoder)
声码器(Vocoder),又称语音信号分析合成系统,负责对声音进行分析和合成,主要用于合成人类的语音。声码器主要由以下功能:分析Analysis,操纵Manipulation,合成Synthesis
分析过程主要是从一段原始声音波形中提取声学特征,比如线性谱、MFCC;操纵过程是指对提取的原始声学特征进行压缩等降维处理,使其表征能力进一步提升;合成过程是指将此声学特征恢复至原始波形。人类发声机理可以用经典的源-滤波器模型建模,也就是输入的激励部分通过线性时不变进行操作,输出的声道谐振部分作为合成语音。输入部分被称为激励部分(Source Excitation Part),激励部分对应肺部气流与声带共同作用形成的激励,输出结果被称为声道谐振部分(Vocal Tract Resonance Part),对应人类发音结构,而声道谐振部分对应于声道的调音部分,对声音进行调制。
声码器的发展可以分为两个阶段,包括用于统计参数语音合成(Statistical Parameteric Speech Synthesis,SPSS)基于信号处理的声码器,和基于神经网络的声码器。常用基于信号处理的声码器包括Griffin-Lim,STRAIGHT 和 WORLD。早期神经声码器包括WaveNet、WaveRNN等,近年来神经声码器发展迅速,涌现出包括MelGAN、HiFiGAN、LPCNet、NHV等优秀的工作。
1. Griffin-Lim声码器
原始的音频很难提取特征,需要进行傅里叶变换将时域信号转换到频域进行分析。音频进行傅里叶变换后,结果为复数,复数的绝对值就是幅度谱,而复数的实部与虚部之间形成的角度就是相位谱。经过傅里叶变换之后获得的幅度谱特征明显,可以清楚看到基频和对应的谐波。基频一般是声带的频率,而谐波则是声音经过声道、口腔、鼻腔等器官后产生的共振频率,且频率是基频的整数倍。
Griffin-Lim将幅度谱恢复为原始波形,但是相比原始波形,幅度谱缺失了原始相位谱信息。音频一般采用的是短时傅里叶变化,因此需要将音频分割成帧(每帧20ms~50ms),再进行傅里叶变换,帧与帧之间是有重叠的。Griffin-Lim算法利用两帧之间有重叠部分的这个约束重构信号,因此如果使用Griffin-Lim算法还原音频信号,就需要尽量保证两帧之间重叠越多越好,一般帧移为每一帧长度的25%左右,也就是帧之间重叠75%为宜。
Griffin-Lim在已知幅度谱,不知道相位谱的情况下重建语音,算法的实现较为简单,整体是一种迭代算法,迭代过程如下:
- 随机初始化一个相位谱;
- 用相位谱和已知的幅度谱经过逆短时傅里叶变换(ISTFT)合成新语音;
- 对合成的语音做短时傅里叶变换,得到新的幅度谱和相位谱;
- 丢弃新的幅度谱,用相位谱和已知的幅度谱合成语音,如此重复,直至达到设定的迭代轮数。
在迭代过程中,预测序列与真实序列幅度谱之间的距离在不断缩小,类似于EM算法。推导过程参见:\href{https://zhuanlan.zhihu.com/p/102539783}{Griffin Lim算法的过程和证明}和\href{https://zhuanlan.zhihu.com/p/66809424}{Griffin Lim声码器介绍}。
2. STRAIGHT声码器
STARIGHT(Speech Transformation and Representation using Adaptive Interpolation of weiGHTed spectrum),即利用自适应加权谱内插进行语音转换和表征。STRAIGHT将语音信号解析成相互独立的频谱参数(谱包络)和基频参数(激励部分),能够对语音信号的基频、时长、增益、语速等参数进行灵活的调整,该模型在分析阶段仅针对语音基音、平滑功率谱和非周期成分3个声学参数进行分析提取,在合成阶段利用上述3个声学参数进行语音重构。
STRAIGHT采用源-滤波器表征语音信号,可将语音信号看作激励信号通过时变线性滤波器的结果。
Probabilistic formulation
重要的TTS范式。WaveNet 最早是作为文本到波形模型(text-to-waveform)推出的(因此结合了声学模型(acoustic model)和声码器(vocoding)),可根据附加信息进行局部和全局调节;后来它被扩展为从输入频谱图(spectrograms)合成波形,从而沦为传统声码器的角色。GAN 通常用于将频谱图映射为波形(有效地充当声码器(vocoders)),或从随机输入中 "想象 "波形,因此包含了 TTS 管道的所有中间步骤以及决定输出何种文本的机制。Tacotron 利用 seq2seq 模型来学习音素/字符(phonemes/characters)到音频特征的映射,从而隐含地将文本分析与声学模型(acoustic model)结合起来;FastSpeech 在此基础上进行了迭代,用 Transformers 代替了 RNN。

Resources
GitHub - ddlBoJack/Speech-Resources: 语音方向实验室/公司/资源/实习等,欢迎推荐或自荐
https://github.com/rossant/awesome-math?tab=readme-ov-file#signal-processing
References
中文:Speech Synthesis: Past, Present and Future (2019),ppt
英文:Statistical approach to speech synthesis---past, present, and future(2019)
In Search of the Optimal Acoustic Features for Statistical Parametric Speech Synthesis
语音合成到了跳变点?深度神经网络变革TTS最新研究汇总-腾讯云开发者社区-腾讯云
LPC/LSP/LSF之间的关系(从线性预测编码到线谱频率) - 实时互动网
整合向:
GitHub - cnlinxi/book-text-to-speech: A book about Text-to-Speech (TTS) in Chinese.

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









